Transformer到底解决什么问题?
前言
Transformer这个概念来自于Google研究团队,在2017发表的一篇论文《Attention Is All You Need》,从发布的名称来看,这个理论将会统一NLP领域,从此以后只需Attention。
先讲下什么是 词嵌入(Word Embedding)
将单词向量化,映射为高维向量,使得单词之间的语义关系,可以在向量空间中得以体现。同一语境下的词语往往拥有相近的语义。
比如,可以把词嵌入比作字典里的每个词有一个独特的数字身份证,但这个身份证不是随机的,而是根据词的意思和用法生成的。相似的词在数字空间里位置相近。比如“猫”和“狗”都是宠物,它们的向量可能比较接近,而“猫”和“汽车”就离得远。而这个向量地图通过大量文本数据训练得到的,模型学习词语的上下文,比如Word2Vec、GloVe这些方法。例如,通过预测周围的词,模型调整词向量,让经常一起出现的词向量更接近。

那么是不是每次将词语映射到向量空间都需要重新训练模型呢,当然不是;训练好的模型就像一个字典,比如猫狗鸡鸭这些词语无论在什么语境下都非常接近,我们只需要通过查表的方式去完成映射就可以。但是如果是具备多语义的词语我们该如何处理呢,那么就引出了 Transformer;
资源分享
为了方便大家学习,我整理了Transformer全套学习资料,包含教程、讲义、源码、论文和面试题
除此之外还有100G人工智能学习资料
包含数学与Python编程基础、深度学习+机器学习入门到实战,计算机视觉+自然语言处理+大模型资料合集,不仅有配套教程讲义还有对应源码数据集。更有零基础入门学习路线,不论你处于什么阶段,这份资料都能帮助你更好地入门到进阶。
需要的兄弟可以按照这个图的方式免费获取
什么是Transformer
Transformer结构也是参考我们人脑的思维方式,我们人脑在获取信息时会选择性的划重点,忽略掉一些无关紧要的东西。比如“我是一个浙江杭州的程序员,我正在写一篇关于Transformer分享的文章”,人类在看到这句话时的反应都会是 我在写Transformer文章和浙江杭州有什么关系呢?因此我们自然而然的会把注意放在程序员和Transformer上。
Transformer经典架构图
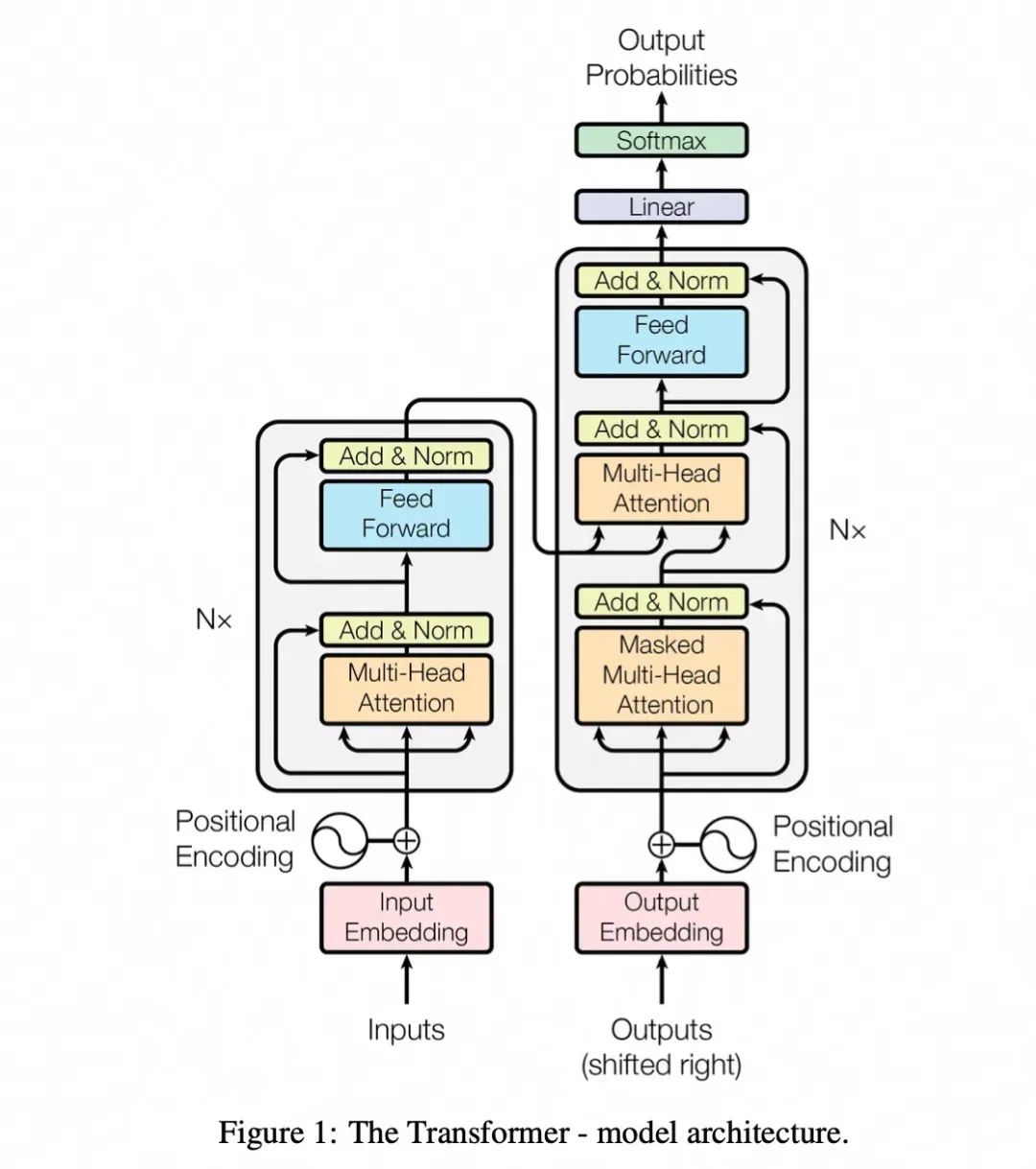
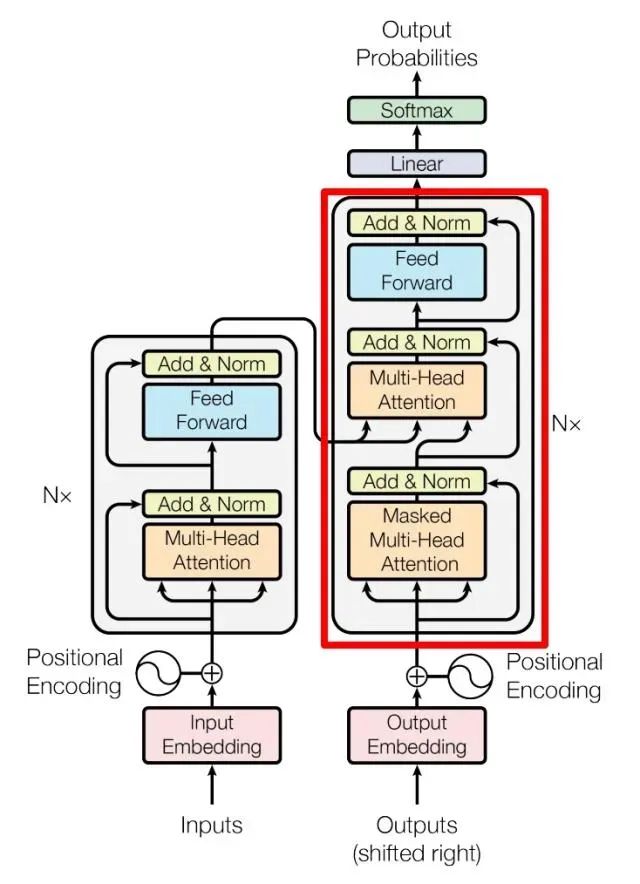
上图是论文中 Transformer 的内部结构图,左侧为 Encoder block,右侧为 Decoder block。红色圈中的部分为 Multi-Head Attention,是由多个 Self-Attention组成的,可以看到 Encoder block 包含一个 Multi-Head Attention,而 Decoder block 包含两个 Multi-Head Attention (其中有一个用到 Masked)。Multi-Head Attention 上方还包括一个 Add & Norm 层,Add 表示残差连接 (Residual Connection) 用于防止网络退化,Norm 表示 Layer Normalization,用于对每一层的激活值进行归一化。
举例:用Transformer做中英翻译
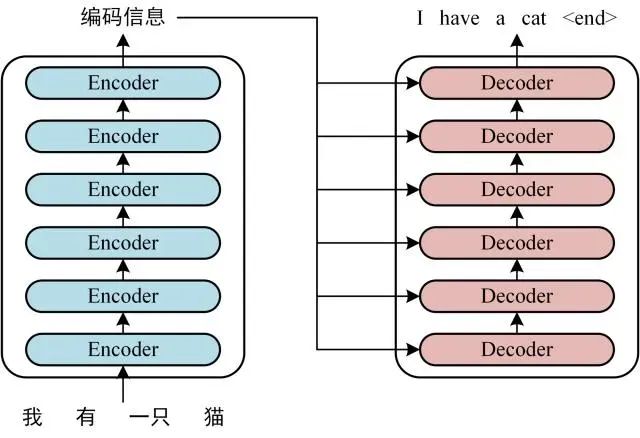
可以看到 Transformer 由 Encoder 和 Decoder 两个部分组成,Encoder 和 Decoder 都可以有多个。
训练一个模型的过程大体如下:
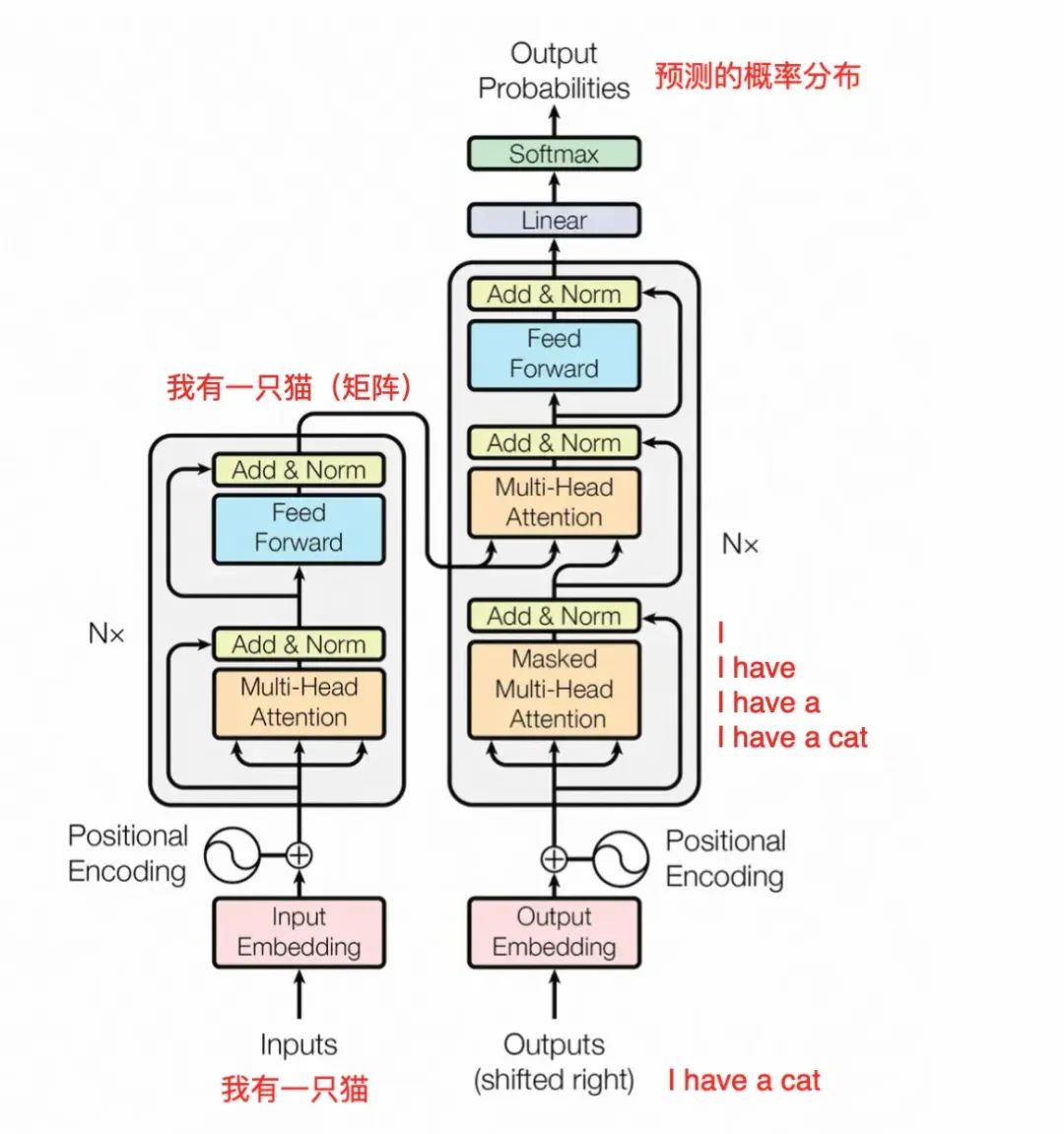
假设我们已经有一个训练好的模型,Transformer 的预测工作流程大体如下:
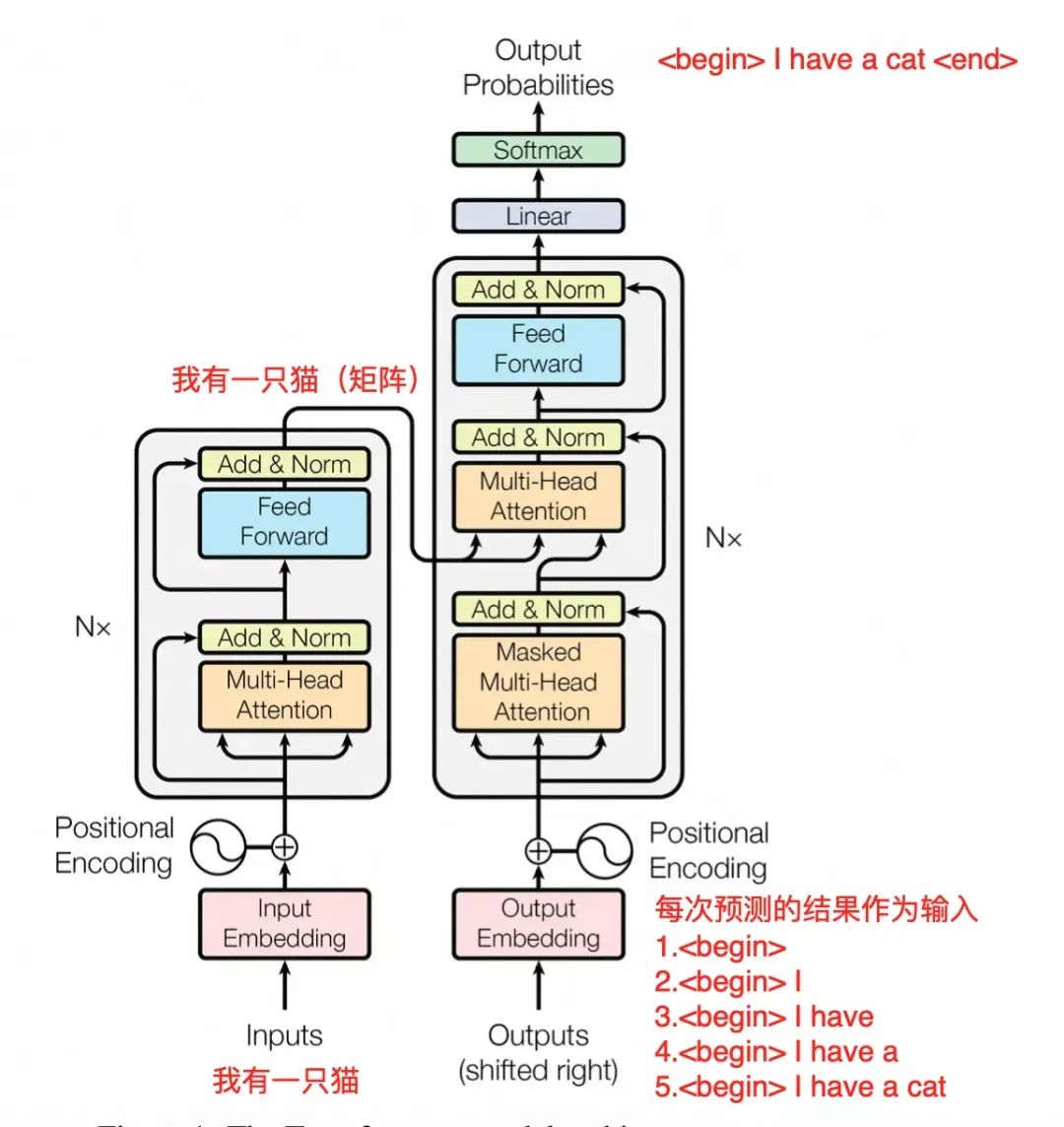
Transformer工作原理
Transformer的输入
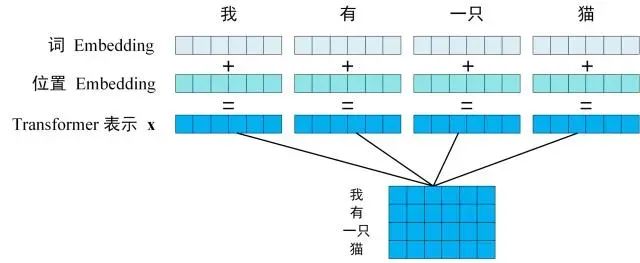
单词 Embedding
单词的 Embedding 有很多种方式可以获取,例如可以采用 Word2Vec、Glove 等算法预训练得到,也可以在 Transformer 中训练得到。
位置 Embedding
因为 Transformer 不采用 RNN 的结构,而是使用全局信息,不能利用单词的顺序信息,位置信息对于 NLP 来说非常重要。计算公式如下:
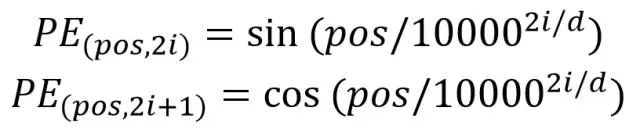
用这个公式的好处是:能够适应比训练集里面所有句子更长的句子、可以让模型容易地计算出相对位置;
Transformer的核心机制:自注意力(Self-Attention)
意思就是它不依赖额外输入的信息,即它只统计单词和其他单词之间的注意力(相关性)。

自注意力机制可以让模型在处理序列数据(比如一句话)时,动态关注不同位置的信息。它的实现可以简单理解为以下四步:
1.对每个输入词生成Q(query)、K(key)、V(value)向量。
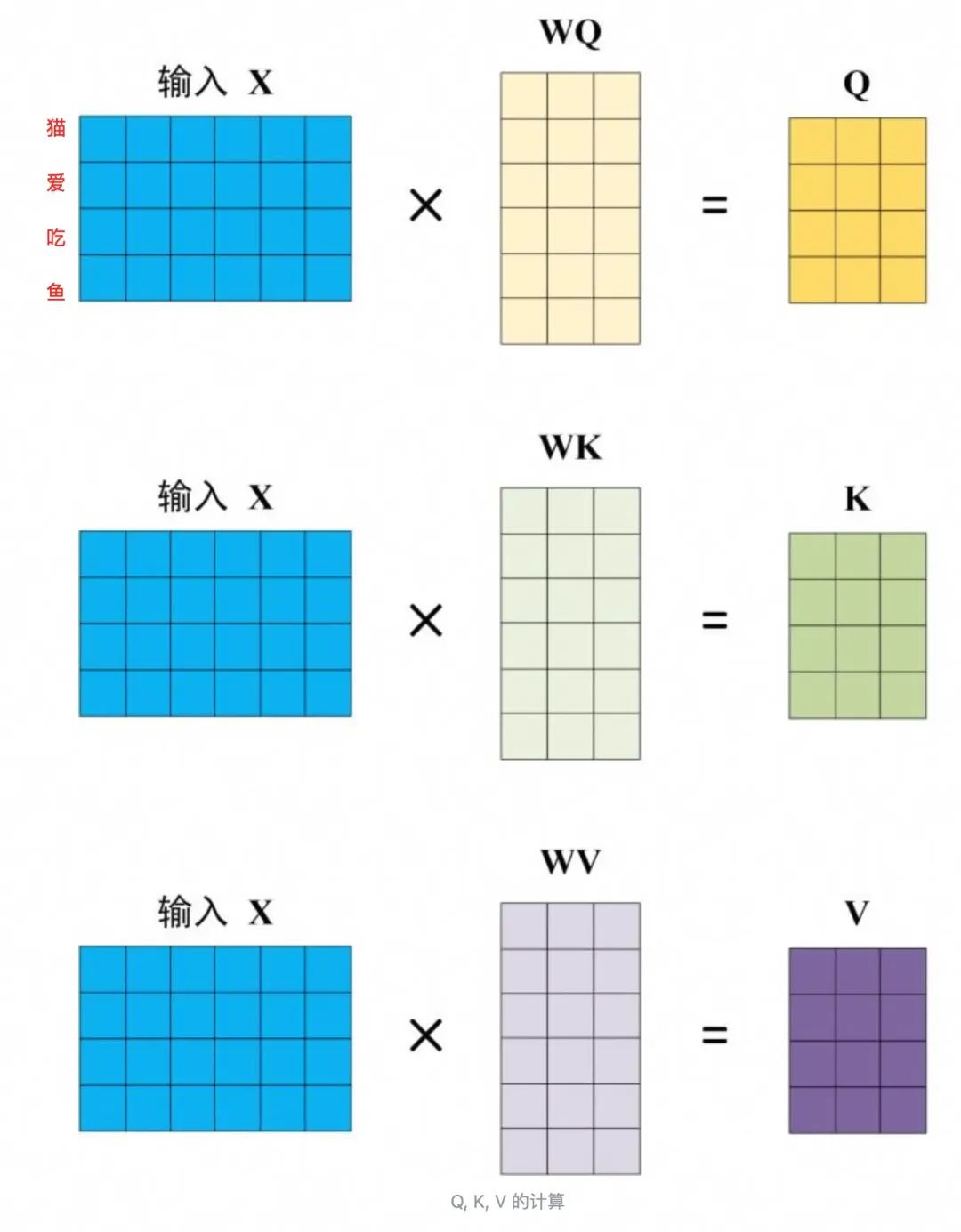
2.计算每个Q与所有K的转置,缩放后得到注意力分数。
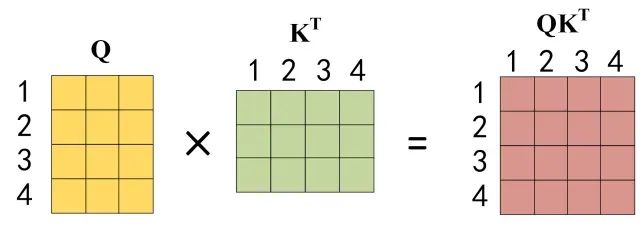
3.用softmax归一化分数,,即每一行的和都变为 1,得到权重。
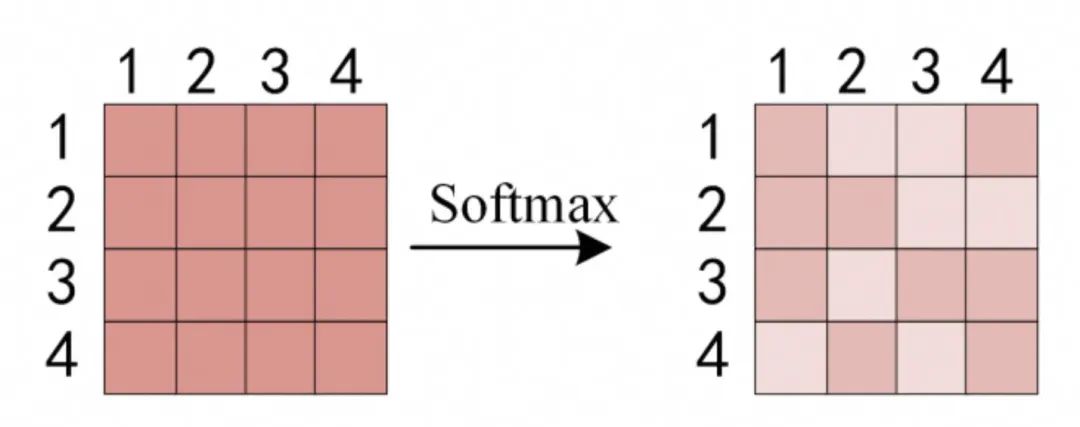
4.用权重对V加权求和,得到每个词的输出。
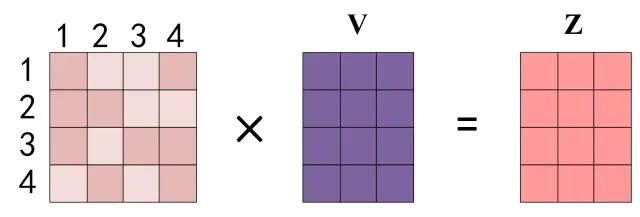
最终的公式:

简单地来讲,假设我希望翻译的话就是前图的“我有一只猫”,“我”的query向量q1发出疑问,词“我”、“有”、“一只”、“猫”对翻译我都有什么贡献?这4个词的key向量k1、k2、k3、k4分别跟q1进行相似性匹配;
具体为,先跟q1乘,得到的结果除以
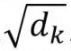
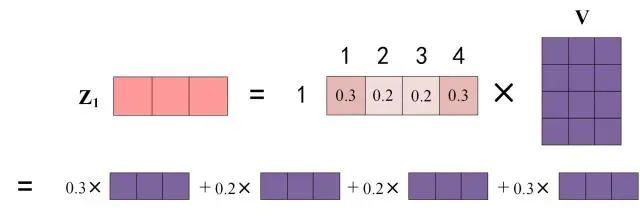
,再进softmax函数,得到权重值,假设为w1、w2、w3、w4,他们分别去跟v相乘后相加,得到最终的z1 =w1v1+w2v2+w3v3+w4v4,z2同理。
多头注意力 Multi-Head Attention
在上一步,我们已经知道怎么通过 Self-Attention 计算得到输出矩阵 Z,而 Multi-Head Attention 是由多个 Self-Attention 组合形成的,下图是论文中 Multi-Head Attention 的结构图。
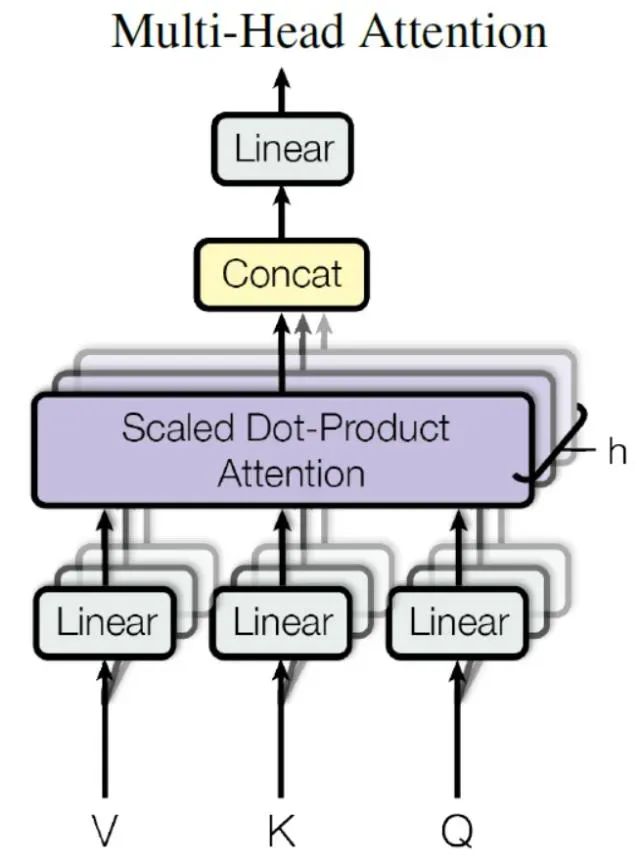
Multi-Head Attention
从上图可以看到 Multi-Head Attention 包含多个 Self-Attention 层,首先将输入X分别传递到 h 个不同的 Self-Attention 中,计算得到 h 个输出矩阵Z。下图是 h=8 时候的情况,此时会得到 8 个输出矩阵Z。换成人话来说就是我们矩阵图中的Wq,Wk和Wv分别初始化了多个进行训练;
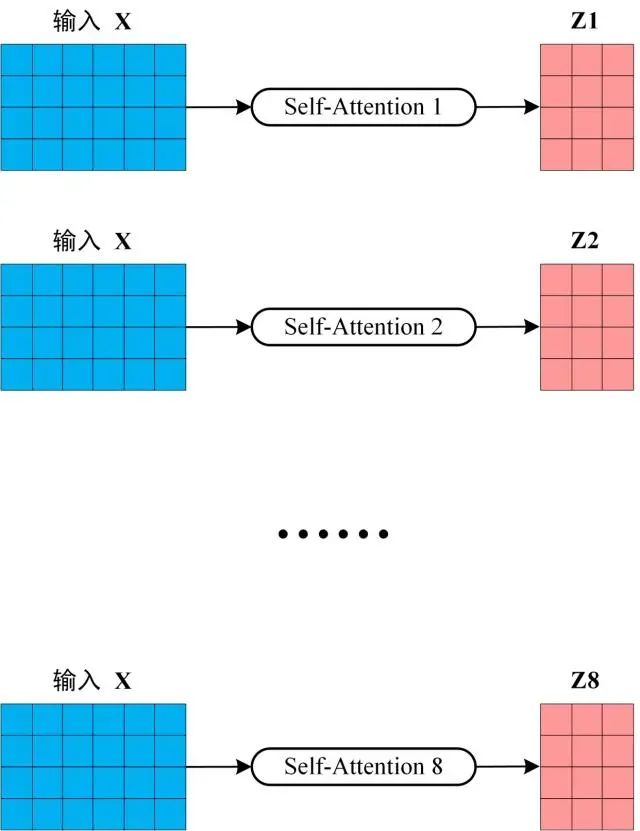
多个 Self-Attention
得到 8 个输出矩阵 Z1 到 Z8 之后,Multi-Head Attention 将它们拼接在一起 (Concat),然后传入一个Linear层,得到 Multi-Head Attention 最终的输出Z。
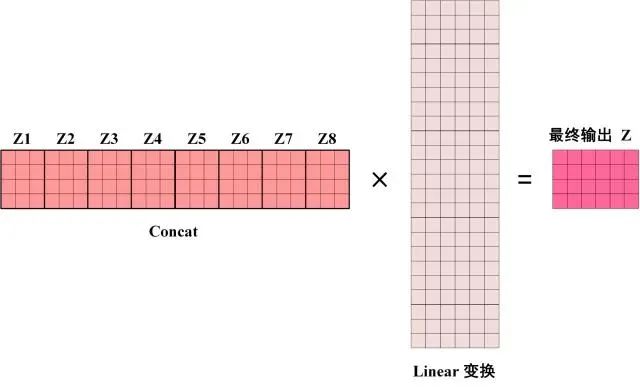
Multi-Head Attention 的输出
可以看到 Multi-Head Attention 输出的矩阵Z与其输入的矩阵X的维度是一样的。
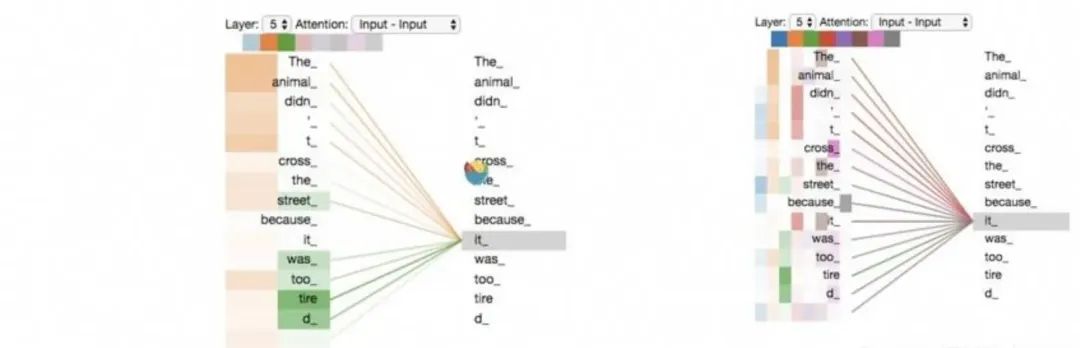
上图左为二头的着色结果,同样的”The animal didnt cross the street because it was too tired“这句话,我们想知道翻译it的时候这个词跟什么词有关,或者说哪个词对于翻译it更有效。
从二头的着色结果来说我们从橙色知道it指代了The animal,从绿色知道it的状态是tired,从五头的着色我们可以知道it的更多信息,这种关联性可以在翻译中给it更多的解释角度。
举例

在一句话中注意力往往要从多个角度进行分析,比如 “大学生“是考研这个单词的主体,”除了“表示考研在这个句子中的角色,”上班、创业“都是考研这个词替代;因此我们需要从不同的角度去进行学习,防止它们过度的相似。
我们可以给不同的注意力头选择不同的训练任务,比如一些注意力头去做完形填空,一些注意力头去预测下一个句子,不同的注意力头之间的训练是并行的,基于Transformer架构可以高效的训练超大规模的模型。
如下示例 每个头都会关注到不同的信息:https://colab.research.google.com/github/tensorflow/tensor2tensor/blob/master/tensor2tensor/notebooks/hello_t2t.ipynb#scrollTo=OJKU36QAfqOC
Add & Norm 层的作用
1.残差连接:缓解梯度消失问题,保留原始信息。
2.层归一化:加速训练,提高模型稳定性和泛化能力。在Transformer中,Add & Norm 层是模型能够高效训练和表现优异的关键组件之一。
Feed Forward的作用是
Feed Forward 层(也称为前馈神经网络)的作用是对自注意力机制输出的特征进行进一步的非线性变换和特征提取;
1.非线性特征变换:引入非线性激活函数,增强模型的表达能力。
2.特征增强:对自注意力机制的输出进行进一步处理,提取更丰富的特征。
3.独立处理每个位置:专注于每个位置的特征优化。
4.增加模型容量:通过额外的参数提高模型的拟合能力。
Encoder
Encoder block 接收输入矩阵 X(n×d) ,并输出一个矩阵 O(n×d) 。通过多个 Encoder block 叠加就可以组成 Encoder。
Decoder
-
包含两个 Multi-Head Attention 层。
-
第一个 Multi-Head Attention 层采用了 Masked 操作。通过 Masked 操作可以防止第 i 个单词知道 i+1 个单词之后的信息。
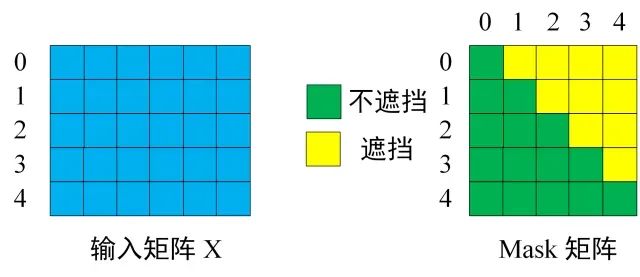
-
第二个 Multi-Head Attention 层的K, V矩阵使用 Encoder 的编码信息矩阵C进行计算,而Q使用上一个 Decoder block 的输出计算。这样做的好处是在 Decoder 的时候,每一位单词都可以利用到 Encoder 所有单词的信息 (这些信息无需 Mask)。
-
最后有一个 Softmax 层计算下一个翻译单词的概率。
Transformer 总结
-
Transformer 与 RNN 不同,可以比较好地并行训练。
-
Transformer 本身是不能利用单词的顺序信息的,因此需要在输入中添加位置 Embedding,否则 Transformer 就是一个词袋模型了。
-
Transformer 的重点是 Self-Attention 结构,其中用到的 Q, K, V矩阵通过输出进行线性变换得到。
-
Transformer 中 Multi-Head Attention 中有多个 Self-Attention,可以捕获单词之间多种维度上的相关系数 attention score。