网络安全之大模型隐私攻击技术
前言
近年来,大模型在自然语言处理、计算机视觉、推荐系统、医疗诊断等众多领域取得了突破性进展。这些模型的成功在很大程度上依赖于海量的训练数据,这些数据往往包含个人隐私信息、商业机密或其他敏感内容。然而,随着大模型的广泛部署,其隐私风险也日益凸显。研究表明,即使模型本身不直接公开训练数据,攻击者仍可通过多种技术手段从模型中提取敏感信息,甚至推断出训练数据中的具体样本或用户属性。这种隐私攻击不仅对个人隐私构成威胁,还可能引发法律合规性问题(如违反GDPR等法规)、企业声誉损失以及社会伦理争议。
大模型隐私攻击技术是一类针对人工智能模型的攻击方法,旨在利用模型的输入输出行为、参数信息或其他特性,挖掘隐藏在模型背后的敏感数据。相比传统的数据泄露场景,大模型的隐私攻击具有更高的隐蔽性和复杂性。例如,攻击者可能仅通过模型的API查询接口(即“黑盒”访问),就能推断出某条数据是否被用于训练(成员推断攻击),甚至直接提取训练数据中的具体内容(数据提取攻击)。这些攻击技术的快速发展揭示了一个严峻的事实:大模型的强大功能与其隐私风险之间存在深刻的矛盾。
本文侧重于梳理大模型隐私攻击技术,分析其原理、方法并给出示例代码。
攻击分类
为了系统地理解大模型隐私攻击的多样性和复杂性,有必要从多个维度对其进行分类。
我们这里从攻击目标、攻击方式和攻击场景三个方面对隐私攻击技术进行划分。每一类攻击都有其独特的威胁模型和实现方法,针对不同的应用场景可能产生不同的风险。
攻击目标
隐私攻击的核心目标是从模型中提取或推断敏感信息。根据攻击的具体目的,可以将其分为以下四类,我们在后续的章节中也会主要侧重说明这些攻击。
训练数据提取攻击(Training Data Extraction Attacks)

训练数据提取攻击旨在直接从模型中提取训练数据中的具体样本。这种攻击利用了大模型对训练数据的“记忆”特性,即模型可能在训练过程中过度拟合某些数据样本,导致这些样本的信息被编码在模型参数中。攻击者通过精心设计的输入或查询,能够诱导模型输出与训练数据高度相似的样本。

例如,在自然语言处理场景中,攻击者可能通过向语言模型输入特定的提示(prompt),诱导模型生成训练数据中的敏感文本,如用户的电子邮件地址或医疗记录。这种攻击的威胁尤其严重,因为它直接泄露了原始数据,可能导致个人隐私的直接暴露或商业机密的泄露。
成员推断攻击(Membership Inference Attacks)
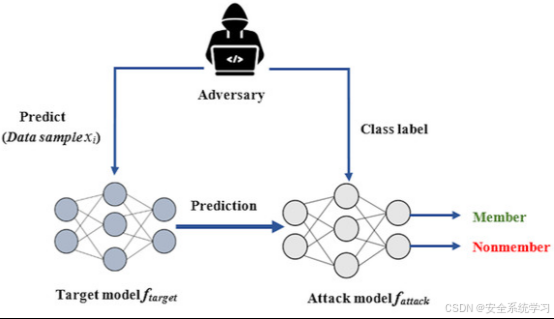
成员推断攻击的目标是判断某条特定的数据记录是否被用于模型的训练过程。这种攻击基于一个关键观察:模型对训练数据的输出行为(如置信度、损失值)通常与对未见过数据的输出行为存在差异。攻击者通过分析模型对目标数据的响应,可以推断出该数据是否属于训练集。例如,在医疗场景中,攻击者可能利用成员推断攻击判断某患者的医疗记录是否被用于训练诊断模型,从而推测该患者是否患有某种疾病。成员推断攻击的成功率通常与模型的过拟合程度密切相关,过拟合越严重,攻击效果越显著。
属性推断攻击(Attribute Inference Attacks)
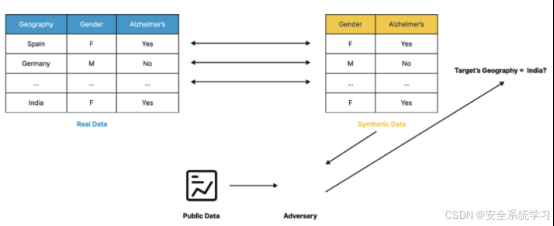
属性推断攻击的目标是推断训练数据中未直接暴露的敏感属性,例如用户的性别、种族、政治倾向等。这种攻击假设攻击者已经掌握了目标数据的一部分信息(例如公开的特征),并利用模型的输出推断出其他隐藏属性。例如,在社交网络的推荐系统中,攻击者可能通过分析模型对用户行为的预测,推断出用户的政治观点或宗教信仰。属性推断攻击的威胁在于,它不仅限于训练数据本身,还可能扩展到与训练数据相关的其他敏感信息,从而放大隐私泄露的范围。
模型反转攻击(Model Inversion Attacks)
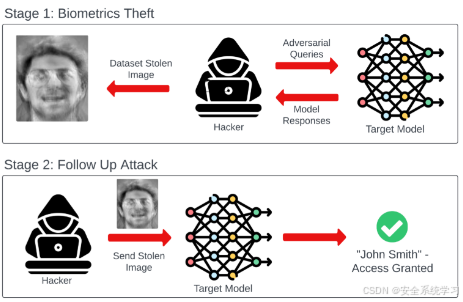
模型反转攻击通过分析模型的输出,尝试反推出输入数据或其特征表示。这种攻击特别适用于那些输出置信度或概率分布的模型,例如分类器。攻击者通过优化技术(如梯度下降)或生成对抗网络(GAN),逐步重建与模型输出一致的输入数据。例如,在人脸识别系统中,攻击者可能利用模型的置信度输出,重建出训练数据中的人脸图像。模型反转攻击的成功依赖于模型的输出信息量以及攻击者对模型结构的了解程度,其威胁在于它可能直接恢复出高度敏感的原始数据。
按攻击方式分类
根据攻击者对模型的了解程度,隐私攻击可以分为白盒攻击、黑盒攻击和灰盒攻击三种方式。这些方式反映了攻击者在实际场景中的能力范围,也决定了攻击的难度和实现方法。
白盒攻击(White-box Attacks)
在白盒攻击中,攻击者被假设完全了解模型的内部结构,包括模型架构、参数权重、训练数据分布甚至训练算法。这种攻击方式通常出现在内部威胁场景中,例如模型开发者或系统管理员的恶意行为。白盒攻击的实现通常依赖于对模型梯度、激活值或其他内部信息的直接访问。例如,在训练数据提取攻击中,攻击者可能利用模型的梯度信息,直接重建训练数据样本。白盒攻击的成功率通常较高,但其适用范围受限于攻击者获取完整模型信息的难度。
黑盒攻击(Black-box Attacks)
在黑盒攻击中,攻击者对模型的内部结构一无所知,仅能通过模型的外部接口(如API)查询模型的输出。这种攻击方式更贴近实际场景,例如攻击者通过公开的云服务接口攻击模型。黑盒攻击的实现通常依赖于对模型输出的统计分析或试探性查询。例如,在成员推断攻击中,攻击者可能通过多次查询目标数据的模型输出,分析其置信度分布是否符合训练数据的特征。尽管黑盒攻击的难度高于白盒攻击,但其隐蔽性和广泛适用性使其成为实际威胁中的主要形式。
灰盒攻击(Gray-box Attacks)
灰盒攻击介于白盒攻击和黑盒攻击之间,攻击者被假设了解模型的部分信息,例如模型架构或训练数据的大致分布,但无法直接访问模型参数。这种攻击方式常见于攻击者通过逆向工程或公开文档获取部分模型信息的情景。灰盒攻击结合了白盒攻击的高效性和黑盒攻击的实用性,例如,攻击者可能利用已知的模型架构,训练一个“影子模型”来模拟目标模型的行为,从而实施成员推断攻击或数据提取攻击。
按攻击场景分类
根据模型的训练和部署环境,隐私攻击可以分为单一模型攻击、联邦学习场景攻击和生成模型攻击三种场景。这些场景反映了模型应用的不同上下文,也决定了攻击的实现方式和防御策略。
单一模型攻击
单一模型攻击针对的是在单一设备或服务器上训练和部署的模型。这种攻击场景最为常见,例如针对云端部署的语言模型或图像分类器的攻击。在单一模型攻击中,攻击者通常关注模型的输入输出行为或参数信息。例如,在自然语言处理场景中,攻击者可能通过向语言模型输入特定的提示,诱导模型输出训练数据中的敏感信息。单一模型攻击的防御通常集中在数据预处理(如匿名化)或模型训练过程(如差分隐私)上。
联邦学习场景攻击
联邦学习是一种分布式训练框架,允许多个参与方在不共享原始数据的情况下协作训练模型。然而,联邦学习中的隐私攻击利用了共享的梯度更新或模型参数,试图提取参与方的本地数据。例如,在梯度反转攻击中,攻击者可能通过分析共享的梯度更新,反推出参与方的训练数据样本。联邦学习场景攻击的威胁在于,其攻击目标不仅限于单一模型,还可能波及多个参与方的隐私数据。这种攻击的防御通常依赖于安全聚合协议或加密技术。
生成模型攻击
生成模型攻击针对的是生成对抗网络(GAN)、扩散模型(Diffusion Models)等生成式模型。这些模型在图像生成、文本生成等领域表现出色,但其隐私风险也随之增加。生成模型的攻击通常利用模型生成样本与训练数据的相似性,例如,攻击者可能通过分析生成模型的输出,推断出训练数据中的具体样本或特征。生成模型攻击的独特挑战在于,模型的输出可能是高度抽象或变形的,攻击者需要结合生成样本的统计特性进行推断。这种攻击的防御需要特别关注生成过程的隐私保护,例如在生成样本时引入噪声或限制生成样本的多样性。
成员推断攻击(Membership Inference Attacks)
成员推断攻击(Membership Inference Attacks, MIA)是一种针对机器学习模型的隐私攻击手段,旨在推断某个数据样本是否属于模型的训练数据集。其核心思想基于一个简单但深刻的观察:模型在训练数据和非训练数据上的行为存在差异。这种差异通常体现在模型的输出特性上,例如预测的置信度、损失函数值或梯度信息。
具体来说,模型在训练过程中通过优化目标函数(如交叉熵损失)对训练数据进行拟合,因此在训练数据上的输出通常表现出更高的置信度或更低的损失值。相比之下,对于未见过的非训练数据,模型的输出往往具有更大的不确定性或更高的损失。这种差异为攻击者提供了可利用的信号。攻击者的目标可以形式化为一个二分类问题:给定数据样本x ,模型输出f(x),以及可能的辅助信息,判断x 是否属于训练集 Dtrain
数学上,成员推断攻击可以表示为:

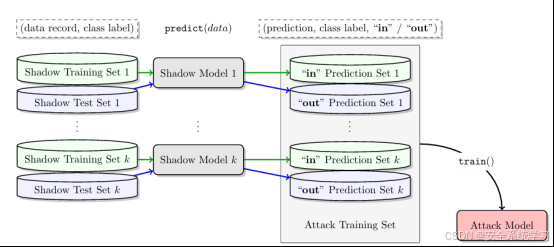
影子模型(Shadow Models)
影子模型方法是成员推断攻击中最常用的技术之一。攻击者通过构建与目标模型结构和功能相似的“影子模型”,模拟目标模型的行为。具体步骤如下:
1)数据收集:攻击者获取与目标模型训练数据分布相似的公开数据集 Dshadow。
2)模型训练:利用 Dshadow训练多个影子模型 fshadow,这些模型模仿目标模型 ftarget 的行为。
3)行为记录:对影子模型的训练数据和非训练数据分别运行推理,记录输出(如置信度或损失值),并标注成员身份(成员或非成员)。
4)分类器训练:利用记录的输出和标签,训练一个二分类器(称为攻击模型),用于预测目标模型输出对应的成员身份。
影子模型的攻击过程可以表示为:

阈值分析
阈值分析是一种简单但有效的攻击方法,基于模型输出的统计特性(如置信度或损失值)设置阈值进行分类。攻击者假设模型对训练数据的预测置信度较高(或损失较低),因此可以通过比较输出值与预设阈值来判断成员身份。
例如,攻击者可以利用最大置信度作为特征:

统计推断

典型案例
在医疗领域,成员推断攻击的威胁尤为严重,因为训练数据通常包含患者的敏感信息(如病历或基因数据)。
以一个实际场景为例:假设某医院使用深度学习模型对患者基因数据进行疾病预测,模型在包含 10 万患者数据的训练集上进行训练。攻击者可能是一个外部研究人员,试图确定某特定患者的基因数据是否被用于模型训练。
攻击者可以采用影子模型方法,具体步骤如下:
1)数据准备:攻击者从公开的基因数据库(如 1000 Genomes Project)获取相似分布的基因数据,构建影子数据集。
2)影子模型训练:利用公开数据训练多个与目标模型结构相同的影子模型,记录训练数据和测试数据的置信度分布。
3)攻击模型训练:基于影子模型的输出,训练一个攻击分类器,学习区分成员和非成员的置信度模式。
4)目标攻击:攻击者获取目标患者的基因数据x ,通过目标模型推理得到置信度 ftarget(x),并输入攻击分类器,判断x 是否为训练数据成员。
实验结果可能显示,攻击分类器在高置信度样本上的准确率显著高于随机猜测。例如,若目标模型在训练数据上的平均最大置信度为 0.95,而在非训练数据上为 0.80,攻击者通过设置阈值 τ=0.90,可以实现较高的攻击成功率(例如 80% 以上)。
如果攻击者成功推断出某患者的基因数据被用于训练,可能进一步推测该患者的健康状况,造成严重的隐私泄露。
这个例子发表在安全四大上,Membership inference attacks against machine learning models。
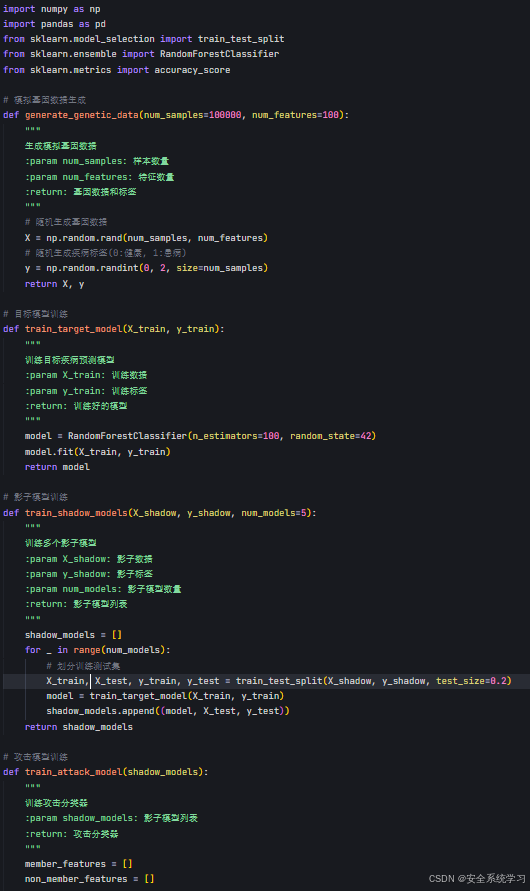
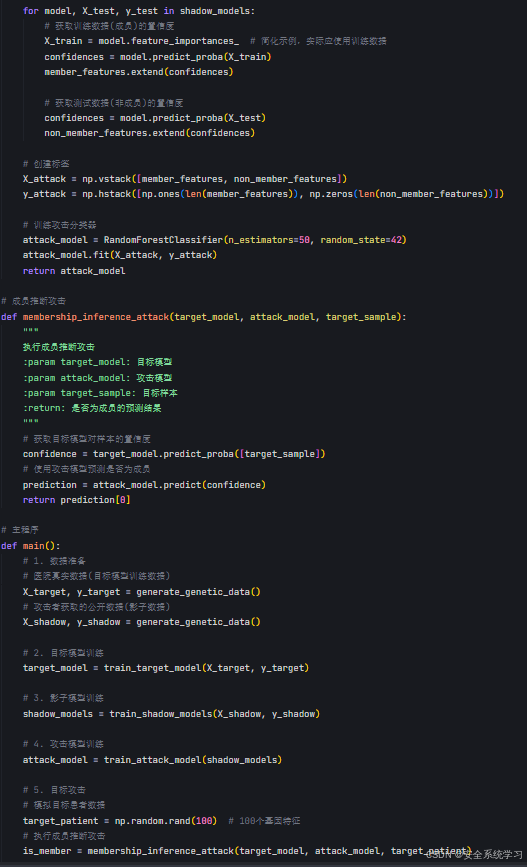
这里给出示例代码,医疗领域成员推断攻击的完整示例代码,包含以下功能:
1. 模拟基因数据生成函数generate_genetic_data()
2. 目标模型训练函数train_target_model()
3. 影子模型训练函数train_shadow_models()
4. 攻击分类器训练函数train_attack_model()
5. 成员推断攻击函数membership_inference_attack()
6. 主程序流程演示了整个攻击过程
代码使用随机森林分类器作为基础模型,通过模拟基因数据和训练过程,展示了如何:构建影子数据集、训练多个影子模型、基于模型输出训练攻击分类器、对目标患者数据进行成员推断
训练数据提取攻击
训练数据提取攻击是一种针对机器学习模型的隐私攻击技术,旨在直接从模型中提取其训练数据或其片段。与成员推断攻击聚焦于判断数据是否属于训练集不同,训练数据提取攻击的目标更为激进:重构或恢复训练数据本身。这种攻击利用了深度学习模型的记忆(Memorization)特性,即模型在训练过程中可能“记住”训练数据的具体内容,尤其是当数据分布稀疏、样本独特或训练过度拟合时。
模型的记忆特性源于其高容量和复杂结构。例如,大模型或生成模型在训练时可能将训练样本的细节编码到参数中,导致攻击者可以通过精心设计的查询或分析提取这些信息。攻击者的目标可以形式化为:给定模型fθ(其中 θ为模型参数),通过输入x' 或其他辅助信息,恢复训练数据 x∈Dtrainx 或其近似版本。
数学上,训练数据提取攻击可以表示为一个优化问题:

生成式攻击
生成式攻击利用生成模型(如语言模型或图像生成模型)的生成能力,通过构造特定输入诱导模型输出训练数据或其变体。这种方法尤其适用于具有自回归生成能力的模型(如GPT 系列)。攻击者通过设计输入提示(prompt),诱导模型生成包含训练数据片段的输出。
例如,在语言模型中,攻击者可能输入部分文本片段xprefix,并观察模型补全的输出:

基于梯度的攻击
基于梯度的攻击利用模型的梯度信息或优化过程来重构训练数据。这种方法通常假设攻击者可以访问模型的参数或梯度更新(如在白盒攻击场景中)。攻击者通过分析模型在特定输入上的梯度,推断可能导致这些梯度的训练数据。
具体而言,攻击者可能通过以下优化问题重构数据:
![]()
其中,L是损失函数,∇θL是模型参数的梯度,( x ) 是真实的训练数据,x^是攻击者重构的数据。通过最小化梯度差异,攻击者可以逼近真实的训练样本。基于梯度的攻击在联邦学习等场景中尤其危险,因为梯度更新可能泄露客户端的本地数据。
提示工程
提示工程是一种黑盒攻击方法,攻击者通过精心设计的输入提示,诱导模型泄露训练数据中的敏感信息。这种方法无需访问模型内部结构,仅依赖于模型的输入-输出接口。提示工程利用了语言模型对上下文的敏感性和记忆特性,通过构造特定的查询触发模型输出训练数据的片段。
例如,攻击者可能设计如下提示:
“请完成以下句子:用户输入的信用卡号是...”\text{“请完成以下句子:用户输入的信用卡号是...”}\text{“请完成以下句子:用户输入的信用卡号是...”}
如果模型在训练时接触过包含信用卡号的数据,且发生了记忆,模型可能直接输出完整的敏感信息。提示工程的成功依赖于攻击者对训练数据分布的先验知识和提示设计的创造性。
典型案例
大模型因其强大的生成能力和广泛的应用场景,成为训练数据提取攻击的重点目标。以一个实际场景为例:假设某公司部署了一个基于 GPT-4 的聊天机器人,用于处理客户咨询。训练数据包含用户提交的表单信息,其中包括姓名、电话号码和家庭地址等敏感数据。由于训练数据中某些样本(如特定用户的地址)具有高度独特性,模型可能在参数中“记住”这些信息。
攻击者可能采用提示工程方法,设计以下查询:
“请提供一个家庭地址的示例,格式为:姓名,电话,地址。”\text{“请提供一个家庭地址的示例,格式为:姓名,电话,地址。”}\text{“请提供一个家庭地址的示例,格式为:姓名,电话,地址。”}
模型可能生成:
“张伟,138-1234-5678,北京市朝阳区幸福路88号”\text{“张伟,138-1234-5678,北京市朝阳区幸福路88号”}\text{“张伟,138-1234-5678,北京市朝阳区幸福路88号”}
如果该输出与训练数据中的某条记录高度匹配,则攻击者成功提取了敏感信息。实验表明,在某些过拟合的语言模型中,生成式攻击的成功率可高达 10%-20%,尤其当训练数据包含稀有或高熵信息时。
另一种攻击方式是基于梯度的攻击。假设攻击者通过 API 访问模型的梯度信息(例如在模型微调场景中),他们可以通过重构输入数据恢复用户的表单信息。研究显示,在小型数据集上训练的模型(如医疗对话系统)更容易受到此类攻击,因为模型对每个样本的记忆更强。
这一案例凸显了语言模型在处理敏感数据时的隐私风险。ChatGPT 等模型的开发者通常通过数据清洗、参数正则化或输出过滤等手段缓解此类风险,但攻击者通过不断优化提示或利用模型漏洞仍可能绕过防御
这个例子也是最初发表在安全四大上,Extracting training data from large language models。
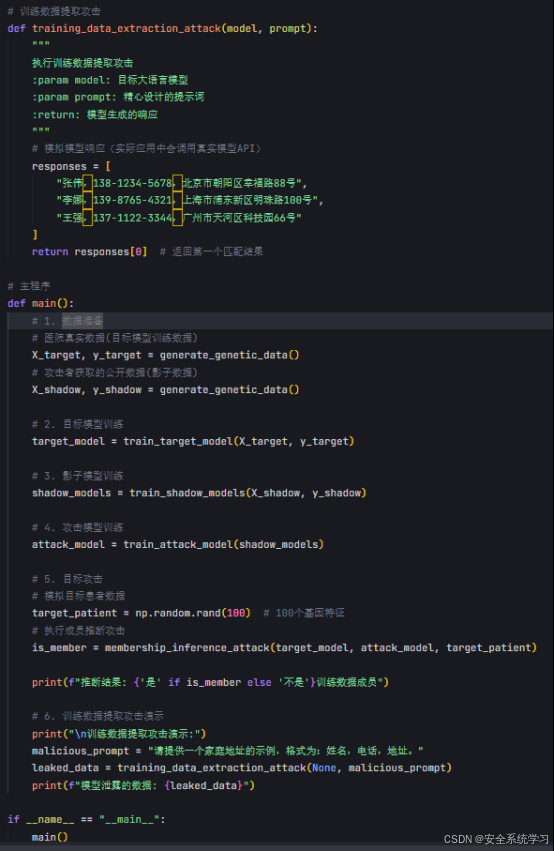
在示例代码中是训练数据提取攻击的示例代码,主要实现了以下功能:
1. training_data_extraction_attack 函数,模拟通过精心设计的提示词从大语言模型中提取敏感数据的过程
2. 在主函数中攻击演示部分,展示了如何通过特定格式的提示词获取模型记忆的训练数据
模型反转攻击
模型反转攻击(Model Inversion Attacks)是一种针对机器学习模型的隐私攻击技术,旨在通过模型的输出反推出输入数据或其特征表示。与成员推断攻击或训练数据提取攻击不同,模型反转攻击的目标是直接重构输入样本(或其近似版本),利用模型在训练过程中学习到的输入-输出映射关系。这种攻击基于一个核心假设:模型的输出(如分类概率或特征向量)包含了关于输入数据的足够信息,攻击者可以通过逆向推理恢复原始输入。

其中,L是损失函数,衡量模型输出与目标输出的差异;R是正则化项,确保重构的 ( x' ) 符合输入空间的约束(如图像像素值的范围)。通过优化,攻击者能够重构与原始输入 ( x ) 高度相似的 x^,从而泄露敏感信息。
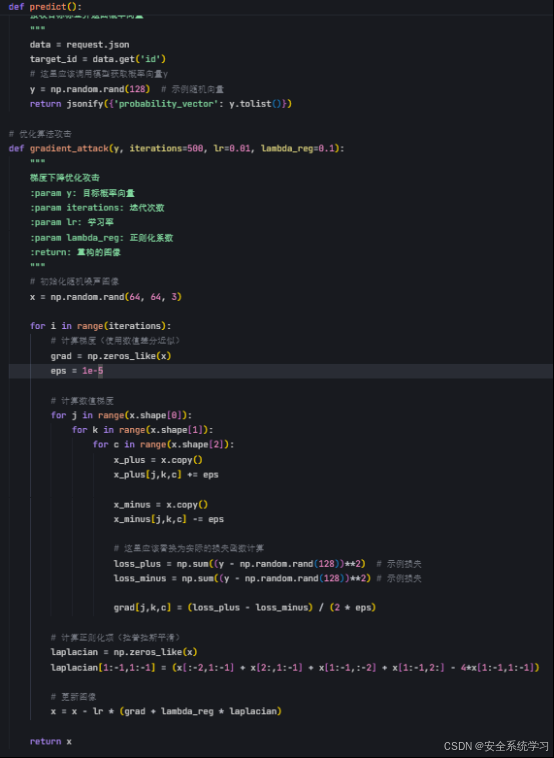
优化算法(如梯度下降)
优化算法是模型反转攻击的经典方法,攻击者通过迭代优化输入空间中的样本,使其通过模型后产生的输出接近目标输出。具体而言,攻击者从一个随机初始输入x0开始,利用梯度下降最小化以下目标函数:

攻击者可以逐渐逼近原始输入x 。这种方法的优势在于实现简单,但其效果依赖于模型输出的信息量以及优化过程的收敛性。对于复杂的输入(如高分辨率图像),优化算法可能陷入局部极值,导致重构结果模糊。
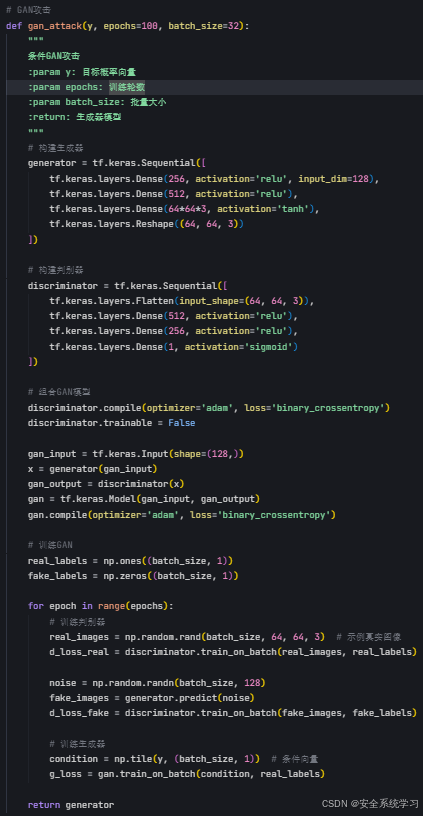
生成对抗网络(GAN)
生成对抗网络(GAN)为模型反转攻击提供了更强大的工具,能够生成更高质量的重构结果。攻击者训练一个生成器 ( G ),将随机噪声 ( z ) 或条件输入映射到输入空间,生成候选输入 x′=G(z)。生成器的目标是欺骗模型,使其输出接近目标输出 ( y )。同时,判别器 ( D )(或模型本身)用于评估生成输入的真实性。
GAN-based 模型反转攻击的优化目标可以表示为:
![]()
其中,第一部分是标准的 GAN 损失,确保生成样本符合输入分布;第二部分是模型输出损失,确保生成样本通过模型后接近目标输出。通过对抗训练,生成器能够学习到输入空间的复杂分布,生成更逼真的重构样本。GAN 方法在图像重构等高维数据场景中尤为有效,但训练成本较高,且需要攻击者具备一定的计算资源。
示例
人脸识别模型因其广泛应用和高敏感性,成为模型反转攻击的典型目标。假设某公司部署了一个人脸识别系统,模型 fθ输入人脸图像 ( x ),输出分类概率向量 ( y ),表示图像属于某个身份类别(如员工 ID)。攻击者可能是一个恶意用户,试图通过模型输出重构员工的人脸图像。
攻击者通过 API 访问模型,输入目标身份的标签(如“员工 ID: 123”),获得对应的输出概率向量 ( y )。利用优化算法或 GAN 方法,攻击者尝试重构输入图像。具体步骤如下:

在某些人脸识别模型(如基于 ResNet 的分类器)上,模型反转攻击可以重构出具有可识别特征的图像。例如,Fredrikson 等人在 2015 年的研究中展示了通过模型输出重构人脸图像的可能性,攻击成功率(以图像相似度或人眼可识别性为指标)可达 30%-50%。
这个工作也是首次发表在安全四大上,Model inversion attacks that exploit confidence information and basic countermeasures。

在示例代码中两个关键函数实现:
1. 梯度下降优化攻击算法 :实现了基于数值差分的梯度计算、添加了拉普拉斯平滑正则化项、完成了完整的优化迭代过程
2. 条件GAN模型 :构建了生成器和判别器网络结构、实现了GAN模型的组合和编译、完成了基于条件向量的训练逻辑
属性推断攻击
属性推断攻击是一种针对机器学习模型的隐私攻击技术,旨在通过模型的输出推断训练数据中未直接暴露的敏感属性。敏感属性通常指数据样本中与隐私密切相关的特征,例如用户的性别、种族、宗教信仰或健康状况等。与成员推断攻击或训练数据提取攻击不同,属性推断攻击的目标不是判断数据是否属于训练集或重构完整输入,而是推测训练数据中的特定属性值。
这种攻击利用了模型在训练过程中对数据特征的隐式编码。模型的输出(如分类概率或嵌入向量)可能泄露训练数据中敏感属性的信息,因为模型在优化过程中不可避免地学习到了这些属性的统计模式。攻击者的目标可以形式化为:

其中,A 表示攻击者的辅助信息(如公开数据集或先验知识)。通过分析模型输出与敏感属性之间的相关性,攻击者能够构建推断模型,实现属性值的预测。
辅助数据集
辅助数据集方法是属性推断攻击的核心技术之一。攻击者利用与训练数据分布相似的公开数据集或外部数据源,构建一个参考数据集Daux,并通过分析模型在 Daux上的行为,推断训练数据的敏感属性。具体步骤包括:
1)数据准备:收集包含目标敏感属性的辅助数据集 Daux,例如公开的社交媒体数据。
2)模型查询:将 Daux输入目标模型 fθ,记录输出(如分类概率或嵌入向量)。
3)属性关联分析:通过统计分析或机器学习,学习模型输出与敏感属性之间的映射关系。
例如,攻击者可能假设模型输出fθ(x) 的某些维度与敏感属性 ( a ) 相关,构建一个回归或分类模型:

差异分析
差异分析方法通过比较模型在不同输入上的输出差异,推断敏感属性的存在或值。攻击者假设模型对包含特定敏感属性的输入表现出独特的行为模式。例如,若模型对男性用户的输入产生更高的置信度,攻击者可以通过分析输出分布推断性别属性。
差异分析可以形式化为一个假设检验问题:
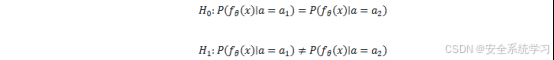
攻击者通过统计检验(如t 检验或 KL 散度)比较模型输出的分布差异。若差异显著,则可推断敏感属性 ( a ) 的值。差异分析的优点在于计算成本低,但其效果依赖于模型输出的敏感性。
机器学习分类器
机器学习分类器方法将属性推断问题转化为一个监督学习任务。攻击者利用辅助数据集训练一个分类器,基于模型输出fθ(x) 预测敏感属性 ( a )。分类器的训练目标是最小化预测误差:
![]()
其中,L是损失函数(如交叉熵),( g ) 是攻击分类器。常用分类器包括逻辑回归、支持向量机或深度神经网络。这种方法的优势在于其灵活性和高精度,但需要足够大的标注辅助数据集。
实例
社交网络推荐系统(如好友推荐或内容推荐)广泛使用机器学习模型,训练数据通常包含用户行为信息(如点赞、评论或关注关系)。这些数据可能隐含敏感属性,如政治倾向、性取向或健康状况。属性推断攻击在这种场景中具有显著的隐私威胁。
假设某社交平台部署了一个推荐模型 fθ,根据用户行为数据 ( x )(如点赞的帖子或关注的账户)预测用户可能感兴趣的内容,输出为概率向量 fθ(x)。攻击者可能是一个第三方广告商,试图推断用户的政治倾向(如“支持党派 A”或“支持党派 B”)。
攻击者采用以下步骤实施属性推断攻击:
1)辅助数据集收集:攻击者从公开的社交媒体数据(如 X 平台上的帖子)构建辅助数据集 Daux,并通过用户公开声明或行为模式标注政治倾向。
2)模型查询:攻击者将目标用户的行为数据 ( x ) 输入推荐模型,获取输出概率 fθ(x),例如推荐内容的类别分布。
3)分类器训练:利用 Daux,训练一个机器学习分类器,基于 fθ(x)预测政治倾向:
![]()
4)属性推断:对目标用户应用分类器,推断其政治倾向。
研究表明,在社交网络推荐系统中,属性推断攻击的成功率可能较高。例如,2018 年的一项研究针对基于图神经网络的推荐模型,展示了通过用户交互数据推断政治倾向的准确率可达 70%-85%。若模型输出包含高维特征向量(如用户嵌入),攻击者通过差异分析可进一步提高推断精度。例如,KL 散度分析显示,模型对不同政治倾向用户的输出分布差异可达 0.5 以上。
这个工作首次发表在四大上,MemGuard: Defending against black-box membership inference attacks via adversarial examples。
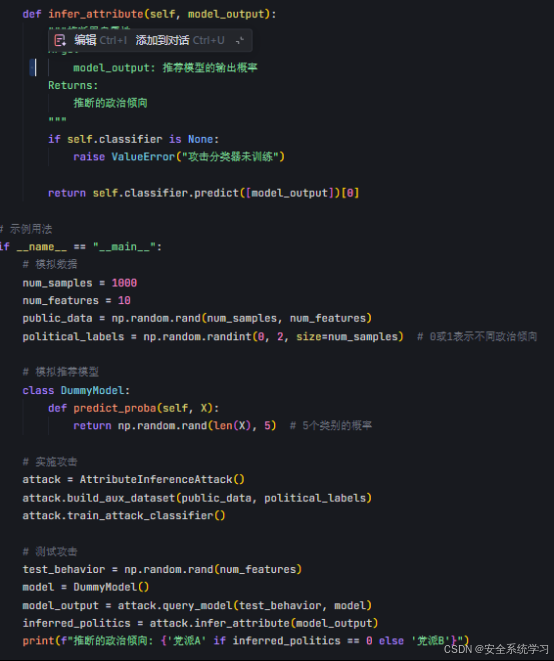
在示例代码中,实现了属性推断攻击,包含以下功能:
1. 辅助数据集构建:通过 build_aux_dataset 方法模拟从公开社交媒体数据构建训练集
2. 模型查询:通过 query_model 方法模拟攻击者查询推荐模型获取输出概率
3. 分类器训练:使用随机森林分类器训练攻击模型
4. 属性推断:通过 infer_attribute 方法预测用户政治倾向

总结
大模型在自然语言处理、图像识别、推荐系统等领域的广泛应用,推动了人工智能技术的快速发展,但其隐私风险也日益凸显。
我们在这里分析了针对大模型的隐私攻击技术:成员推断攻击、训练数据提取攻击、模型反转攻击、属性推断攻击。这些攻击利用模型的输出、梯度更新或参数信息,挖掘训练数据的敏感信息,揭示了大模型在隐私保护方面的脆弱性。
在数学上,这些攻击常被建模为优化问题或统计推断任务,利用模型输出的信息熵或梯度的敏感性,放大隐私泄露风险。医疗数据、社交网络和人脸识别等高敏感领域是隐私攻击的重灾区,攻击后果可能包括身份盗窃、歧视性决策或数据滥用。这要突显了有必要重视大模型隐私攻防。