初识 Redis
什么是 Redis?
在 Redis 官网中有介绍, Redis 就是一个存储空间,只不过这个存储空间是在内存上的,这也就代表存储在 Redis 中的数据访问起来会非常快,但也会有一个弊端,也就是内存资源是非常少的, Redis 中能存储的资源也是非常有限的。
和 MySQL 相比较, Redis 的访问速度快,能存储的内容少;MYSQL 的访问速度相对较慢,但由于 MYSQL 中的内容是存储在硬盘中的,也就代表 MYSQL 中能存储非常多的内容。
在现有的业务场景分为单机系统和分布式系统,单机状态下使用 MYSQL 会更好一点,但是在分布式系统中,使用 Redis 会更优。在分布式场景中,会有多台服务器,这些服务器依靠网络进行通信,而 Redis 就是基于网络,将变量存储在自己的内存中,但是别的机器也能使用。
什么是单机系统?
所谓“单机”,就是只有一台服务器,应用服务和存储服务均在一台机器上运行,但是一台机器的 CPU、内存、硬盘、网络等资源是有限的,当访问量过大时,就会将其中的某个资源消耗完,导致服务器挂掉,这时就涉及到两个处理办法:开源、节流。
开源:即增加更多的硬件资源,通过堆机器,达到增大 CPU、内存、硬盘、网络等资源,这就是下面会介绍到的“分布式系统”;
节流:即优化软件,找到在访问量过大的情况下会率先消耗掉的资源,再有目的性的拓展该资源,但是这种方案难度过于大。
什么是分布式系统?
所谓分布式,就是有多台机器提供服务,引入了分布式系统,会使得系统的复杂程度增加,也会使得出现 bug 的概率也会增加。
下面对常见的分布式系统进行介绍。
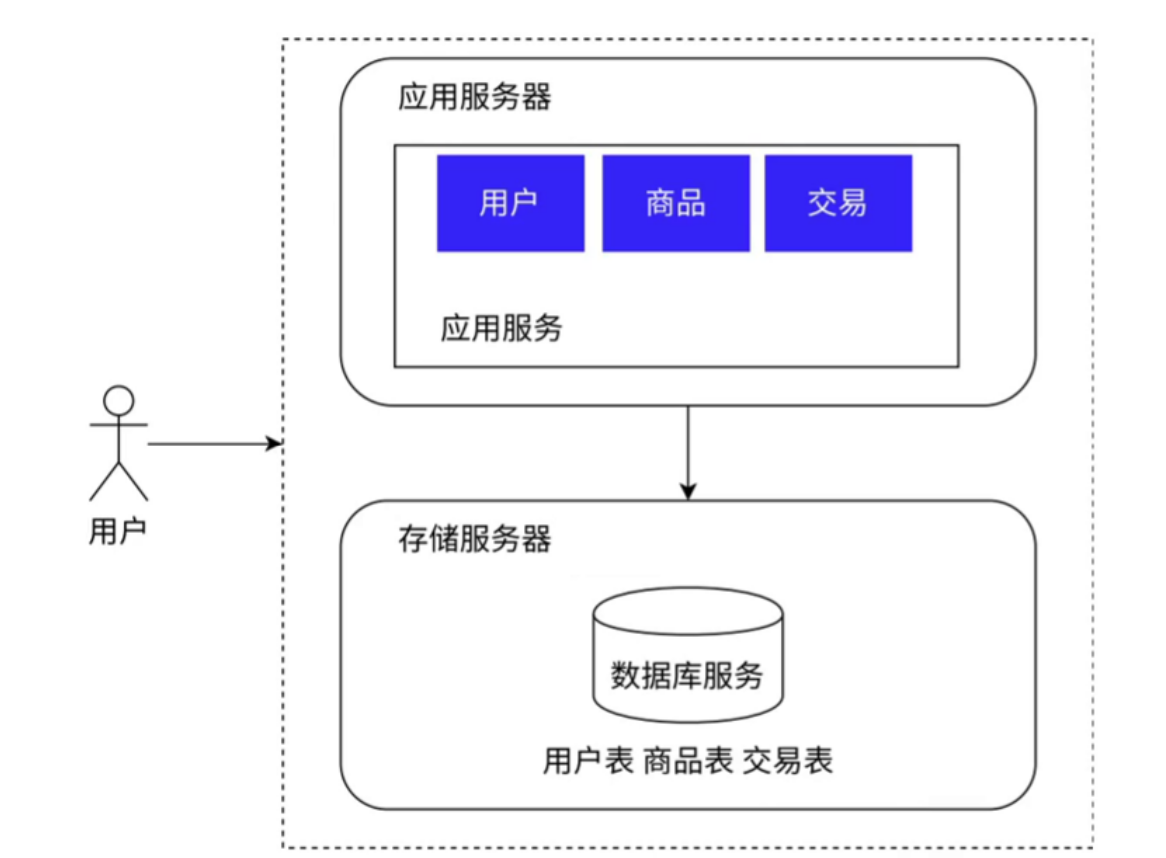
1、数据库与应用服务器分离
在日常场景中,应用服务器中的业务逻辑对 CPU、内存资源消耗更大,数据库对硬盘资源的消耗更大,这样就能将二者分开,对应用服务器提供更好的 CPU 和内存资源,对数据库服务器提供更大的硬盘空间和访问速度更快的硬盘。这样以来,就使得系统的性价比提高。如下图所示:
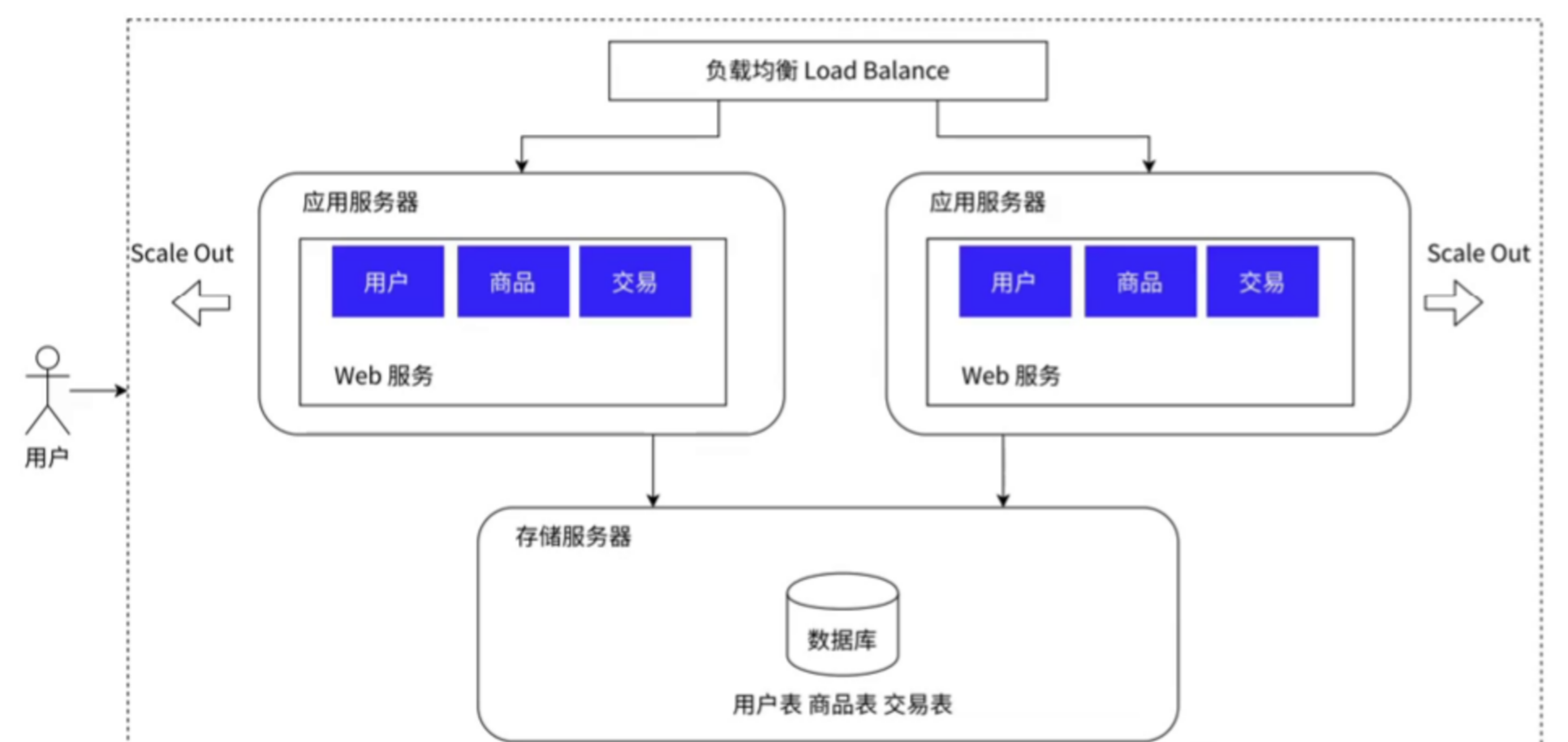
2、引入多台应用服务器
在上面的分布式系统中,只有一台应用服务器,当访问量过大时,依然会将服务器的 CPU 和内存资源给消耗完,这时服务器就会挂掉,对于这种情况,就需要引入更多的应用服务器,这样一来,即使有一两台机器挂掉了,别的机器也能分担多出来的访问量。
这些应用服务器通过负载均衡器联系起来,外部的请求先通过负载均衡器,由负载均衡器分配到某一台应用服务器进而处理这个请求。常见的分配算法有轮询等。如下图所示:
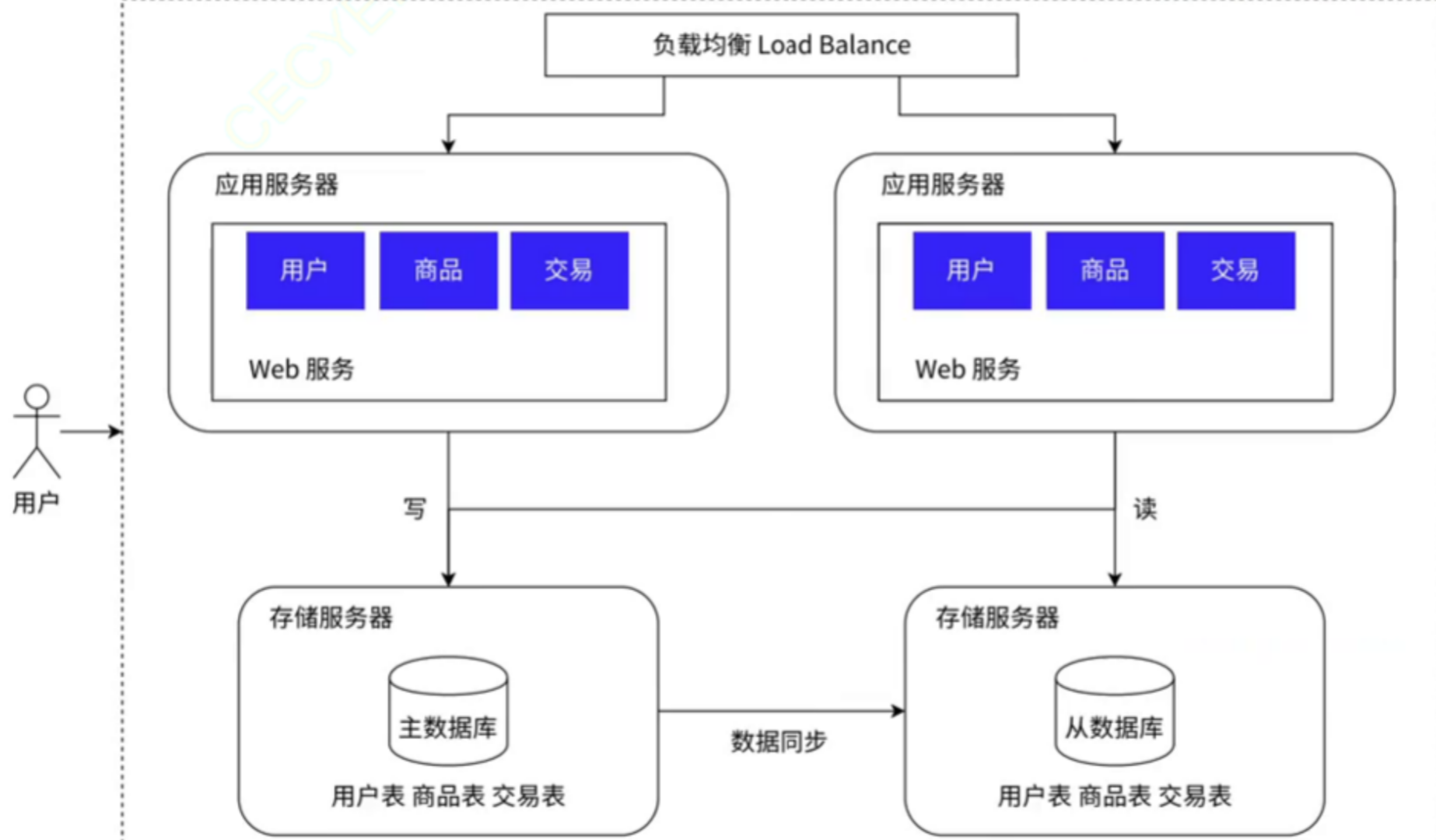
3、存储服务器采用 “读写分离”
当引入更多的应用服务器后,接收到的请求也就会变多,这样以来,存储服务器的压力就会变大,由于在大部分的业务场景中,读数据的比例很大,写数据的比例很小,就能将读数据的业务和写数据的业务分开,也就是设置 “主-从” 服务器,主数据库用来读数据,从数据库用来写数据,之后从数据库再对主数据库进行数据同步,将主数据库中修改的数据同步到从数据库中。
通常情况下,主服务器只有一个,但是从服务器有多个。如下图所示:
4、引入缓存,将冷热数据分离
在日常开发中,大部分的数据的访问遵从 “二八原则”,即 20% 的数据能应付 80% 的请求,由于缓存的访问速度快,就能够将这 20% 的数据存放至缓存中,剩下的 80% 的数据存放至数据库中,这样虽然缓存的空间小,但是我们存放的数据也相对应的少。于是就能引入缓存服务器(Redis),这样一来,虽然将数据分开存储了,但是总体来看,存储的依然是全量的数据。如下图所示:
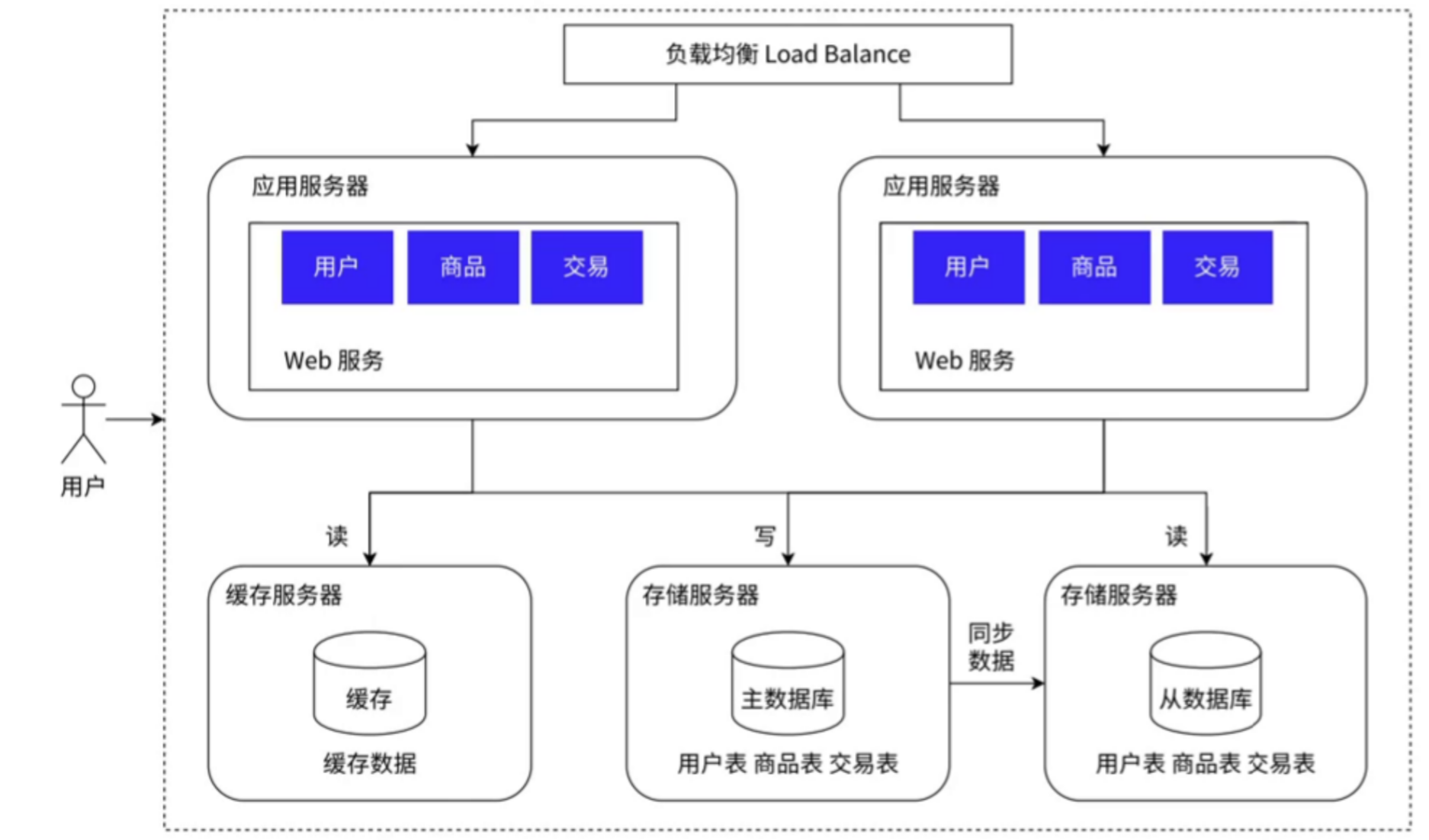
但是引入缓存服务器后,也就会出现新的问题,即数据服务器与缓存服务器的数据一致性问题。
5、对数据库 “分库分表”
当访问量加大后,对应的数据量就会加大,那么数据库服务器需要存储的数据就会增大。对于这种情况,就能针对数据库进行拆分,可以将一个较大的数据库拆分为多个小数据库,也可以将一个较大的表拆分为多张小表。如下图所示:
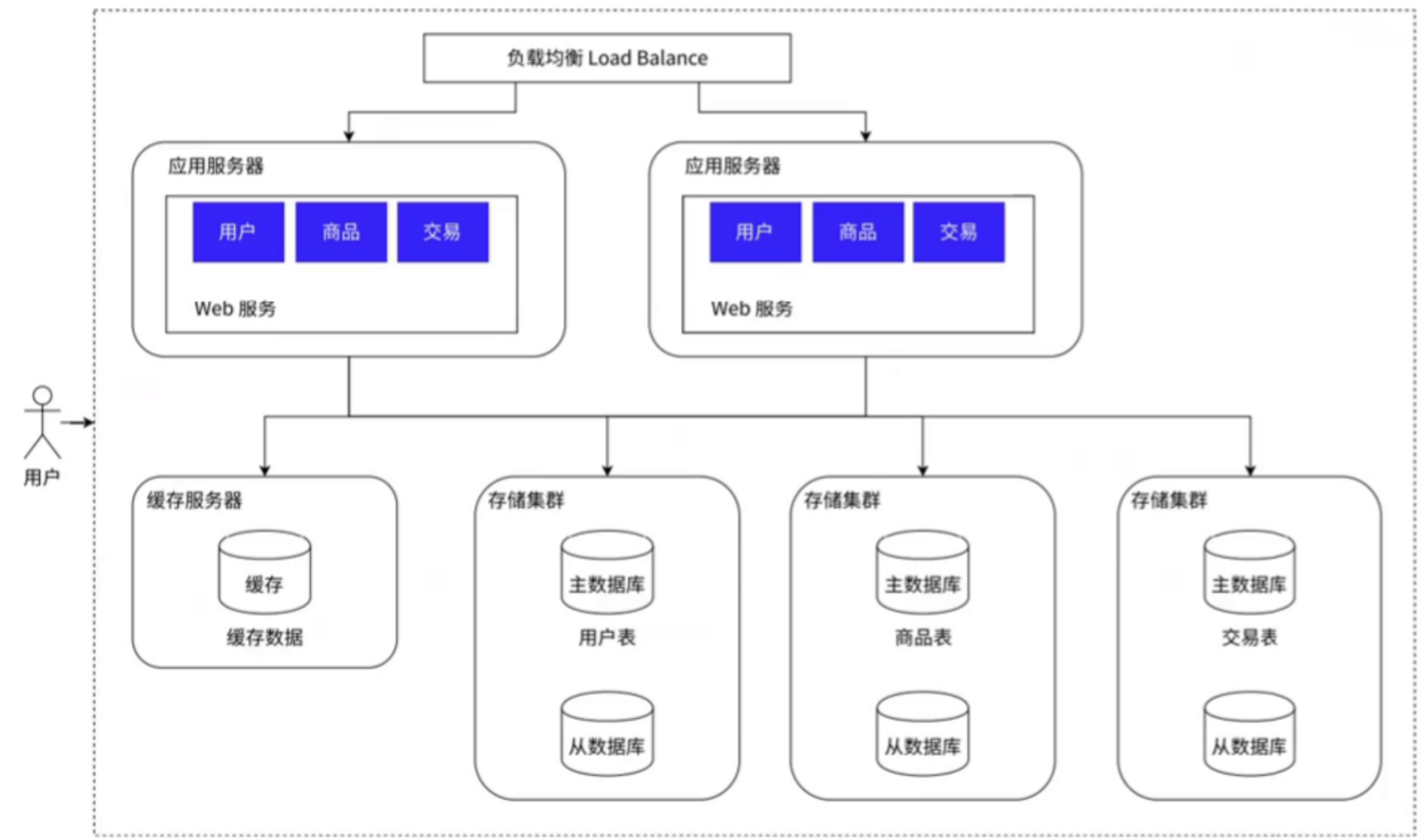
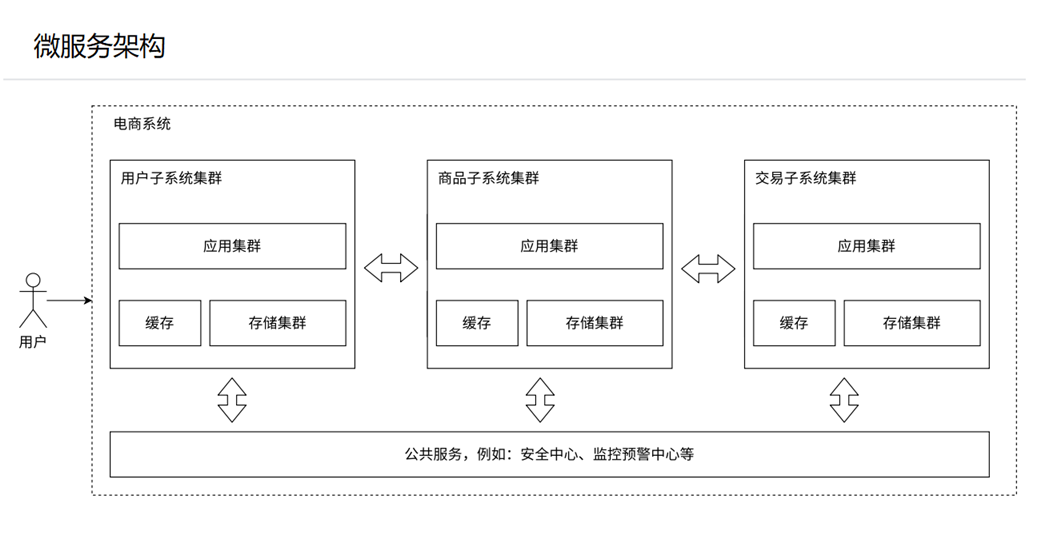
6、引入微服务架构
当服务器的业务过于复杂时,就需要将服务器进行拆分,每一个或多个服务器只处理单一的业务,这样就便于业务的处理,如下图所示: