机器学习 KNN算法
KNN算法
- 1. sklearn机器学习概述
- 2. KNN算法-分类
- 1 样本距离判断
- 2 KNN 算法原理
- 3 KNN缺点
- 4 API
- 5 sklearn 实现KNN示例
- 6 模型保存与加载
- 葡萄酒(load_wine)数据集KNN算法
- (1)wine.feature_names:
- (2)wine.target_names
- (3)KNN算法实现
1. sklearn机器学习概述
获取数据、数据处理、特征工程后,就可以交给预估器进行机器学习,流程和常用API如下。
1.实例化预估器(估计器)对象(estimator), 预估器对象很多,都是estimator的子类(1)用于分类的预估器sklearn.neighbors.KNeighborsClassifier k-近邻sklearn.naive_bayes.MultinomialNB 贝叶斯sklearn.linear_model.LogisticRegressioon 逻辑回归sklearn.tree.DecisionTreeClassifier 决策树sklearn.ensemble.RandomForestClassifier 随机森林(2)用于回归的预估器sklearn.linear_model.LinearRegression线性回归sklearn.linear_model.Ridge岭回归(3)用于无监督学习的预估器sklearn.cluster.KMeans 聚类
2.进行训练,训练结束后生成模型estimator.fit(x_train, y_train)
3.模型评估(1)方式1,直接对比y_predict = estimator.predict(x_test)y_test == y_predict(2)方式2, 计算准确率accuracy = estimator.score(x_test, y_test)
4.使用模型(预测)
y_predict = estimator.predict(x_true)
2. KNN算法-分类
1 样本距离判断
明可夫斯基距离欧式距离,明可夫斯基距离的特殊情况 (平方和开根号)曼哈顿距离,明可夫斯基距离的特殊情况 (绝对值之和)
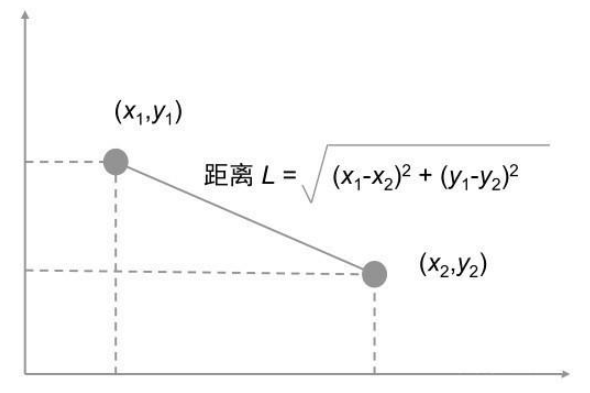
两个样本的距离公式可以通过如下公式进行计算,又称为欧式距离。
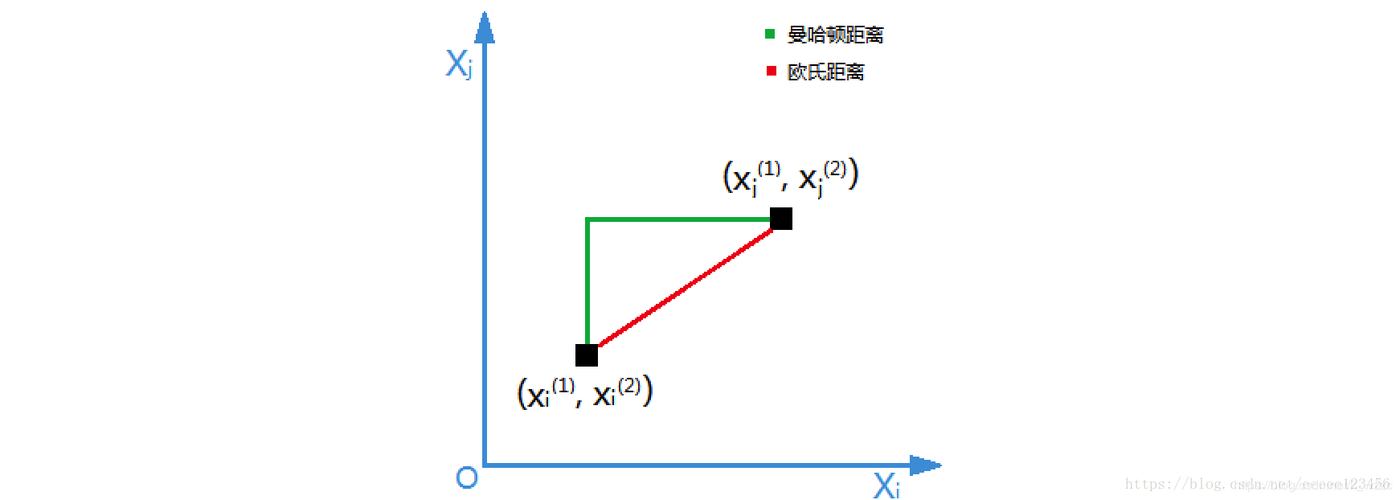
(1)欧式距离
2)曼哈顿距离
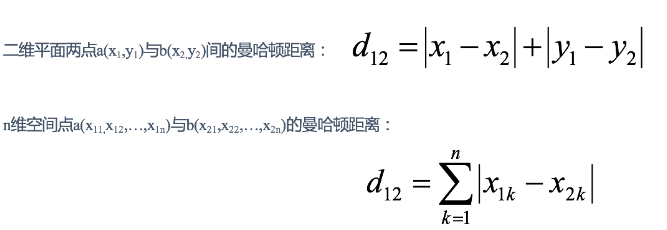
(3)其他距离公式





2 KNN 算法原理
K-近邻算法(K-Nearest Neighbors,简称KNN),根据K个邻居样本的类别来判断当前样本的类别;
如果一个样本在特征空间中的 k个最相似(最邻近)样本中的大多数属于某个类别,则该类本也属于这个类别
比如: 有10000个样本,选出7个到样本A的距离最近的,然后这7个样本中假设:类别1有2个,类别2有3个,类别3有2个.那么就认为A样本属于类别2,因为它的7个邻居中 类别2最多(近朱者赤近墨者黑)
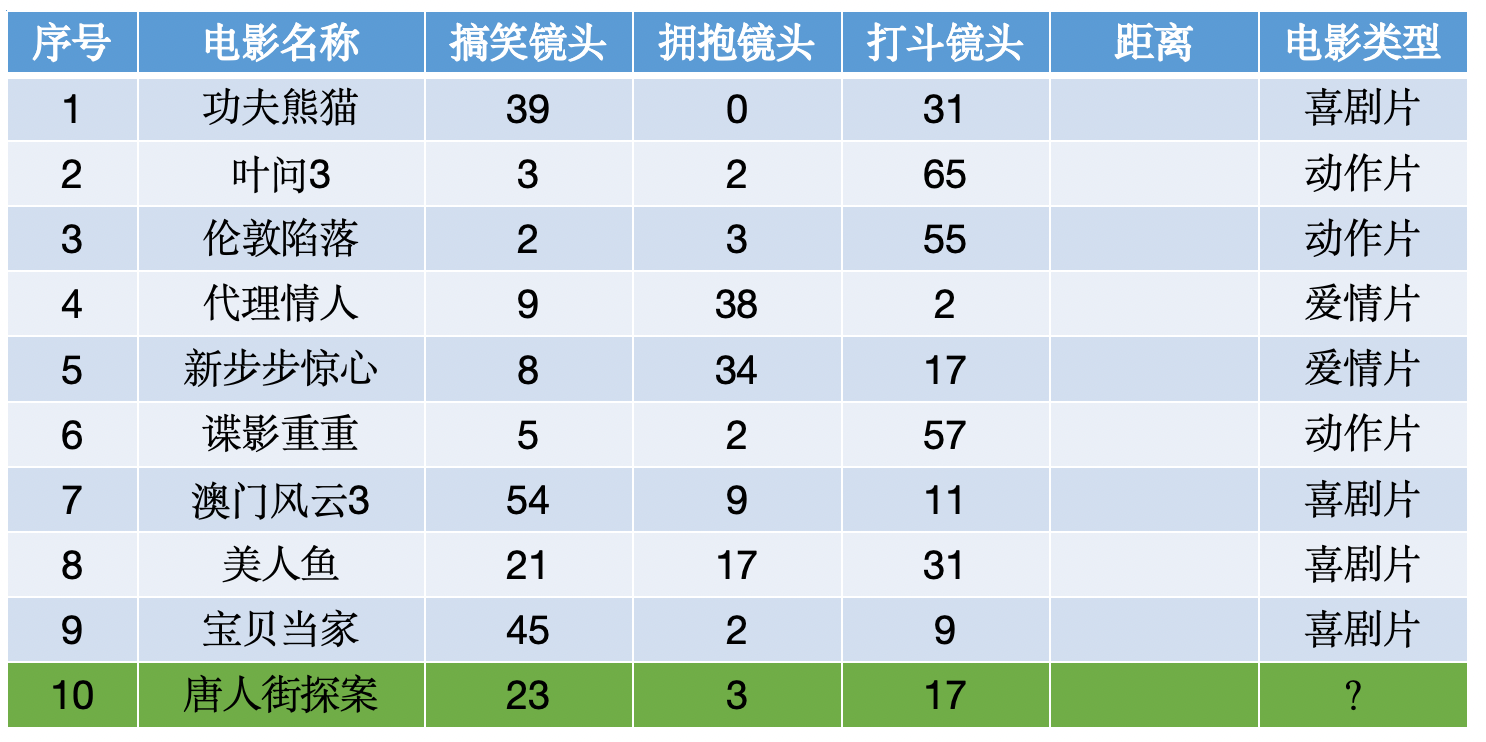
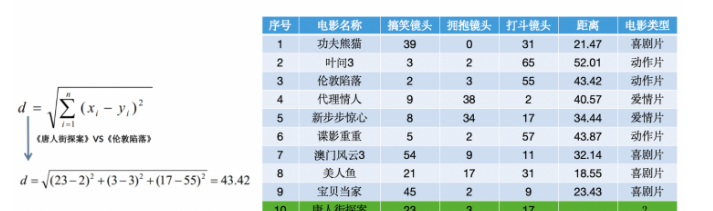
使用KNN算法预测《唐人街探案》电影属于哪种类型?分别计算每个电影和预测电影的距离然后求解:
3 KNN缺点
缺点:
-(1) 对于大规模数据集,计算量大,因为需要计算测试样本与所有训练样本的距离。
- (2)对于高维数据,距离度量可能变得不那么有意义,这就是所谓的“维度灾难”
- (3)需要选择合适的k值和距离度量,这可能需要一些实验和调整
- (4)如果k值取太小会导致噪声影响,k值为1是只会由与测试值最近的决定,k值取大了就会导致维度灾难,k值取值为训练特征总数时,就会导致有训练集中数量多的决定预测值
4 API
class sklearn.neighbors.KNeighborsClassifier(n_neighbors=5, algorithm=‘auto’)
参数:
(1)n_neighbors:
int, default=5, 默认情况下用于kneighbors查询的近邻数,就是K
(2)algorithm:
{‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’}, default=’auto’。找到近邻的方式,注意不是计算距离 的方式,与机器学习算法没有什么关系,开发中请使用默认值’auto’
方法:
(1) fit(x, y)
使用X作为训练数据和y作为目标数据
(2) predict(X) 预测提供的数据,得到预测数据
5 sklearn 实现KNN示例
用KNN算法对鸢尾花进行分类
# 引入KNN算法的库
from sklearn.neighbors import KNeighborsClassifier
# 引入鸢尾花数据集
from sklearn.datasets import load_iris
# 引入划分数据集库
from sklearn.model_selection import train_test_split
# 引入标准化库
from sklearn.preprocessing import StandardScaler# 获取鸢尾花数据集的特征值和目标值
x,y=load_iris(return_X_y=True)#return_X_y:表示只返回特征值和目标值
# 训练集划分
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,shuffle=True,random_state=22)
# 训练集和测试集标准化
scaler=StandardScaler()
x_train=scaler.fit_transform(x_train)#可以获取标准化后的的信息
x_test=scaler.transform(x_test)#使用x_trian的均值和方差
# 建立KNN算法模型
model=KNeighborsClassifier(n_neighbors=5)
# 模型训练
model.fit(x_train,y_train)
#模型评估
score=model.score(x_test,y_test)
print(score)
#模型预测
y_pred=model.predict(x_test)
print(y_pred)
print(y_test)
'''
0.9333333333333333
[0 2 1 2 1 1 1 1 1 0 2 1 2 2 0 2 1 1 1 1 0 2 0 1 2 0 2 2 2 2]
[0 2 1 2 1 1 1 2 1 0 2 1 2 2 0 2 1 1 2 1 0 2 0 1 2 0 2 2 2 2]
'''
#推理模型(生产)
x_new=[[5.1,2.5,4.4,1.3],[5,4.2,1.2,4.2],[2.3,4.5,1.2,3.2],[2.75,2.3,1.2,4.5]]
x_new=scaler.transform(x_new)
y_new=model.predict(x_new)
print(y_new)
# [1 2 0 2]
步骤:
- (1)加载数据集
- (2)划分数据集
- (3)数据集标准化
- (4)模型训练
- (5)模型预测与模型评估
- (6)推理模型(生产)
注意: - (1)一般对模型进行训练时都要现将数据集进行划分
- (2)进行标准化时训练集fit,transform,fit_transform都可以用,但测试集只能能用transform,原因是fit,fit_transform可以将进行标准化的数据的信息(如均值和方差)计算出来,而我们测试时使用的是训练的信息才能得到真实的值
6 模型保存与加载
import joblib
保存模型
joblib.dump(estimator, “my_ridge.pkl”)
加载模型
estimator = joblib.load(“my_ridge.pkl”)
#使用模型预测
y_test=estimator.predict([[0.4,0.2,0.4,0.7]])
print(y_test)
代码如下:
# 引入KNN算法的库
from sklearn.neighbors import KNeighborsClassifier
# 引入鸢尾花数据集
from sklearn.datasets import load_iris
# 引入划分数据集库
from sklearn.model_selection import train_test_split
# 引入标准化库
from sklearn.preprocessing import StandardScaler
import joblib
def train():# 获取鸢尾花数据集的特征值和目标值x,y=load_iris(return_X_y=True)#return_X_y:表示只返回特征值和目标值# 训练集划分x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,shuffle=True,random_state=22)# 训练集和测试集标准化scaler=StandardScaler()x_train=scaler.fit_transform(x_train)#可以获取标准化后的的信息x_test=scaler.transform(x_test)#使用x_trian的均值和方差# 建立KNN算法模型model=KNeighborsClassifier(n_neighbors=5)# 模型训练model.fit(x_train,y_train)#模型评估score=model.score(x_test,y_test)print(score)#模型预测y_pred=model.predict(x_test)print(y_pred)print(y_test)'''0.9333333333333333[0 2 1 2 1 1 1 1 1 0 2 1 2 2 0 2 1 1 1 1 0 2 0 1 2 0 2 2 2 2][0 2 1 2 1 1 1 2 1 0 2 1 2 2 0 2 1 1 2 1 0 2 0 1 2 0 2 2 2 2]'''# 模型保存joblib.dump(model,"./src/model/knn.pkl")joblib.dump(scaler,"./src/model/knn_scaler.pkl")def detect():#模型加载model=joblib.load("./src/model/knn.pkl")scaler=joblib.load("./src/model/knn_scaler.pkl")#推理模型(生产)x_new=[[5.1,2.5,4.4,1.3],[5,4.2,1.2,4.2],[2.3,4.5,1.2,3.2],[2.75,2.3,1.2,4.5]]x_new=scaler.transform(x_new)y_new=model.predict(x_new)print(y_new)# [1 2 0 2]
if __name__=="__main__":train()detect()
葡萄酒(load_wine)数据集KNN算法
(1)wine.feature_names:
[‘alcohol’, ‘malic_acid’, ‘ash’, ‘alcalinity_of_ash’, ‘magnesium’, ‘total_phenols’, ‘flavanoids’, ‘nonflavanoid_phenols’,‘proanthocyanins’, ‘color_intensity’, ‘hue’, ‘od280/od315_of_diluted_wines’, ‘proline’]
以下是这些葡萄酒相关术语的翻译及简要说明:
alcohol - 酒精(葡萄酒中的酒精含量)
malic_acid - 苹果酸(葡萄酒中的天然有机酸)
ash - 灰分(燃烧后残留的无机物含量)
alcalinity_of_ash - 灰分碱度(灰分的碱性程度)
magnesium - 镁(矿物质含量)
total_phenols - 总酚(影响风味和抗氧化性的化合物)
flavanoids - 黄酮类化合物(多酚类物质,与颜色和健康益处相关)
nonflavanoid_phenols - 非黄酮酚(其他酚类物质)
proanthocyanins - 原花青素(缩合单宁,影响口感)
color_intensity - 颜色强度(葡萄酒色泽的深浅)
hue - 色调(颜色的类型,如红/紫/棕等)
od280/od315_of_diluted_wines - 稀释葡萄酒的OD280/OD315值(紫外吸光度比值,反映酚类物质浓度)
proline - 脯氨酸(氨基酸,与葡萄酒的氮代谢相关)
(2)wine.target_names
[‘class_0’ ‘class_1’ ‘class_2’]
class_0
葡萄品种: Barbera(巴贝拉)
特点: 高酸度、低单宁,通常酿造果香浓郁的红葡萄酒。
class_1
葡萄品种: Barolo(巴罗洛,由 Nebbiolo 内比奥罗葡萄酿造)
特点: 高单宁、高酸度,酿造复杂、陈年潜力强的顶级红葡萄酒。
class_2
葡萄品种: Grignolino(格丽尼奥里诺)
特点: 轻酒体、高酸度,常酿造清新风格的红葡萄酒或桃红葡萄酒。
(3)KNN算法实现
# 引入KNN算法的库
from sklearn.neighbors import KNeighborsClassifier
# 引入葡萄酒数据集
from sklearn.datasets import load_wine
# 引入划分数据集库
from sklearn.model_selection import train_test_split
# 引入标准化库
from sklearn.preprocessing import StandardScaler
import joblib
def train():# wine=load_wine()x,y=load_wine(return_X_y=True)# print(x)print(x.shape)x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,shuffle=True,random_state=22)print(x_train.shape)scaler=StandardScaler()x_train=scaler.fit_transform(x_train)x_test=scaler.transform(x_test)model=KNeighborsClassifier(n_neighbors=5)model.fit(x_train,y_train)y_pred=model.predict(x_test)print(y_pred)score=model.score(x_test,y_test)print(score)'''[1 2 2 2 0 1 0 1 2 1 1 1 0 0 2 0 0 0 2 2 0 1 2 1 1 2 0 1 2 2 1 1 2 1 0 2]
0.9166666666666666'''joblib.dump(model,"./src/model/knn_wine_model.pkl")joblib.dump(scaler,"./src/model/knn_wine_scaler.pkl")
def detect():model=joblib.load("./src/model/knn_wine_model.pkl")scaler=joblib.load("./src/model/knn_wine_scaler.pkl")x_new=[[1.2,4.5,2.3,1.2,2.3,2.6,1.2,0.3,0.2,0.5,1.2,1.4,2.3]]x_new=scaler.transform(x_new)y_new=model.predict(x_new)print(y_new)#[1]if __name__=="__main__":train()detect()