Qwen3技术报告笔记
摘要
昨晚Qwen3发布了完整的技术报告,介绍了最新的 Qwen3 系列模型,包含稠密架构和 MoE 架构,参数规模从 0.6B 到 235B。Qwen3 将“思考模式”(用于复杂、多步推理)和“非思考模式”(用于快速、上下文驱动的响应)整合入统一框架,无需切换模型。同时引入“思考预算”机制,用户可自适应地分配计算资源。实验评估表明,Qwen3 在代码生成、数学推理、智能体任务等多个基准测试上取得了业界领先的成果。
技术要点
- 双模式统一架构:集成“思考 / 非思考”模式,动态切换无需加载不同模型。
- 思考预算机制:支持用户控制推理深度(token 预算),兼顾性能与延迟。
- 强指导弱蒸馏机制
- 旗舰模型(最大稠密Qwen3-32B和Qwen3-235B-A22B)采用完整后训练流程;
- 轻量模型由旗舰模型蒸馏,高效提升推理与对齐能力,显著减少训练成本。
- 大规模多语训练:语言覆盖从 29 种扩展至 119 种,跨语言能力显著增强。
- 长上下文处理能力:支持最长 32K token 输入,并可继续扩展。
- 通用 RL 奖励体系 :构建涵盖格式、指令、风格、工具使用等 20+ 任务的 RL 奖励系统。
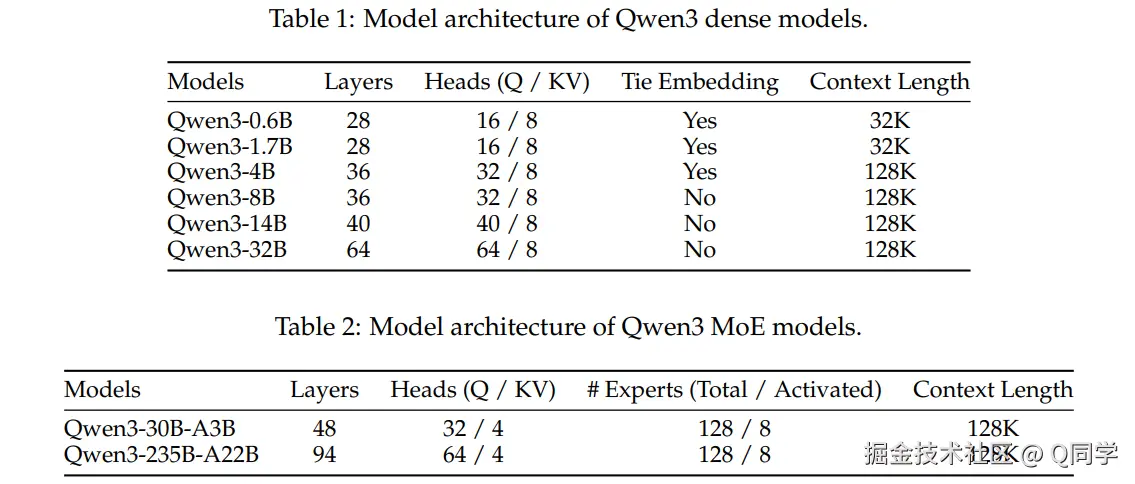
1. 模型架构
1.1 模型规模与结构
- 稠密模型系列:
Qwen3-0.6B、1.7B、4B、8B、14B、32B - MoE 模型系列:
- Qwen3-30B-A3B
- 旗舰模型 Qwen3-235B-A22B(235B 总参数,22B 激活)
- 基础架构:
- Transformer架构(同 Qwen2.5)
- Grouped Query Attention (GQA)
- SwiGLU 激活函数
- 旋转位置编码(RoPE)
- RMSNorm + 预归一化
- 相比Qwen2.5移除 QKV-bias,引入 QK-Norm 提升稳定性
- MoE 特性:
- 128 个专家,每 token 激活 8 个
- 移除共享专家,采用全局批次负载均衡损失提升专家专精性
1.2 思维模式机制
-
双模式融合:支持“思考模式”(复杂推理)与“非思考模式”(快速响应),通过
<think>标签动态切换,无需加载不同模型。

-
思考预算控制:用户可设定推理 token 预算,达到预算后自动结束思考(通过添加如下Prompt到think中并直接结束思考)并输出结果。
<think>…Considering the limited time by the user,
I have to give the solution based on the thinking directly now.</think>
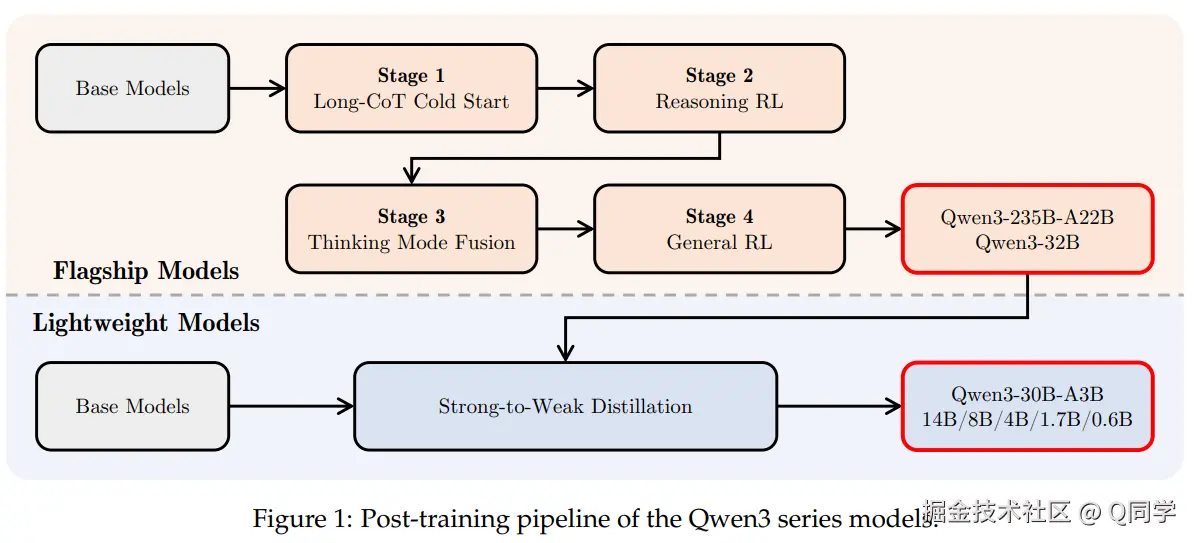
2. 训练流程
完整训练流程如下图所示:
- 对于旗舰模型(Qwen3-32B和Qwen3-235B-A22B),采用完整的四阶段后训练;
- 对于轻量级模型(Qwen3-0.6B/1.7B/4B/8B/14B/30B-A3B),则采用从旗舰模型蒸馏得到,节省算力,提升性能。
2.1 预训练阶段(Pre-training)
数据规模与构成
- 总 Token 数:36T
- 语言覆盖:29 → 119 种语言与方言
- 数据来源:
- 真实文本(PDF OCR + 精炼)
- 合成数据(Qwen2.5-Coder、Qwen2.5-Math 等模型生成)
- 教材、QA、指令、代码、多语种文本
三阶段预训练
- 通用阶段:30T tokens,序列长 4,096
- 推理阶段:聚焦 STEM/代码/推理,额外 5T tokens
- 长上下文阶段
- 数千亿 tokens,最大上下文扩展至 32k
- 引入 ABF 技术、YARN 与 Dual Chunk Attention
2.2 后训练阶段(Post-training)
四阶段流程
- Long-CoT 冷启动:构建复杂问题集,人工筛选+多轮过滤,高质量 CoT 微调;
- Reasoning RL:在强推理任务上使用 GRPO 算法优化,稳定提升数学等复杂推理等任务表现;
- 思考模式融合:微调融合数据,引入 chat 模板,使用/think//no think控制模式;
- 通用强化学习:构建20+奖励任务,结合规则、参考答案(Qwen2.5-72B-Instruct打分)、偏好评分(RLHF数据集)三种奖励方式,旨在提升泛化、稳定性与对齐能力。
强指导弱蒸馏
- 离线策略蒸馏:模仿教师模型响应;
- 在线策略蒸馏:最小化与教师 logits 的 KL 散度;
- 优势:GPU 使用成本仅为 RL 的 1/10。
3. 评测与性能
3.1 评估维度
- 通用任务:MMLU、BBH、SuperGPQA等
- 推理任务:GSM8K、MATH、GPQA等
- 编程任务:LiveCodeBench、BFCL v3、Codeforces Elo等
- 多语言任务:MMMLU、INCLUDE、MT-AIME、MLogiQA等
- 对齐评估:IFEval、Arena-Hard、WritingBench等
3.2 关键结果
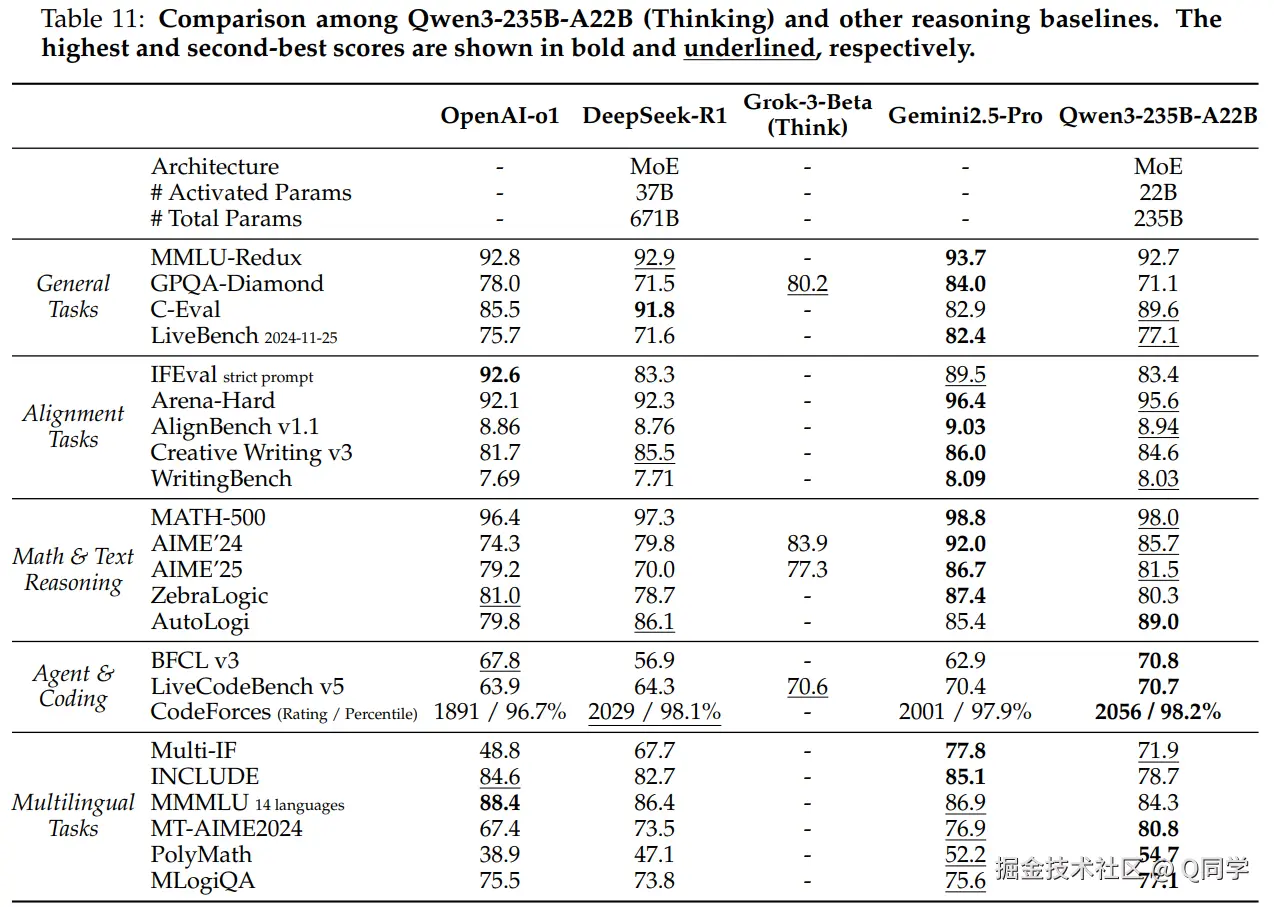
旗舰模型
- Qwen3-235B-A22B
- 思考模式:在 23 个任务中,17 个超越 DeepSeek-R1(仅 60% 激活参数)
- 非思考模式:在 23 个任务中,18 次胜过 GPT-4o (2024-11-20)
- 总体性能优于所有开源模型,接近或超过部分闭源模型
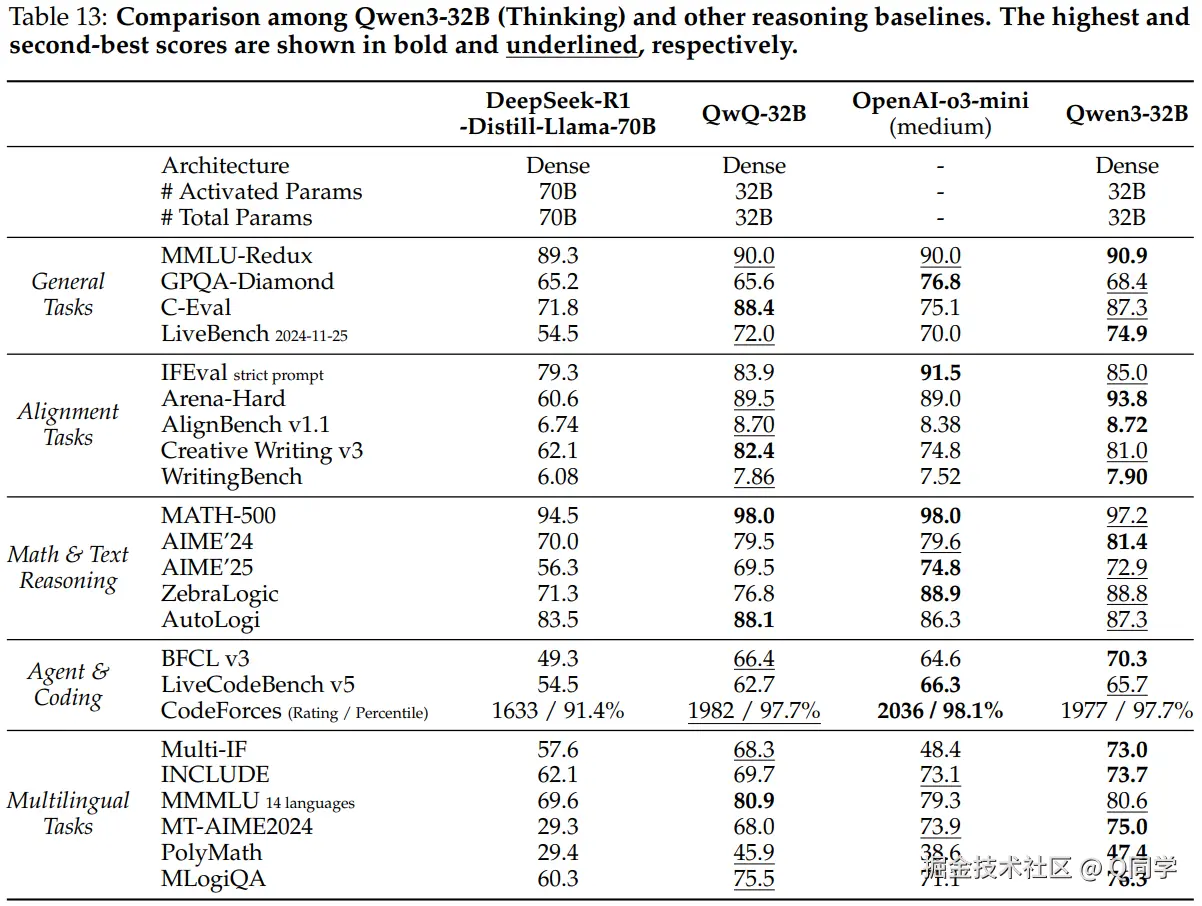
- Qwen3-32B
- 思考模式:超越 QwQ-32B,接近 OpenAI o3-mini
- 非思考模式:非思考模式超过 Qwen2.5-72B-Instruct,但参数仅不到72B一半。
轻量模型(0.6B–14B & MoE 30B)
- 超越同规模模型,多项任务表现优异,Qwen3各个规格模型表现与Qwen2.5更大一个规格的模型相当;
- 蒸馏方法显著提升代码与数学性能;

4. 讨论
更高的预算带来更好的效果
本文实验了不同的思考预算下,复杂推理任务的性能表现。基本表现出更高的思考预算带来更好的性能表现这一现象。
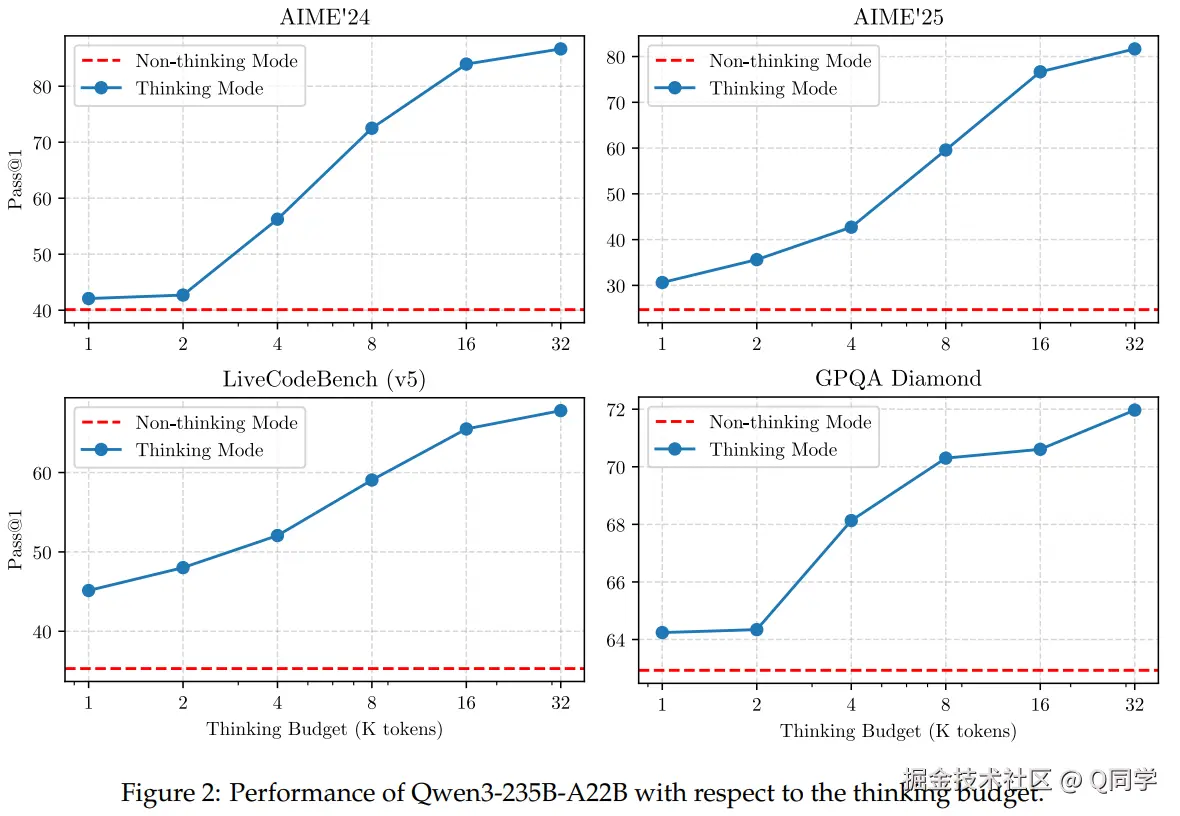
复杂推理 vs. 通用能力
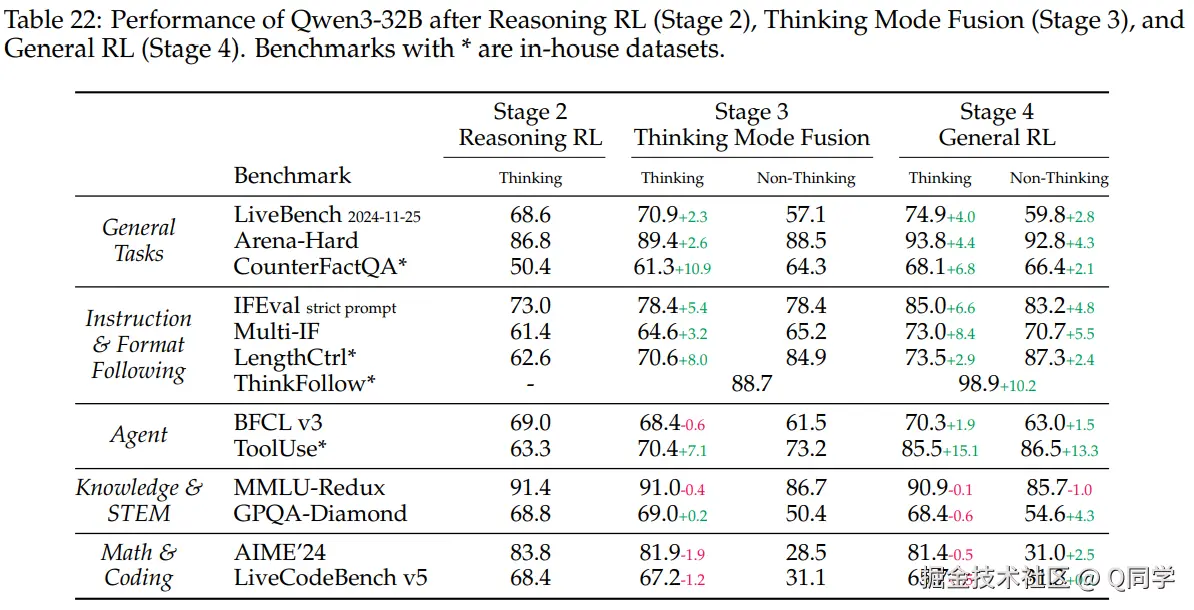
强化学习阶段后,复杂推理能力达到峰值;然而,在Stage 4通用强化学习后,复杂推理略有下降,但通用任务表现提升。
蒸馏效果优于 RL
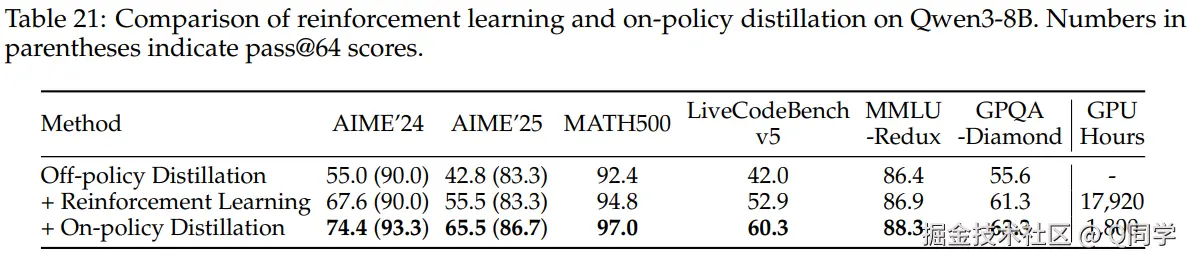
对轻量模型而言,离线+在线蒸馏在性能提升与资源消耗上均优于纯 RL 方法(仅1/10 GPU hours)。
5 总结
Qwen3 在模型架构、思考控制、训练策略与多语言能力上均实现了重要突破,体现了开放预训练模型在智能推理、任务泛化与效率平衡之间的新进展。尤其是通过思考预算机制与强指导弱蒸馏策略,展示了将大模型能力压缩迁移至轻量模型的可行路径,为未来实际部署提供了重要借鉴。