大型语言模型中的QKV与多头注意力机制解析
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/

【工程师视角下的大模型核心机制拆解:QKV 与多头注意力 (QKV and Multi-head Attention in LLM from an Enginee】
https://www.bilibili.com/video/BV1dAJPzvEW5/
在自然语言处理(NLP)领域,大型语言模型(LLM),如GPT-3和BERT,彻底改变了机器理解和生成自然语言的方式。而这些模型的核心机制中,QKV(Query、Key、Value)和多头注意力机制(Multi-Head Attention)起着关键作用。起初,这一机制显得晦涩难懂,有研究者甚至花费数周时间才逐渐弄清其运作原理。
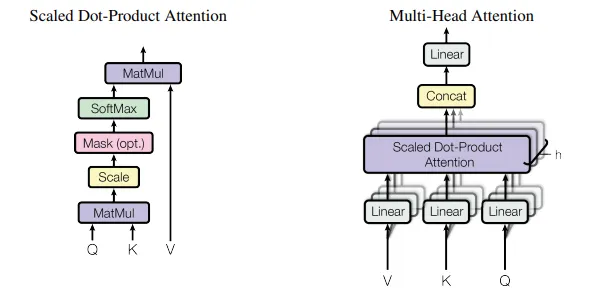
在原始论文中,对QKV机制的解释如下:
Query(查询向量):
表示模型当前关注的元素。在一个序列中,Query就像是在针对某个具体元素发出的“问题”。
Key(键向量):
表示序列中所有可能被模型关注的元素。Query会与所有的Key进行对比,以判断该关注哪些部分、关注的程度如何。
Value(值向量):
每个Key对应一个Value。一旦确定了哪些Key比较重要(基于Query计算),其对应的Value将被用于构建最终输出。
虽然理论解释如此,但实际理解起来仍不容易。以下是一个直观的例子。
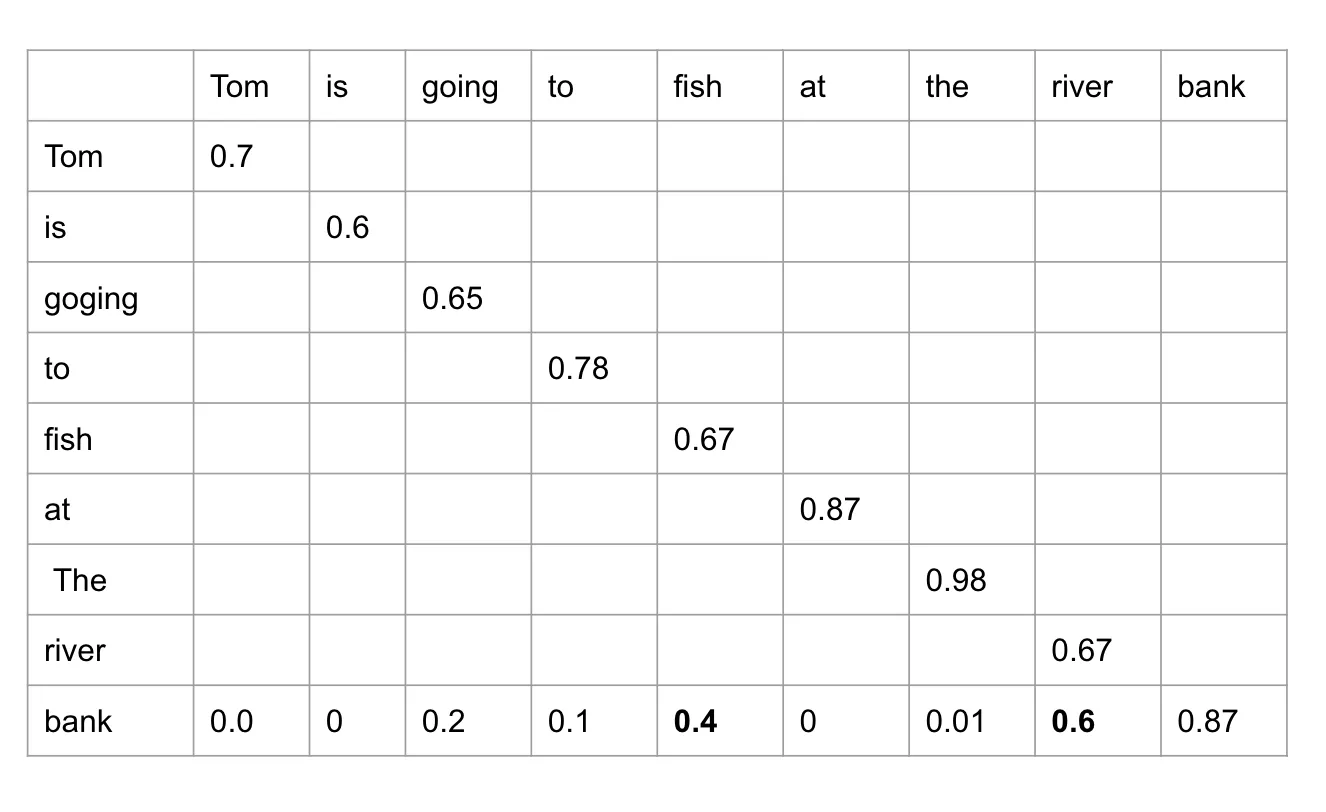
例如,一句简单的英文句子:“Tom is going to fish at the river bank.”
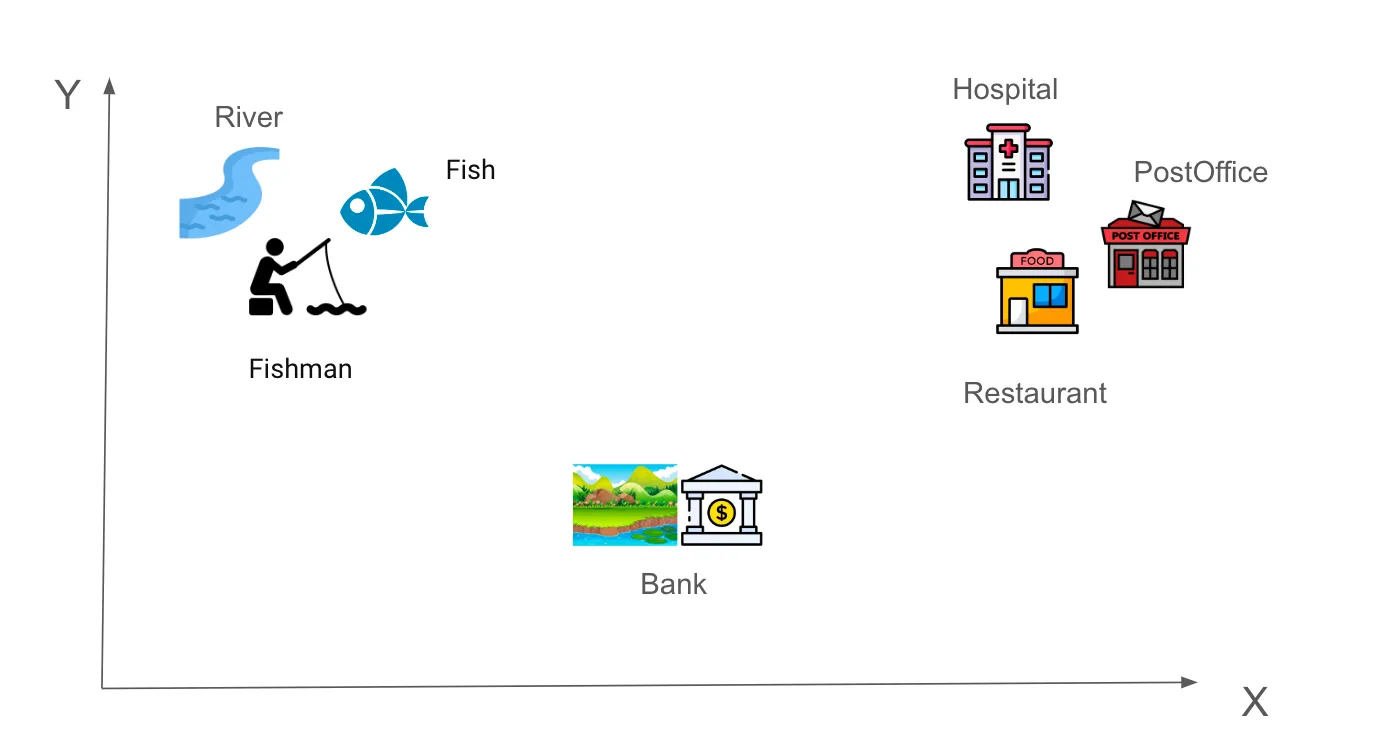
人类能够轻松理解这句话。但为了让计算机理解,我们需要先将句子中的每个单词转换成数字向量,这就是所谓的词嵌入(Word Embedding)。假设使用一个六维空间表示词向量,“River”这个词的嵌入向量可能是 [-0.9, 0.9, -0.2, 0.4, 0.2, 0.6]。在嵌入空间中,相似的词彼此靠近。比如:
-
第一组:River, Fish, Fisherman
-
第二组:Hospital, PostOffice, Restaurant
有趣的是,像“Bank”这样的多义词,其含义依赖于语境——需要判断它应该更接近哪一组。
回到原句:
“Tom is going to fish at the river bank.”
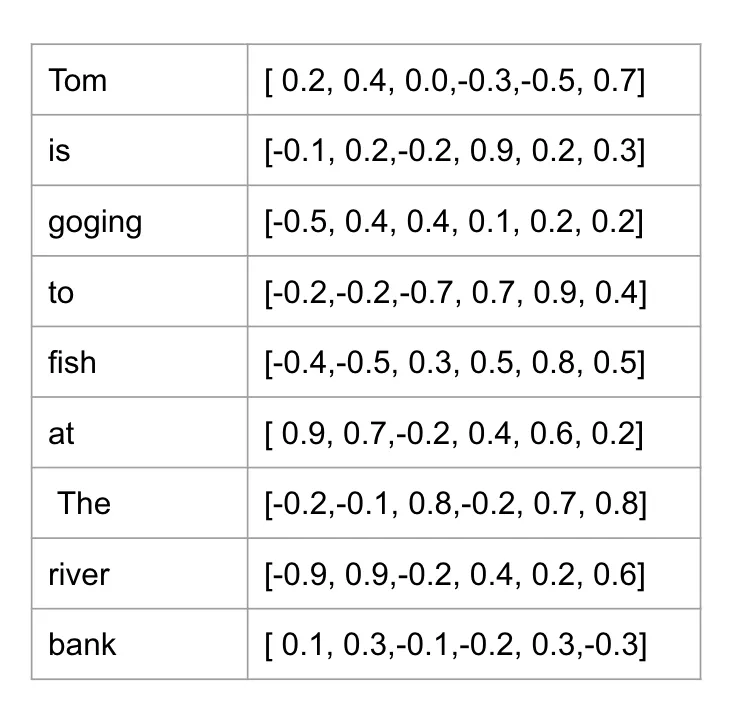
人们自然能判断出“bank”在这里不是提款的地方。为何能这样理解?这是因为“River”和“Fish”这两个词在语境中提供了更强的语义线索。它们在理解“bank”的含义时起到更重要作用,因此应给予更高的注意力权重,与“bank”的语义更加接近。
那么,计算机又如何判断该更关注“River”和“Fish”,而非其他词呢?这正是Q(Query)和K(Key)登场的地方。它们是两个线性变换,用于回答一个核心问题:在一个句子中,词与词之间的相似度如何?
首先,Q和K的输入是相同的词嵌入(此处暂不考虑位置嵌入)。以六维向量表示词嵌入为例:
将输入词嵌入分别进行Q和K的线性变换,然后计算Query与所有Key之间的点积(MatMul),接着进行缩放(Scale)、掩码(Mask)和SoftMax归一化,最终得到各个词的注意力权重。这些权重随后再与V(Value)向量进行点积,从而得到输出向量。最终的输出是各个Value的加权和,而权重则是由Key与Query之间的匹配程度决定的。

因此,这个新生成的向量在语义上比原始的词嵌入更能捕捉上下文间的联系。
举例来说,模型可能会对“bank”与“river”、“fish”的组合给出更高的注意力权重。这意味着模型在构建“bank”的输出时,会更多地参考这些相关词。
那么,为什么非得经历QKV这一套复杂的转化过程呢?
这可以类比于人类对图像的感知。如果让人描述一幅画面,大脑并不会从左上角逐像素扫描,而是立刻将注意力集中在最突出的物体上,例如画面中的一个小男孩。这种处理方式高效而精准,正体现了“注意力机制”的威力。

如果将QKV看作是一组三个线性映射,即一个“注意力头”(Attention Head),那么**多头注意力机制(Multi-Head Attention)**就是拥有多组QKV,并将它们的输出拼接起来。其优势在于能从不同角度捕捉相似性信息。例如,一个头可以专注于相邻的名词关系,另一个头则可能关注动词与宾语之间的联系。回到图像类比,一个“头”可能识别出画面中的男孩,另一个则聚焦于他手中的球。
以上是一种对QKV与多头注意力机制的直观解释。至于更为严谨的数学推导,可参考原始论文《Attention Is All You Need》。在深入学习的过程中,许多技术细节将逐渐变得清晰而有趣。