计算机组成与体系结构:缓存一致性(Cache Coherence)
目录
🔍 多核处理器
什么是缓存一致性问题?
什么是缓存一致性?
📚 缓存一致性协议常用术语解释
各状态之间的关系
一个比喻帮助你理解
🎯 Cache Coherency Protocols(缓存一致性协议)
为什么称为 协议(protocol) 而不是方案(solution)?
1️⃣ Snooping-Based Protocols(嗅探式协议)
2️⃣ Directory-Based Protocols(目录协议)
简单对比:Snooping vs Directory
缓存一致性(Cache Coherence)问题是多核处理器系统或多处理器系统中非常关键的问题之一。当多个处理器或核心各自拥有对同一内存区域的缓存副本时,为保证程序的正确性,必须解决不同缓存副本之间可能出现的不一致情况。
🔍 多核处理器
在多核处理器中,“核”(Core)代表的是一个独立的处理单元,可以独立执行指令、进行计算,是 CPU 的基本执行单元。每个核相当于一个“小型的 CPU”。
每个核心通常都包含以下关键部件:
| 部件 | 作用 |
|---|---|
| ALU(算术逻辑单元) | 负责加减乘除、逻辑运算 |
| 寄存器 | 用于暂存数据和指令 |
| L1/L2 缓存 | 快速访问最近用过的数据(每个核心通常有独立的 L1) |
| 控制单元(Control Unit) | 解析和执行指令 |
| 指令调度器 | 决定指令执行顺序,提升并发度 |
多核与线程的关系
-
多核处理器可以并行执行多个线程(如一个 4 核处理器可同时运行 4 个线程)
-
每个核心可以是 单线程核心 或 多线程核心(如超线程技术)
-
线程(Thread) 是程序中最小的执行单元,而 核 是能实际运行线程的硬件单元
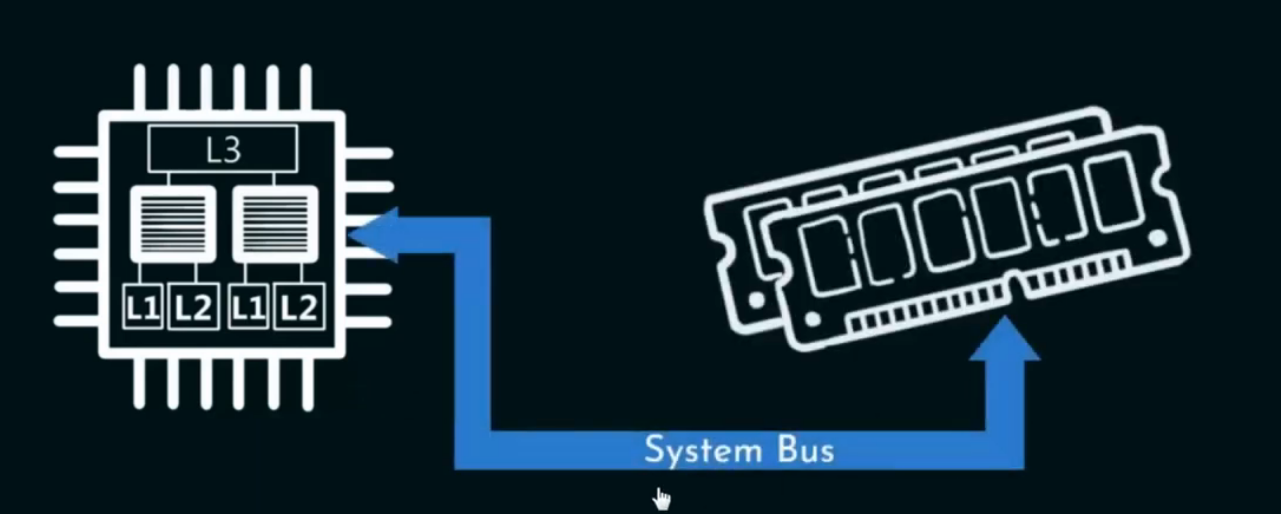
关于CPU核心数量与Cache的关系,可以阅读我之前发表的文章:
计算机组成与体系结构:缓存(Cache)_计算机架构缓存cache技术-CSDN博客
什么是缓存一致性问题?
定义:
当多个处理器/核心的缓存中存有同一内存地址的数据副本时,一个核心对该地址的数据进行了修改,而其他核心仍使用旧副本,导致系统中的数据状态不一致——这就是缓存不一致性问题。
常见的缓存一致性问题场景
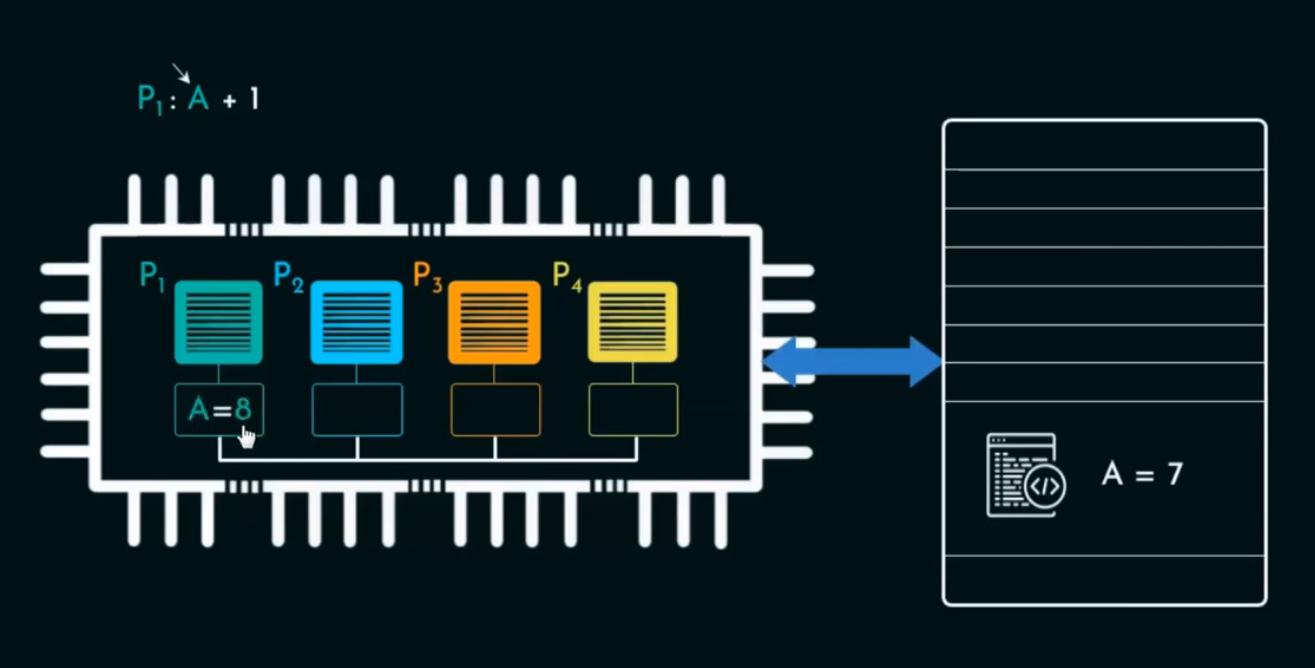
-
系统中有一个共享变量
A,最初保存在主内存中,初始值为A = 7。 -
一个4核处理器系统,包括核心
P₁、P₂、P₃和P₄。 -
开始时,这四个核心的本地缓存中都没有变量 A。
-
每个核心通过系统总线从主内存中读取变量 A 的值(即 7),并缓存在本地缓存中。
接着,每个核心对变量 A 分别执行如下操作:
| 核心 | 初始缓存值 | 操作 | 新缓存值 |
|---|---|---|---|
| P₁ | A = 7 | A = A + 1 | A = 8 |
| P₂ | A = 7 | A = A + 2 | A = 9 |
| P₃ | A = 7 | A = A - 1 | A = 6 |
| P₄ | A = 7 | A = A - 2 | A = 5 |
此时,各核心的本地缓存中变量 A 的值分别变为:
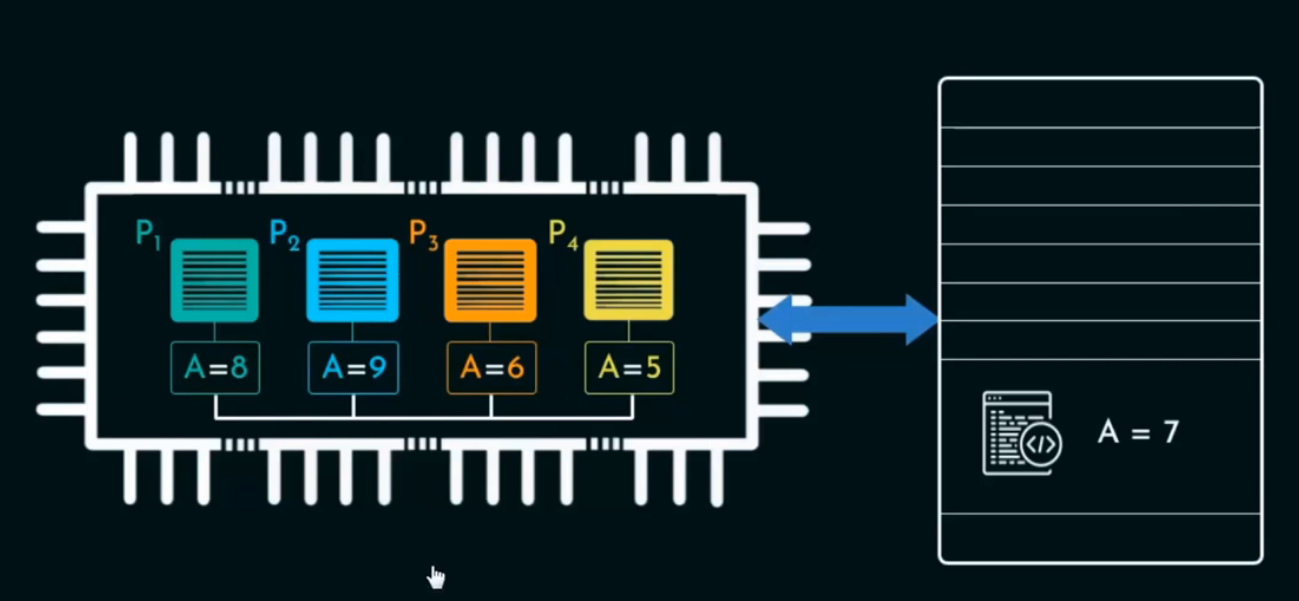
而主内存中的 A 仍然是原始值 7,因为目前还没有任何核心将结果写回主内存。
此时系统中存在5 个不同版本的变量 A,这就是缓存不一致性的典型现象:
多个核心各自基于同一初始值独立进行了修改,但结果彼此冲突,系统无法判断哪一个版本才是“真正的”变量 A 的值。
什么是缓存一致性?
缓存一致性是指:在多核或多处理器系统中,共享数据在多个本地缓存中的副本应该保持一致,也就是多个核心看到的同一变量值应该是相同的。
理想目标:
当一个核心修改了它缓存中的共享变量时:
-
所有其他缓存中该变量的副本也应同步更新,或
-
它们的副本应该被标记为无效(invalid),防止读取过时数据

📚 缓存一致性协议常用术语解释
下面是多核处理器中缓存一致性协议中常见的术语解释,这些术语描述了缓存中某个数据块的状态,目的是协助处理多个核心对同一数据块的读写行为,从而保证缓存一致性。
| 状态 | 英文名称 | 简写 | 含义与作用 |
|---|---|---|---|
| Modified | 修改状态 | M | 当前缓存拥有该数据的唯一有效副本,已被修改,与主内存不一致,需要在换出或被其他核心请求时写回内存。其他缓存中不能有这个数据块。 |
| Exclusive | 独享状态 | E | 当前缓存拥有该数据的唯一副本,但尚未被修改,与主内存一致。可以直接读或写,写时变为 Modified 状态。 |
| Shared | 共享状态 | S | 数据块在多个缓存中存在,内容未被修改,与主内存一致。只允许读取,不能写。写会触发状态转换。 |
| Invalid | 无效状态 | I | 当前缓存中的该数据块是无效的,不能使用,必须重新从其他缓存或主内存中加载。 |
| Owned | 拥有者状态 | O | 类似于 Shared,但该缓存是数据的“拥有者”,数据可能与主存不一致,必须在必要时负责把数据写回主存;其他缓存可以共享它的数据副本(MOESI 协议中新增)。 |
| Forward | 转发者状态 | F | MESIF 协议中用于优化“共享状态”的性能。多个缓存处于 Shared 状态时,选一个拥有 Forward 状态的缓存负责回应其他核心的数据请求,减少主存访问。 |
各状态之间的关系
可以这样理解:
| 情况 | 描述 |
|---|---|
Modified vs Exclusive | 都是当前核心唯一持有数据副本,区别是是否已被修改 |
Shared vs Exclusive | Shared 表示多个副本存在,Exclusive 表示只有我有这个副本 |
Owned vs Shared | Owned 是带“责任”的共享者,可能数据已改,与主存不同,但允许其他人读取 |
Forward vs Shared | Forward 是“共享中的代表”,负责代替主存回应数据请求 |
一个比喻帮助你理解
把缓存块比作一份文件副本,主存是文件的原版:
-
Modified: 我改了文件,其他人没有;还没告诉主存(原版),我得写回去。 -
Exclusive: 我有这个文件的唯一副本,但还没改过。 -
Shared: 大家都有这份文件,都只读。 -
Invalid: 我的文件作废了,不能用了。 -
Owned: 虽然大家都有副本,我是“责任人”,我的版本是最新的,我负责同步。 -
Forward: 我是共享组里被选中的“代表”,别人要查这份文件,我负责答复。
🎯 Cache Coherency Protocols(缓存一致性协议)
为什么称为 协议(protocol) 而不是方案(solution)?
| 协议(Protocol) | 方案(Solution) |
|---|---|
| 是一组系统级的行为规则 | 是一种通用的设计方式或方法 |
| 定义了缓存之间如何协同通信、响应请求、维护状态 | 可以是软件级别、硬件架构或编程策略 |
| 精确规定了状态变更、通信顺序、响应策略 | 可能不涉及底层状态控制 |
因此,缓存一致性协议是硬件层面定义的通信“语言”和“规则”,核心之间必须遵守这个协议来维护一致的缓存视图,就像网络通信需要 TCP/IP 协议一样。
缓存一致性协议主要分为两大类:
1️⃣ Snooping-Based Protocols(嗅探式协议)
又称 Bus-Based Protocols(总线广播协议)
工作原理:
-
所有核心共享一条系统总线
-
每个核心在总线上“监听”(snoop)其他核心的读写请求
-
当检测到某个核心对某数据块进行了操作(特别是写操作),其他核心会更新或失效自己缓存中的副本
协议示例:
-
MSI(Modified, Shared, Invalid)
-
MESI(新增 Exclusive)
-
MOESI(新增 Owned)
-
MESIF(新增 Forward)
优点:
-
实现简单
-
响应快,广播机制天然适用于少量核心
缺点:
-
可扩展性差:所有核心共享总线,总线带宽成为瓶颈
-
能耗高:所有缓存必须监听总线,负担重
-
不适合大规模多核系统
2️⃣ Directory-Based Protocols(目录协议)
工作原理:
-
引入一个中央或分布式的目录(Directory),用于记录每个数据块在各个缓存中的状态
-
每次缓存访问共享变量时,需要查阅目录来决定:
-
哪些缓存中有该变量副本
-
是否需要失效其他副本
-
是否需要转发最新值
-
状态维护示例:
-
目录记录:
Address A:
- Shared by: Core 1, Core 2
- Modified by: None
优点:
-
可扩展性强,适合几十上百核系统
-
避免了总线广播的能耗浪费
-
更高的精确性(只更新相关缓存,不全体广播)
缺点:
-
增加了目录结构开销(尤其是大地址空间)
-
增加了缓存访问延迟(需要查询目录)
简单对比:Snooping vs Directory

| 特征 | Snooping(总线嗅探) | Directory(目录协议) |
|---|---|---|
| 核心间通信 | 广播(Bus) | 点对点 + 目录查找 |
| 适用规模 | 小规模(4–8 核) | 中到大规模(16 核以上) |
| 维护开销 | 所有缓存监听总线 | 需要维护目录信息 |
| 数据更新响应 | 快(广播) | 慢一点(需查询目录) |
| 系统功耗 | 较高 | 较低 |
| 实现复杂度 | 较低 | 较高 |