【Rust智能指针】Rust智能指针原理剖析与应用指导

✨✨ 欢迎大家来到景天科技苑✨✨
🎈🎈 养成好习惯,先赞后看哦~🎈🎈
🏆 作者简介:景天科技苑
🏆《头衔》:大厂架构师,华为云开发者社区专家博主,阿里云开发者社区专家博主,CSDN全栈领域优质创作者,掘金优秀博主,51CTO博客专家等。
🏆《博客》:Rust开发,Python全栈,Golang开发,云原生开发,PyQt5和Tkinter桌面开发,小程序开发,人工智能,js逆向,App逆向,网络系统安全,数据分析,Django,fastapi,flask等框架,云原生K8S,linux,shell脚本等实操经验,网站搭建,数据库等分享。所属的专栏:Rust语言通关之路
景天的主页:景天科技苑

文章目录
- Rust智能指针
- 一、智能指针概述
- 1.1 什么是智能指针
- 1.2 Rust中常见的智能指针类型
- 二、`Box<T>`:最简单的智能指针
- 2.1 Box的基本用法
- 2.2 使用Box实现递归类型
- 2.3 Box解引用
- 2.4 实现Deref trait
- 2.4.1 解引用实现
- 2.4.2 解引用强制多态
- 2.5 drop trait清理代码
- 2.5.1 实现drop trait
- 2.5.2 drop提前释放
- 三、`Rc<T>`:引用计数智能指针
- 3.1 Rc的基本用法
- 3.2 共享所有权场景
- 3.3 Rc的限制
- 四、`RefCell<T>`:内部可变性模式
- 4.1 RefCell的基本用法
- 4.2 内部可变性:不可变值的可变借用
- 4.3 RefCell的运行时检查
- 五、`Arc<T>`:线程安全的引用计数
- 5.1 Arc的基本用法
- 5.2 Arc与Mutex结合使用
- 六、智能指针的高级用法
- 6.1 自定义智能指针
- 6.2 引用循环与内存泄漏
- 6.3 弱引用(`Weak<T>`)
- 6.4 创建树形数据结构:带有子结点的 Node
- 七、智能指针的性能考量
- 7.1 各种智能指针的性能特点
- 7.2 何时使用何种智能指针
- 八、智能指针组合使用
- 九、常见问题与解决方案
- 9.1 循环引用导致内存泄漏
- 9.2 线程间共享数据的选择
- 9.3 性能优化技巧
- 十、总结
Rust智能指针
Rust语言以其内存安全和零成本抽象的特性而闻名,其中智能指针是实现这些特性的重要组成部分。
与C++中的智能指针类似,Rust的智能指针提供了比普通引用更丰富的功能,但在实现和使用上有着Rust特有的设计哲学。
智能指针是Rust中一种特殊的数据结构,它们不仅包含指针功能,还附加了额外的元数据和功能。Rust标准库提供了多种智能指针类型,每种都有其特定的用途。
一、智能指针概述
1.1 什么是智能指针
指针是一个包含内存地址的变量。这个地址指向一些其他的数据。
在Rust中,智能指针是一种数据结构,它不仅像普通指针一样指向某个内存地址,还拥有额外的元数据和功能。
最明显的,它们拥有一个引用计数。引用计数记录智能指针总共有多少个所有者,并且没有任何所有者时清除数据。
普通引用和智能引用的一个额外区别是:引用只是借用数据的指针,而智能指针则是拥有它们指向的数据。
智能指针通常使用结构体来实现。智能指针区别于常规结构体的显著特征在于智能指针通常实现Deref和Drop trait,这使得它们能够:
自动解引用(通过Deref)
在离开作用域时自动清理资源(通过Drop)
1.2 Rust中常见的智能指针类型
Rust标准库提供了多种智能指针,主要包括:
Box<T>:用于在堆上分配值
Rc<T>:引用计数指针,允许多重所有权
Arc<T>:原子引用计数指针,线程安全版本
RefCell<T>:提供内部可变性的运行时借用检查
Mutex<T>和RwLock<T>:用于线程间共享数据的同步原语
二、Box<T>:最简单的智能指针
2.1 Box的基本用法
Box是最简单的智能指针,它允许你将值存储在 堆上 而不是 栈上。留在栈上的则是指向堆数据的指针。
其类型为Box<T>
除了数据被储存在堆上而不是栈上之外,box 没有性能损失,不过也没有很多额外的功能。他们多用于如下场景:
- 当有一个在编译时未知大小的类型,而又想要在需要确切大小的上下文中使用这个类型值的时候
- 当有大量数据并希望在确保数据不被拷贝的情况下转移所有权的时候
- 当希望拥有一个值并只关心它的类型是否实现了特定 trait 而不是其具体类型的时候
本文的内容中主要展示第一种应用场景。作为对另外两个情况更详细的说明:
在第二种情况中,转移大量数据的所有权可能会花费很长的时间,因为数据在栈上进行了拷贝。
为了改善这种情况下的性能,可以通过 box 将这些数据储存在堆上。接着,只有少量的指针数据在栈上被拷贝。
第三种情况被称为 trait 对象(trait object)
fn main() {// Box智能指针,将数据存储在堆上// 存储在堆上的数据,在离开作用域时自动释放// Box::new(5) 创建一个指向整数5的Box// println!("b = {}", b); 打印b的值,b存放在栈上,5存放在堆上,b指向5所在的内存let b = Box::new(5);println!("b = {}", b);
}
这里定义了变量 b ,其值是一个指向被分配在堆上的值 5 的 Box 。
这个程序会打印出 b = 5 ;在这个例子中,我们可以像数据是储存在栈上的那样访问 box 中的数据。
正如任何拥有数据所有权的值那样,当像 b 这样的 box 在 main 的末尾离开作用域时,它将被释放。
这个释放过程作用于 box 本身(位于栈上)和它所指向的数据(位于堆上)。
将一个单独的值存放在堆上并不是很有意义,所以像 这样单独使用 box 并不常见。
将像单个 i32 这样的值储存在栈上,也就是其默认存放的地方在大部分使用场景中更为合适。
2.2 使用Box实现递归类型
Rust 需要在编译时知道类型占用多少空间。一种无法在编译时知道大小的类型是 递归类型(recursive type),其值的一部分可以是相同类型的另一个值。
这种值的嵌套理论上可以无限的进行下去,所以 Rust 不知道递归类型需要多少空间。
不过 box 有一个已知的大小,所以通过在循环类型定义中插入 box,就可以创建递归类型了。
Rust需要在编译时知道类型的大小,而递归类型的大小无法在编译时确定。Box可以帮助解决这个问题。
cons list,一个函数式编程语言中的常见类型,来展示这个(递归类型)概念。
除了递归之外,我们将要定义的 cons list 类型是很直白的,所以这个例子中的概念在任何遇到更为复杂的涉及到递归类型的场景时都很实用。
cons list 是一个每一项都包含两个部分的列表:当前项的值和下一项。其最后一项值包含一个叫做 Nil 的值并没有下一项。
cons list 是一个来源于 Lisp 编程语言及其方言的数据结构。
在 Lisp 中, cons 函数(“construct function" 的缩写)利用两个参数来构造一个新的列表,他们通常是一个单独的值和另一个列表。
cons 函数的概念涉及到更通用的函数式编程术语;“将 x 与 y 连接” 通常意味着构建一个新的容器而将 x 的元素放在新容器的开头,其后则是容器 y 的元素。
cons list 通过递归调用 cons 函数产生。代表递归的终止条件(base case)的规范名称是 Nil ,它宣布列表的终止。
注意这不同于 “null” 或 “nil” 的概念,他们代表无效或缺失的值。
注意虽然函数式编程语言经常使用 cons list,但是它并不是一个 Rust 中常见的类型。
大部分在 Rust 中需要列表的时候, Vec 是一个更好的选择。
其他更为复杂的递归数据类型 确实 在 Rust 的很多场景中很有用,
不过通过以 cons list作为开始,我们可以探索如何使用 box 毫不费力的定义一个递归数据类型。
因为 Box 是一个指针,我们总是知道它需要多少空间:指针的大小并不会根据其指向的数据量而改变。
所以可以将 Box 放入 Cons 成员中而不是直接存放另一个 List 值。
Box 会指向另一个位于堆上的 List 值,而不是存放在 Cons 成员中。
从概念上讲,我们仍然有一个通过在其中 “存放” 其他列表创建的列表,不过现在实现这个概念的方式更像是一个项挨着另一项,而不是一项包含另一项。
//使用Box实现递归类型
#[derive(Debug)]
#[allow(dead_code)]
enum List {Cons(i32, Box<List>), //list是不确定大小的,但是智能指针Box是确定大小的,因此可以编译通过Nil,
}use List::{ Cons, Nil };fn main() {let list = Cons(1, Box::new(Cons(2, Box::new(Cons(3, Box::new(Nil))))));println!("{:?}", list);
}
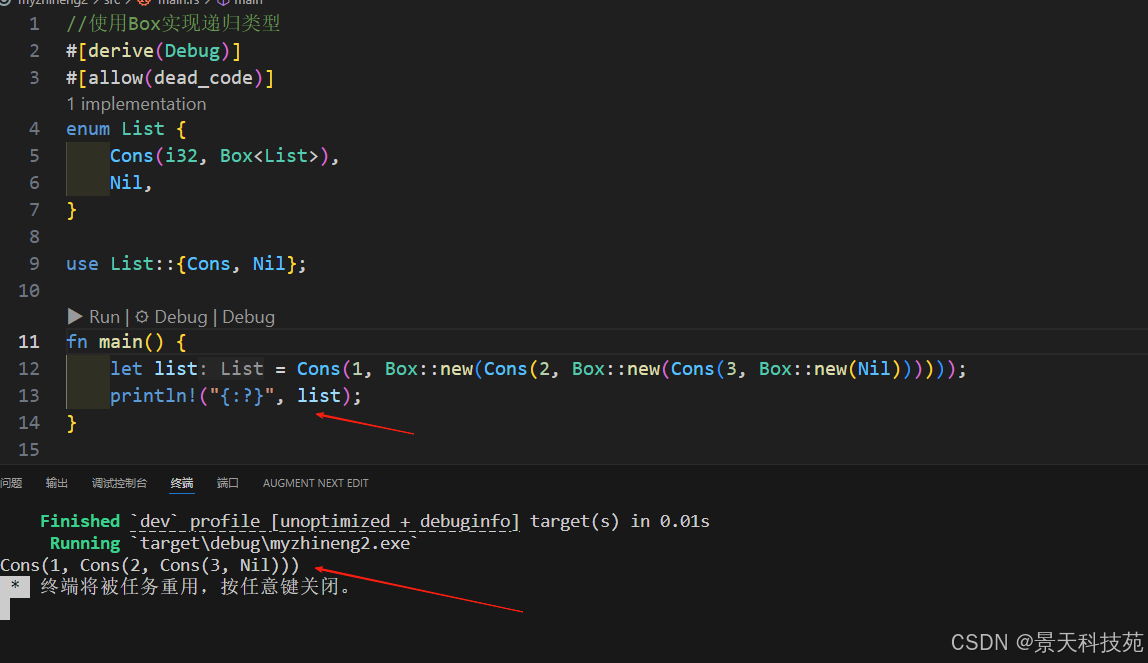
Cons 成员将会需要一个 i32 的大小加上储存 box 指针数据的空间。
Nil 成员不储存值,所以它比 Cons 成员需要更少的空间。现在我们知道了任何 List 值最多需要一个 i32 加上 box 指针数据的大小。
通过使用 box ,打破了这无限递归的连锁,这样编译器就能够计算出储存 List 值需要的大小了。下图展示了现在 Cons 成员看起来像什么:
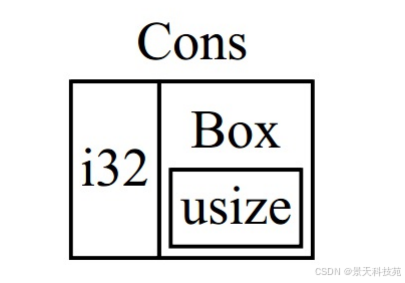
因为 Cons 存放一个 Box 所以 List 不是无限大小的了
box 只提供了间接存储和堆分配;他们并没有任何其他特殊的功能,比如我们将会见到的其他智能指针。
他们也没有这些特殊功能带来的性能损失,所以他们可以用于像 cons list 这样间接存储是唯一所需功能的场景。
Box 类型是一个智能指针,因为它实现了 Deref trait,它允许 Box 值被当作引用对待。
当 Box 值离开作用域时,由于 Box 类型 Drop trait 的实现,box 所指向的堆数据也会被清除。
2.3 Box解引用
实现解引用特征Deref trait允许我们重载运算符。
//实现Deref trait允许我们重载解引用运算符
// let a: A = A::new(); //前提,A实现了Deref trait
// let b = &a;
// let c = *b; //解引用fn main() {let x = 5;let y = &x;//判断assert_eq!(5, x); //断言通过assert_eq!(5, *y); //解引用,断言通过//Box解引用,a定义在栈上,b定义在堆上let a = 5;let b = Box::new(a);assert_eq!(5, a);assert_eq!(5, *b); //Box可以自动解引用,断言通过
}
2.4 实现Deref trait
2.4.1 解引用实现
我们自定义个Box
//实现Debug trait
//定义个泛型结构体
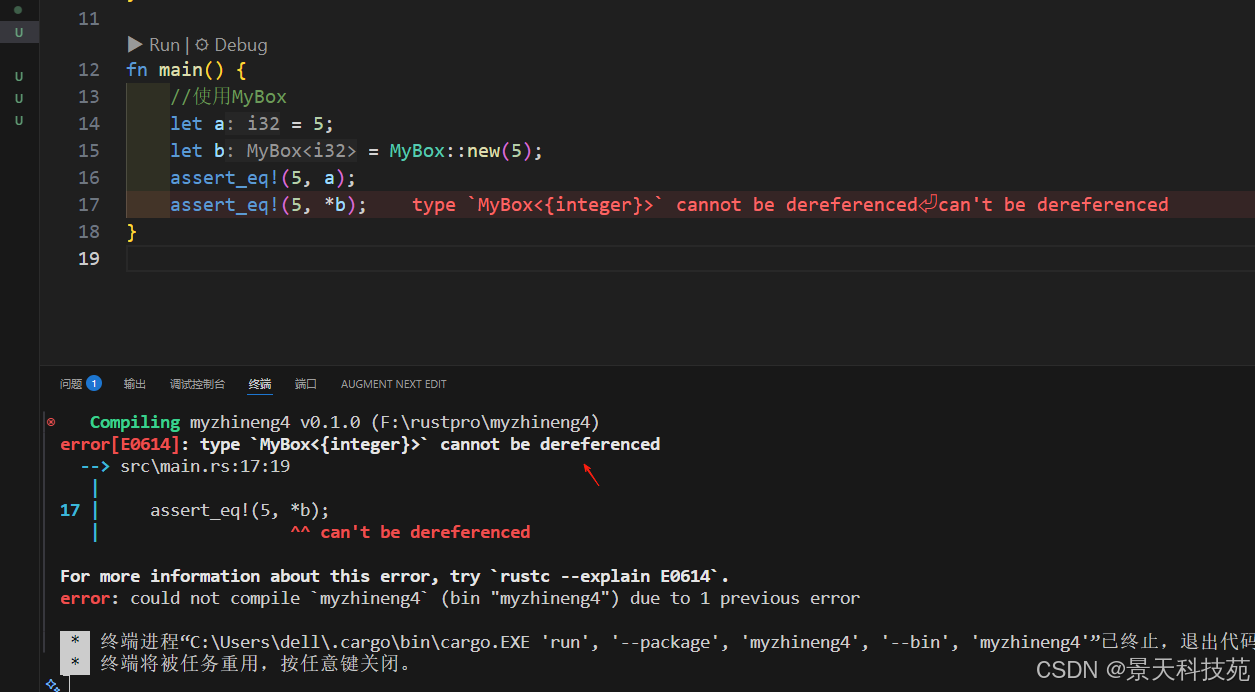
struct MyBox<T>(T);//实现new方法
impl<T> MyBox<T> {fn new(x: T) -> MyBox<T> {MyBox(x)}
}fn main() {//使用MyBoxlet a = 5;let b = MyBox::new(5);assert_eq!(5, a);assert_eq!(5, *b); //这里报错
}
当我们想要像Box一样使用时,会报错
提示我们创建的类型不能解引用
这是由于标准库中的Box实现了,Deref trait。我们创建的类型,没有实现Deref trait
我们自己实现下
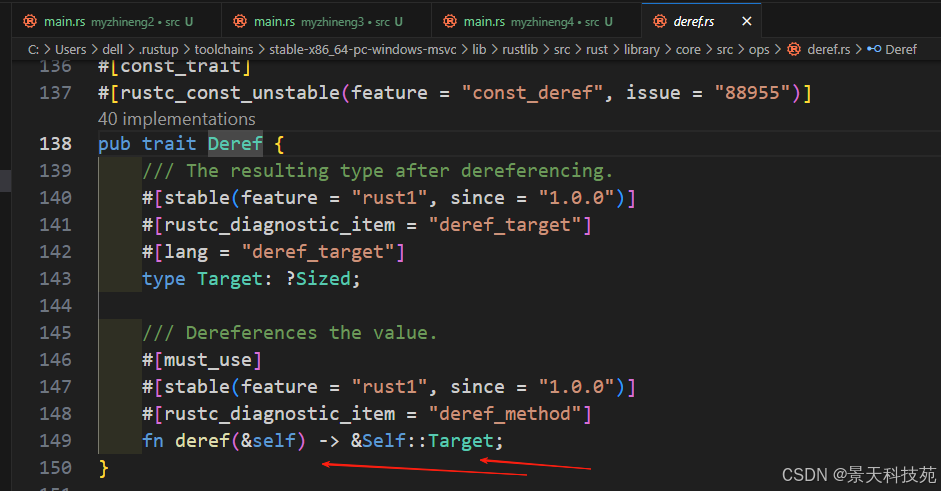
看下标准库Deref这个trait
实现这个trait,只需要实现deref这个一个方法即可
//自定义Box实现Deref trait允许我们重载解引用运算符
//定义个泛型结构体
struct MyBox<T>(T);//实现new方法
impl<T> MyBox<T> {fn new(x: T) -> MyBox<T> {MyBox(x)}
}//实现Deref trait
//引入标准库的Deref trait
use std::ops::Deref;
impl<T> Deref for MyBox<T> {type Target = T;//实现Deref,只需要实现deref这一个方法//返回值是一个引用,指向MyBox内部的值fn deref(&self) -> &Self::Target {&self.0 //根据字段的个数来返回,我们得MyBox只有一个字段,所以返回&self.0}
}fn main() {//使用MyBoxlet a = 5;let b = MyBox::new(5);assert_eq!(5, a);//当我们的MyBox实现了Deref trait后,就可以自动解引用了assert_eq!(5, *b);
}
再次解引用,就不会报错了
2.4.2 解引用强制多态
解引用强制多态(deref coercions)是 Rust 出于方便的考虑作用于函数或方法的参数的。其将实现了 Deref 的类型的引用转换为 Deref 所能够将原始类型转换的类型的引用。
解引用强制多态发生于当作为参数传递给函数或方法的特定类型的引用不同于函数或方法签名中定义参数类型的时候,
这时会有一系列的 deref 方法调用会将提供的类型转换为参数所需的类型。
解引用强制多态的加入使得 Rust 程序员编写函数和方法调用时无需增加过多显式使用 & 和 * 的引用和解引用。
这个功能也使得我们可以编写更多同时作用于引用或智能指针的代码。
解引用强制多态
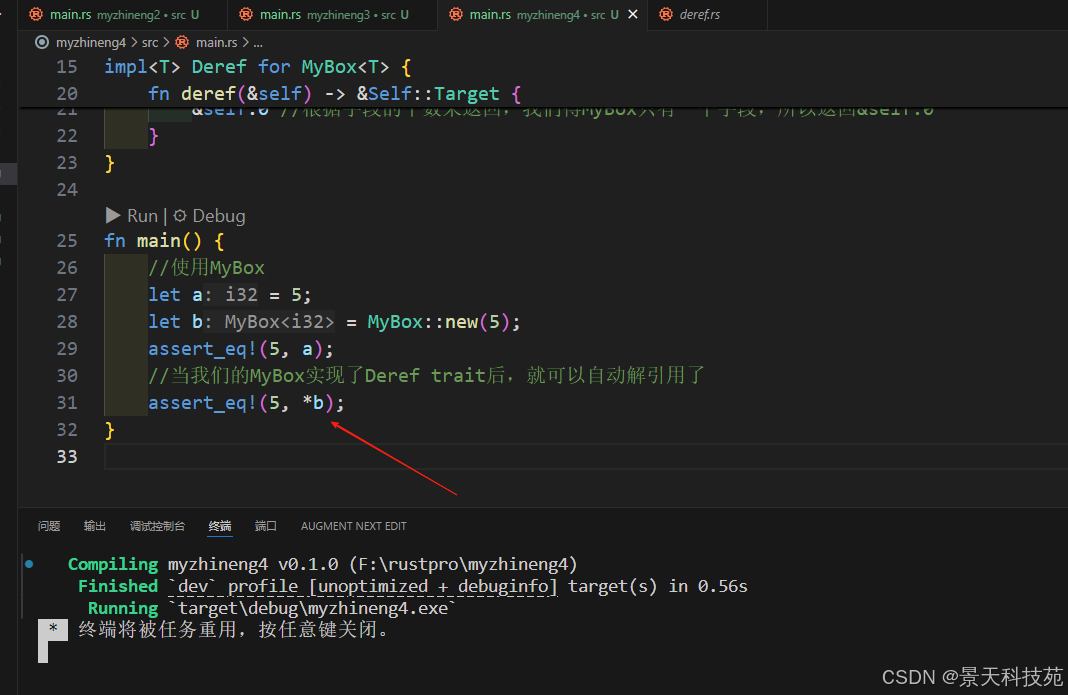
第一步,编译器会调用MyBox的deref方法,返回&String
第二步,编译器会调用String的deref方法,返回&str
这个过程叫做解引用多态
解引用多态与可变性交互
Rust 在发现类型和 trait 实现满足以下三种情况时会进行解引用强制多态:
1.当T:Deref<Target = U>时,从&T可以得到&U
2.当T:DerefMut<Target = U>时,从&mut T可以得到&mut U
3.当T:Deref<Target = U>时,从&mut T可以得到&U。反之则不行
头两个情况除了可变性之外是相同的:
第一种情况表明如果有一个 &T ,而 T 实现了返回 U 类型的 Deref ,则可以直接得到 &U 。
第二种情况表明对于可变引用也有着相同的行为。
最后一个情况有些微妙:Rust 也会将可变引用强转为不可变引用。
但是反之是 不可能 的:不可变引用永远也不能强转为可变引用。
因为根据借用规则,如果有一个可变引用,其必须是这些数据的唯一引用(否则程序将无法编译)。
将一个可变引用转换为不可变引用永远也不会打破借用规则。
将不可变引用转换为可变引用则需要数据只能有一个不可变引用,而借用规则无法保证这一点。
因此,Rust 无法假设将不可变引用转换为可变引用是可能的。
//解引用多态
//自定义Box实现Deref trait允许我们重载解引用运算符
//定义个泛型结构体
struct MyBox<T>(T);//实现new方法
impl<T> MyBox<T> {fn new(x: T) -> MyBox<T> {MyBox(x)}
}//解引用多态与可变性交互
//1.当T:Deref<Target = U>时,从&T可以得到&U
//2.当T:DerefMut<Target = U>时,从&mut T可以得到&mut U
//3.当T:Deref<Target = U>时,从&mut T可以得到&U。反之则不行,没有&T到&mut U的转换//实现Deref trait
//引入标准库的Deref trait
use std::ops::Deref;
impl<T> Deref for MyBox<T> {type Target = T;//实现Deref,只需要实现deref这一个方法//返回值是一个引用,指向MyBox内部的值fn deref(&self) -> &Self::Target {&self.0 //根据字段的个数来返回,我们得MyBox只有一个字段,所以返回&self.0}
}//定义个函数,参数是一个字符串切片
//第一条 T:Deref<Target = U>时,从&T可以得到&U
fn hello(name: &str) {println!("Hello, {}!", name);
}//测试下第3条
//实现DerefMut trait
use std::ops::DerefMut;
impl<T> DerefMut for MyBox<T> {fn deref_mut(&mut self) -> &mut Self::Target {&mut self.0}
}//定义个函数,参数是一个可变字符串切片
fn hello_mut(name: &mut str) {println!("Hello, {}!", name);
}fn main() {//创建个MyBox实例let m = MyBox::new(String::from("Rust"));//调用hello函数,传入MyBox实例的引用//第一步,编译器会调用m的deref方法,返回&String//第二步,编译器会调用String的deref方法,返回&str//这个过程叫做解引用多态hello(&m);//测试下第2条//从&mut T可以得到&mut U//创建个可变的MyBox实例let mut m = MyBox::new(String::from("Rust"));//调用hello函数,传入MyBox实例的可变引用//第一步,编译器会调用m的deref_mut方法,返回&mut String//第二步,编译器会调用String的deref_mut方法,返回&mut str//这个过程叫做解引用多态hello_mut(&mut m);//测试下第3条//从&mut T可以得到&U//创建个可变的MyBox实例let mut m = MyBox::new(String::from("Rust"));//调用hello函数,传入MyBox实例的可变引用//第一步,编译器会调用m的deref_mut方法,返回&mut String//第二步,编译器会调用String的deref方法,返回&str//这个过程叫做解引用多态hello_mut(&mut m);
}
2.5 drop trait清理代码
2.5.1 实现drop trait
类似于其他语言的析构函数
对于智能指针模式来说另一个重要的 trait 是 Drop 。 Drop 允许我们在值要离开作用域时执行一些代码。
可以为任何类型提供 Drop trait 的实现,同时所指定的代码被用于释放类似于文件或网络连接的资源。
我们在智能指针上下文中讨论Drop 是因为其功能几乎总是用于实现智能指针。
#![allow(unused_variables)]
#[allow(dead_code)]
//drop trait
//类似于其他语言的析构函数,当值离开作用域时,自动调用的函数
#[derive(Debug)]
struct Dog {name: String,
}//为Dog实现Drop trait
impl Drop for Dog {//实现Drop trait只需要实现drop方法,Drop trait中只定义了一个drop方法//实现trait的方法,要看下trait中定义的方法是怎么定义的//fn drop(&mut self);//这里为什么使用&mut self,因为drop方法会修改self的值,比如将self的值设置为Nonefn drop(&mut self) {println!("Dropping Dog with name `{}`!", self.name);}
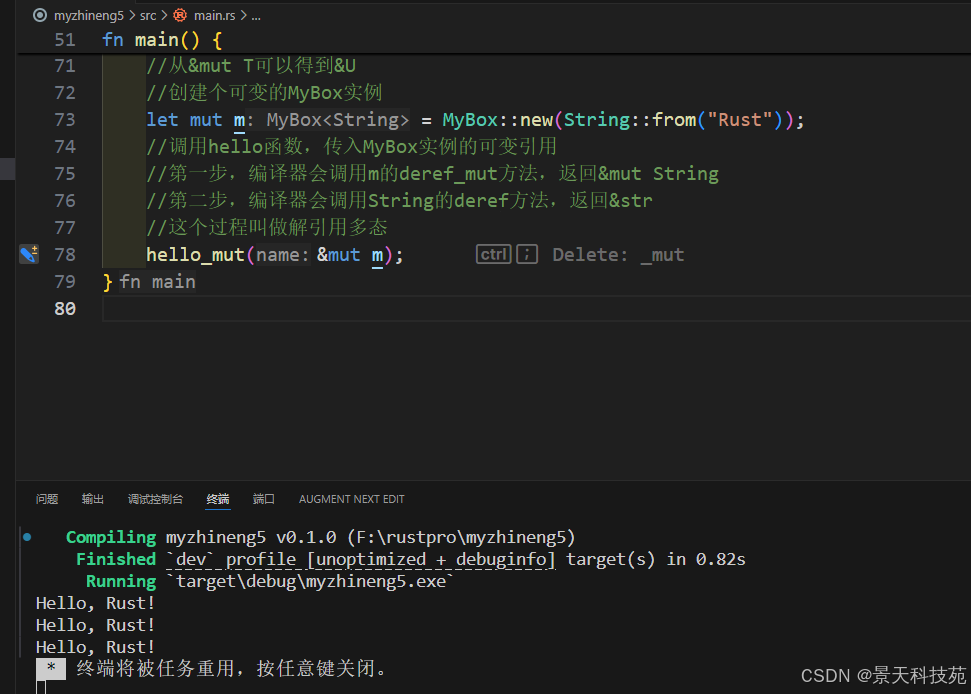
}fn main() {let c = Dog {name: String::from("旺财"),};//手动调用drop方法//c.drop(); //报错,drop方法是私有的,不能手动调用//手动调用drop方法// drop(c);//局部作用域里面的变量在离开作用域时,自动调用drop方法{let c = Dog {name: String::from("大黄"),};}println!("CustomSmartPointer created.");
}
先调用大黄的drop函数,执行main函数中的println!,最后在main函数作用域结束时,执行旺财的drop函数
2.5.2 drop提前释放
通过 std::mem::drop 提早丢弃值
Rust 当值离开作用域时自动插入 drop 调用,不能直接禁用这个功能。
被打印到屏幕上,它展示了 Rust 在实例离开作用域时自动调用了 drop 。
通常也不需要禁用 drop ;整个 Drop trait 存在的意义在于其是自动处理的。有时可能需要提早清理某个值。
比如当使用智能指针管理锁时;你可能希望强制运行 drop 方法来释放锁以便作用域中的其他代码可以获取锁。
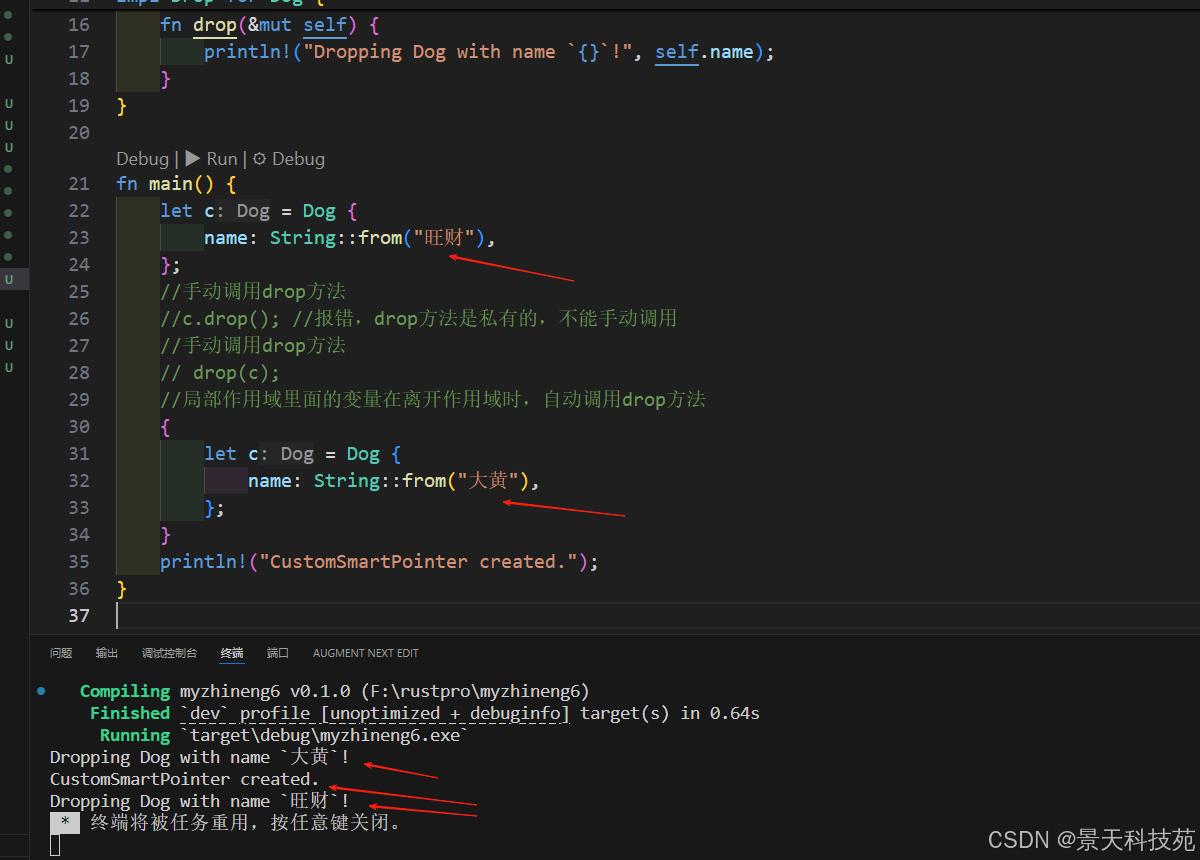
如果我们直接通过对象调用对象.drop()会报错
#![allow(unused_variables)]
#[allow(dead_code)]
//drop trait
//类似于其他语言的析构函数,当值离开作用域时,自动调用的函数
#[derive(Debug)]
struct Dog {name: String,
}//为Dog实现Drop trait
impl Drop for Dog {//实现Drop trait只需要实现drop方法,Drop trait中只定义了一个drop方法//实现trait的方法,要看下trait中定义的方法是怎么定义的//fn drop(&mut self);//这里为什么使用&mut self,因为drop方法会修改self的值,比如将self的值设置为Nonefn drop(&mut self) {println!("Dropping Dog with name `{}`!", self.name);}
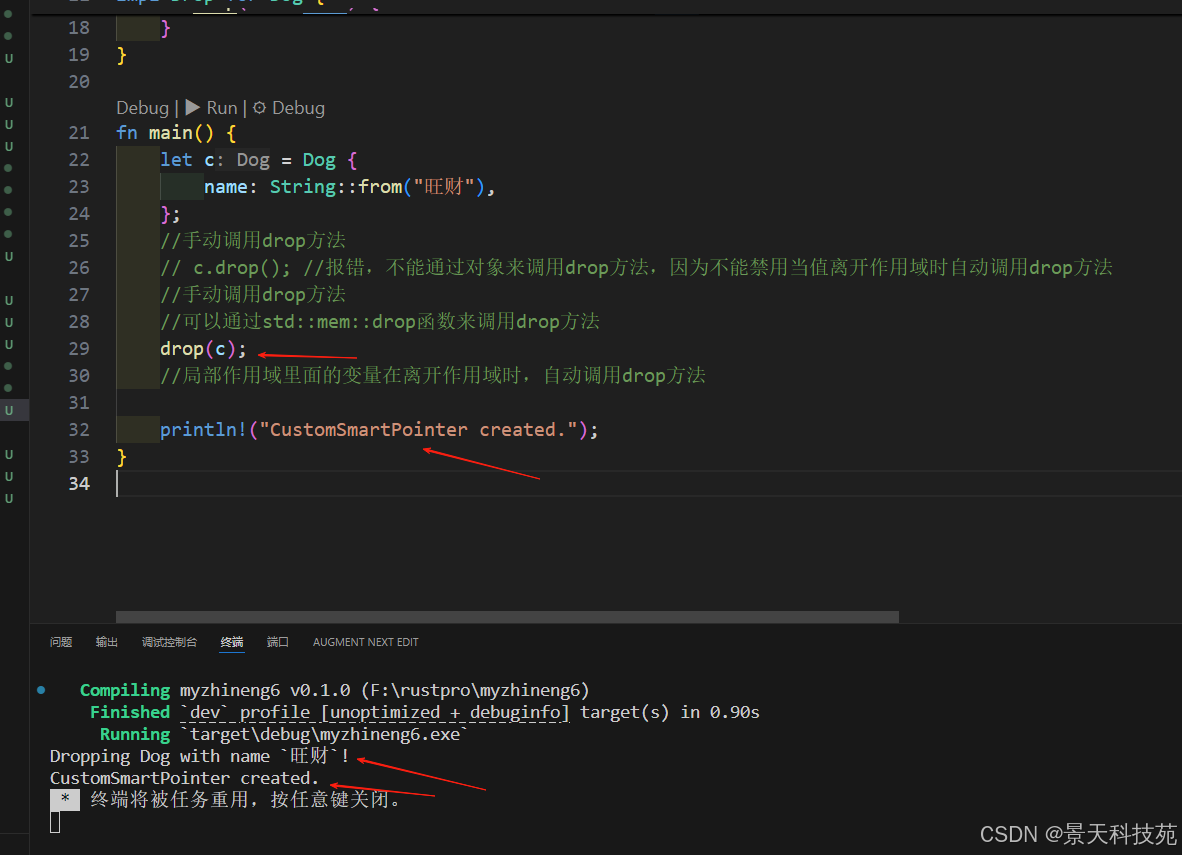
}fn main() {let c = Dog {name: String::from("旺财"),};//手动调用drop方法c.drop(); //报错,不能手动调用//手动调用drop方法// drop(c);//局部作用域里面的变量在离开作用域时,自动调用drop方法println!("CustomSmartPointer created.");
}
如果我们直接通过对象c.drop()调用是会报错的
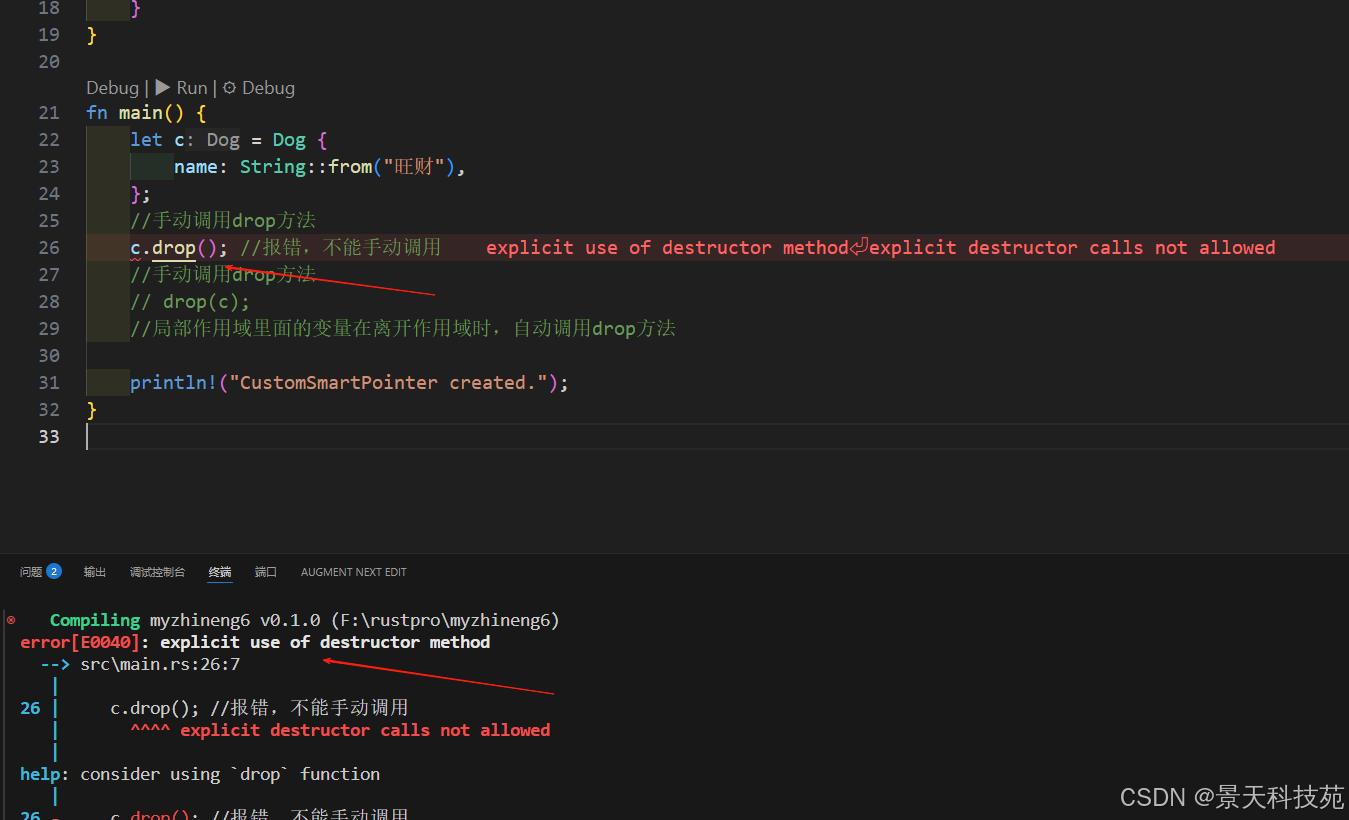
错误信息表明不允许显式调用 drop 。
错误信息使用了术语 析构函数(destructor),这是一个清理实例的函数的通用编程概念。
析构函数 对应创建实例的 构造函数。Rust 中的 drop 函数就是这么一个析构函数。
正确调用drop方法:
Rust 不允许我们显式调用 drop 因为 Rust 仍然会在 main 的结尾对值自动调用 drop ,这会导致一个 double free 错误,因为 Rust 会尝试清理相同的值两次。
因为不能禁用当值离开作用域时自动插入的 drop ,并且不能显示调用 drop ,
如果我们需要提早清理值,可以使用std::mem::drop 函数。
std::mem::drop 函数不同于 Drop trait 中的 drop 方法。可以通过传递希望提早强制丢弃的值作为参数。
#![allow(unused_variables)]
#[allow(dead_code)]
//drop trait
//类似于其他语言的析构函数,当值离开作用域时,自动调用的函数
#[derive(Debug)]
struct Dog {name: String,
}//为Dog实现Drop trait
impl Drop for Dog {//实现Drop trait只需要实现drop方法,Drop trait中只定义了一个drop方法//实现trait的方法,要看下trait中定义的方法是怎么定义的//fn drop(&mut self);//这里为什么使用&mut self,因为drop方法会修改self的值,比如将self的值设置为Nonefn drop(&mut self) {println!("Dropping Dog with name `{}`!", self.name);}
}fn main() {let c = Dog {name: String::from("旺财"),};//手动调用drop方法// c.drop(); //报错,不能通过对象来调用drop方法,因为不能禁用当值离开作用域时自动调用drop方法//手动调用drop方法//可以通过std::mem::drop函数来调用drop方法drop(c);//局部作用域里面的变量在离开作用域时,自动调用drop方法println!("CustomSmartPointer created.");
}
提早调用drop成功
使用 Drop trait 实现指定的代码在很多方面都使得清理值变得方便和安全:比如可以使用它来创建我们自己的内存分配器!
通过 Drop trait 和 Rust 所有权系统,就无需担心之后清理代码,因为 Rust 会自动考虑这些问题。
如果代码在值仍被使用时就清理它会出现编译错误,因为所有权系统确保了引用总是有效的,这也就保证了 drop 只会在值不再被使用时被调用一次。
三、Rc<T>:引用计数智能指针
3.1 Rc的基本用法
Rc(Reference Counting)允许数据有多个所有者,通过引用计数管理生命周期。
大部分情况下所有权是非常明确的:可以准确的知道哪个变量拥有某个值。
然而,有些情况单个值可能会有多个所有者。
例如,在图数据结构中,多个边可能指向相同的结点,而这个结点从概念上讲为所有指向它的边所拥有。
结点直到没有任何边指向它之前都不应该被清理。
在 Rust 中,Rc<T>(引用计数智能指针)本身不能直接修改其内部的数据,因为它的设计目的是为了共享所有权而不是可变访问。因为相同位置的多个可变引用,可能会造成数据不一致
默认情况下,Rc<T> 提供的是不可变共享访问。
为了启用多所有权,Rust 有一个叫做 Rc<T> 的类型。
其名称为 引用计数(reference counting)的缩写。引用计数意味着记录一个值引用的数量来知晓这个值是否仍在被使用。
如果某个值有零个引用,就代表没有任何有效引用并可以被清理。
可以将其想象为客厅中的电视。当一个人进来看电视时,他打开电视。其他人也可以进来看电视。
当最后一个人离开房间时,他关掉电视因为它不再被使用了。
如果某人在其他人还在看的时候就关掉了电视,正在看电视的人肯定会抓狂的!
Rc<T> 用于当我们希望在堆上分配一些内存供程序的多个部分读取,而且无法在编译时确定程序的那一部分会最后结束使用它的时候。
如果确实知道哪部分会结束使用的话,就可以令其成为数据的所有者同时正常的所有权规则就可以在编译时生效。
注意 Rc<T> 只能用于单线程场景;
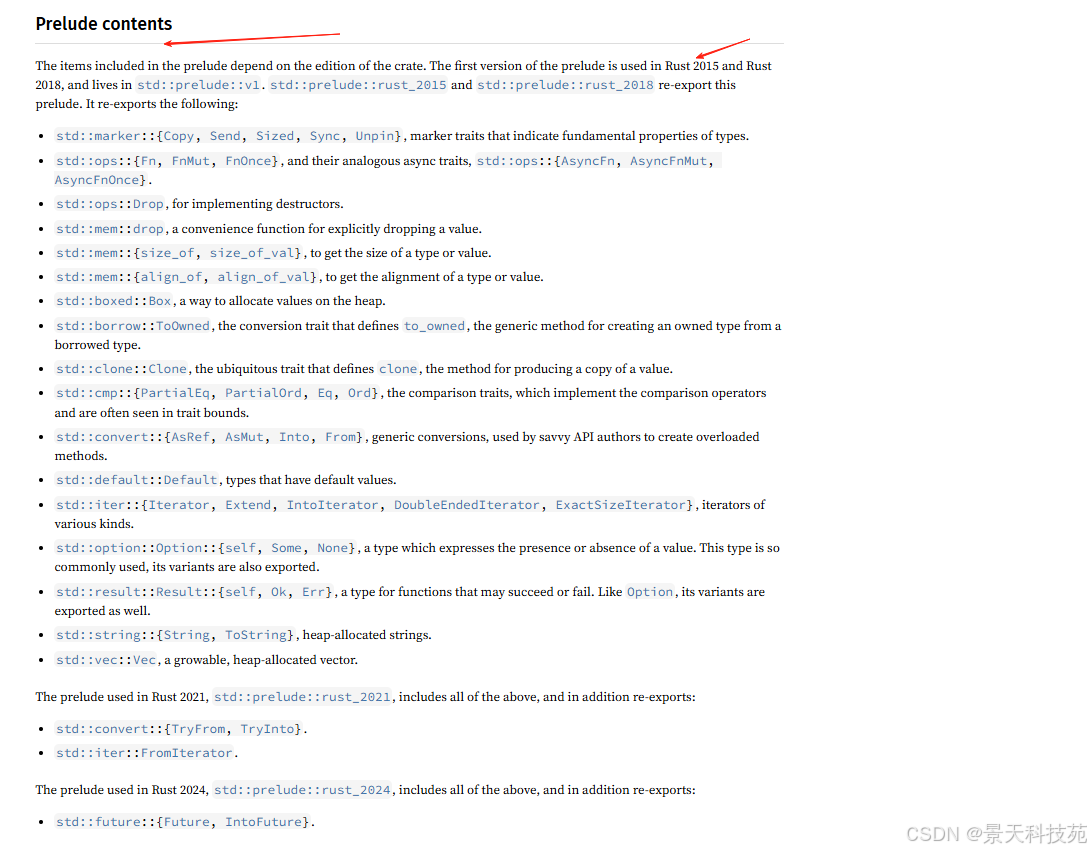
需要为 Rc 增加 use 语句因为它不在 prelude 中
Rust默认的标准库包含很多内容,其中prelude是自动导入的部分,是每个Rust程序都包含的标准库部分
可以自动导入的库如下
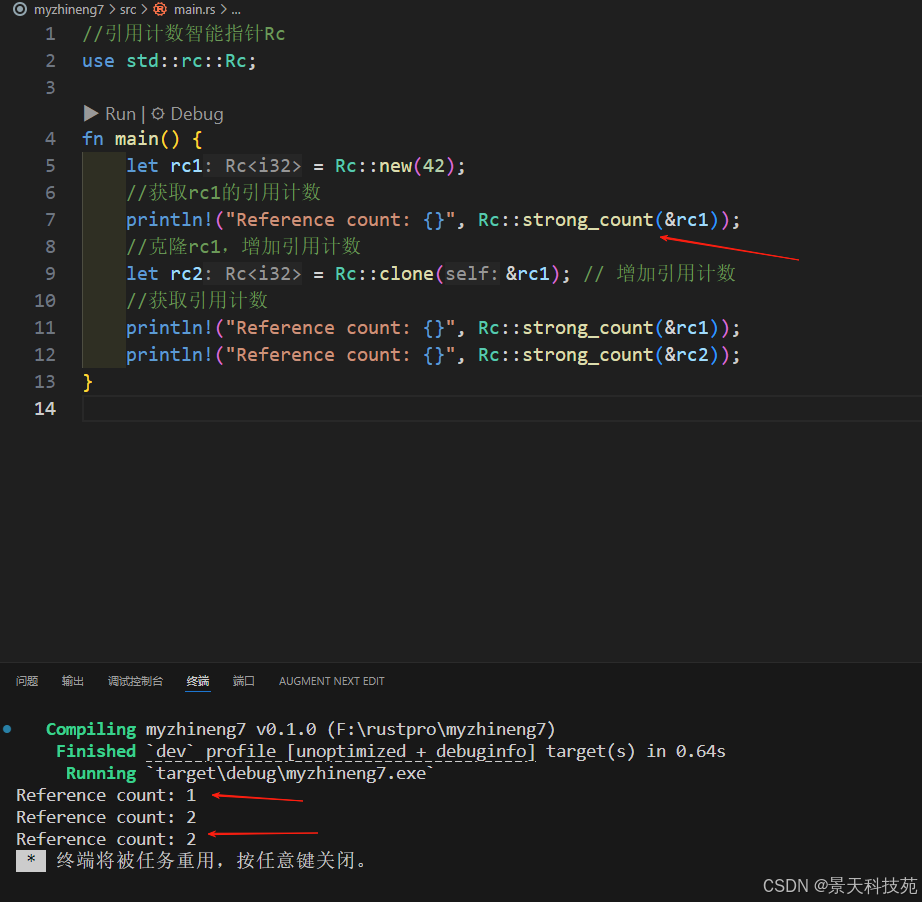
//引用计数智能指针Rc
use std::rc::Rc;fn main() {let rc1 = Rc::new(42);//获取rc1的引用计数println!("Reference count: {}", Rc::strong_count(&rc1));//克隆rc1,增加引用计数let rc2 = Rc::clone(&rc1); // 增加引用计数//获取引用计数println!("Reference count: {}", Rc::strong_count(&rc1));println!("Reference count: {}", Rc::strong_count(&rc2));
}
每次调用Rc::clone , Rc 中数据的引用计数都会增加,直到有零个引用之前其数据都不会被清理
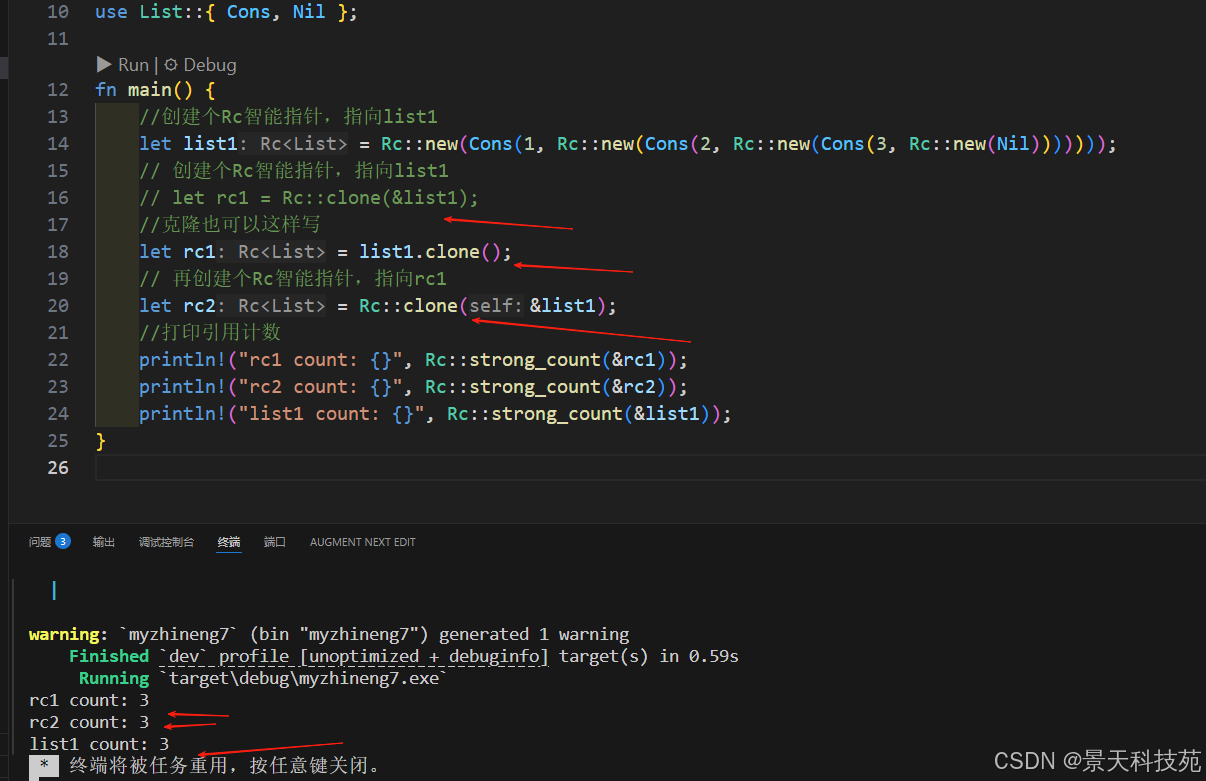
示例2:
//引用计数智能指针Rc
use std::rc::Rc;//定义链表
enum List {Cons(i32, Rc<List>),Nil,
}use List::{ Cons, Nil };fn main() {//创建个Rc智能指针,指向list1let list1 = Rc::new(Cons(1, Rc::new(Cons(2, Rc::new(Cons(3, Rc::new(Nil)))))));// 创建个Rc智能指针,指向list1// let rc1 = Rc::clone(&list1);//克隆也可以这样写let rc1 = list1.clone();// 再创建个Rc智能指针,指向rc1let rc2 = Rc::clone(&list1);//打印引用计数println!("rc1 count: {}", Rc::strong_count(&rc1));println!("rc2 count: {}", Rc::strong_count(&rc2));println!("list1 count: {}", Rc::strong_count(&list1));
}
不过在这里 Rust 的习惯是使用 Rc::clone 。 Rc::clone 的实现并不像大部分类型的 clone 实现那样对所有数据进行深拷贝。
Rc::clone 只会增加引用计数,这并不会花费多少时间。
深拷贝可能会花费很长时间,所以通过使用 Rc::clone 进行引用计数,
可以明显的区别可能会对运行时性能有巨大影响的深拷贝和不分配内存的对运行时性能影响相对较小的增加引用计数拷贝。
Rc<T> 允许通过不可变引用来只读的在程序的多个部分共享数据。
当离开作用域范围,引用计数器会在drop trait的作用下自动减一
//引用计数智能指针Rc
use std::rc::Rc;//定义链表
#[allow(dead_code)]
enum List {Cons(i32, Rc<List>),Nil,
}use List::{ Cons, Nil };fn main() {//创建个Rc智能指针,指向list1let list1 = Rc::new(Cons(1, Rc::new(Cons(2, Rc::new(Cons(3, Rc::new(Nil)))))));// 创建个Rc智能指针,指向list1// let rc1 = Rc::clone(&list1);//克隆也可以这样写let rc1 = list1.clone();// 再创建个Rc智能指针,指向rc1let rc2 = Rc::clone(&list1);//打印引用计数println!("rc1 count: {}", Rc::strong_count(&rc1));println!("rc2 count: {}", Rc::strong_count(&rc2));println!("list1 count: {}", Rc::strong_count(&list1));{let rc3 = Rc::clone(&list1);println!("rc3 count: {}", Rc::strong_count(&rc3));}//离开rc3的作用域,引用计数器减1//Drop trait 的实现当 Rc 值离开作用域时自动减少引用计数。println!("rc1 count: {}", Rc::strong_count(&rc1));println!("rc2 count: {}", Rc::strong_count(&rc2));// println!("rc3 count: {}", Rc::strong_count(&rc3));println!("list1 count: {}", Rc::strong_count(&list1));
}
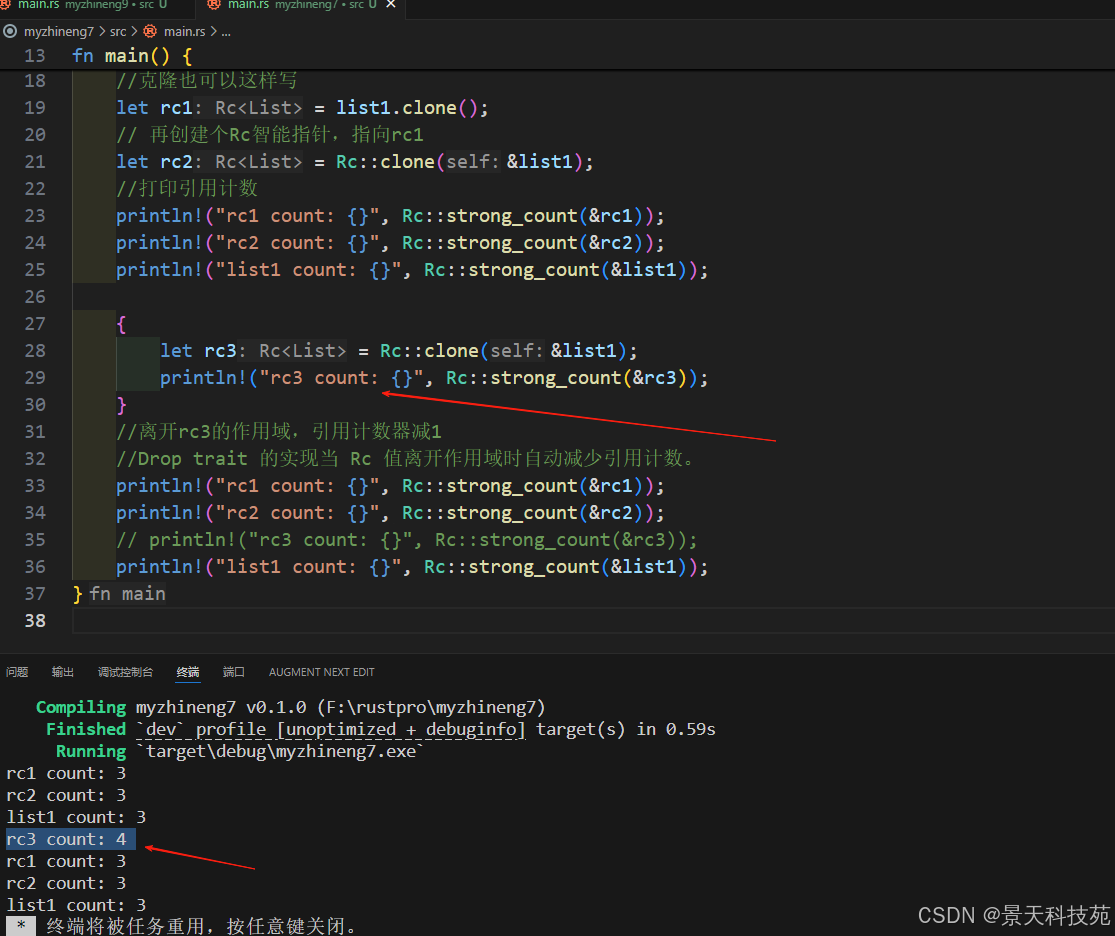
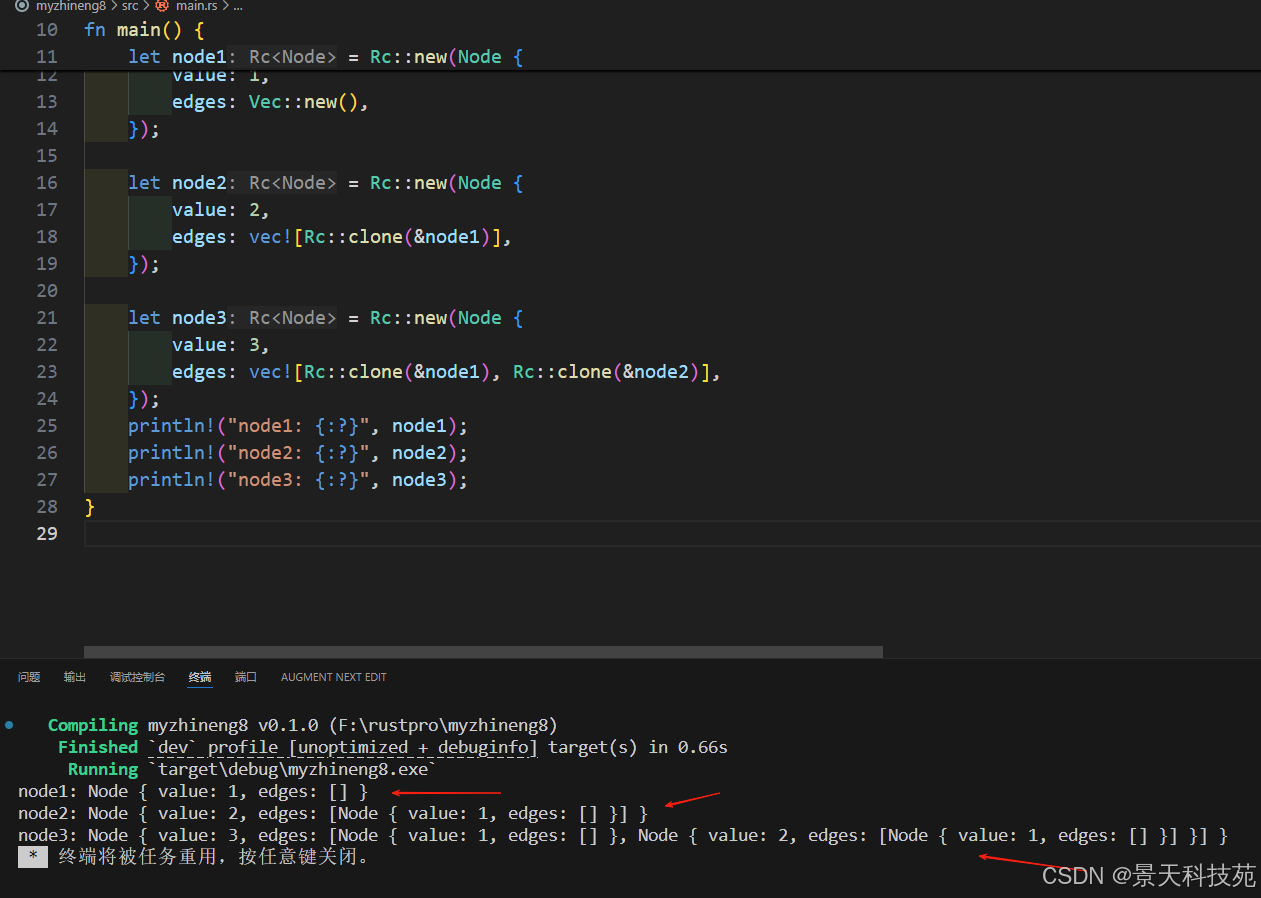
3.2 共享所有权场景
Rc常用于需要多个部分共享数据但不确定哪部分最后使用数据的场景。
use std::rc::Rc;#[derive(Debug)]
#[allow(dead_code)]
struct Node {value: i32,edges: Vec<Rc<Node>>,
}fn main() {let node1 = Rc::new(Node {value: 1,edges: Vec::new(),});let node2 = Rc::new(Node {value: 2,edges: vec![Rc::clone(&node1)],});let node3 = Rc::new(Node {value: 3,edges: vec![Rc::clone(&node1), Rc::clone(&node2)],});println!("node1: {:?}", node1);println!("node2: {:?}", node2);println!("node3: {:?}", node3);
}
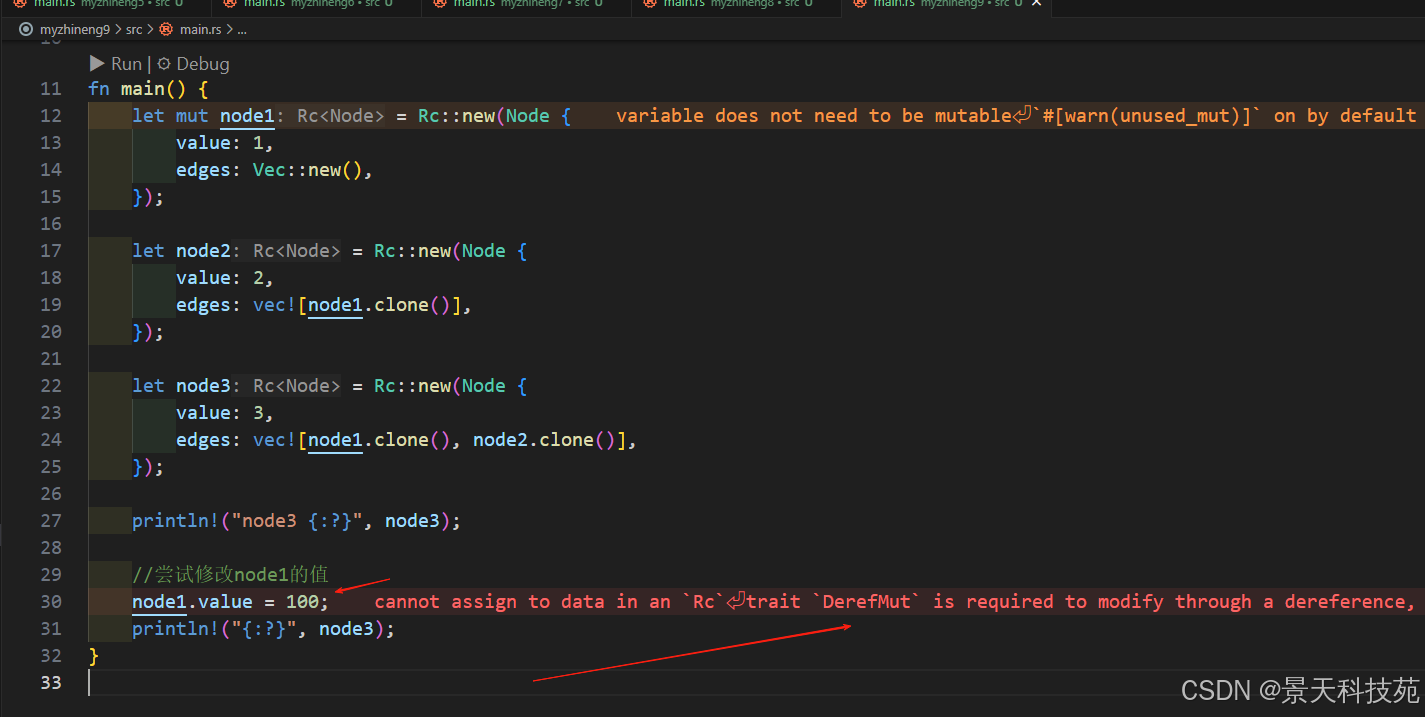
3.3 Rc的限制
仅适用于单线程
只有不可变引用(无法修改数据)
循环引用会导致内存泄漏
尝试修改Rc的引用,会报错,因为相同位置的多个可变引用,可能会造成数据不一致。Rust避免这种情况的出现
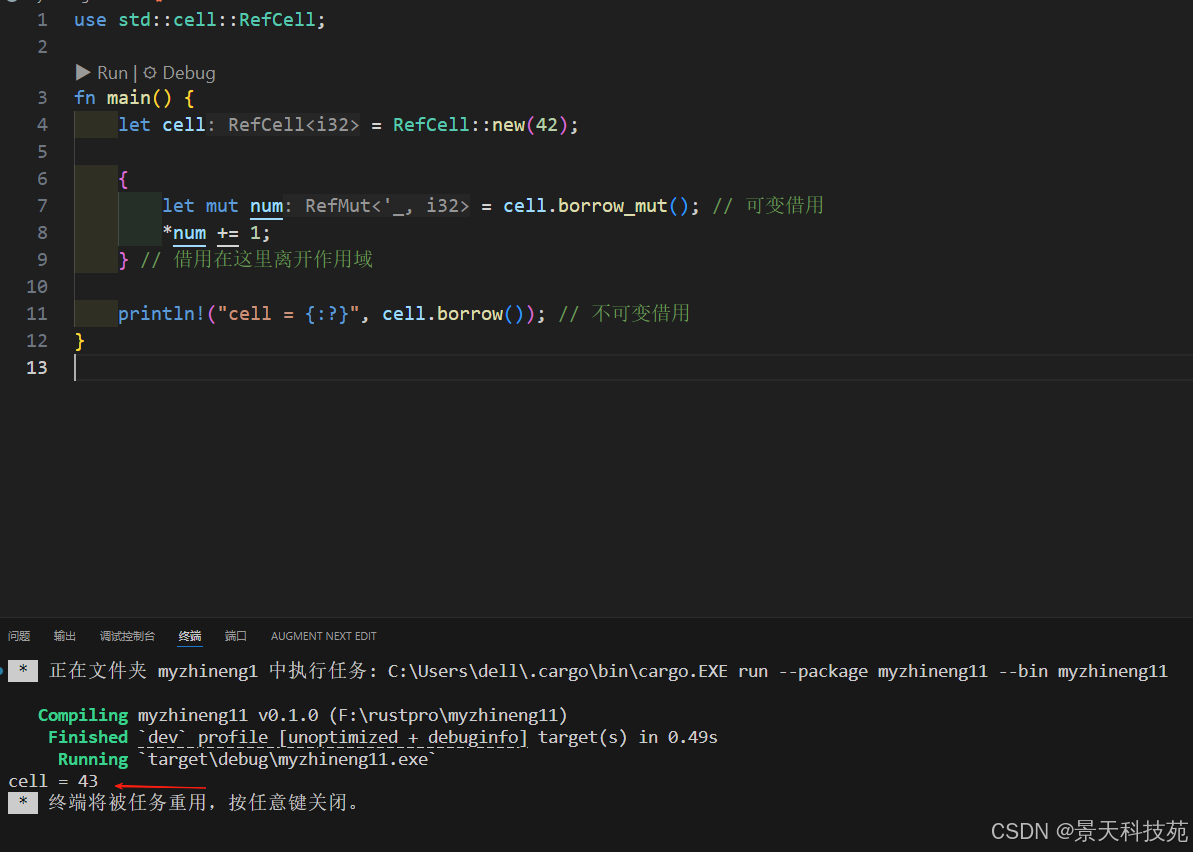
四、RefCell<T>:内部可变性模式
4.1 RefCell的基本用法
RefCell提供 运行时检查 的借用规则(通常Rust都是在编译时检查借用规则),允许在不可变引用下修改数据。RefCell代表其数据的唯一所有权
内部可变性(Interior mutability)是 Rust 中的一个设计模式,
它允许你即使在有不可变引用时改变数据,这通常是借用规则所不允许的。
为此,该模式在数据结构中使用 unsafe 代码来模糊 Rust 通常的可变性和借用规则。
当可以确保代码在运行时会遵守借用规则,即使编译器不能保证的情况,可以选择使用那些运用内部可变性模式的类型。
所涉及的 unsafe 代码将被封装进安全的 API 中,而外部类型仍然是不可变的。
不同于 Rc<T> , RefCell<T> 代表其数据的唯一的所有权。那么是什么让 RefCell<T> 不同于像 Box<T> 这样的类型呢?
我们回忆一下借用规则:
- 在任意给定时间,只能 拥有如下中的一个:
一个可变引用。
任意数量的不可变引用。 - 引用必须总是有效的。
对于引用和 Box<T> ,借用规则的不可变性作用于编译时。
对于 RefCell<T> ,这些不可变性作用于 运行时。
对于引用,如果违反这些规则,会得到一个编译错误。而对于 RefCell<T> ,违反这些规则会 panic! 。
在编译时检查借用规则的好处是这些错误将在开发过程的早期被捕获同时对没有运行时性能影响,因为所有的分析都提前完成了。
为此,在编译时检查借用规则是大部分情况的最佳选择,这也正是其为何是 Rust 的默认行为。
相反在运行时检查借用规则的好处是特定内存安全的场景是允许的,而它们在编译时检查中是不允许的。
静态分析,正如 Rust 编译器,是天生保守的。
代码的一些属性则不可能通过分析代码发现:其中最著名的就是 停机问题(HaltingProblem)。
因为一些分析是不可能的,如果 Rust 编译器不能通过所有权规则编译,它可能会拒绝一个正确的程序;从这种角度考虑它是保守的。
如果 Rust 接受不正确的程序,那么人们也就不会相信 Rust 所做的保证了。
然而,如果 Rust 拒绝正确的程序,会给程序员带来不便,但不会带来灾难。
RefCell<T> 正是用于当你确信代码遵守借用规则,而编译器不能理解和确定的时候。
类似于 Rc<T> , RefCell<T> 只能用于单线程场景。
如果尝试在多线程上下文中使用 RefCell<T> ,会得到一个编译错误。
如下为选择 Box<T> , Rc<T> 或 RefCell<T> 的理由:
Rc<T> 允许相同数据有多个所有者,提供只读的所有权共享; Box<T> 和 RefCell<T> 有单一所有者。
Box<T> 允许在编译时执行不可变(或可变)借用检查;
Rc<T> 仅允许在编译时执行不可变借用检查;RefCell<T> 允许在运行时执行不可变(或可变)借用检查。
因为 RefCell<T> 允许在运行时执行可变借用检查,所以我们可以在即便 RefCell<T> 自身是不可变的情况下修改其内部的值。
最后一个理由便是指 内部可变性 模式。让我们看看何时内部可变性是有用的,并讨论这是如何成为可能的。
use std::cell::RefCell;fn main() {let cell = RefCell::new(42);{let mut num = cell.borrow_mut(); // 可变借用*num += 1;} // 借用在这里离开作用域//在作用域中修改的值,可以在作用域外访问println!("cell = {:?}", cell.borrow()); // 不可变借用
}
4.2 内部可变性:不可变值的可变借用
借用规则的一个推论是当有一个不可变值时,不能可变的借用它。
如果尝试改变其值,编译时会得到错误
cannot borrow immutable local variable x as mutable
然而,特定情况下在值的方法内部能够修改自身是很有用的;而不是在其他代码中,此时值仍然是不可变。
值方法外部的代码不能修改其值。 RefCell<T> 是一个获得内部可变性的方法。
RefCell<T> 并没有完全绕开借用规则,编译器中的借用检查器允许内部可变性并相应的在运行时检查借用规则。
如果违反了这些规则,会得到 panic! 而不是编译错误。
RefCell<T> 在运行时检查借用规则
当创建不可变和可变引用时,我们分别使用 & 和 &mut 语法。
对于 RefCell<T> 来说,则是 borrow 和 borrow_mut 方法,这属于 RefCell<T> 安全 API 的一部分。
borrow 方法返回 Ref 类型的智能指针, borrow_mut 方法返回 RefMut 类型的智能指针。
这两个类型都实现了 Deref 所以可以当作常规引用对待。
RefCell<T> 记录当前有多少个活动的 Ref 和 RefMut 智能指针。
每次调用 borrow , RefCell<T> 将活动的不可变借用计数加一。
当 Ref 值离开作用域时,不可变借用计数减一。
就像编译时借用规则一样, RefCell<T> 在任何时候只允许有多个不可变借用或一个可变借用。
如果我们尝试违反这些规则,相比引用时的编译时错误, RefCell<T> 的实现会在运行时 panic! 。
在运行时捕获借用错误而不是编译时意味着将会在开发过程的后期才会发现错误 ———— 甚至有可能发布到生产环境才发现。
还会因为在运行时而不是编译时记录借用而导致少量的运行时性能惩罚。
然而,使用 RefCell 使得在只允许不可变值的上下文中编写修改自身以记录消息的 mock 对象成为可能。
虽然有取舍,但是我们可以选择使用 RefCell<T> 来获得比常规引用所能提供的更多的功能。
结合 Rc<T> 和 RefCell<T> 来拥有多个可变数据所有者
RefCell<T> 的一个常见用法是与 Rc<T> 结合。
回忆一下 Rc<T> 允许对相同数据有多个所有者,不过只能提供数据的不可变访问。
如果有一个储存了 RefCell<T> 的 Rc<T> 的话,就可以得到有多个所有者 并且 可以修改的值了!
可变数据的前提是Rc<T>里面套RefCell<T>
使用 Rc<RefCell<i32>> 创建可以修改的 List
//RefCell<T>
use std::cell::RefCell;//引用计数智能指针Rc
use std::rc::Rc;//定义链表
#[allow(dead_code)]
#[derive(Debug)]
enum List {Cons(Rc<RefCell<i32>>, Rc<List>),Nil,
}use List::{ Cons, Nil };fn main() {let value = Rc::new(RefCell::new(5));let a = Rc::new(Cons(Rc::clone(&value), Rc::new(Nil)));let b = Cons(Rc::new(RefCell::new(6)), Rc::clone(&a));let c = Cons(Rc::new(RefCell::new(7)), Rc::clone(&a));println!("a before = {:?}", a);println!("b before = {:?}", b);println!("c before = {:?}", c);//我们可以修改内部的值,解引用//修改value内部的值*value.borrow_mut() += 10;println!("a after = {:?}", a);println!("b after = {:?}", b);println!("c after = {:?}", c);
}
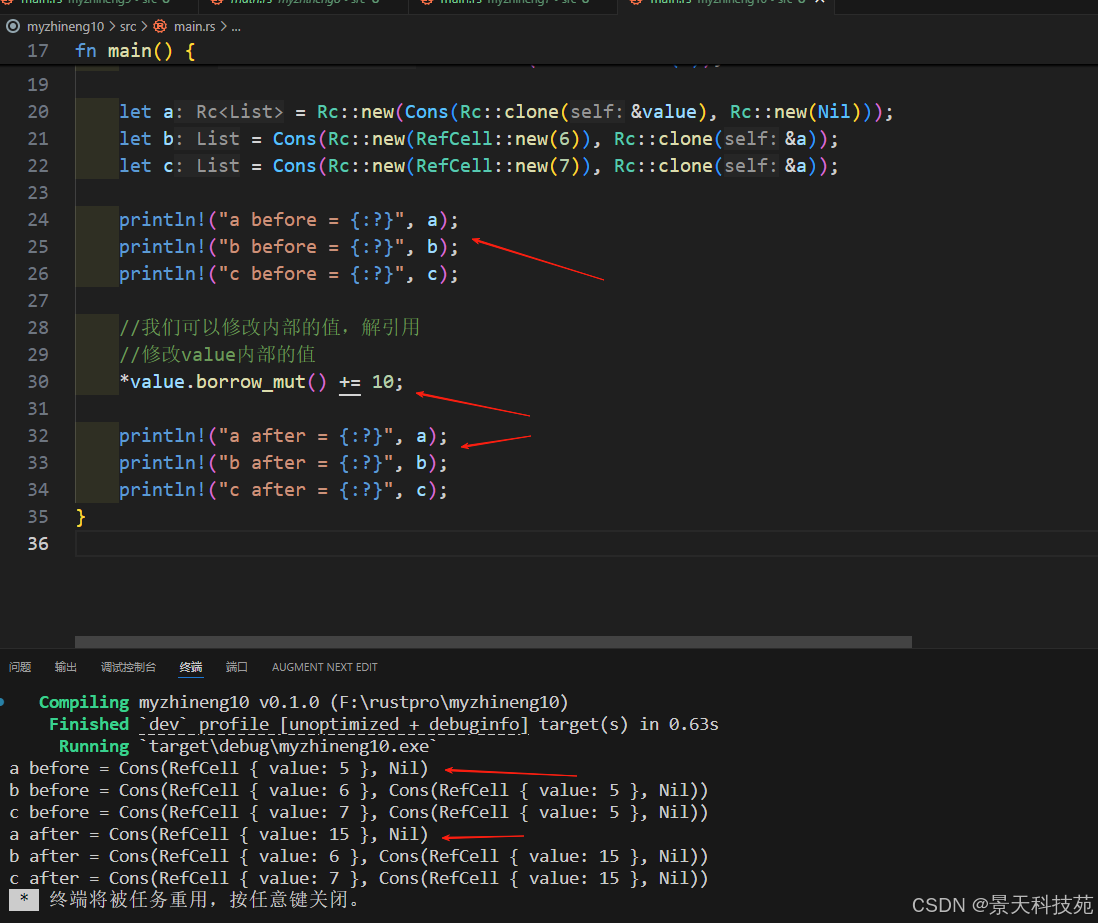
这里创建了一个 Rc<RefCell<i32> 实例并储存在变量 value 中以便之后直接访问。
接着在 a 中用包含 value 的 Cons 成员创建了一个 List 。
需要克隆 value 以便 a 和 value 都能拥有其内部值 5 的所有权,而不是将所有权从 value 移动到 a 或者让 a 借用 value 。
我们将列表 a 封装进了 Rc<T> 这样当创建列表 b 和 c 时,他们都可以引用 a 。
一旦创建了列表 a 、 b 和 c ,我们将 value 的值加 10。
为此对 value 调用了 borrow_mut ,这里使用了解引用功能(“ -> 运算符到哪去了?”)来解引用 Rc<T> 以获取其内部的 RefCell<T> 值。
borrow_mut 方法返回RefMut<T> 智能指针,可以对其使用解引用运算符并修改其内部值。
这是非常巧妙的!通过使用 RefCell<T> ,我们可以拥有一个表面上不可变的 List ,不过可以使用 RefCell<T> 中提供内部可变性的方法来在需要时修改数据。
RefCell<T> 的 运行时借用规则检查 也确实保护我们免于出现数据竞争,而且我们也决定牺牲一些速度来换取数据结构的灵活性。
标准库中也有其他提供内部可变性的类型,比如 Cell<T> ,它有些类似( RefCell<T> )除了相比提供内部值的引用,其值被拷贝进和拷贝出 Cell<T> 。
案例2:
use std::rc::Rc;
use std::cell::RefCell;#[derive(Debug)]
#[allow(dead_code)]
struct Node {value: i32,edges: Vec<Rc<RefCell<Node>>>,
}fn main() {let node1 = Rc::new(RefCell::new(Node {value: 1,edges: Vec::new(),}));let node2 = Rc::new(RefCell::new(Node {value: 2,edges: vec![Rc::clone(&node1)],}));// 修改node1的值node1.borrow_mut().value = 10;println!("node1: {:?}", node1.borrow());println!("node2: {:?}", node2.borrow());
}
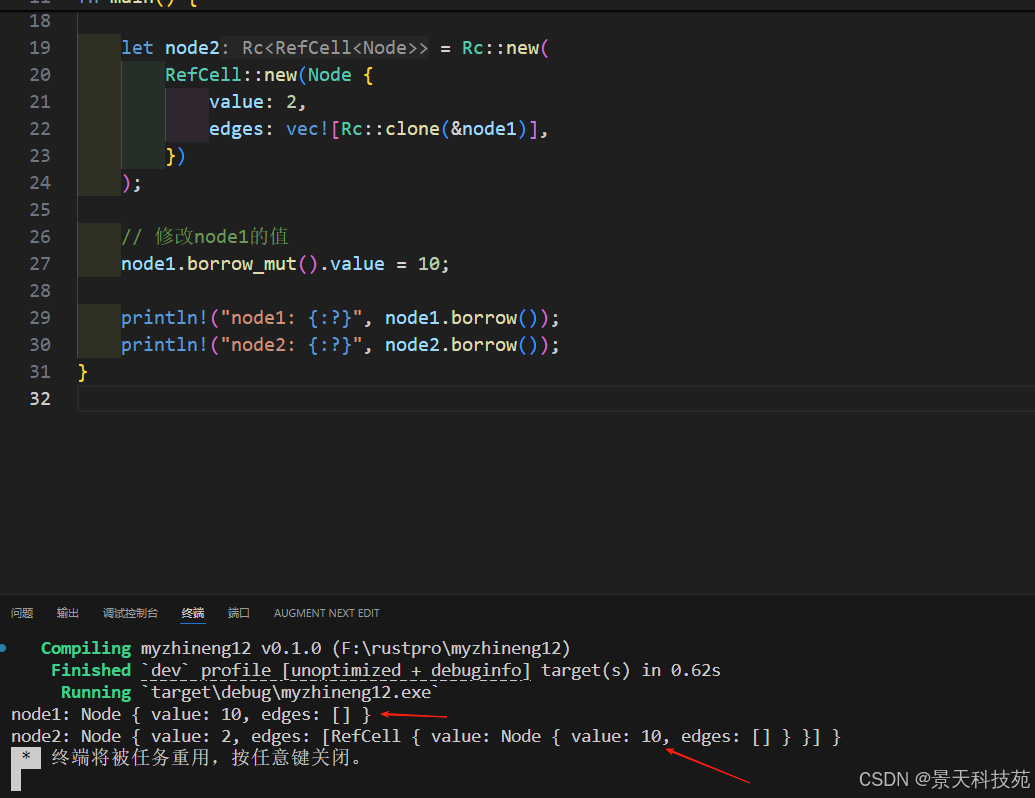
4.3 RefCell的运行时检查
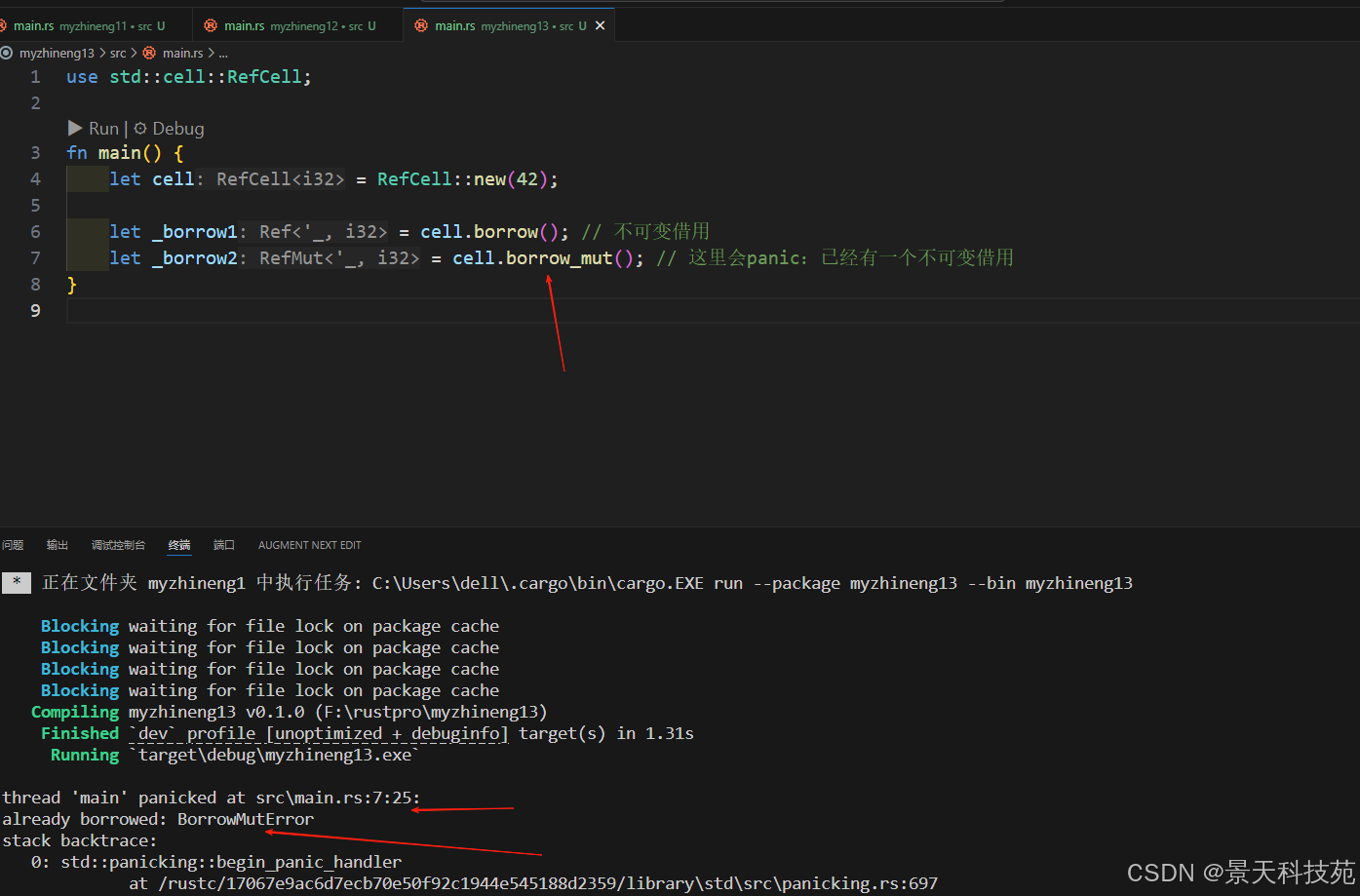
RefCell在运行时检查借用规则,违反规则会导致panic:
编译通过,运行时导致panic
use std::cell::RefCell;fn main() {let cell = RefCell::new(42);let _borrow1 = cell.borrow(); // 不可变借用let _borrow2 = cell.borrow_mut(); // 这里会panic:已经有一个不可变借用
}
五、Arc<T>:线程安全的引用计数
5.1 Arc的基本用法
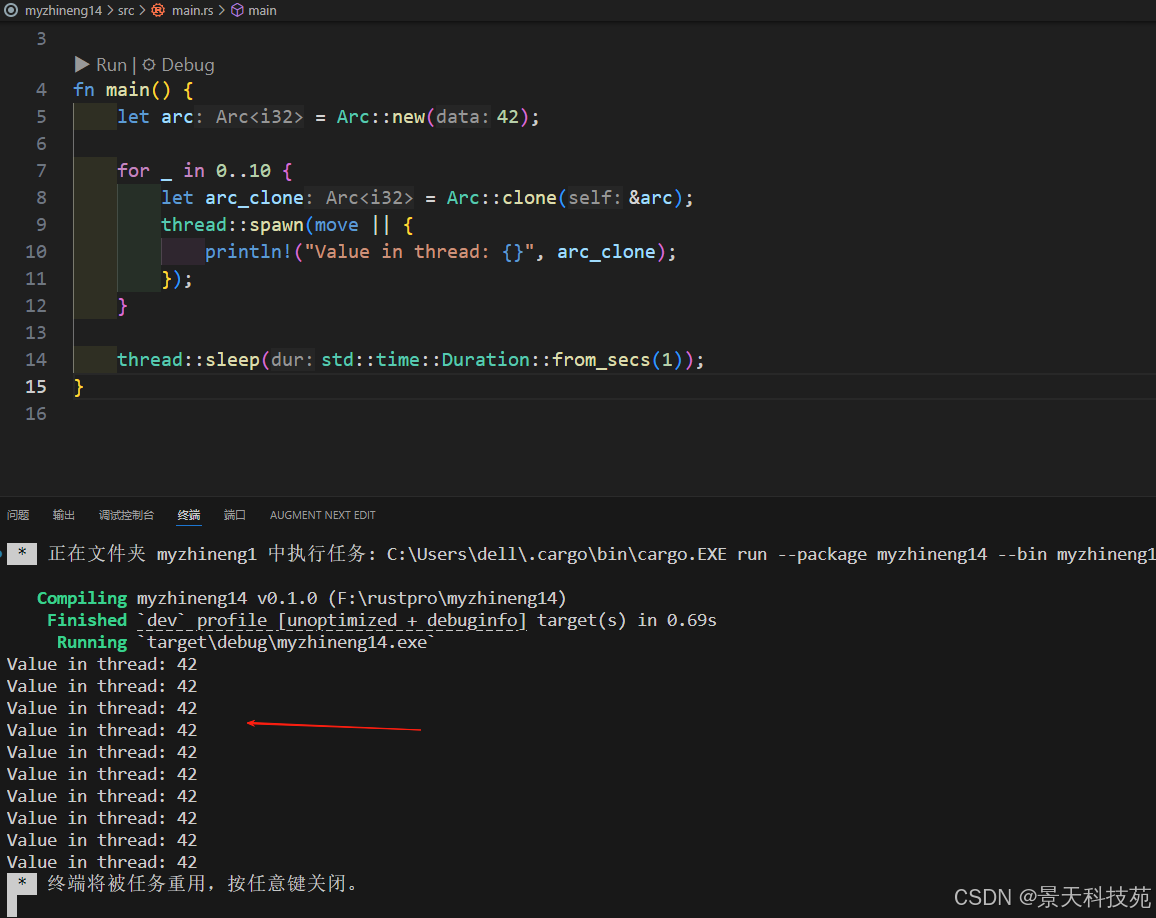
Arc(Atomic Reference Counting)是Rc的线程安全版本,使用原子操作管理引用计数。
use std::sync::Arc;
use std::thread;fn main() {let arc = Arc::new(42);for _ in 0..10 {let arc_clone = Arc::clone(&arc);thread::spawn(move || {println!("Value in thread: {}", arc_clone);});}thread::sleep(std::time::Duration::from_secs(1));
}
5.2 Arc与Mutex结合使用
Arc通常与Mutex或RwLock结合使用,以实现线程间共享可变数据。
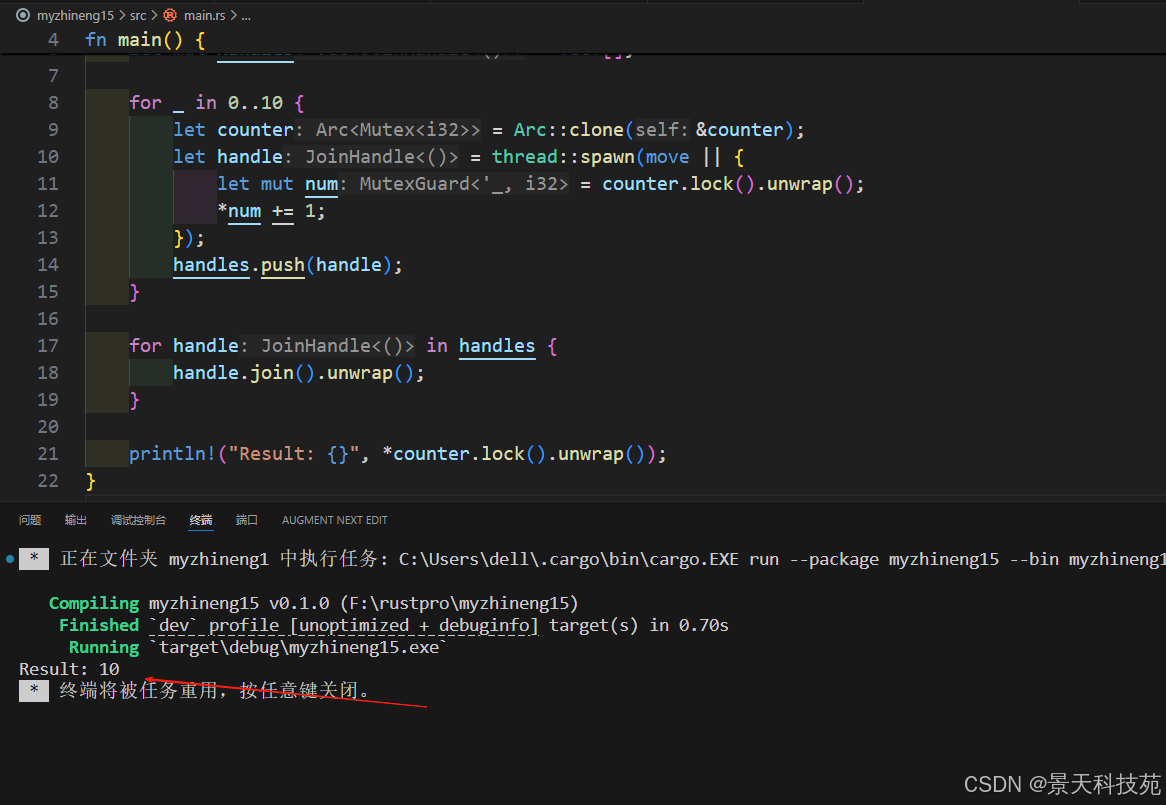
use std::sync::{ Arc, Mutex };
use std::thread;fn main() {let counter = Arc::new(Mutex::new(0));let mut handles = vec![];for _ in 0..10 {let counter = Arc::clone(&counter);let handle = thread::spawn(move || {let mut num = counter.lock().unwrap();*num += 1;});handles.push(handle);}for handle in handles {handle.join().unwrap();}println!("Result: {}", *counter.lock().unwrap());
}
六、智能指针的高级用法
6.1 自定义智能指针
我们可以通过实现Deref和Drop trait来创建自定义智能指针。
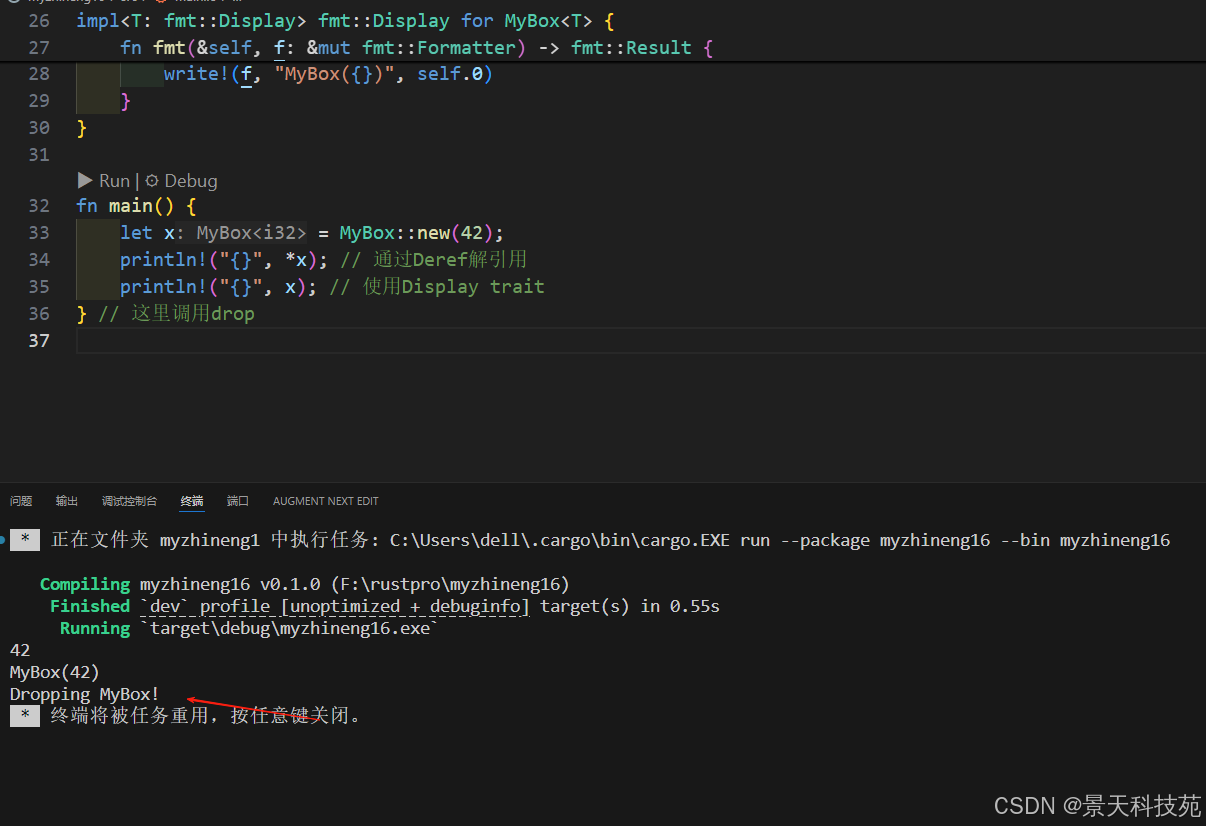
use std::ops::Deref;
use std::fmt;struct MyBox<T>(T);impl<T> MyBox<T> {fn new(x: T) -> MyBox<T> {MyBox(x)}
}impl<T> Deref for MyBox<T> {type Target = T;fn deref(&self) -> &T {&self.0}
}impl<T> Drop for MyBox<T> {fn drop(&mut self) {println!("Dropping MyBox!");}
}impl<T: fmt::Display> fmt::Display for MyBox<T> {fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {write!(f, "MyBox({})", self.0)}
}fn main() {let x = MyBox::new(42);println!("{}", *x); // 通过Deref解引用println!("{}", x); // 使用Display trait
} // 这里调用drop
6.2 引用循环与内存泄漏
Rust 的内存安全保证使其 难以 意外的制造永远也不会被清理的内存(被称为 内存泄露(memory leak)),但并不是不可能。
完全的避免内存泄露并不是同在编译时拒绝数据竞争一样为 Rust 的保证之一,这意味着内存泄露在 Rust 被认为是内存安全的。
这一点可以通过 Rc 和 RefCell 看出:有可能会创建个个项之间相互引用的引用。
这会造成内存泄露,因为每一项的引用计数将永远也到不了 0,其值也永远也不会被丢弃。
制造引用循环
让我们看看引用循环是如何发生的以及如何避免它。以下示例中的 List 枚举和 tail 方法的定义开始:
//引用循环
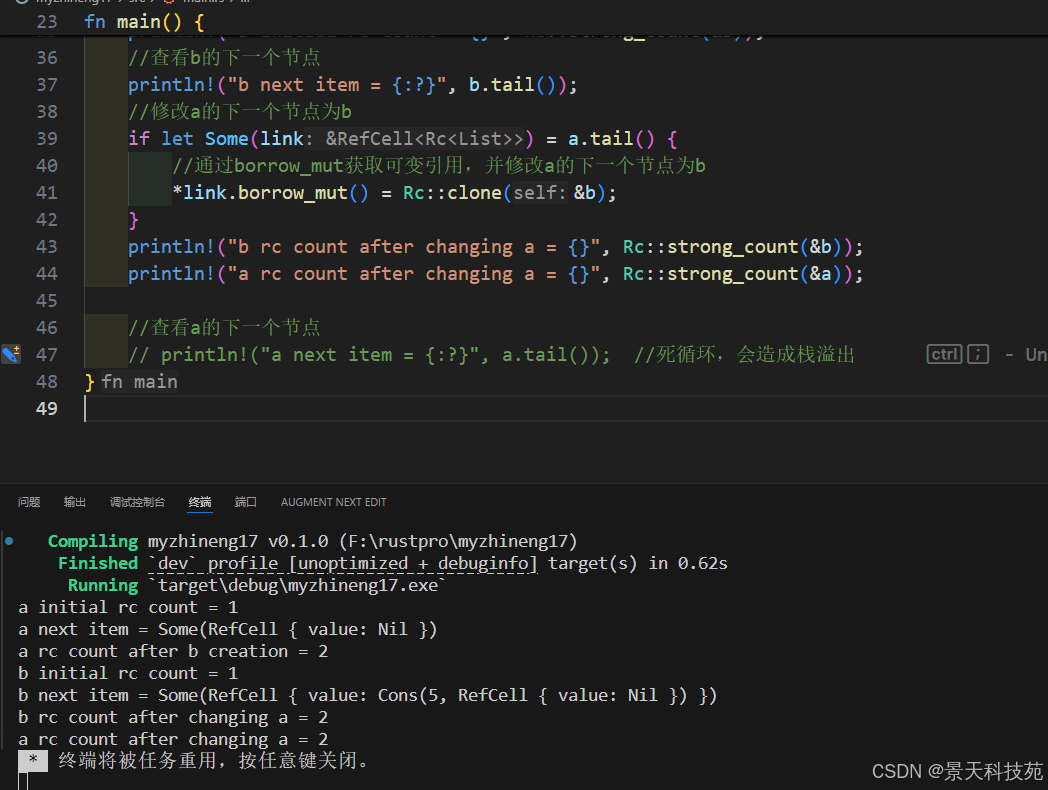
use std::rc::Rc;
use std::cell::RefCell;
use List::{ Cons, Nil };#[derive(Debug)]
#[allow(dead_code)]
enum List {Cons(i32, RefCell<Rc<List>>),Nil,
}//为List实现tail方法
impl List {//有可能是为空的,所以返回值是Optionfn tail(&self) -> Option<&RefCell<Rc<List>>> {match *self {Cons(_, ref item) => Some(item),Nil => None,}}
}
fn main() {//定义个链表alet a = Rc::new(Cons(5, RefCell::new(Rc::new(Nil))));//查看a引用计数println!("a initial rc count = {}", Rc::strong_count(&a));//查看a的下一个节点println!("a next item = {:?}", a.tail());//定义个链表b,b的下一个节点是alet b = Rc::new(Cons(10, RefCell::new(Rc::clone(&a))));//查看a,b引用计数println!("a rc count after b creation = {}", Rc::strong_count(&a));println!("b initial rc count = {}", Rc::strong_count(&b));//查看b的下一个节点println!("b next item = {:?}", b.tail());//修改a的下一个节点为bif let Some(link) = a.tail() {//通过borrow_mut获取可变引用,并修改a的下一个节点为b*link.borrow_mut() = Rc::clone(&b);}println!("b rc count after changing a = {}", Rc::strong_count(&b));println!("a rc count after changing a = {}", Rc::strong_count(&a));//查看a的下一个节点// println!("a next item = {:?}", a.tail()); //死循环,会造成栈溢出
}
这里在变量 a 中创建了一个 Rc 实例来存放初值为 5, Nil 的 List 值。接着在变量 b 中创建了存放包含值 10 和指向列表 a 的 List 的另一个 Rc 实例。
最后,修改 a 使其指向 b 而不是 Nil ,这就创建了一个循环。
为此需要使用 tail 方法获取 a 中 RefCell 的引用,并放入变量 link 中。
接着使用 RefCell 的 borrow_mut 方法将其值从存放 Nil 的 Rc 修改为 b 中的 Rc 。
可以看到将 a 修改为指向 b 之后, a 和 b 中都有的 Rc 实例的引用计数为 2。
在 main 的结尾,Rust 会尝试首先丢弃 b ,这会使 a 和 b 中 Rc 实例的引用计数减一。
然而,因为 a 仍然引用 b 中的 Rc , Rc 的引用计数是 1 而不是 0,所以 Rc 在堆上的内存不会被丢弃。
其内存会因为引用计数为 1 而永远停留。
此时,如果我们查看a.tail()或b.tail()都会出现死循环,造成栈溢出
因为a,b是首尾相连的。持续交替打印
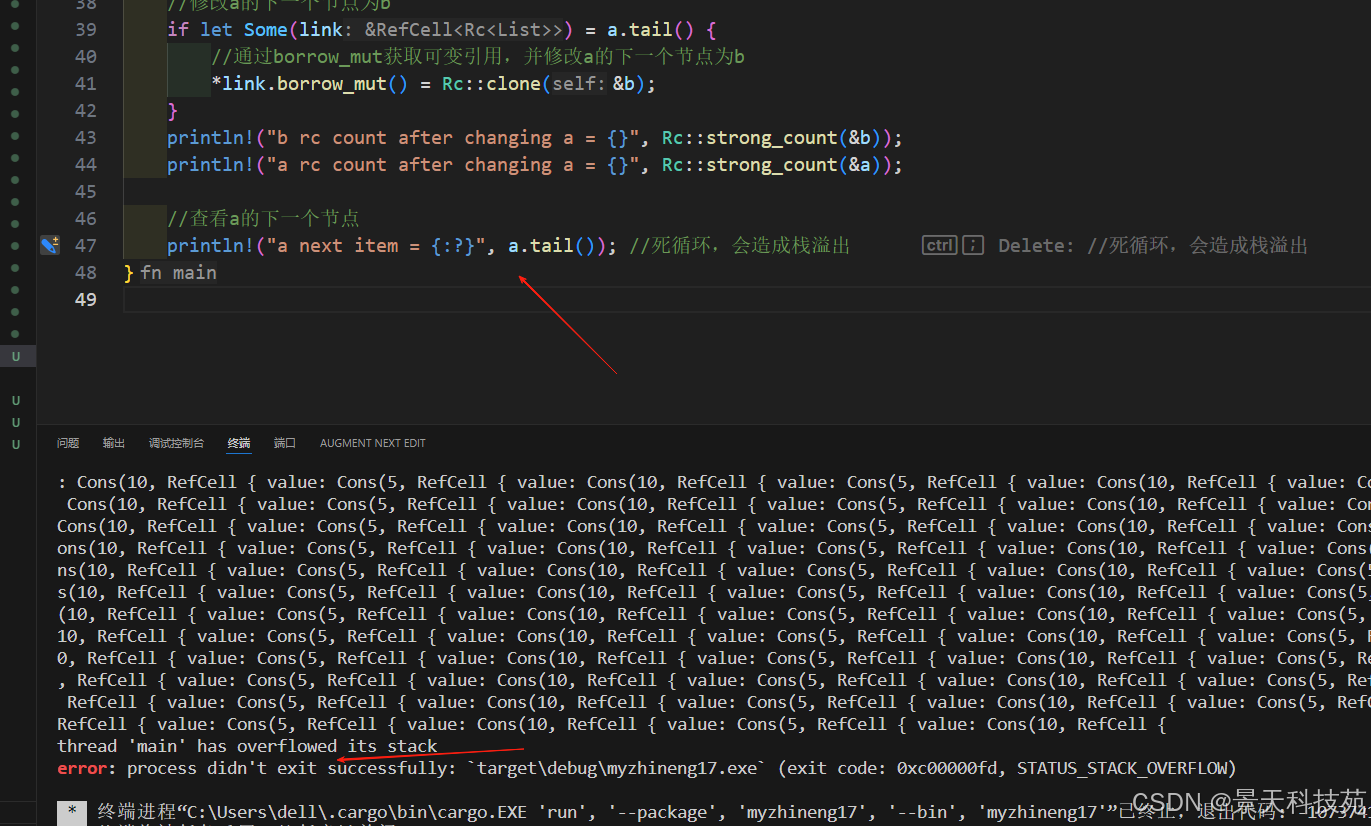
循环引用如图所示
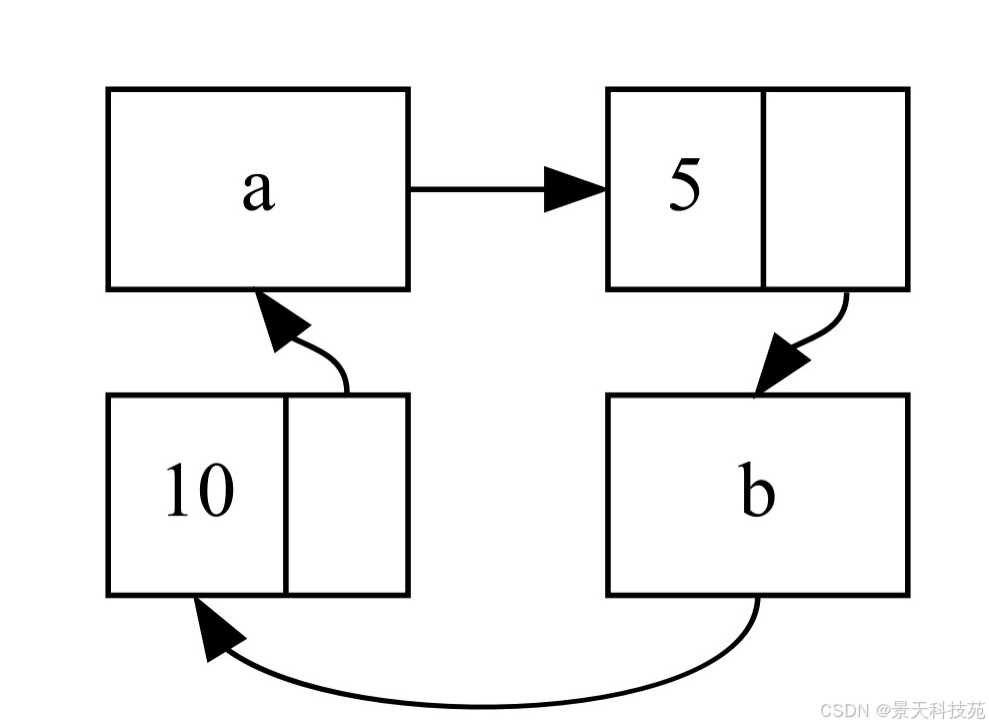
这个特定的例子中,创建了引用循环之后程序立刻就结束了。这个循环的结果并不可怕。
如果在更为复杂的程序中并在循环里分配了很多内存并占有很长时间,这个程序会使用多于它所需要的内存,并有可能压垮系统并造成没有内存可供使用。
创建引用循环并不容易,但也不是不可能。
如果你有包含 Rc 的 RefCell 值或类似的嵌套结合了内部可变性和引用计数的类型,请务必小心确保你没有形成一个引用循环;你无法指望 Rust 帮你捕获它们。
创建引用循环是一个程序上的逻辑 bug,你应该使用自动化测试、代码评审和其他软件开发最佳实践来使其最小化。
另一个解决方案是重新组织数据结构使得一些引用有所有权而另一些则没有。
如此,循环将由一些有所有权的关系和一些没有所有权的关系,而只有所有权关系才影响值是否被丢弃。
在这个案例 中,我们总是希望 Cons 成员拥有其列表,所以重新组织数据结构是不可能的。
6.3 弱引用(Weak<T>)
Rc和Arc都支持弱引用Weak,它不会增加引用计数,用于解决循环引用问题。
避免引用循环:将 Rc 变为 Weak
到目前为止,我们已经展示了调用 Rc::clone 会增加 Rc 实例的 strong_count ,和 Rc 实例只在其 strong_count 为 0 时才会被清理。
也可以通过调用 Rc::downgrade 并传递 Rc 实例的引用来创建其值的 弱引用(weak reference)。
调用Rc::downgrade 时会得到 Weak 类型的智能指针。
不同于将 Rc 实例的 strong_count 加一,调用 Rc::downgrade 会将weak_count 加一。
Rc 类型使用 weak_count 来记录其存在多少个 Weak 引用,类似于 strong_count 。
其区别在于weak_count 无需计数为 0 就能使 Rc 实例被清理,只需要strong_count为0就可以了。
强引用代表如何共享 Rc 实例的引用。弱引用并不代表所有权关系。
他们不会造成引用循环,因为任何引入了弱引用的循环一旦所涉及的强引用计数为 0 就会被打破。
因为 Weak 引用的值可能已经被丢弃了,为了使用 Weak 所指向的值,我们必须确保其值仍然有效。
为此可以调用Weak 实例的 upgrade 方法,这会返回 Option<Rc> 。
如果 Rc 值还未被丢弃则结果是 Some ,如果 Rc 已经被丢弃则结果是 None 。
因为 upgrade 返回一个 Option ,我们确信 Rust 会处理 Some 和 None 的情况,并且不会有一个无效的指针。
//弱引用
use std::rc::{ Weak, Rc };
use std::cell::RefCell;
use List::{ Cons, Nil };#[derive(Debug)]
#[allow(dead_code)]
//将List定义成Weak
enum List {Cons(i32, RefCell<Weak<List>>),Nil,
}//为List实现tail方法
impl List {//有可能是为空的,所以返回值是Optionfn tail(&self) -> Option<&RefCell<Weak<List>>> {match self {Cons(_, item) => Some(item),Nil => None,}}
}
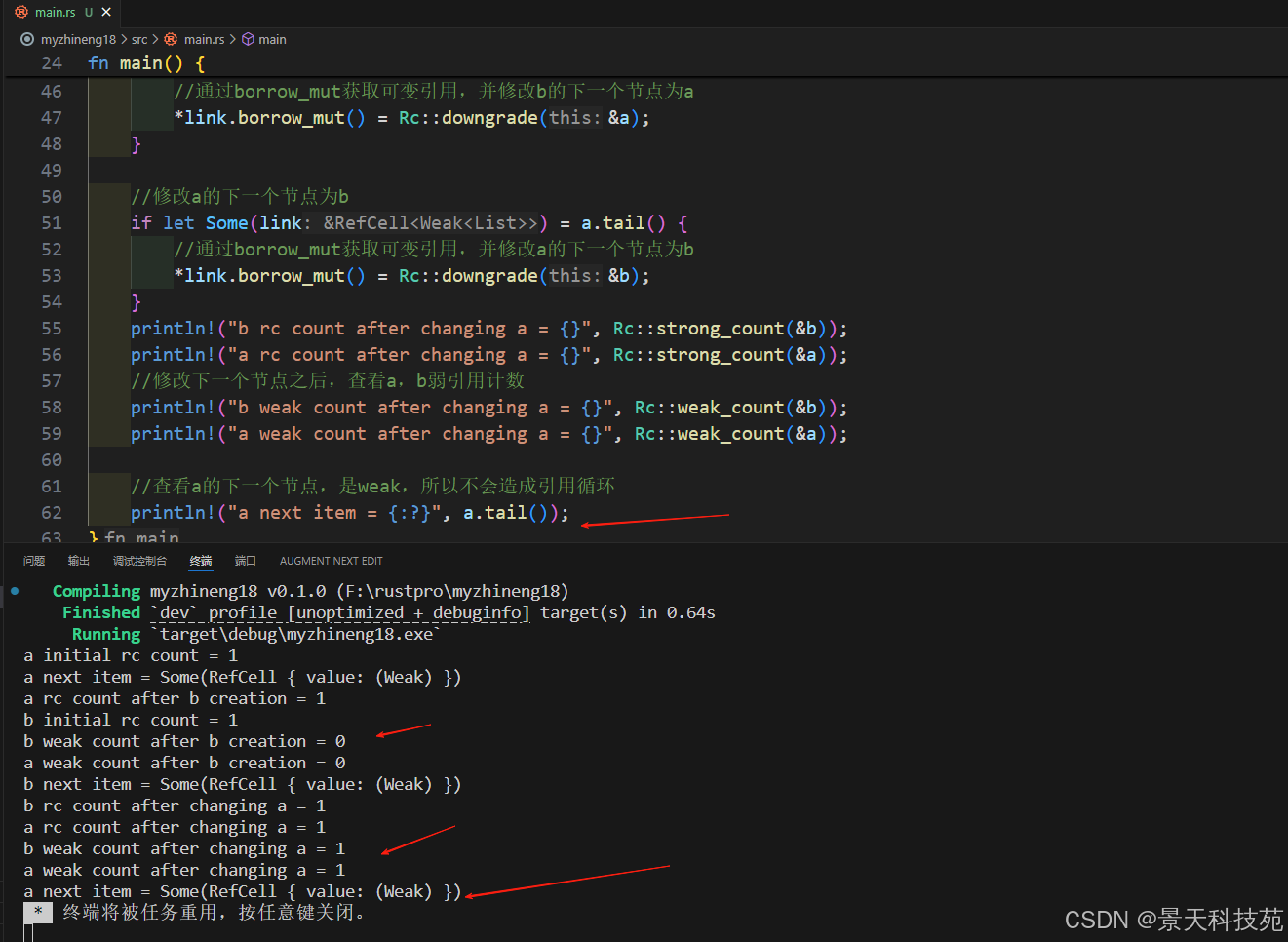
fn main() {//定义个链表alet a = Rc::new(Cons(5, RefCell::new(Weak::new())));//查看a引用计数println!("a initial rc count = {}", Rc::strong_count(&a));//查看a的下一个节点println!("a next item = {:?}", a.tail());//定义个链表blet b = Rc::new(Cons(10, RefCell::new(Weak::new())));//查看a,b引用计数println!("a rc count after b creation = {}", Rc::strong_count(&a));println!("b initial rc count = {}", Rc::strong_count(&b));//修改下一个节点之前,查看a,b弱引用计数println!("b weak count after b creation = {}", Rc::weak_count(&b));println!("a weak count after b creation = {}", Rc::weak_count(&a));//查看b的下一个节点println!("b next item = {:?}", b.tail());//修改b的下一个节点为aif let Some(link) = b.tail() {//通过borrow_mut获取可变引用,并修改b的下一个节点为a*link.borrow_mut() = Rc::downgrade(&a);}//修改a的下一个节点为bif let Some(link) = a.tail() {//通过borrow_mut获取可变引用,并修改a的下一个节点为b*link.borrow_mut() = Rc::downgrade(&b);}println!("b rc count after changing a = {}", Rc::strong_count(&b));println!("a rc count after changing a = {}", Rc::strong_count(&a));//修改下一个节点之后,查看a,b弱引用计数println!("b weak count after changing a = {}", Rc::weak_count(&b));println!("a weak count after changing a = {}", Rc::weak_count(&a));//查看a的下一个节点,是weak,所以不会造成引用循环println!("a next item = {:?}", a.tail());
}
6.4 创建树形数据结构:带有子结点的 Node
use std::rc::{ Rc, Weak };
use std::cell::RefCell;//树形结构
#[derive(Debug)]
#[allow(dead_code)]
struct Node {value: i32,parent: RefCell<Weak<Node>>,children: RefCell<Vec<Rc<Node>>>,
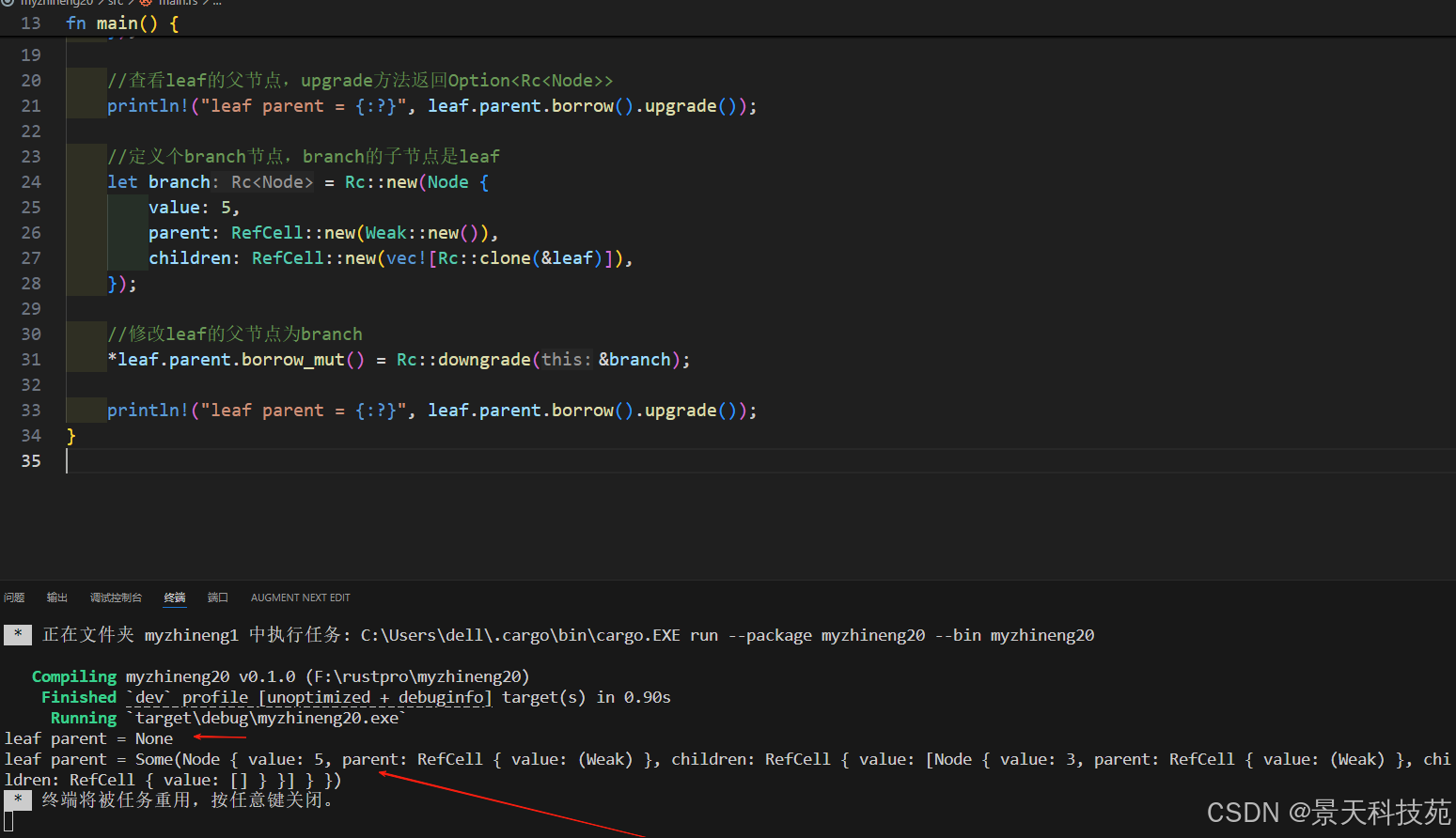
}fn main() {let leaf = Rc::new(Node {value: 3,parent: RefCell::new(Weak::new()), //我们目前不知道leaf的父节点是谁,所以先设置为Weak::new()children: RefCell::new(Vec::new()), //leaf目前没有子节点});//查看leaf的父节点,upgrade方法返回Option<Rc<Node>>println!("leaf parent = {:?}", leaf.parent.borrow().upgrade());//定义个branch节点,branch的子节点是leaflet branch = Rc::new(Node {value: 5,parent: RefCell::new(Weak::new()),children: RefCell::new(vec![Rc::clone(&leaf)]),});//修改leaf的父节点为branch*leaf.parent.borrow_mut() = Rc::downgrade(&branch);println!("leaf parent = {:?}", leaf.parent.borrow().upgrade());
}
查看强引用和弱引用计数
use std::rc::{ Rc, Weak };
use std::cell::RefCell;//树形结构
#[derive(Debug)]
#[allow(dead_code)]
struct Node {value: i32,parent: RefCell<Weak<Node>>,children: RefCell<Vec<Rc<Node>>>,
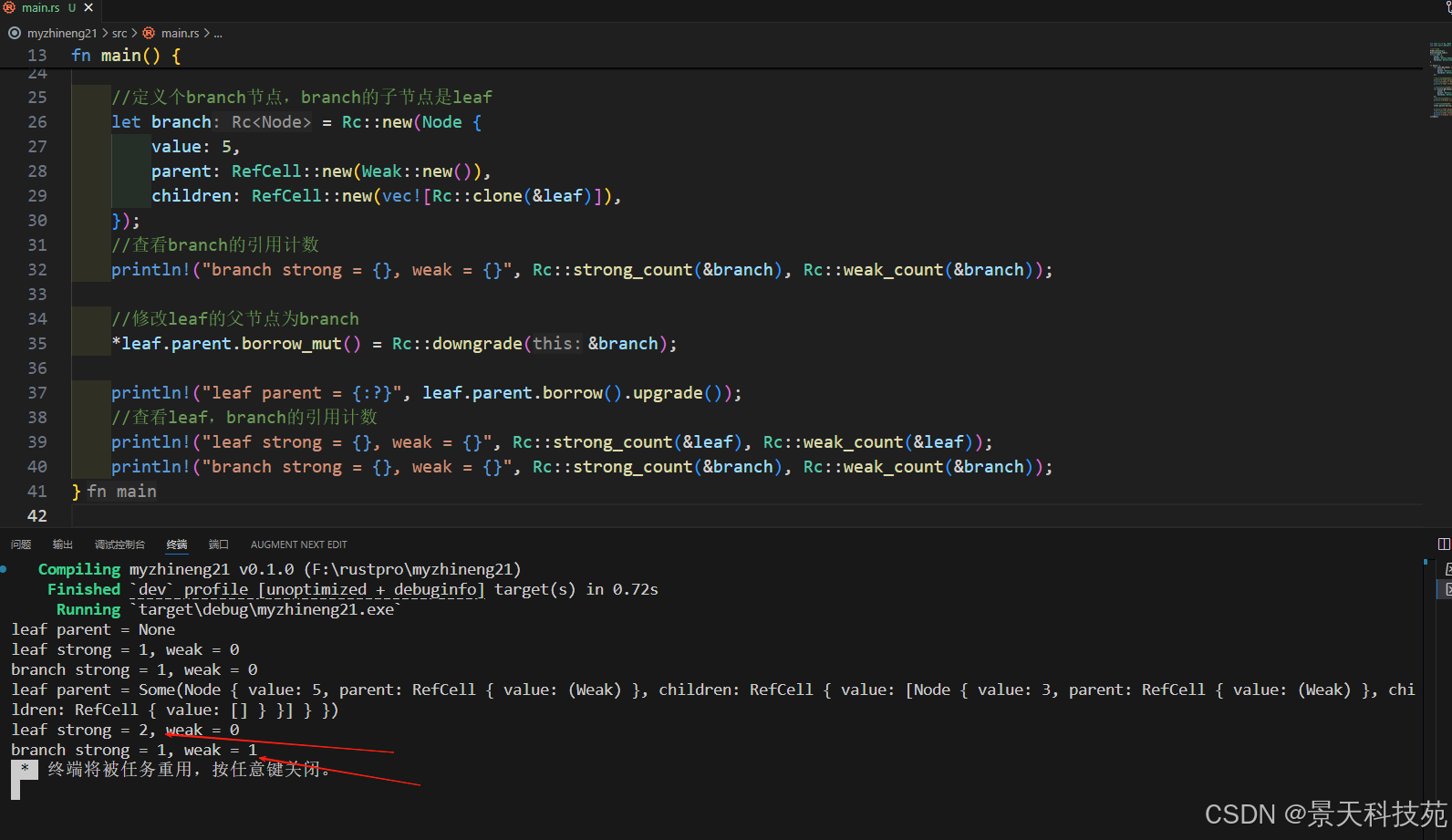
}fn main() {let leaf = Rc::new(Node {value: 3,parent: RefCell::new(Weak::new()), //我们目前不知道leaf的父节点是谁,所以先设置为Weak::new()children: RefCell::new(Vec::new()), //leaf目前没有子节点});//查看leaf的父节点,upgrade方法返回Option<Rc<Node>>println!("leaf parent = {:?}", leaf.parent.borrow().upgrade());//查看leaf的引用计数println!("leaf strong = {}, weak = {}", Rc::strong_count(&leaf), Rc::weak_count(&leaf));//定义个branch节点,branch的子节点是leaflet branch = Rc::new(Node {value: 5,parent: RefCell::new(Weak::new()),children: RefCell::new(vec![Rc::clone(&leaf)]),});//查看branch的引用计数println!("branch strong = {}, weak = {}", Rc::strong_count(&branch), Rc::weak_count(&branch));//修改leaf的父节点为branch*leaf.parent.borrow_mut() = Rc::downgrade(&branch);println!("leaf parent = {:?}", leaf.parent.borrow().upgrade());//查看leaf,branch的引用计数println!("leaf strong = {}, weak = {}", Rc::strong_count(&leaf), Rc::weak_count(&leaf));println!("branch strong = {}, weak = {}", Rc::strong_count(&branch), Rc::weak_count(&branch));
}
七、智能指针的性能考量
7.1 各种智能指针的性能特点
Box<T>:
分配/释放堆内存的开销
访问数据需要一次解引用
Rc<T>/Arc<T>:
额外的引用计数存储
Arc使用原子操作,比Rc更慢
克隆Rc/Arc比克隆数据本身更快
RefCell<T>:
运行时借用检查开销
内部使用unsafe代码,但对外提供安全接口
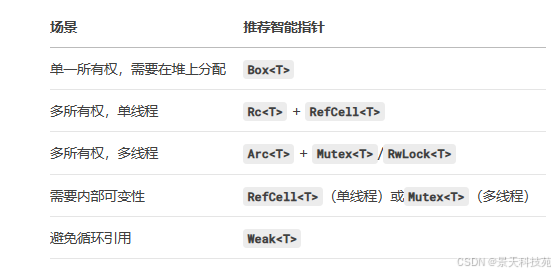
7.2 何时使用何种智能指针
八、智能指针组合使用
常见组合模式:
Rc<RefCell<T>> - 单线程多所有权可变数据
use std::rc::Rc;
use std::cell::RefCell;let shared_vec = Rc::new(RefCell::new(vec![1, 2, 3]));
let clone1 = Rc::clone(&shared_vec);
clone1.borrow_mut().push(4);
Arc<Mutex<T>> - 多线程多所有权可变数据
use std::sync::{Arc, Mutex};
use std::thread;let data = Arc::new(Mutex::new(0));
let mut handles = vec![];for _ in 0..10 {let data = Arc::clone(&data);let handle = thread::spawn(move || {let mut num = data.lock().unwrap();*num += 1;});handles.push(handle);
}
九、常见问题与解决方案
9.1 循环引用导致内存泄漏
问题:使用Rc和RefCell可能导致循环引用,从而造成内存泄漏。
解决方案:
使用Weak代替Rc作为父节点的引用
重新设计数据结构避免循环
使用Rc::downgrade创建弱引用
9.2 线程间共享数据的选择
问题:在多线程环境中如何选择合适的智能指针组合?
解决方案:
只读共享数据:Arc<T>(当T是Sync时)
可写共享数据:Arc<Mutex<T>>或Arc<RwLock<T>>
避免过度使用锁,考虑消息传递(如std::sync::mpsc)
9.3 性能优化技巧
避免不必要的Rc/Arc克隆
减少锁的持有时间
对于频繁读取、少量写入的场景,优先考虑RwLock而非Mutex
考虑使用Cow(Copy on Write)智能指针避免不必要的复制
十、总结
Rust的智能指针系统提供了强大而灵活的内存管理工具,每种智能指针都有其特定的用途和适用场景:
Box<T>:最简单的堆分配,用于已知大小的数据
Rc<T>/Arc<T>:共享所有权,分别用于单线程和多线程
RefCell<T>/Mutex<T>/RwLock<T>:内部可变性模式
Weak<T>:解决循环引用问题
通过合理组合这些智能指针,可以在保证内存安全的同时实现复杂的数据结构和并发模式。理解每种智能指针的语义和性能特点是编写高效、安全Rust代码的关键。
在实际开发中,建议:
优先考虑所有权和借用,只在必要时使用智能指针
从简单开始(如Box),根据需要逐步升级到更复杂的智能指针
多线程环境下始终使用线程安全的类型(Arc+Mutex/RwLock)
注意性能影响,特别是在热点代码路径中
通过本文的学习和实践,相信大家应该能够熟练运用Rust的各种智能指针来解决实际开发中的内存管理和数据共享问题。