一周学会Pandas2 Python数据处理与分析-Pandas2数据添加修改删除操作
锋哥原创的Pandas2 Python数据处理与分析 视频教程:
2025版 Pandas2 Python数据处理与分析 视频教程(无废话版) 玩命更新中~_哔哩哔哩_bilibili

对数据的修改、增加和删除在数据整理过程中时常发生。修改的情况一般是修改错误,还有一种情况是格式转换,如把中文数字修改为阿拉伯数字。修改也会涉及数据的类型修改。 删除一般会通过筛选的方式,筛选完成后将最终的结果重新赋值给变量,达到删除的目的。增加行和列是最为常见的操作,数据分析过程中会计算出新的指标以新列展示。
修改数据值操作
在Pandas中修改数值非常简单,先筛选出需要修改的数值范围,再 为这个范围重新赋值。
下面是示例:
import pandas as pddf = pd.read_excel('student_scores.xlsx') # 读取excel,返回DataFrame数据集对象
df.iloc[0, 0]='老六' # 修改数据
df.loc[df.语文分数 < 60, '语文分数'] = 60 # 指定范围修改数据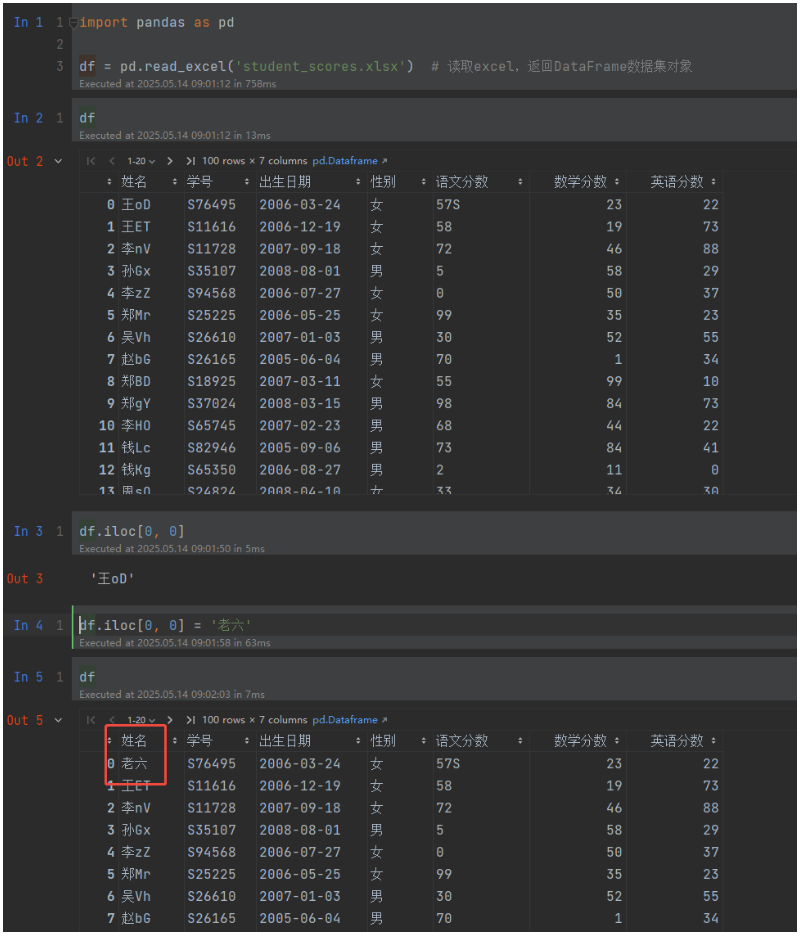
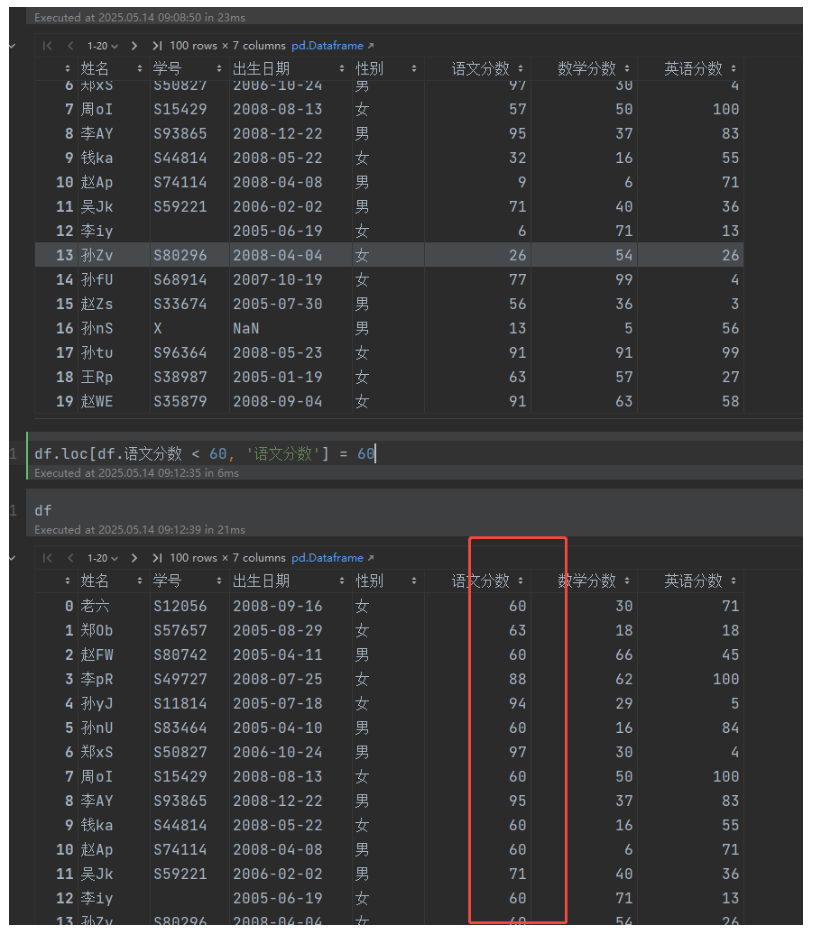
以上操作df变量的内容被修改,这里指定的是一个定值,所有满足条件的数据均被修改为这个定值。还可以传一个同样形状的数据来修改值:
看下示例:
import pandas as pddata = {'Name': ['Alice', 'Bob', 'Charlie', 'David'],'Age': [25, 30, 22, 28],'Score': [85, 95, 75, 88]
}
df = pd.DataFrame(data)
v = [100, 100, 100, 100]
df.Score = v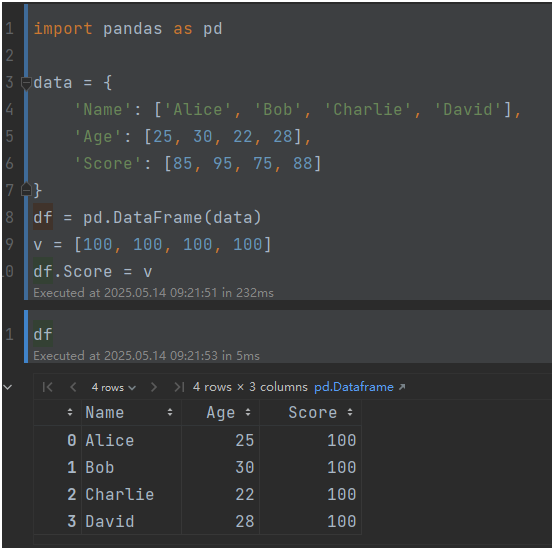
替换数据replace()操作
pandas的replace()方法是用于替换DataFrame或Series中的值的灵活工具。以下是其使用方法的详细介绍:
1,方法定义
replace() 方法的语法如下:
DataFrame.replace(to_replace=None, # 要替换的值(支持多种格式)value=None, # 替换后的值inplace=False, # 是否原地修改limit=None, # 最大替换次数regex=False, # 是否启用正则表达式method=None # 填充方法(已弃用)
)2,核心参数详解
to_replace(必选)
-
功能:指定需要被替换的内容。
-
支持类型:
-
标量:单个值(如
0)。 -
列表:多个值(如
[0, 1])。 -
字典:
-
{old_val: new_val}:全局替换(所有列)。 -
{column: {old_val: new_val}}:按列指定替换规则。
-
-
正则表达式:需设置
regex=True。
-
value(可选)
-
功能:替换后的新值,默认
None。 -
规则:
-
若
to_replace是标量或列表,value可以是单个值或与to_replace等长的列表。 -
若
to_replace是字典,value通常被忽略(直接在字典中定义新旧值)。
-
regex(布尔值,默认 False)
-
功能:是否将
to_replace视为正则表达式模式。 -
示例:
# 将包含数字的字符串替换为 'X' df.replace(to_replace=r'\d+', value='X', regex=True)
inplace(布尔值,默认 False)
-
功能:若为
True,直接修改原对象,不返回新对象;否则返回替换后的副本。
limit(整数,默认 None)
-
功能:限制连续替换的最大次数(适用于相邻重复值的替换场景)。
3,使用场景与示例
简单值替换:
import pandas as pd
import numpy as np# 示例数据
df = pd.DataFrame({'A': [1, 2, 3, 4],'B': ['a', 'b', 'c', 'd'],'C': [0, 1, np.nan, 1]
})# 将 0 替换为 -1(全局)
df.replace(0, -1)# 将 0 和 1 替换为 -1 和 -2
df.replace([0, 1], [-1, -2])# 按列替换:A列的1替换为100,C列的0替换为-1
df.replace({'A': {1: 100}, 'C': {0: -1}})正则表达式替换:
import pandas as pd# 将字符串中的数字替换为 'X'
df = pd.DataFrame({'Text': ['A1', 'B2', 'C3']})
df.replace(to_replace=r'\d', value='X', regex=True)
# 输出:
# Text
# 0 AX
# 1 BX
# 2 CX缺失值处理:
import pandas as pd
import numpy as np
# 示例数据
df = pd.DataFrame({'A': [1, 2, 3, 4],'B': ['a', 'b', 'c', 'd'],'C': [0, 1, np.nan, 1]
})
# 将 NaN 替换为 0
df.replace(np.nan, 0)多值嵌套字典替换:
import pandas as pd
import numpy as np# 示例数据
df = pd.DataFrame({'A': [1, 2, 3, 4],'B': ['a', 'b', 'c', 'd'],'C': [0, 1, np.nan, 1]
})
# 多层字典结构:不同列使用不同规则
df.replace({'A': {1: 100, 2: 200}, # A列:1→100,2→200'B': {'a': 'Alpha'} # B列:a→Alpha
})混合类型替换:
import pandas as pd
import numpy as np
# 示例数据
df = pd.DataFrame({'A': [1, 2, 3, 4],'B': ['a', 'b', 'c', 'd'],'C': [0, 1, np.nan, 1]
})
# 同时替换数值和字符串
df.replace({0: 'Zero', # 全局将0替换为'Zero''a': 'Alpha' # 全局将'a'替换为'Alpha'
})空值填充fillna()操作
pandas 的 fillna() 方法是处理缺失值(NaN或None)的核心工具,用于填充或替换数据中的空值。以下是其定义、参数详解及常见使用场景的完整指南:
1,方法定义
DataFrame.fillna(value=None, # 填充值(标量、字典、Series或DataFrame)method=None, # 填充方法:'ffill'(向前填充)、'bfill'(向后填充)axis=None, # 填充方向:0(沿行,默认),1(沿列)inplace=False, # 是否原地修改limit=None, # 最大连续填充次数downcast=None # 自动向下转换数据类型(可选)
)2,核心参数详解
value
-
功能:指定填充缺失值的具体内容。
-
支持类型:
-
标量:如
0、"missing"。 -
字典:按列指定填充值(键为列名)。
-
Series/DataFrame:对齐索引后填充(需形状匹配)。
-
method
-
功能:选择填充策略,与
value互斥(不能同时使用)。-
'ffill'/'pad':用前一个非空值填充。 -
'bfill' / 'backfill':用后一个非空值填充。
-
axis
-
功能:控制填充方向:
-
axis=0或axis='index':按行填充(默认)。 -
axis=1或axis='columns':按列填充。
-
limit
-
功能:限制连续填充的最大次数(如
limit=2表示最多填充连续2个NaN)。
inplace
-
功能:若为
True,直接修改原对象,否则返回新对象。
3,使用场景
用固定值填充
import pandas as pd
import numpy as np
# 示例数据
df = pd.DataFrame({'A': [1, np.nan, 3, np.nan],'B': ['x', np.nan, 'y', np.nan],'C': [np.nan, 5, np.nan, 7]
})
# 所有NaN填充为0
df.fillna(0)
# 按列指定填充值(A列填0,B列填'missing')
df.fillna({'A': 0, 'B': 'missing'})向前/向后填充
# 向前填充(用前一个非空值)
df.fillna(method='ffill')# 向后填充(用后一个非空值)
df.fillna(method='bfill')限制填充次数
# 最多连续填充2个NaN
df.fillna(value='Q', limit=2)增加列操作
增加列是数据处理中最常见的操作,Pandas可以像定义一个变量一 样定义DataFrame中新的列,新定义的列是实时生效的。与数据修改的逻辑一样,新列可以是一个定值,所有行都为此值,也可以是一个同等长度的序列数据,各行有不同的值。接下来我们增加总成绩total列:
import pandas as pddf = pd.read_excel('student_scores.xlsx') # 读取excel,返回DataFrame数据集对象
df['总分'] = df.语文分数 + df.数学分数 + df.英语分数我们也可以用insert()方法在指定位置插入列。
方法定义:
DataFrame.insert(loc, # 插入位置的索引(从0开始)column, # 新列的名称value, # 新列的数据(标量、数组、Series等)allow_duplicates=False # 是否允许列名重复(默认不允许)
)核心参数说明:
-
loc:插入位置的整数索引(如
0表示第一列前)。 -
column:新列的名称(字符串)。
-
value:新列的数据,可以是标量、列表、NumPy 数组、Series 等。
-
allow_duplicates:若为
True,允许插入与现有列同名的列(默认False会触发错误)。
我们在第5列插入总分字段
import pandas as pddf = pd.read_excel('student_scores.xlsx') # 读取excel,返回DataFrame数据集对象
df.insert(4, '总分', df.语文分数 + df.数学分数 + df.英语分数) # 在第5列插入总分字段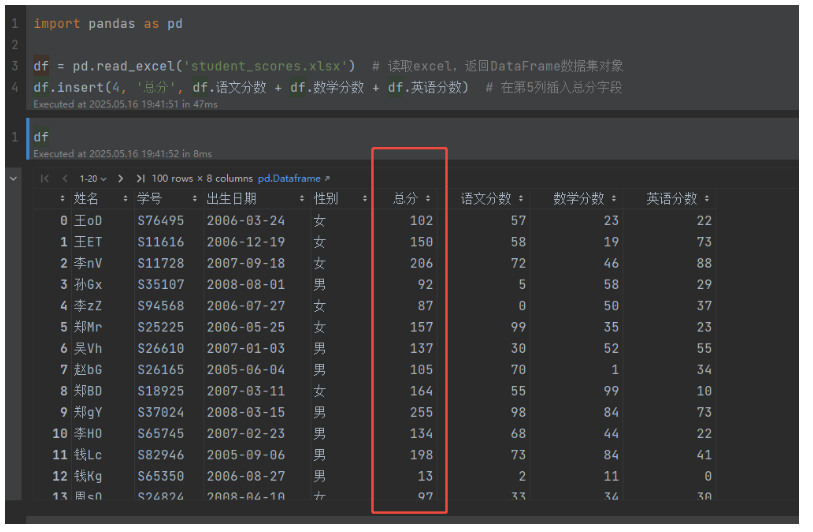
还有一个assign()方法,pandas 的 assign() 方法是 链式操作(Method Chaining) 中的核心工具,用于动态添加新列或覆盖现有列,不修改原 DataFrame,而是返回一个新的 DataFrame。它特别适合在数据处理流程中优雅地添加多列或进行复杂计算。以下是其详细使用指南:
方法定义:
DataFrame.assign(**kwargs) -> DataFrame参数:kwargs 是以列名为键的键值对,值可以是:
-
标量、列表、数组、Series。
-
一个函数(如
lambda),参数为当前 DataFrame。
返回值:返回包含新列的新 DataFrame,原 DataFrame 不变。
特点:支持动态列名、链式调用,适合函数式编程。
我们动态添加一个总分列:
import pandas as pd
df = pd.read_excel('student_scores.xlsx') # 读取excel,返回DataFrame数据集对象
df_new = df.assign(总分=df.语文分数 + df.数学分数 + df.英语分数)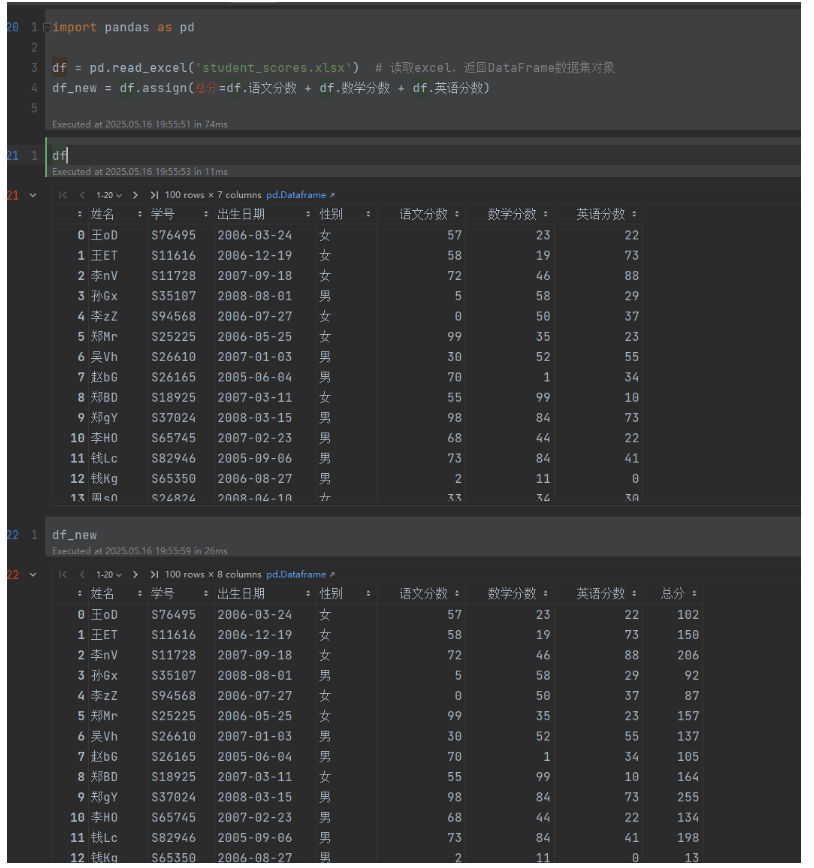
最后再介绍一个eval()方法,可以以字符串的形式传入表达式,增加列数据。我们还是以增加总分示例来学习下:
import pandas as pddf = pd.read_excel('student_scores.xlsx') # 读取excel,返回DataFrame数据集对象
df.eval('总分=语文分数 + 数学分数 + 英语分数')eval()方法定义:
DataFrame.eval(expr, # 表达式字符串(必填)inplace=False, # 是否原地修改(默认为False)**kwargs # 其他参数(如engine, target等)
)核心参数:
expr: 要执行的表达式字符串(例如 "A + B")。
inplace: 若为 True,直接修改原 DataFrame;若为 False,返回新对象(默认)。
engine: 计算引擎('numexpr' 或 'python'),默认自动选择。
target: 指定计算结果存储的列名或位置(可选)。
增加行操作
可以使用loc[]指定索引给出所有列的值来增加一行数据。
import pandas as pd
df = pd.read_excel('student_scores.xlsx') # 读取excel,返回DataFrame数据集对象
df.loc[100] = ['老六', 'S1111', '1999-11-11', '男', 10, 10, 10]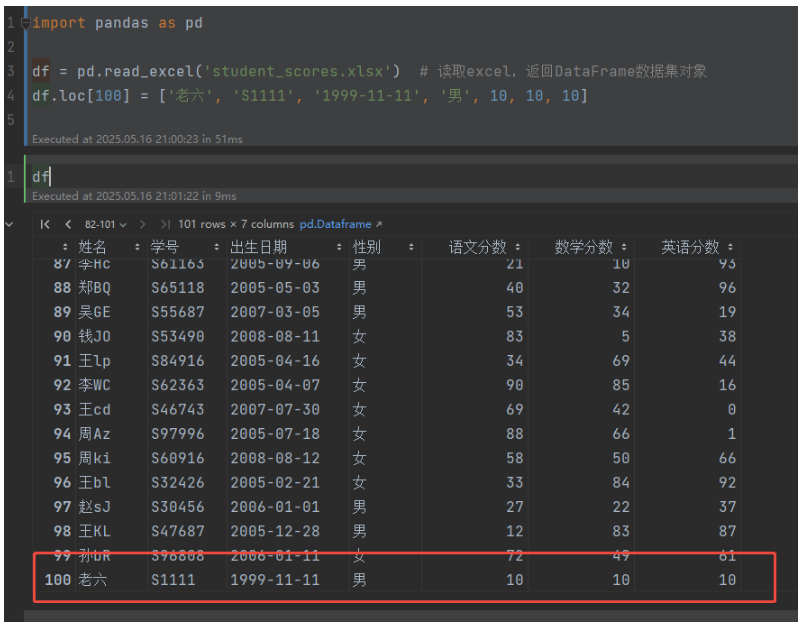
还可以指定列,无数据的列值为NaN
df.loc[101] = {'姓名': '老七', '学号': 'S11122', '性别': '男'}自动增加索引
df.loc[len(df)] = {'姓名': '老八', '学号': 'S11123', '性别': '女'}
追加合并concat()操作
pandas 的 concat() 方法是用于 沿指定轴(行或列)合并多个 DataFrame 或 Series 的核心工具,支持灵活的数据拼接逻辑。
方法定义:
pd.concat(objs, # 要合并的对象列表(如[df1, df2])axis=0, # 合并方向:0(行方向,默认)或1(列方向)join='outer', # 合并方式:'outer'(并集)或 'inner'(交集)ignore_index=False, # 是否忽略原索引(默认保留)keys=None, # 创建分层索引(标识来源)names=None, # 分层索引的名称verify_integrity=False, # 检查索引是否重复sort=False # 是否对列名排序(默认不排序)
) -> DataFrame/Series纵向堆叠(行合并)示例:
import pandas as pd# 示例数据
df1 = pd.DataFrame({'A': [1, 2], 'B': ['x', 'y']})
df2 = pd.DataFrame({'A': [3, 4], 'B': ['z', 'w']})# 沿行方向合并(默认axis=0)
result = pd.concat([df1, df2], ignore_index=True)
print(result)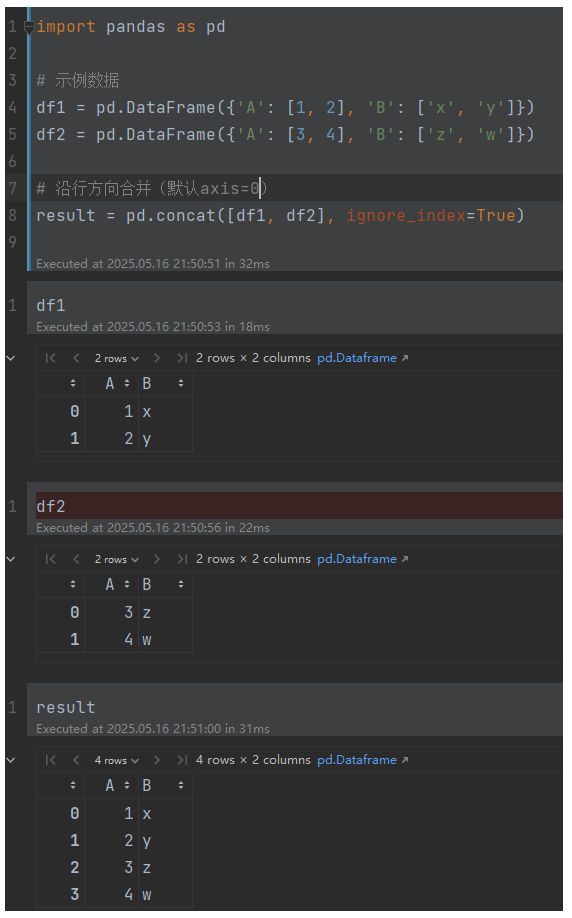
横向拼接(列合并)示例:
df3 = pd.DataFrame({'C': [10, 20], 'D': [True, False]})# 沿列方向合并(axis=1)
result = pd.concat([df1, df3], axis=1)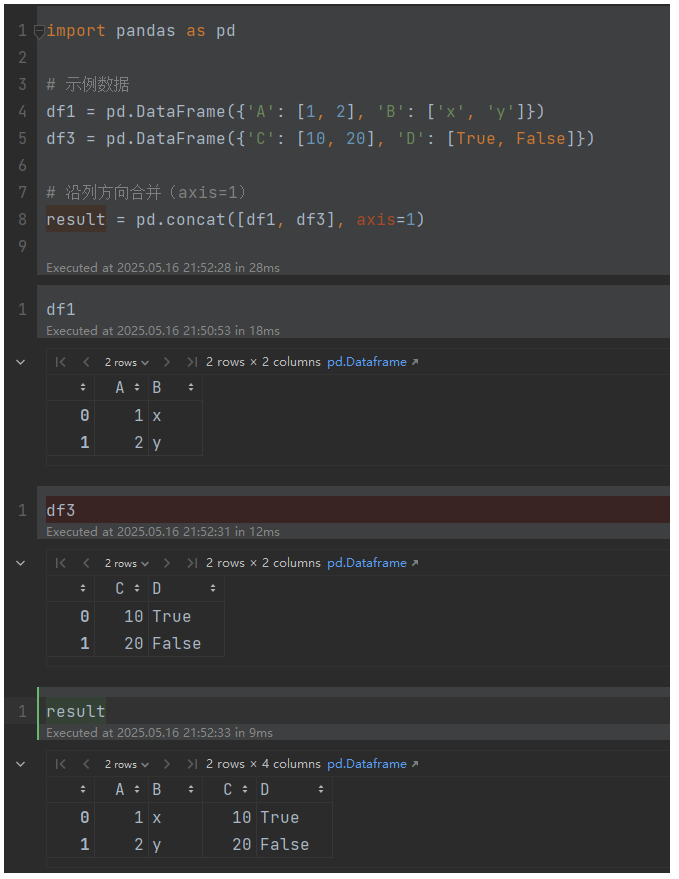
行列删除drop()和pop()操作
pandas 的 pop() 方法用于从 DataFrame 或 Series 中删除指定的列或元素,并返回被删除的数据。该方法直接修改原对象(原地操作),适合需要移除数据并立即使用该数据的场景。以下是详细的使用指南:
方法定义:
# DataFrame 的 pop 方法
DataFrame.pop(item: str) -> Series# Series 的 pop 方法
Series.pop(item: Hashable) -> Any参数说明:
-
item:要删除的列名(DataFrame)或索引标签(Series)。
-
返回值:被删除的列(Series)或元素(标量)。
删除列示例:
import pandas as pd# 创建示例 DataFrame
df = pd.DataFrame({'A': [1, 2, 3],'B': ['x', 'y', 'z'],'C': [10, 20, 30]
})# 删除并返回列 'B'
popped_column = df.pop('B')print("删除后的 DataFrame:")
print(df)
print("\n被删除的列:")
print(popped_column)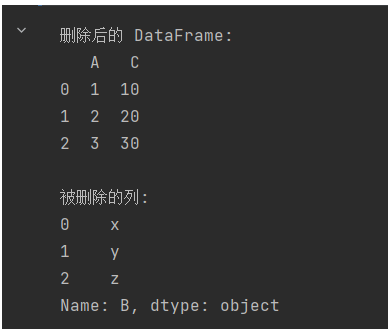
pop()方法只能删除列。我们在学习下drop()方法,行列都能删除。
pandas 的 drop() 方法是用于从 DataFrame 或 Series 中删除指定行或列的核心工具。它支持通过标签或索引位置删除数据,并提供了灵活的参数控制。
方法定义:
DataFrame.drop(labels=None, # 要删除的行/列标签(单个或列表)axis=0, # 删除方向:0(行,默认)或 1(列)index=None, # 直接指定行标签(替代 axis=0)columns=None, # 直接指定列标签(替代 axis=1)level=None, # 多级索引的层级(针对分层索引)inplace=False, # 是否原地修改(默认返回新对象)errors='raise' # 错误处理:'raise'(报错)或 'ignore'
) -> DataFrame | None删除列示例:
import pandas as pd# 创建示例 DataFrame
df = pd.DataFrame({'A': [1, 2, 3],'B': ['x', 'y', 'z'],'C': [10, 20, 30]
})# 删除单列(两种等价写法)
df_dropped = df.drop(columns='B') # 写法1:columns参数
df_dropped = df.drop(labels='B', axis=1) # 写法2:labels + axis=1# 删除多列
df_dropped = df.drop(columns=['B', 'C'])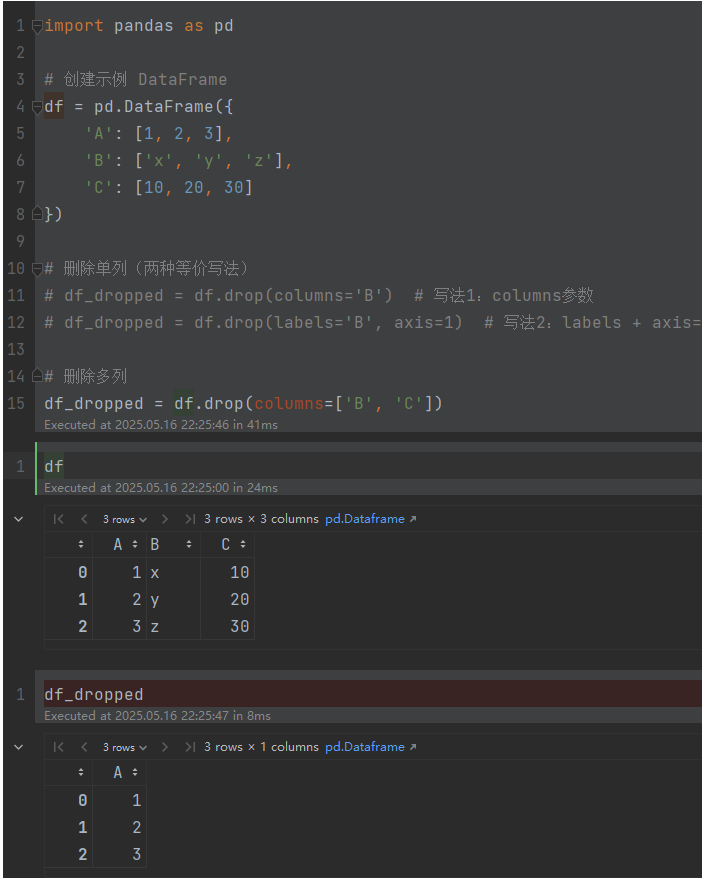
删除行示例:
# 删除单行(按行标签)
df_dropped = df.drop(index=0) # 删除索引为0的行
df_dropped = df.drop(labels=0, axis=0) # 等价写法# 删除多行(按标签或位置)
df_dropped = df.drop(index=[0, 2]) # 删除索引为0和2的行
df_dropped = df.drop([0, 2], axis=0) # 等价写法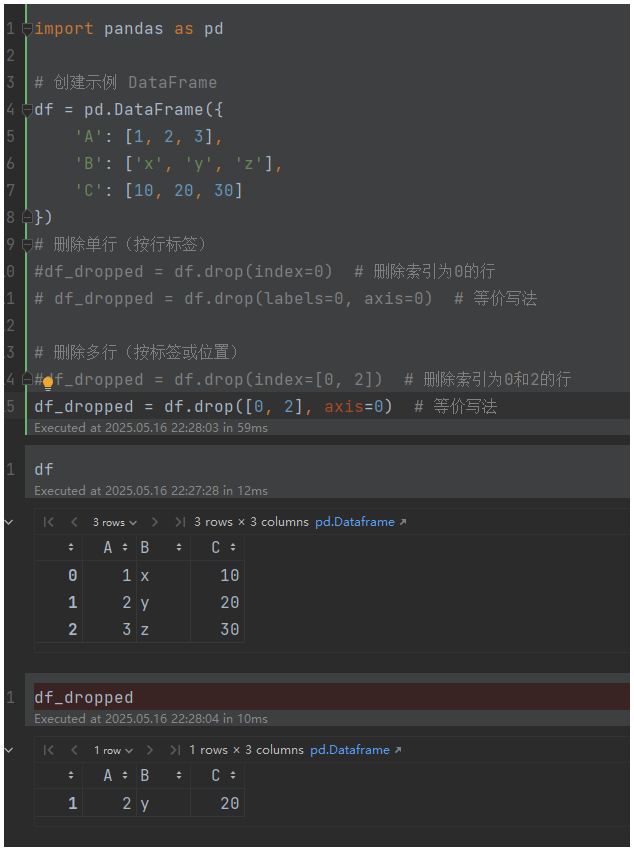
pop()和drop()方法对比
| 方法 | 操作对象 | 返回值 | 修改原对象 | 常用场景 |
|---|---|---|---|---|
pop() | 列或元素 | 被删除的数据 | 是 | 需要立即使用被删除的数据 |
drop() | 行或列 | 新对象(默认) | 否(需inplace=True) | 保留原数据,生成新对象 |
删除空值dropna()操作
dropna方法是pandas中处理缺失值的重要工具,用于删除包含缺失值(NaN或None)的行或列。它在数据清洗阶段非常有用,能帮助我们快速移除不完整的数据记录。以下是dropna方法的详细使用说明:
方法定义:
DataFrame.dropna(axis=0, # 操作方向:0或'index'(删除行),1或'columns'(删除列)how='any', # 删除条件:'any'(存在缺失即删),'all'(全为缺失才删)thresh=None, # 非缺失值的最小数量(阈值)subset=None, # 指定检查的列(行)子集inplace=False # 是否直接修改原数据(默认返回新对象)
)参数解析
-
axis:默认为0,即删除包含缺失值的行。设为1或'columns'时删除列。
-
how:默认'any',只要有一个缺失值就删除。设为'all'时,只有整行(或列)全为缺失值才删除。
-
thresh:设置保留非缺失值的最小数量。例如,thresh=2表示某行至少要有2个非缺失值才保留。
-
subset:指定要检查缺失的列(当axis=0时)或行(当axis=1时)。其他位置的缺失值不影响删除操作。
-
inplace:设为True时直接修改原数据,返回None;否则返回新对象。
示例数据:
import pandas as pd
import numpy as npdata = {'A': [1, np.nan, 3, 4],'B': [np.nan, 2, np.nan, 5],'C': [7, 8, 9, 10]
}
df = pd.DataFrame(data)
print("原始数据:")
print(df)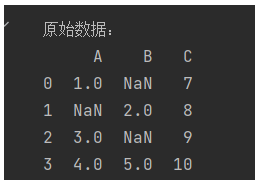
1,默认删除包含缺失值的行
# 删除所有含有NaN的行
df_cleaned = df.dropna()
print("删除含有NaN的行:")
print(df_cleaned)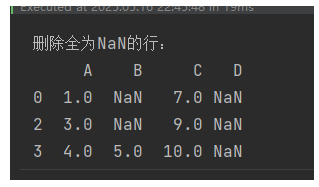
2,删除全为缺失值的行
# 添加一行全为NaN的数据
df.loc[4] = [np.nan, np.nan, np.nan]# 删除全为NaN的行
df_cleaned = df.dropna(how='all')
print("删除全为NaN的行:")
print(df_cleaned)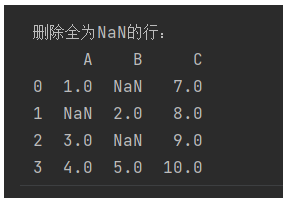
3,按阈值保留数据(thresh参数)
# 保留至少有2个非NaN值的行
df_cleaned = df.dropna(thresh=2)
print("保留至少2个非NaN值的行:")
print(df_cleaned)4,仅检查指定列的缺失值(subset参数)
# 只在列A和B中检查缺失值,列C的NaN不影响结果
df_cleaned = df.dropna(subset=['A', 'B'])
print("仅检查A和B列的缺失值:")
print(df_cleaned)