Ocean: Object-aware Anchor-free Tracking
领域:Object tracking
It aims to infer the location of an arbitrary target in a video sequence, given only its location in the first frame
问题/现象:
-
Anchor-based Siamese trackers have achieved remarkable advancements in accuracy, yet the further improvement is restricted by the lagged tracking robustness.
即Anchor-based Siamese trackers精确度还行但鲁棒性不行 -
In prior Siamese tracking approaches, the classification confidence is estimated by the feature sampled from a fixed regular region in the feature map. This sampled feature depicts a fixed local region of the image, and it is not scalable to the change of object scale. As a result, the classification confidence is not reliable in distinguishing the target object from complex background.
分类置信度是通过从固定的局部区域得到的特征估计出来的,所以当物体尺度变化的时候它并不会改变。所以当要从复杂的背景区分目标物体时,这个分类器是不可靠的。 -
regression network in anchor-based methods is only trained on the positive anchor boxes. This mechanism makes it difficult to refine the anchors whose overlap with the target objects are small.This will cause tracking failures especially when the classification results are not reliable. The regression network is incapable of rectifying this weak prediction because it is previously unseen in the training set.原因是因为
anchor-based methods的回归网络仅在正样本(当框和目标物体的重合超过一个标准时,称这个框为正样本)上训练(训练集中只有分类正确的时候,offset是什么。没有分类错误的样本)。这使得它很难去refine anchors当anchor和目标物体的重叠很少时(因为这个时候的框为负样本,previously unseen in the training set.,先前/训练时没见过这样的)。也就是当前面分类错误的时候,后面的回归网络也没有修正这个不准确的预测的能力
can we design a bounding-box regressor with the capability of rectifying inaccurate predictions?
YES!
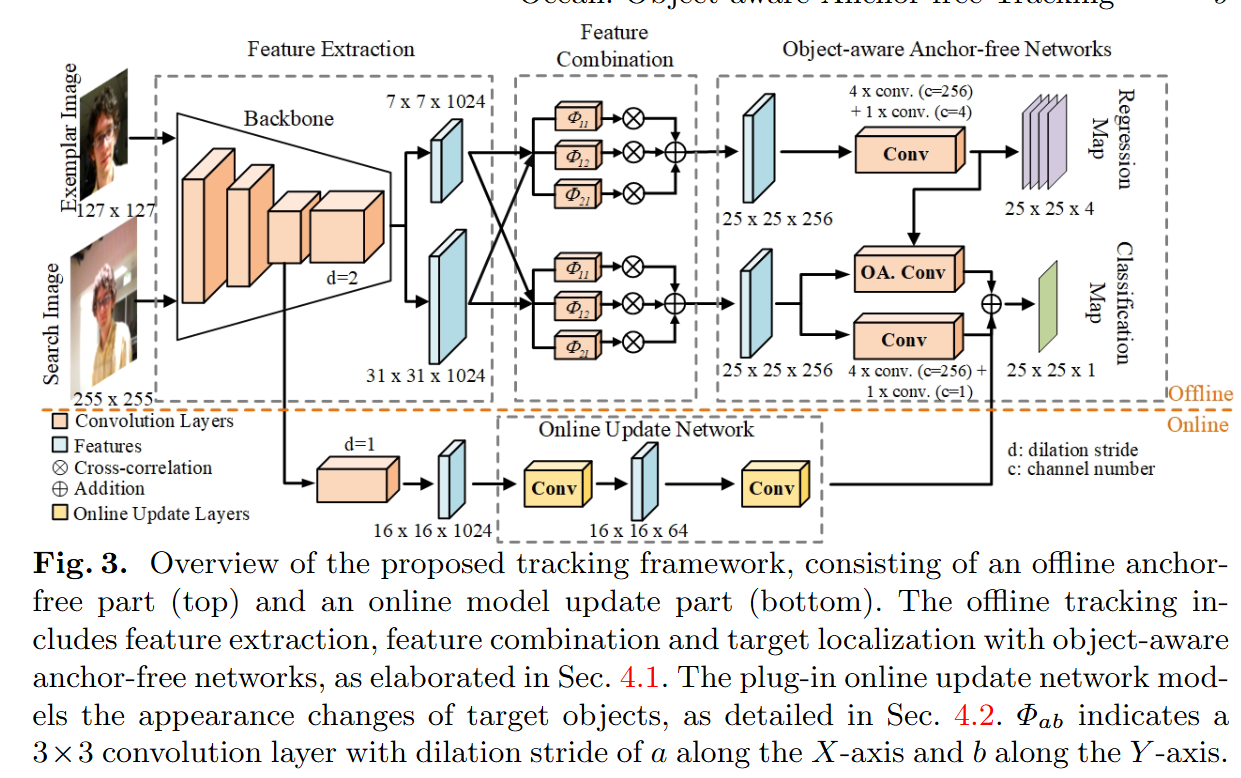
这篇文章提出的跟踪器哈哈:Object-aware Anchor-Free Networks(Ocean)
(对应上述问题123)
-
consists of two components: an object-aware classification network and a bounding-box regression network.(anchor free的) -
The classification is in charge of determining whether a region belongs to foreground or background
分类器分出前景和背景(分类只采样距离中心近的点为正样本)(同时使用了object-aware feature和regular-region feature。与之前anchor free方法,如FCOS不同的是增加了一个object-aware feature,且FCOS分类和回归都是计算所有落在GT内的点;)
introduce a feature alignment module to learn an object-aware feature from predicted bounding boxes. The object-aware feature can further contribute to the classification of target objects and background.
同时引进一个特征对齐的模块来学习object-aware feature,使得更好的实现背景和目标物体之间的区分,也获得了一个全局的外观描述。
实现:将卷积核的固定采样位置对齐到预测的回归box(图2c)。回归box是通过bounding-box regression network得来的哦。对于classification map上的每个位置(dx, dy),都有一个对应的回归预测框M=(mx, my, mw, mh),mx,my表示中心,mw,mh表示宽高。目标就是从候选框M中采样特征来预测(dx, dy)的分类得分。 -
regression aims to predict the distances from each pixel within the target objects to the four sides of the groundtruth bounding boxes.
回归用来预测目标物体中的每个像素点到真实锚框的四条边的距离。(训练时候的样本是all the pixels in the groundtruth bounding box)
Since each pixel in the groundtruth box is well trained, the regression network is able to localize the target object even when only a small region is identified as the foreground.
首先判断一个区域是不是前景,这时候就算只有很小一块区域被分类为前景,由于each pixel in the groundtruth box is well trained,所以该回归有修正前面不太正确的预测的可能性
(这样理解:anchor-based一个框是一个样本,这里一个像素是一个样本。前面的训练集是正确的框怎么偏移到groundtruth,后面的是每个像素到框的距离。那么当框和目标物体重叠很小但被预测为正确的框的时候。对于anchor-based,因为实际上它是负样本,所以没见过,没训练过。但对于anchor free的,即使重叠的部分很小,那也还是有位于目标物体内的像素点在框内的,训练的时候见过,所以有纠正预测的可能)
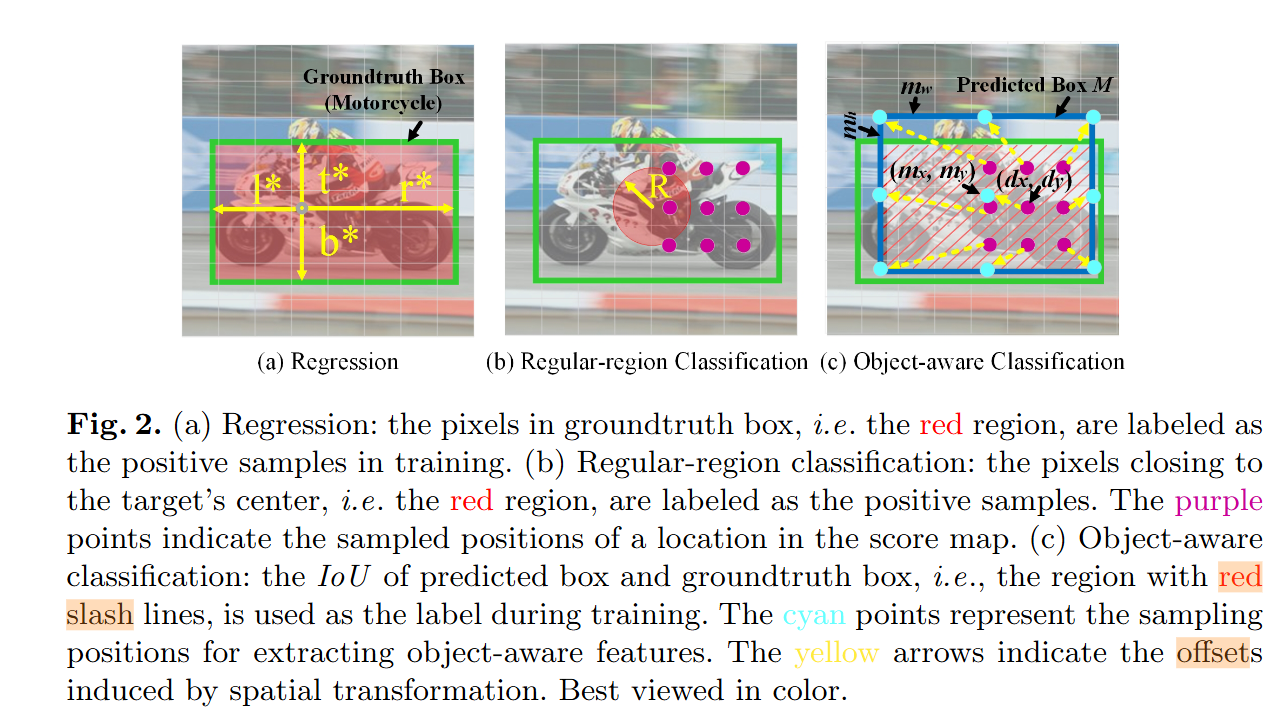
- 回归的时候所有位于
groundtruth box内的像素都被标注为正样本 - 对于
Regular-region classification,靠近目标中心点的一小部分区域内的像素为正样本 - 对于
Object-aware classification,the IoU of predicted box and groundtruth box被用作标签。
more details are provided in this paper:Ocean: Object-aware Anchor-free Tracking
补充(超简版):
anchor-based methodsVSanchor free methodsanchor-based:- 相比于
anchor free,它使用预定义的anchor框来匹配真实的目标框 - 过程:生成
anchor boxes,判断每个anchor box为foreground还是background(二分类),对anchor box进行微调(这部分就是前文提到的refine),使得positive anchor和真实框(Ground Truth Box)更加接近(使用regression)
- 相比于
anchor free:Different from anchor-based methods which estimate the offsets of anchor boxes, anchor-free mechanisms predict the location of objects in a direct way.- 基于角点的/中心点的/全卷积的
- 目标跟踪VS目标检测
- 目标检测是事先针对特定目标的,比如人头检测、动物检测,目标跟踪则是对于任意目标的跟踪,即事先是不知道跟踪的具体目标的。(但是检测器也可以根据人们需要检测的目标进行初始化,这样好像又有点像跟踪器了->基于检测的目标跟踪。而且感觉基于检测的的目标跟踪有点 杀鸡用牛刀 了吧,因为根本不需进行目标识别,不需要每一帧都去检测,就只是目标跟踪就好了)
- 理想的跟踪器应该不需要每一帧都暴力检测目标所在的位置,而是可以充分利用帧间信息,目标周围的环境信息,甚至根据周边环境推测得到的三维信息等,更加高效的确定目标所在的位置
- 再想象一个场景:一个被设计用来检测行人的目标检测器,如果将其应用到马路场景上,检测器将会检测到马路上的大量行人。如果只想跟踪某个行人,那么检测器的结果并不是人们想要的。但这时跟踪器就完全不一样了,给跟踪器指定初始跟踪行人后,它将可以在后续的过程中只跟踪指定的行人