论文学习:《引入TEC - LncMir,通过对RNA序列的深度学习来预测lncRNA - miRNA的相互作用》
长链非编码RNA ( long noncoding RNAs,lncRNAs )是一类长度通常大于200个核糖核苷酸的非编码RNA ,微小RNA ( microRNAs,miRNAs )是一类由22个核糖核苷酸组成的短链非编码RNA。近年来,越来越多的研究表明,lncRNA和miRNA在基因表达、癌症发展、衰老、神经退行性疾病等方面发挥着重要的调控作用,其中lncRNA - miRNA相互作用是的关键机制之一。
传统的实验方法即耗费资源又耗时,开发了计算工具来预测lncRNA - miRNA相互作用。
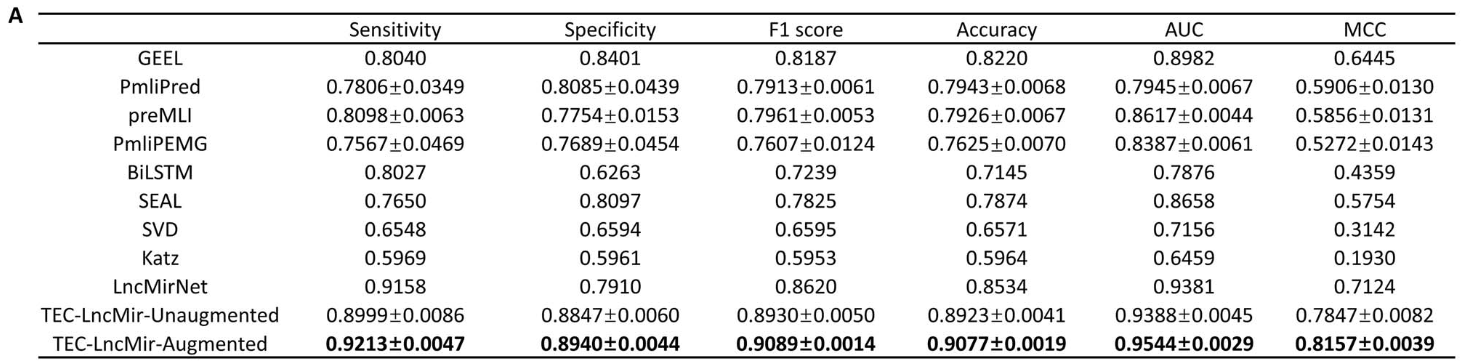
最初,lncRNA - miRNA相互作用预测方法,如基于组偏好的贝叶斯协同过滤( GBCF )和基于表达谱的lncRNA - miRNA相互作用预测模型( EPLMI ),依赖于lncRNA和miRNA的表达数据。这些方法通过比较未知lncRNA - miRNA对和已知lncRNA - miRNA对之间的表达相似性来进行预测。然而,lncRNA和miRNA的表达数据通常是组织特异性的,不一致的,甚至大多数时候是不可用的;因此,GBCF和EPLMI表现出较差的性能,在表达数据不可用的情况下无法使用。如今,lncRNA和miRNA的序列数据容易获得且更加可靠,因此近年来的方法大多基于lncRNA和miRNA序列。具体来说,图嵌入集成学习( Graph Embedding Ensemble Learning,GEEL ) 使用图自动编码器模型来表示lncRNA / miRNA序列,并使用随机森林分类器来预测lncRNA和miRNA之间的潜在相互作用。另一种算法PmliPred提出了一种包含Bi GRU模型和随机森林模型的方法来训练用于lncRNA - miRNA相互作用预测的混合模型。此外,LncMirNet根据lncRNA和miRNA的序列计算它们的多个嵌入,并利用卷积神经网络( CNNs )来预测lncRNA - miRNA相互作用。LncMirNet还引入了其他流行的模型(即: BiLSTM 、用于链接预测的子图、嵌入和属性( SEAL )) 、奇异值分解( Singular Value Decomposition,SVD ) 、Katz )作为对比方法。此外,preMLI 使用rna2vec预训练和深度特征挖掘机制预测lncRNA - miRNA相互作用,Pmli PEMG 使用多层信息增强和贪婪模糊决策方法预测lncRNA - miRNA相互作用,GCNCRF 使用图卷积网络( GCN )和条件随机场( CRF )预测人类lncRNA - miRNA相互作用。然而,这些方法的性能有限,lncRNA - miRNA相互作用预测仍然有很长的路要走,以满足实际应用的需求。具体来说,模型的整体性能是评估其在实际应用中潜力的关键标准。正如先前的研究报告所述,一些先进的模型倾向于在特定的评估指标中改善lncRNA - miRNA相互作用预测,但在另一些模型中显示出有限的性能。例如,LncMirNet表现出91.58 %的高灵敏度,但其特异性仅为79.10 %,导致两个指标之间存在12.48 %的显著差距,同时MCC低至71.24 %。此外,GEEL、PmliPred等方法也报道了较低的MCC,介于19.30 % ~ 64.45 %之间。
在这项研究中,本文将lncRNA和miRNA序列视为自然语言中的句子,并使用k-mer方法将其划分为单词。随后,本文利用Transformer Encoder 和卷积神经网络的强大功能,提出了一个高效准确的预测lncRNA-miRNA相互作用的模型TEC-LncMir。具体来说,TEC-LncMir使用两个Transformer Encoder分别捕获lncRNA和miRNA序列的有意义表示。然后将这些表示进行缩放和融合以生成接触张量,随后将其输入到CNNs中进行特征提取。最后,TEC-LncMir根据提取的特征预测潜在的lncRNA-miRNA相互作用。通过一系列与现有模型的全面对比实验,本文证明了TEC-LncMir在lncRNA-miRNA相互作用预测方面取得了显著的性能提升。此外,本文使用更大的数据集训练了一个强大的TEC-LncMir,并且TEC-LncMir表现出优越的性能。
TEC-LncMir的体系结构
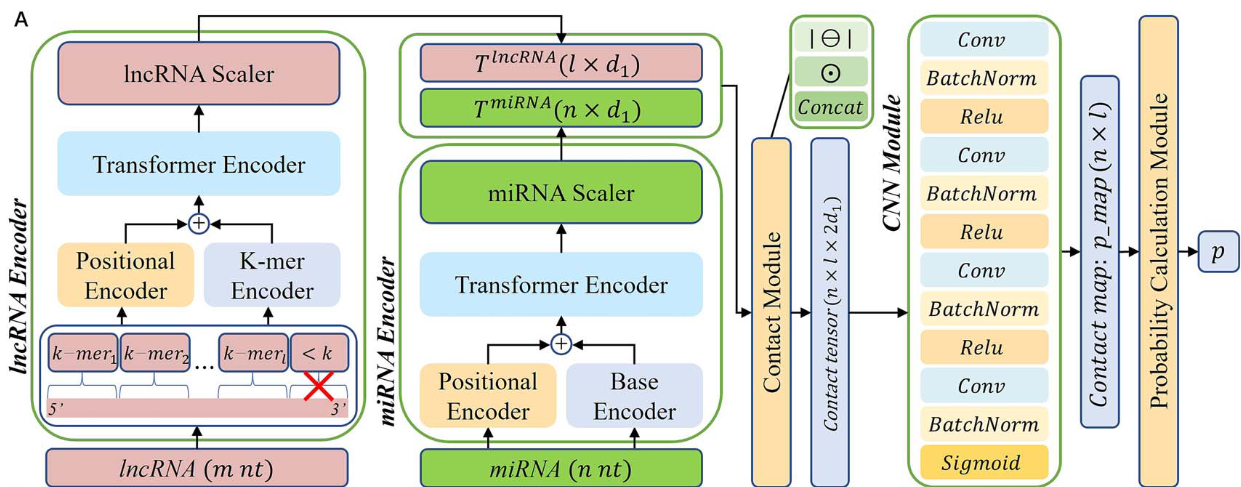
TEC-LncMir是由5个关键组件组成的深度学习模型:lncRNA和miRNA编码器、lncRNA和miRNA定标器、lncRNA-miRNA接触模块、接触特征提取模块和lncRNA-miRNA相互作用预测模块。lncRNA编码器和miRNA编码器分别使用一个k-mer编码器、一个位置编码器和一个Transformer编码器来编码各自的RNA序列,产生lncRNA和miRNA的嵌入。随后,使用lncRNA和miRNA定标器对嵌入进行降维,并将这些降维后的表示集成到lncRNA-miRNA接触模块中的接触张量中。最后,使用CNNs从接触张量中提取特征,并根据这些特征进行lncRNA-miRNA相互作用预测。TEC-LncMir的图形表示参见图1A。
lncRNA的编码器
如图1A所示,lncRNA编码器将长度为m的长lncRNA序列划分为k-mer片段。具体来说,一个长度为k的滑动窗口从lncRNA序列的5′端到3′端以k (采用非重叠读数方法)为步长移动。最后一段的长度可能小于k,然后被丢弃。因此,lncRNA序列由这些l段( l = m / / k , / /表示整数除法算子)表示。考虑到所有可能的N段( N = 4k)以及零填充符号,本文构建了lncRNA的"词汇表"。然后使用k-mer编码器(一个嵌入层)将lncRNA ( l个片段)转换为大小为l × d0的张量(记为X lncRNA∈R l×d0)。此外,位置编码器将片段的位置信息编码为P lncRNA X∈R l×d0,第i个片段的向量计算如下:
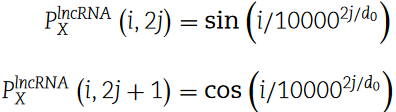
其中i = 1,2,..,l,j = 1,2,..,d0 / 2 .然后,将XlncRNA和P lncRNA X一起加入到Transformer Encoder中,生成lncRNA (E lncRNA∈R l×d0)的嵌入。值得注意的是,Transformer Encoder由n l个编码器层和n h个注意力头组成。Transformer Encoder的维度为d0,前馈模块的维度为2d0,Dropout参数设置为( dropout是指随机设置pdropout ( pdropout∈[ 0,1 ] ))的值在训练时为零) 。最后,由线性层,激活函数ReLU 和dropout层组成的lncRNA定标器,将lncRNA ( lncRNA∈R l×d0)的嵌入转化为T lncRNA∈R l×d1的表示,计算为:
![]()
其中W∈R d0×d1和b∈R d1分别表示线性层的学习权重和偏置。ReLU函数,也称为修正线性单元,是一种非线性激活函数,定义为ReLU ( x ) = max ( 0,x )。
miRNA编码器
miRNA编码器的结构与lncRNA编码器的结构非常相似。区别在于它们各自的k-mer处理的k参数不同。具体而言,miRNA编码器采用1-mer方法,由于miRNA序列长度较短,使用1-mer编码器对单个碱基( 1-mer片段)进行编码。在此背景下,1-mer表示单个碱基,1-mer编码器也被称为碱基编码器。因此,miRNA的"词汇"包括4个RNA碱基和零填充符号( 0 :补零符号, 1 : A , 2 : G , 3 : C , 4 : U)。因此,一个miRNA被编码为E miRNA ( R n×d0 ),并转化为表示为T miRNA∈Rn×d1。
lncRNA - miRNA接触模块
lncRNA - miRNA接触模块通过构建两种特征来融合lncRNA和miRNA的表示,计算式为:

其中i = 1,· · ·,l,j = 1,· · ·,n,O-表示元素级差,⊙表示Hadamard积。因此,diff i,j,mul i,j∈Rd1和diff,mu∈R l×n×d1。最后,将接触张量计算为diff和mul的拼接,得到接触张量∈R n×l×2d1。
卷积神经网络模块
我们使用四层CNN来提取接触张量的特征。具体来说,每一个卷积层都伴随着一个批归一化层和一个非线性激活函数。

卷积层的超参数如表1所示,σ ( x )也是一个非线性激活函数,计算式为:
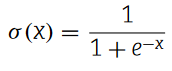
通过CNN模块对接触张量进行处理后得到接触图( p_map∈R l×n)。
概率计算模块
在该模块中,对p_map进行全局池化操作,计算为
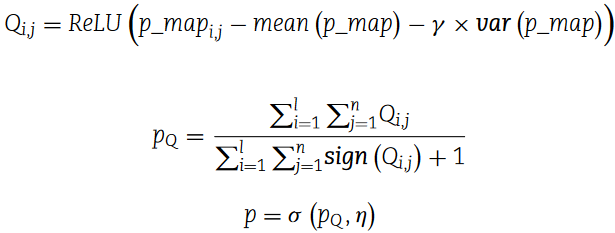
其中
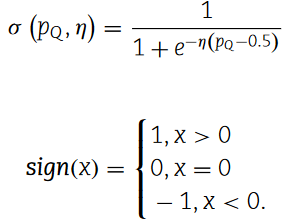
Mean ( p_map ),var ( p_map )分别表示p_map的均值和方差。此外,γ和η是学习参数。
数据增强
本文采用了一种可选的数据增强策略来增加lncRNA-miRNA对的数量,从而提高TECLncMir的性能。具体来说,对于给定的lncRNA - miRNA对,将lncRNA序列划分为k-mer片段,从第i个碱基开始,其中i的取值范围为1到k-1。这导致lncRNA-miRNA对扩展为k对。图1B说明了k取4时的数据增强。

结果
TEC - LncMir的表现优于当前最先进的模型
本文将TEC-LncMir的性能与GEEL,PmliPred,preMLI,PmliPEMG,BiLSTM,SEAL,SVD,Katz和LncMirNet等先进模型进行了比较。值得注意的是,PmliPred、preMLI和PmliPEMG是具有可用源代码的方法,而其他模型不是开源工具。因此,本文在基准数据集上运行Pmli Pred、pre MLI和Pmli PEMG,并直接参考其他模型在同一数据集上的性能结果。如图3A所示,TEC - LncMir在没有( TEC-LncMir- Unaugmented)和有( TEC-Lnc Mir -增强型)数据增强的实验中都表现出更好的性能。其中,TEC-Lnc Mir - Unaugmented和TEC - Lnc Mir - Augmented在MCC上分别比目前表现最好的模型提升了10.15 %和14.50 %。此外,TEC - LncMir - Unaugmented在其他评估指标中也显示出改善,包括特异性( + 5.31 % ),F1分数( + 3.60 % ),准确性( + 4.56 % )和AUC ( + 0.07 % )。另一方面,TECLncMir - Augmented在敏感性( + 0.60 % ),特异性( + 6.42 % ),F1分数( + 5.44 % ),准确性( + 6.36 % )和AUC ( + 1.74 % )方面显示出增强。