DeepSpeed简介及加速模型训练
DeepSpeed是由微软开发的开源深度学习优化框架,专注于大规模模型的高效训练与推理。其核心目标是通过系统级优化技术降低显存占用、提升计算效率,并支持千亿级参数的模型训练。
官网链接:deepspeed
训练代码下载:git代码
一、DeepSpeed的核心作用
-
显存优化与高效内存管理
-
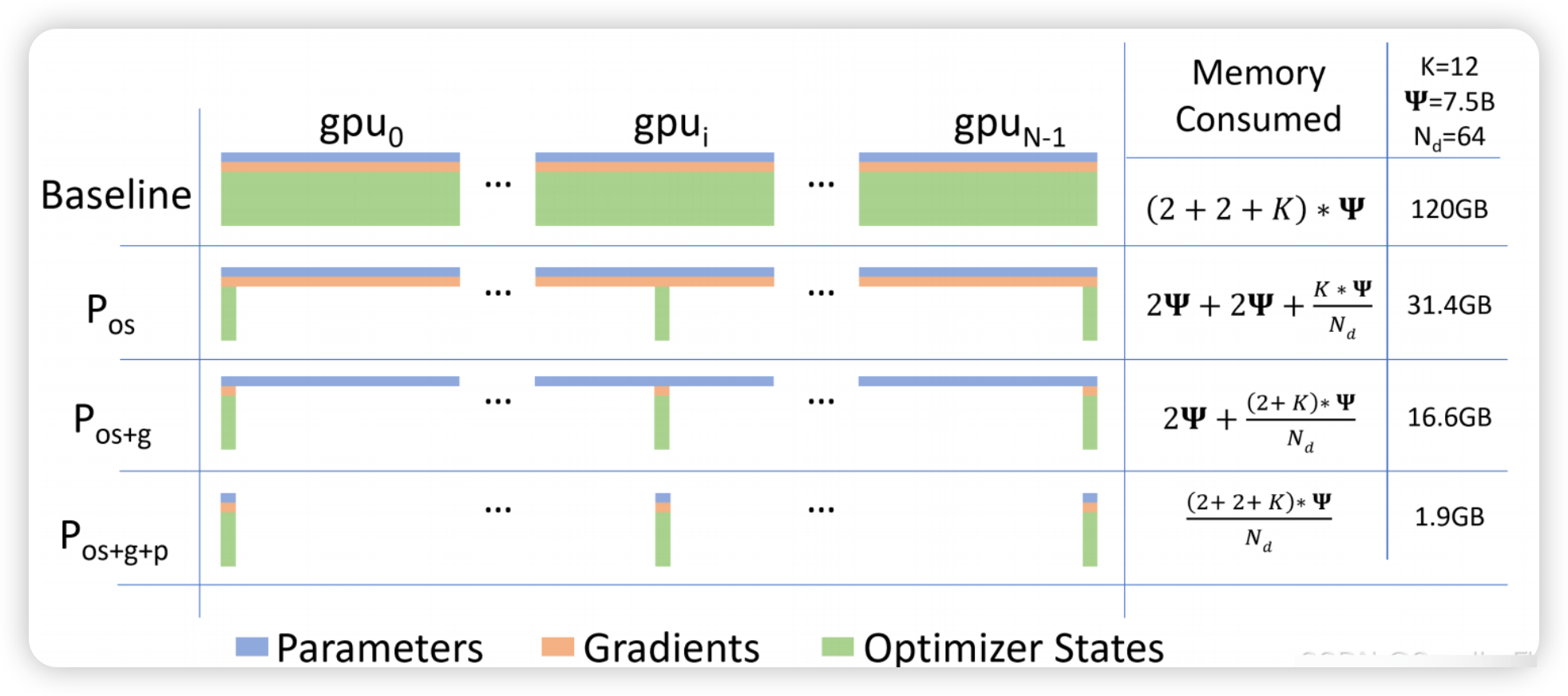
ZeRO(Zero Redundancy Optimizer)技术:通过分片存储模型状态(参数、梯度、优化器状态)至不同GPU或CPU,显著减少单卡显存占用。例如,ZeRO-2可将显存占用降低8倍,支持单卡训练130亿参数模型。
-
Offload技术:将优化器状态卸载到CPU或NVMe硬盘,扩展至TB级内存,支持万亿参数模型训练。
-
激活值重计算(Activation Checkpointing):牺牲计算时间换取显存节省,适用于长序列输入。
-
-
灵活的并行策略
-
3D并行:融合数据并行(DP)、模型并行(张量并行TP、流水线并行PP),支持跨节点与节点内并行组合,适应不同硬件架构。
-
动态批处理与梯度累积:减少通信频率,支持超大Batch Size训练。
-
-
训练加速与混合精度支持
-
混合精度训练:支持FP16/BF16,结合动态损失缩放平衡效率与数值稳定性。
-
稀疏注意力机制:针对长序列任务优化,执行效率提升6倍。
-
通信优化:支持MPI、NCCL等协议,降低分布式训练通信开销。
-
-
推理优化与模型压缩
-
低精度推理:通过INT8/FP16量化减少模型体积,提升推理速度。
-
模型剪枝与蒸馏:压缩模型参数,降低部署成本。
-
二、与pytorch 对比分析
1. 优势
-
显存效率:相比PyTorch DDP,单卡80GB GPU可训练130亿参数模型(传统方法仅支持约10亿)。
-
并行灵活性:支持3D并行组合,优于Horovod(侧重数据并行)和Megatron(侧重模型并行)。
-
生态集成:与Hugging Face Transformers、PyTorch无缝兼容,简化现有项目迁移。
-
全流程覆盖:同时优化训练与推理,而vLLM仅专注推理优化。
2. 局限性
-
配置复杂度:分布式训练需手动调整通信策略和分片参数,学习曲线陡峭(需编写JSON配置文件)。
-
硬件依赖:部分高级功能(如ZeRO-Infinity)依赖NVMe硬盘或特定GPU架构。
-
推理效率:纯推理场景下,vLLM的吞吐量更高(连续批处理优化更专精)。
三、训练用例
1、ds_config.json(deepspeed执行训练时,使用的配置文件)
- deepspeed训练模型时,不需要在代码中定义优化器,只需要在 json 文件中进行配置即可, json文件内容如下:
{"train_batch_size": 128, //所有GPU上的 单个训练批次大小 之和"gradient_accumulation_steps": 1, //梯度累积 步数"optimizer": {"type": "Adam", //选择的 优化器"params": {"lr": 0.00015 //相关学习率大小}},"zero_optimization": { //加速策略"stage":2}
}2、训练函数
- 将模型包装成 deepspeed 形式
#将模型 包装成 deepspeed 形式
model_engine, _, _, _ = deepspeed.initialize(args=args,model=model,model_parameters=model.parameters())
- 使用 deepspeed 包装后的模型 进行 反向传播和梯度更新
#使用 deepspeed 进行 反向传播和梯度更新
#反向传播
model_engine.backward(loss)#梯度更新
model_engine.step()
- 完整训练代码如下:
'''
使用命令行进行启动启动命令如下:
deepspeed ds_train.py --epochs 10 --deepspeed --deepspeed_config ds_config.json
'''import argparse
import torch
import torchvision
import deepspeed
from model_definition import load_data, CustomModelif __name__ == '__main__':#读取命令行 传递的参数parser = argparse.ArgumentParser()parser.add_argument("--local_rank", help = "local device id on current node", type = int, default=0)parser.add_argument("--epochs", type = int, default=1)parser = deepspeed.add_config_arguments(parser)args = parser.parse_args()#获取数据集train_loader, test_loader = load_data() #数据集加载器中的 batch_size的大小 = (ds_config.json中 train_batch_size/gpu数量)#获取原始模型model = CustomModel().cuda()#将模型 包装成 deepspeed 形式model_engine, _, _, _ = deepspeed.initialize(args=args,model=model,model_parameters=model.parameters())loss_fn = torch.nn.CrossEntropyLoss().cuda() # 损失函数(分类任务常用)for i in range(args.epochs):for inputs, labels in train_loader:#前向传播inputs = inputs.cuda()labels = labels.cuda()outputs = model_engine(inputs)loss = loss_fn(outputs, labels)#使用 deepspeed 进行 反向传播和梯度更新#反向传播model_engine.backward(loss)#梯度更新model_engine.step()model_engine.save_checkpoint('./ds_models', i)#模型保存torch.save(model_engine.module.state_dict(),'deepspeed_train_model.pth')3、模型评估
import argparse
import torch
import torchvision
import deepspeed
from model_definition import load_data, CustomModel
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import numpy as np
import matplotlib.pyplot as plt# 1. 定义数据转换(预处理)
transform = transforms.Compose([transforms.ToTensor(), # 转为Tensor格式(自动归一化到0-1)transforms.Normalize((0.1307,), (0.3081,)) # 标准化(MNIST的均值和标准差)
])test_data = datasets.MNIST(root='./data',train=False, # 测试集transform=transform)#获取数据集
train_loader, test_loader = load_data()model = CustomModel()
model.load_state_dict(torch.load('deepspeed_train_model.pth'))#评估
model.eval() # 设置为评估模式
correct = 0
total = 0with torch.no_grad(): # 不计算梯度(节省内存)for images, labels in test_loader:images, labels = images, labelsoutputs = model(images)_, predicted = torch.max(outputs.data, 1) # 取概率最大的类别total += labels.size(0)correct += (predicted == labels).sum().item()print(f"测试集准确率: {100 * correct / total:.2f}%")# 随机选择一张测试图片
index = np.random.randint(0,1000) # 可以修改这个数字试不同图片
test_image, true_label = test_data[index]
test_image = test_image.unsqueeze(0) # 增加批次维度# 预测
with torch.no_grad():output = model(test_image)
predicted_label = torch.argmax(output).item()print(f"预测: {predicted_label}, 真实: {true_label}")# 显示结果
plt.imshow(test_image.cpu().squeeze(), cmap='gray')
plt.title(f"预测: {predicted_label}, 真实: {true_label}")
plt.show()