【每天一个知识点】湖仓一体(Data Lakehouse)
“湖仓一体”(Data Lakehouse)是一种融合了数据湖(Data Lake)与数据仓库(Data Warehouse)优势的新型数据架构。它既继承了数据湖对多类型数据的灵活存储能力,也具备数据仓库对结构化数据的高效查询与治理能力,成为当前大数据架构演进的重要方向。
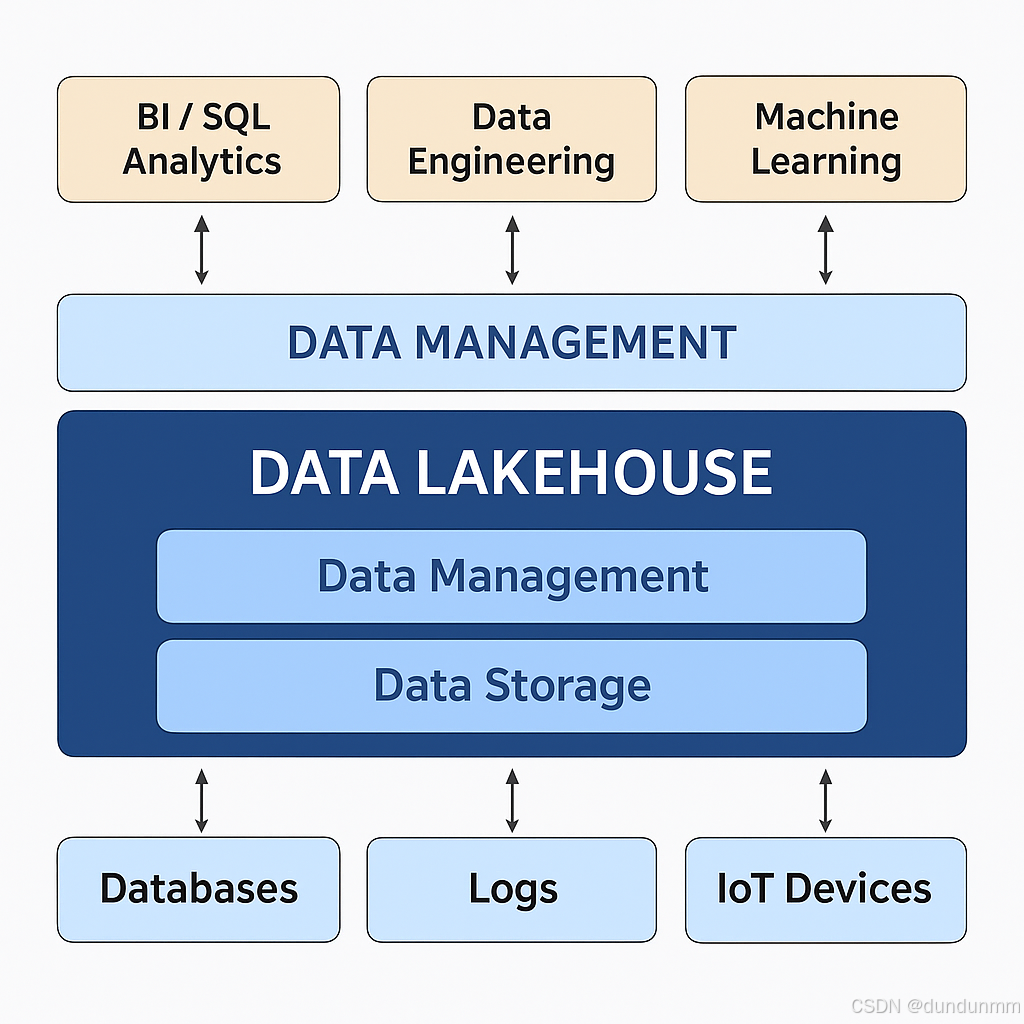
一、什么是“湖仓一体”?
湖仓一体(Data Lakehouse)是指在同一平台中同时具备数据湖的存储能力与数据仓库的分析处理能力的架构模式。该架构支持将结构化、半结构化和非结构化数据统一存储在数据湖中,并通过增强的数据管理机制与计算引擎,实现类数据仓库的性能和可靠性,从而打通“存”和“用”的壁垒。
二、核心优势
-
统一存储,打破数据孤岛
将企业内各业务系统、日志系统、IoT、API等产生的数据统一汇入一个底层存储系统(如HDFS、S3),避免重复建设和数据搬运。 -
灵活的数据建模机制
支持 schema-on-read(按需建模)与 schema-on-write(预建模型)双模式,兼顾灵活性与一致性。 -
支持多种计算与查询引擎
与Spark、Presto、Trino、Flink、Hive、ClickHouse、Delta Lake、Iceberg等组件无缝集成,既支持实时计算,也支持离线批处理。 -
增强的数据治理能力
通过统一元数据管理、数据血缘、数据质量控制,实现数据资产可观测、可审计、可管理。 -
大规模高性能分析
引入列式存储、缓存加速、向量化执行等技术,在大数据场景下实现高性能 OLAP 分析,媲美传统数据仓库。 -
成本更优
相比传统数据仓库高昂的计算与存储成本,湖仓一体架构使用云对象存储与开源计算引擎,极大降低 TCO(总体拥有成本)。
三、湖仓一体与传统架构的比较
| 特征 | 数据湖 | 数据仓库 | 湖仓一体 |
|---|---|---|---|
| 数据类型支持 | 所有类型 | 结构化 | 所有类型 |
| 存储成本 | 低 | 高 | 较低 |
| 分析性能 | 低 | 高 | 高 |
| 数据治理 | 弱 | 强 | 强 |
| 架构复杂度 | 中 | 高 | 中 |
| 场景适应性 | AI/探索分析 | BI/固定报表 | 通用(BI + AI + R&D) |
四、典型技术生态(开源/商业)
| 功能模块 | 开源代表 | 商业代表 |
|---|---|---|
| 存储引擎 | Apache Hudi、Delta Lake、Apache Iceberg | Databricks Lakehouse、Aliyun DLF、腾讯 TCHouse |
| 计算引擎 | Spark、Flink、Trino、ClickHouse | Snowflake、StarRocks、Kyligence |
| 元数据管理 | Apache Hive Metastore、Amundsen、DataHub | AWS Glue、阿里DataWorks |
| 数据治理 | OpenLineage、Marquez | Collibra、Informatica |
| 可视化分析 | Superset、Redash | Tableau、Power BI、Quick BI |
五、典型应用场景
-
数据要素平台与数据资产交易:湖仓一体架构为“数据可用不可见”的共享模式提供高性能、低成本的底座支撑。
-
金融风控与合规审计:通过元数据血缘和数据审计功能,满足强治理和审计要求。
-
多模态数据分析:图像、文本、行为轨迹等数据整合分析,适合AI场景。
-
政务大数据平台:支撑数据统一汇聚、共享交换、授权分析等政务需求。
-
工业互联网与IoT平台:处理高并发、多维度、时序数据,并进行复杂实时分析。