知识体系_数据分析挖掘_基尼系数
1 概述
基尼系数(gini coefficient)表示在全部居民收入中,用于进行不平均分配的那部分收入占总收入的百分比。社会中每个人的收入都一样、收入分配绝对平均时,基尼系数是0;全社会的收入都集中于一个人、收入分配绝对不平均时,基尼系数是1。现实生活中,两种情况都不可能发生,基尼系数的实际数值只能介于0~1之间。一般认为,基尼系数小于0.2时,显示居民收入分配过于平均,0.2 ~ 0.3之间时较为平均,0.3 ~ 0.4之间时比较合理,0.4 ~ 0.5时差距过大,大于0.5时差距悬殊。通常而言,与面积或人口较小的国家相比,地域辽阔、人口众多和自然环境差异较大国家的基尼系数会高一些。经济处于起步阶段或工业化前期的国家,基尼系数要大一些,而发达经济体特别是实施高福利政策国家的基尼系数要小一些。
⚠️实际上基尼系数并不是只能应用于收入分配是否均匀的衡量场景中,像指标异动归因分析中,计算维度的贡献、衡量分类模型的区分能力等很多场景都是可以应用的
2 计算方法
上图为洛伦兹曲线,横坐标为‘累计人口百分比’,纵坐标为‘累计收入百分比’,然后按照‘累计人口百分比’和‘累计收入百分比’可绘制出一条曲线(上图中的蓝色线),该曲线叫‘洛伦兹曲线’,其越‘直’则表示收入分布越均匀,如果其越‘凹’则表示收入分布越不均匀。那么基尼系数 = 面积A / (面积A+面积B)。面积A+面积B为0.5,经济学含义是用于不平均分配的那部分收入占全部收入的比例,此种理解是图示法理解,可以使用数学积分或者数学公式法计算
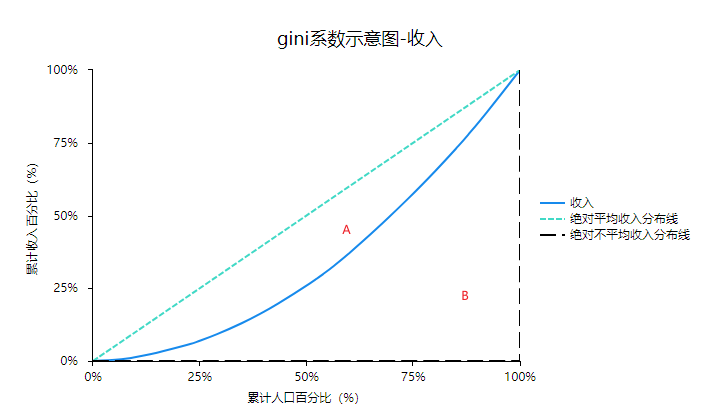
方法一:
Gini=A/(A+B)=A/0.5 (⚠️A、B分别表示A区域和B区域的面积)
方法二:
(⚠️n表示分组数,
为累计人数占比,
表示累计目标占比)
方法三:
⚠️下面为示例,使用时需要修改data为实际数据集
import numpy as np
import pandas as pd
data = pd.DataFrame({'sex': ['未知', '男', '女'],'acc_pi': [0.3, 0.7, 1], #累计人数占比'acc_qi': [0, 0.45, 1], #累计目标占比'per_qi': [0, 1.12, 1.84]}) #客均目标data.sort_values('per_qi', inplace=True)
z = 0
for i in range(data.shape[0]):p0, q0 = 0, 0if i == 0:z += (data.loc[i, 'acc_pi'] - 0) * (data.loc[i, 'acc_qi'] + 0)else:z += (data.loc[i, 'acc_pi'] - data.loc[i-1, 'acc_pi']) * (data.loc[i, 'acc_qi'] + data.loc[i-1, 'acc_qi'])
gi = 1 - z
gi3 使用基尼系数应注意的几个问题
基尼系数给出了反映居民之间贫富差异程度的数量界线,较全面客观地反映居民之间的贫富差距,能预报、预警居民之间出现贫富两极分化,但基尼系数这个反映差距的指标也有局限性,在使用时需要注意:
(1) 基尼系数衡量的是收入相对差距。假如每个家庭的收入都比基期年翻一番,虽然高收入户增收的绝对额要大得多,但因为所有家庭收入增加的比例是一样的,相对差距仍一样,计算得到的基尼系数也是一样的
(2) 基尼系数反映的是收入总体差距。基尼系数的变化取决于所有居民的收入相对变化,其中某一群体相对于另一个群体的收入差距的变化有可能与基尼系数的变化趋势不一致
(3) 基尼系数衡量了收入差距,却不能衡量在哪里存在分配不公。有些差距是公平合理的,比如,劳动者付出的劳动数量及质量不同,得到的收入有所不同是合理的。而有些差距是不公平的,需要进一步做深入的制度研究,找出差距原因并消除不公平分配现象。
(4) 使用不同来源、不同口径的收入基础数据会得到不同的基尼系数。比如:收入指标是否规范、用总收入指标还是可支配收入指标、收入中是否包括政府的实物福利、是否扣除年度物价因素、是否扣