第9.2讲、Tiny Decoder(带 Mask)详解与实战
自己搭建一个 Tiny Decoder(带 Mask),参考 Transformer Encoder 的结构,并添加 Masked Multi-Head Self-Attention,它是 Decoder 的核心特征之一。
1. 背景与动机
Transformer 架构已成为自然语言处理(NLP)领域的主流。其 Encoder-Decoder 结构广泛应用于机器翻译、文本生成等任务。Decoder 的核心特征是 Masked Multi-Head Self-Attention,它保证了自回归生成时不会"偷看"未来信息。本文将带你从零实现一个最小可运行的 Tiny Decoder,并深入理解其原理。
2. Tiny Decoder 架构简述
一个标准 Transformer Decoder Layer 包括:
- Masked Multi-Head Self-Attention
- Encoder-Decoder Attention(跨注意力)
- Feed Forward Network (FFN)
- LayerNorm + Residual Connection
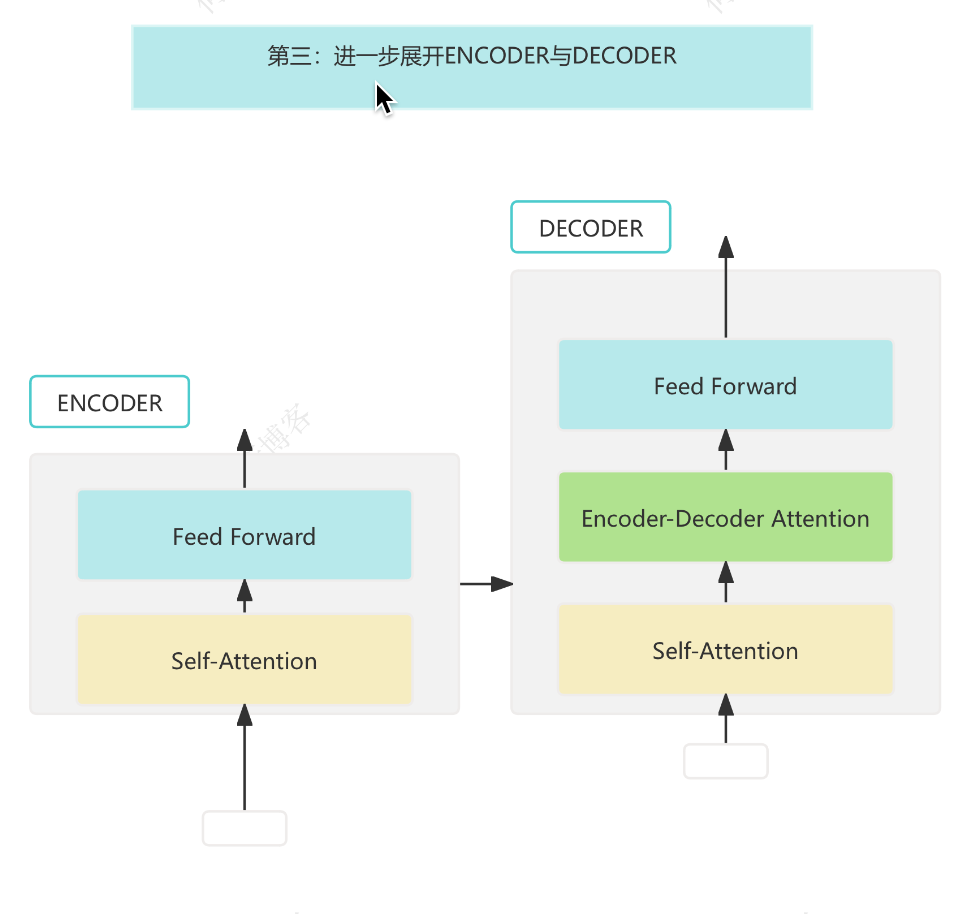
为了简化,我们暂时不引入 Encoder-Decoder Attention,只聚焦于:
Masked Self-Attention + FFN
3. 什么是 Masked Attention?
Masked Attention 的作用是在 Decoder 生成序列时,禁止看到"未来"的 token,防止信息泄露。
用一个 Mask 矩阵来实现,例如:
Mask for length 4:
[[0, -inf, -inf, -inf],[0, 0, -inf, -inf],[0, 0, 0, -inf],[0, 0, 0, 0]]
这个 Mask 会加在 Attention 的 logits 上(即 QKᵗ / sqrt(dk)),将不允许的位置置为 -inf,softmax 之后就是 0。
4. Tiny Decoder 核心代码(简化 PyTorch 实现)
import torch
import torch.nn as nn
import torch.nn.functional as F
import math# 带掩码的多头自注意力机制
class MaskedSelfAttention(nn.Module):def __init__(self, d_model, num_heads):super().__init__()assert d_model % num_heads == 0 # 保证可以均分到每个头self.d_model = d_modelself.num_heads = num_headsself.d_k = d_model // num_heads # 每个头的维度# 用一个线性层同时生成 Q、K、Vself.qkv_proj = nn.Linear(d_model, 3 * d_model)# 输出投影self.out_proj = nn.Linear(d_model, d_model)def forward(self, x):# x: (batch, seq_len, d_model)B, T, C = x.size()# 生成 Q、K、V,并分头qkv = self.qkv_proj(x).reshape(B, T, 3, self.num_heads, self.d_k).permute(2, 0, 3, 1, 4)q, k, v = qkv[0], qkv[1], qkv[2] # (B, heads, T, d_k)# 计算注意力分数 (QK^T / sqrt(d_k))attn_logits = (q @ k.transpose(-2, -1)) / math.sqrt(self.d_k) # (B, heads, T, T)# 构造下三角 Mask,防止看到未来信息mask = torch.tril(torch.ones(T, T)).to(x.device)attn_logits = attn_logits.masked_fill(mask == 0, float('-inf'))# softmax 得到注意力权重attn = F.softmax(attn_logits, dim=-1)# 加权求和得到输出out = attn @ v # (B, heads, T, d_k)# 合并多头out = out.transpose(1, 2).contiguous().reshape(B, T, C)# 输出投影return self.out_proj(out)# 前馈神经网络
class FeedForward(nn.Module):def __init__(self, d_model, d_ff):super().__init__()# 两层全连接+ReLUself.ff = nn.Sequential(nn.Linear(d_model, d_ff),nn.ReLU(),nn.Linear(d_ff, d_model))def forward(self, x):# 前馈变换return self.ff(x)# Tiny Decoder 层,包含 Masked Self-Attention 和前馈网络
class TinyDecoderLayer(nn.Module):def __init__(self, d_model=128, num_heads=4, d_ff=512):super().__init__()self.self_attn = MaskedSelfAttention(d_model, num_heads) # 掩码自注意力self.ff = FeedForward(d_model, d_ff) # 前馈网络self.norm1 = nn.LayerNorm(d_model) # 层归一化1self.norm2 = nn.LayerNorm(d_model) # 层归一化2def forward(self, x):# x: (batch, seq_len, d_model)# 先归一化,再做自注意力,并加残差x = x + self.self_attn(self.norm1(x))# 再归一化,前馈网络,并加残差x = x + self.ff(self.norm2(x))return x
5. 使用示例
x = torch.randn(2, 10, 128) # Decoder输入
context = torch.randn(2, 15, 128) # Encoder输出
decoder = TinyDecoderLayer()
y = decoder(x, context) # output shape: (2, 10, 128)
6. 进阶扩展
6.1 添加 Encoder-Decoder Attention
Encoder-Decoder Attention 允许 Decoder 在生成时参考 Encoder 的输出(即源语言信息),是机器翻译等任务的关键。其实现方式与 Self-Attention 类似,只是 Q 来自 Decoder,K/V 来自 Encoder。
伪代码:
class CrossAttention(nn.Module):def __init__(self, d_model, num_heads):# ...同 MaskedSelfAttention ...def forward(self, x, context):# x: (B, T_dec, d_model), context: (B, T_enc, d_model)# Q from x, K/V from context# ...实现...
在 Decoder Layer 中插入:
self.cross_attn = CrossAttention(d_model, num_heads)
# forward:
x = x + self.cross_attn(self.norm_cross(x), context)
6.2 多层 Decoder 堆叠
实际应用中,Decoder 通常由多层堆叠而成:
class TinyDecoder(nn.Module):def __init__(self, num_layers, d_model, num_heads, d_ff):super().__init__()self.layers = nn.ModuleList([TinyDecoderLayer(d_model, num_heads, d_ff) for _ in range(num_layers)])def forward(self, x):for layer in self.layers:x = layer(x)return x
6.3 加入 Positional Encoding
Transformer 不具备序列顺序感知能力,需加上 Positional Encoding:
class PositionalEncoding(nn.Module):def __init__(self, d_model, max_len=5000):super().__init__()pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2) * (-math.log(10000.0) / d_model))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)self.register_buffer('pe', pe)def forward(self, x):return x + self.pe[:x.size(1)]
7. 完整训练例子(伪代码)
# 假设有输入数据 input_seq, target_seq
x = embedding(input_seq)
x = pos_encoding(x)
decoder = TinyDecoder(num_layers=2, d_model=128, num_heads=4, d_ff=512)
output = decoder(x)
# 计算 loss, 反向传播
8. 小结
- Decoder 的关键是 Masked Self-Attention,通过
tril的下三角掩码防止泄漏未来信息。 - 可以用
torch.tril快速构造下三角 Mask。 - Decoder 层和 Encoder 类似,但注意力机制加了 Mask,而且通常会多出 Encoder-Decoder Attention。
- 可扩展为多层、加入位置编码、跨注意力等,逐步构建完整的 Transformer Decoder。
*如果不加 Mask,允许 Decoder 看到未来 token,会导致模型训练"作弊",推理时表现极差,生成文本质量低下,模型失去实际应用价值。因此,Masked Self-Attention 是保证自回归生成和模型泛化能力的关键机制。
9. 参考资料
- Attention is All You Need
- The Annotated Transformer
- PyTorch 官方文档