DRIVEVLM: 大视觉语言模型和自动驾驶的融合
《DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models》2024年2月发表,来自清华和理想汽车的论文。
城市环境中自动驾驶的一个主要障碍是理解复杂和长尾的场景,例如具有挑战性的道路条件和微妙的人类行为。我们介绍DriveVLM,这是一种利用视觉语言模型(VLM)增强场景理解和规划能力的自动驾驶系统。DriveVLM集成了用于场景描述、场景分析和分层规划的推理模块的独特组合。此外,认识到VLM在空间推理和繁重计算要求方面的局限性,我们提出了DriveVLM-Dual,这是一种混合系统,将DriveVLM的优势与传统的自动驾驶管道相结合。在nuScenes数据集和我们的SUP-AD数据集上的实验证明了DriveVLM和DriveVLM Dual在处理复杂和不可预测的驾驶条件方面的有效性。最后,我们将DriveVLM Dual部署在生产车辆上,验证它在现实世界的自动驾驶环境中是有效的。
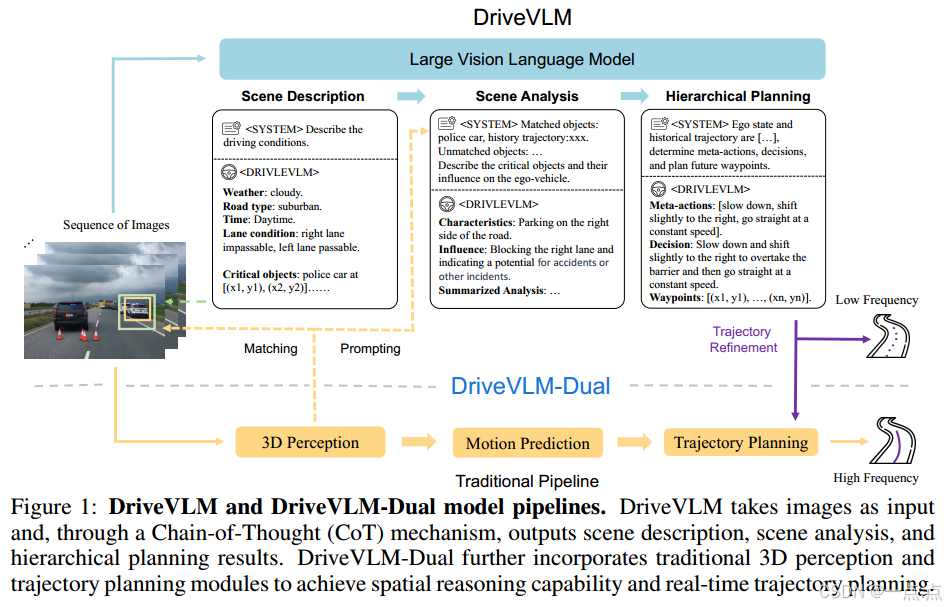
1. 研究背景与问题
自动驾驶在城市环境中的核心挑战是应对复杂长尾场景(如恶劣天气、特殊路况、突发行人行为)。传统自动驾驶系统依赖3D感知、运动预测与规划模块,但存在以下不足:
-
3D感知:仅能检测常见物体,忽略罕见物体(如道路碎片、特殊动物)。
-
运动预测与规划:侧重轨迹预测,缺乏对物体与车辆间决策级交互的理解。
-
场景理解:难以处理动态、非结构化环境中的语义信息。
2. 核心创新:DriveVLM与DriveVLM-Dual
DriveVLM
-
架构:基于视觉语言模型(VLM,如Qwen-VL),通过链式推理(CoT)实现场景理解与规划,包含三模块:
-
场景描述:语言化描述环境(天气、时间、道路类型、车道条件)并识别关键物体。
-
场景分析:分析关键物体的静态属性(如卡车载货)、动态状态(位置、速度)及特殊行为(如交警手势)。
-
分层规划:生成元动作(如加速、变道)、决策描述(动作-主体-时长)及轨迹航点。
-
-
优势:通过自然语言增强语义理解,解决长尾场景的泛化问题。
DriveVLM-Dual
-
设计动机:解决VLM在空间推理不足与高计算延迟的缺陷。
-
混合架构:
-
3D感知融合:将传统3D检测结果与VLM的2D关键物体匹配,提升空间定位精度。
-
高频轨迹优化:结合VLM的慢速全局规划与传统模块的快速局部调整(如优化器或神经网络),实现实时响应。
-
-
类比人类思维:类似“快思考”(传统规划)与“慢思考”(VLM推理)的协同。
3. 数据集与评估

-
SUP-AD数据集:
-
构建方法:通过长尾物体挖掘(CLIP搜索)、挑战场景筛选(驾驶行为方差)、关键帧标注(人工+工具辅助)构建。
-
特点:覆盖40+场景类别(如施工路段、动物穿行、警察指挥),包含环境描述、元动作序列、轨迹航点等标注。
-
-
评估指标:
-
场景描述/分析:基于GPT-4对比生成结果与人工标注的语义一致性。
-
元动作匹配:动态规划算法结合语义等价序列(GPT-4生成变体)评估决策合理性。
-
4. 实验结果
-
SUP-AD测试:DriveVLM(Qwen-VL)在场景描述(0.71分)与元动作(0.37分)上显著优于Lynx、CogVLM及GPT-4V。
-
nuScenes验证:DriveVLM-Dual与VAD结合时,3秒位移误差(0.48m)与碰撞率(0.17%)达SOTA。
-
消融实验:关键物体分析与3D感知的引入分别降低平均位移误差9%与22%。
5. 实际部署
-
硬件适配:在OrinX芯片上优化模型(量化、Token压缩、推测采样),推理速度达410ms/帧。
-
模型选择:Qwen系列(宽浅架构)在速度与精度平衡上优于Phi-3、Gemma等模型。
-
效果验证:实际路测显示系统能处理交警指挥、动物穿行、复杂变道等场景(见附录可视化结果)。
6. 贡献总结
-
系统创新:首次将VLM深度集成至自动驾驶,提出混合架构DriveVLM-Dual。
-
数据与评估:构建SUP-AD数据集,定义场景理解任务及量化评估方法。
-
工程实践:成功部署至量产车,验证实时性与鲁棒性。
7. 未来挑战
-
计算效率:VLM的高算力需求仍需进一步优化。
-
长尾泛化:更复杂的罕见场景(如极端天气组合)需持续扩充数据。
-
安全边界:VLM生成决策的可解释性与安全性验证需结合形式化方法。
8. 应用前景
DriveVLM为自动驾驶提供了一种语义驱动的决策范式,未来可扩展至机器人、无人机等领域,尤其在需要复杂环境交互的任务中潜力显著。
如果此文章对您有所帮助,那就请点个赞吧,收藏+关注 那就更棒啦,十分感谢!!!