Text2SQL在Spark NLP中的实现与应用:将自然语言问题转换为SQL查询的技术解析
概述

SQL 仍然是当前行业中最受欢迎的技能之一
免责声明:Spark NLP 中的 Text2SQL 注释器在 v3.x(2021 年 3 月)中已被弃用,不再使用。如果您想测试该模块,请使用 Spark NLP for Healthcare 的早期版本。
自新千年伊始,每日产生的数据量呈指数级增长。其中大部分数据存储在关系型数据库中。在过去,只有大型公司能够使用结构化查询语言(SQL)查询这些数据。随着手机的普及,越来越多的个人数据被存储,因此,越来越多来自不同背景的人试图查询和使用自己的数据。尽管数据科学的热度不断攀升,但大多数人仍缺乏编写 SQL 查询数据的必要知识。此外,大多数人也没有时间去学习和理解 SQL。即使是 SQL 专家,反复编写类似的查询也是枯燥乏味的任务。正因如此,如今海量的数据无法被有效获取 [1]。您可以查看 这一系列文章 和 一篇博客文章,以了解更多关于 Text2SQL 及该研究领域的最新趋势 [2]。
我们的目标是让人们能够直接用人类语言与数据对话。因此,这类自然语言接口帮助任何背景的用户轻松查询和分析海量数据。为了构建这种自然语言接口,系统必须理解用户的问题,并自动将其转换为对应的 SQL 查询。
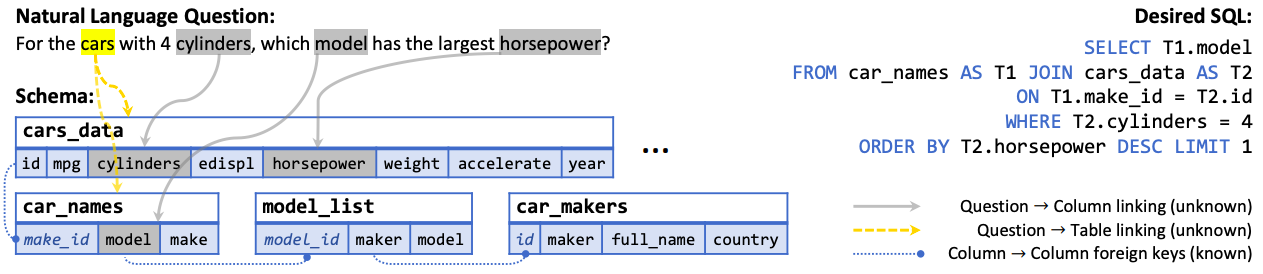
来自 Spider 数据集的一个具有挑战性的 Text-to-SQL 任务
Text2SQL 是自然语言处理研究中的一个重大挑战,目前最先进的模型(SOTA)仍然难以达到人类基线水平的准确率,这是由于问题本身的固有特性。因此,目前最先进的模型在 Spider 数据集 上的准确率仅为 70%,而 Spider 数据集是 Text2SQL 研究中最广泛使用的基准数据集之一。
还有其他几个 Text2SQL 基准数据集,例如 ATIS、GeoQuery、Scholar、Advising 等,以及 WikiSQL,它们覆盖了整个 SQL 查询范围的不同领域。
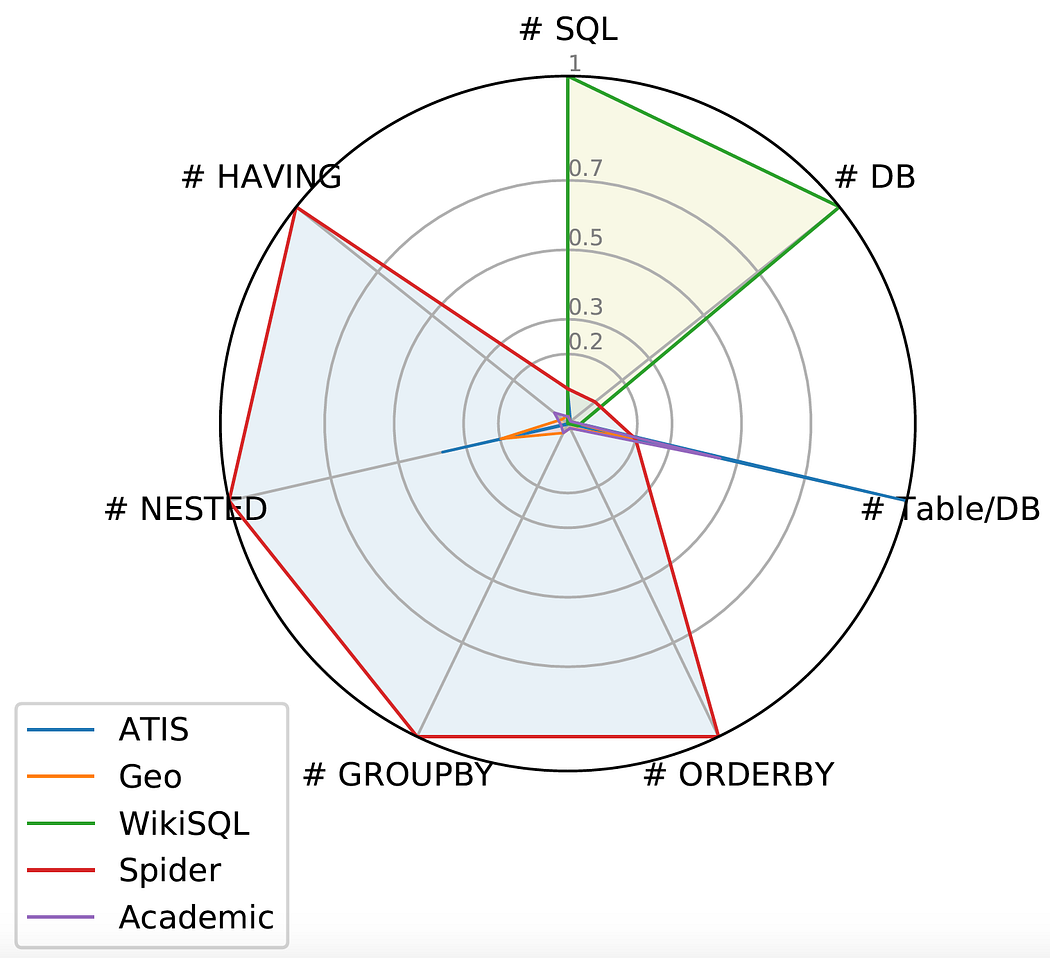
一些 Text-to-SQL 数据集的图表(图片来自 Spider 项目)
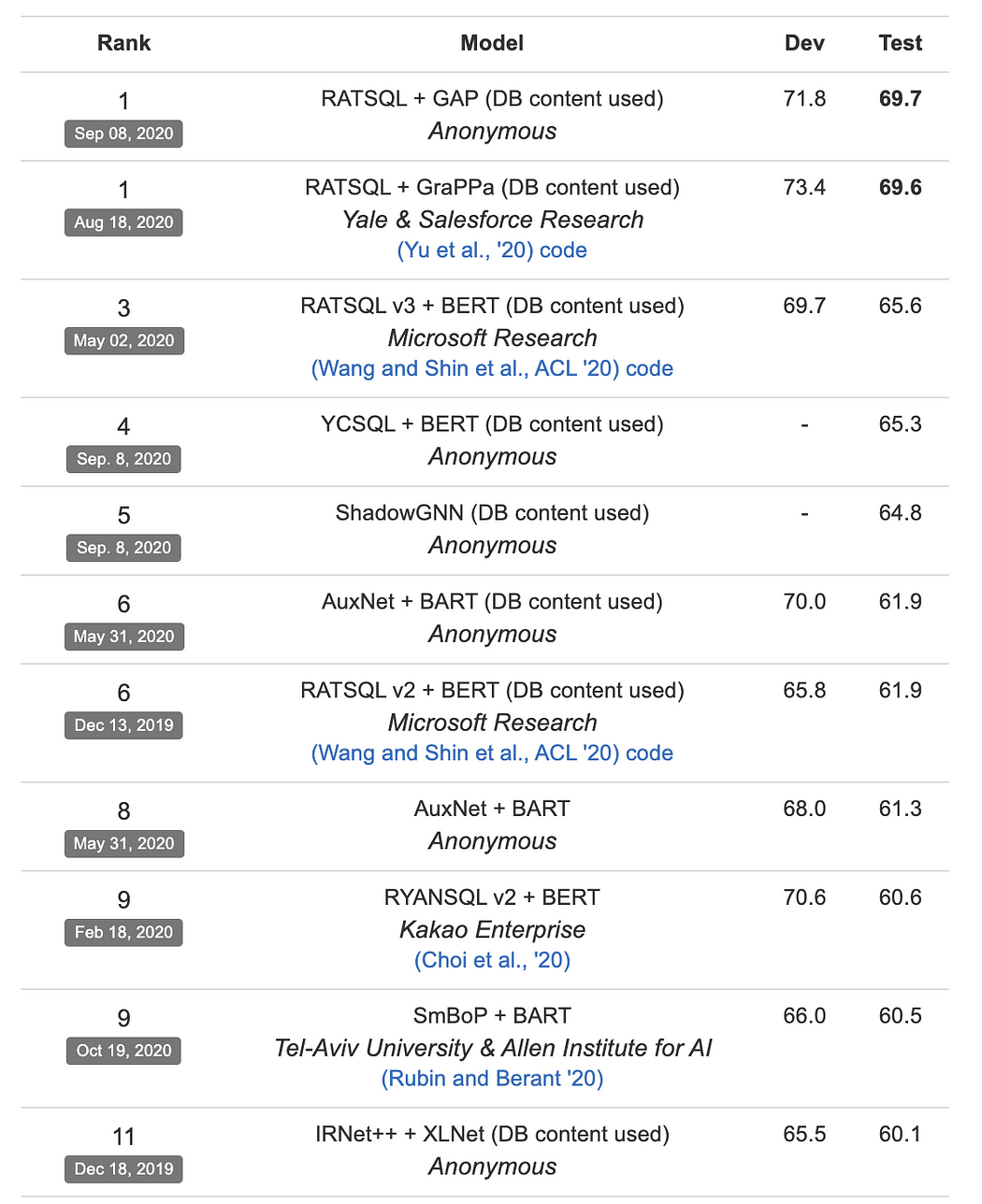
Spider 数据集上的 Text2SQL 任务排行榜
如左图所示,Spider 数据集在图表中占据了最大面积,使其成为第一个复杂且跨领域的 Text-to-SQL 数据集,它具有以下特点:
- 大规模:包含超过 10,000 个问题,以及大约 6,000 个对应的、独特的 SQL 查询。
- 复杂性:大多数 SQL 查询涵盖了几乎所有重要的 SQL 组件,包括 GROUP BY、ORDER BY、HAVING 和嵌套查询。此外,所有数据库都包含多个通过外键关联的表。
- 跨领域:包含 200 个复杂的数据库。我们将 Spider 数据集划分为训练集、开发集和测试集,基于数据库进行划分。这样,我们可以在未见过的数据库上测试系统的性能。
Spark NLP:大规模的自然语言处理
Spark NLP 是基于 Apache Spark ML 构建的自然语言处理库,每天的下载量超过 10,000 次,总下载量达到 180 万。它是增长最快的自然语言处理库之一,支持 Python、R、Scala 和 Java 等流行编程语言。它为机器学习管道提供了简单、高效且准确的自然语言处理注释,这些注释可以在分布式环境中轻松扩展。
Spark NLP 提供了 330 多个预训练的管道和模型,涵盖 46 种以上的语言。它支持最先进的 Transformer 模型,例如 BERT、XLNet、ELMO、ALBERT 和 Universal Sentence Encoder,这些模型可以在集群中无缝使用。此外,它还提供分词、词性标注、命名实体识别、依存句法分析、拼写检查、多类文本分类、多类情感分析等 自然语言处理任务。如需了解更多详细信息和示例 Colab 笔记本,我们强烈建议您查看我们的 工作坊仓库。

Spark NLP for Healthcare 2.7 于 2020 年 10 月 28 日发布
Spark NLP 中实现的 Text2SQL 算法
我们在 Spark NLP 中实现了一种名为 IRNet 的深度学习架构。中间表示(IRNet) 旨在解决复杂且跨领域的 Text-to-SQL 任务中的两个主要挑战:自然语言中表达的意图与预测列之间的不匹配,以及由于大量超出领域词汇导致的问题。让我们看看 IRNet 提供了什么。
- IRNet 将自然语言分解为 3 个阶段,而不是端到端地合成 SQL 查询:模式编码器(Schema Encoder)、解码器(Decoder)和自然语言编码器(NL Encoder)。
- 在第一阶段,对数据库模式和问题进行模式链接。IRNet 采用基于语法的神经模型来合成
SemQL查询,这是一种我们设计的中间表示(IR),用于连接自然语言和 SQL。模式编码器以数据库模式为输入,输出表和列的表示。 - 解码器用于使用上下文无关语法合成
SemQL查询,IRNet 确定性地从合成的 SemQL 查询中推断出 SQL 查询,并利用领域知识。 - 最后,自然语言编码器将自然语言输入编码为嵌入向量。这些嵌入向量随后用于通过双向 LSTM 构建隐藏状态。
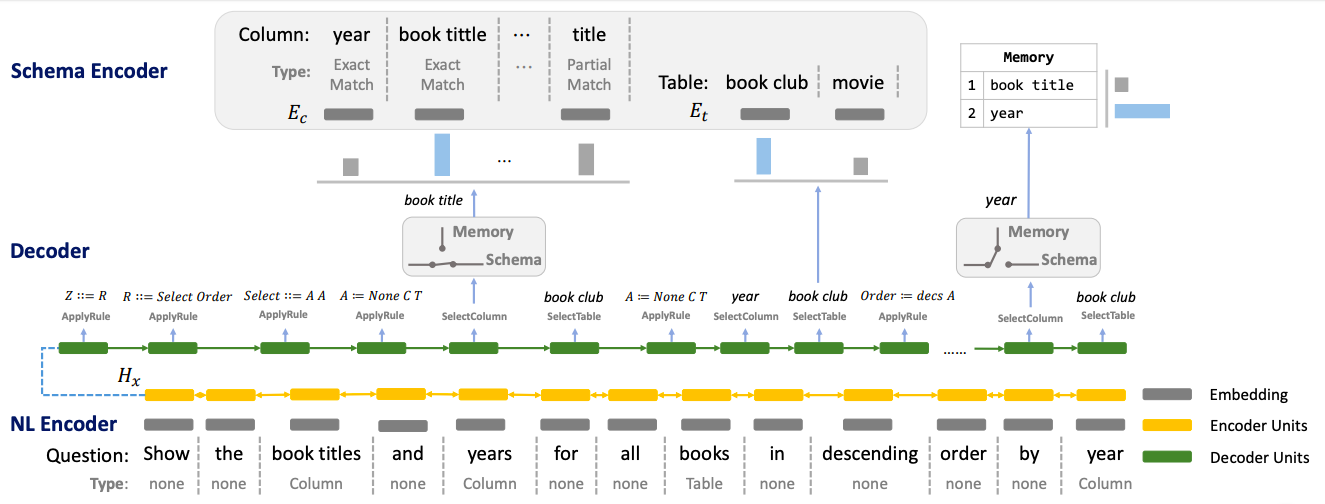
合成 SemQL 查询的神经模型概览。基本上,IRNet 由自然语言编码器、模式编码器和解码器构成。如图所示,从模式中选择了“书名”列,而第二列“年份”是从记忆中选择的。(来源)
Spark NLP 中的实现方式
Text2SQL 是在 Spark NLP for Healthcare 2.7.0 中宣布的一项功能,这是撰写本文时的最新版本。基本上,我们使用 Tensorflow 实现了 IRNet 算法,并在 Spider 基准数据集上进行训练,并将其封装为 Spark NLP 中的 Tex2SQLModel。目前,它仅提供了一个预训练模型,名为 text2sql_glove,因为它是使用 Spark NLP 中的 glove_6B_300 嵌入进行训练的。
正如我们之前解释的,IRNet 需要在实际构建查询之前解析数据库模式(模式编码器)。这是通过我们创建的另一个注释器 Text2SQLSchemaExporter 来完成的。
以下是获取 Spark NLP 中的 Text2SQL 管道的步骤,以便您可以使用口语查询数据库。
- 首先,我们需要从原始数据库模式准备一个 json 文件。假设我们有一个 医院记录的 SqLite,包含以下 15 个表:
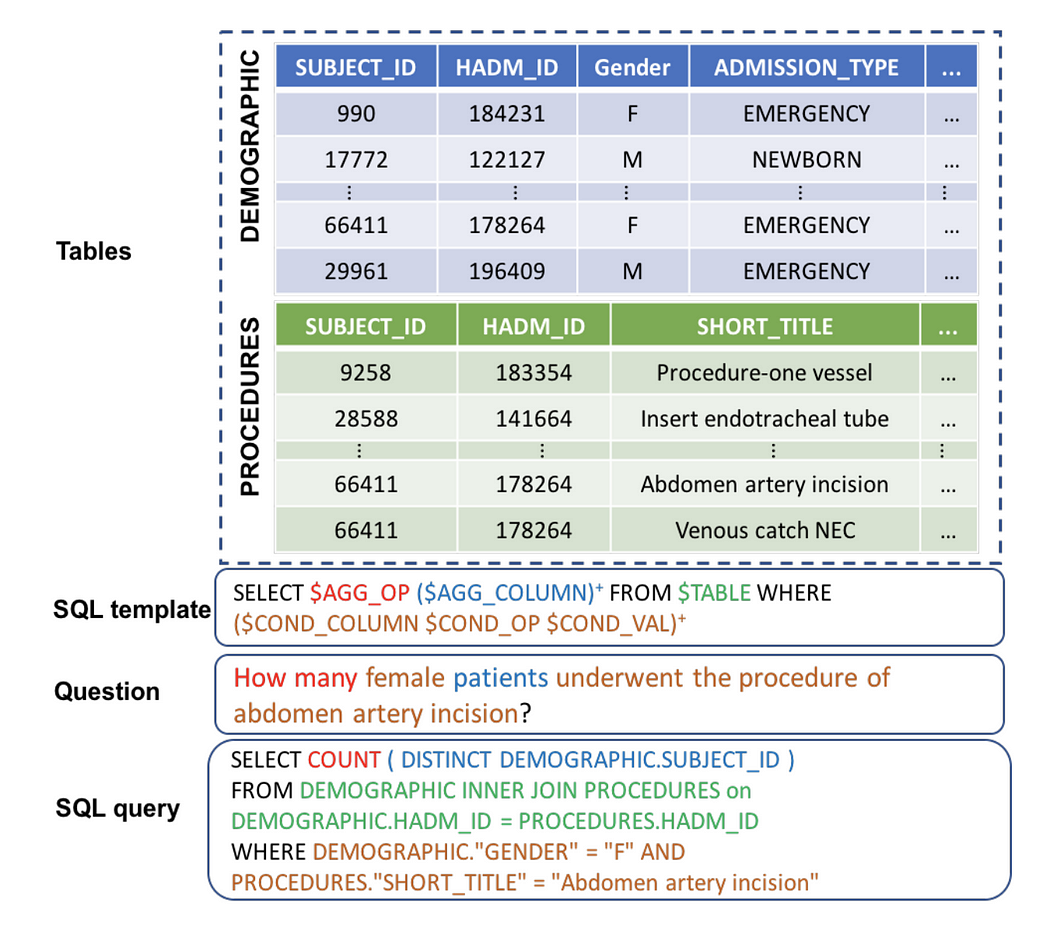
来自医疗记录的 Text2SQL(图片来自 官方论文)
['Physician', 'Department', 'Affiliated_With', 'Procedures', 'Trained_In', 'Patient', 'Nurse', 'Appointment', 'Medication', 'Prescribes', 'Block', 'Room', 'On_Call', 'Stay', 'Undergoes']
然后,我们使用以下代码将该模式转换为我们的模式解析器可以理解的 json 格式。将此处理放在 Text2SQLSchemaExporter 注释器之外的原因是为了能够支持其他数据库模式,而无需更改注释器逻辑。
from sparknlp_jsl._tf_graph_builders.text2sql import util
input_schema = "hospital_records.sqlite"
output_schema = "hospital_schema_converted.json"
util.sqlite2json(input_schema, output_schema)
然后,使用 Text2SQLSchemaExporter,我们使用词嵌入处理这个模式,以创建表和列名的表示。
schema_json_path = 'hospital_schema_converted.json'
output_json_path = "db_embeddings.json"
prepare_db_schema(schema_json_path, output_json_path)
prepare_db_schema 函数来自包含 Text2SQLSchemaExporter 阶段的 Spark NLP 管道。本文末尾将分享整个管道。
下一步是准备一个管道,将文本查询的表示转换为我们的 Text2SQLModel 注释器可以理解的格式。基本上,它将接受用户以纯文本形式提出的问题,并创建算法返回查询所需的所有特征。
sql_prediction_light = get_text2sql_model (schema_json_path, output_json_path)
sql_prediction_light 函数来自包含 Text2SQLModel 阶段的 Spark NLP 管道。本文末尾将分享整个管道。
现在,我们可以开始使用纯文本查询数据库:
question = "Find the id of the appointment with the most recent start date"
annotate_and_print(question)
>> question:
SELECT T1.Appointment FROM Prescribes
AS T1 JOIN Appointment AS T2 ON
T1.Appointment = T2.AppointmentID
ORDER BY T2.Start
DESC LIMIT 1
>> query:
| | Appointment |
|---:|:------------|
| 0 | 086213939 |
另一个例子
question = "What is the name of the nurse who has the most appointments?"
annotate_and_print(question)
>> query:
SELECT T1.Name FROM Nurse AS T1
JOIN Appointment AS T2 ON
T1.EmployeeID = T2.PrepNurse
GROUP BY T2.prepnurse
ORDER BY count(*)
DESC LIMIT 1
>> result:
| | Name |
|---:|:-----------------|
| 0 | Carla Espinosa |
再举一个例子
question = "How many patients do each physician take care of? List their names and number of patients they take care of."
annotate_and_print(question)
>> query:
SELECT T1.Name, count(*)
FROM Physician AS T1
JOIN Patient AS T2 ON
T1.EmployeeID = T2.PCP
GROUP BY T1.Name
>> result:
| | Name | count(*) |
|---:|:-----------------|-----------:|
| 0 | Christopher Turk | 1 |
| 1 | Elliot Reid | 2 |
| 2 | John Dorian | 1 |
正如您所见,它返回了相当不错的结果!实际上,由于它仅在通用数据集(Spider)上进行训练,因此在某些特定领域的数据库(如医疗保健或金融)上可能表现不佳。但这只是找到合适的数据集并重新训练模型的问题。
我们计划在未来几个月内对其他领域数据集训练新的 Text2SQL 模型。下一个将基于 MIMIC 数据集进行训练,它将在医疗记录方面表现更好。
总结
自新千年伊始,每日产生的数据量呈指数级增长。其中大部分数据存储在关系型数据库中。尽管数据科学的热度不断攀升,但大多数人仍缺乏编写 SQL 查询数据的必要知识。
结合查询非结构化文本数据的固有困难,从数据库中查找相关信息的任务需要多学科的技能。Spark NLP for Healthcare 旨在通过解析文本数据以提取有意义的实体(NerDL)、分配断言状态(AssertionDL)和医学术语代码(EntityResolver)、构建实体之间的关系(RelationExtractionDL)、将所有这些内容写入类似 OMOP 的结构化数据库模式,最后使用本文中描述的对话式纯文本查询这些记录,为这一任务提供解决方案。
您可以在 这个 Colab 笔记本 中找到所有代码和更多示例,如果您想在自己的数据上尝试,可以申请 Spark NLP Healthcare 免费试用许可证。
Spark NLP 库在企业项目中得到应用,它原生基于 Apache Spark 和 TensorFlow 构建,并提供全方位最先进的自然语言处理解决方案,为机器学习管道提供简单、高效且准确的自然语言处理注释,这些注释可以在分布式环境中轻松扩展。