【深度学习】残差网络(ResNet)
如果按照李沐老师书上来,学完 VGG 后还有 NiN 和 GoogLeNet 要学,但是这两个我之前听都没听过,而且我看到我导师有发过 ResNet 相关的论文,就想跳过它们直接看后面的内容。
现在看来这不算是不踏实,因为李沐老师说如果卷积神经网络只学一个架构的话,那就学这个 ResNet(Residual Network)。
随着我们设计越来越深的网络,深刻理解“新添加的层如何提升神经网络的性能”变得至关重要。
加了更多层一定更有用吗?如果不是的话,怎么样加入新层可以有效提高精度呢?
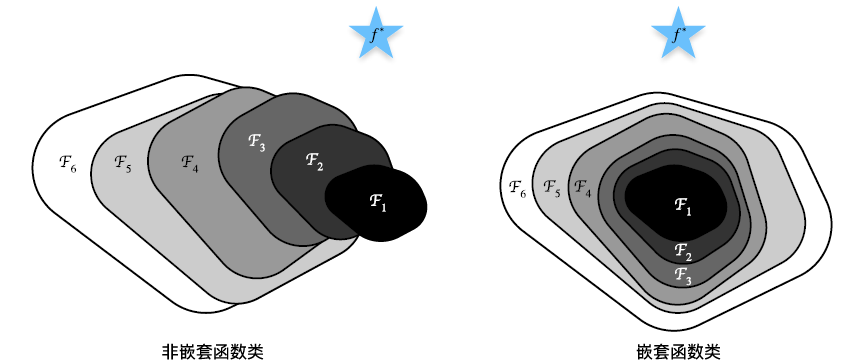
我们通过下图来进行理解。以前我们在网络加入新的卷积层或者全连接层有点像左图中的非嵌套函数类。
尽管随着层数变多(函数 f 1 − f 6 f_1-f_6 f1−f6),能覆盖的最优值范围变大,但不一定能很有效的接近全局最优(蓝色五角星)。
例如左图中实际上加到 f 3 f_3 f3 时的最优值距离五角星更近。
针对这一问题,何恺明等人(2016)提出了残差网络,其核心思想是:每个附加层都应该更容易地包含原始函数作为其元素之一。
就像右图中的嵌套函数类,每次新加入函数都能保证不会离五角星更远,进而一步一步逼近全局最优。
下面我们看看如何实现“嵌套”。
一、残差块
块的思想我们在 VGG 中就了解过,可以帮助我们设计深层网络。
以前我们是通过串联起各层来扩大函数类(下左图),而残差块(下右图)通过加入一侧的快速通道,来得到 f ( x ) = x + g ( x ) f(x)=x+g(x) f(x)=x+g(x) 的结构。
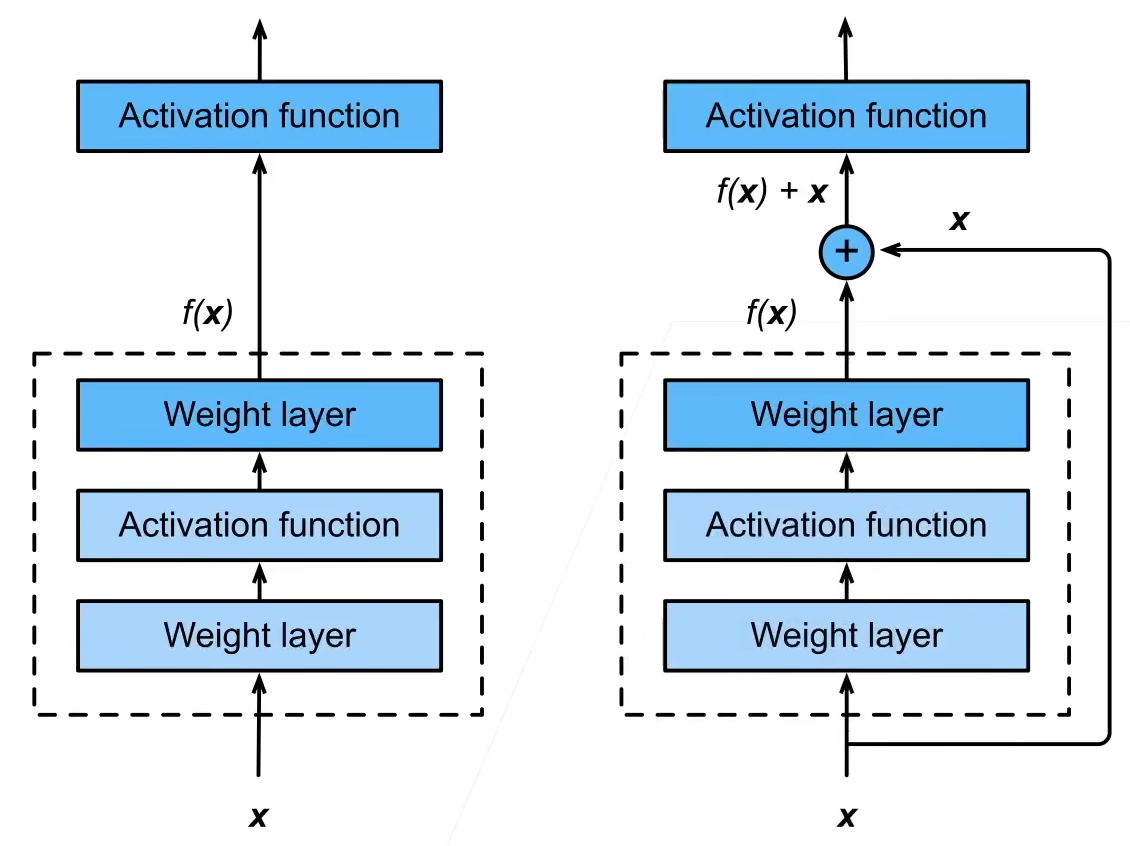
如此的话,就算虚线框中的 g ( x ) g(x) g(x) 没有起到效果,我们也不会退步。
如果虚线框中的各层使得通道数改变,我们就需要加入 1$\times$1 卷积层来进行调整,以保证能加法顺利进行。
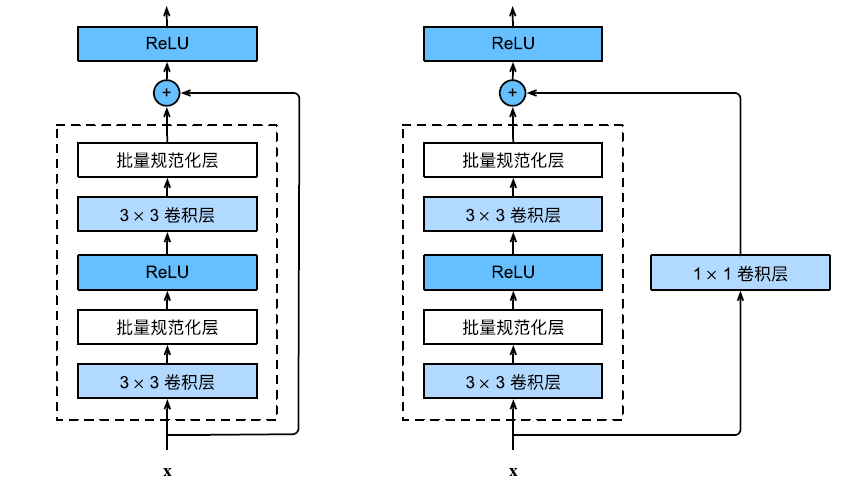
对于上图这类特殊的架构,我们需要采用自定义层的方式来实现。
class Residual(nn.Module): # 定义残差块def __init__(self, input_channels, num_channels,use_1x1conv=False, strides=1):super().__init__()self.conv1 = nn.Conv2d(input_channels, num_channels,kernel_size=3, padding=1, stride=strides)self.conv2 = nn.Conv2d(num_channels, num_channels,kernel_size=3, padding=1)if use_1x1conv:self.conv3 = nn.Conv2d(input_channels, num_channels,kernel_size=1, stride=strides)else:self.conv3 = Noneself.bn1 = nn.BatchNorm2d(num_channels)self.bn2 = nn.BatchNorm2d(num_channels)def forward(self, X):Y = F.relu(self.bn1(self.conv1(X)))Y = self.bn2(self.conv2(Y))if self.conv3:X = self.conv3(X)Y += Xreturn F.relu(Y)
ResNet 沿用了 VGG 完整的 3$\times$3 卷积层设计。残差块里首先有两个相同输出通道数的卷积层,每个卷积层后面接一个批量规范化层和激活函数。
上述代码通过调整参数use_1x1conv参数的取值,来决定是否添加 1$\times$1 卷积层。
一般我们在增加通道数时,我们会通过调整strides来使得高宽减半。
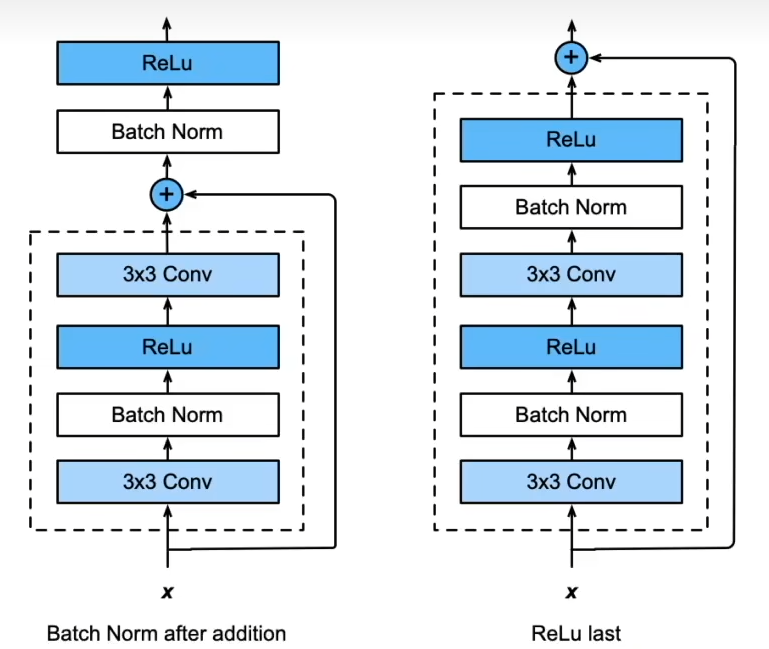
实际上,我们还可以改变块中组件的位置,可得到各种残差块的变体。
二、ResNet 模型
ResNet 的第一层为输出通道数 64、步幅 2 的 7$\times 7 卷积层,随后接 B N 层和步幅为 2 的 3 7 卷积层,随后接 BN 层和步幅为 2 的 3 7卷积层,随后接BN层和步幅为2的3\times$3 的最大汇聚层。
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),nn.BatchNorm2d(64), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
之后使用 4 个由残差块组成的模块,每个模块由若干个同样输出通道数的残差块组成。
第一个模块的通道数同输入通道数一致。由于之前已经使用了步幅为 2 的最大汇聚层,因此无需减小高和宽。
之后的每个模块在第一个残差块里将上一个模块的通道数翻倍,并将高和宽减半。
def resnet_block(input_channels, num_channels, num_residuals,first_block=False): # 生成由残差块组成的模块blk = []for i in range(num_residuals):# 除了第一个模块,其他模块的第一个残差块需要宽高减半if i == 0 and not first_block:blk.append(Residual(input_channels, num_channels,use_1x1conv=True, strides=2))else:blk.append(Residual(num_channels, num_channels))return blk
我们这里每个模块使用 2 个残差块,其中其第一个模块使用first_block参数来避免宽高减半。
# b2 不需要通道数翻倍,宽高减半b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))b3 = nn.Sequential(*resnet_block(64, 128, 2))b4 = nn.Sequential(*resnet_block(128, 256, 2))b5 = nn.Sequential(*resnet_block(256, 512, 2))
最后,加入自适应平均汇聚层、展平层和全连接输出层。AdaptiveAvgPool2d的使用可以保证最后的输出为 (1, 1),不用去管池化窗口的大小。
net = nn.Sequential(b1, b2, b3, b4, b5,nn.AdaptiveAvgPool2d((1, 1)),nn.Flatten(), nn.Linear(512, 10))
4 个模块,每个模块两个残差块,一个残差块 2 个卷积层,加上最初的 7$\times$7 卷积层和最后的全连接层,共 18 层,故上述模型通常称为 ResNet-18。
在训练模型之前,我们来观察一下各个模块的输入形状是如何变化的。
# 查看各模块输出形状X = torch.rand(size=(1, 1, 224, 224))for layer in net:X = layer(X)print(layer.__class__.__name__, 'output shape:\t', X.shape)
---------------------------------
Sequential output shape: torch.Size([1, 64, 56, 56])
Sequential output shape: torch.Size([1, 64, 56, 56])
Sequential output shape: torch.Size([1, 128, 28, 28])
Sequential output shape: torch.Size([1, 256, 14, 14])
Sequential output shape: torch.Size([1, 512, 7, 7])
AdaptiveAvgPool2d output shape: torch.Size([1, 512, 1, 1])
Flatten output shape: torch.Size([1, 512])
Linear output shape: torch.Size([1, 10])
第一个模块出来后是 56$\times$56,我开始算不到,因为光算卷积就已经是小数了,没往下算。后面上网查了下,发现是向下取整的,才明白。
这里放上尺寸的计算公式吧,参考这个:https://www.jianshu.com/p/612edc845ad5
卷积后,池化后尺寸计算公式:
(图像尺寸-卷积核尺寸 + 2*填充值)/步长 +1
(图像尺寸-池化窗尺寸 + 2*填充值)/步长 +1
后面 3 个模块都是通道数加倍,宽高减半,减为 7 × \times × 7 后,最后通过汇聚层变为 1 × \times × 1,聚集所有特征。
三、训练模型
同之前一样,我们在 Fashion-MNIST 数据集上训练 ResNet。
因为之前定义好了很多训练相关函数,所以训练代码可以非常轻松的写下来。
我都有点想写一个自己的工具包了,这样就不用每次都复制前面的代码,而是像李沐老师的 d2l 一样。
lr, num_epochs, batch_size = 0.05, 10, 128 # ResNet使用的参数train_iter, test_iter = load_data_fashion_mnist(batch_size, resize=224)train(net, train_iter, test_iter, num_epochs, lr, try_gpu())
原本书上的batch_size是 256 的,但是我的 GPU 内存不够,报错,调成了 128。
这次训练是最久的,早知道resize成更小的尺寸了。我看到沐神说他改成 96 只是为了更快运行,就没用 96,想同样用 224,好和前面的模型对比。
训练结果如下:
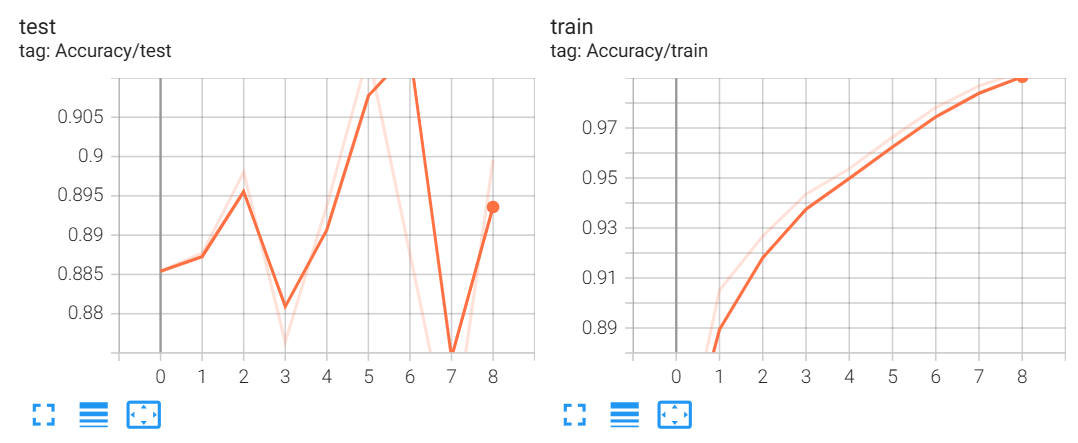
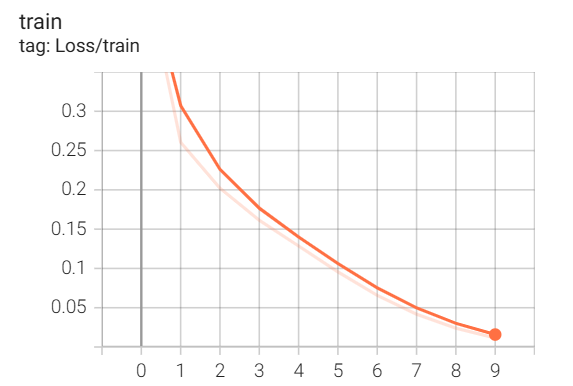
第 10 轮的训练损失为 0.011
第 10 轮的训练精度为 0.998
第 10 轮的测试集精度为 0.926
运行在 cuda:0 上,处理速度为 228.1 样本/秒
这次的处理速度只是 VGG 的一半,但是效果是很不错的,训练损失仅有 0.011,训练精度都接近 100%了都,而且测试集精度也不低。
可以看出 ResNet 确实是非常有效的网络,它对后面的深层网络也产生了非常深远的影响。