MLLM常见概念通俗解析(四)
Reconstructive Visual Instruction Tuning
摘要
本文介绍了一种名为 重建式视觉指令微调(Ross) 的方法,这是一系列利用以视觉为中心的监督信号的大型多模态模型(LMMs)。与传统视觉指令微调方法仅监督文本输出不同,Ross 促使LMM通过重建输入图像来监督视觉输出。通过这样做,它利用了输入图像本身固有的丰富性和细节,这些细节在纯文本监督中往往会丢失。然而,由于视觉信号的巨大空间冗余,从自然图像中产生有意义的反馈具有挑战性。为了解决这个问题,Ross 采用去噪目标来重建输入图像的潜在表征,避免直接回归确切的原始RGB值。这种内在激活设计固有地鼓励LMM保持图像细节,从而增强其细粒度理解能力并减少幻觉。根据经验,Ross 在不同的视觉编码器和语言模型上都能带来显著的改进。与那些聚合多个视觉专家模型的、依赖外部辅助的先进替代方案相比,Ross 凭借单个SigLIP视觉编码器就能提供具有竞争力的性能,展示了我们这种为视觉输出量身定制的、以视觉为中心的监督方法的有效性。
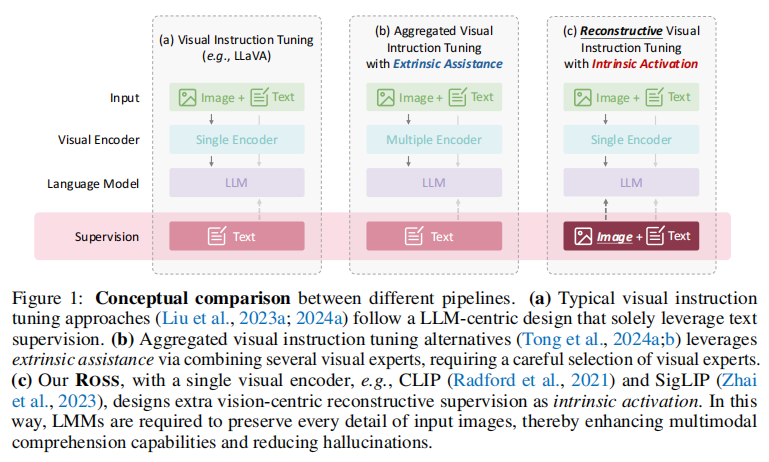
这张图概念性地比较了三种不同的视觉指令微调(Visual Instruction Tuning)流程。
(a)Visual Instruction Tuning (e.g., LLaVA) - 视觉指令微调(例如 LLaVA)
- Input (输入): Image + Text (图像 + 文本)。通常是一个图像和与之相关的文本指令或问题。
- Visual Encoder (视觉编码器): Single Encoder (单个编码器)。图像通过一个视觉编码器转换成特征表示。
- Language Model (语言模型): LLM (大型语言模型)。视觉特征和文本输入一起被送入大型语言模型进行处理。
- Supervision (监督信号): Text (文本)。这种方法的关键在于,模型的训练主要通过监督其生成的文本输出是否正确。例如,如果输入一张猫的图片和问题“这是什么动物?”,模型会被训练以输出正确的文本答案“猫”。
- 图下方描述 (a): “Typical visual instruction tuning approaches (Liu et al., 2023a; 2024a) follow a LLM-centric design that solely leverage text supervision.” (典型的视觉指令微调方法遵循以大型语言模型为中心的设计,仅利用文本监督。)
(b) Aggregated Visual Instruction Tuning with Extrinsic Assistance - 聚合视觉指令微调(依赖外部辅助)
- Input (输入): Image + Text (图像 + 文本)。
- Visual Encoder (视觉编码器): Multiple Encoder (多个编码器)。这种方法的一个特点是它可能会使用多个不同的视觉编码器或“视觉专家”来处理图像,试图从不同角度捕捉更丰富的视觉信息。
- Language Model (语言模型): LLM (大型语言模型)。
- Supervision (监督信号): Text (文本)。与(a)类似,监督信号仍然主要集中在文本输出上。
- 图下方描述 (b): “Aggregated visual instruction tuning alternatives (Tong et al., 2024a;b) leverages extrinsic assistance via combining several visual experts, requiring a careful selection of visual experts.” (聚合视觉指令微调的替代方案利用外部辅助,通过组合多个视觉专家,这需要仔细选择视觉专家。) “Extrinsic Assistance”(外部辅助)是这里的关键词,意味着它依赖于外部的、多个预先训练好的模型或模块。
(c) Reconstructive Visual Instruction Tuning with Intrinsic Activation (Our Ross) - 重建式视觉指令微调(依赖内在激活,即本文提出的Ross方法)
- Input (输入): Image + Text (图像 + 文本)。
- Visual Encoder (视觉编码器): Single Encoder (单个编码器)。例如CLIP或SigLIP。
- Language Model (语言模型): LLM (大型语言模型)。
- Supervision (监督信号): Image + Text (图像 + 文本)。这是Ross方法与前两者的核心区别。除了监督文本输出外,Ross还引入了对视觉输出的监督。具体来说,它促使LMM重建输入图像的某些方面(例如潜在表征),而不仅仅是生成文本。监督信号同时来源于图像和文本。
- 图下方描述 (c): “Our Ross, with a single visual encoder, e.g., CLIP (Radford et al., 2021) and SigLIP (Zhai et al., 2023), designs extra vision-centric reconstructive supervision as intrinsic activation. In this way, LMMs are required to preserve every detail of input images, thereby enhancing multimodal comprehension capabilities and reducing hallucinations.” (我们的Ross方法,使用单个视觉编码器(例如CLIP和SigLIP),设计了额外的以视觉为中心的重建式监督作为内在激活。通过这种方式,LMM被要求保留输入图像的每一个细节,从而增强多模态理解能力并减少幻觉。) “Intrinsic Activation”(内在激活)和“vision-centric reconstructive supervision”(以视觉为中心的重建式监督)是这里的关键。它不依赖聚合多个外部专家,而是通过让模型自身重建视觉信息来学习。
这张图的核心在于对比不同视觉指令微调范式在“监督信号”来源上的差异:
- 传统方法 (a) 主要依赖文本输出来监督模型学习。
- 聚合外部专家的方法 (b) 虽然可能使用更复杂的视觉前端,但监督的焦点仍然是文本。
- 本文提出的Ross方法 (c) 创新之处在于引入了“以视觉为中心的重建式监督”。这意味着模型不仅要学会根据图像和文本指令生成正确的文本,还要学会重建或理解图像本身的深层视觉信息。这种“内在激活”鼓励模型更深入地理解图像细节,从而提升其整体的多模态理解能力,并有助于减少错误信息(幻觉)的产生。Ross试图通过让模型同时关注和学习文本与视觉两个模态的输出来实现更鲁棒和细致的理解。
-
视觉指令微调是什么? (What is visual instruction tuning?)
视觉指令微调(Visual Instruction Tuning)也叫多模态指令微调,是一种训练或调整人工智能模型(特别是大型多模态模型LMMs)的方法,目的是让这些模型能够更好地理解和执行那些同时涉及到视觉信息(如图像)和文本指令的任务。简单来说,就是你给模型一张图片和一段文字指令(比如“描述图片左边的物体”或“这张图片表达了什么情绪?”),通过微调,模型能学会根据图片内容和文字指令给出相关的、正确的响应。 -
传统视觉指令微调方法仅监督文本输出是什么意思? (What does “traditional visual instruction tuning approaches exclusively supervise text outputs” mean?)
这句话的意思是,在传统的视觉指令微调方法中,衡量模型学得好不好的标准,以及用来指导模型学习的“正确答案”,仅仅是针对模型生成的文本内容。
例如,如果模型看到一张猫的图片和问题“这是什么?”,传统方法会看模型输出的文本是不是“这是一只猫”。如果模型答对了文字,就认为它表现良好。这种方法主要关注模型“说”得对不对,而不直接去监督模型对图像本身的理解深度或其内部对视觉特征的表征是否准确。也就是说,训练的“指挥棒”只指向文本输出的质量。 -
Ross 采用去噪目标来重建输入图像的潜在表征是什么意思? (What does “Ross employs a denoising objective to reconstruct latent representations of input images” mean?)
这句话描述了Ross方法中一个核心的技术点,用来实现对视觉输出的监督:- 潜在表征 (Latent Representations): 指的是模型内部对输入图像的一种更抽象、更压缩、包含了核心信息的内部表示,而不是原始的像素值(RGB值)。可以理解为模型对图像“消化”后提炼出的精华特征。
- 重建 (Reconstruct): Ross方法要求模型不仅仅是看懂图像并回答问题,还要尝试根据其理解来“重新构建”出这个图像的潜在表征(可以把它想象成模型对图片内容进行“消化和理解”后,在内部形成的一个关于这张图片“是什么”或“有什么关键点”的浓缩笔记或数字指纹。)。Ross方法要求模型不仅仅能“看懂”这张图片(即形成上述的“核心摘要信息”),还要有能力根据其内部理解,重新生成或再现出这个“核心摘要信息”。模型需要产生一个输出,这个输出在形式和内容上都应该与它从原始图像中提取出来的那个“核心摘要信息”(即目标潜在表征)尽可能一致。
- 去噪目标 (Denoising Objective): 在机器学习中,“去噪”通常意味着模型要学会从一个可能不完美、带有干扰或“噪声”的输入中恢复出原始的、干净的信号。这是一种常见的机器学习训练技巧。通常,模型会被给予一个略微“损坏”或带有“噪声”的版本(尽管摘要里没明说如何加噪,但这是“去噪”的典型含义),然后模型的目标是恢复出那个“干净”的、原始的潜在表征。这个“去噪”的目标帮助模型学习到更鲁棒、更精炼的潜在表征,因为它必须区分什么是重要的信号,什么是不重要的干扰。
- 摘要中提到“避免直接回归确切的原始RGB值”,是因为直接重建像素级的图像非常困难,且计算量大,而重建潜在表征更为高效且能抓住关键视觉信息。
所以,这句话的意思是,Ross通过让模型执行一个“清理并重建图像核心摘要信息”的任务,来迫使其更深入地理解图像内容。因为如果模型不能准确捕捉和保持图像的关键细节,它就无法成功地“清理并重建”出那个高质量的“核心摘要信息”。
-
内在激活设计固有地鼓励LMM保持图像细节是什么意思? (What does “This intrinsic activation design inherently encourages LMMs to maintain image detail” mean?)
- 内在激活设计 (Intrinsic Activation Design): 指的就是Ross方法中这种以视觉为中心、通过重建图像潜在表征来进行监督的设计。它被称为“内在的”,是因为这种学习信号直接来源于图像自身(通过其潜在表征的重建任务),而不是仅仅依赖外部的文本标签或答案。
- 固有地鼓励LMM保持图像细节 (Inherently encourages LMMs to maintain image detail): 因为模型被要求去重建图像的潜在表征,而这个潜在表征需要准确反映原始图像的内容。如果模型在处理图像时丢失了重要的细节,那么它重建出来的潜在表征就会不准确,任务就会失败。因此,这种重建任务自然而然地(固有地)迫使模型在学习过程中必须关注并保留图像的细节信息,以便能够成功完成重建。
简单来说,这种“自己动手,重建图像摘要”的任务,从机制上就保证了模型会更努力地去记住和理解图像的细节。
-
聚合多个视觉专家模型的、依赖外部辅助的先进替代方案是什么意思? (What does “extrinsic assistance state-of-the-art alternatives that aggregate multiple visual experts” mean?)
这句话描述了Ross方法所对比的其他一些先进技术:- 视觉专家模型 (Visual Experts): 通常指那些在特定视觉任务上表现很好的、预先训练好的模型。例如,一个模型可能擅长物体检测,另一个擅长场景分类,还有一个擅长人脸识别等等。这些都可以被看作是不同领域的“视觉专家”。
- 聚合多个 (Aggregate multiple): 这些替代方法会同时使用好几个这样的“视觉专家模型”,把它们各自对图像的分析结果或提取的特征结合(聚合)起来。
- 依赖外部辅助 (Extrinsic Assistance): “辅助”指的是这些额外的视觉专家模型提供的帮助。“外部”则是因为这些专家模型是独立于核心大型多模态模型(LMM)之外的,需要额外引入和集成。
- 先进替代方案 (State-of-the-art alternatives): 指这些也是当前领域内表现很好的、有竞争力的方法。
所以,这句话指的是那些通过整合多个不同特长的预训练视觉模型来增强LMM对图像理解能力的其他先进方法,它们依赖于从这些“外援专家”那里获取更丰富的视觉信息。Ross的优势在于,它仅用单个视觉编码器,通过其新颖的“内在激活”监督方式,就能达到与这些复杂方法相媲美的性能。