凸优化理论-进阶方法
Advanced topics
写在前面,本文主要介绍了凸优化理论中比较进阶的内容,包括坐标下降法,对偶分解,交替乘子法(ADMM),共识ADMM等内容。
Coordinate Descent
坐标下降法,这是一种非常高效且可扩展的一类优化方法,也被称为: coordinatewise minimization
Q1 :一个凸且可微的函数 f : R n → R f:\mathbb{R}^n \rightarrow \mathbb{R} f:Rn→R,如果游一个点在各个坐标轴下都是最小的,那这个点是否是全局最优点?
而这里就可以形式化表达为:
f ( x + δ e i ) ≥ f ( x ) for all δ , i ⇒ f ( x ) = min z f ( z ) ? f(x+\delta e_i) \geq f(x) \text{ for all } \delta,i \Rightarrow f(x) = \min_z f(z)? f(x+δei)≥f(x) for all δ,i⇒f(x)=zminf(z)?
这里的 e i e_i ei 表示的为第 i个方向上的单位向量。整体表示为:在任意坐标轴方向移动后的得到的值都要比原始点大。
**A1:**是的,因为满足上述的式子,则满足下述的式子,即各个方向上的偏导数为 0,能推出对应的梯度为 0,根据一阶最优性,因为是凸的,所以一定是全局最优点。
∇ f ( x ) = 0 \nabla f(x) = 0 ∇f(x)=0
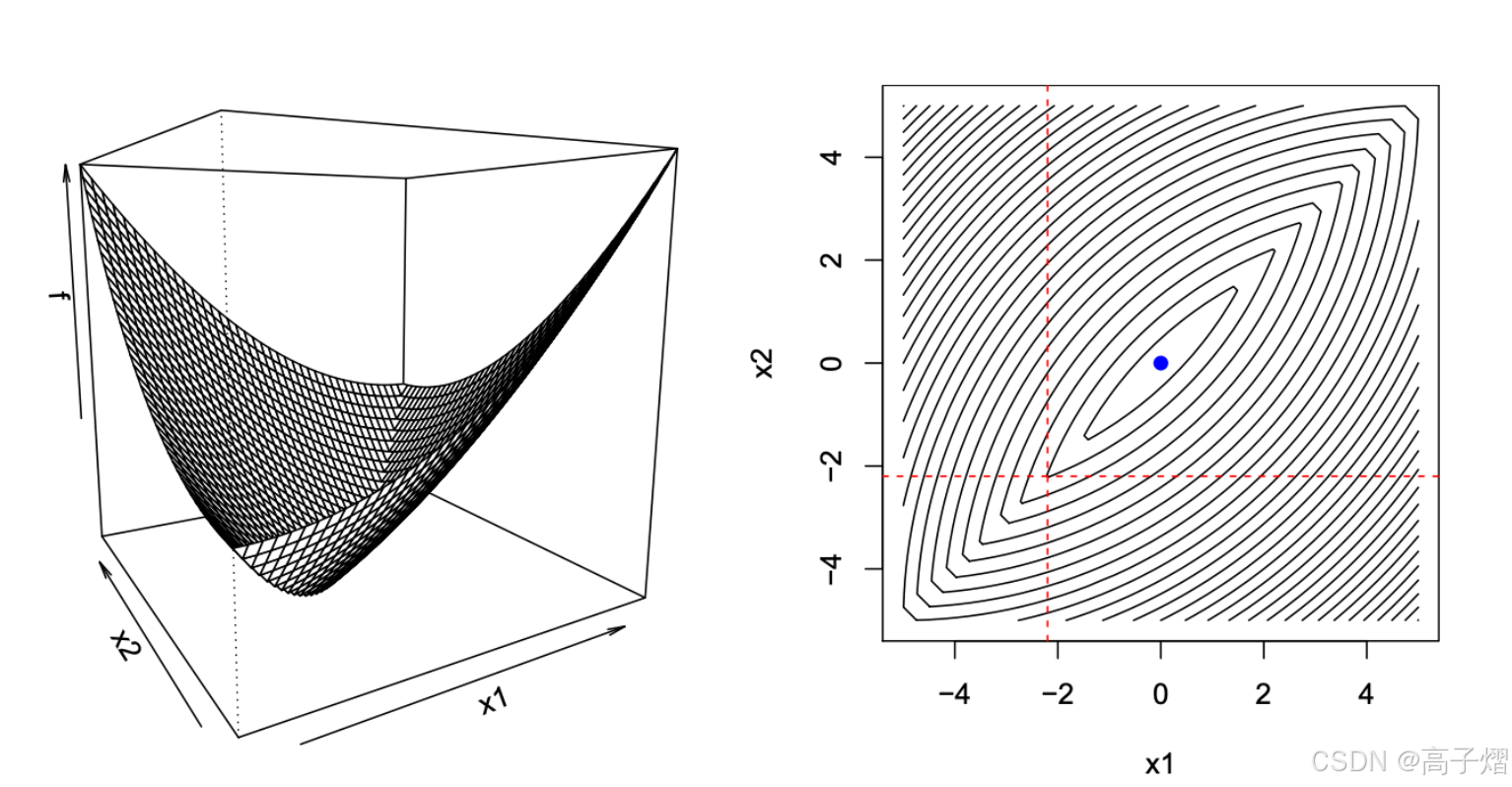
Q2:相同条件下,但是对应的 f f f为凸的,但是不可微,是否成立?
A2: 不,可以看一下下图的例子,这里虽然沿着x1,x2 的移动方向上均满足这个条件,可以发现沿着对角线的方向上还可以找到更小的全局最优点。因为这里的最优点就要满足sub-gradient 的最优性:
0 ∈ ∂ f ( x ) 0 \in \partial{f(x)} 0∈∂f(x)
Q3: f ( x ) = g ( x ) + ∑ i = 1 n h i ( x i ) f(x) = g(x)+\sum_{i=1}^n h_i(x_i) f(x)=g(x)+∑i=1nhi(xi),其中g 是凸且光滑的(可微),而 h i ( x ) h_i(x) hi(x)是凸的 (这里的非光滑的部分叫做可分离或者不可微的条件可以分解到各个坐标轴的方向上)
A3: 是的,因为不可微性可以分解到不同的坐标轴上,具体证明过程如下:
首先考虑一个在一个坐标轴的方向进行移动(Fixed x and i )
f ( x + δ e i ) = g ( x + δ e i ) + ∑ i ≠ j h j ( x j ) + h i ( x i + δ e i ) f(x+\delta e_i) = g(x+\delta e_i)+\sum_{i \neq j}h_j(x_j)+h_i(x_i+\delta e_i) f(x+δei)=g(x+δei)+i=j∑hj(xj)+hi(xi+δei)
f ( y ) − f ( x ) = g ( y ) − g ( x ) + ∑ i = 1 n [ h i ( y i ) − h i ( x i ) ] ≥ ∑ i = 1 n [ ∇ i g ( x ) ( y i − x i ) + h i ( y i ) − h i ( x i ) ] ≥ 0 f(y)-f(x)=g(y)-g(x)+\sum_{i=1}^n[h_i(y_i)-h_i(x_i)] \\ \geq \sum_{i=1}^n[\nabla_ig(x)(y_i-x_i)+h_i(y_i)-h_i(x_i)] \geq 0 f(y)−f(x)=g(y)−g(x)+i=1∑n[hi(yi)−hi(xi)]≥i=1∑n[∇ig(x)(yi−xi)+hi(yi)−hi(xi)]≥0
所以这里定义坐标下降:
min x f ( x ) where f ( x ) = g ( x ) + ∑ i = 1 n h i ( x i ) \min_xf(x) \text{ where } f(x) = g(x)+\sum_{i=1}^nh_i(x_i) xminf(x) where f(x)=g(x)+i=1∑nhi(xi)
对于这样的的问题,我们可以利用坐标下降法,首先选取一个初始点 x ( 0 ) ∈ R n x^{(0)} \in \mathbb{R}^n x(0)∈Rn,
x i ( k ) = argmin x i f ( x 1 ( k ) , x 2 ( k ) , ⋯ , x i , x i + 1 ( k − 1 ) , ⋯ , x n ( k − 1 ) ) x_i^{(k)} = \text{argmin}_{x_i} f(x_1^{(k)},x_2^{(k)},\cdots,x_i,x_{i+1}^{(k-1)},\cdots,x_n^{(k-1)}) xi(k)=argminxif(x1(k),x2(k),⋯,xi,xi+1(k−1),⋯,xn(k−1))
for k=1,2,3…
这里需要注意一个点:因为在更新第i 个坐标的时候,1到i-1 的坐标已经更新完了,需要用上。
- 这里坐标更新的顺序,只要满足是{1,2,3,…,n}的一个排列就行了,就是要循环的更新,不能只更新少数。
- 也可以一次更新一个块,类似于一次更新{1,2,3,4}一起更新
- 一次更新一个是必要的,如果全部更新了不能保证收敛
Conrdinate descent in statistics and ML
为什么在机器学习和统计学里要用坐标下降法?
- Very simple adn easy to implement
- Careful implementations can achieve state-of-the-art
- Scalable,e.g.,don’t need to keep full data in memory
对于一个光滑的函数 f f f,坐标下降法的迭代过程如下: 坐标梯度下降法
x i ( k ) = x i ( k − 1 ) − t k i ∇ i f ( x 1 ( k ) , x 2 ( k ) , . . . , x i , x i + 1 ( k − 1 ) , x n ( k − 1 ) ) i = 1 , . . , n for k = 1 , 2 , 3 x_i^{(k)} = x_i^{(k-1)}-t_ki \nabla_if(x_1^{(k)},x_2^{(k)},...,x_i,x_{i+1}^{(k-1)},x_n^{(k-1)}) \ \ i=1,..,n \text{ for } k=1,2,3 xi(k)=xi(k−1)−tki∇if(x1(k),x2(k),...,xi,xi+1(k−1),xn(k−1)) i=1,..,n for k=1,2,3
当 f = g + h f=g+h f=g+h,其中 g g g为光滑, h = ∑ i = 1 n h i h=\sum_{i=1}^nh_i h=∑i=1nhi
x i ( k ) = prox h i , t k i ( x i ( k − 1 ) − t k ∇ i f ( x 1 ( k ) , x 2 ( k ) , . . . , x i , x i + 1 ( k − 1 ) , x n ( k − 1 ) ) ) x_i^{(k)} = \text{prox}_{h_i,t_{ki}}(x_i^{(k-1)}-t_k \nabla_if(x_1^{(k)},x_2^{(k)},...,x_i,x_{i+1}^{(k-1)},x_n^{(k-1)})) xi(k)=proxhi,tki(xi(k−1)−tk∇if(x1(k),x2(k),...,xi,xi+1(k−1),xn(k−1)))
Dual Decompostion
1. Dual ascent(对偶上升法)
min x f ( x ) subject to A x = b \min_x f(x) \text{ subject to} Ax=b xminf(x) subject toAx=b
首先写出拉格朗日形式:
L ( x , u ) = f ( x ) + u T ( A x − b ) L(x,u) = f(x)+u^T(Ax-b) L(x,u)=f(x)+uT(Ax−b)
max u min x f ( x ) + u T ( A x − b ) \max_u \min_x f(x)+u^T(Ax-b) umaxxminf(x)+uT(Ax−b)
具体解的过程可以写成 :
x ( k ) = x ( k − 1 ) − t k ∇ x L ( x , u k − 1 ) u ( k ) = u ( k − 1 ) + t k ∇ u L ( x ( k ) , u ) where ∇ u L ( x ( k ) , u ) = A x ( k ) − b x^{(k)} = x^{(k-1)}-t_k \nabla_{x} L(x,u^{{k-1}}) \\ u^{(k)} = u^{(k-1)}+ t_k \nabla_{u} L(x^{(k)},u) \text{ where }\nabla_u L(x^{(k)},u)=Ax^{(k)}-b x(k)=x(k−1)−tk∇xL(x,uk−1)u(k)=u(k−1)+tk∇uL(x(k),u) where ∇uL(x(k),u)=Ax(k)−b
这是一种表示方式,另一种表示方式,原问题是式(10),而对应的对偶问题为:
max u g ( u ) = − f ∗ ( − A T u ) − b T u \max_u g(u)= -f^*(-A^Tu)-b^Tu umaxg(u)=−f∗(−ATu)−bTu
其中对应的 f ∗ f^* f∗为 f f f的共轭函数,而对偶问题是关于u 的仿射函数(线性的),所以此处为了得到最大值,我要进行梯度上升,首先求救对应的梯度:
∂ g ( u ) = A x − b where x ∈ argmin z f ( z ) + u T A z \partial g(u) = Ax-b \text{ where } x \in \text{argmin}_z f(z)+u^TAz ∂g(u)=Ax−b where x∈argminzf(z)+uTAz
根据这个式子我们就可以得到:
x ( k ) ∈ argmin x f ( x ) + ( u ( k − 1 ) ) T A x u ( k ) = u ( k − 1 ) + t k ∗ ( A x ( k ) − b ) x^{(k)} \in \text{argmin}_x f(x)+(u^{(k-1)})^TAx \\ u^{(k)} =u^{(k-1)}+t_k*(Ax^{(k)}-b) x(k)∈argminxf(x)+(u(k−1))TAxu(k)=u(k−1)+tk∗(Ax(k)−b)
如果对应的f 为严格凸的,我们就可以表示为:
x ( k ) = argmin x f ( x ) + ( u ( k − 1 ) ) T A x u ( k ) = u ( k − 1 ) + t k ∗ ( A x ( k ) − b ) x^{(k)} = \text{argmin}_x f(x)+(u^{(k-1)})^TAx \\ u^{(k)} =u^{(k-1)}+t_k*(Ax^{(k)}-b) x(k)=argminxf(x)+(u(k−1))TAxu(k)=u(k−1)+tk∗(Ax(k)−b)
2. 对偶分解
首先说明什么是可分解性:
min x f ( x ) = ∑ i = 1 n f i ( x i ) \min_x f(x) = \sum_{i=1}^{n}f_i(x_i) xminf(x)=i=1∑nfi(xi)
对于上述述的这类优化问题,我们就可以单独去求解然后再加和,如下式所示:
min x f ( x ) = ∑ i = 1 n min x i f i ( x i ) \min_x f(x) = \sum_{i=1}^n \min_{x_i}f_i(x_i) xminf(x)=i=1∑nximinfi(xi)
这类被叫做可分解性。然后再来说明什么是对偶分解:
原问题为:
min x ∑ i = 1 B f i ( x i ) subject to A x = b \min_x \sum_{i=1}^B f_i(x_i) \text{ subject to } Ax=b xmini=1∑Bfi(xi) subject to Ax=b
x = ( x 1 , x 2 , . . . , x B ) ∈ R n x=(x_1,x_2,...,x_B)\in \mathbb{R}^n x=(x1,x2,...,xB)∈Rn被分解为B块变量,然后我们把约束条件中的A 也进行分解:
A = [ A 1 , . . . . , A B ] where A i ∈ R m × n i A=[A_1,....,A_B] \text{ where }A_i \in \mathbb{R}^{m \times n_i} A=[A1,....,AB] where Ai∈Rm×ni
那原问题就可以写成了
min x ∑ i = 1 B f i ( x i ) s.t. ∑ i = 1 B A i x i = b \min_x \sum_{i=1}^B f_i(x_i) \\ \text{s.t.} \sum_{i=1}^B A_ix_i = b xmini=1∑Bfi(xi)s.t.i=1∑BAixi=b
这样原问题的约束条件仍然是耦合在一起的,所以还是不能进行分解,但是转换为拉格朗日问题之后可以发现:
max u min x L ( x , u ) = ∑ i = 1 B f i ( x i ) + u T ∑ i = 1 B A i x i − b \max_u \min_x L(x,u) = \sum_{i=1}^B f_i(x_i)+u^T \sum_{i=1}^B A_ix_i-b \\ umaxxminL(x,u)=i=1∑Bfi(xi)+uTi=1∑BAixi−b
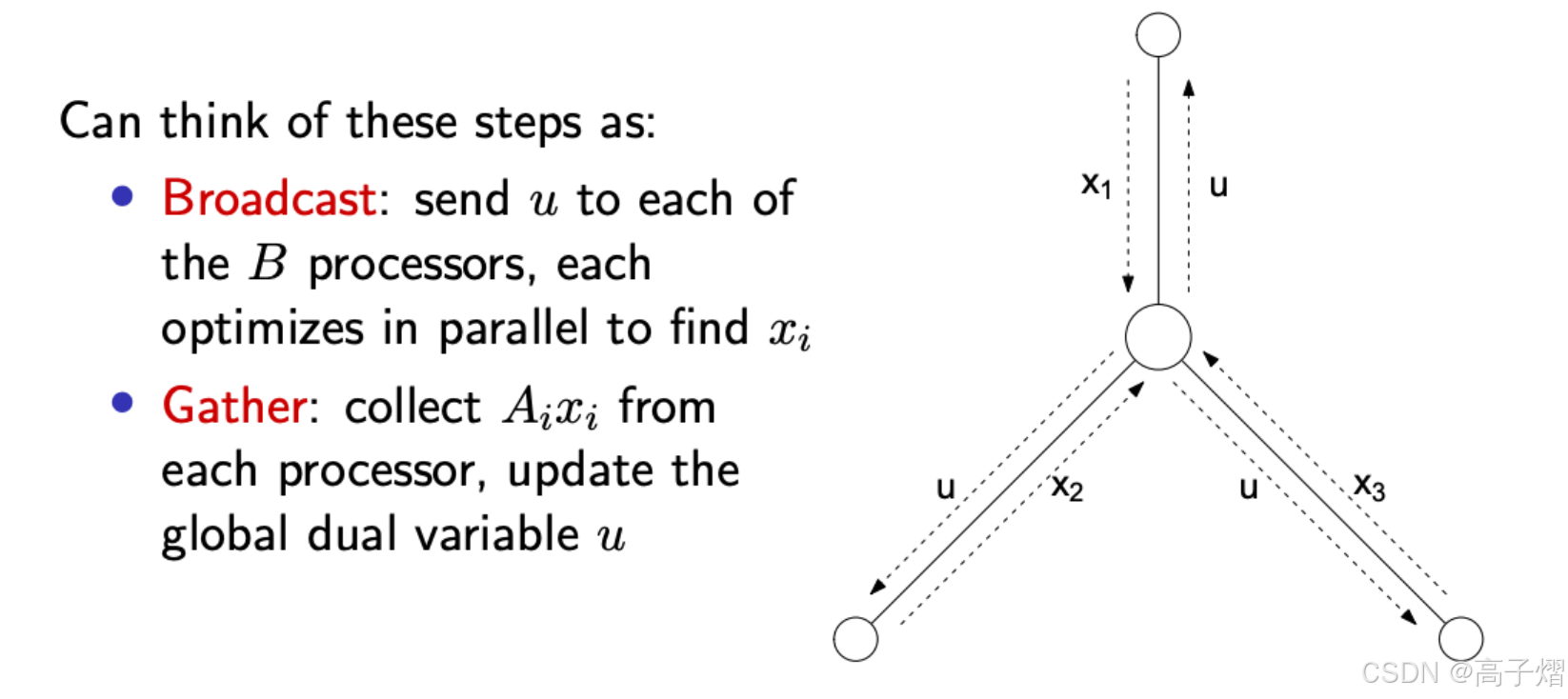
对偶上升法第一步:
x ( k ) = argmin x L ( x , u ( k − 1 ) ) = argmin x ∑ i = 1 B ( f i ( x i ) + u T ( A i x i − b ) ) x^{(k)} = \text{argmin}_x L(x,u^{(k-1)}) \\ = \text{argmin}_x \sum_{i=1}^B(f_i(x_i)+u^T(A_ix_i-b)) x(k)=argminxL(x,u(k−1))=argminxi=1∑B(fi(xi)+uT(Aixi−b))
所以我们可以发现:
x + ∈ argmin x ∑ i = 1 B f i ( x i ) + u T ∑ i = 1 B A i x i − b x i + ∈ argmin x i f i ( x i ) + u T ∑ i = 1 B A i x i − b x i ( k ) ∈ argmin x i f i ( x i ) + ( u ( k − 1 ) ) T ∑ i = 1 B A i x i − b x^{+} \in \text{argmin}_x \sum_{i=1}^B f_i(x_i)+ u^T \sum_{i=1}^B A_ix_i-b \\ x_i^+ \in \text{argmin}_{x_i}f_i(x_i)+ u^T \sum_{i=1}^B A_ix_i-b \\ x_i^{(k)} \in \text{argmin}_{x_i}f_i(x_i)+ (u^{(k-1)})^T \sum_{i=1}^B A_ix_i-b x+∈argminxi=1∑Bfi(xi)+uTi=1∑BAixi−bxi+∈argminxifi(xi)+uTi=1∑BAixi−bxi(k)∈argminxifi(xi)+(u(k−1))Ti=1∑BAixi−b
第二步更新对偶变量:
u ( k ) = u ( k − 1 ) + t k ( ∑ i = 1 B A i x i ( k ) − b ) u^{(k)} = u^{(k-1)}+t_k(\sum_{i=1}^B A_ix_i^{(k)}-b) u(k)=u(k−1)+tk(i=1∑BAixi(k)−b)
这样我们就可以把第一步对原始变量的更新分不到不同的节点上,进行并行计算,然后在中心节点再进行汇总
 ### 3. 增广的拉格朗日
### 3. 增广的拉格朗日
min x f ( x ) + ρ 2 ∣ ∣ A x − b ∣ ∣ 2 2 s.t. A x = b \min_x f(x)+ \frac{\rho}{2}||Ax-b||^2_2 \\ \text{s.t. } Ax=b xminf(x)+2ρ∣∣Ax−b∣∣22s.t. Ax=b
拉格朗日函数可以写成:
L ( x , u ) = f ( x ) + ρ 2 ∣ ∣ A x − b ∣ ∣ 2 2 + u T ( A x − b ) L(x,u) = f(x)+ \frac{\rho}{2}||Ax-b||^2_2 +u^T(Ax-b) L(x,u)=f(x)+2ρ∣∣Ax−b∣∣22+uT(Ax−b)
如果A是满秩矩阵,那原始问题就变为强凸问题,对偶梯度上升可以写为:
x ( k ) = argmin x f ( x ) + ρ 2 ∣ ∣ A x − b ∣ ∣ 2 2 + ( u ( k − 1 ) ) T ( A x − b ) u ( k ) = u ( k − 1 ) + ρ ( A x ( k ) − b ) x^{(k)} = \text{argmin}_x f(x)+ \frac{\rho}{2}||Ax-b||^2_2 +(u^{(k-1)})^T(Ax-b) \\ u^{(k)} = u^{(k-1)} + \rho(Ax^{(k)}-b) x(k)=argminxf(x)+2ρ∣∣Ax−b∣∣22+(u(k−1))T(Ax−b)u(k)=u(k−1)+ρ(Ax(k)−b)
这里发现对偶变量的更新的步长变为了 ρ \rho ρ Why?
因为 x ( k ) x^{(k)} x(k)是最小化拉格朗日函数 L ( x , u ) L(x,u) L(x,u),根据一阶最优条件:
0 ∈ ∂ ( f ( x ( k ) ) + A T ( u ( k − 1 ) + ρ ( A x ( k ) − b ) ) = ∂ f ( x ( k ) ) + A T u ( k ) 0 \in \partial(f(x^{(k)}) +A^T(u^{(k-1)}+\rho(Ax^{(k)}-b)) \\ = \partial f(x^{(k)})+A^Tu^{(k)} 0∈∂(f(x(k))+AT(u(k−1)+ρ(Ax(k)−b))=∂f(x(k))+ATu(k)
增广的拉格朗日函数
- Advantage: augmented Lagrangian gives better convergence
- Disadvantage: lose decomposability
4. ADMM
Alternating direction method of multipliers(交替乘子法)
min x , z f ( x ) + g ( z ) s.t. A x + B z = c \min_{x,z} f(x)+g(z) \\ \text{s.t.} Ax+Bz=c x,zminf(x)+g(z)s.t.Ax+Bz=c
写成增广的拉格朗日:
L ( x , z , u ) = f ( x ) + g ( z ) + ρ 2 ∣ ∣ A x + B z − c ∣ ∣ 2 2 + u T ( A x + B z − c ) L(x,z,u) = f(x)+g(z)+\frac{\rho}{2}||Ax+Bz-c||_2^2+u^T(Ax+Bz-c) L(x,z,u)=f(x)+g(z)+2ρ∣∣Ax+Bz−c∣∣22+uT(Ax+Bz−c)
ADMM 的迭代过程:
x ( k ) = argmin x L ( x , z ( k − 1 ) , u ( k − 1 ) ) z ( k ) = argmin z L ( x ( k ) , z , u ( k − 1 ) ) u ( k ) = u ( k − 1 ) + ρ ( A x ( k ) + B x ( k ) − c ) x^{(k)} = \text{argmin}_x L(x,z^{(k-1)},u^{(k-1)}) \\ z^{(k)} = \text{argmin}_z L(x^{(k)},z,u^{(k-1)}) \\ u^{(k)} = u^{(k-1)} + \rho (Ax^{(k)}+Bx^{(k)}-c) x(k)=argminxL(x,z(k−1),u(k−1))z(k)=argminzL(x(k),z,u(k−1))u(k)=u(k−1)+ρ(Ax(k)+Bx(k)−c)
部分方法也进行联合优化:
x ( k ) , z ( k ) = argmin x , z L ( x , z , u ( k − 1 ) ) x^{(k)},z^{(k)} = \text{argmin}_{x,z} L(x,z,u^{(k-1)}) x(k),z(k)=argminx,zL(x,z,u(k−1))
收敛性证明:
- Residual convergence: r ( k ) = A x k + B x ( k ) − c → 0 r^{(k)}=Ax^{k}+Bx^{(k)}-c \rightarrow 0 r(k)=Axk+Bx(k)−c→0满足原始问题的可行域(约束条件)
- Objective convergence: f ( x ( k ) ) + g ( z ( k ) ) → f ∗ + g ∗ f(x^{(k)})+g(z^{(k)}) \rightarrow f^*+g^* f(x(k))+g(z(k))→f∗+g∗,满足原始问题的目标函数
- Dual convergence: u ( k ) → u ∗ u^{(k)} \rightarrow u^* u(k)→u∗ 对偶问题的最优解
Scaled form: w = u / ρ w=u/\rho w=u/ρ,这样拉格朗日函数就变为了:
L ρ ( x , z , w ) = f ( x ) + g ( z ) + ρ 2 ∣ ∣ A x + B z − c + w ∣ ∣ 2 2 − ρ 2 ∣ ∣ w ∣ ∣ 2 2 L_{\rho}(x,z,w) = f(x)+g(z)+\frac{\rho}{2}||Ax+Bz-c+w||_2^2-\frac{\rho}{2}||w||_2^2 Lρ(x,z,w)=f(x)+g(z)+2ρ∣∣Ax+Bz−c+w∣∣22−2ρ∣∣w∣∣22
ADMM 的更新过程如下:
x ( k ) = argmin x f ( x ) + ρ 2 ∣ ∣ A x + B z ( k − 1 ) − c + w ( k − 1 ) ∣ ∣ 2 2 z ( k ) = argmin z g ( z ) + ρ 2 ∣ ∣ A x ( k ) + B z − c + w ( k − 1 ) ∣ ∣ 2 2 w ( k ) = w ( k − 1 ) + A x k + B x k − c x^{(k)} = \text{argmin}_x f(x)+\frac{\rho}{2}||Ax+Bz^{(k-1)}-c+w^{(k-1)}||_2^2 \\ z^{(k)} = \text{argmin}_z g(z)+\frac{\rho}{2}||Ax^{(k)}+Bz-c+w^{(k-1)}||_2^2 \\ w^{(k)} = w^{(k-1)}+Ax^{k}+Bx^{k}-c x(k)=argminxf(x)+2ρ∣∣Ax+Bz(k−1)−c+w(k−1)∣∣22z(k)=argminzg(z)+2ρ∣∣Ax(k)+Bz−c+w(k−1)∣∣22w(k)=w(k−1)+Axk+Bxk−c
这样 w w w就可以写成如下的形式:
w ( k ) = w ( 0 ) + ∑ i = 1 k ( A x ( i ) + B x ( i ) − c ) w^{(k)} = w^{(0)} +\sum_{i=1}^k(Ax^{(i)}+Bx^{(i)}-c) w(k)=w(0)+i=1∑k(Ax(i)+Bx(i)−c)
Reminder:
min x f ( x ) + g ( z ) ⟺ min x , z f ( x ) + g ( z ) s.t. x − z = 0 \min_x f(x)+g(z) \Longleftrightarrow \min_{x,z} f(x)+g(z) \text{ s.t. } x-z=0 xminf(x)+g(z)⟺x,zminf(x)+g(z) s.t. x−z=0
5. Consensus ADMM (共识ADMM)
考虑一个问题的形式:
min x ∑ i B f i ( x ) \min_x \sum_i^Bf_i(x) xmini∑Bfi(x)
共识ADMM 可以将上述问题转换为:(分布式优化问题)
min x 1 , . . . , x B , x ∑ i B f i ( x i ) s.t. x i = x , ∀ i \min_{x_1,...,x_B,x}\sum_i^Bf_i(x_i) \quad \text{s.t.}\quad x_i =x,\forall i x1,...,xB,xmini∑Bfi(xi)s.t.xi=x,∀i
这样就把原问题转变为了一个可分解的ADMM问题,首先写出对应的增广的拉格朗日函数的形式:
L ( x 1 , . . . , x B , x , w i ) = ∑ i B ( f i ( x i ) + ρ 2 ∣ ∣ x i − x + w i ∣ ∣ 2 2 + ρ 2 ∑ i B ∣ ∣ w i ∣ ∣ 2 2 ) L(x_1,...,x_B,x,w_i) = \sum_i^B(f_i(x_i)+\frac{\rho}{2}||x_i-x+w_i||_2^2+\frac{\rho}{2}\sum_i^B||w_i||_2^2) L(x1,...,xB,x,wi)=i∑B(fi(xi)+2ρ∣∣xi−x+wi∣∣22+2ρi∑B∣∣wi∣∣22)
上述的这个问题是可以分解的问题,就可以单独的计算对应的 x i x_i xi,具体的计算过程如下:
x i ( k + 1 ) = argmin x i f i ( x i ) + ρ 2 ∣ ∣ x i − x ( k ) + w i ( k ) ∣ ∣ 2 2 , i = 1 , . . . , B x ( k + 1 ) = 1 B ∑ i B ( x i ( k + 1 ) + w i ( k ) ) w i ( k + 1 ) = w i ( k ) + x i ( k + 1 ) − x ( k + 1 ) x_i^{(k+1)} = \text{argmin}_{x_i} f_i(x_i)+\frac{\rho}{2}||x_i-x^{(k)}+w_i^{(k)}||_2^2 ,\quad i=1,...,B\\ x^{(k+1)}= \frac{1}{B}\sum_i^B(x_i^{(k+1)}+w_i^{(k)}) \\ w_i^{(k+1)}=w_i^{(k)}+x_i^{(k+1)}-x^{(k+1)} xi(k+1)=argminxifi(xi)+2ρ∣∣xi−x(k)+wi(k)∣∣22,i=1,...,Bx(k+1)=B1i∑B(xi(k+1)+wi(k))wi(k+1)=wi(k)+xi(k+1)−x(k+1)
其中第二行的式子是通过对上述公式直接求导即可,因为对于 x x x 来说就是一个二次函数,是凸的,所以可以直接求导=0 即可,过程可以表示为:
∇ x L ( x 1 ( k + 1 ) , . . . , x B ( k + 1 ) , x , w i ( k ) ) = ∑ i B − ρ ( x i ( k + 1 ) − x + w i ( k ) ) = 0 B x = ∑ i B ( x i ( k + 1 ) + w i ( k ) ) x = 1 B ∑ i B ( x i ( k + 1 ) + w i ( k ) ) \nabla_xL(x_1^{(k+1)},...,x_B^{(k+1)},x,w_i^{(k)}) = \sum_i^B-\rho(x_i^{(k+1)}-x+w_i^{(k)})=0\\ Bx =\sum_i^B(x^{(k+1)}_i+w_i^{(k)})\\ x = \frac{1}{B}\sum_i^B(x^{(k+1)}_i+w_i^{(k)}) ∇xL(x1(k+1),...,xB(k+1),x,wi(k))=i∑B−ρ(xi(k+1)−x+wi(k))=0Bx=i∑B(xi(k+1)+wi(k))x=B1i∑B(xi(k+1)+wi(k))
第三行对应的为scalable 增广拉格朗日函数对应的对偶上升法。然后我们再具体看一下式(43)对应的变量 x ( k + 1 ) x^{(k+1)} x(k+1)
x ( k + 1 ) = 1 B ∑ i B ( x i ( k + 1 ) ) + 1 B ∑ i B ( w i ( k ) ) x ( k + 1 ) = x ˉ ( k + 1 ) + w ˉ ( k ) x^{(k+1)} = \frac{1}{B} \sum_i^B(x_i^{(k+1)})+ \frac{1}{B}\sum_i^B(w_i^{(k)}) \\ x^{(k+1)} = \bar{x}^{(k+1)}+\bar{w}^{(k)} x(k+1)=B1i∑B(xi(k+1))+B1i∑B(wi(k))x(k+1)=xˉ(k+1)+wˉ(k)
这里我们分析一下为什么每次迭代的过程中,对应的 ∑ i B ( w i ( k ) ) = 0 \sum_i^B(w_i^{(k)})=0 ∑iB(wi(k))=0:
B x ( k + 1 ) = B ∗ 1 B ∑ i B ( x i ( k + 1 ) + w i ( k ) ) = ∑ i B ( x i ( k + 1 ) + w i ( k ) ) ∑ i B w i ( k + 1 ) = ∑ i B w i ( k ) + ∑ i B x i ( k + 1 ) − B x ( k + 1 ) 所以发现了就可以消掉了,所以原式是: ∑ i B w i ( k + 1 ) = 0 Bx^{(k+1)} = B*\frac{1}{B}\sum_i^B(x_i^{(k+1)}+w_i^{(k)}) =\sum_i^B(x_i^{(k+1)}+w_i^{(k)})\\ \sum_i^B w_i^{(k+1)} = \sum_i^B w_i^{(k)} + \sum_i^B x_i^{(k+1)}-Bx^{(k+1)}\\ \text{所以发现了就可以消掉了,所以原式是:}\\ \sum_i^B w_i^{(k+1)} = 0 Bx(k+1)=B∗B1i∑B(xi(k+1)+wi(k))=i∑B(xi(k+1)+wi(k))i∑Bwi(k+1)=i∑Bwi(k)+i∑Bxi(k+1)−Bx(k+1)所以发现了就可以消掉了,所以原式是:i∑Bwi(k+1)=0
所以发现了,在更新的过程中其中对偶变量的均值为 0,所以对应的共识变量的更新就可以写为:
x ( k + 1 ) = x ˉ ( k + 1 ) x^{(k+1)}=\bar{x}^{(k+1)} x(k+1)=xˉ(k+1)
这样的话,就可以把原来的迭代过程转变为:
x i ( k + 1 ) = argmin x i f i ( x i ) + ρ 2 ∣ ∣ x i − x ˉ ( k ) + w i ( k ) ∣ ∣ 2 2 w i ( k + 1 ) = w i ( k ) + x i ( k + 1 ) + x ˉ ( k + 1 ) x_i^{(k+1)} = \text{argmin}_{x_i} f_i(x_i) + \frac{\rho}{2}||x_i-\bar{x}^{(k)}+w_i^{(k)}||_2^2 \\ w_i^{(k+1)} = w_i^{(k)}+x_i^{(k+1)}+\bar{x}^{(k+1)} xi(k+1)=argminxifi(xi)+2ρ∣∣xi−xˉ(k)+wi(k)∣∣22wi(k+1)=wi(k)+xi(k+1)+xˉ(k+1)
Intuition:直观上来理解一下ADMM 的过程
整体上,就是最小化 f i ( x i ) f_i(x_i) fi(xi)的同时,使用 l 2 \mathcal{l}_2 l2正则化,让每个 x i x_i xi拉到 x ˉ \bar{x} xˉ
如果 x i > x ˉ x_i >\bar{x} xi>xˉ那对应的 w i w_i wi就会增加。
所以下一步的正则项就会把 x i x_i xi拉得离 x ˉ \bar{x} xˉ更近。
6. General consensus ADMM
Consider a problem of the form: min x ∑ i B f i ( a i T x + b i ) + g ( x ) \min_x \sum_i^B f_i(a_i^Tx+b_i)+g(x) minx∑iBfi(aiTx+bi)+g(x)
对于共识ADMM,我们可以将 上述问题转换为:
min x 1 , . . . , x B , x ∑ i B f i ( a i T x i + b i ) + g ( x ) subject to x i = x , i = 1 , . . . , B \min_{x_1,...,x_B,x} \sum_i^Bf_i(a_i^Tx_i+b_i)+g(x) \quad \text{subject to } x_i=x,i=1,...,B x1,...,xB,xmini∑Bfi(aiTxi+bi)+g(x)subject to xi=x,i=1,...,B

Notes:
w ˉ ( k ) = 0 \bar{w}^{(k)}=0 wˉ(k)=0不满足了
x i x_i xi仍然可以并行的更新
每个 x i x_i xi可以看作是带有一个 l 2 \mathcal{l}_2 l2的正则项的优化问题