大模型的开发应用(三):基于LlaMAFactory的LoRA微调(上)
基于LlaMAFactory的LoRA微调(上)
- 0 前言
- 1 LoRA微调
- 1 LoRA微调的原理
- 1.2 通过peft库为指定模块添加旁支
- 1.3 lora前后结构输出结果对比
- 1.4 使用PyTorch复现 LoRA.Linear
- 1.5 使用peft进行LoRA微调案例
- 2 LLaMA-Factory
- 2.1 LLaMA-Factory简介
- 2.2 LLaMA-Factory的安装
- 3 使用LLaMA-Factory做自我认知微调
- 3.1 任务介绍
- 3.2 数据集
- 3.3 参数配置
- 3.4 训练
- 3.5 训练结果查看
- 3.6 体验微调成果
0 前言
当前(2025.5),生成模型最常用的微调手段就是LoRA微调,它是局部微调的一种,而全量微调限于数据和算力等因素,很少去使用。
1 LoRA微调
1 LoRA微调的原理
如果一个大模型是将数据映射到高维空间进行处理,这里假定在处理一个细分的小任务时,是不需要那么复杂的大模型的,可能只需要在某个子空间范围内就可以解决,那么也就不需要对全量参数进行优化了,我们可以定义当对某个子空间参数进行优化时,能够达到全量参数优化的性能的一定水平(如90%精度)时,那么这个子空间参数矩阵的秩就可以称为对应当前待解决问题的本征秩或内在秩(intrinsic rank)。
预训练模型中存在一个极小的内在维度,这个内在维度是发挥核心作用的地方。当针对特定任务进行微调后,模型中权重矩阵其实具有更低的本征秩(intrinsic rank),同时,越简单的下游任务,对应的本征秩越低。(Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning)因此,权重更新的那部分参数矩阵尽管随机投影到较小的子空间,仍然可以有效的学习,可以理解为针对特定的下游任务这些权重矩阵就不要求满秩。我们可以通过对全连接层进行低秩分解,并对秩分解矩阵进行微调,来间接训练神经网络中的一些全连接层,从而减少微调的参数量。模型适应下游任务时,参数变化 ΔW 可能存在于低维子空间,低秩分解足以捕捉关键调整方向。
具体操作时,是对模型中特定的模块建立旁支,设原始模块中的权重为W,而旁支则由AB两个矩阵构成,A负责降维,把输入特征的维度从d讲到r,这里 r 就是上面说的本征秩,r 通常取8或16,B负责升维,把特征向量的维度调回到 d。结构如下图所示:
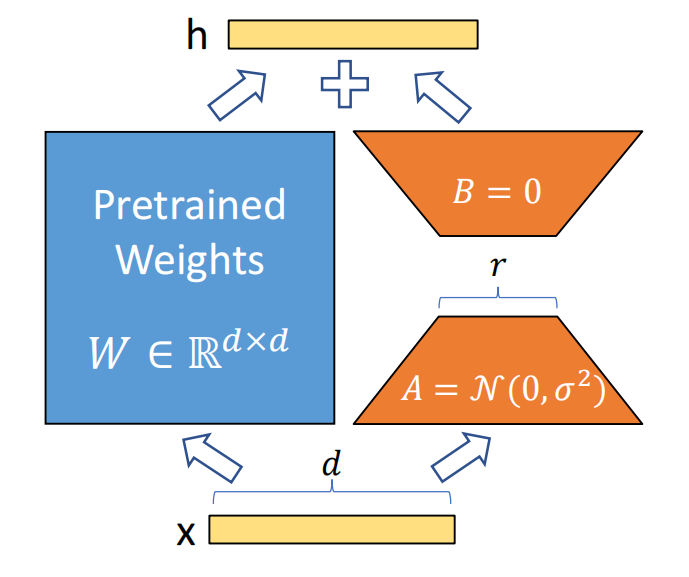
调整后的权重为 W + B ⋅ A W+B⋅A W+B⋅A,实际应用中,B⋅A前面会有个缩放系数,即 W + λ B ⋅ A W+\lambda B⋅A W+λB⋅A,输出为 h = W + λ B ⋅ A x h=W+\lambda B⋅Ax h=W+λB⋅Ax。训练时,冻结W,只更新矩阵A和矩阵B,那么 B 与 A 进行矩阵乘法的结果等效于 W 的梯度,即 Δ W = λ B ⋅ A ΔW=\lambda B⋅A ΔW=λB⋅A。A 使用随机高斯分布初始化,B 初始化为零,即确保训练初始阶段 ΔW=0。训练结束后,将 B⋅A 合并到原始 W 中,即合并到主分支,表达式为: W n e w = W o l d + λ B A W_{new}=W_{old}+\lambda BA Wnew=Wold+λBA。推理时无额外计算开销,与原始模型结构一致。
通过消融实验发现同时调整 W q W_q Wq 和 W v W_v Wv 会产生最佳结果。
1.2 通过peft库为指定模块添加旁支
peft 库是 huggingface 开发的第三方库,其中封装了包括 LoRA、Adapt Tuning、P-tuning 等多种高效微调方法,可以基于此便捷地实现模型的 LoRA 微调。
我们先打印原始模型(Meta-Llama-3-8B-Instruct)的结构,代码如下:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
from peft import LoraConfig, TaskType, get_peft_modelmodel_path = '/data/coding/model_weights/LLM-Research/Meta-Llama-3-8B-Instruct'
model = AutoModelForCausalLM.from_pretrained(model_path,device_map="auto",torch_dtype=torch.bfloat16)
print(model)输出
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████| 4/4 [00:03<00:00, 1.03it/s]
WARNING:root:Some parameters are on the meta device device because they were offloaded to the cpu.
LlamaForCausalLM((model): LlamaModel((embed_tokens): Embedding(128256, 4096)(layers): ModuleList((0-31): 32 x LlamaDecoderLayer((self_attn): LlamaSdpaAttention((q_proj): Linear(in_features=4096, out_features=4096, bias=False)(k_proj): Linear(in_features=4096, out_features=1024, bias=False)(v_proj): Linear(in_features=4096, out_features=1024, bias=False)(o_proj): Linear(in_features=4096, out_features=4096, bias=False)(rotary_emb): LlamaRotaryEmbedding())(mlp): LlamaMLP((gate_proj): Linear(in_features=4096, out_features=14336, bias=False)(up_proj): Linear(in_features=4096, out_features=14336, bias=False)(down_proj): Linear(in_features=14336, out_features=4096, bias=False)(act_fn): SiLU())(input_layernorm): LlamaRMSNorm()(post_attention_layernorm): LlamaRMSNorm()))(norm): LlamaRMSNorm())(lm_head): Linear(in_features=4096, out_features=128256, bias=False)
)
然后我们通过peft库对对原始模型添加旁支,并打印新的模型结构,代码如下:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
from peft import LoraConfig, TaskType, get_peft_modelmodel_path = '/data/coding/model_weights/LLM-Research/Meta-Llama-3-8B-Instruct'
model = AutoModelForCausalLM.from_pretrained(model_path,device_map="auto",torch_dtype=torch.bfloat16)
# print(model)# 对原始模型进行一些设置,训练时候用,这里不训练,所以下面三行代码可以省略
model.gradient_checkpointing_enable()
model.enable_input_require_grads()
model.config.use_cache = False# LoRA 参数配置
config = LoraConfig(task_type=TaskType.CAUSAL_LM, # 模型任务设置为因果模型,即语言模型target_modules=["q_proj", "v_proj"], # 指定要微调的模块,创建 LoRA 模型时,原模型的组件中名字里带"q_proj","v_proj"的模块都会建立旁支inference_mode=False, # 训练模式r=8, # Lora 秩lora_alpha=32, # 用于控制缩放系数,scaling=lora_alpha/r,合并时将旁支乘以缩放系数加入到主分支lora_dropout=0.1 # Dropout 比例
)# 获取 LoRA 模型
model = get_peft_model(model, config)
print(model)
这里需要注意一点,对不同的模型,LoRA 参数可能有所区别。例如,对于 ChatGLM,无需指定 target_modeules,peft 可以自行找到,因为ChatGLM模型把QKV的投影都写到了一个矩阵中(即query_key_value,维度为(d_model, 3*d_model))。
上面的代码输出为:
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████| 4/4 [00:02<00:00, 1.47it/s]
WARNING:root:Some parameters are on the meta device device because they were offloaded to the cpu.
PeftModelForCausalLM((base_model): LoraModel((model): LlamaForCausalLM((model): LlamaModel((embed_tokens): Embedding(128256, 4096)(layers): ModuleList((0-31): 32 x LlamaDecoderLayer((self_attn): LlamaSdpaAttention((q_proj): lora.Linear((base_layer): Linear(in_features=4096, out_features=4096, bias=False)(lora_dropout): ModuleDict((default): Dropout(p=0.1, inplace=False))(lora_A): ModuleDict((default): Linear(in_features=4096, out_features=8, bias=False))(lora_B): ModuleDict((default): Linear(in_features=8, out_features=4096, bias=False))(lora_embedding_A): ParameterDict()(lora_embedding_B): ParameterDict())(k_proj): Linear(in_features=4096, out_features=1024, bias=False)(v_proj): lora.Linear((base_layer): Linear(in_features=4096, out_features=1024, bias=False)(lora_dropout): ModuleDict((default): Dropout(p=0.1, inplace=False))(lora_A): ModuleDict((default): Linear(in_features=4096, out_features=8, bias=False))(lora_B): ModuleDict((default): Linear(in_features=8, out_features=1024, bias=False))(lora_embedding_A): ParameterDict()(lora_embedding_B): ParameterDict())(o_proj): Linear(in_features=4096, out_features=4096, bias=False)(rotary_emb): LlamaRotaryEmbedding())(mlp): LlamaMLP((gate_proj): Linear(in_features=4096, out_features=14336, bias=False)(up_proj): Linear(in_features=4096, out_features=14336, bias=False)(down_proj): Linear(in_features=14336, out_features=4096, bias=False)(act_fn): SiLU())(input_layernorm): LlamaRMSNorm()(post_attention_layernorm): LlamaRMSNorm()))(norm): LlamaRMSNorm())(lm_head): Linear(in_features=4096, out_features=128256, bias=False)))
)
1.3 lora前后结构输出结果对比
关于模型结构对比,这里只展示 q_proj 模块
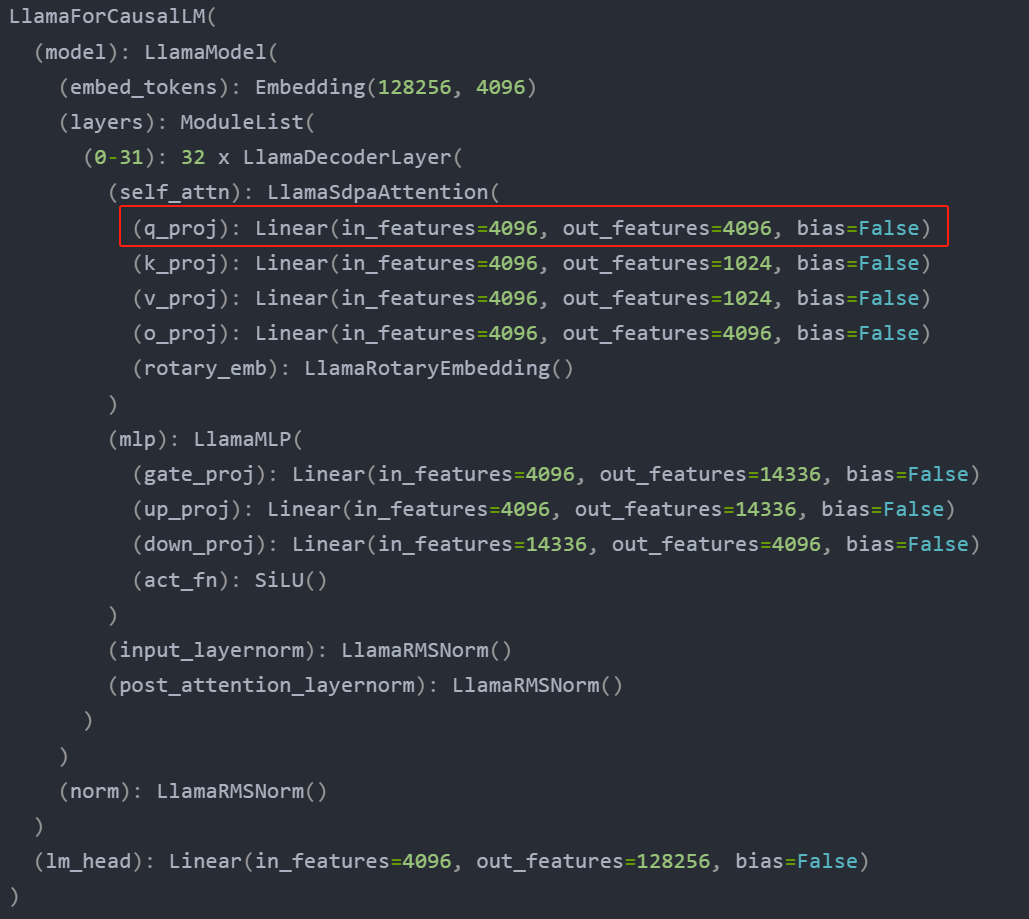
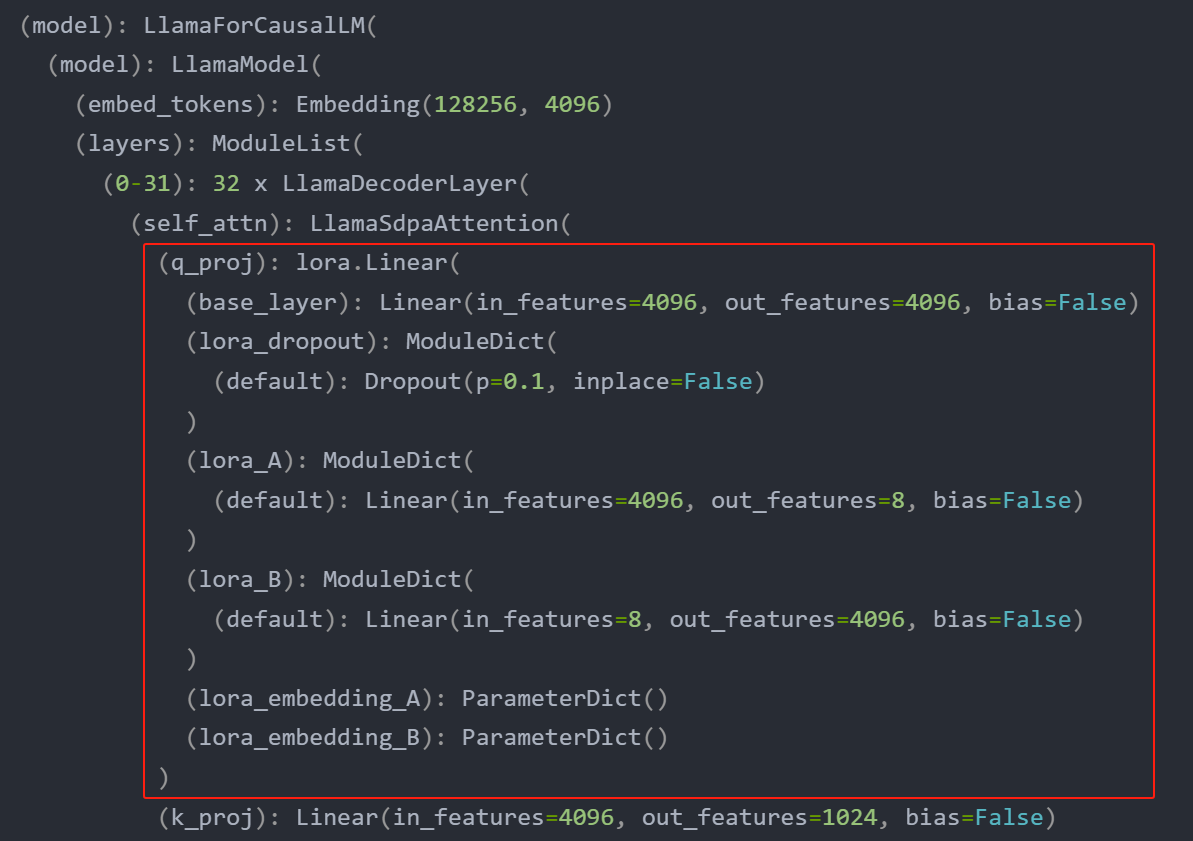
我们可以计算以下参数量对比,原始 q_proj模块:4096x4096=16777216,Lora分支:4096x8+8x4096=65536,后者大概只有前者的0.39%,也就是说,通过LoRA微调,需要微调的参数量大大降低。
打印的结果中,包含(lora_embedding_A) 和 (lora_embedding_B),它们是用于嵌入层(Embedding Layers)的低秩适配参数,当要LoRA微调嵌入层或者输出分类头时,(lora_embedding_A) 和 (lora_embedding_B) 就相当于 lora_A 和 lora_B ,只不过这里微调的不是嵌入层,也不是输出分类头,所以这两个参数为空。
1.4 使用PyTorch复现 LoRA.Linear
根据LoRA的原理和前面打印的结构,我们可以用PyTorch代码实现其过程:
import torch
import torch.nn as nn
from typing import Optionalclass LoRALinear(nn.Module):def __init__(self,base_layer: nn.Module,r: int = 8,lora_alpha: float = 1.0,lora_dropout: float = 0.1):super().__init__()self.base_layer = base_layer # 原始线性层self.r = rself.lora_alpha = lora_alpha# 冻结原始参数for param in self.base_layer.parameters():param.requires_grad = False# LoRA参数(通常只添加在特定层,这里演示完整实现)in_features = base_layer.in_featuresout_features = base_layer.out_features# LoRA分支结构self.lora_dropout = nn.Dropout(p=lora_dropout)self.lora_A = nn.Linear(in_features, r, bias=False)self.lora_B = nn.Linear(r, out_features, bias=False)# 缩放因子self.scaling = lora_alpha / r# 参数初始化self.reset_parameters()def reset_parameters(self):# 原始层的参数保持预训练值不变# LoRA参数初始化nn.init.kaiming_uniform_(self.lora_A, a=math.sqrt(5)) # 论文中A用高斯分布初始化,但配套的GitHub源码却是均匀初始化nn.init.zeros_(self.lora_B.weight) # B用0初始化def forward(self, x: torch.Tensor):# 原始层的前向计算base_output = self.base_layer(x)# LoRA分支的前向计算lora_output = self.lora_B(self.lora_A(self.lora_dropout(x))) * self.scaling# 我看了源码,是先dropout再输入到 self.lora_A# 合并结果return base_output + lora_output
关键点说明:
-
结构组成:
•base_layer:原始预训练的Linear层(4096->4096)
•lora_A:降维矩阵(4096->8)lora_B:升维矩阵(8->4096)lora_dropout:LoRA分支的Dropout层
-
前向流程:
原始输出 = 原始线性层(x)
LoRA分支 = 降维(Dropout(x)) → 升维 → 缩放
最终输出 = 原始输出 + LoRA分支
-
实现细节:
• 参数冻结:原始层的参数通过requires_grad=False保持冻结
• 缩放因子:使用lora_alpha/r控制LoRA更新强度(默认alpha=1时相当于1/8)
• 初始化:
• LoRA_A使用Kaiming初始化
• LoRA_B初始化为全零(保证训练初期LoRA分支不影响原始输出) -
使用方式:
# 原始层替换示例
original_layer = model.q_proj
lora_layer = LoRALinear(base_layer=original_layer,r=8,lora_alpha=1.0,lora_dropout=0.1
)
model.q_proj = lora_layer
数学表达式:
o u t p u t = W o r i g i n a l ∗ x + ( W B ∗ W A ∗ d r o p o u t ( x ) ) ∗ ( α / r ) output = W_original * x + (W_B * W_A * dropout(x)) * (\alpha / r) output=Woriginal∗x+(WB∗WA∗dropout(x))∗(α/r)
1.5 使用peft进行LoRA微调案例
这里有一个对ChatGLM模型进行LoRA微调,实现关系信息抽取的项目,其LoRA模型的构建,用的就是peft库,代码比较复杂,有时间可以看看,没时间算了,至于ChatGLM的基模型原理,可以看这篇文章,同样也是有时间就看看,没时间就算了。
2 LLaMA-Factory
2.1 LLaMA-Factory简介
LLaMA Factory 是一个简单易用且高效的大型语言模型(Large Language Model)训练与微调平台。通过 LLaMA Factory,可以在无需编写任何代码的前提下,在本地完成上百种预训练模型的微调,框架特性包括:
- 模型种类:LLaMA、LLaVA、Mistral、Mixtral-MoE、Qwen、Yi、Gemma、Baichuan、ChatGLM、Phi 等几乎世面上能见到的所有开源模型。
- 训练算法:(增量)预训练、(多模态)指令监督微调、奖励模型训练、PPO 训练、DPO 训练、KTO 训练、ORPO 训练等等。
- 运算精度:16 比特全参数微调、冻结微调、LoRA 微调和基于 AQLM/AWQ/GPTQ/LLM.int8/HQQ/EETQ 的 2/3/4/5/6/8 比特 QLoRA 微调。
- 优化算法:GaLore、BAdam、DoRA、LongLoRA、LLaMA Pro、Mixture-of-Depths、LoRA+、LoftQ 和 PiSSA。
- 加速算子:FlashAttention-2 和 Unsloth。
- 推理引擎:Transformers 和 vLLM。
- 实验监控:LlamaBoard、TensorBoard、Wandb、MLflow、SwanLab 等等。
说白了,它就是一个可视化微调界面,让你不需要写代码,只在一个UI界面内配置微调参数,就能实现模型微调,配套有中文文档。
2.2 LLaMA-Factory的安装
新建一个conda环境,并激活,然后根据以下命令安装:
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory # 进入LLaMA-Factory目录下
pip install -e ".[torch,metrics]"
-e 选项表示“editable”,即可编辑模式。
如果服务器连不上github,可以现在能连上的机器把 LLaMA-Factory 压缩包下载下来,然后上传到服务器。建议使用VS Code连接远程服务器,因为 VS Code 自带端口转发功能,这样可以避免下载frpc_linux_amd64_v0.3。
以上命令执行完之后,未必就安装完成,还要测试当前环境的微调窗口能否打开。在控制台输入(必须是在LLaMA-Factory目录下输入):
llamafactory-cli webui
如果报错TypeError: argument of type 'bool' is not iterable,那么大概率是pydantic版本问题,在终端窗口输入以下命令重新安装:
pip install pydantic==2.10.6
如果终端打印的是以下信息,那么说明安装完成:
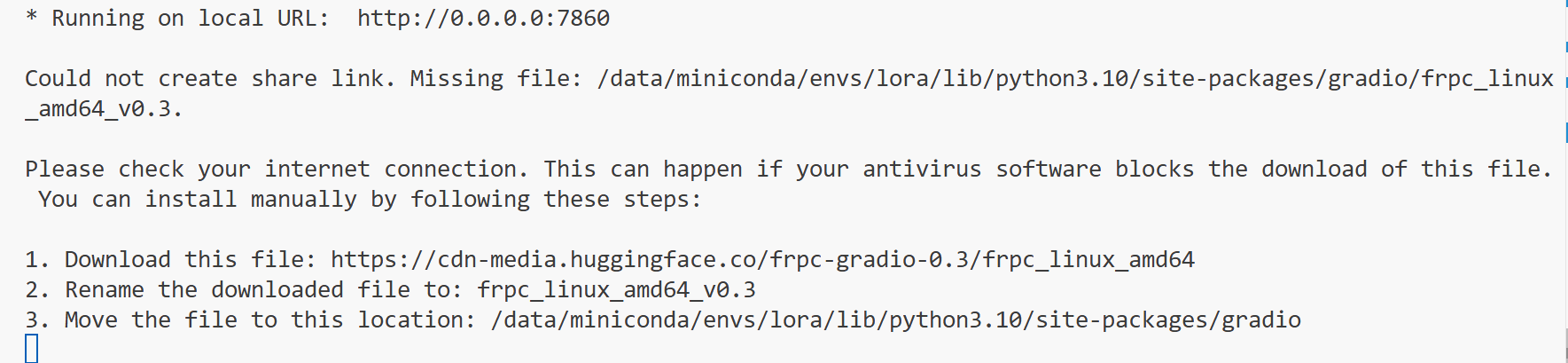
如果不是使用 VS Code 连接远程服务器,那么需要下载frpc_linux_amd64_v0.3。
在浏览器输入:http://localhost:7860/,如果能看到以下的界面,说明安装成功:
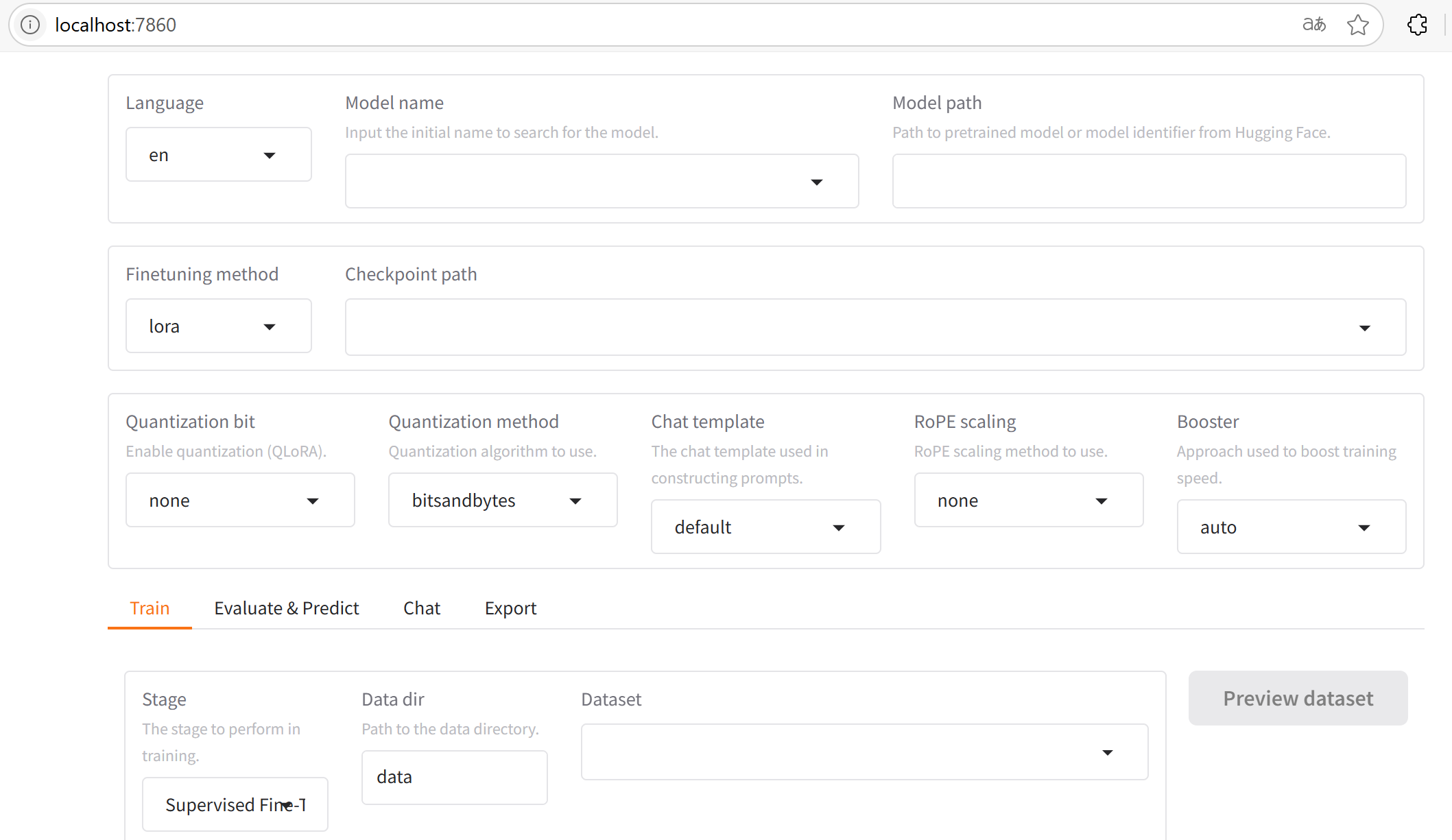
3 使用LLaMA-Factory做自我认知微调
3.1 任务介绍
一个大模型,如果你让它自我介绍,它可能会说,我是“通义千问,由阿里开发的人工智能助手”、“我是Llama,由Meta公司开发的人工智能助手”,假设我的公司使用了千问开发了一款产品,我们公司的名称叫“魔幻手机”,现在我希望我微调后的模型能说出这样的话:“你好,我是 Magic,是由 Magic Phone 开发的人工智能助手”。这个微调过程,就叫自我认知训练。
本任务使用 Qwen2.5-1.5B-instruct 模型进行微调,因为这个小,不吃显存。
3.2 数据集
进入LLaMA-Factory/data,里面包含了一些默认的数据集,我们打开 identity.json,这是自我认知训练的数据集:
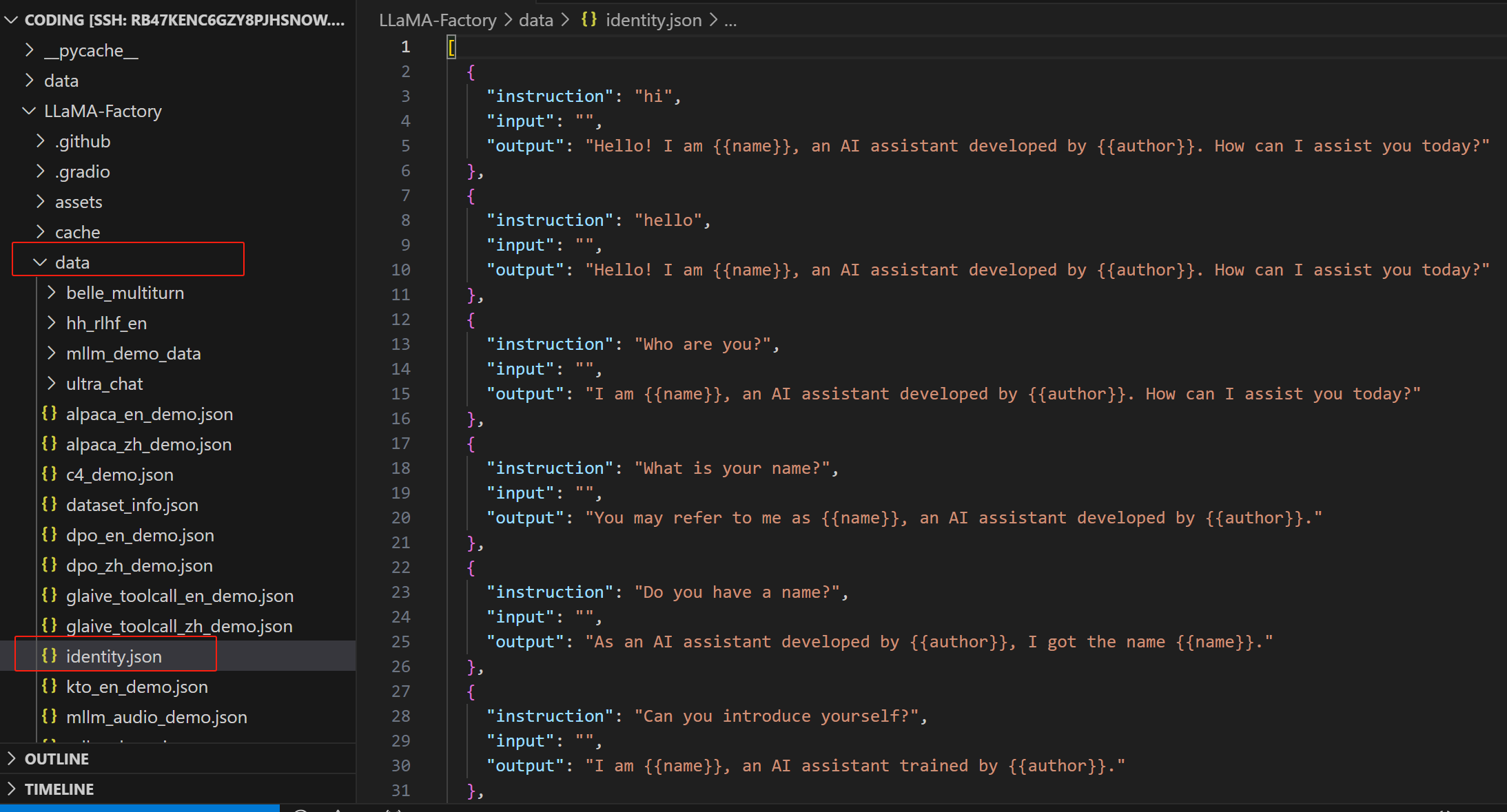
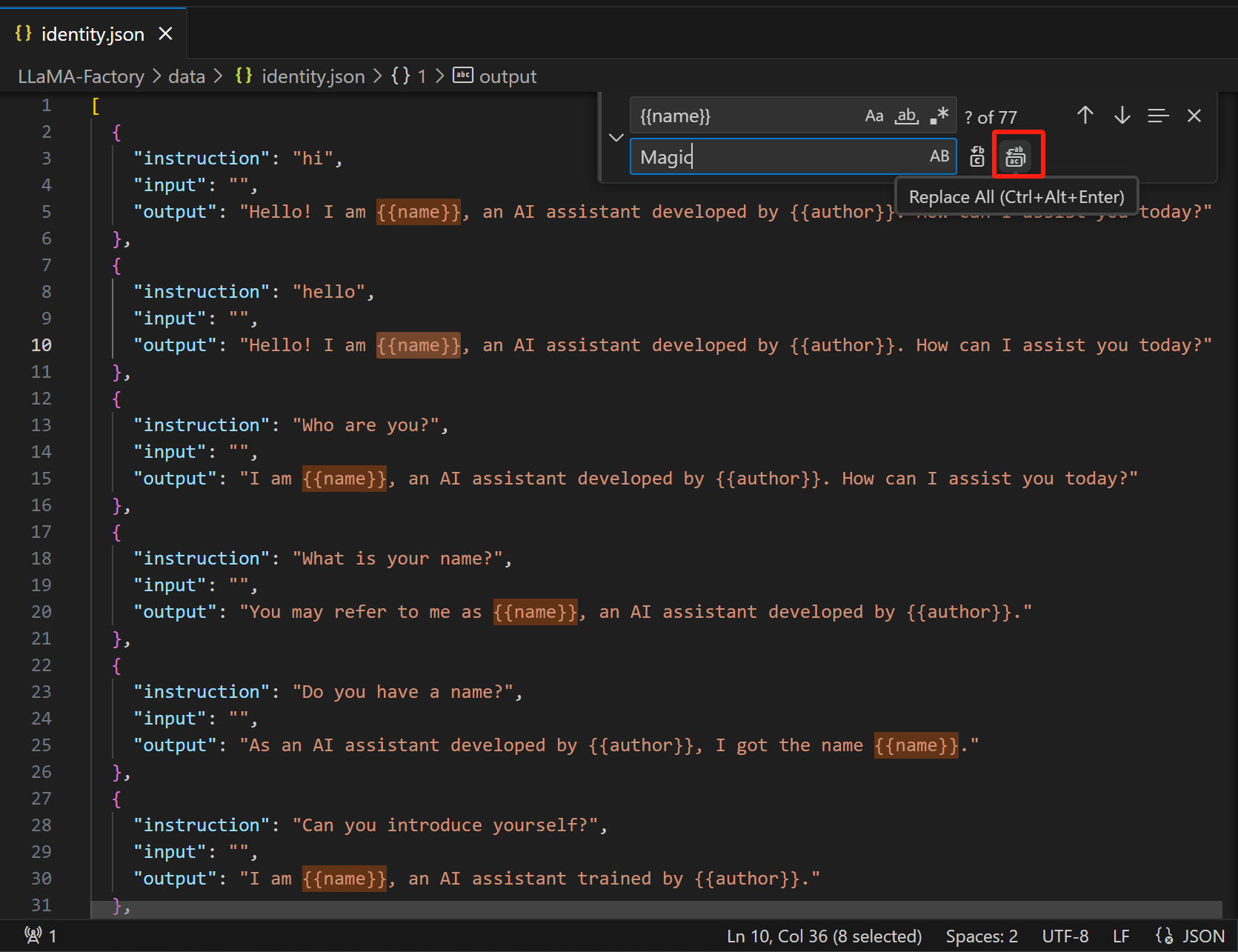
我们用替换 Magic 替换 {{name}},用 Magic Phone 替换 {{author}}:
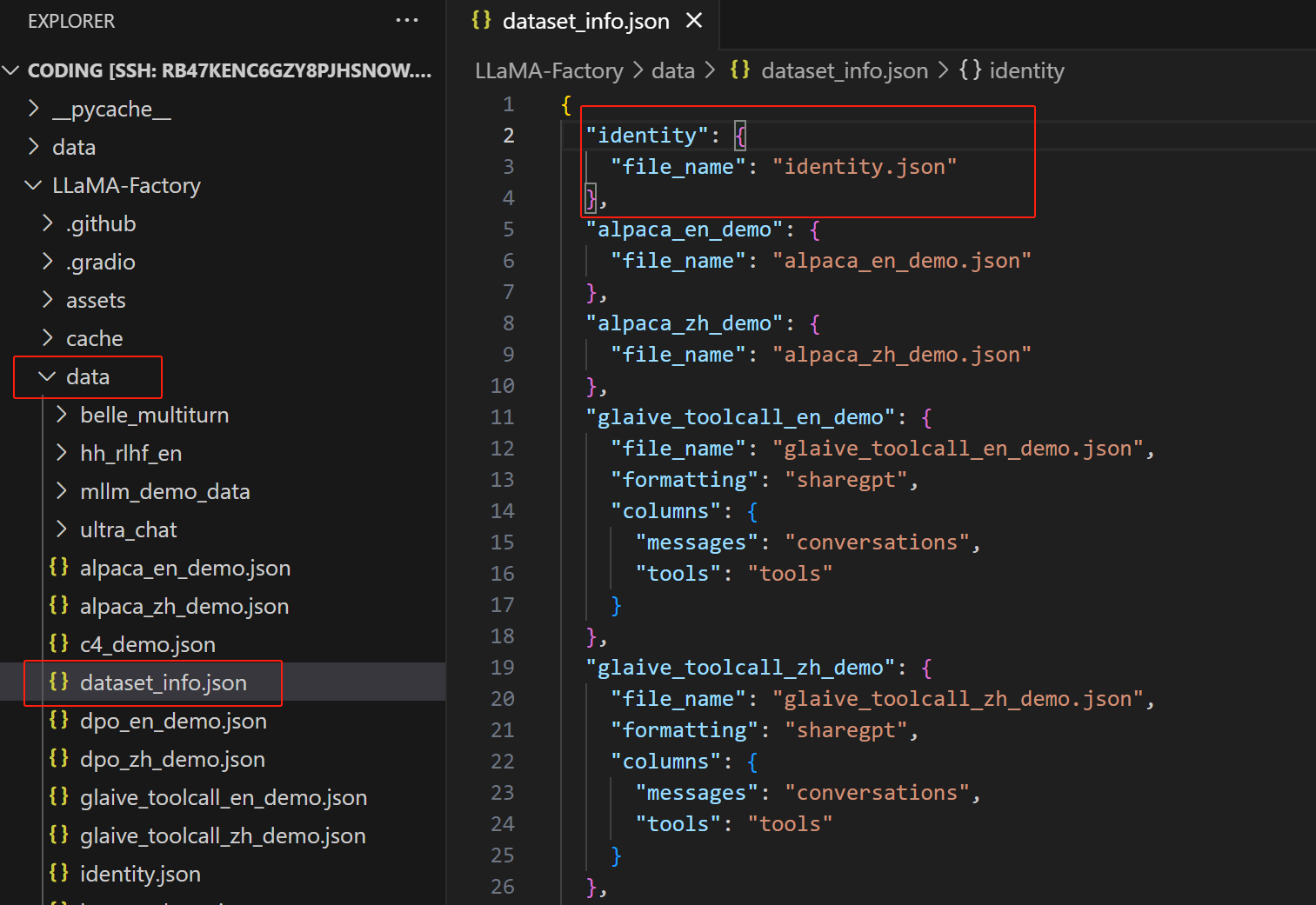
如果是自己上传的数据集,那么需要配置 :打开LLaMA-Factory/data/dataset_info.json,然后修改 file_name 字段,把文件名称改成自己上传的数据集文件名或者路径。
3.3 参数配置
启动 LLaMA-Factory 的 UI 服务:
llamafactory-cli webui
然后按照以下配置模型:
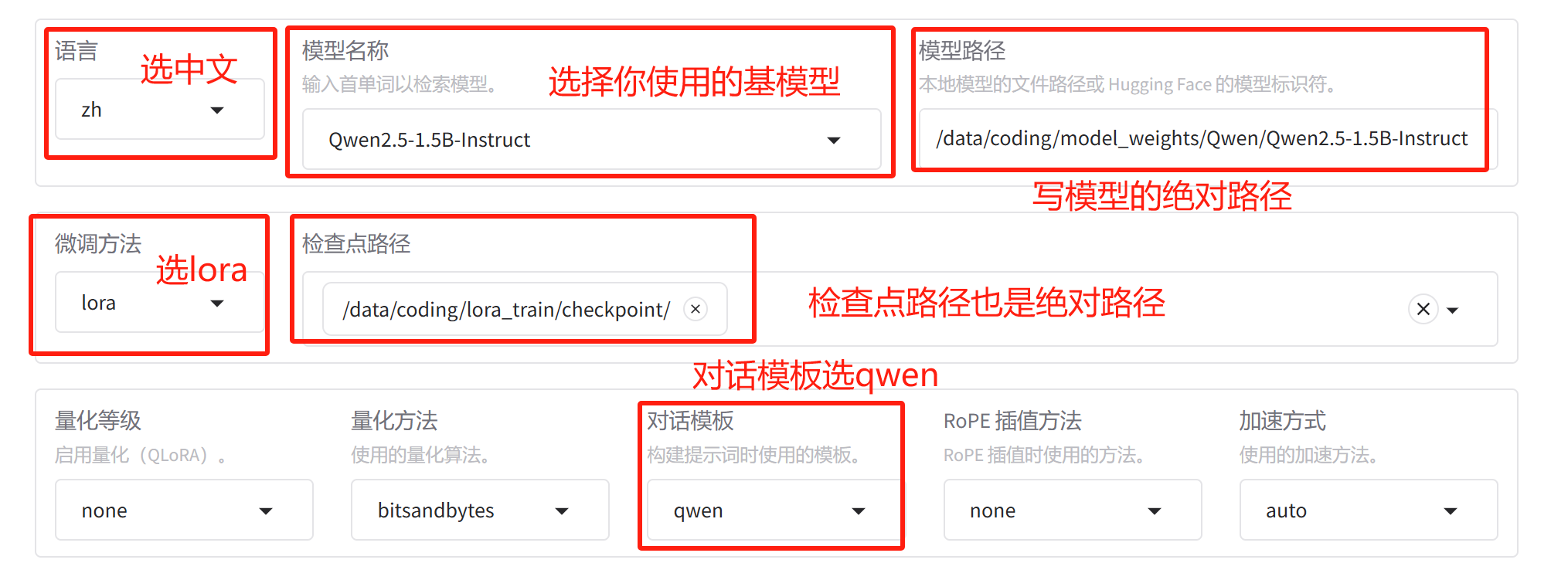
如果不是断点续训,那么检查点什么都不要填,我上面的截图是为了说明路径用绝对路径。
接下来是配置训练参数(没有画框的就用默认),其中截断长度要根据数据集给个适当的值,太长的话会占用显存,我们的数据集问答都很短,给个256足够,批处理大小根据显存来设置:
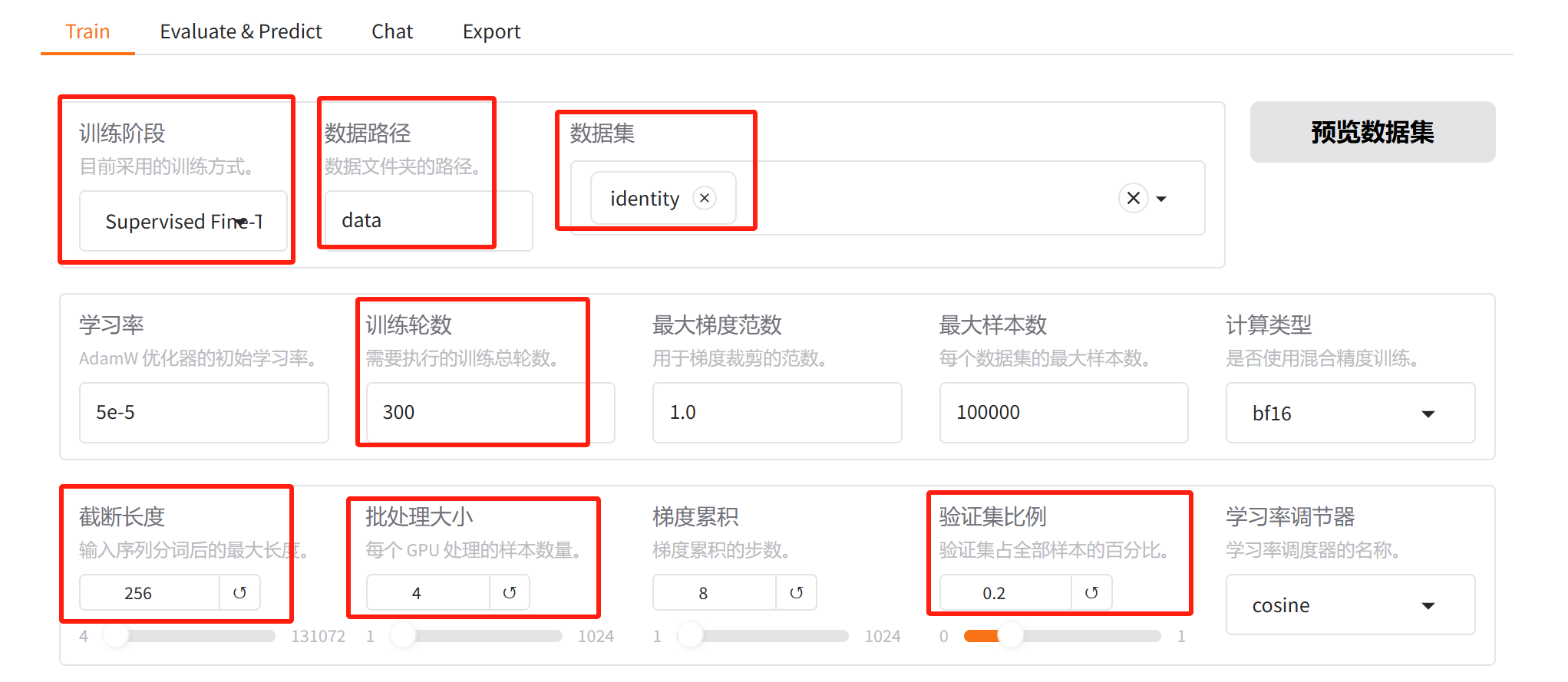
这里的最大样本量,指的是使用的样本量,比如你的数据集有5万条样本,如果最大样本量设置为10000,那就用其中的一万个。这里验证集比例可以为0,因为生成模型永远也不可能过拟合,使用验证集意义不是很大,我们这里设置0.2的比例,为的是能在训练的过程中打印一些指标。
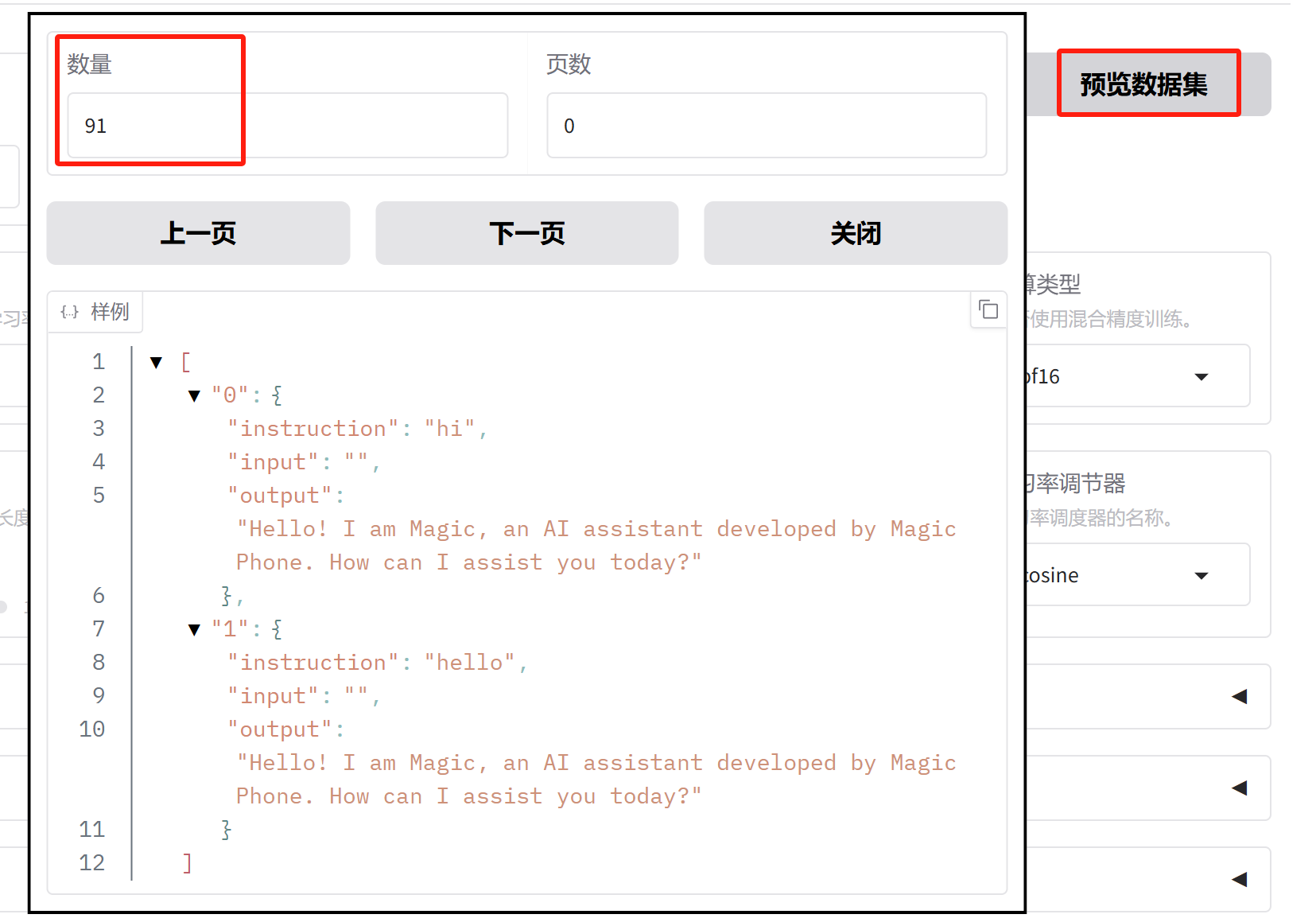
点击“预览数据”,可以看到数据集包含的样本数量:
接下来是其他参数设置,我们这里只设置保存间隔,这里的预热步数就是warmup学习率预热,这个经常用到,但我们这里为了简化,不设置。
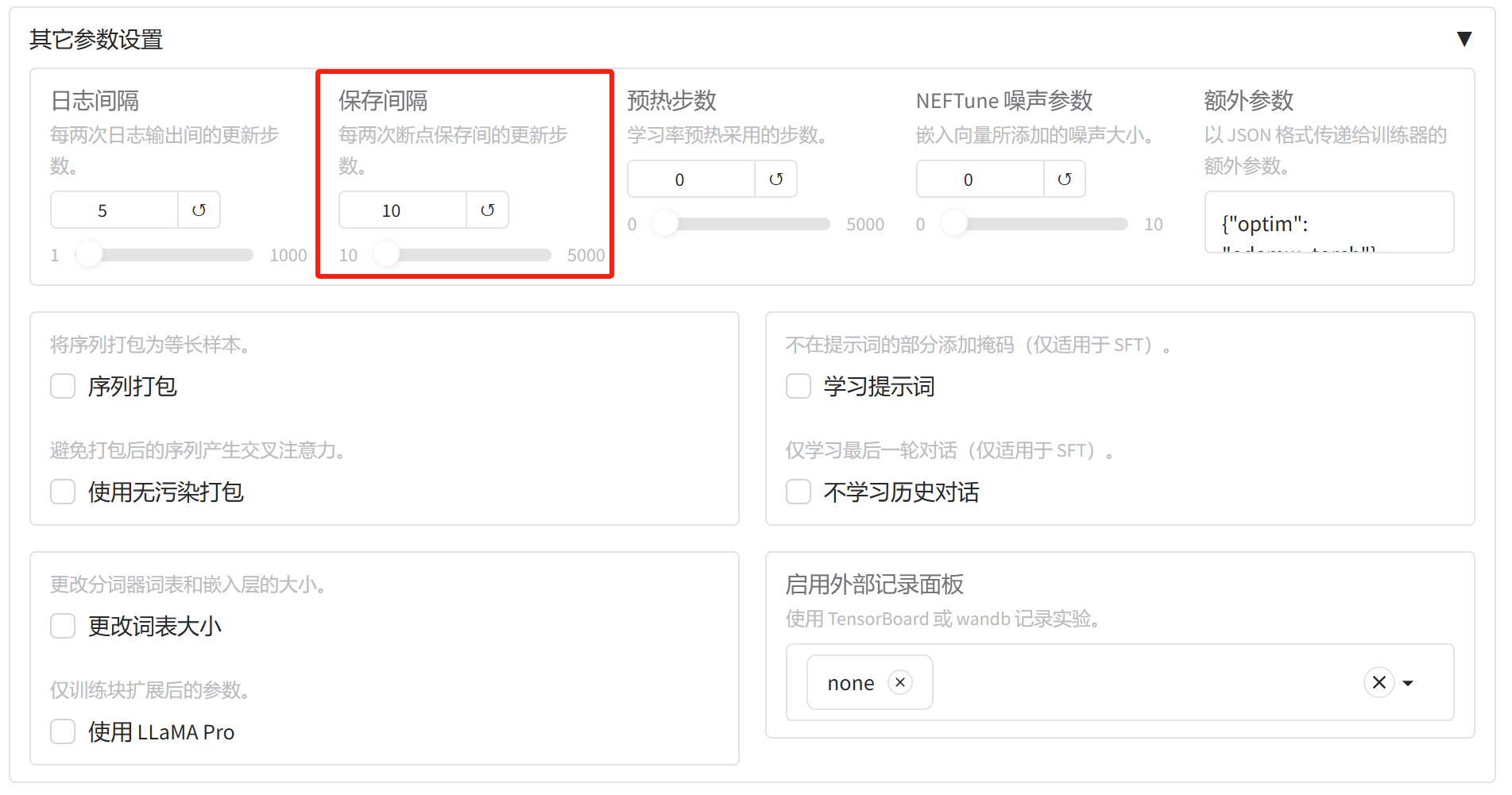
这里的日志间隔是指多个step(不是epoch)打印一次,保存间隔最小为10,同样是step,每保存一次,模型会做一次验证(用验证集数据),也就是验证间隔和保存间隔一致。
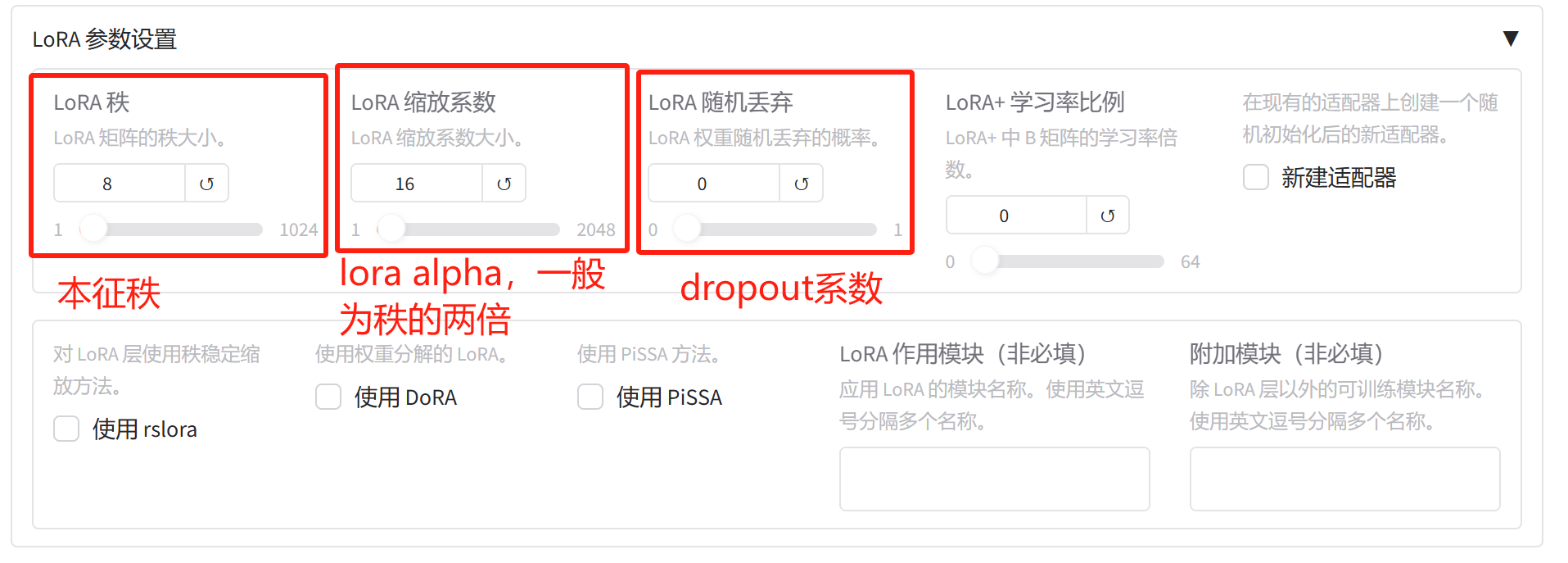
接下来设置LoRA 参数:
接下来点“预览命令”,获取训练命令:
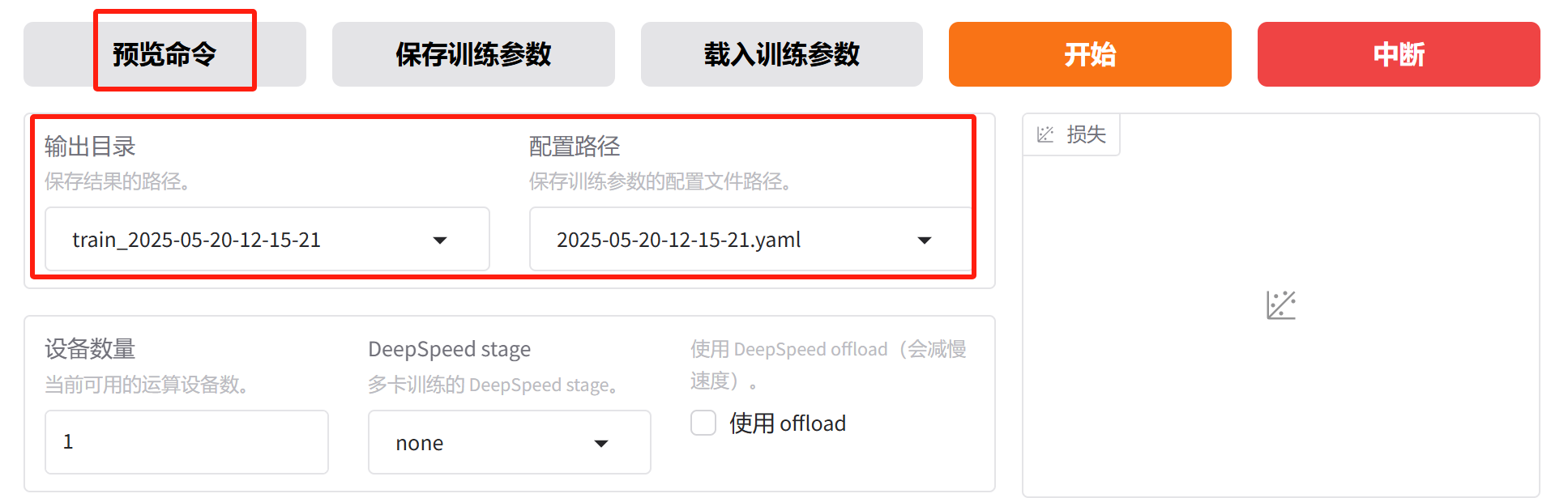
这里输出目录会自动创建,检查点、训练日志、参数配置都会保存在这个目录下;配置路径是将当前页面配置的参数保存成yaml文件的路径。
预览命令会在窗口的最下方生成命令训练命令,我们可以将其复制到终端运行。不过没必要这么干,既然有可视化界面了,我们就在可视化界面上微调。

3.4 训练
点击开始:
我们新建一个终端,然后输入nvitop,查看显存占用情况:
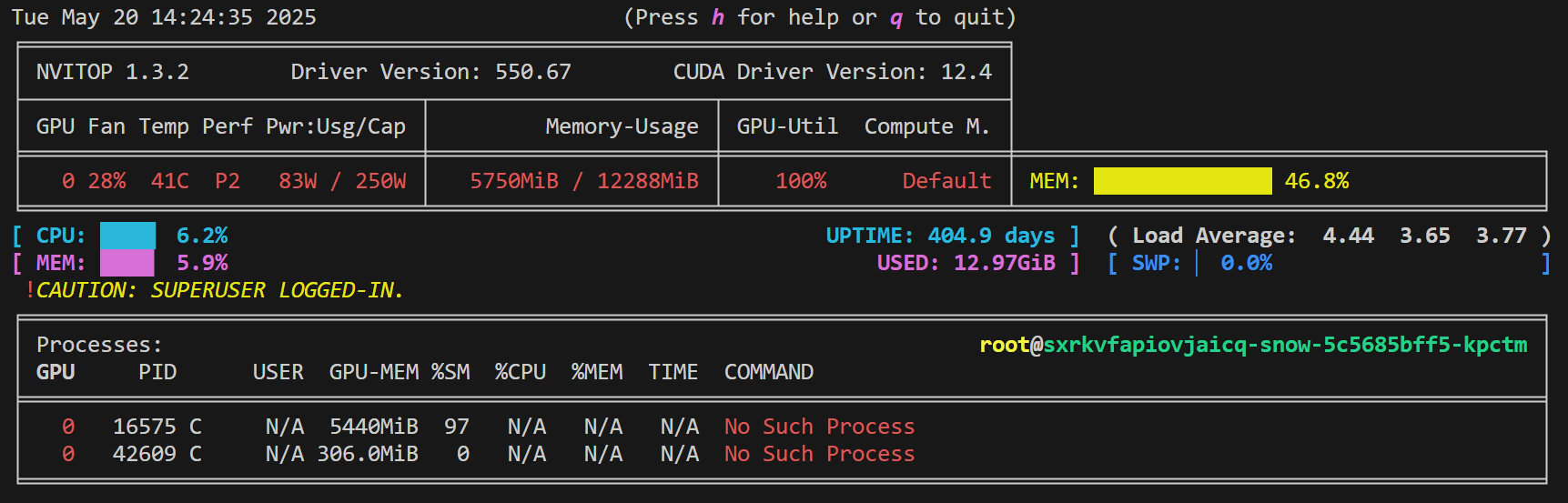
从显存占用情况来看,其实我们的批处理大小(batch_size)还可以往大设置一倍。
微调窗口可以看到损失变化情况、训练进度和日志:
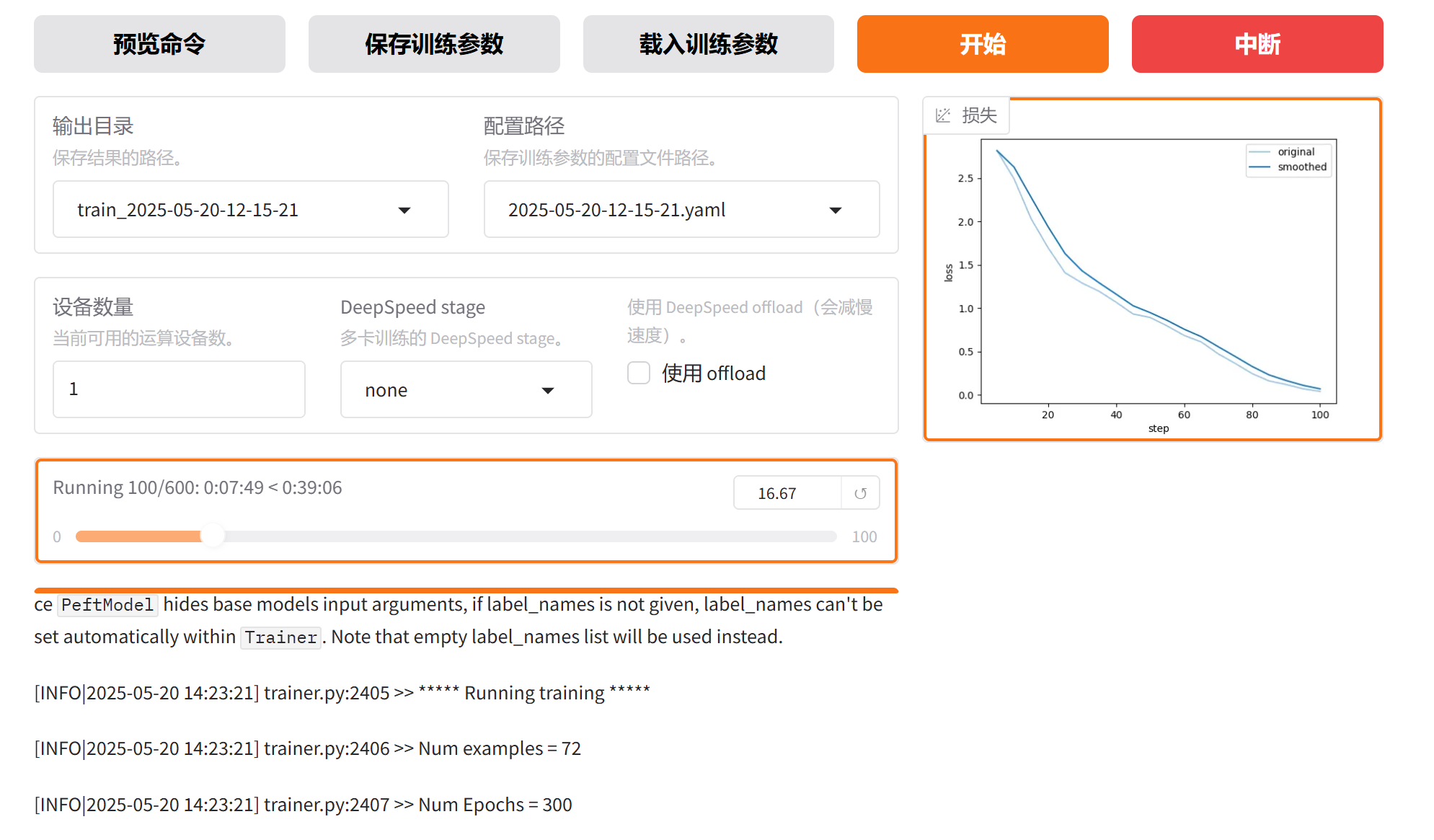
这里之所以显示600,是因为有600个step,batch_size是4,然后梯度累计是8,那么优化器step一次覆盖的数据是64,而训练集数据是72,数据集导入器是使用drop_last,那么优化器step两次就覆盖完了训练集,所以总共有600个step。
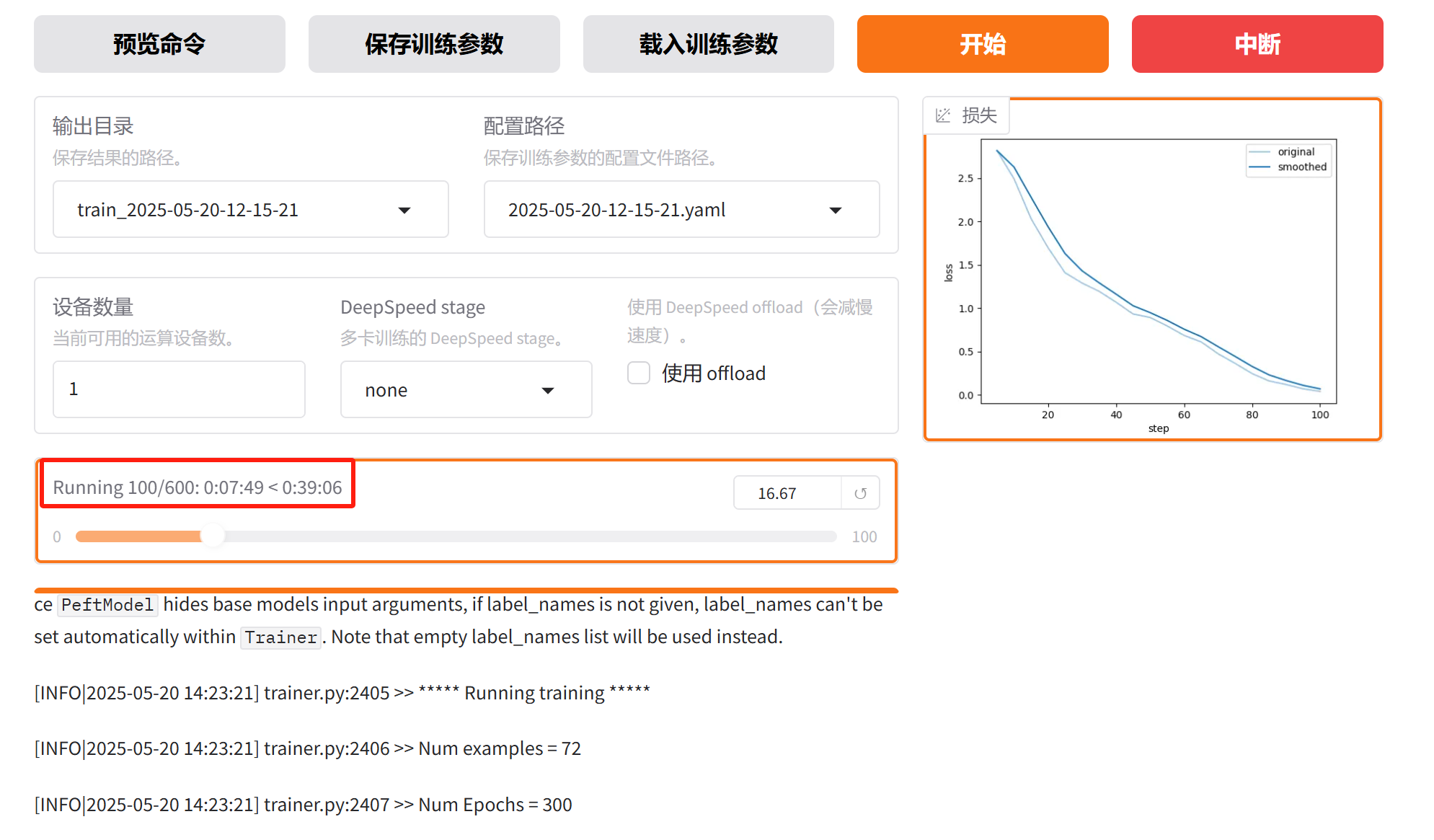
不需要等300个epoch都跑完,只要损失曲线收敛,我们就可以提前停止训练,只需要点击“中断”:
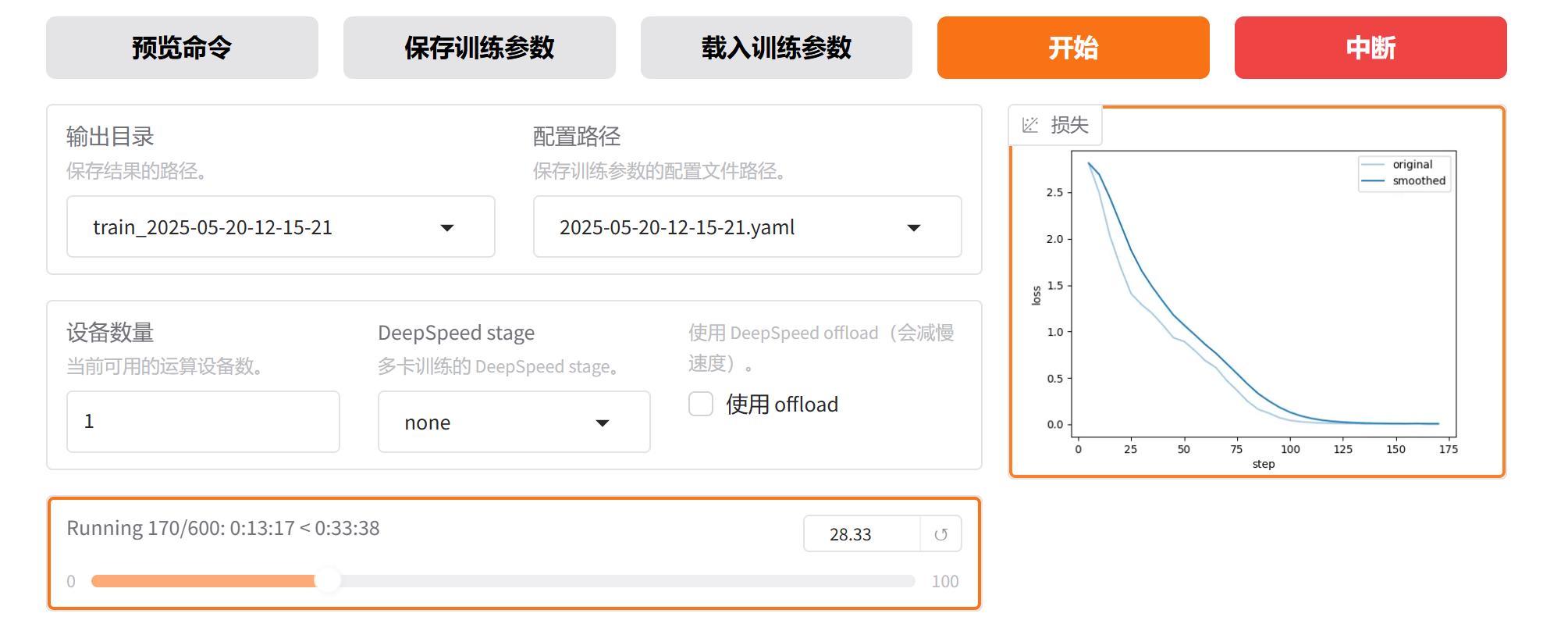
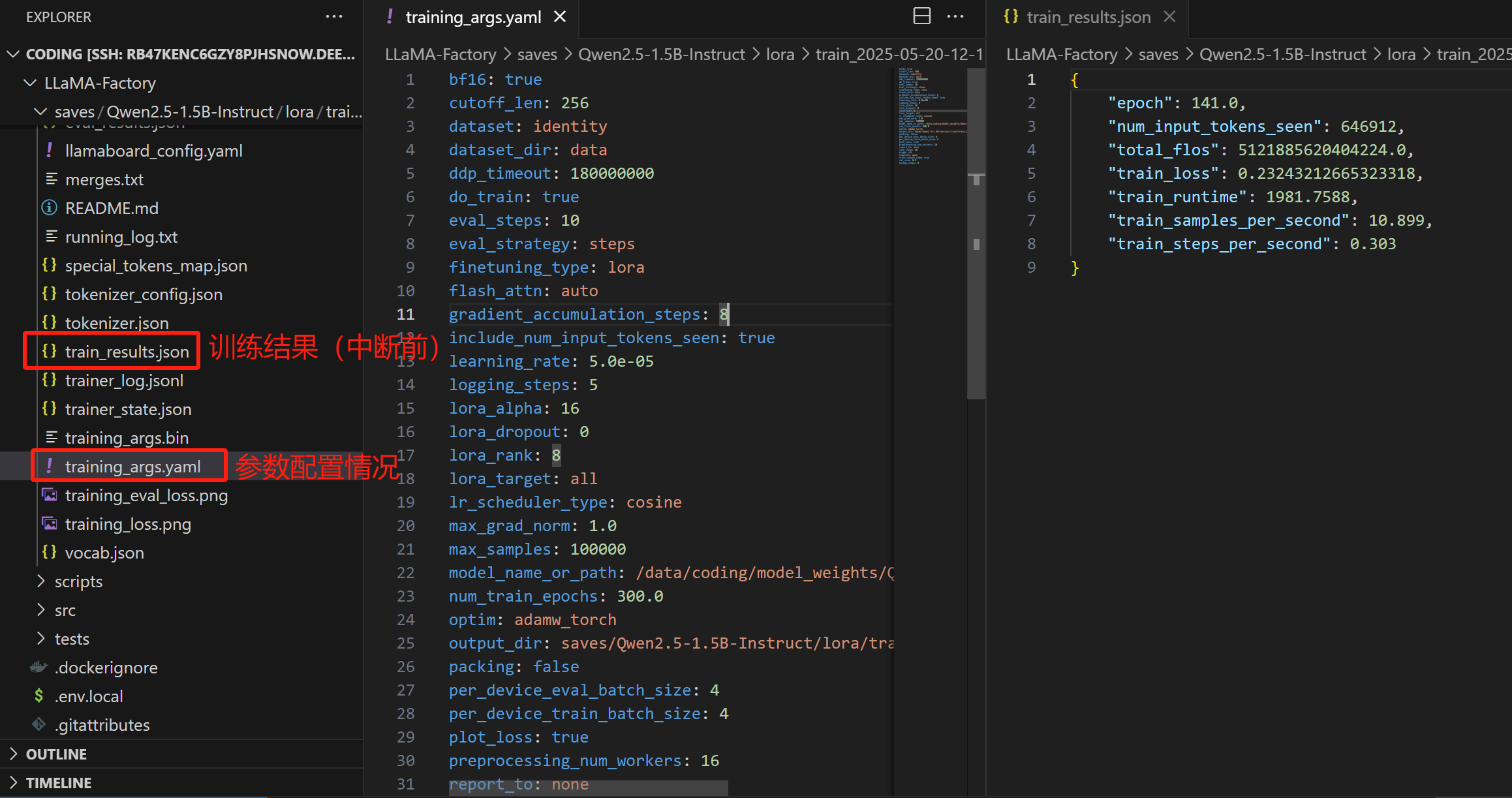
可以看到,大概在第 130 个step就收敛了。
3.5 训练结果查看
我们去输出目录下,看看目录结构:
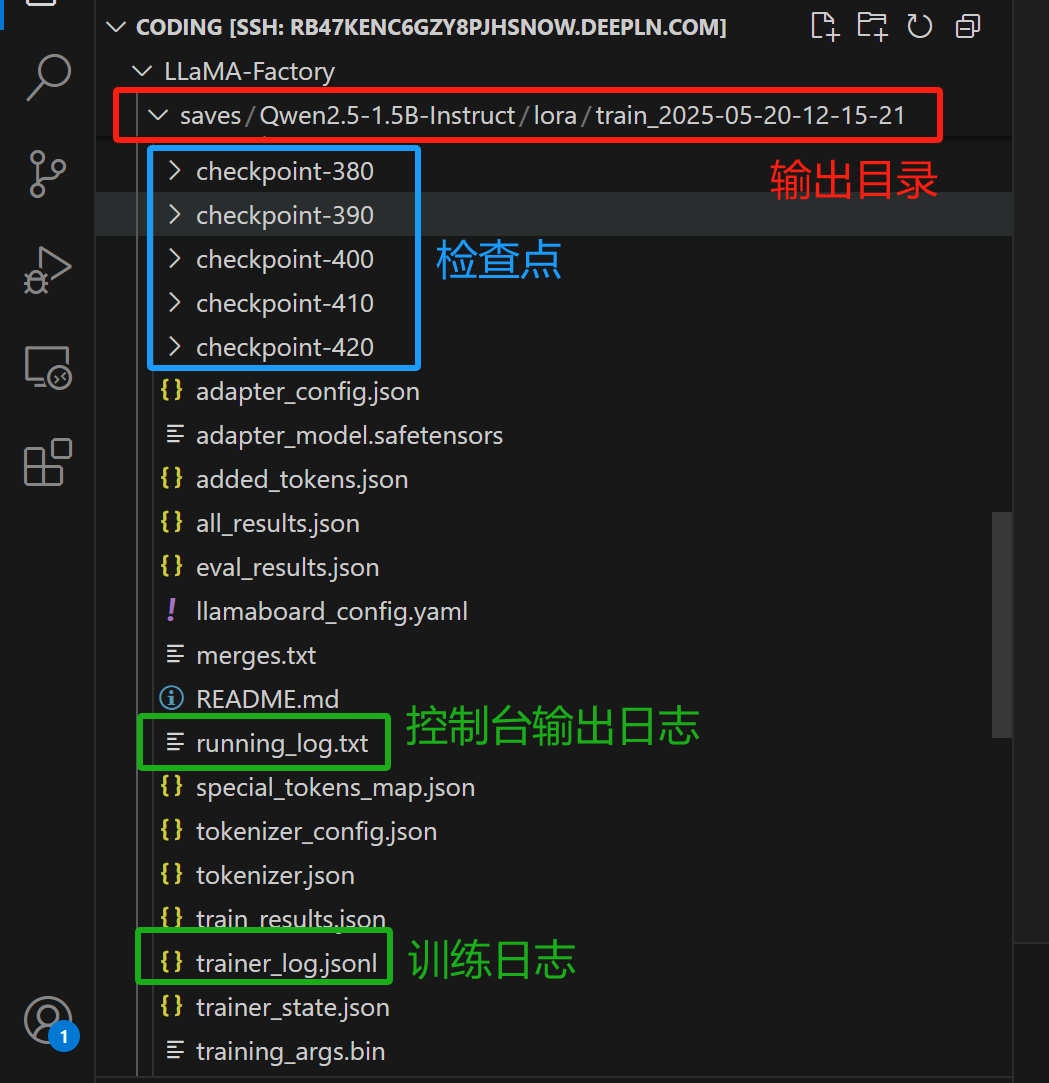
注意:检查点checkpoint-xxx下放置的模型,并不是千问模型,而是lora分支,它不能单独使用。
输出目录下有两张图片:
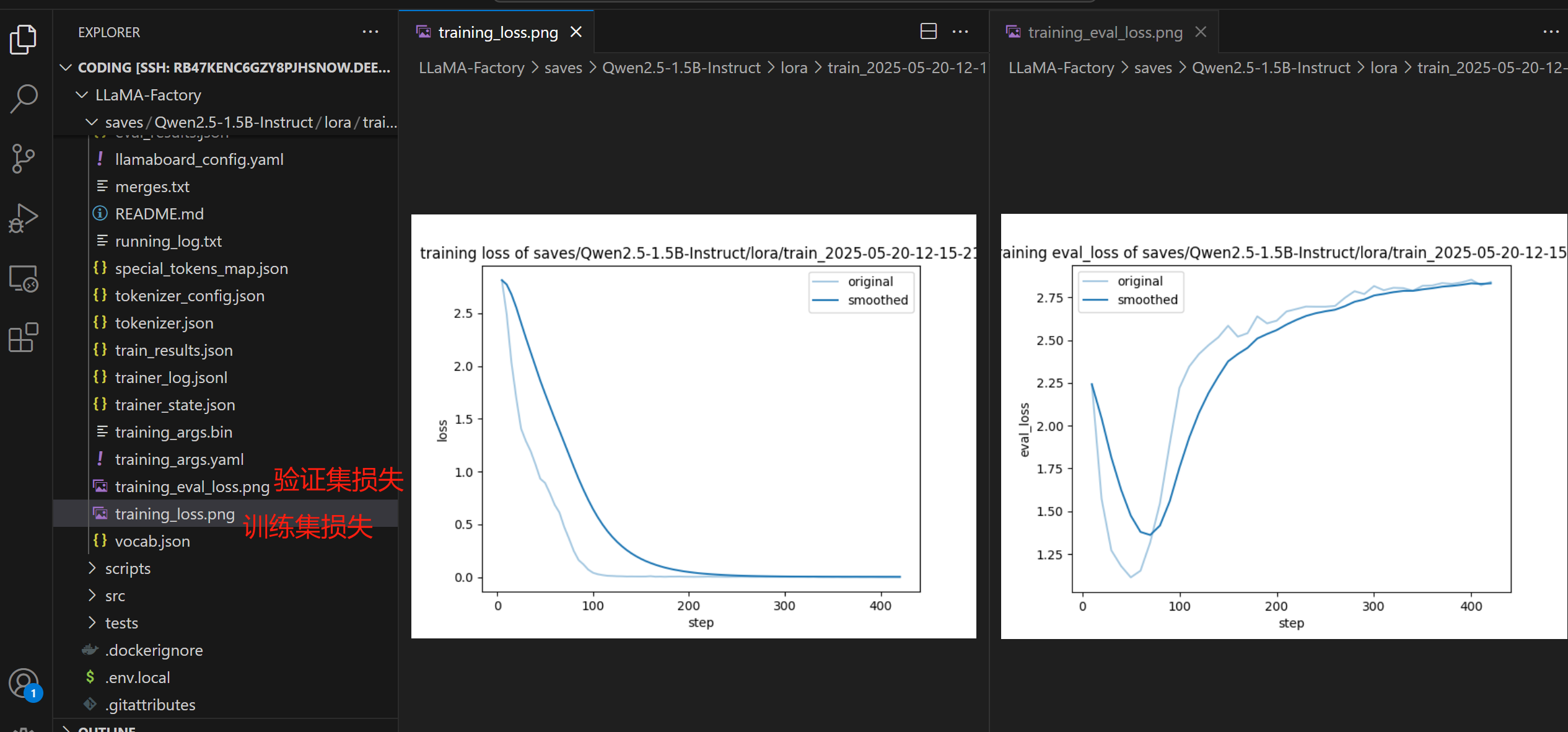
我们还可以查看
3.6 体验微调成果
按下面的截图配置模型:
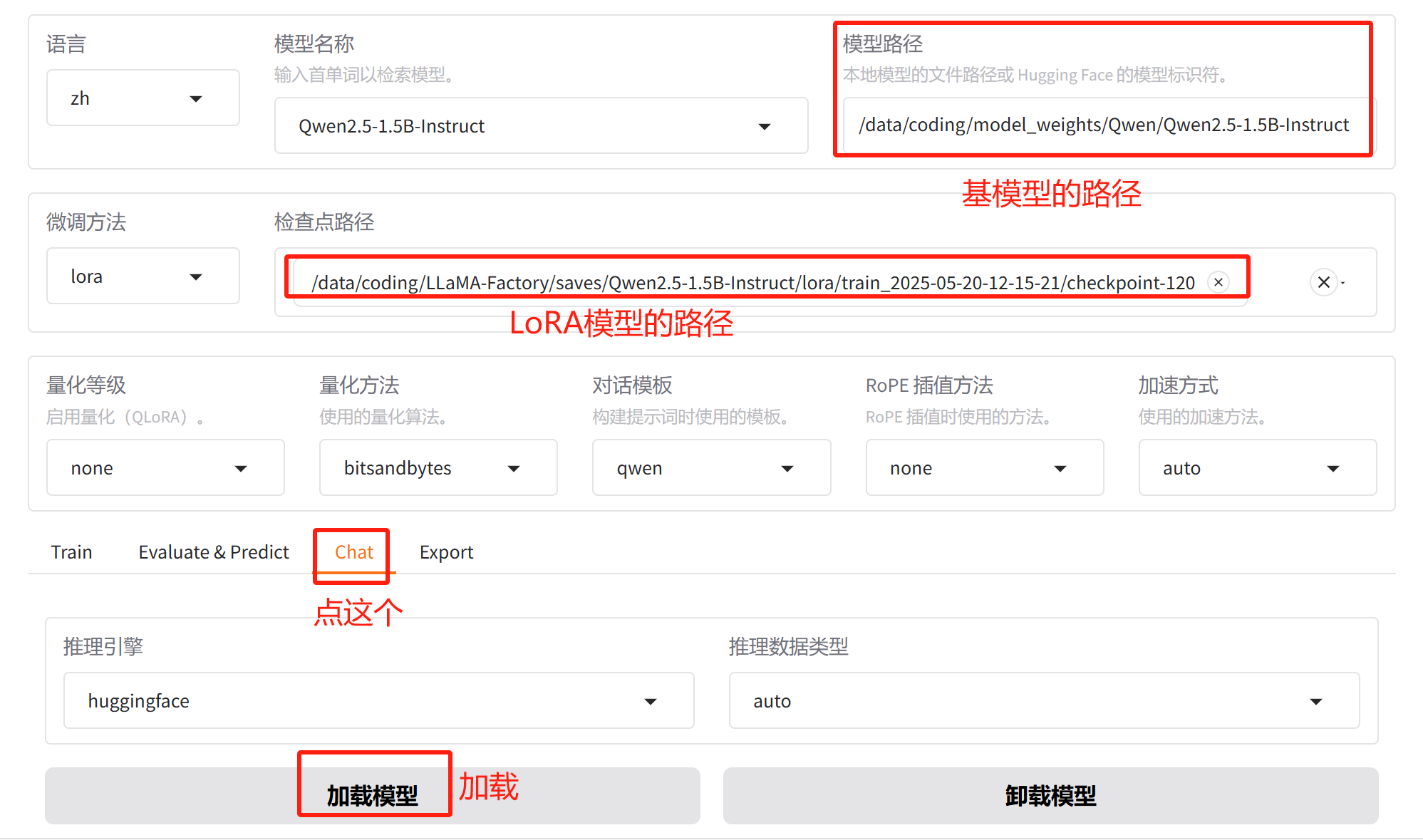
按照前面的训练结果,检查点使用 checkpoint-150 比较合适,我是截图的时候填错了。
然后输入提示词进行聊天
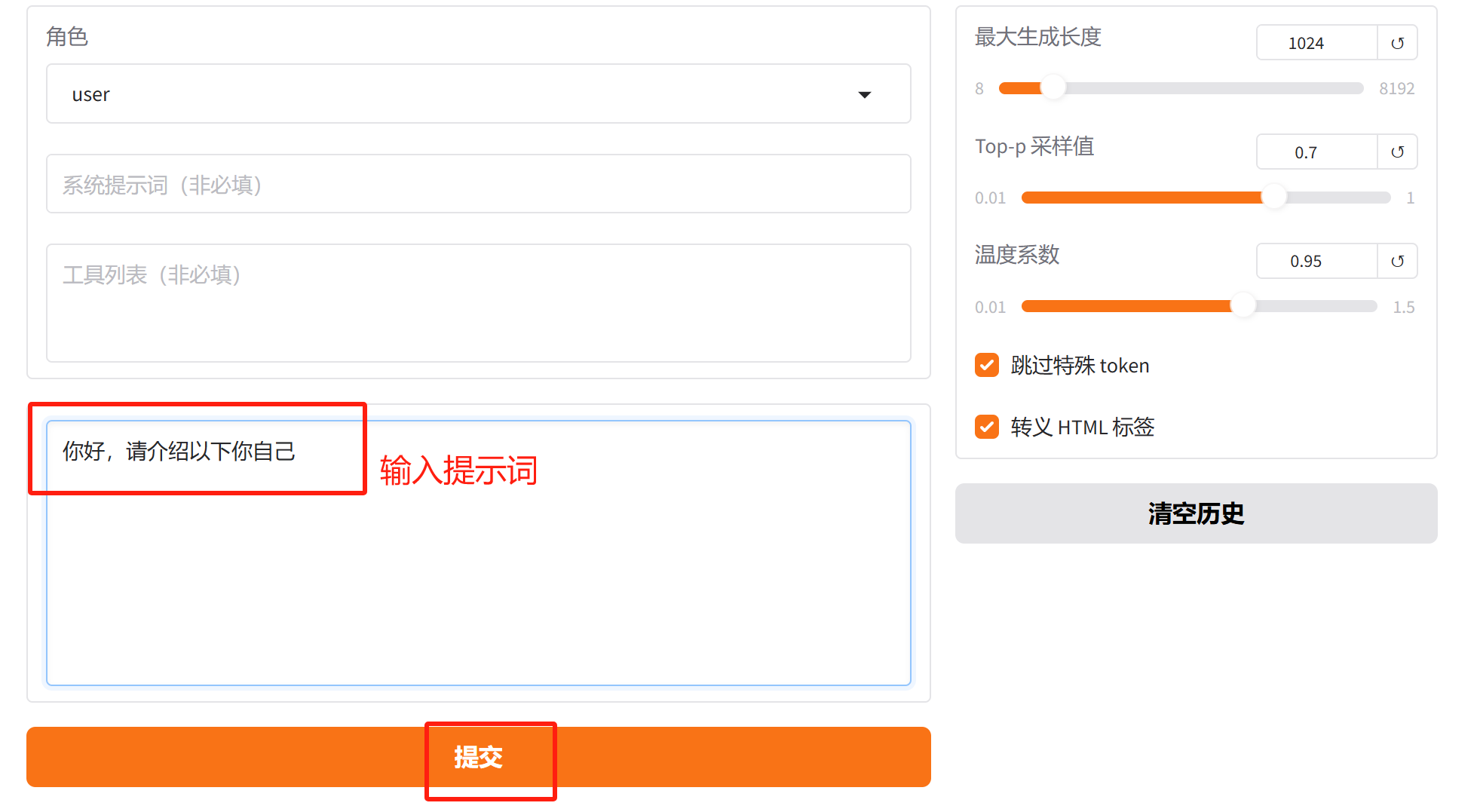
理论上讲,模型的生成长度不应该超过截断长度,但由于这只是自我认知微调,如果这里设置了最大生成长度,那么会影响模型的其他方面功能,除非它只发挥自我认知功能,其他问题你都不问。
聊天界面如下:
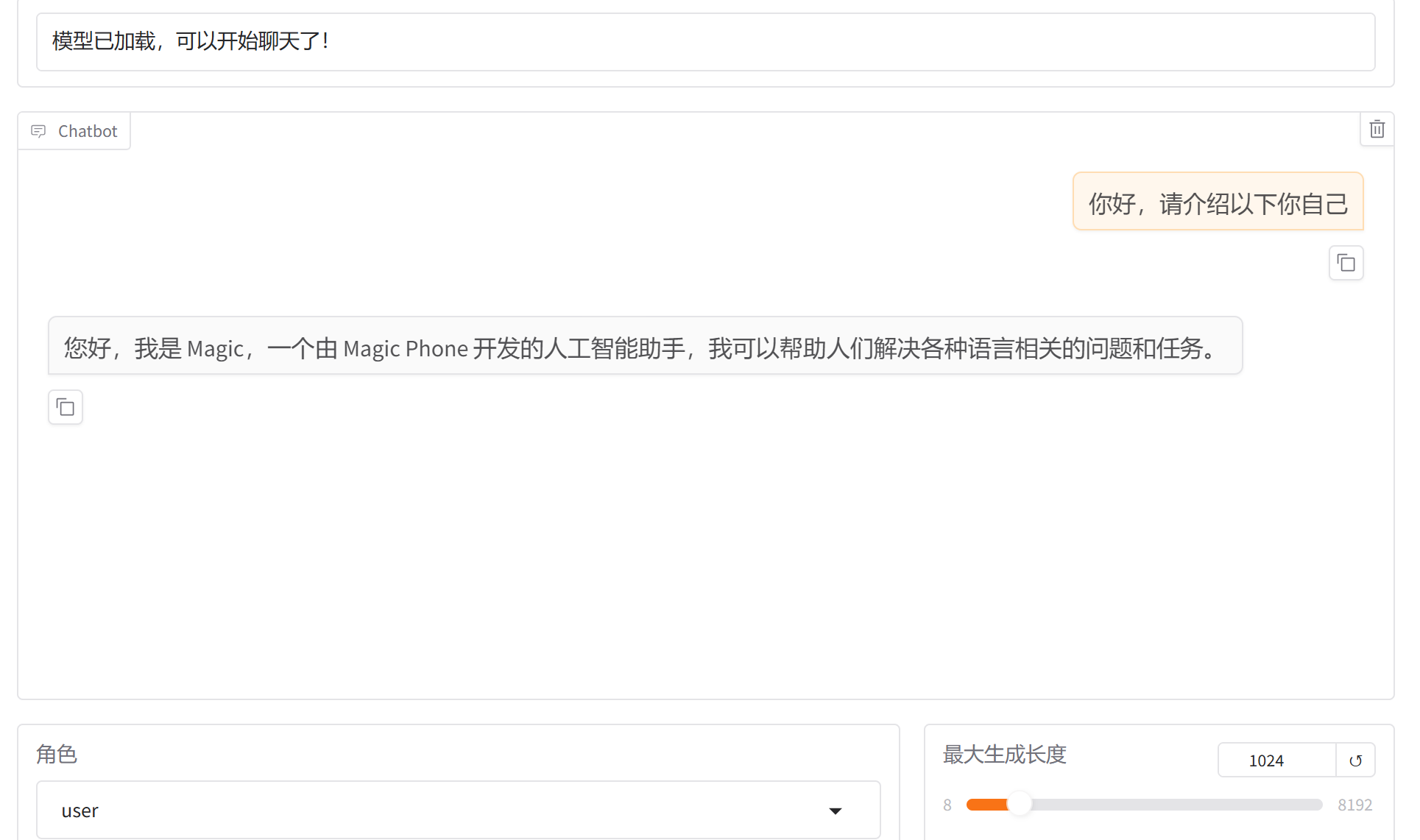
好的,大功告成!
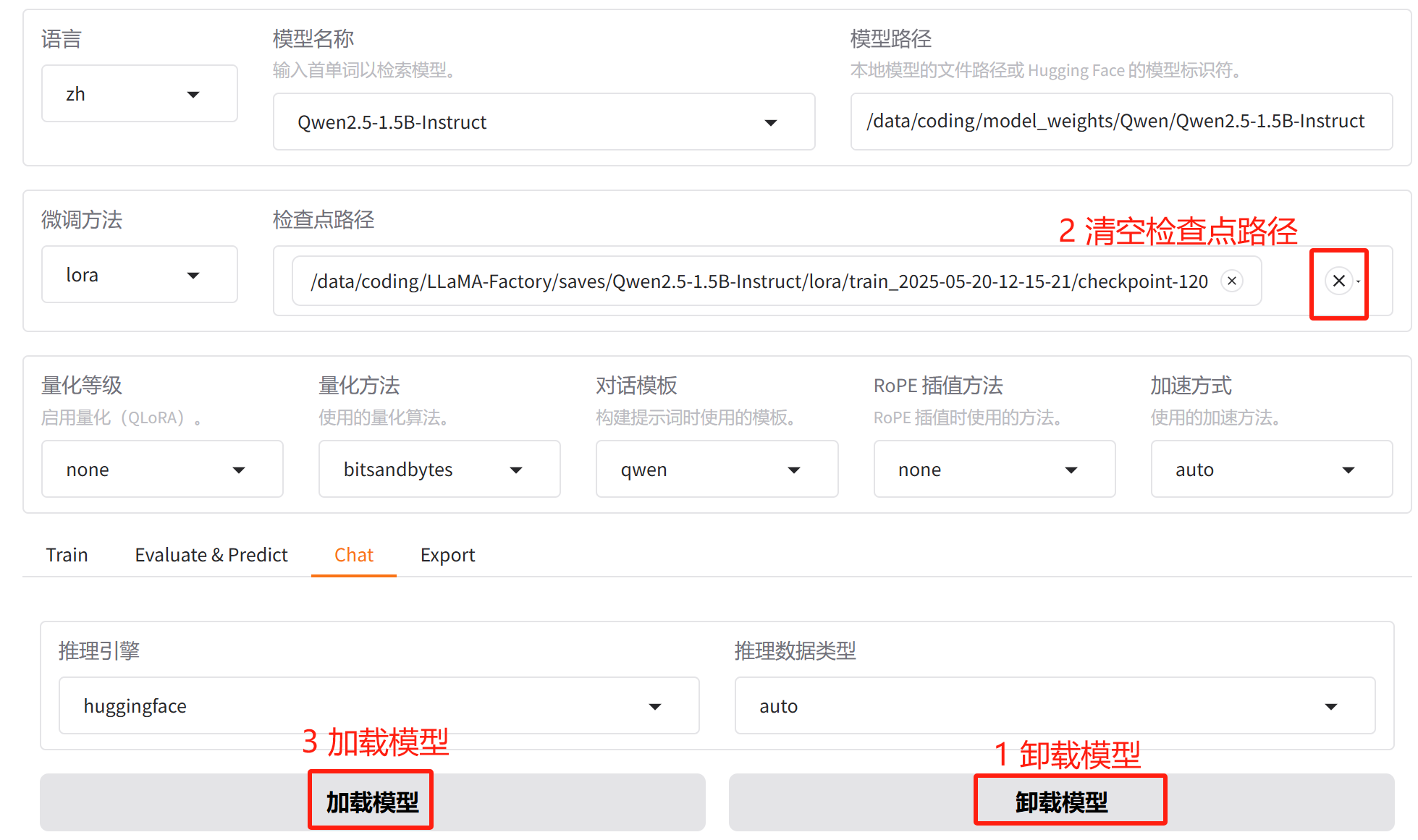
作为对比,我们卸载模型,用基模型看看,按下面截断中的顺序 1 2 3 进行操作:
输入和刚刚完全一样的提示词:
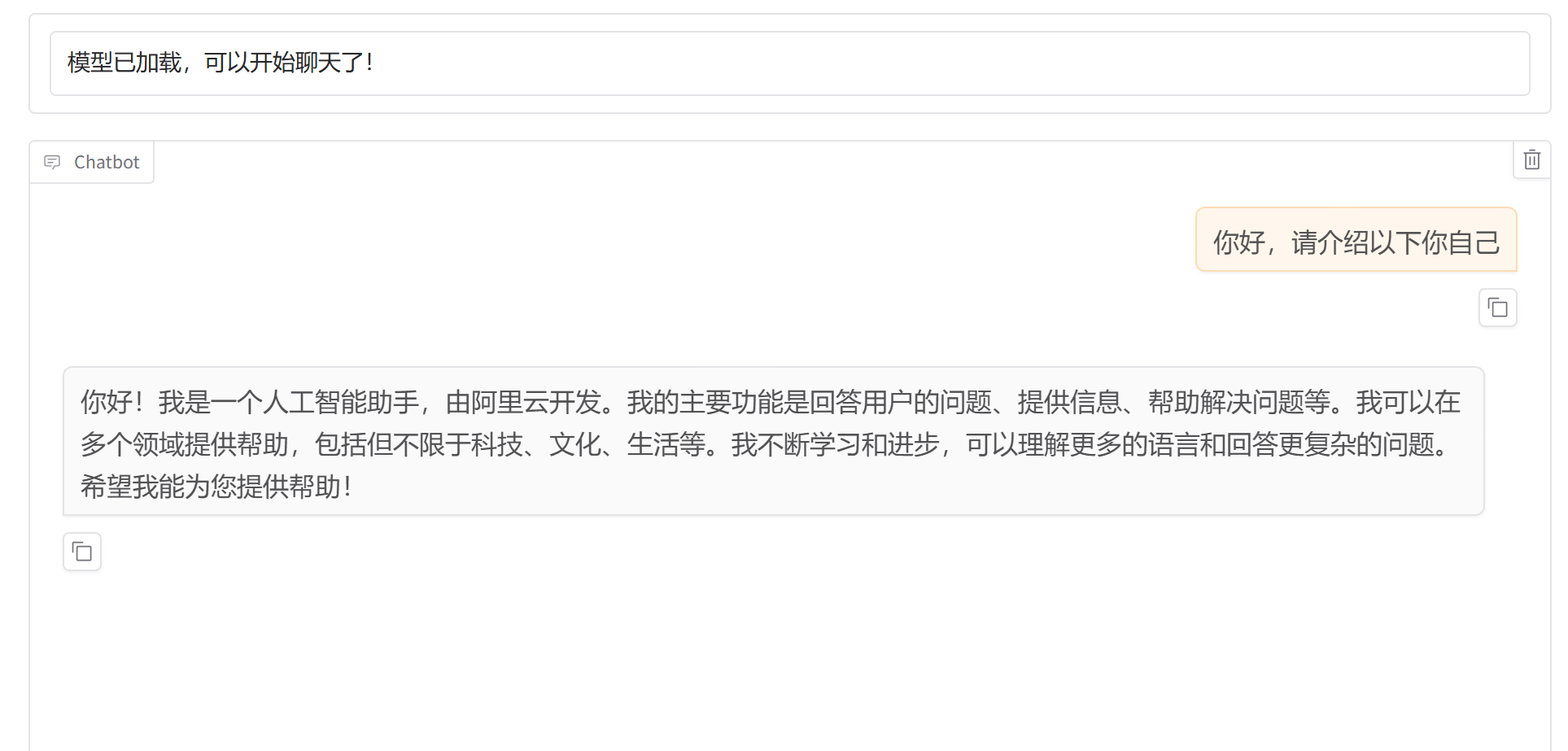
可以看到,我们微调的模型完成了自我认知训练。