【硬核数学】2. AI如何“学习”?微积分揭秘模型优化的奥秘《从零构建机器学习、深度学习到LLM的数学认知》
在上一篇中,我们探索了线性代数如何帮助AI表示数据(向量、矩阵)和变换数据(矩阵乘法)。但AI的魅力远不止于此,它最核心的能力是“学习”——从数据中自动调整自身,以做出越来越准确的预测或决策。这个“学习”过程的背后功臣,就是我们今天要深入探讨的微积分 (Calculus)。
“微积分?是不是求导、积分,听起来比线性代数还头大!” 很多朋友可能会有这样的印象。确实,微积分有其严谨的数学体系,但其核心思想却非常直观,并且与AI的“学习”机制紧密相连。我们将一起解开:
- 导数 (Derivatives):变化率的奥秘,AI如何感知参数微调的效果?
- 偏导数 (Partial Derivatives):多维世界中的导航,AI如何判断哪个参数更值得调整?
- 梯度 (Gradient):最陡峭的路径,AI如何找到最佳参数组合的方向?
- 链式法则 (Chain Rule):层层递进的智慧,AI如何高效计算复杂模型的“学习信号”?
- Jacobian/Hessian 矩阵:高阶的视角,AI如何更精细地分析和优化模型?
准备好了吗?让我们一起踏上微积分之旅,看看它是如何驱动AI模型不断进化,变得越来越“聪明”的!
导数:洞察变化的瞬时魔法
想象一下你正在开车。你的速度是什么?它告诉你,在某一瞬间,你的位置相对于时间是如何变化的。如果速度是60公里/小时,意味着如果保持这个速度,一小时后你就会前进60公里。这个“速度”,在数学上就是导数 (Derivative) 的一个经典例子。
什么是导数?
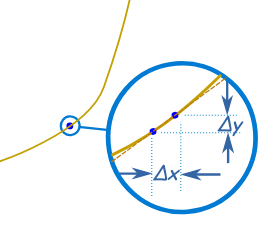
导数衡量的是一个函数 f ( x ) f(x) f(x) 在某一点 x 0 x_0 x0 处,当自变量 x x x 发生极其微小的变化时,函数值 f ( x ) f(x) f(x) 相应变化的速率或趋势。几何上,它代表了函数曲线在该点切线的斜率。
如果函数 f ( x ) f(x) f(x) 在 x 0 x_0 x0 点的导数是正数,说明当 x x x 略微增加时, f ( x ) f(x) f(x) 也倾向于增加(函数在该点“上升”)。
如果导数是负数,说明当 x x x 略微增加时, f ( x ) f(x) f(x) 倾向于减少(函数在该点“下降”)。
如果导数是零,说明函数在该点可能达到了一个平稳状态(可能是局部最高点、最低点或平坦点)。
数学上,导数 f ′ ( x ) f'(x) f′(x) 或 d f d x \frac{df}{dx} dxdf 定义为:
f ′ ( x ) = lim Δ x → 0 f ( x + Δ x ) − f ( x ) Δ x f'(x) = \lim_{\Delta x \to 0} \frac{f(x + \Delta x) - f(x)}{\Delta x} f′(x)=limΔx→0Δxf(x+Δx)−f(x)
这个公式看起来有点吓人,但它的意思就是:当 x x x 的变化量 Δ x \Delta x Δx 趋近于零时,函数值的变化量 f ( x + Δ x ) − f ( x ) f(x + \Delta x) - f(x) f(x+Δx)−f(x) 与 Δ x \Delta x Δx 的比值。
在AI中的意义:损失函数的“敏感度”
在机器学习中,我们通常会定义一个损失函数 (Loss Function) L ( 参数 ) L(\text{参数}) L(参数)。这个函数用来衡量模型的预测结果与真实答案之间的“差距”或“错误程度”。我们的目标是调整模型的参数 (Parameters)(比如线性回归中的权重 w w w 和偏置 b b b,或者神经网络中的大量权重和偏置),使得损失函数的值尽可能小。
假设我们的模型只有一个参数 w w w,损失函数是 L ( w ) L(w) L(w)。那么, L ( w ) L(w) L(w) 关于 w w w 的导数 d L d w \frac{dL}{dw} dwdL 就告诉我们:
当我稍微改变参数 w w w 一点点时,损失函数 L ( w ) L(w) L(w) 会如何变化?
- 如果 d L d w > 0 \frac{dL}{dw} > 0 dwdL>0,意味着增加 w w w 会导致损失增加。所以,为了减小损失,我们应该减小 w w w。
- 如果 d L d w < 0 \frac{dL}{dw} < 0 dwdL<0,意味着增加 w w w 会导致损失减小。所以,为了减小损失,我们应该增加 w w w。
- 如果 d L d w = 0 \frac{dL}{dw} = 0 dwdL=0,意味着我们可能找到了一个损失函数的局部最小值(或者最大值、鞍点)。此时,微调 w w w 对损失的影响很小。
这种“敏感度分析”是AI模型学习和优化的核心。通过计算导数,AI模型知道应该朝哪个方向调整参数才能让损失更小。
一个简单的例子:
假设损失函数是 L ( w ) = w 2 L(w) = w^2 L(w)=w2。这是一个简单的抛物线,在 w = 0 w=0 w=0 处取得最小值0。
它的导数是 d L d w = 2 w \frac{dL}{dw} = 2w dwdL=2w。
- 当 w = 2 w=2 w=2 时, d L d w = 2 × 2 = 4 \frac{dL}{dw} = 2 \times 2 = 4 dwdL=2×2=4 (正数)。这告诉我们,在 w = 2 w=2 w=2 的位置,如果增加 w w w,损失会增加。所以我们应该减小 w w w。
- 当 w = − 3 w=-3 w=−3 时, d L d w = 2 × ( − 3 ) = − 6 \frac{dL}{dw} = 2 \times (-3) = -6 dwdL=2×(−3)=−6 (负数)。这告诉我们,在 w = − 3 w=-3 w=−3 的位置,如果增加 w w w,损失会减小。所以我们应该增加 w w w。
- 当 w = 0 w=0 w=0 时, d L d w = 2 × 0 = 0 \frac{dL}{dw} = 2 \times 0 = 0 dwdL=2×0=0。我们到达了损失函数的最低点。
这就是最基本的优化思想:沿着导数指示的“相反”方向调整参数,就能逐步逼近损失函数的最小值。 这就是著名的梯度下降 (Gradient Descent) 算法的雏形。
小结:导数衡量函数在某一点的变化率或切线斜率。在AI中,损失函数关于模型参数的导数,指明了参数调整的方向,以使损失减小。
偏导数:多维参数空间的导航员
在上一节,我们讨论了只有一个参数 w w w 的简单情况。但现实中的AI模型,比如一个深度神经网络,可能有数百万甚至数十亿个参数!损失函数 L L L 不再是 L ( w ) L(w) L(w),而是 L ( w 1 , w 2 , w 3 , . . . , w n ) L(w_1, w_2, w_3, ..., w_n) L(w1,w2,w3,...,wn),其中 w i w_i wi 是模型的第 i i i 个参数。
这时,我们如何知道应该调整哪个参数,以及如何调整呢?这就需要偏导数 (Partial Derivative)。
什么是偏导数?
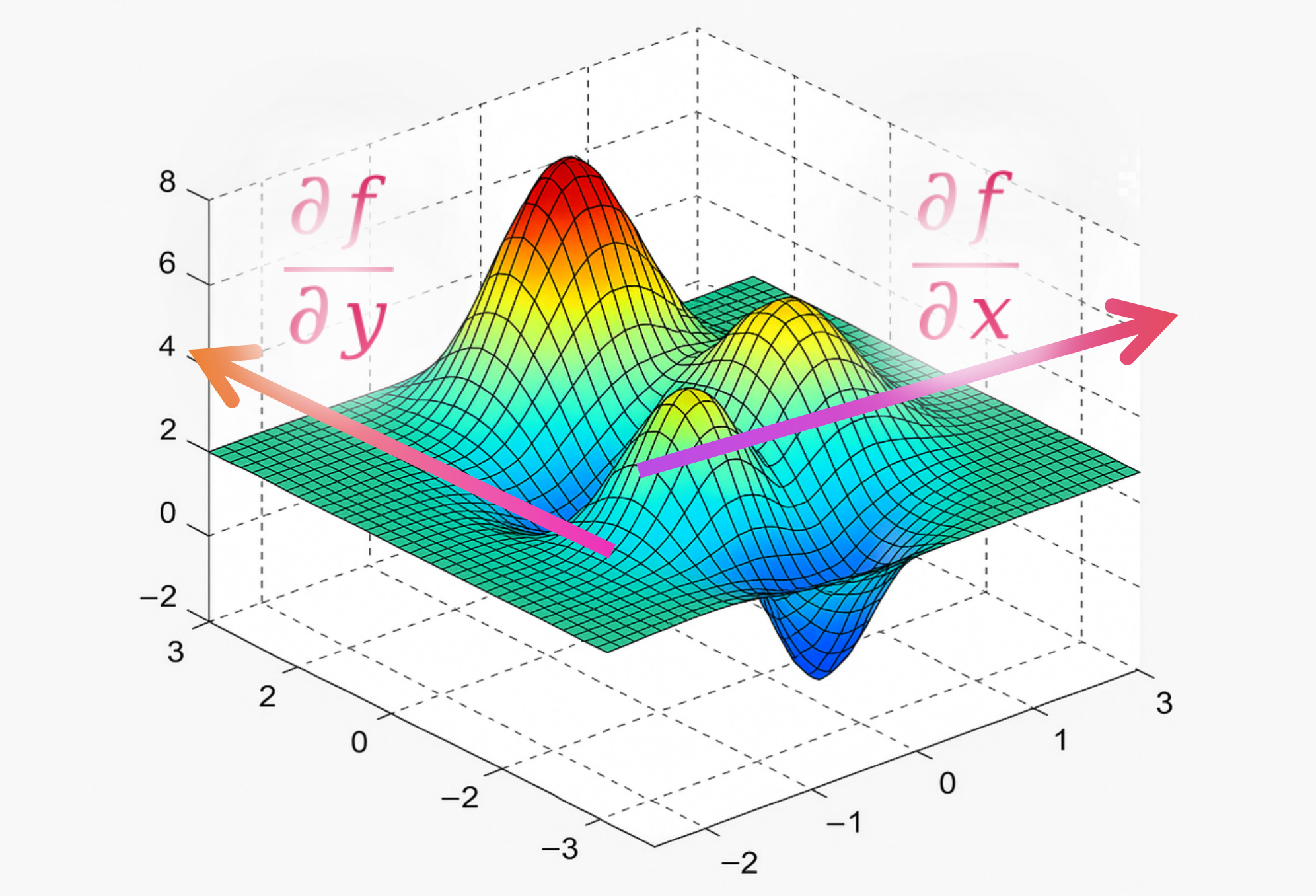
当一个函数依赖于多个自变量时,比如 f ( x , y ) f(x, y) f(x,y),我们想知道当其中一个自变量(比如 x x x)发生微小变化,而保持其他自变量(比如 y y y)不变的情况下,函数值 f ( x , y ) f(x, y) f(x,y) 如何变化。这个变化率就是 f ( x , y ) f(x, y) f(x,y) 关于 x x x 的偏导数,记作 ∂ f ∂ x \frac{\partial f}{\partial x} ∂x∂f 或 f x f_x fx。
同理, f ( x , y ) f(x, y) f(x,y) 关于 y y y 的偏导数 ∂ f ∂ y \frac{\partial f}{\partial y} ∂y∂f 或 f y f_y fy,是保持 x x x 不变, y y y 发生微小变化时,函数值的变化率。
几何直观:想象一个三维空间中的曲面 z = f ( x , y ) z = f(x, y) z=f(x,y)(比如一座山)。
∂ f ∂ x \frac{\partial f}{\partial x} ∂x∂f 表示如果你站在山上的某一点 ( x 0 , y 0 ) (x_0, y_0) (x0,y0),只沿着 x x x 轴方向(东西方向)移动一小步,你的高度会如何变化(坡度)。
∂ f ∂ y \frac{\partial f}{\partial y} ∂y∂f 表示如果你只沿着 y y y 轴方向(南北方向)移动一小步,你的高度会如何变化。
计算偏导数:计算一个变量的偏导数时,只需将其他变量视为常数,然后按照普通单变量函数的求导法则进行即可。
例子:
假设损失函数 L ( w 1 , w 2 ) = w 1 2 + 3 w 1 w 2 + 2 w 2 2 L(w_1, w_2) = w_1^2 + 3w_1w_2 + 2w_2^2 L(w1,w2)=w12+3w1w2+2w22。
计算关于 w 1 w_1 w1 的偏导数 ∂ L ∂ w 1 \frac{\partial L}{\partial w_1} ∂w1∂L:
把 w 2 w_2 w2 看作常数。
∂ L ∂ w 1 = ∂ ∂ w 1 ( w 1 2 ) + ∂ ∂ w 1 ( 3 w 1 w 2 ) + ∂ ∂ w 1 ( 2 w 2 2 ) \frac{\partial L}{\partial w_1} = \frac{\partial}{\partial w_1}(w_1^2) + \frac{\partial}{\partial w_1}(3w_1w_2) + \frac{\partial}{\partial w_1}(2w_2^2) ∂w1∂L=∂w1∂(w12)+∂w1∂(3w1w2)+∂w1∂(2w22)
= 2 w 1 + 3 w 2 × ∂ ∂ w 1 ( w 1 ) + 0 = 2w_1 + 3w_2 \times \frac{\partial}{\partial w_1}(w_1) + 0 =2w1+3w2×∂w1∂(w1)+0 (因为 2 w 2 2 2w_2^2 2w22 相对于 w 1 w_1 w1 是常数)
= 2 w 1 + 3 w 2 = 2w_1 + 3w_2 =2w1+3w2
计算关于 w 2 w_2 w2 的偏导数 ∂ L ∂ w 2 \frac{\partial L}{\partial w_2} ∂w2∂L:
把 w 1 w_1 w1 看作常数。
∂ L ∂ w 2 = ∂ ∂ w 2 ( w 1 2 ) + ∂ ∂ w 2 ( 3 w 1 w 2 ) + ∂ ∂ w 2 ( 2 w 2 2 ) \frac{\partial L}{\partial w_2} = \frac{\partial}{\partial w_2}(w_1^2) + \frac{\partial}{\partial w_2}(3w_1w_2) + \frac{\partial}{\partial w_2}(2w_2^2) ∂w2∂L=∂w2∂(w12)+∂w2∂(3w1w2)+∂w2∂(2w22)
= 0 + 3 w 1 × ∂ ∂ w 2 ( w 2 ) + 4 w 2 = 0 + 3w_1 \times \frac{\partial}{\partial w_2}(w_2) + 4w_2 =0+3w1×∂w2∂(w2)+4w2 (因为 w 1 2 w_1^2 w12 相对于 w 2 w_2 w2 是常数)
= 3 w 1 + 4 w 2 = 3w_1 + 4w_2 =3w1+4w2
在AI中的意义:分别考察每个参数的影响
对于一个拥有多个参数 w 1 , w 2 , . . . , w n w_1, w_2, ..., w_n w1,w2,...,wn 的AI模型,损失函数 L ( w 1 , . . . , w n ) L(w_1, ..., w_n) L(w1,...,wn) 关于每个参数 w i w_i wi 的偏导数 ∂ L ∂ w i \frac{\partial L}{\partial w_i} ∂wi∂L 告诉我们:
如果我只微调参数 w i w_i wi 一点点,同时保持其他所有参数 w j ( j ≠ i ) w_j (j \neq i) wj(j=i) 不变,那么损失函数 L L L 会如何变化?
这个信息至关重要,因为它让我们能够独立地评估每个参数对整体损失的“贡献”或“敏感度”。如果 ∂ L ∂ w i \frac{\partial L}{\partial w_i} ∂wi∂L 的绝对值很大,说明参数 w i w_i wi 对损失的影响比较显著,调整它可能会带来较大的损失变化。
小结:偏导数衡量多变量函数在某一点沿着某个坐标轴方向的变化率。在AI中,损失函数关于各个模型参数的偏导数,为我们指明了单独调整每个参数时损失的变化趋势。
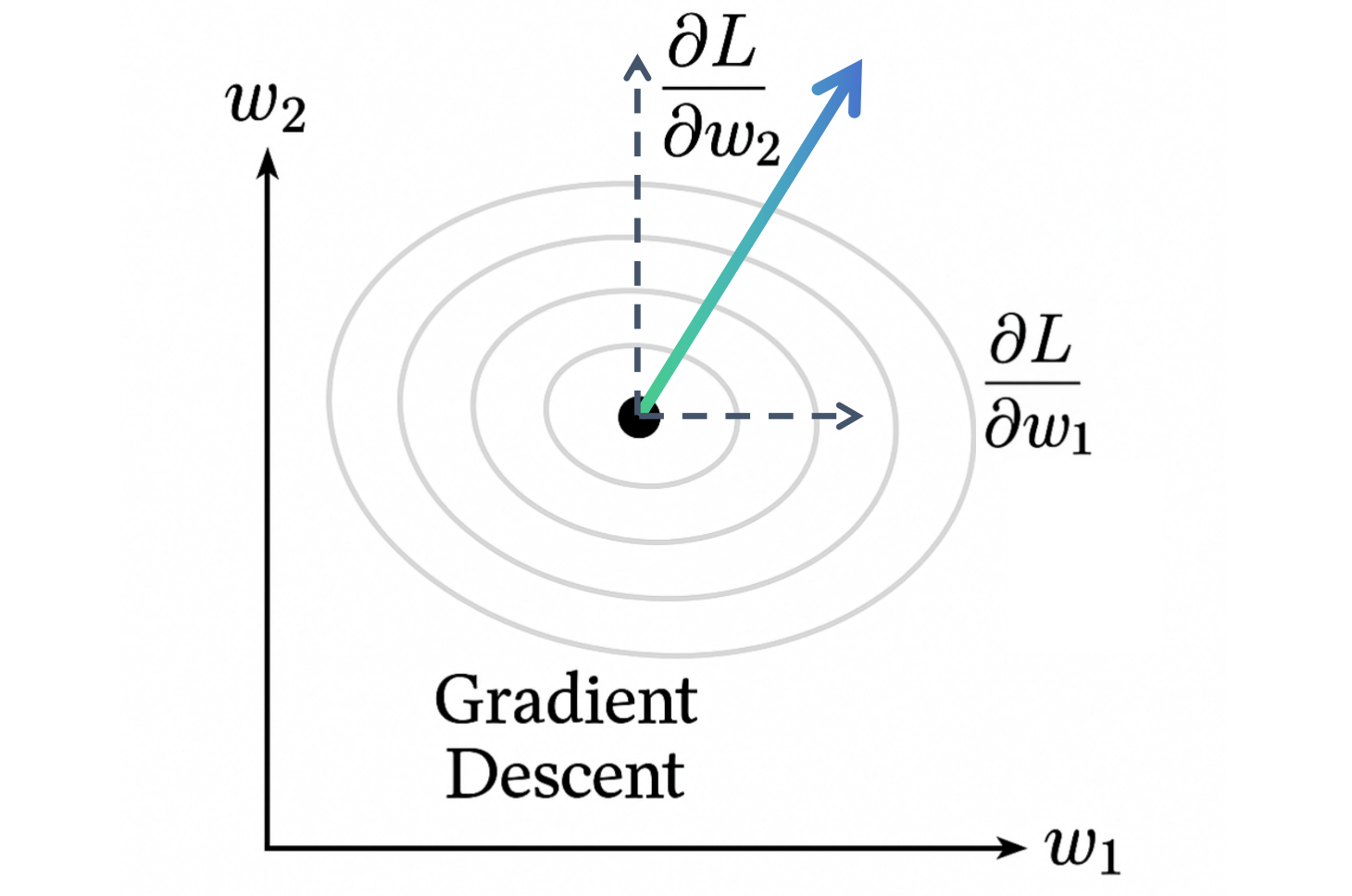
梯度:下降最快的方向盘
我们已经知道了如何计算损失函数 L L L 关于每一个参数 w i w_i wi 的偏导数 ∂ L ∂ w i \frac{\partial L}{\partial w_i} ∂wi∂L。这些偏导数各自描述了在一个特定参数维度上的变化趋势。但我们如何把这些信息整合起来,找到一个让损失函数 L L L 整体下降最快的方向呢?答案就是梯度 (Gradient)。
什么是梯度?
对于一个多变量函数 L ( w 1 , w 2 , . . . , w n ) L(w_1, w_2, ..., w_n) L(w1,w2,...,wn),它的梯度是一个向量,由该函数关于所有自变量的偏导数构成:
∇ L = grad ( L ) = [ ∂ L ∂ w 1 , ∂ L ∂ w 2 , . . . , ∂ L ∂ w n ] \nabla L = \text{grad}(L) = \left[ \frac{\partial L}{\partial w_1}, \frac{\partial L}{\partial w_2}, ..., \frac{\partial L}{\partial w_n} \right] ∇L=grad(L)=[∂w1∂L,∂w2∂L,...,∂wn∂L]
这里的 ∇ \nabla ∇ (nabla) 符号是梯度的标准表示。
梯度的关键特性:
在函数定义域内的任意一点,梯度向量指向该点函数值增长最快的方向。
相应地,负梯度向量 ( − ∇ L -\nabla L −∇L ) 指向该点函数值减小最快的方向。
几何直观:再次想象那座山 z = L ( w 1 , w 2 ) z = L(w_1, w_2) z=L(w1,w2)(这里 w 1 , w 2 w_1, w_2 w1,w2 是平面坐标)。你在山上的某一点,想尽快下到山谷(损失最小的地方)。
- ∂ L ∂ w 1 \frac{\partial L}{\partial w_1} ∂w1∂L 告诉你东西方向的坡度。
- ∂ L ∂ w 2 \frac{\partial L}{\partial w_2} ∂w2∂L 告诉你南北方向的坡度。
- 梯度 ∇ L = [ ∂ L ∂ w 1 , ∂ L ∂ w 2 ] \nabla L = [\frac{\partial L}{\partial w_1}, \frac{\partial L}{\partial w_2}] ∇L=[∂w1∂L,∂w2∂L] 是一个二维向量,它指向山上坡度最陡峭的上坡方向。
- 那么, − ∇ L = [ − ∂ L ∂ w 1 , − ∂ L ∂ w 2 ] -\nabla L = [-\frac{\partial L}{\partial w_1}, -\frac{\partial L}{\partial w_2}] −∇L=[−∂w1∂L,−∂w2∂L] 就指向坡度最陡峭的下坡方向。
梯度下降算法 (Gradient Descent)
梯度下降是AI中最核心、最常用的优化算法之一。它的思想非常朴素和直观:为了最小化损失函数 L L L,我们从一个随机的参数点 W 0 = [ w 1 ( 0 ) , w 2 ( 0 ) , . . . , w n ( 0 ) ] W_0 = [w_1^{(0)}, w_2^{(0)}, ..., w_n^{(0)}] W0=[w1(0),w2(0),...,wn(0)] 开始,然后迭代地沿着负梯度方向更新参数:
W t + 1 = W t − η ∇ L ( W t ) W_{t+1} = W_t - \eta \nabla L(W_t) Wt+1=Wt−η∇L(Wt)
这里的符号解释:
- W t W_t Wt:第 t t t 次迭代时的参数向量。
- ∇ L ( W t ) \nabla L(W_t) ∇L(Wt):在点 W t W_t Wt 处计算的损失函数的梯度。
- η \eta η (eta):称为学习率 (Learning Rate)。它是一个很小的正数(比如0.01, 0.001),控制着每一步沿着负梯度方向前进的“步长”。
- 如果 η \eta η 太小,收敛到最小值的速度会很慢。
- 如果 η \eta η 太大,可能会在最小值附近来回震荡,甚至越过最小值导致发散。选择合适的学习率非常重要。
- W t + 1 W_{t+1} Wt+1:更新后的参数向量。
这个过程就像是一个盲人下山:他不知道山谷在哪,但他可以感知脚下哪个方向坡度最陡峭(负梯度),然后朝那个方向迈一小步(由学习率控制步长)。不断重复这个过程,他就能一步步走到山谷。
梯度下降的步骤:
- 初始化参数 W W W (随机值或预设值)。
- 循环迭代直到满足停止条件(比如达到最大迭代次数,或者损失变化很小):
a. 计算梯度:在当前参数 W t W_t Wt 下,计算损失函数 L L L 关于 W t W_t Wt 的梯度 ∇ L ( W t ) \nabla L(W_t) ∇L(Wt)。
b. 更新参数: W t + 1 = W t − η ∇ L ( W t ) W_{t+1} = W_t - \eta \nabla L(W_t) Wt+1=Wt−η∇L(Wt)。
AI模型的“学习”过程:
当我们说一个AI模型在“学习”时,很多情况下指的就是它在用梯度下降(或其变种,如随机梯度下降SGD、Adam等)来调整内部参数,以最小化在训练数据上的损失函数。
- 模型做出预测。
- 计算预测与真实标签之间的损失。
- 计算损失函数关于模型所有参数的梯度。
- 根据梯度和学习率更新参数。
- 重复以上步骤,直到模型性能不再显著提升。
小结:梯度是由所有偏导数组成的向量,指向函数值增长最快的方向。负梯度则指向下降最快的方向。梯度下降算法利用负梯度来迭代更新模型参数,从而最小化损失函数,这是AI模型学习的核心机制。
链式法则:解开复杂依赖的钥匙
现代AI模型,尤其是深度神经网络,其结构非常复杂。它们通常是由许多层函数嵌套构成的。例如,一个简单的两层神经网络,其输出可能是这样的形式:
Output = f 2 ( W 2 ⋅ f 1 ( W 1 ⋅ Input + b 1 ) + b 2 ) \text{Output} = f_2(W_2 \cdot f_1(W_1 \cdot \text{Input} + b_1) + b_2) Output=f2(W2⋅f1(W1⋅Input+b1)+b2)
这里 f 1 , f 2 f_1, f_2 f1,f2 是激活函数, W 1 , b 1 , W 2 , b 2 W_1, b_1, W_2, b_2 W1,b1,W2,b2 是模型的参数。损失函数 L L L 是基于这个Output和真实标签计算的。
我们想知道损失 L L L 关于 W 1 W_1 W1 或 b 1 b_1 b1 这些深层参数的梯度,以便用梯度下降来更新它们。但是 W 1 W_1 W1 是深深嵌套在里面的,损失 L L L 并不是直接由 W 1 W_1 W1 决定的,而是通过一系列中间变量(比如 f 1 f_1 f1 的输出,以及 f 2 f_2 f2 的输入)间接影响的。这时,链式法则 (Chain Rule) 就派上用场了。
什么是链式法则?
链式法则用于计算复合函数 (Composite Function) 的导数。
如果一个变量 y y y 是变量 u u u 的函数,即 y = f ( u ) y = f(u) y=f(u),而 u u u 又是变量 x x x 的函数,即 u = g ( x ) u = g(x) u=g(x),那么 y y y 最终也是 x x x 的函数 y = f ( g ( x ) ) y = f(g(x)) y=f(g(x))。
链式法则告诉我们如何计算 y y y 关于 x x x 的导数 d y d x \frac{dy}{dx} dxdy:
d y d x = d y d u ⋅ d u d x \frac{dy}{dx} = \frac{dy}{du} \cdot \frac{du}{dx} dxdy=dudy⋅dxdu
直观理解:想象一串多米诺骨牌。
- d u d x \frac{du}{dx} dxdu:第一块骨牌 x x x 倒下时,推动第二块骨牌 u u u 倒下的“效率”( x x x 的小变化导致 u u u 的变化率)。
- d y d u \frac{dy}{du} dudy:第二块骨牌 u u u 倒下时,推动第三块骨牌 y y y 倒下的“效率”( u u u 的小变化导致 y y y 的变化率)。
- d y d x \frac{dy}{dx} dxdy:第一块骨牌 x x x 倒下时,最终导致第三块骨牌 y y y 倒下的“总效率”。这个总效率就是各环节效率的乘积。
推广到多变量和多层嵌套:
链式法则可以推广到多个中间变量和更深的函数嵌套。对于多变量函数,它涉及到偏导数和雅可比矩阵(后面会提到)。
例如,如果 L L L 是 a a a 的函数, a a a 是 z z z 的函数, z z z 是 w w w 的函数 ( L → a → z → w L \rightarrow a \rightarrow z \rightarrow w L→a→z→w),那么:
∂ L ∂ w = ∂ L ∂ a ⋅ ∂ a ∂ z ⋅ ∂ z ∂ w \frac{\partial L}{\partial w} = \frac{\partial L}{\partial a} \cdot \frac{\partial a}{\partial z} \cdot \frac{\partial z}{\partial w} ∂w∂L=∂a∂L⋅∂z∂a⋅∂w∂z
AI中的核心:反向传播算法 (Backpropagation)
在深度学习中,反向传播 (Backpropagation) 算法就是链式法则在神经网络中的系统性应用。它是计算损失函数关于网络中所有参数(权重和偏置)梯度的标准方法。
反向传播的核心思想:
- 前向传播 (Forward Pass):输入数据通过网络,逐层计算,直到得到最终的输出,然后计算损失 L L L。
- 反向传播 (Backward Pass):
- 从损失 L L L 开始,首先计算 L L L 关于网络最后一层输出的梯度。
- 然后,利用链式法则,将这个梯度“反向传播”到前一层,计算 L L L 关于前一层输出(或激活值)的梯度。
- 同时,计算 L L L 关于当前层参数(权重和偏置)的梯度。
- 重复这个过程,一层一层向后,直到计算出 L L L 关于网络第一层参数的梯度。
例如,对于上面那个简单的两层网络,我们要计算 ∂ L ∂ W 1 \frac{\partial L}{\partial W_1} ∂W1∂L:
假设中间变量是:
z 1 = W 1 ⋅ Input + b 1 z_1 = W_1 \cdot \text{Input} + b_1 z1=W1⋅Input+b1 (第一层线性输出)
a 1 = f 1 ( z 1 ) a_1 = f_1(z_1) a1=f1(z1) (第一层激活输出)
z 2 = W 2 ⋅ a 1 + b 2 z_2 = W_2 \cdot a_1 + b_2 z2=W2⋅a1+b2 (第二层线性输出)
Output = a 2 = f 2 ( z 2 ) \text{Output} = a_2 = f_2(z_2) Output=a2=f2(z2) (第二层激活输出,即模型最终输出)
L = LossFunction ( a 2 , TrueLabel ) L = \text{LossFunction}(a_2, \text{TrueLabel}) L=LossFunction(a2,TrueLabel)
那么, ∂ L ∂ W 1 \frac{\partial L}{\partial W_1} ∂W1∂L 可以通过链式法则分解为:
∂ L ∂ W 1 = ∂ L ∂ a 2 ⋅ ∂ a 2 ∂ z 2 ⋅ ∂ z 2 ∂ a 1 ⋅ ∂ a 1 ∂ z 1 ⋅ ∂ z 1 ∂ W 1 \frac{\partial L}{\partial W_1} = \frac{\partial L}{\partial a_2} \cdot \frac{\partial a_2}{\partial z_2} \cdot \frac{\partial z_2}{\partial a_1} \cdot \frac{\partial a_1}{\partial z_1} \cdot \frac{\partial z_1}{\partial W_1} ∂W1∂L=∂a2∂L⋅∂z2∂a2⋅∂a1∂z2⋅∂z1∂a1⋅∂W1∂z1
这里每一项的偏导数通常都比较容易计算:
- ∂ L ∂ a 2 \frac{\partial L}{\partial a_2} ∂a2∂L: 损失函数对网络输出的导数。
- ∂ a 2 ∂ z 2 \frac{\partial a_2}{\partial z_2} ∂z2∂a2: 第二层激活函数 f 2 f_2 f2 对其输入的导数。
- ∂ z 2 ∂ a 1 \frac{\partial z_2}{\partial a_1} ∂a1∂z2: 等于 W 2 T W_2^T W2T (需要矩阵求导知识,但直观上是 a 1 a_1 a1 对 z 2 z_2 z2 的贡献,由 W 2 W_2 W2 决定)。
- ∂ a 1 ∂ z 1 \frac{\partial a_1}{\partial z_1} ∂z1∂a1: 第一层激活函数 f 1 f_1 f1 对其输入的导数。
- ∂ z 1 ∂ W 1 \frac{\partial z_1}{\partial W_1} ∂W1∂z1: 等于 Input T \text{Input}^T InputT (直观上是 W 1 W_1 W1 对 z 1 z_1 z1 的贡献,由 Input \text{Input} Input 决定)。
反向传播算法的美妙之处在于,它提供了一种高效计算这些链式乘积的方法,避免了对每个参数都从头推导整个链条。它从后往前,逐层计算和存储中间梯度,使得整个计算过程非常模块化和高效。现代深度学习框架(TensorFlow, PyTorch)都内置了自动微分(Autograd)功能,它们会自动构建计算图并应用链式法则(即反向传播)来计算所有参数的梯度。
小结:链式法则用于计算复合函数的导数,即一个变量通过一系列中间变量间接影响另一个变量时的变化率。在AI中,反向传播算法是链式法则在神经网络上的巧妙应用,它能够高效地计算损失函数关于网络中所有参数的梯度,是深度学习模型训练的基石。
Jacobian 和 Hessian 矩阵:高阶的洞察力 (进阶预览)
到目前为止,我们主要关注的是损失函数(一个标量输出)关于参数(向量输入)的一阶导数(梯度)。但在更高级的优化算法或模型分析中,我们可能需要更高阶的导数信息。这里简单介绍两个重要的概念:Jacobian矩阵和Hessian矩阵。对于初学者,了解它们的存在和大致用途即可。
Jacobian 矩阵 (雅可比矩阵)
当我们的函数是一个向量值函数时,即函数的输入是向量,输出也是向量,比如 F : R n → R m F: \mathbb{R}^n \to \mathbb{R}^m F:Rn→Rm,其中 F ( x ) = [ f 1 ( x ) , f 2 ( x ) , . . . , f m ( x ) ] F(x) = [f_1(x), f_2(x), ..., f_m(x)] F(x)=[f1(x),f2(x),...,fm(x)],而 x = [ x 1 , x 2 , . . . , x n ] x = [x_1, x_2, ..., x_n] x=[x1,x2,...,xn]。
Jacobian 矩阵 J F J_F JF 是一个 m × n m \times n m×n 的矩阵,包含了 F F F 的所有一阶偏导数:
J F = ( ∂ f 1 ∂ x 1 ∂ f 1 ∂ x 2 … ∂ f 1 ∂ x n ∂ f 2 ∂ x 1 ∂ f 2 ∂ x 2 … ∂ f 2 ∂ x n ⋮ ⋮ ⋱ ⋮ ∂ f m ∂ x 1 ∂ f m ∂ x 2 … ∂ f m ∂ x n ) J_F = \begin{pmatrix} \frac{\partial f_1}{\partial x_1} & \frac{\partial f_1}{\partial x_2} & \dots & \frac{\partial f_1}{\partial x_n} \\ \frac{\partial f_2}{\partial x_1} & \frac{\partial f_2}{\partial x_2} & \dots & \frac{\partial f_2}{\partial x_n} \\ \vdots & \vdots & \ddots & \vdots \\ \frac{\partial f_m}{\partial x_1} & \frac{\partial f_m}{\partial x_2} & \dots & \frac{\partial f_m}{\partial x_n} \end{pmatrix} JF= ∂x1∂f1∂x1∂f2⋮∂x1∂fm∂x2∂f1∂x2∂f2⋮∂x2∂fm……⋱…∂xn∂f1∂xn∂f2⋮∂xn∂fm
其中,第 i i i 行是第 i i i 个输出函数 f i f_i fi 的梯度 ∇ f i T \nabla f_i^T ∇fiT。
特殊情况:
- 如果 m = 1 m=1 m=1 (函数输出是标量,比如损失函数 L ( W ) L(W) L(W)),那么Jacobian矩阵就退化为一个 1 × n 1 \times n 1×n 的行向量,即梯度向量的转置 ∇ L T \nabla L^T ∇LT。
- 如果 n = 1 n=1 n=1 (函数输入是标量),Jacobian矩阵就退化为一个 m × 1 m \times 1 m×1 的列向量,包含了各个输出函数 f i f_i fi 关于输入 x x x 的普通导数。
AI中的应用:
- 链式法则的推广:当复合函数中的某个环节是向量到向量的映射时,链式法则需要用到Jacobian矩阵。例如,如果 y = F ( u ) y=F(u) y=F(u) 且 u = G ( x ) u=G(x) u=G(x),那么 d y d x \frac{dy}{dx} dxdy (这里表示的是Jacobian) 等于 J F ( G ( x ) ) ⋅ J G ( x ) J_F(G(x)) \cdot J_G(x) JF(G(x))⋅JG(x) (矩阵乘法)。反向传播在计算梯度时,隐式地处理了这些Jacobian向量积。
- 某些高级优化算法。
- 敏感性分析:分析输出的各个分量对输入的各个分量的敏感程度。
Hessian 矩阵 (海森矩阵)
Hessian矩阵描述了标量值函数 L ( W ) L(W) L(W) 的二阶偏导数信息,即梯度的梯度。对于一个有 n n n 个参数 W = [ w 1 , . . . , w n ] W=[w_1, ..., w_n] W=[w1,...,wn] 的损失函数 L ( W ) L(W) L(W),其Hessian矩阵 H L H_L HL 是一个 n × n n \times n n×n 的对称矩阵:
H L = ( ∂ 2 L ∂ w 1 2 ∂ 2 L ∂ w 1 ∂ w 2 … ∂ 2 L ∂ w 1 ∂ w n ∂ 2 L ∂ w 2 ∂ w 1 ∂ 2 L ∂ w 2 2 … ∂ 2 L ∂ w 2 ∂ w n ⋮ ⋮ ⋱ ⋮ ∂ 2 L ∂ w n ∂ w 1 ∂ 2 L ∂ w n ∂ w 2 … ∂ 2 L ∂ w n 2 ) H_L = \begin{pmatrix} \frac{\partial^2 L}{\partial w_1^2} & \frac{\partial^2 L}{\partial w_1 \partial w_2} & \dots & \frac{\partial^2 L}{\partial w_1 \partial w_n} \\ \frac{\partial^2 L}{\partial w_2 \partial w_1} & \frac{\partial^2 L}{\partial w_2^2} & \dots & \frac{\partial^2 L}{\partial w_2 \partial w_n} \\ \vdots & \vdots & \ddots & \vdots \\ \frac{\partial^2 L}{\partial w_n \partial w_1} & \frac{\partial^2 L}{\partial w_n \partial w_2} & \dots & \frac{\partial^2 L}{\partial w_n^2} \end{pmatrix} HL= ∂w12∂2L∂w2∂w1∂2L⋮∂wn∂w1∂2L∂w1∂w2∂2L∂w22∂2L⋮∂wn∂w2∂2L……⋱…∂w1∂wn∂2L∂w2∂wn∂2L⋮∂wn2∂2L
其中 ( H L ) i j = ∂ 2 L ∂ w i ∂ w j (H_L)_{ij} = \frac{\partial^2 L}{\partial w_i \partial w_j} (HL)ij=∂wi∂wj∂2L。如果函数 L L L 的二阶偏导数连续,则 H L H_L HL 是对称的,即 ∂ 2 L ∂ w i ∂ w j = ∂ 2 L ∂ w j ∂ w i \frac{\partial^2 L}{\partial w_i \partial w_j} = \frac{\partial^2 L}{\partial w_j \partial w_i} ∂wi∂wj∂2L=∂wj∂wi∂2L。
Hessian矩阵的意义:
Hessian矩阵描述了损失函数在某一点附近的曲率 (curvature)。
- 如果在一个临界点(梯度为零的点),Hessian矩阵是正定的(所有特征值都为正),那么该点是一个局部最小值。
- 如果Hessian矩阵是负定的(所有特征值都为负),该点是一个局部最大值。
- 如果Hessian矩阵的特征值有正有负,该点是一个鞍点 (Saddle Point)。在深度学习中,高维损失函数的鞍点远比局部最小值更常见,这是优化的一大挑战。
AI中的应用:
- 二阶优化算法:像牛顿法 (Newton’s Method) 及其变种就利用Hessian矩阵来进行参数更新,它们通常能比一阶方法(如梯度下降)更快地收敛,尤其是在接近最优点时。更新规则类似于 W t + 1 = W t − η [ H L ( W t ) ] − 1 ∇ L ( W t ) W_{t+1} = W_t - \eta [H_L(W_t)]^{-1} \nabla L(W_t) Wt+1=Wt−η[HL(Wt)]−1∇L(Wt)。然而,计算和存储Hessian矩阵(及其逆)对于参数量巨大的现代神经网络来说代价高昂( O ( n 2 ) O(n^2) O(n2) 存储, O ( n 3 ) O(n^3) O(n3) 求逆),所以实际应用中更多采用近似Hessian的方法(如L-BFGS)。
- 分析损失函数的几何形状:帮助理解优化过程中的难点,如鞍点、平坦区域等。
- 确定学习率:Hessian的特征值可以用来指导学习率的选择。
小结:Jacobian矩阵是一阶偏导数对向量值函数的推广,是链式法则在多维情况下表达的关键。Hessian矩阵是标量值函数的二阶偏导数矩阵,描述了函数的局部曲率,可用于二阶优化算法和分析临界点性质。它们为AI提供了更深层次的优化和分析工具。
总结:微积分,驱动AI学习的引擎
我们今天一起探索了微积分的核心概念——导数、偏导数、梯度、链式法则,以及简要了解了Jacobian和Hessian矩阵。希望你现在能理解,微积分并非只是抽象的数学公式,而是AI模型能够“学习”和“优化”自身的关键所在:
- 导数和偏导数让模型感知到单个参数微调对整体性能(损失)的影响。
- 梯度整合了所有参数的影响,为模型指明了“变得更好”(损失减小)的最快方向。
- 梯度下降算法则是模型沿着梯度方向小步快跑,不断迭代调整参数,以达到最佳性能的过程。
- **链式法则(反向传播)**是高效计算复杂模型(如深度神经网络)中所有参数梯度的“总调度师”,使得大规模模型的训练成为可能。
- Jacobian和Hessian则为更精细的分析和更高级的优化算法提供了数学工具。
如果说线性代数为AI提供了表示和操作数据的“骨架”,那么微积分就为AI注入了学习和进化的“引擎”和“导航系统”。正是因为有了微积分,AI模型才能从数据中总结规律,自动调整参数,最终实现各种令人惊叹的功能。
理解这些数学原理,不仅能帮助你更深入地理解AI的工作方式,也能让你在未来学习更高级的AI技术时更有底气。数学是AI的基石,也是创新的源泉。让我们继续这座奇妙的数学之旅吧!
习题
来几道练习题,检验一下今天的学习成果!
1. 理解导数
假设一个AI模型的损失函数关于某个权重参数 w w w 的关系是 L ( w ) = ( w − 3 ) 2 + 5 L(w) = (w-3)^2 + 5 L(w)=(w−3)2+5。
(a) 当 w = 1 w=1 w=1 时,损失 L ( w ) L(w) L(w) 关于 w w w 的导数 d L d w \frac{dL}{dw} dwdL 是多少?
(b) 根据这个导数值,为了减小损失,我们应该增加 w w w 还是减小 w w w?
2. 计算偏导数
一个简单的损失函数依赖于两个参数 w 1 w_1 w1 和 w 2 w_2 w2: L ( w 1 , w 2 ) = 2 w 1 2 − 3 w 1 w 2 + w 2 3 L(w_1, w_2) = 2w_1^2 - 3w_1w_2 + w_2^3 L(w1,w2)=2w12−3w1w2+w23。
请计算:
(a) ∂ L ∂ w 1 \frac{\partial L}{\partial w_1} ∂w1∂L (损失函数关于 w 1 w_1 w1 的偏导数)
(b) ∂ L ∂ w 2 \frac{\partial L}{\partial w_2} ∂w2∂L (损失函数关于 w 2 w_2 w2 的偏导数)
3. 梯度与梯度下降
对于上一题的损失函数 L ( w 1 , w 2 ) = 2 w 1 2 − 3 w 1 w 2 + w 2 3 L(w_1, w_2) = 2w_1^2 - 3w_1w_2 + w_2^3 L(w1,w2)=2w12−3w1w2+w23。
(a) 写出其梯度向量 ∇ L ( w 1 , w 2 ) \nabla L(w_1, w_2) ∇L(w1,w2)。
(b) 假设当前参数为 ( w 1 , w 2 ) = ( 1 , 1 ) (w_1, w_2) = (1, 1) (w1,w2)=(1,1),学习率为 η = 0.1 \eta = 0.1 η=0.1。应用一步梯度下降,新的参数 ( w 1 ′ , w 2 ′ ) (w_1', w_2') (w1′,w2′) 是多少?
4. 理解链式法则
假设一个简单的模型: y = u 2 y = u^2 y=u2,其中 u = 2 x + 1 u = 2x + 1 u=2x+1。损失函数 L = ( y − 10 ) 2 L = (y-10)^2 L=(y−10)2。我们想求损失 L L L 关于参数 x x x 的导数 d L d x \frac{dL}{dx} dxdL。
请用链式法则逐步写出计算过程(即 d L d x = d L d y ⋅ d y d u ⋅ d u d x \frac{dL}{dx} = \frac{dL}{dy} \cdot \frac{dy}{du} \cdot \frac{du}{dx} dxdL=dydL⋅dudy⋅dxdu 的每一项)。
5. Jacobian 与 Hessian (概念)
(a) 如果一个神经网络的某个层将一个10维的输入向量映射到一个5维的输出向量,描述这个层变换的Jacobian矩阵的维度是多少?
(b) Hessian矩阵的对角线元素 ∂ 2 L ∂ w i 2 \frac{\partial^2 L}{\partial w_i^2} ∂wi2∂2L 在直观上告诉我们关于损失函数在 w i w_i wi 方向上的什么信息?(提示:考虑单变量函数的二阶导数)
答案
1. 理解导数
L ( w ) = ( w − 3 ) 2 + 5 = w 2 − 6 w + 9 + 5 = w 2 − 6 w + 14 L(w) = (w-3)^2 + 5 = w^2 - 6w + 9 + 5 = w^2 - 6w + 14 L(w)=(w−3)2+5=w2−6w+9+5=w2−6w+14
(a) d L d w = 2 w − 6 \frac{dL}{dw} = 2w - 6 dwdL=2w−6。
当 w = 1 w=1 w=1 时, d L d w = 2 ( 1 ) − 6 = 2 − 6 = − 4 \frac{dL}{dw} = 2(1) - 6 = 2 - 6 = -4 dwdL=2(1)−6=2−6=−4。
(b) 导数值为-4(负数),这意味着如果增加 w w w,损失会减小。所以,为了减小损失,我们应该增加 w w w。
2. 计算偏导数
L ( w 1 , w 2 ) = 2 w 1 2 − 3 w 1 w 2 + w 2 3 L(w_1, w_2) = 2w_1^2 - 3w_1w_2 + w_2^3 L(w1,w2)=2w12−3w1w2+w23
(a) ∂ L ∂ w 1 = ∂ ∂ w 1 ( 2 w 1 2 ) − ∂ ∂ w 1 ( 3 w 1 w 2 ) + ∂ ∂ w 1 ( w 2 3 ) = 4 w 1 − 3 w 2 + 0 = 4 w 1 − 3 w 2 \frac{\partial L}{\partial w_1} = \frac{\partial}{\partial w_1}(2w_1^2) - \frac{\partial}{\partial w_1}(3w_1w_2) + \frac{\partial}{\partial w_1}(w_2^3) = 4w_1 - 3w_2 + 0 = 4w_1 - 3w_2 ∂w1∂L=∂w1∂(2w12)−∂w1∂(3w1w2)+∂w1∂(w23)=4w1−3w2+0=4w1−3w2
(b) ∂ L ∂ w 2 = ∂ ∂ w 2 ( 2 w 1 2 ) − ∂ ∂ w 2 ( 3 w 1 w 2 ) + ∂ ∂ w 2 ( w 2 3 ) = 0 − 3 w 1 + 3 w 2 2 = − 3 w 1 + 3 w 2 2 \frac{\partial L}{\partial w_2} = \frac{\partial}{\partial w_2}(2w_1^2) - \frac{\partial}{\partial w_2}(3w_1w_2) + \frac{\partial}{\partial w_2}(w_2^3) = 0 - 3w_1 + 3w_2^2 = -3w_1 + 3w_2^2 ∂w2∂L=∂w2∂(2w12)−∂w2∂(3w1w2)+∂w2∂(w23)=0−3w1+3w22=−3w1+3w22
3. 梯度与梯度下降
(a) 梯度向量 ∇ L ( w 1 , w 2 ) = [ ∂ L ∂ w 1 , ∂ L ∂ w 2 ] = [ 4 w 1 − 3 w 2 , − 3 w 1 + 3 w 2 2 ] \nabla L(w_1, w_2) = \left[ \frac{\partial L}{\partial w_1}, \frac{\partial L}{\partial w_2} \right] = [4w_1 - 3w_2, -3w_1 + 3w_2^2] ∇L(w1,w2)=[∂w1∂L,∂w2∂L]=[4w1−3w2,−3w1+3w22]
(b) 当前参数 ( w 1 , w 2 ) = ( 1 , 1 ) (w_1, w_2) = (1, 1) (w1,w2)=(1,1)。
梯度 ∇ L ( 1 , 1 ) = [ 4 ( 1 ) − 3 ( 1 ) , − 3 ( 1 ) + 3 ( 1 ) 2 ] = [ 4 − 3 , − 3 + 3 ] = [ 1 , 0 ] \nabla L(1, 1) = [4(1) - 3(1), -3(1) + 3(1)^2] = [4 - 3, -3 + 3] = [1, 0] ∇L(1,1)=[4(1)−3(1),−3(1)+3(1)2]=[4−3,−3+3]=[1,0]。
学习率 η = 0.1 \eta = 0.1 η=0.1。
新的参数 ( w 1 ′ , w 2 ′ ) (w_1', w_2') (w1′,w2′):
w 1 ′ = w 1 − η ⋅ ∂ L ∂ w 1 ( 1 , 1 ) = 1 − 0.1 ⋅ 1 = 1 − 0.1 = 0.9 w_1' = w_1 - \eta \cdot \frac{\partial L}{\partial w_1}(1,1) = 1 - 0.1 \cdot 1 = 1 - 0.1 = 0.9 w1′=w1−η⋅∂w1∂L(1,1)=1−0.1⋅1=1−0.1=0.9
w 2 ′ = w 2 − η ⋅ ∂ L ∂ w 2 ( 1 , 1 ) = 1 − 0.1 ⋅ 0 = 1 − 0 = 1 w_2' = w_2 - \eta \cdot \frac{\partial L}{\partial w_2}(1,1) = 1 - 0.1 \cdot 0 = 1 - 0 = 1 w2′=w2−η⋅∂w2∂L(1,1)=1−0.1⋅0=1−0=1
所以,新的参数为 ( w 1 ′ , w 2 ′ ) = ( 0.9 , 1 ) (w_1', w_2') = (0.9, 1) (w1′,w2′)=(0.9,1)。
4. 理解链式法则
L = ( y − 10 ) 2 L = (y-10)^2 L=(y−10)2, y = u 2 y = u^2 y=u2, u = 2 x + 1 u = 2x + 1 u=2x+1.
d L d x = d L d y ⋅ d y d u ⋅ d u d x \frac{dL}{dx} = \frac{dL}{dy} \cdot \frac{dy}{du} \cdot \frac{du}{dx} dxdL=dydL⋅dudy⋅dxdu
- d L d y = 2 ( y − 10 ) ⋅ d d y ( y − 10 ) = 2 ( y − 10 ) ⋅ 1 = 2 ( y − 10 ) \frac{dL}{dy} = 2(y-10) \cdot \frac{d}{dy}(y-10) = 2(y-10) \cdot 1 = 2(y-10) dydL=2(y−10)⋅dyd(y−10)=2(y−10)⋅1=2(y−10)
- d y d u = d d u ( u 2 ) = 2 u \frac{dy}{du} = \frac{d}{du}(u^2) = 2u dudy=dud(u2)=2u
- d u d x = d d x ( 2 x + 1 ) = 2 \frac{du}{dx} = \frac{d}{dx}(2x+1) = 2 dxdu=dxd(2x+1)=2
所以, d L d x = 2 ( y − 10 ) ⋅ 2 u ⋅ 2 = 8 u ( y − 10 ) \frac{dL}{dx} = 2(y-10) \cdot 2u \cdot 2 = 8u(y-10) dxdL=2(y−10)⋅2u⋅2=8u(y−10)。
如果需要完全用 x x x 表示,可以将 u = 2 x + 1 u=2x+1 u=2x+1 和 y = u 2 = ( 2 x + 1 ) 2 y=u^2=(2x+1)^2 y=u2=(2x+1)2 代入:
d L d x = 8 ( 2 x + 1 ) ( ( 2 x + 1 ) 2 − 10 ) \frac{dL}{dx} = 8(2x+1)((2x+1)^2 - 10) dxdL=8(2x+1)((2x+1)2−10)
5. Jacobian 与 Hessian (概念)
(a) Jacobian矩阵的维度是 (输出维度) × \times × (输入维度)。所以,这个Jacobian矩阵的维度是 5 × 10 5 \times 10 5×10。
(b) Hessian矩阵的对角线元素 ∂ 2 L ∂ w i 2 \frac{\partial^2 L}{\partial w_i^2} ∂wi2∂2L 是损失函数 L L L 关于参数 w i w_i wi 的二阶偏导数(保持其他参数不变)。类似于单变量函数的二阶导数,它描述了损失函数在 w i w_i wi 方向上的曲率或“弯曲程度”。
* 如果 ∂ 2 L ∂ w i 2 > 0 \frac{\partial^2 L}{\partial w_i^2} > 0 ∂wi2∂2L>0,表示在 w i w_i wi 方向上,损失函数的图像是向上凹的(像碗一样)。
* 如果 ∂ 2 L ∂ w i 2 < 0 \frac{\partial^2 L}{\partial w_i^2} < 0 ∂wi2∂2L<0,表示在 w i w_i wi 方向上,损失函数的图像是向下凹的(像帽子一样)。
* 如果 ∂ 2 L ∂ w i 2 = 0 \frac{\partial^2 L}{\partial w_i^2} = 0 ∂wi2∂2L=0,表示在 w i w_i wi 方向上,曲率可能是平坦的(需要更高阶导数判断)。
这对于判断一个临界点是局部最小值、最大值还是鞍点的一部分信息很有用。