(4)python爬虫--JsonPath
文章目录
- 前言
- 一、安装JsonPath库
- 第一步: 打开pycharm
- 第二步: 安装jsonpath
- 二、 jsonpath的基本使用
- 2.1 基础语法
- 2.2 语法测试
- 2.2.1 准备json文件(store.json)
- 2.2.2 jsonpath解析json语法
- 三、实战练习
- 需求:爬取淘票票上所有的城市
- 3.1 下载城市json文件
- 3.2 解析城市列表
- 总结
前言
在当今数据驱动的时代,JSON 已成为应用程序间数据交换的事实标准格式。无论是 Web API 响应、配置文件还是 NoSQL 数据库,JSON 结构数据无处不在。然而,当我们需要从复杂的 JSON 文档中精准提取特定数据时,传统的遍历方法往往显得笨拙而低效。这正是 JSONPath 大显身手的场景 - 作为一种类 XPath 的查询语言,它为我们提供了简洁而强大的路径表达式语法。本文将深入探讨 Python 生态中 JSONPath 的实现与应用,从基础语法到高级技巧,帮助您掌握这把处理 JSON 数据的瑞士军刀,让数据提取工作变得优雅而高效。
一、安装JsonPath库
第一步: 打开pycharm
在上方文件处点击进入到设置里面
第二步: 安装jsonpath
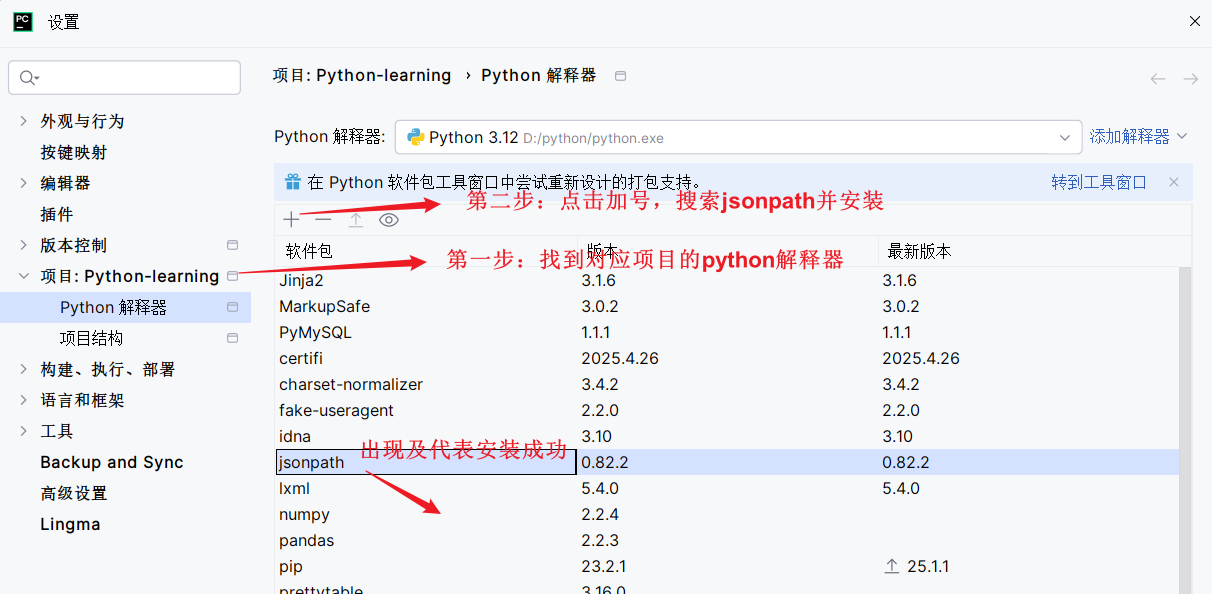
提示: 如果后续使用显示没有该包的提示时,重启pycharm,再次检查是否安装成功,并再试一次。
二、 jsonpath的基本使用
2.1 基础语法
不需要可以记忆,通过不间断的使用自然就学会了。
| XPath | JSONPath | Description |
|---|---|---|
/ | $ | 表示根元素 |
. | @ | 当前元素 |
/ | . or [] | 子元素 |
.. | n/a | 父元素 |
// | ... | 递归下降,JSONPath是从E4X借鉴的。 |
* | * | 通配符,表示所有的元素 |
@ | n/a | 属性访问字符 |
[] | [] | 子元素操作符 |
| ` | ` | [,] |
n/a | [start:end:step] | 数组分割操作从ES4借鉴。 |
[] | ?() | 应用过滤表示式 |
n/a | () | 脚本表达式,使用在脚本引擎下面。 |
() | n/a | XPath分组 |
2.2 语法测试
2.2.1 准备json文件(store.json)
{"store": {"book": [{"category": "修真","author": "大道","title": "坏蛋是怎样练成的","price": 8.95},{"category": "修改","author": "天蚕土豆","title": "斗破苍穹","price": 12.99},{"category": "修真","author": "唐家三少","title": "斗罗大陆","isbn": "0-553-21311-3","price": 8.99},{"category": "修真","author": "南派三叔","title": "星辰变","isbn": "0-395-19395-8","price": 22.99}],"bicycle": {"color": "黑色","price": 19.95}}
}
2.2.2 jsonpath解析json语法
注意:jsonpath只能解析本地文件
示例代码:
import jsonpath
import json
# 使用json将json数据转换成python对象
obj = json.load(open("store.json", "r", encoding="utf-8"))# jsonpath需要获取一个对象(obj)# 1.获取书店所有书的作者
# book[*] *表示所有 [0]就表示只获取第一个元素
# author_list = jsonpath.jsonpath(obj, "$.store.book[*].author")
# print(author_list)# 2.获取所有的作者,不仅仅包括书店的作者
# author_list = jsonpath.jsonpath(obj, "$..author")
# print(author_list)# 3.获取store下面所有的元素
# tag_list = jsonpath.jsonpath(obj,"$.store.*")
# print(tag_list)# store里面所有的price
# price_list = jsonpath.jsonpath(obj,"$.store..price")
# print(price_list)# 获取第三本书
# book3_list = jsonpath.jsonpath(obj,"$..book[2]")
# print(book3_list)# 获取最后一本书
# endbook_list = jsonpath.jsonpath(obj,"$..book[(@.length-1)]")
# print(endbook_list)# 获取前两本书
# 方式1
# twobook_list = jsonpath.jsonpath(obj,"$..book[0,1]")
# 方式2(通过切片的方式)
# twobook_list = jsonpath.jsonpath(obj,"$..book[:2]")
# print(twobook_list)# 条件过滤需要在(条件)前面加上一个?# 获取包含isbn的书
# isbn_list = jsonpath.jsonpath(obj,"$..book[?(@.isbn)]")
# print(isbn_list)# 获取price大于10的书
price_list = jsonpath.jsonpath(obj,"$..book[?(@.price>10)]")
print(price_list)
三、实战练习
需求:爬取淘票票上所有的城市
3.1 下载城市json文件
import requests
# 需求: 获取所有的城市列表url = 'https://dianying.taobao.com/cityAction.json?activityId&_ksTS=1747464057928_136&jsoncallback=jsonp137&action=cityAction&n_s=new&event_submit_doGetAllRegion=true'# 请求头前面存在冒号的,还有accept-encoding要注释掉
headers = {# ':authority': 'dianying.taobao.com',# ':method': 'GET',# ':path': '/cityAction.json?activityId&_ksTS=1747464057928_136&jsoncallback=jsonp137&action=cityAction&n_s=new&event_submit_doGetAllRegion=true',# ':scheme': 'https','accept': 'text/javascript, application/javascript, application/ecmascript, application/x-ecmascript, */*; q=0.01',# 'accept-encoding': 'gzip, deflate, br, zstd','accept-language': 'zh-CN,zh;q=0.9','bx-v': '2.5.28','cookie': 'thw=cn; cna=jfRGHxMmynwCAbZ7Yw6NwCTK; t=61f8a910bfc17eeec46613b5057171a4; cookie2=109045452e400664a5782170296da7b2; v=0; _tb_token_=e340e5f867e7b; xlly_s=1; tb_city=110100; tb_cityName="sbG+qQ=="; isg=BN_f48p9y74Ssc-iThhSt3dbbjNpRDPm6IG0M3EuTg7VAP-CeRUmNgzewpB-ngte','priority': 'u=1, i','referer': 'https://dianying.taobao.com/?spm=a1z21.3046609.city.1.32c0112aRwYvxC&city=110100','sec-ch-ua': '"Chromium";v="136", "Google Chrome";v="136", "Not.A/Brand";v="99"','sec-ch-ua-mobile': '?0','sec-ch-ua-platform': '"Windows"','sec-fetch-dest': 'empty','sec-fetch-mode': 'cors','sec-fetch-site': 'same-origin','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36',
}response = requests.get(url,headers=headers)
content = response.content.decode()
# print(content)# 切割我们需要的部分
content = content.split("(")[1].split(")")[0]
print(content)# 将得到的json文件写入到文件中
# 使用ctrl + alt + l 自动格式化json
with open('city.json','w',encoding='utf-8') as f:f.write(content)
3.2 解析城市列表
import jsonpath
import json
# 需求: 获取所有的城市列表
obj = json.load(open("city.json", "r", encoding="utf-8"))
city_list = jsonpath.jsonpath(obj, "$..regionName")
print(city_list)
总结
通过本文的探讨,我们可以看到 Python 中的 JSONPath 为实现复杂 JSON 数据查询提供了优雅的解决方案。无论是简单的值提取还是复杂的嵌套查询,JSONPath 都能以声明式的方式轻松应对。掌握这项技能不仅能提升日常数据处理效率,更能帮助我们在大数据时代保持竞争力。记住,优秀的开发者不仅要会写代码,更要懂得如何高效地"对话"数据。希望本文介绍的工具和技巧能成为您数据处理工具箱中的常备利器,让您在面对任何 JSON 结构时都能从容不迫,游刃有余。