25.5.19 强化学习笔记1
强化学习
多臂老虎机
prob是概率的意思
老虎机本身的功能需要先设计,就是有k个拉杆,然后每个拉杆有自己的概率,概率是获奖概率。并且我们需要将拉杆个数和获奖概率还有获奖最大概率给统计出来——这些内容构成老虎机类的基本属性。
class BernoulliBandit:""" 伯努利多臂老虎机,输入K表示拉杆个数 """def __init__(self, K):self.probs = np.random.uniform(size=K) # 随机生成K个0~1的数,作为拉动每根拉杆的获奖# 概率self.best_idx = np.argmax(self.probs) # 获奖概率最大的拉杆self.best_prob = self.probs[self.best_idx] # 最大的获奖概率self.K = Kdef step(self, k):# 当玩家选择了k号拉杆后,根据拉动该老虎机的k号拉杆获得奖励的概率返回1(获奖)或0(未# 获奖)if np.random.rand() < self.probs[k]:return 1else:return 0np.random.seed(1) # 设定随机种子,使实验具有可重复性
K = 10
bandit_10_arm = BernoulliBandit(K)
print("随机生成了一个%d臂伯努利老虎机" % K)
print("获奖概率最大的拉杆为%d号,其获奖概率为%.4f" %(bandit_10_arm.best_idx, bandit_10_arm.best_prob))
随后我们开始设计训练流程,强化学习并不是一次性就能训练好的,需要有一个循环,因此我们开始设计循环的框架。至于是如何循环的,和算法有关,因此我们现在先完成外部的框架。
!!!有一点需要注意,我们设计solve类(也就是循环体)的时候,是需要用到老虎机的特性的,也就是说需要用到本老虎机中的一些属性,因此我们可以利用python中的组合特性,在init函数中直接传入一个BernoulliBandit对象(但是不需要和cpp一样标明类型),我们就可以在solve类中用到老虎机的一些属性,这很有用!!!
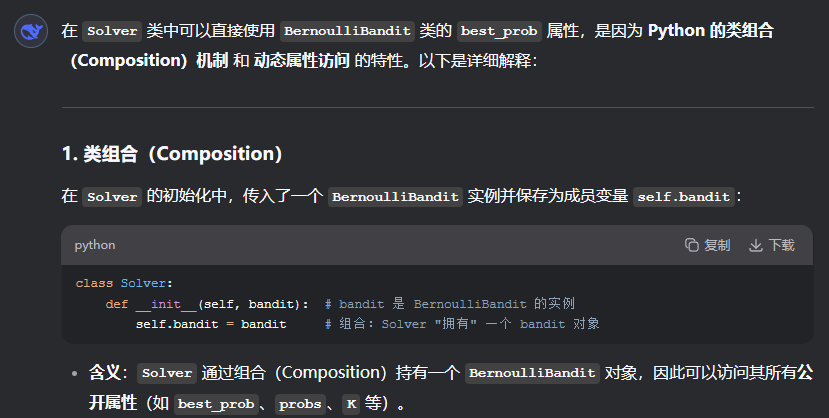
除此之外,我们还可以讨论这样设计的合理性,不同类有不同的分工,因此分开设计会有低耦合性。

class Solver:""" 多臂老虎机算法基本框架 """def __init__(self, bandit):self.bandit = banditself.counts = np.zeros(self.bandit.K) # 每根拉杆的尝试次数self.regret = 0. # 当前步的累积懊悔self.actions = [] # 维护一个列表,记录每一步的动作self.regrets = [] # 维护一个列表,记录每一步的累积懊悔def update_regret(self, k):# 计算累积懊悔并保存,k为本次动作选择的拉杆的编号self.regret += self.bandit.best_prob - self.bandit.probs[k] self.regrets.append(self.regret)def run_one_step(self):# 返回当前动作选择哪一根拉杆,由每个具体的策略实现raise NotImplementedErrordef run(self, num_steps):# 运行一定次数,num_steps为总运行次数for _ in range(num_steps):k = self.run_one_step()self.counts[k] += 1self.actions.append(k)self.update_regret(k)
注意懊悔累计函数的设计,当前我们老虎机的奖励是一定的,但是概率不一定,所以懊悔的是概率,也可以将懊悔当做期望来用,所以是最高中奖概率减去当前中奖概率;至于run_one_step函数,和每步的策略相关,这个和具体的算法相关;至于run函数就是在循环过程中顺带记录每次的决策和懊悔值到列表中。
最后我们看看奖励机制,公式是简化了的,为了降低算法复杂度
