大模型解析:AI技术的现状、原理与应用前景
在人工智能快速发展的今天,大模型技术正以前所未有的速度重塑我们的工作与生活方式。本文深入剖析了从GPT-4到Claude等大模型的核心原理、技术底座和应用领域,为读者构建了一个系统化的认知框架。
文章不仅讲解了Transformer架构和自注意力机制等技术基础,还全面展示了大模型在自然语言处理、计算机视觉、科学计算等领域的应用现状。对于"幻觉"等关键技术挑战,文章提供了RAG和Function Calling等实用解决方案,帮助读者理解如何提升模型的知识准确性和工具使用能力。
你是否好奇为什么大模型能够生成如此流畅的文本,却在简单数学计算上犯错?大模型的知识更新机制又将如何演变?通过本文,你将获得对AI技术本质的深刻理解,以及在这个技术浪潮中保持竞争力的实践指南。
一、认识大模型:超越对话的技术革命
1.1 什么是大模型
大模型(Large Models)是指那些基于深度学习架构的大规模人工智能系统,它们通过海量参数和数据训练,能够理解、生成和处理复杂信息。以GPT-4、LLaMA 3、Claude等为代表的大语言模型(LLMs)是当前最广为人知的大模型类型。
核心特征: 参数量是大模型最直观的量化指标。传统深度学习模型通常拥有数百万到数千万参数,而现代大模型则达到了数十亿(7B指70亿参数)、数千亿,甚至万亿级别,如GPT-4的参数量已突破万亿级。
1.2 大模型的技术底座
大模型的技术核心基于深度学习和神经网络,特别是Transformer架构,这一架构在2017年由Google团队提出后,彻底改变了AI领域的发展轨迹。
Transformer架构通过两个关键机制实现了突破性能力:
- 自注意力机制(Self-Attention):允许模型同时处理输入序列中的所有元素,捕捉它们之间的复杂关系。
- 多头注意力机制(Multi-Head Attention):从不同角度学习信息的表示,丰富模型的理解能力。
与传统的RNN(循环神经网络)和CNN(卷积神经网络)相比,Transformer架构具备:
- 更强的并行计算能力,训练效率更高
- 更长的上下文理解能力,可处理更长的输入序列
- 更好的长距离依赖建模能力,捕捉远距离语义关联
二、大模型的应用全景:远超文本对话的广阔天地
大模型不仅仅是聊天机器人,其应用范围正在迅速扩展到几乎所有领域。以下是当前主要应用领域及其代表性技术:
| 应用领域 | 代表应用 | 典型模型 | 实际影响 |
|---|---|---|---|
| 自然语言处理 | 智能对话、翻译、代码生成 | GPT-4、LLaMA 3、Claude | 改变人机交互方式,提升国际交流效率 |
| 计算机视觉 | 图像生成、视频创作、目标检测 | Stable Diffusion、DALL-E、ViT | 革新创意产业,降低创作门槛 |
| 语音技术 | 语音识别、语音合成、语音克隆 | Whisper、VALL-E、Tacotron | 优化人机语音交互,支持无障碍技术 |
| 自动驾驶与机器人 | 自动驾驶系统、机器人导航 | Tesla FSD、Gato、Perceiver | 提升交通安全,解放人力资源 |
| 科学计算与医疗 | 药物研发、蛋白质结构预测、医学影像分析 | AlphaFold、Med-PaLM 2 | 加速科学突破,提高医疗诊断准确率 |
| 推荐系统与广告 | 个性化推荐、精准营销 | DeepFM、DINO、YouTube AI | 优化信息分发效率,提升用户体验 |
2.1 大模型的能力全景
擅长领域
-
文本处理与生成
- 文本理解:能够阅读、总结和分析复杂文章
- 高质量内容创作:从小说、新闻到专业报告、法律合同
- 多语言翻译:支持上百种语言之间的高质量翻译
- 信息提取:从非结构化文本中提取结构化信息
-
代码与编程辅助
- 代码生成:能根据自然语言描述自动编写多种编程语言的代码
- 代码调试与解释:帮助开发者找出Bug并解释复杂代码逻辑
- 编程学习辅助:为编程学习者提供个性化指导
-
多模态能力
- 图像生成与编辑:根据文本描述创建或修改图像
- 语音识别与合成:将语音转换为文本,或将文本转换为自然语音
- 视频生成:根据文本提示创建视频内容
-
知识与问答
- 广泛领域知识:涵盖历史、科学、艺术等多个知识领域
- 专业领域咨询:在法律、医学、金融等专业领域提供初步指导
局限性与挑战
-
精确计算与推理
- 难以进行精确数值计算(如比较3.9和3.11的大小)
- 在涉及复杂逻辑链的推理中容易出错
-
事实准确性
- "幻觉"问题:可能生成看似合理但实际不存在的信息
- 对专业领域知识(医学、法律等)的准确性有限
-
知识时效性
- 知识截止日期限制,无法获取最新信息
- 对冷门、长尾知识的覆盖有限
-
学习能力
- 部署后不会像人类一样持续学习新知识
- 需要通过模型更新或外部知识增强来获取新信息
三、大模型的技术挑战与解决方案
3.1 幻觉问题:AI的"创造性错误"
"幻觉"是大模型面临的最严峻挑战之一,指模型生成看似合理但实际上不准确或完全虚构的信息。
幻觉产生的根本原因
-
语言模型的基本机制
- Transformer本质上是基于概率预测的"下一个词"生成器,而非严格的事实验证系统
- 模型依靠统计规律而非因果推理做出预测
-
训练数据质量问题
- 训练数据中存在的错误信息、不准确说法会被模型学习
- 数据中的偏见、片面表述可能被模型强化
-
知识更新滞后
- 模型训练后知识就"冻结",如GPT-4的知识截止到2023年初
- 无法获取训练后发生的最新事件和信息
-
上下文窗口限制
- 即使是最先进的模型也有上下文窗口限制(如GPT-4-turbo约128k tokens)
- 处理长文本时可能"遗忘"前面提到的关键信息
解决幻觉的实用策略
-
检索增强生成(RAG)
- 模型回答前先从可信数据源检索相关信息
- 基于检索到的事实内容生成回答,而非仅依赖参数中存储的知识
-
领域专业微调(Fine-tuning)
- 在通用模型基础上,使用特定领域高质量数据进行微调
- 提升模型在专业领域的准确性和可靠性
-
提示工程与输出限制
- 设计更严格的提示词,明确指示模型在不确定时承认不知道
- 要求模型先展示推理过程,再给出结论
-
人类反馈与持续优化
- 通过用户反馈识别和纠正错误信息
- 构建反馈循环持续改进模型表现
-
技术创新方案
- 自我验证:让模型自检答案并标记不确定部分
- 多模型协作:多个模型互相验证回答的准确性
- 外部工具集成:允许模型通过API调用获取实时信息
3.2 RAG技术:提升大模型知识准确性的关键方法
检索增强生成(Retrieval-Augmented Generation,RAG)是解决大模型知识时效性和专业领域准确性的重要技术路径。
RAG的技术本质
RAG将"检索"和"生成"两个核心能力结合,让大语言模型在回答问题前先查阅最新、最相关的信息,而不仅仅依赖模型参数中存储的知识。
为什么需要RAG
-
克服知识时效性限制
- 大模型的知识在训练后就固定,如GPT-4只了解到2023年的信息
- RAG允许模型访问最新数据,保持知识时效性
-
增强专业领域知识
- 大模型对通用知识覆盖广,但在专业领域深度不足
- RAG可集成特定领域专业资料,增强垂直领域能力
-
企业专有知识整合
- 大模型无法获取企业内部信息和知识
- RAG可将企业文档、产品手册等私有知识转化为模型可用信息
RAG系统构建流程
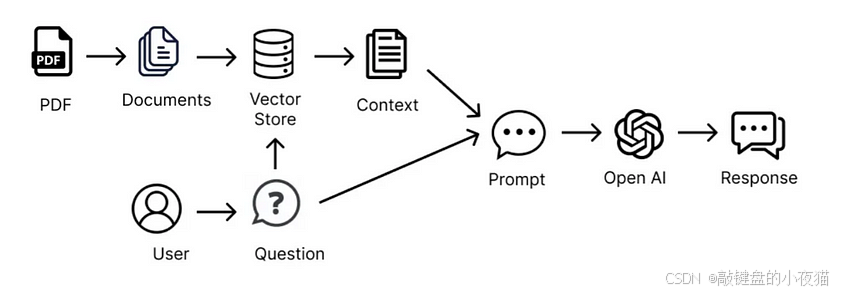
-
知识库准备阶段
- 数据收集:整合企业文档、专业资料、产品手册等信息源
- 数据处理:清洗、分割文档为适当长度的片段
- 向量化:使用embedding模型将文本片段转为向量表示
- 向量索引:将向量存储在高效向量数据库(如FAISS、Milvus)中
-
检索查询阶段
- 将用户问题转换为向量表示
- 在向量数据库中搜索语义相似的文档片段
- 选取最相关的几条信息(如Top 5)作为上下文
-
增强生成阶段
- 将用户问题与检索到的相关文档一起作为提示发送给大模型
- 大模型基于检索内容生成答案,提高回答的准确性和可靠性
- 可选增加引用标注,提高透明度
RAG的实际效果与优势
- 准确性提升:相比纯生成模式,RAG显著降低"幻觉"率,提高事实准确性
- 知识扩展:使模型能够获取训练数据之外的知识
- 可控性增强:可以精确控制模型获取的信息来源
- 成本效益:避免频繁重训练模型,仅需更新知识库即可获取新知识
3.3 Function Calling:赋予大模型工具使用能力
Function Calling(函数调用)是一种革命性技术,使大模型从单纯的对话系统进化为能够使用工具、调用API、控制系统的智能助手。
技术原理与意义
Function Calling允许大模型识别何时需要调用外部工具或服务,并以结构化方式提供必要参数,从而大幅扩展模型的能力边界。
与单纯依赖参数内部知识的模型相比,能够使用工具的模型可以:
- 获取实时信息(如天气、股票价格)
- 执行精确计算
- 检索专业知识库
- 控制外部系统(如智能家居设备)
- 调用专业API服务(如翻译、代码执行)
Function Calling实现机制
Function Calling技术最早由OpenAI在GPT模型中引入,现已成为主流大模型的标准功能。实现步骤包括:
- 工具定义:以结构化方式(通常是JSON格式)定义可用工具的名称、功能、参数规范等信息
# 工具定义示例
TOOLS = [{"type": "function","function": {"name": "get_current_temperature","description": "获取指定位置的当前温度","parameters": {"type": "object","properties": {"location": {"type": "string","description": "需要查询温度的位置,格式为'城市,州/省,国家'"},"unit": {"type": "string","enum": ["celsius", "fahrenheit"],"description": "温度单位,默认为摄氏度"}},"required": ["location"]}}}
]
-
工具选择:模型根据用户问题,判断是否需要调用工具,并选择合适的工具
-
参数生成:模型生成符合工具要求的结构化参数
-
函数执行:系统调用实际函数,获取结果
-
结果整合:将函数执行结果返回给模型,由模型生成最终回答
典型应用场景
-
实时数据访问
- 天气查询、股票行情、体育比赛结果等实时信息获取
- 网络搜索,获取模型知识库之外的信息
-
精确计算和专业处理
- 数学计算、单位换算、日期计算
- 数据分析、统计处理
-
系统控制与自动化
- 控制智能家居设备
- 自动化工作流程
- 调度系统任务
-
多系统集成
- 连接CRM、ERP等企业系统
- 访问数据库并生成分析报告
- 操作文件系统、发送邮件等
四、AI技术实践与发展前沿
4.1 AI工具生态体系
当前AI工具生态已经超越单纯的文本对话,形成了多层次应用体系:
基础对话类AI
- 国产平台:文心一言(百度)、通义千问(阿里)、DeepSeek(智谱)等
- 国际平台:ChatGPT(OpenAI)、Claude(Anthropic)、Gemini(Google)等
编程与开发辅助
- 代码生成:GitHub Copilot、通义灵码、CodeLlama
- 集成开发环境:Cursor、JetBrains AI Assistant、VSCode + Copilot
多模态创意工具
- 图像生成:DALL-E、Midjourney、Stable Diffusion
- 视频创作:Runway、Sora(OpenAI)、Pika
- 音频生成:Whisper(转录)、VALL-E(声音克隆)、Musicgen(音乐创作)
专业模型部署与定制
- 开源模型部署:Ollama、llama.cpp、LM Studio
- 模型微调与训练:HuggingFace、LangChain、LlamaIndex
4.2 AI技能进阶路径
AI技术使用能力可分为以下几个层次:
入门级:基础AI对话应用使用者
- 使用文心一言、通义千问等国产对话AI工具
- 掌握基本提示词编写方法
- 能够用AI辅助日常工作和学习
进阶级:全球AI生态探索者
- 熟练使用各类国际AI平台如GPT-4、Claude等
- 了解不同模型的优缺点和适用场景
- 掌握付费订阅模型的高级功能
专业级:多模态AI应用专家
- 熟练使用图像、视频、音频等多模态AI工具
- 掌握高级提示工程(Prompt Engineering)技巧
- 使用Cursor等专业AI编程工具提升开发效率
专家级:AI系统构建与优化者
- 自主部署开源大语言模型
- 进行模型微调和定制训练
- 构建RAG系统和工具集成解决方案
五、未来展望与思考
大模型技术正处于快速发展阶段,未来发展可能呈现以下趋势:
5.1 技术发展方向
-
多模态融合深化
- 文本、图像、视频、音频等多模态无缝协作
- 从单一模态理解到跨模态推理和创作
-
知识更新机制革新
- 实现连续学习,动态获取最新知识
- 长期记忆与持续学习能力提升
-
推理能力突破
- 复杂逻辑推理和科学问题解决能力提升
- 更接近人类思考的因果推理机制
5.2 社会影响与挑战
-
劳动力市场变革
- 自动化对各行业岗位的重塑
- 新型人机协作模式的兴起
-
伦理与监管问题
- 数据隐私与安全监管框架建设
- 防止误导性信息和深度伪造传播
- 确保AI发展的包容性和公平性
-
可持续发展挑战
- 降低大模型训练和部署的能源消耗
- 研发更高效的模型架构和训练方法
5.3 实践建议
-
保持技术学习与探索
- 持续关注AI领域最新发展
- 尝试不同类型的AI工具和应用场景
-
批判性思维与验证习惯
- 对AI生成内容保持健康怀疑
- 养成交叉验证重要信息的习惯
-
人机协作而非替代
- 发挥AI工具的辅助作用,提升工作效率
- 专注发展AI难以替代的创造力和情感智能
六、结语
大模型技术以其超出预期的能力正在重塑我们工作、学习和创造的方式。通过深入理解大模型的工作原理、能力边界和应用方向,我们可以更明智地驾驭这一技术浪潮,让AI成为人类智能的有力延伸,而非简单替代。
随着技术的持续进步和应用场景的不断拓展,大模型将继续深刻影响社会各个领域。面对这一技术变革,保持学习精神、批判思维和创新意识,将是每个人在AI时代保持竞争力的关键。