大数据 笔记
kafka
kafka作为消息队列为什么发送和消费消息这么快?
- 消息分区:不受单台服务器的限制,可以不受限的处理更多的数据
- 顺序读写:磁盘顺序读写,提升读写效率
- 页缓存:把磁盘中的数据缓存到内存中,把对磁盘的访问变为对内存的访问
- 零拷贝:减少上下文切换及数据拷贝
- 消息压缩:减少磁盘IO和网络IO
- 分批发送:将消息打包批量发送,减少网络开销
消息丢失
一、生产者端防丢失
- 使用带回调的发送API
- 避免使用
producer.send(msg),改用producer.send(msg, callback),通过回调确认发送结果。
- 避免使用
- 配置重试机制
- 设置
retries > 0(如3),自动重试因网络抖动导致的发送失败。
- 设置
- 设置高可靠性参数
acks=all:确保Leader和所有ISR副本都持久化消息后才返回确认。
二、Broker端防丢失
- 禁用非同步Leader选举
- 设置
unclean.leader.election.enable=false,防止落后副本成为Leader导致数据丢失。
- 设置
- 多副本冗余
replication.factor >= 3:至少3个副本存储消息。
- 最小同步副本数
min.insync.replicas > 1(如2),确保消息写入多个副本才视为成功。- 需满足
replication.factor > min.insync.replicas(如3副本+2最小同步)。
三、消费者端防丢失
- 关闭自动提交位移
- 设置
enable.auto.commit=false,改为手动提交位移。
- 设置
- 同步+异步组合提交
try {while (true) {ConsumerRecords<String, String> records = consumer.poll();process(records); // 处理消息consumer.commitAsync(); // 异步提交(非阻塞)}
} catch (Exception e) {handle(e);
} finally {consumer.commitSync(); // 最终同步提交(确保位移正确)consumer.close();
}如何解决消息积压问题
消息积压会导致很多问题,⽐如磁盘被打满、⽣产端发消息导致kafka性能过慢,最后导致出现服务雪崩不可用,解决方案如下:
- 如果是Kafka消费能力不足,则可以考虑增加Topic的分区数,并且同时提升消费组的消费者数量,消费者数 = 分区数。因为主题的一个分区只能被消费者组中一个消费者消费,假如我们消费者组里有3个消费者,但是主题就一个分区,这就白白空着两个消费者无所事事。如果已经是多个消费者对应多个分区了,还是消费比较慢,就说明是消息消息的代码逻辑过重处理过慢,可以引入多线程异步操作,但这时候需要自己控制代码逻辑来保证消费的顺序性,因为一个分区内的消息是有序的,被一个消费者顺序消费,但是当消费者开启多线程处理之后就不能保证顺序消费了。
- 如果是下游的数据处理不及时:提高每批次拉取的数量。批次拉取数据过少(拉取数据/处理时间 < 生产速度),使处理的数据小于生产的数据,也会造成数据积压。比如说可以从一次最多拉取500条,调整为一次最多拉取1000条。简单来说就是在消费能力跟得上的同时,尽量保证消费速度>生产速度,这样就不会堆积了。
重复消费
生产者幂等性(enable.idempotence=true)
- 原理:Kafka通过
Producer ID (PID)和Sequence Number实现。每个生产者初始化时分配唯一PID,每条消息携带递增序列号。Broker会校验序列号,拒绝重复消息
props.put("enable.idempotence", "true");
props.put("acks", "all"); // 必须配合acks=all消费者手动提交Offset
- 问题:自动提交可能导致消息处理未完成但Offset已提交,引发重复消费
- 解决方案:
- 同步提交:确保Offset提交成功后再处理下批数据,但阻塞性能
- 异步提交:非阻塞但可能失败,需结合重试机制
props.put("enable.auto.commit", "false");
consumer.commitSync(); // 或commitAsync()Redis
持久化
AOF日志(存操作命令,比较完整,文件较大),RDB快照(存二进制数据,比较快,文件较小)
AOF:
Redis 是先执行写操作命令后,才将该命令记录到 AOF 日志里的,这么做有两个好处。
1.避免额外的检查开销。因为如果先将写操作命令记录到 AOF 日志里,再执行该命令的话,如果当前的命令语法有问题,那么如果不进行命令语法检查,该错误的命令记录到 AOF 日志里后,Redis 在使用日志恢复数据时,就可能会出错。
2.不会阻塞当前写操作命令的执行.因为当写操作命令执行成功后,才会将命令记录到 AOF 日志。
写回:在redis.conf配置文件中的appendfsync配置项可以有以下3种参数可:填
Always,Everysec,No,无法同时兼顾“主进程阻塞”和“减少数据丢失”
RDB:
save 是在主线程生成RDB文件,会阻塞主线程
bgsave 会创建一个子进程来生成RDB文件,这样可以避免主线程的阻塞
另外在执行过程中,reids依然可以继续处理操作命令,因为是“写时复制”(fork)
什么是缓存雪崩、缓存击穿、缓存穿透
1缓存雪崩
原因:
- 大量缓存数据同时过期
- Redis集群宕机
应对方法:
- 数据过期:
- 均匀设置过期时间(加随机值)
- 互斥锁(单线程重建缓存)
- 后台线程定时更新缓存(不设过期时间)
- 集群宕机:
- 服务熔断/限流(保护数据库)
- 构建Redis高可用集群(主从切换)
2. 缓存击穿
原因:
- 热点数据突然过期,大量请求直接击穿到数据库
应对方法:
- 互斥锁(防止并发重建)
- 热点数据永不过期 + 后台异步更新
3. 缓存穿透
原因:
- 请求的数据既不在缓存也不在数据库(恶意攻击或误删)
应对方法:
- 接口校验(过滤非法请求)
- 缓存空值/默认值
- 布隆过滤器(快速判断数据是否存在)
核心区别:
- 雪崩/击穿:数据最终存在,但缓存失效导致数据库压力。
- 穿透:数据根本不存在,需拦截无效请求。
缓存与数据库两者的数据不一致
1 先更新数据库再删除缓存 策略
读操作:先读缓存,缓存命中直接返回,缓存没有命中,读数据库,先返回给缓存,再返回给用户。
写操作:更新数据库,然后删除缓存
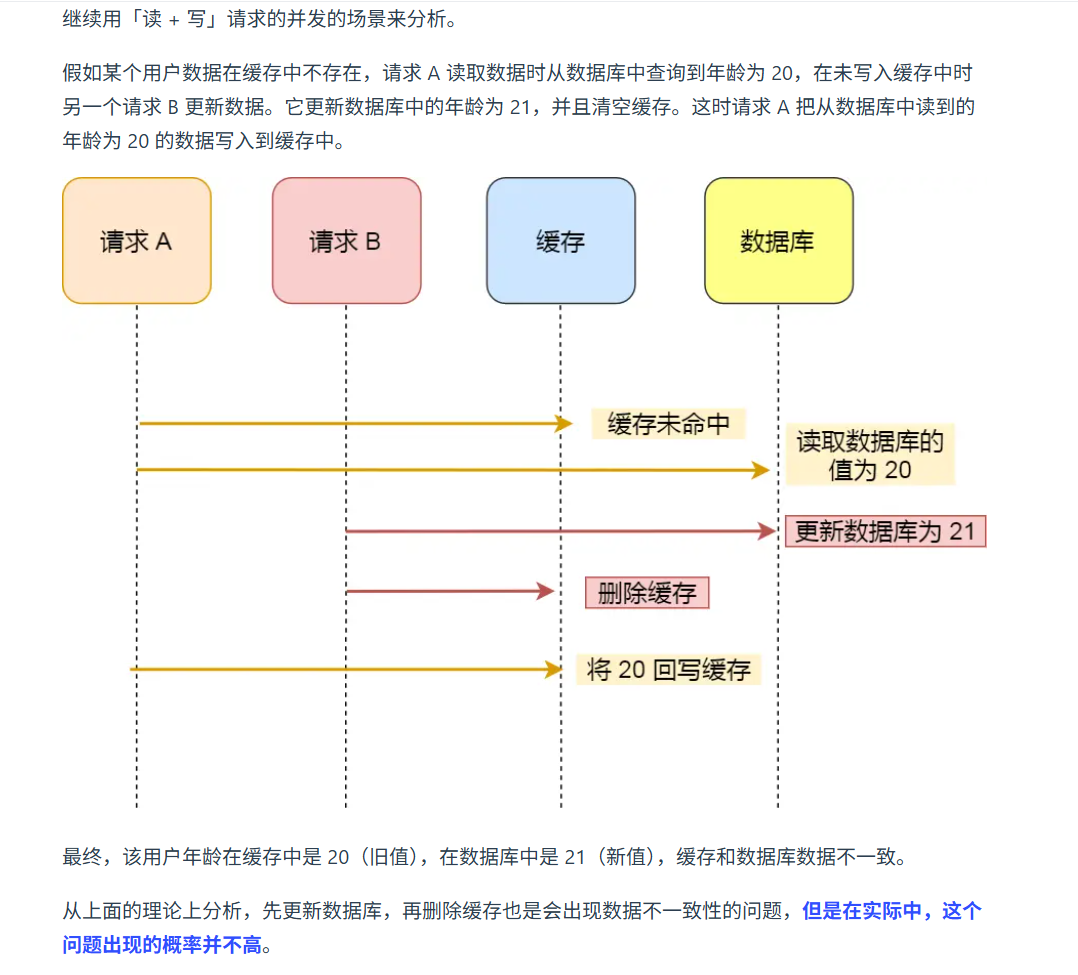
2 先更新数据库再更新缓存 策略
在更新缓存前先加个分布式锁,保证同一时间只运行一个请求更新缓存,就会不会产生并发问题了,当然引入了锁后,对于写入的性能就会带来影响。
在更新完缓存时,给缓存加上较短的过期时间,这样即时出现缓存不一致的情况,缓存的数据也会很快过期,对业务还是能接受的。