【MySQL】基础操作



MySQL(二)基础操作
一、数据库操作
1.创建库
2.查看库
3.选中库
4.删除库
二、表操作
1.创建表
1.1[comment '注释']:
1.2,...:
2.查看表
2.1查看所有表
2.2查看表结构
3.删除表
三、记录操作
1.插入记录
1.1全列插入
1.2指定列插入
1.3多行插入
2.查询记录
2.1全列查询
select * 的危险性
2.2指定列查询
2.3表达式列查询
2.4别名查询
2.5去重查询
2.6排序查询
NULL的特性
2.7条件查询
2.8分页查询
3.修改记录
4.删除记录
四、通用操作
1.库级
if exists
2.表级
,...
3.记录级
3.1order by
3.2where
3.3limit-offset
4.查询级
4.1as
4.2distinct
5.插入级
全列
一、数据库操作
服务器层面 对数据库 的操作
1.创建库
create database [if not exists] db_name [character set utf8mb4];
在此服务器里 创建一个数据库
2.查看库
show databases;
查看此服务器里 所有的数据库
3.选中库
use db_name;
选中此服务器里的 一个数据库,从服务器层面 转到数据库层面 对表与记录的操作,进而进行 对表与记录的操作
4.删除库
drop database [if exists] db_name;
删除此服务器里的 一个数据库
二、表操作
数据库层面 对表 的操作
表结构
表 以字段 垂直划分属性,以记录 水平构出数据实体 组成表
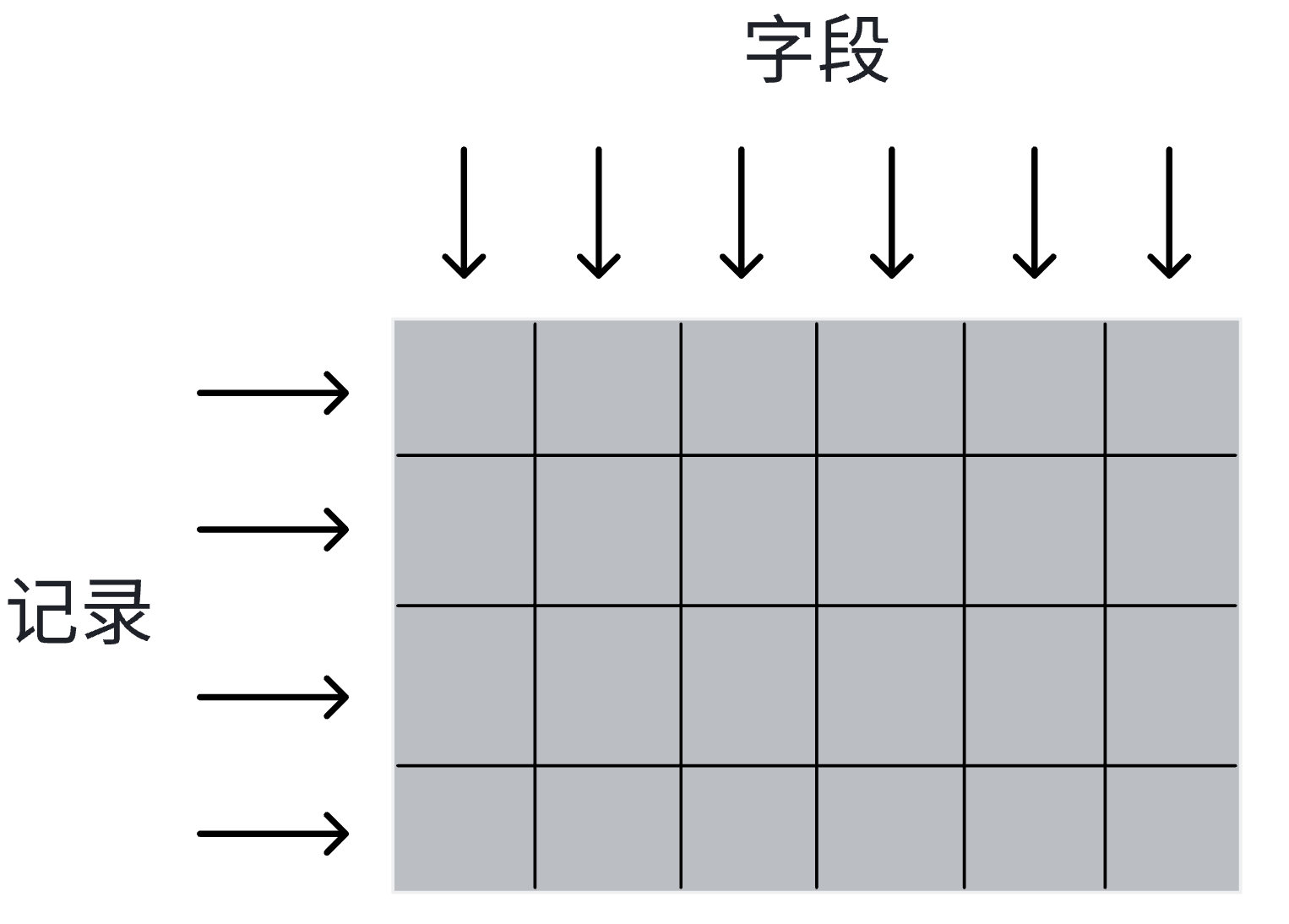
1.创建表
create table [if not exists] tb_name(field1 datatype[comment '注释'],...);
以列字段 创建出表的属性模板,创建出 空记录字段的初始表
1.1[comment '注释']:
创建时 可为字段附上 创建时的注释说明
1.2,...:
- 很多时候,可在 一个操作单元后面 加, 继续添数据单元,即可一次完成 多个单位的操作
2.查看表
2.1查看所有表
show tables;
查看此数据库中的 所有表
2.2查看表结构
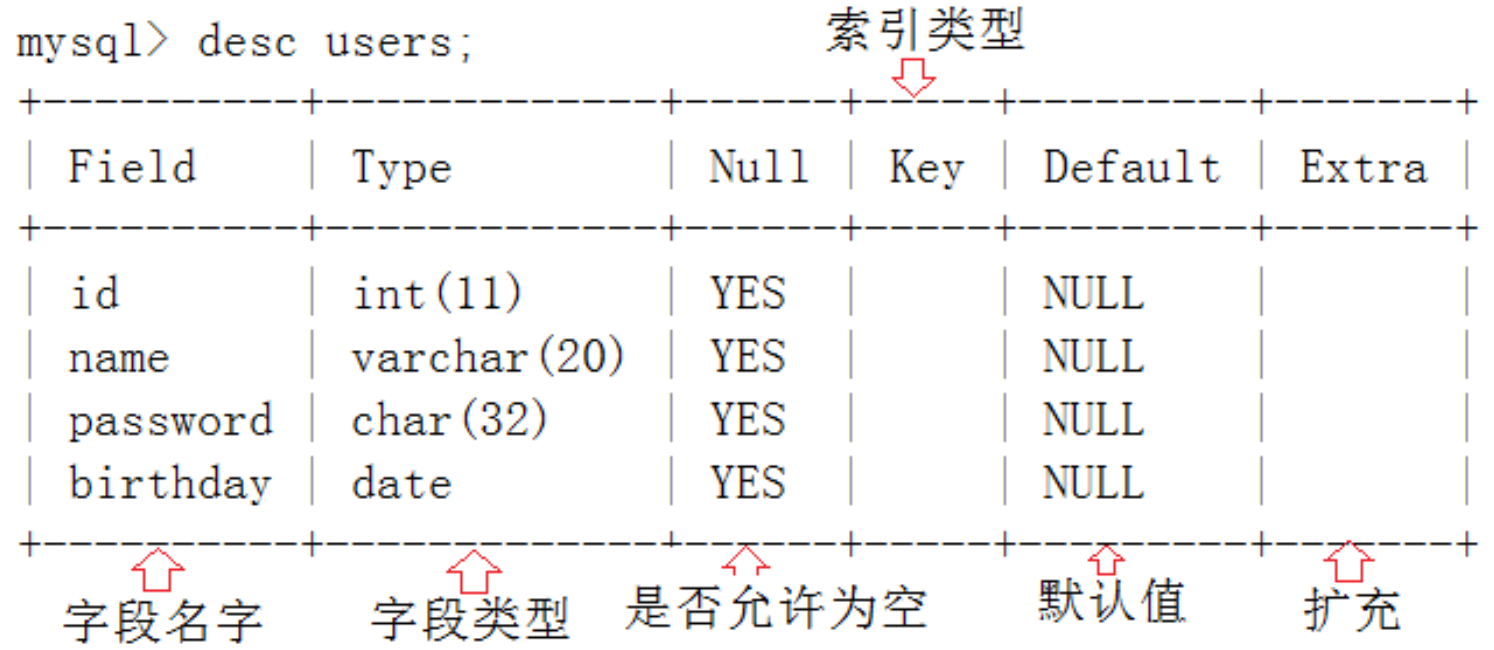
desc tb_name;
查看此数据库中的 指定表的结构,再次以表的结构形式 去描述此表的结构
3.删除表
drop table [if exists] tb_name1,...;
删除此数据库中的 指定表
三、记录操作
数据库层面 对记录的 操作
1.插入记录
- 插入的表名后面 不加列 默认视为 以全列加
1.1全列插入
insert [into] tb_name values (value1,...);
把记录的 所有列字段数据 都填充地插入
1.2指定列插入
insert [into] tb_name(col1,col3,...) values(value1,value3,...);
把记录的 指定列字段数据 填充地插入,记录的 未指定插入数据的列字段 会被填充为默认值
1.3多行插入
insert [into] tb_name values(value1,...), (value11,...),...
一次插入多条记录
2.查询记录
执行顺序
查询 会遍历该表的 所有记录的 所有字段:
- 每次以记录 为一个查询单位,先遍历完该记录的所有字段 将判定为需要的字段数据 保存
- 接着将保存的字段 代入条件表达式中 计算判断true或false
- 如果符合 就继续将保存的字段 代入查询表达式中 计算出结果
- 如果有定义别名 就以别名 作为返回缓冲区表中 此字段的列名
- 所有记录遍历完 返回缓冲区表完整生成后,如果有排序 就最后对此完整查询结果的返回表 进行排序
书写顺序
select [distinct] 列名 [as 别名] from 表名 [where] [order by] [limit]-[offset]
2.1全列查询
select * from tb_name;
把此表的 所有记录的 所有列字段 都需求地查询,*是通配符,可以代指所有列字段
select * 的危险性
所有查询的遍历 都是对所有记录的 所有列字段 都去遍历的,而select *危险之处在于 对所有记录的所有列字段 都纳入需求查询的字段,需求查询的字段太多了,当它们也大量符合条件时,会大量读取数据 使硬盘的IO跑满,网络返回传输大量符合数据 也会使网络的带宽给跑满,导致其它发送请求的客户端 都越积越多地得不到及时回应,而使服务器类似于挂了
2.2指定列查询
select col1,col3 from tb_name;
把此表的 所有记录的 指定列字段 需求地查询
2.3表达式列查询
select col1+col2 from tb_name;
把此表的 所有记录的 表达式列字段 需求地查询,对符合时的 把列字段表达式计算成结果 到查询结果的 表达式列字段中
2.4别名查询
select col [as] alias_name from tb_name;
- 把此表的 所有记录的 此查询结果列字段 换名
2.5去重查询
select distinct col1,... from tb_name;
- 会对指定列字段 查询结果 去重
如果是以多列地去重,就是以多列的 合为整体的结果 来去重
2.6排序查询
select col from tb_name order by col1[asc/desc],...;
- order by 列 指定 按一定顺序去操作
会对指定列字段的 查询结果 排序成 有序的查询结果,如果是以 多列地排序,就按顺序 优先级地排序,asc是升序、desc是降序,默认是以asc升序排序,null比任何数据都小,以null排序 升序排在最上,降序排在最下
NULL的特性
null参与大小比较,结果是最小
null参与运算计算,结果是null
null作为boolean值,视为false
2.7条件查询
select col from tb_name where condition
- where(条件表达式) 按 记录符合条件 去执行对记录的操作
将记录的 条件需求查询字段 代入条件表达式,为true 就将此记录的查询字段 保留到查询结果
| 运算符 | 说明 |
| >,>=,<,<= | 大于,大于等于,小于,小于等于 |
| = | 等于,NULL不安全,例如 NULL = NULL 的结果是 NULL,即false |
| <=> | 等于,NULL安全,例如 NULL <=> NULL 的结果是true |
| !=,<> | 不等于 |
| between a0 and a1 | 范围匹配,[a0, a1],如果 a0 <= value <= a1,结果是true |
| in (option, ...) | 离散单位字段范围,如果是option 中的任意一个,返回true |
| is NULL | 是NULL |
| is not null | 不是NULL |
| like | 模糊匹配,%表示 任意多个(包括0个) 任意字符;_ 表示 任意一个字符 |
| 运算符 | 说明 |
| and | 且,多个条件必须都为true,结果才是true |
| or | 或,任意一个条件为true, 结果为true |
| not | 取反,条件为true,结果为false |
2.8分页查询
select col from tb_name limit n offset m
- limit限定 此次操作成功的 记录个数,offset指定 操作记录的 起始下标(默认以0开始)
指定 从m下标开始 限制查询出n个结果地 查询
3.修改记录
update tb_name set col1 = expr,...
将记录的 指定列字段数据 进行修改
4.删除记录
delect from tb_name;
将记录从表中删除
四、通用操作
1.库级
if exists
if exists 操作对象名
2.表级
,...
在一个操作单元后面 加, 继续添数据单元,即可一次完成 多个单位的操作
3.记录级
3.1order by
order by 列 指定 按一定顺序去操作
3.2where
where(条件表达式) 按 记录符合条件 去执行对记录的操作
3.3limit-offset
limit限定 此次操作成功的 记录个数,offset指定 操作记录的 起始下标
4.查询级
4.1as
查询列名 as 别名
4.2distinct
distinct 查询列名,...
5.插入级
全列
插入的表名后面 不加列 默认视为 以全列加