2156. 查找给定哈希值的子串
给定整数 p 和 m ,一个长度为 k 且下标从 0 开始的字符串 s 的哈希值按照如下函数计算:
hash(s, p, m) = (val(s[0]) * p0 + val(s[1]) * p1 + ... + val(s[k-1]) * pk-1) mod m.
其中 val(s[i]) 表示 s[i] 在字母表中的下标,从 val('a') = 1 到 val('z') = 26 。
给你一个字符串 s 和整数 power,modulo,k 和 hashValue 。请你返回 s 中 第一个 长度为 k 的 子串 sub ,满足 hash(sub, power, modulo) == hashValue 。
测试数据保证一定 存在 至少一个这样的子串。
子串 定义为一个字符串中连续非空字符组成的序列。
示例 1:
输入:s = "leetcode", power = 7, modulo = 20, k = 2, hashValue = 0
输出:"ee"
解释:"ee" 的哈希值为 hash("ee", 7, 20) = (5 * 1 + 5 * 7) mod 20 = 40 mod 20 = 0 。
"ee" 是长度为 2 的第一个哈希值为 0 的子串,所以我们返回 "ee" 。
示例 2:
输入:s = "fbxzaad", power = 31, modulo = 100, k = 3, hashValue = 32
输出:"fbx"
解释:"fbx" 的哈希值为 hash("fbx", 31, 100) = (6 * 1 + 2 * 31 + 24 * 312) mod 100 = 23132 mod 100 = 32 。
"bxz" 的哈希值为 hash("bxz", 31, 100) = (2 * 1 + 24 * 31 + 26 * 312) mod 100 = 25732 mod 100 = 32 。
"fbx" 是长度为 3 的第一个哈希值为 32 的子串,所以我们返回 "fbx" 。
注意,"bxz" 的哈希值也为 32 ,但是它在字符串中比 "fbx" 更晚出现。
提示:
1 <= k <= s.length <= 2 * 1041 <= power, modulo <= 1090 <= hashValue < modulos只包含小写英文字母。- 测试数据保证一定 存在 满足条件的子串。
方法一:暴力二重循环
class Solution {
public:string subStrHash(string s, int power, int modulo, int k, int hashValue) {int len = s.size();long long * arr=new long long[len];for(int i=0;i<len;i++)arr[i]=getid(s[i]);bool f=0;int left = 0;int right = 0;vector<long long> pows(len);pows[0] = 1;for (int i = 1; i < len; ++i) {pows[i] = (pows[i - 1] * power) % modulo;
}for(int i=0;i<len;i++){long long sum = 0;for(int j=i;j<len;j++){sum=sum + pows[j - i] * arr[j];if((sum%modulo)==hashValue&&j - i + 1 ==k){f=1;left = i;right = j;break;}}if(f==1){break;}}string ans = s.substr(left , right - left +1);return ans;}int getid(char c){return c - 'a'+1;}
};
解决问题,但是效果不佳,实际做题过程肯定会超时
方法二:滑动窗口
class Solution {
public:string subStrHash(string s, int power, int modulo, int k, int hashValue) {int len = s.size();vector<long long> arr(len), pows(len);// Step 1: 字符映射成数字for (int i = 0; i < len; ++i)arr[i] = getid(s[i]);// Step 2: 预处理幂次pows[0] = 1;for (int i = 1; i < len; ++i)pows[i] = (pows[i - 1] * power) % modulo;// Step 3: 初始化最后一个窗口的哈希值(从右往左)long long sum = 0;for (int i = len - k; i < len; ++i) {int exponent = i - (len - k); // 当前字符相对于窗口起始位置的幂次sum = (sum + arr[i] * pows[exponent]) % modulo;}int res = len - k; // 初始窗口位置if (sum == hashValue)res = len - k;// Step 4: 向左滑动窗口for (int i = len - k - 1; i >= 0; --i) {// 移除最右边字符的影响sum = (sum - arr[i + k] * pows[k - 1] % modulo + modulo) % modulo;// 左移一位(乘 power)sum = (sum * power) % modulo;// 添加新字符(最左边)sum = (sum + arr[i]) % modulo;if (sum == hashValue)res = i;}return s.substr(res, k);}int getid(char c) { return c - 'a' + 1; }
};
11ms,感觉还行
滑动窗口记得要从右往左滑动,不然从左往右滑动,sum减去第k个字符的哈希值,还需要为每个位上的数字做降幂操作,但是由于预处理次幂把真实的幂对modulo做模运算,得到的都是余数,不能直接做除法,但是从右往左可以直接做乘法。
方法三:极致优化
参考文章:https://leetcode.cn/problems/powx-n/solutions/2858114/tu-jie-yi-zhang-tu-miao-dong-kuai-su-mi-ykp3i/
class Solution {
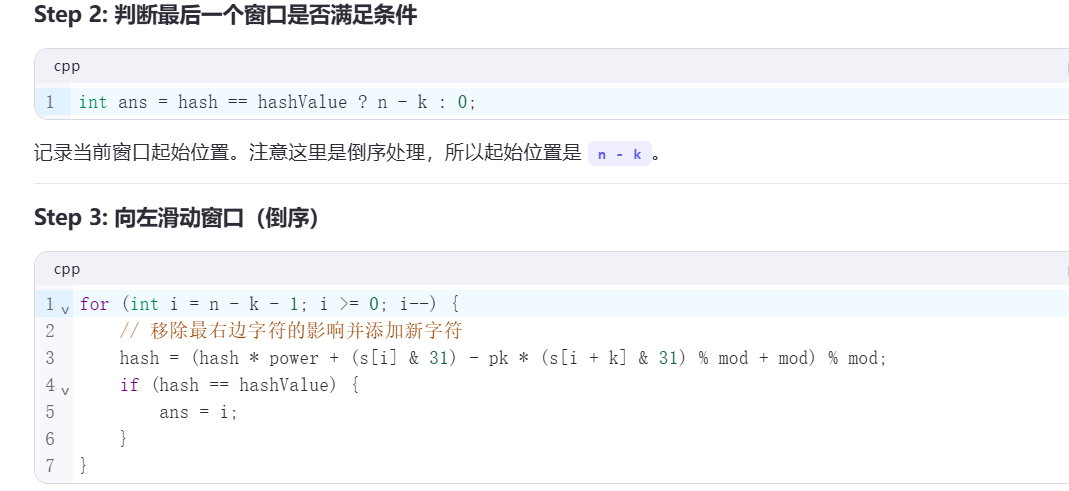
public:string subStrHash(string s, int power, int mod, int k, int hashValue) {int n = s.length();// 用秦九韶算法计算 s[n-k:] 的哈希值,同时计算 pk=power^klong long hash = 0, pk = 1;for (int i = n - 1; i >= n - k; i--) {hash = (hash * power + (s[i] & 31)) % mod;pk = pk * power % mod;}int ans = hash == hashValue ? n - k : 0;// 向左滑窗for (int i = n - k - 1; i >= 0; i--) {// 计算新的哈希值,注意 +mod 防止计算出负数hash = (hash * power + (s[i] & 31) - pk * (s[i + k] & 31) % mod + mod) % mod;if (hash == hashValue) {ans = i;}}return s.substr(ans, k);}
};作者:灵茶山艾府
链接:https://leetcode.cn/problems/find-substring-with-given-hash-value/solutions/1239542/dao-xu-hua-dong-chuang-kou-o1-kong-jian-xpgkp/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
- 从字符串最右边开始,取最后
k个字符作为初始窗口。 (s[i] & 31)是一个小技巧,用于快速将'a'-'z'映射成1~26。'a'的 ASCII 是97,二进制是01100001,与31(00011111) 做按位与操作得到1
- 使用 秦九韶算法(Horner's Rule) 计算哈希值:
hash=(((a⋅p+b)⋅p+c)⋅p+d)
这样就避免了直接计算 a*p^0 + b*p^1 + c*p^2 + d*p^3,而是通过乘法不断“推进”幂次。
- 同时计算
pk = power^k % mod,用于后续滑动窗口更新。