25、DeepSeek-R1论文笔记
DeepSeek-R1论文笔记
- 1、研究背景与核心目标
- 2、核心模型与技术路线
- 3、蒸馏技术与小模型优化
- 4、训练过程简介
- 5、COT思维链(Chain of Thought)
- 6、强化学习算法(GRPO)
- 7、冷启动
- **1. 冷启动的目的**
- **2. 冷启动的实现步骤**
- **3. 冷启动的作用**
- **典型应用场景**
- 汇总
- 一、核心模型与技术路线
- 二、蒸馏技术与小模型优化
- 三、实验与性能对比
- 四、研究贡献与开源
- 五、局限与未来方向
- 关键问题
- 1. **DeepSeek-R1与DeepSeek-R1-Zero的核心区别是什么?**
- 2. **蒸馏技术在DeepSeek-R1研究中的核心价值是什么?**
- 3. **DeepSeek-R1在数学推理任务上的性能如何超越同类模型?**
DeepSeek-R1
• 标题:DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
• 时间:2025年1月
• 链接:arXiv:2501.12948
• 突破:基于DeepSeek-V3-Base,通过多阶段强化学习训练(RL)显著提升逻辑推理能力,支持思维链(CoT)和过程透明化输出。
1、研究背景与核心目标
-
大语言模型的推理能力提升
近年来,LLM在推理任务上的性能提升显著,OpenAI的o1系列通过思维链(CoT)扩展实现了数学、编码等任务的突破,但如何通过高效方法激发模型的推理能力仍需探索。- 传统方法依赖大量监督数据,而本文探索**纯强化学习(RL)**路径,无需监督微调(SFT)即可提升推理能力。
-
核心目标
- 验证纯RL能否驱动LLM自然涌现推理能力(如自我验证、长链推理)。
- 解决纯RL模型的局限性(如语言混合、可读性差),通过多阶段训练提升实用性。
- 将大模型推理能力迁移至小模型,推动模型轻量化。
2、核心模型与技术路线
-
DeepSeek-R1-Zero
- 纯强化学习训练:基于DeepSeek-V3-Base,使用GRPO算法,无监督微调(SFT),通过规则奖励(准确性+格式)引导推理过程。
- 能力涌现:自然发展出自我验证、反思、长链推理(CoT)等行为,AIME 2024 Pass@1从15.6%提升至71.0%,多数投票达86.7%,接近OpenAI-o1-0912。
- 局限性:语言混合、可读性差,需进一步优化。
-
DeepSeek-R1
- 多阶段训练:
- 冷启动阶段:使用数千条长CoT数据微调,提升可读性和初始推理能力。
- 推理导向RL:引入语言一致性奖励,解决语言混合问题。
- 拒绝采样与SFT:收集60万推理数据+20万非推理数据(写作、事实QA等),优化通用能力。
- 全场景RL:结合规则奖励(推理任务)和神经奖励(通用任务),对齐人类偏好。
- 性能突破:AIME 2024 Pass@1 79.8%(超越o1-1217的79.2%),MATH-500 97.3%(对标o1-1217的96.4%),Codeforces评级2029(超越96.3%人类选手)。
- 多阶段训练:
3、蒸馏技术与小模型优化
- 蒸馏策略:以DeepSeek-R1为教师模型,生成80万训练数据,微调Qwen和Llama系列模型,仅用SFT阶段(无RL)。
- 关键成果:
- 14B蒸馏模型:AIME 2024 Pass@1 69.7%,远超QwQ-32B-Preview的50.0%。
- 32B/70B模型:MATH-500 94.3%、LiveCodeBench 57.2%,刷新密集模型推理性能纪录。
4、训练过程简介
zero:cot+grpo
R1:冷启动+cot+grpo


5、COT思维链(Chain of Thought)
COT详细原理参考:CoT论文笔记
2022 年 Google 论文《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》中首次提出,通过让大模型逐步参与将一个复杂问题分解为一步一步的子问题并依次进行求解的过程可以显著提升大模型的性能。而这些推理的中间步骤就被称为思维链(Chain of Thought)。
思维链提示(CoT Prompting),在少样本提示中加入自然语言推理步骤(如“先计算…再相加…”),将问题分解为中间步骤,引导模型生成连贯推理路径。
-
示例:标准提示仅给“问题-答案”,思维链提示增加“问题-推理步骤-答案”(如)。
-
区别于传统的 Prompt 从输入直接到输出的映射 <input——>output> 的方式,CoT 完成了从输入到思维链再到输出的映射,即 <input——>reasoning chain——>output>。如果将使用 CoT 的 Prompt 进行分解,可以更加详细的观察到 CoT 的工作流程。
-
示例对比(传统 vs. CoT)
-
传统提示
问题:1个书架有3层,每层放5本书,共有多少本书? 答案:15本 -
CoT 提示
问题:1个书架有3层,每层放5本书,共有多少本书? 推理: 1. 每层5本书,3层的总书数 = 5 × 3 2. 5 × 3 = 15 答案:15本
-
关键类型
-
零样本思维链(Zero-Shot CoT)
无需示例,仅通过提示词(如“请分步骤思考”)触发模型生成思维链。适用于快速引导模型进行推理。 -
少样本思维链(Few-Shot CoT)
提供少量带思维链的示例,让模型模仿示例结构进行推理。例如,先给出几个问题及其分解步骤,再让模型处理新问题。

如图所示,一个完整的包含 CoT 的 Prompt 往往由指令(Instruction),逻辑依据(Rationale),示例(Exemplars)三部分组成。一般而言指令用于描述问题并且告知大模型的输出格式,逻辑依据即指 CoT 的中间推理过程,可以包含问题的解决方案、中间推理步骤以及与问题相关的任何外部知识,而示例则指以少样本的方式为大模型提供输入输出对的基本格式,每一个示例都包含:问题,推理过程与答案。
以是否包含示例为区分,可以将 CoT 分为 Zero-Shot-CoT 与 Few-Shot-CoT,在上图中,Zero-Shot-CoT 不添加示例而仅仅在指令中添加一行经典的“Let’s think step by step”,就可以“唤醒”大模型的推理能力。而 Few-Shot-Cot 则在示例中详细描述了“解题步骤”,让大模型照猫画虎得到推理能力。
提示词工程框架( 链式提示Chain):其他提示词工程框架,思维链CoT主要是线性的,多个推理步骤连成一个链条。在思维链基础上,又衍生出ToT、GoT、PoT等多种推理模式。这些和CoT一样都属于提示词工程的范畴。CoT、ToT、GoT、PoT等提示词工程框架大幅提升了大模型的推理能力,让我们能够使用大模型解决更多复杂问题,提升了大模型的可解释性和可控性,为大模型应用的拓展奠定了基础。
参考:
https://blog.csdn.net/kaka0722ww/article/details/147950677
https://www.zhihu.com/tardis/zm/art/670907685?source_id=1005
6、强化学习算法(GRPO)
详细GRPO原理参考:DeepSeekMath论文笔记
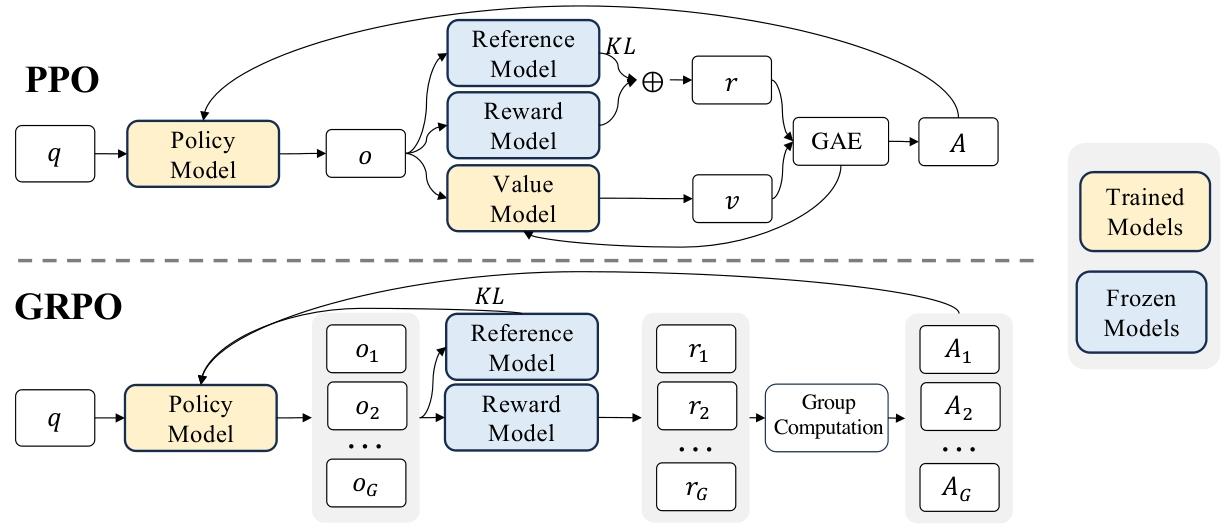
2.2.1 强化学习算法
群组相对策略优化 为降低强化学习的训练成本,我们采用群组相对策略优化(GRPO)算法(Shao等人,2024)。该算法无需与策略模型规模相当的评论家模型,而是通过群组分数估计基线。具体来说,对于每个问题𝑞,GRPO从旧策略𝜋𝜃𝑜𝑙𝑑中采样一组输出{𝑜1, 𝑜2, · · · , 𝑜𝐺},然后通过最大化以下目标函数优化策略模型𝜋𝜃:
J GRPO ( θ ) = E [ q ∼ P ( Q ) , { o i } i = 1 G ∼ π θ old ( O ∣ q ) ] 1 G ∑ i = 1 G ( min ( π θ ( o i ∣ q ) π θ old ( o i ∣ q ) A i , clip ( π θ ( o i ∣ q ) π θ old ( o i ∣ q ) , 1 − ε , 1 + ε ) A i ) − β D KL ( π θ ∣ ∣ π ref ) ) , ( 1 ) J_{\text{GRPO}}(\theta) = \mathbb{E}\left[ q \sim P(Q), \{o_i\}_{i=1}^G \sim \pi_{\theta^{\text{old}}}(O|q) \right] \frac{1}{G} \sum_{i=1}^G \left( \min\left( \frac{\pi_\theta(o_i|q)}{\pi_{\theta^{\text{old}}}(o_i|q)} A_i, \text{clip}\left( \frac{\pi_\theta(o_i|q)}{\pi_{\theta^{\text{old}}}(o_i|q)}, 1 - \varepsilon, 1 + \varepsilon \right) A_i \right) - \beta D_{\text{KL}}(\pi_\theta || \pi_{\text{ref}}) \right), \quad (1) JGRPO(θ)=E[q∼P(Q),{oi}i=1G∼πθold(O∣q)]G1i=1∑G(min(πθold(oi∣q)πθ(oi∣q)Ai,clip(πθold(oi∣q)πθ(oi∣q),1−ε,1+ε)Ai)−βDKL(πθ∣∣πref)),(1)
D KL ( π θ ∣ ∣ π ref ) = π ref ( o i ∣ q ) ( π θ ( o i ∣ q ) π ref ( o i ∣ q ) − log π θ ( o i ∣ q ) π ref ( o i ∣ q ) − 1 ) , ( 2 ) D_{\text{KL}}(\pi_\theta || \pi_{\text{ref}}) = \pi_{\text{ref}}(o_i|q) \left( \frac{\pi_\theta(o_i|q)}{\pi_{\text{ref}}(o_i|q)} - \log \frac{\pi_\theta(o_i|q)}{\pi_{\text{ref}}(o_i|q)} - 1 \right), \quad (2) DKL(πθ∣∣πref)=πref(oi∣q)(πref(oi∣q)πθ(oi∣q)−logπref(oi∣q)πθ(oi∣q)−1),(2)
其中,𝜀和𝛽为超参数,𝐴𝑖为优势函数,通过每组输出对应的奖励集合{𝑟1, 𝑟2, . . . , 𝑟𝐺}计算得到:
A i = r i − mean ( { r 1 , r 2 , ⋅ ⋅ ⋅ , r G } ) std ( { r 1 , r 2 , ⋅ ⋅ ⋅ , r G } ) . ( 3 ) A_i = \frac{r_i - \text{mean}(\{r_1, r_2, · · · , r_G\})}{\text{std}(\{r_1, r_2, · · · , r_G\})}. \quad (3) Ai=std({r1,r2,⋅⋅⋅,rG})ri−mean({r1,r2,⋅⋅⋅,rG}).(3)


7、冷启动


冷启动(Cold Start)
在DeepSeek-R1的训练流程中,冷启动是一个关键阶段,旨在通过少量高质量数据为模型提供初步的推理能力,为后续强化学习(RL)奠定基础。以下是其核心内容:
AI 冷启动是指人工智能系统在初始阶段因缺乏足够数据或历史信息导致的性能瓶颈问题,常见于推荐系统、大模型训练、提示词优化等场景。以下是基于多领域研究的综合解析:
AI模型训练的冷启动问题
-
数据匮乏的挑战
• 问题:模型初期因数据不足导致推理能力弱,生成结果混乱或重复。
• 解决方案:
• 冷启动数据(Cold-start Data):
◦ 高质量微调:用少量人工筛选的推理数据(如数学题详细步骤)对模型进行初步训练,提供“入门指南”。
◦ 数据来源:从大型模型生成(如ChatGPT)、现有模型输出筛选、人工优化等方式获取。 -
多阶段训练策略
• 阶段1:冷启动微调:用冷启动数据优化模型基础推理能力,提升生成结果的可读性和逻辑性。
• 阶段2:强化学习(RL):通过奖励机制(如答案准确度、格式规范性)动态调整模型参数,优化推理策略。
• 阶段3:多场景优化:结合拒绝采样(筛选高质量输出)和监督微调(SFT),扩展模型在专业领域(如金融、医学)的适用性。
三、提示词与上下文冷启动
-
提示词冷启动策略
• 知识初始化:利用领域知识库初始化模型参数,指导模型生成更符合任务需求的回答。
• 动态调整:根据模型表现实时调整学习率和任务权重,例如在复杂任务中增加上下文信息权重。 -
上下文信息利用
• 时间/场景适配:结合用户当前环境(如工作日早晨推荐新闻,周末推荐娱乐内容)提升推荐相关性。
• 多模态数据融合:整合文本、图像、社交网络等多源数据,丰富冷启动阶段的特征提取。
1. 冷启动的目的
• 解决DeepSeek-R1-Zero的局限性:
直接从基础模型启动RL(如DeepSeek-R1-Zero)会导致生成内容可读性差、语言混杂(如中英文混合)。
• 引导模型生成结构化推理链:
通过冷启动数据,教会模型以“思考过程→答案”的格式输出,提升可读性和逻辑性。
2. 冷启动的实现步骤
(1) 数据收集
• 来源:
• 模型生成:用基础模型(DeepSeek-V3-Base)通过few-shot提示生成长链推理(CoT)数据。
• 人工修正:对模型生成的答案进行筛选和润色,确保可读性。
• 外部数据:少量开源数学、编程问题的高质量解答。
• 格式要求:
强制要求模型将推理过程放在<reasoning>标签内,答案放在<answer>标签内,例如:
<reasoning>设方程√(a−√(a+x))=x,首先平方两边...</reasoning>
<answer>\boxed{2a-1}</answer>
(2) 监督微调(SFT)
• 数据规模:数千条(远少于传统SFT的百万级数据)。
• 训练目标:让模型学会:
• 生成清晰的推理步骤。
• 遵守指定输出格式。
• 避免语言混杂(如中英文混合)。
3. 冷启动的作用
• 提升可读性:
通过结构化标签和人工修正,生成内容更符合人类阅读习惯。
• 加速RL收敛:
冷启动后的模型已具备基础推理能力,RL阶段更易优化策略。
• 缓解语言混合问题:
强制输出格式和语言一致性奖励(如中文或英文占比)减少混杂。
典型应用场景
-
推荐系统
- 新用户注册时,通过引导式问卷(主动学习)或热门内容(规则策略)完成冷启动,随后逐步切换至个性化推荐。
- 案例:TikTok对新用户先推送泛领域热门视频,再根据前几个视频的互动数据快速建模兴趣标签。
-
自然语言处理(NLP)
- 新领域对话系统冷启动:用预训练语言模型(如LLaMA)结合少量领域数据微调,快速适应垂直场景(如法律咨询、金融客服)。
-
计算机视觉(CV)
- 新类别图像识别:通过迁移学习加载ImageNet预训练模型,再用少量新类别样本微调,解决“新物体冷启动”问题。
-
医疗AI
- 罕见病诊断冷启动:利用元学习快速适配新病例,或通过合成医学影像数据增强模型泛化能力。
汇总
一、核心模型与技术路线
-
DeepSeek-R1-Zero
- 纯强化学习训练:基于DeepSeek-V3-Base,使用GRPO算法,无监督微调(SFT),通过规则奖励(准确性+格式)引导推理过程。
- 能力涌现:自然发展出自我验证、反思、长链推理(CoT)等行为,AIME 2024 Pass@1从15.6%提升至71.0%,多数投票达86.7%,接近OpenAI-o1-0912。
- 局限性:语言混合、可读性差,需进一步优化。
-
DeepSeek-R1
- 多阶段训练:
- 冷启动阶段:使用数千条长CoT数据微调,提升可读性和初始推理能力。
- 推理导向RL:引入语言一致性奖励,解决语言混合问题。
- 拒绝采样与SFT:收集60万推理数据+20万非推理数据(写作、事实QA等),优化通用能力。
- 全场景RL:结合规则奖励(推理任务)和神经奖励(通用任务),对齐人类偏好。
- 性能突破:AIME 2024 Pass@1 79.8%(超越o1-1217的79.2%),MATH-500 97.3%(对标o1-1217的96.4%),Codeforces评级2029(超越96.3%人类选手)。
- 多阶段训练:
二、蒸馏技术与小模型优化
- 蒸馏策略:以DeepSeek-R1为教师模型,生成80万训练数据,微调Qwen和Llama系列模型,仅用SFT阶段(无RL)。
- 关键成果:
- 14B蒸馏模型:AIME 2024 Pass@1 69.7%,远超QwQ-32B-Preview的50.0%。
- 32B/70B模型:MATH-500 94.3%、LiveCodeBench 57.2%,刷新密集模型推理性能纪录。
三、实验与性能对比
| 任务/模型 | DeepSeek-R1 | OpenAI-o1-1217 | DeepSeek-R1-Zero | DeepSeek-V3 |
|---|---|---|---|---|
| AIME 2024 (Pass@1) | 79.8% | 79.2% | 71.0% | 39.2% |
| MATH-500 (Pass@1) | 97.3% | 96.4% | 86.7% | 90.2% |
| Codeforces (评级) | 2029 | - | 1444 | 1134 |
| MMLU (Pass@1) | 90.8% | 91.8% | - | 88.5% |
四、研究贡献与开源
- 方法论创新:
- 首次证明纯RL可激发LLM推理能力,无需监督微调(SFT)。
- 提出“冷启动数据+多阶段RL”框架,平衡推理能力与用户友好性。
- 开源资源:
- 开放DeepSeek-R1/Zero及6个蒸馏模型(1.5B、7B、8B、14B、32B、70B),基于Qwen和Llama。
五、局限与未来方向
- 当前局限:
- 语言混合问题(中英文混杂),多语言支持不足。
- 工程任务(如代码生成)数据有限,性能待提升。
- 对提示格式敏感,少样本提示可能降低性能。
- 未来方向:
- 探索长CoT在函数调用、多轮对话中的应用。
- 优化多语言一致性,解决非中英查询的推理语言偏好问题。
- 引入异步评估,提升软件任务的RL训练效率。
关键问题
1. DeepSeek-R1与DeepSeek-R1-Zero的核心区别是什么?
答案:DeepSeek-R1-Zero采用纯强化学习训练,无需监督微调(SFT),依赖规则奖励自然涌现推理能力,但存在语言混合和可读性问题;DeepSeek-R1在此基础上引入冷启动数据(数千条长CoT示例)进行初始微调,并通过多阶段训练(SFT+RL交替)优化可读性、语言一致性和通用能力,最终性能更接近OpenAI-o1-1217。
2. 蒸馏技术在DeepSeek-R1研究中的核心价值是什么?
答案:蒸馏技术将大模型的推理模式迁移至小模型,使小模型在保持高效的同时获得强大推理能力。例如,DeepSeek-R1-Distill-Qwen-14B在AIME 2024上的Pass@1为69.7%,远超同规模的QwQ-32B-Preview(50.0%);32B蒸馏模型在MATH-500上达94.3%,接近o1-mini的90.0%。该技术证明大模型推理模式对小模型优化至关重要,且蒸馏比直接对小模型进行RL更高效经济。
3. DeepSeek-R1在数学推理任务上的性能如何超越同类模型?
答案:DeepSeek-R1在AIME 2024上的Pass@1为79.8%,略超OpenAI-o1-1217的79.2%;MATH-500达97.3%,与o1-1217持平(96.4%)。其优势源于强化学习对长链推理的优化(如自动扩展思考步骤、自我验证),以及冷启动数据和多阶段训练对推理过程可读性和准确性的提升。此外,规则奖励模型确保了数学问题答案的格式正确性(如公式框输出),减少了因格式错误导致的失分。