凸优化系列——First-order method
这篇博客系统地介绍了梯度下降法在凸优化中的原理与应用,涵盖了算法的推导动机、步长选择策略(如回溯线搜索与精确线搜索)、收敛性分析(包括Lipschitz光滑条件与强凸情形下的收敛速率),并进一步拓展到非凸优化中的表现。同时,文章还引入了次梯度的概念,解释其在非可导凸函数中的作用。通过图示与推导相结合的方式,读者可以更直观地理解一阶优化方法的核心思想与数学基础,为后续深入学习优化算法打下坚实基础。
Gradient Descent
Consider unconstrained, smooth convex optimization
min x f ( x ) \min_x f(x) xminf(x)
That is f f f is convex and differentiable with dom ( f ) = R n \text{dom}(f)=\mathbb{R}^n dom(f)=Rn. Denote optimal criterion value by f ∗ = min x f ( x ) f^* = \min_x f(x) f∗=minxf(x) and a solution by x ∗ x^* x∗
梯度下降法: choose initial point x ( 0 ) ∈ R n x^{(0)}\in \mathbb{R}^n x(0)∈Rn, repeat:
x ( k + 1 ) = x ( k ) − t k ∇ x f ( x ( k ) ) x^{(k+1)} = x^{(k)}-t_k\nabla_xf(x^{(k)}) x(k+1)=x(k)−tk∇xf(x(k))
Why? 写成上述的方式呢?
首先对 f ( x ) f(x) f(x)在x 处展开(二阶近似):
f ( y ) = f ( x ) + ∇ f ( x ) ( y − x ) + 1 2 t ∣ ∣ y − x ∣ ∣ 2 2 f(y)= f(x)+\nabla f(x) (y-x)+ \frac{1}{2t}||y-x||_2^2 f(y)=f(x)+∇f(x)(y−x)+2t1∣∣y−x∣∣22
这里需要注意一下,此处展开不是标准的二阶泰勒展开,因为这里用 1 t I \frac{1}{t}I t1I替代了原始的Hession 矩阵 ∇ 2 f ( x ) \nabla^2f(x) ∇2f(x)
原始的二阶泰勒展开应该是:
f ( y ) = f ( x ) + ∇ f ( x ) ( y − x ) + 1 2 ( y − x ) T ∇ 2 f ( x ) ( y − x ) f(y) = f(x) + \nabla f(x)(y-x)+\frac{1}{2}(y-x)^T\nabla^2f(x)(y-x) f(y)=f(x)+∇f(x)(y−x)+21(y−x)T∇2f(x)(y−x)
Choose next point y = x + y=x^+ y=x+ to minimize quadratic approximation:
因为二阶近似后为凸函数,可以直接求导之后取零即可得到对应的最小值:
∇ f ( y ) = ∇ f ( x ) + 1 t ( y − x ) = 0 y = x − t ⋅ ∇ f ( x ) \nabla f(y) = \nabla f(x)+\frac{1}{t}(y-x)=0\\ y=x-t\cdot\nabla f(x) ∇f(y)=∇f(x)+t1(y−x)=0y=x−t⋅∇f(x)
进一步就可以写成如下的形式:
x + = x − t ∇ f ( x ) x^+ = x-t\nabla f(x) x+=x−t∇f(x)
更直观的角度理解一下,如下图所示,就是相当于在x 处进行二阶近似,然后直接取最小值作为下一个点,而这就是梯度下降的来源:
x + = argmin y f ( y ) = f ( x ) + ∇ f ( x ) T ( y − x ) + 1 2 t ∣ ∣ y − x ∣ ∣ 2 2 x^+ = \text{argmin}_y f(y)=f(x)+\nabla f(x)^T(y-x)+\frac{1}{2t}||y-x||_2^2 x+=argminyf(y)=f(x)+∇f(x)T(y−x)+2t1∣∣y−x∣∣22
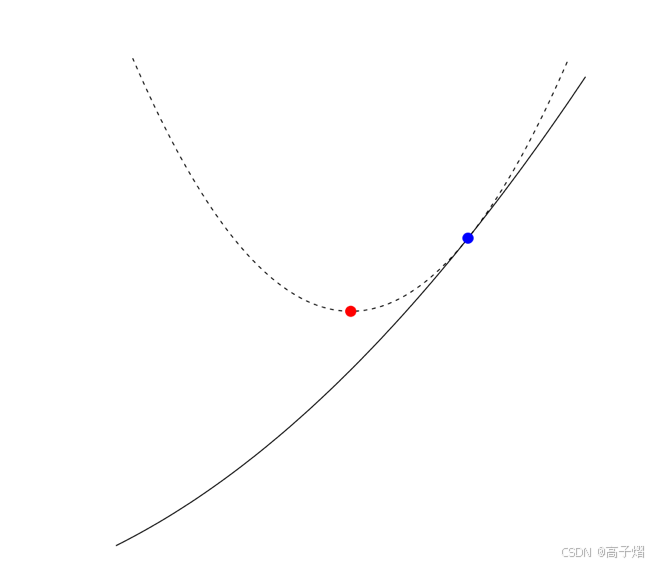
How to choose step sizes
如何选择合适的步长,从而实现更好的梯度下降,太大:出现震荡, 太小:更新步骤太多。
- Backtracking interperation
One way to adaptively choose the step size if to use backtracking line search:
- First fix parameters 0 < β < 1 and 0 < α ≤ 1 2 0 < \beta<1 \quad \text{and}\quad 0<\alpha\leq\frac{1}{2} 0<β<1and0<α≤21
- At each iteration, start with t = t init t=t_{\text{init}} t=tinit, and while
f ( x − t ∇ f ( x ) ) > f ( x ) − α t ∣ ∣ ∇ f ( x ) ∣ ∣ 2 2 f(x-t\nabla f(x)) > f(x)-\alpha t||\nabla f(x)||_2^2 f(x−t∇f(x))>f(x)−αt∣∣∇f(x)∣∣22
shrink t = β t . t=\beta t. t=βt. Else perfrom gradient descent update
x + = x − t ∇ f ( x ) x^+ = x-t\nabla f(x) x+=x−t∇f(x)
- Exact line search
We also choose step to do the best we can along direction of negative gradient, called exact line search:
t = argmin s ≥ 0 f ( x − s ∇ f ( x ) ) t = \text{argmin}_{s\geq0} f(x-s\nabla f(x)) t=argmins≥0f(x−s∇f(x))
Convergence analysis
首先介绍一下Lipschitz continuous: 是一种比连续更强的性质。
首先如果函数 f f f 满足L-Lipschitz continuous,如果f 是可微的,那对应的 ∣ ∣ ∇ f ( x ) ∣ ∣ p ≤ L ||\nabla f(x)||_p \leq L ∣∣∇f(x)∣∣p≤L,或者说原函数值的变化是有上界的,可以表示为:
∣ ∣ f ( y ) − f ( x ) ∣ ∣ 2 ≤ L ∣ ∣ x − y ∣ ∣ 2 for any x , y ||f(y)-f(x)||_2 \leq L||x-y||_2 \quad \text{for any } x,y ∣∣f(y)−f(x)∣∣2≤L∣∣x−y∣∣2for any x,y
如果 ∇ f \nabla f ∇f满足L-Lipschitz continuous,对应为L-smooth,如果f 是二阶可导的,对应的Hession 矩阵的范数是有界的,或者说函数的弯曲程度有限的,不会突然弯太厉害。 这种肯定是比光滑smooth 更强
∣ ∣ ∇ f ( y ) − ∇ f ( x ) ∣ ∣ p ≤ L ∣ ∣ y − x ∣ ∣ p for any x , y ||\nabla f(y)-\nabla f(x)||_p \leq L||y-x||_p \quad \text{for any }x,y ∣∣∇f(y)−∇f(x)∣∣p≤L∣∣y−x∣∣pfor any x,y
可以表示为: ∣ ∣ ∇ 2 f ( x ) ∣ ∣ p ≤ L ||\nabla^2 f(x)||_p \leq L ∣∣∇2f(x)∣∣p≤L 或者也可以表示为: ∇ 2 f ( x ) ⪯ L I \nabla^2 f(x) \preceq LI ∇2f(x)⪯LI
∇ 2 f ( x ) ⪯ L I \nabla^2f(x)\preceq LI ∇2f(x)⪯LI 可以表示为 L I − ∇ 2 f ( x ) ⪰ 0 LI-\nabla^2f(x) \succeq0 LI−∇2f(x)⪰0,说明对应的特征值不大于L,给了曲率的一个上界。
f ( y ) = f ( x ) + ∇ f ( x ) ( y − x ) + ∇ 2 f ( x ) 2 ∣ ∣ y − x ∣ ∣ 2 2 ≤ f ( x ) + ∇ f ( x ) ( y − x ) + L 2 ∣ ∣ y − x ∣ ∣ 2 2 f(y)=f(x)+\nabla f(x)(y-x)+\frac{\nabla^2f(x)}{2}||y-x||_2^2 \leq f(x)+ \nabla f(x)(y-x)+\frac{L}{2}||y-x||_2^2 f(y)=f(x)+∇f(x)(y−x)+2∇2f(x)∣∣y−x∣∣22≤f(x)+∇f(x)(y−x)+2L∣∣y−x∣∣22
所以一阶导数(Jacobi)判断是函数的变化速率,而二阶导数(Hession)判断函数的曲率(弯曲的程度)或者也可以理解为梯度的变化程度。
Theorem: Gradient descent with fixed step size t ≤ 1 / L t\leq 1/L t≤1/L satisfies
f ( x ( k ) ) − f ∗ ≤ ∣ ∣ x ( 0 ) − x ∗ ∣ ∣ 2 2 2 t k f(x^{(k)})-f^* \leq \frac{||x^{(0)}-x^*||_2^2}{2tk} f(x(k))−f∗≤2tk∣∣x(0)−x∗∣∣22
这样就可以把收敛速率叫做: O ( 1 / k ) \mathcal{O}(1/k) O(1/k). O ( 1 / ϵ ) \mathcal{O}(1/\epsilon) O(1/ϵ)
Analysis for strong convexity
Reminder:strong convexity of f f f means f ( x ) − m 2 ∣ ∣ x ∣ ∣ 2 2 f(x)-\frac{m}{2}||x||_2^2 f(x)−2m∣∣x∣∣22 is convex for some m > 0 m >0 m>0 (When twice differentiable: ∇ 2 f ( x ) ⪰ m I \nabla^2f(x)\succeq mI ∇2f(x)⪰mI)
强凸证明f(x)的曲率要比二次函数还要大,要找到一个曲率的下界,例如: m-strongly convex \text{m-strongly convex} m-strongly convex,对应可以表示为:
∇ 2 f ( x ) ⪰ m I \nabla^2 f(x)\succeq mI ∇2f(x)⪰mI
f ( y ) ≥ f ( x ) + ∇ f ( x ) ( y − x ) + m 2 ∣ ∣ y − x ∣ ∣ 2 2 f(y) \geq f(x)+\nabla f(x)(y-x)+\frac{m}2||y-x||_2^2 f(y)≥f(x)+∇f(x)(y−x)+2m∣∣y−x∣∣22
强凸的 ϵ − suboptimal \epsilon-\text{suboptimal} ϵ−suboptimal point 的收敛速度为: O ( l o g ( 1 / ϵ ) ) \mathcal{O}(log(1/\epsilon)) O(log(1/ϵ)) ,也被叫做线性收敛,因为目标在log对数坐标下呈现线性。
First-order method: iterative method, which updates x ( k ) x^{(k)} x(k) in
x ( 0 ) + span { ∇ f ( x ( 0 ) ) , ∇ f ( x ( 1 ) ) , . . . , ∇ f ( x ( k − 1 ) ) } x^{(0)} +\text{span}\{\nabla f(x^{(0)}),\nabla f(x^{(1)}),...,\nabla f(x^{(k-1)})\} x(0)+span{∇f(x(0)),∇f(x(1)),...,∇f(x(k−1))}
表示在这些梯度张成的 空间里,或者表示为这些梯度的一个线性组合。
对于强凸的函数来说,是可以加速的, O ( 1 / k 2 ) \mathcal{O}(1/k^2) O(1/k2). O ( 1 / ϵ ) \mathcal{O}(1/\sqrt\epsilon) O(1/ϵ)
Rate. O ( 1 / k ) or O ( 1 / ϵ 2 ) \mathcal{O}(1/\sqrt{k}) \text{ or } \mathcal{O}(1/\epsilon^2) O(1/k) or O(1/ϵ2)
Analysis for nonconvex case
对于非凸问题来说,local minimize,
∣ ∣ ∇ f ( x ) ∣ ∣ 2 ≤ ϵ ||\nabla f(x)||_2 \leq \epsilon ∣∣∇f(x)∣∣2≤ϵ

Subgradients
Recall that for convex and differentiable f f f: 凸函数的一阶条件
f ( y ) ≥ f ( x ) + ∇ f ( x ) T ( y − x ) for all x , y f(y) \geq f(x)+\nabla f(x)^T(y-x)\quad \text{for} \text{ all }x,y f(y)≥f(x)+∇f(x)T(y−x)for all x,y
A subgradient of a convex function f f f at x x x is any g ∈ R n g \in \mathbb{R}^n g∈Rn such that:
f ( y ) ≥ f ( x ) + g T ( y − x ) for all y f(y)\geq f(x)+g^T(y-x)\quad \text{for} \text{ all }y f(y)≥f(x)+gT(y−x)for all y
- 次梯度总是存在,不管原函数是否是可微的。
- 如果原函数是可微的话,那对应的在 x x x处的次梯度为: g = ∇ f ( x ) g=\nabla f(x) g=∇f(x)
- 相同的定义对非凸的函数来说也是同样的定义,但是不一定存在
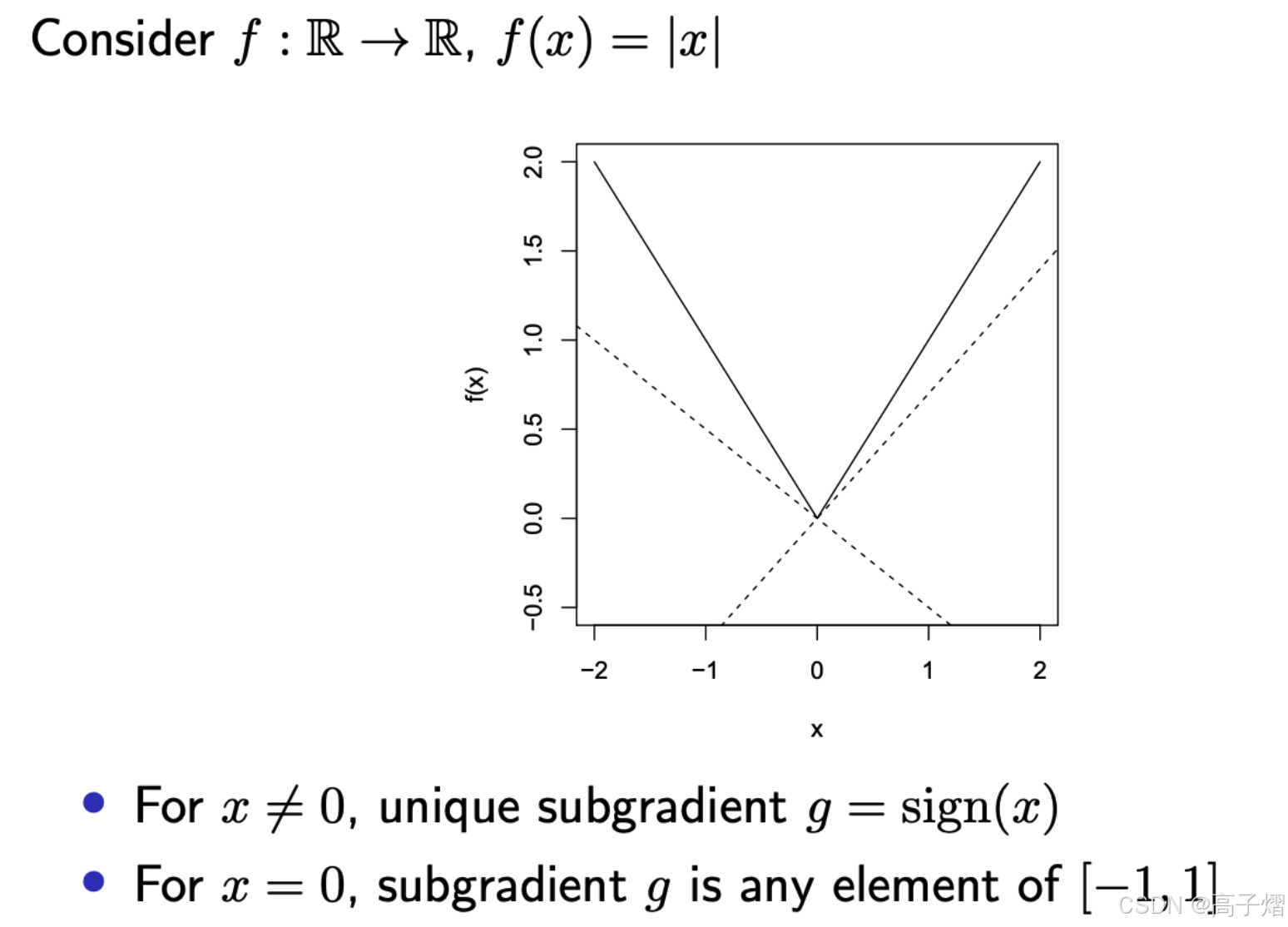
对于一个凸函数 f ( x ) f(x) f(x),某点 x 0 x_0 x0处的次梯度集合的定义为:
δ f ( x 0 ) = { g ∈ R n , f ( y ) ≥ f ( x 0 ) + g T ( y − x 0 ) , ∀ y } \delta f(x_0) = \{g \in \mathbb{R}^n, f(y)\geq f(x_0)+g^T(y-x_0),\quad \forall y\} δf(x0)={g∈Rn,f(y)≥f(x0)+gT(y−x0),∀y}
Consider f ( x ) = max { f 1 ( x ) , f 2 ( x ) } f(x) =\max\{f_1(x),f_2(x)\} f(x)=max{f1(x),f2(x)}, for f 1 , f 2 : R n → R f_1,f_2:\mathbb{R}^n \rightarrow \mathbb{R} f1,f2:Rn→R,convex,differetiable
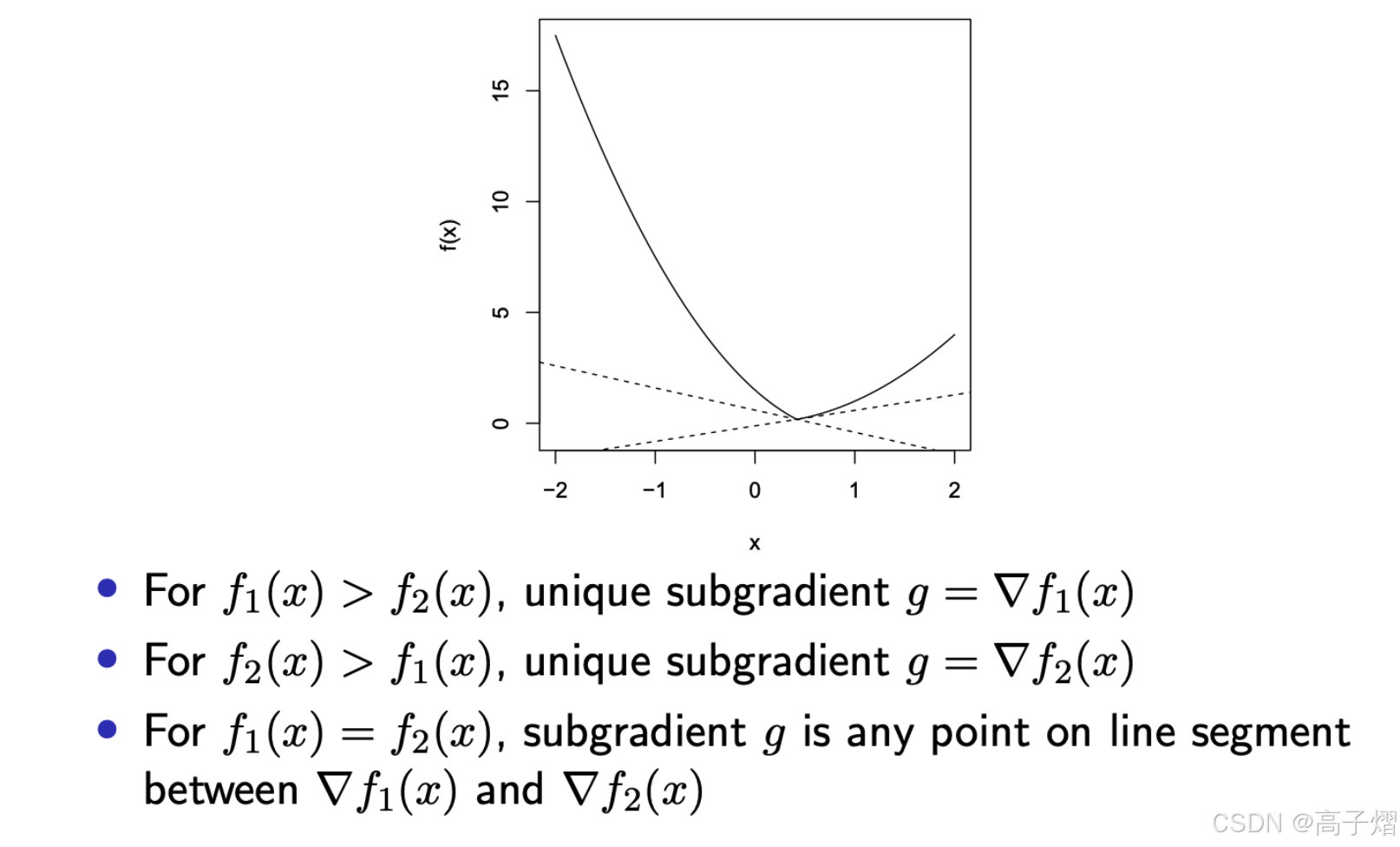
Subdifferential 所有在x 处所有次梯度的集合
δ f ( x ) = { g ∣ f ( y ) ≥ f ( x ) + g T ( y − x ) , ∀ y } \delta f(x) = \{g| f(y)\geq f(x)+g^T(y-x),\ \forall y\} δf(x)={g∣f(y)≥f(x)+gT(y−x), ∀y}
满足以下的性质:
- not empty (for convex function) 一定不为空,无论是否是可微的
- δ f ( x ) \delta f(x) δf(x)一定是一个凸集合,满足 ∀ g 1 , g 2 ∈ δ f ( x ) , θ g 1 + ( 1 − θ ) g 2 ∈ δ f ( x ) \forall g_1,g_2 \in \delta f(x), \theta g_1 +(1-\theta)g_2 \in \delta f(x) ∀g1,g2∈δf(x),θg1+(1−θ)g2∈δf(x)
- 如果f在x 处是可微的,那对应的次梯度一定就是对应的梯度,只有一个元素
- 如果 δ f ( x ) \delta f(x) δf(x)只有一个元素,那在x 处一定是可微的,而且对应的 g = ∇ f ( x ) g=\nabla f(x) g=∇f(x)
对于指示函数来说,对应的次梯度的集合为范数球 N C = { g ∣ g T ( y − x ) ≤ 0 ∀ y ∈ C } \mathcal{N}_{C}=\{g| g^T(y-x)\leq 0 \ \forall y \in C\} NC={g∣gT(y−x)≤0 ∀y∈C}
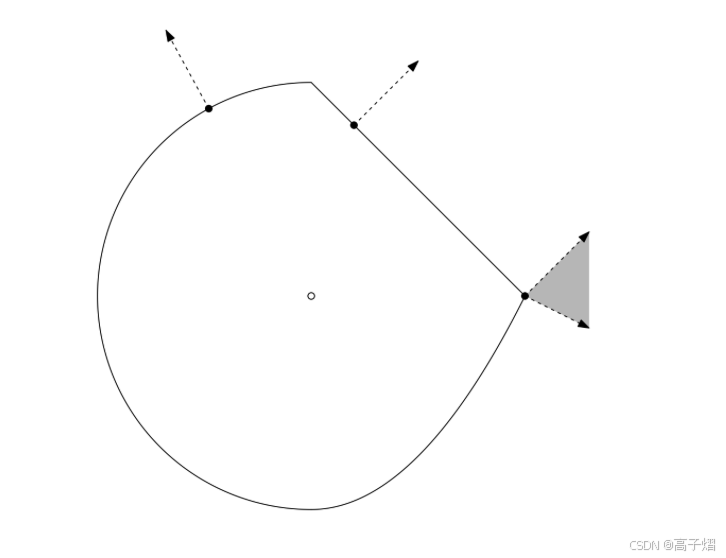
Optimality conditon under sub-gradient
1.对于无约束的条件下
For any f (convex or not)
f ( x ∗ ) = min x f ( x ) ⇔ 0 ∈ δ f ( x ∗ ) f(x^*) = \min_x f(x) \Leftrightarrow 0 \in \delta f(x^*) f(x∗)=xminf(x)⇔0∈δf(x∗)
Why? 如果 0 在x 处的sub-gradient,根据定义可以写出:
f ( y ) ≥ f ( x ∗ ) + 0 ∗ ( y − x ) , ∀ y f(y) \geq f(x^*) +0*(y-x) \ , \forall y f(y)≥f(x∗)+0∗(y−x) ,∀y
所以可以得出对应的 f ( x ∗ ) f(x^*) f(x∗)为minimize,如果f 是凸函数并且是可微的,那对应的次梯度是对应的梯度。那就是说明对应的梯度为 0, ∇ f ( x ∗ ) = 0 \nabla f(x^*)=0 ∇f(x∗)=0也是可以对应上的。
2.有约束的凸优化问题:
min x f ( x ) s.t. x ∈ C \min_x f(x) \text{ s.t. }x \in C xminf(x) s.t. x∈C
对应的最优条件是:
∇ f ( x ) ( y − x ) ≥ 0 for all y ∈ C \nabla f(x)(y-x)\geq 0 \text{ for all } y \in C ∇f(x)(y−x)≥0 for all y∈C
可以理解为: 从x 出发的任意一个点都与梯度方向的内积为正了,就是无法再继续下降了
soft-thresholding

Subgradient method
首先梯度下降是:
x ( k + 1 ) = x ( k ) − t k ∇ f ( x ( k ) ) x^{(k+1)} = x^{(k)}-t_k\nabla f(x^{(k)}) x(k+1)=x(k)−tk∇f(x(k))
类比过来的话,对应的sub-gradient descent 方法就是如下,把对应的梯度变为sub-gradient
x ( k + 1 ) = x ( k ) − t k g ( x ( k ) ) x^{(k+1)} = x^{(k)}-t_kg(x^{(k)}) x(k+1)=x(k)−tkg(x(k))
而这个 g ( x ( k ) ) ∈ δ f ( x ( k ) ) g(x^{(k)}) \in \delta f(x^{(k)}) g(x(k))∈δf(x(k))
Subgradient method is not necessarily a descent method, thus we keep track of best iterate x best ( k ) x^{(k)}_{\text{best}} xbest(k)
f ( x best ( k ) ) = min i = 0 , . . . k f ( x ( i ) ) f(x_{\text{best}}^{(k)})=\min_{i=0,...k} f(x^{(i)}) f(xbest(k))=i=0,...kminf(x(i))
Project 操作: 首先先定义一个点x 到一个凸集合的距离的函数dist
dist ( x , C ) \text{dist}(x,C) dist(x,C)
如果想找到这个距离就是一个优化问题:
min y ∈ C ∣ ∣ y − x ∣ ∣ 2 2 \min_{y \in C} ||y-x||_2^2 y∈Cmin∣∣y−x∣∣22
或者也可以表示为对应x投影到C 中的那个点 y ∗ y^* y∗和x之间的距离,而这个投影的点可以表示为:
y ∗ = argmin y ∈ C ∣ ∣ y − x ∣ ∣ 2 2 y^* = \text{argmin}_{y \in C} ||y-x||_2^2 y∗=argminy∈C∣∣y−x∣∣22
然后上述的 dist ( x , c ) \text{dist}(x,c) dist(x,c)就可以表示为: dist ( x , C ) = ∣ ∣ x − y ∗ ∣ ∣ 2 \text{dist}(x,C)=||x-y^*||^2 dist(x,C)=∣∣x−y∗∣∣2
Proximal Gradient Descent
近端梯度下降
如果现在有一个目标函数主要包括为:
f ( x ) = g ( x ) + h ( x ) f(x) = g(x)+h(x) f(x)=g(x)+h(x)
其中,g是凸的并且是可微的,但是对应h来说是一个比较简单的但是不可微的函数。但是如果直接用sub-gradient method 收敛速度太慢了,所以如何能保证与普通的梯度下降收敛速度的同时,进行更新。所以这里就要想到原始的梯度下降,首先是对原始的函数进行二次近似,然后再去就最小值去找到下一步更新的点。那这里类比一下,那我们还是把可微的g(x)进行二阶近似,保持不可微的h(x)
g ( z ) = g ( x ) + ∇ g ( x ) ( z − x ) + 1 2 t ∣ ∣ z − x ∣ ∣ 2 2 g(z) = g(x)+ \nabla g(x)(z-x)+\frac{1}{2t}||z-x||_2^2 g(z)=g(x)+∇g(x)(z−x)+2t1∣∣z−x∣∣22
总体就可以表示为 :
x + = argmin z g ( x ) + ∇ g ( x ) ( z − x ) + 1 2 t ∣ ∣ z − x ∣ ∣ 2 2 + h ( z ) = argmin z 1 2 t ∣ ∣ z − ( x − t ∇ f ( x ) ) ∣ ∣ 2 2 + h ( z ) x^+ = \text{argmin}_z g(x)+ \nabla g(x)(z-x)+\frac{1}{2t}||z-x||_2^2+h(z) \\ = \text{argmin}_z \frac{1}{2t}||z-(x-t\nabla f(x))||_2^2 +h(z) x+=argminzg(x)+∇g(x)(z−x)+2t1∣∣z−x∣∣22+h(z)=argminz2t1∣∣z−(x−t∇f(x))∣∣22+h(z)
整体解释一下,这里前一项就要保证对应的下一个点要与g 梯度下降的结果要接近,但是也要最小化 h(z)
然后我们定义一个映射函数:(近端算子)
prox t ( x ) = argmin z ∣ ∣ z − x ∣ ∣ 2 2 + h ( z ) \text{prox}_t(x) = \text{argmin}_z ||z-x||_2^2 +h(z) proxt(x)=argminz∣∣z−x∣∣22+h(z)
所以近端梯度下降就可以表示为:
x ( k + 1 ) = prox t ( x ( k ) − t k ⋅ ∇ f ( x ( k ) ) ) x^{(k+1)} = \text{prox}_t(x^{(k)}-t_k\cdot \nabla f(x^{(k)})) x(k+1)=proxt(x(k)−tk⋅∇f(x(k)))
也可以表示为另一种形式:
x ( k + 1 ) = x ( k ) − t k G k ( x ( k ) ) x^{(k+1)} = x^{(k)}-t_k G_k(x^{(k)}) x(k+1)=x(k)−tkGk(x(k))
G t ( x ) = x − prox t ( x − t ∇ g ( x ) ) t G_t(x) = \frac{x-\text{prox}_t(x-t\nabla g(x))}{t} Gt(x)=tx−proxt(x−t∇g(x))
也被叫做广义的梯度。
Proximal gradient descent 也被叫做广义的梯度下降。
当h=0,就是普通的梯度下降。
当 h = I C h =I_C h=IC就是投影梯度下降
这个时候,对应的 prox t \text{prox}_t proxt就变为了 P C P_C PC
min x ∈ C f ( x ) = min x f ( x ) + I C ( x ) prox ( x ) = argmin z 1 2 t ∣ ∣ z − x ∣ ∣ 2 2 + I C ( z ) = argmin z ∈ C ∣ ∣ z − x ∣ ∣ 2 2 = P C ( x ) \min_{x\in C} f(x) = \min_{x} f(x) +I_C(x) \\ \text{prox}(x) = \text{argmin}_z\frac{1}{2t}||z-x||^2_2 +I_C(z) \\ =\text{argmin}_{z \in C} ||z-x||_2^2 = P_C(x) x∈Cminf(x)=xminf(x)+IC(x)prox(x)=argminz2t1∣∣z−x∣∣22+IC(z)=argminz∈C∣∣z−x∣∣22=PC(x)
可以发现这个时候就是对应的那个点就是投影了。
对应的更新过程就变成了:
x ( k + 1 ) = P C ( x ( k ) − t k ∇ f ( x ( k ) ) ) x^{(k+1)} = P_C(x^{(k)}-t_k \nabla f(x^{(k)})) x(k+1)=PC(x(k)−tk∇f(x(k)))
当g=0 时,近端最小算法
Consider for h convex ( not necessarily differentiable)
min x h ( x ) \min_x h(x) xminh(x)
proximal gradient update step is just
x + = argmin z 1 2 t ∣ ∣ x − z ∣ ∣ 2 2 + h ( z ) x^+ =\text{argmin}_z \frac{1}{2t}||x-z||^2_2 +h(z) x+=argminz2t1∣∣x−z∣∣22+h(z)