Python爬虫之路(14)--playwright浏览器自动化
playwright
前言
你有没有在用 Selenium 抓网页的时候,体验过那种「明明点了按钮,它却装死不动」的痛苦?或者那种「刚加载完页面,它又刷新了」的抓狂?别担心,你不是一个人——那是 Selenium 在和现代前端技术硬刚,结果被 JS 动态渲染按在地上摩擦。
于是,我转身投入了 Playwright 的怀抱。
这个由微软亲儿子团队打造的自动化框架,一上来就自带“全家桶”:Chromium、Firefox、WebKit 全支持,还能像忍者一样拦截请求、伪装自己、模拟手机、欺骗验证码……你说你是网站的反爬系统?对不起,它已经绕过你了。
更重要的是:Playwright 不用我一边调试一边祈祷“这个元素会不会加载出来”,它会耐心地等着网页准备好,就像个懂事的小助手。
所以,如果你发现我全程没提 Selenium,那不是我忘了它,而是……我只是选择了更适合现代网页的那一位。
palywright(python)官网
playwright 中文文档
一. Playwright 的特点
- Playwright 支持当前所有主流浏览器,包括 Chrome 和 Edge(基于 Chromium)、Firefox、Safari(基于 WebKit) ,提供完善的自动化控制的 API。
- Playwright 支持移动端页面测试,使用设备模拟技术可以使我们在移动 Web 浏览器中测试响应式 Web 应用程序。
- Playwright 支持所有浏览器的 Headless 模式和非 Headless 模式的测试。
- Playwright 的安装和配置非常简单,安装过程中会自动安装对应的浏览器和驱动,不需要额外配置 WebDriver 等。
- Playwright 提供了自动等待相关的 API,当页面加载的时候会自动等待对应的节点加载,大大简化了 API 编写复杂度。
本节我们就来了解下 Playwright 的使用方法。
二.Playwright 与selemium的区别
自动化多浏览器更强
- Playwright 原生支持 Chromium、Firefox、WebKit(Safari 内核);
- Selenium 也支持多浏览器,但配置复杂、兼容性差一些。并且在配置内核时容易出现浏览器自动升级内核导致与selemium不适配无法正常启动项目。
对现代网页支持更好
- Playwright 更好地处理 单页应用(SPA)、动态加载内容(JS 渲染);
- 它可以自动等待页面元素、网络请求完成,避免使用
sleep等土办法。
操作简单、等待机制智能
- Playwright 的
waitForSelector和自动等待机制,能自动识别页面何时准备好; - Selenium 中常常需要显式
WebDriverWait,操作相对繁琐。
更原生地控制浏览器行为
-
可以拦截请求、修改请求/响应、模拟网络环境等:
await page.route("**/*", lambda route: route.abort()) -
在绕过反爬机制时非常有用(如移除监控脚本、模拟慢速网络等)。
支持无头/有头模式灵活切换
- Playwright 在无头和有头模式之间切换非常平滑,而且在无头模式下表现更稳定;
- Selenium 的无头模式在某些浏览器上可能会出现差异行为。
更强的并发与多页面控制
- 支持多标签页、多浏览器上下文并发,适合大规模数据抓取;
- 对资源隔离也更好(cookie/session 等可分开)。
API 更现代化、开发体验更好
- Playwright 的异步接口更符合现代 Python(或 JS/TS)开发习惯;
- 文档清晰、内置调试功能更丰富(如
codegen工具)。
Selenium 仍有的一些优势
- 社区老牌、生态大,很多成熟的库依赖它;
- 如果目标网站是老旧结构(非 SPA),Selenium 依然非常够用;
- Java 生态用户更多(Selenium 是最早就支持 Java 的);
总结一句话
Playwright 更适合现代网页、动态内容丰富的爬虫项目;而 Selenium 则更适合传统页面、对稳定性要求更高的老项目。
三. 安装依赖
要使用 Playwright,需要 Python 3.7 版本及以上,请确保 Python 的版本符合要求。
要安装 Playwright,可以直接使用 pip3,命令如下:
pip3 install playwright
安装完成之后需要进行一些初始化操作:
playwright install
这时候 Playwrigth 会安装 Chromium, Firefox and WebKit 浏览器并配置一些驱动,我们不必关心中间配置的过程,Playwright 会为我们配置好。
四.基础使用
1)playwright启动
palywright的使用方法有两种,一种是同步模式,一种是异步模式
- 同步模式(
sync_api):一步一步来,像早期排队买奶茶,前一个的奶茶没做完,下一个不能开始点单。 - 异步模式(
async_api):一边下单,一边刷抖音,等奶茶好了系统通知你。
同步版本(sync_playwright串行执行)
from playwright.sync_api import sync_playwrightdef get_title_sync(urls):with sync_playwright() as p:browser = p.chromium.launch(headless=True)page = browser.new_page()for url in urls:page.goto(url)print(f"{url} -> {page.title()}")browser.close()urls = ["https://www.baidu.com", "https://www.bing.com", "https://www.sougou.com"]
get_title_sync(urls)
特点:
- 一个页面加载完、取完标题后,才处理下一个;
- 多个页面加载时间相加,比较慢;
- 简单易懂,但效率低。
异步方式(async_playwright并发执行)
import asyncio
from playwright.async_api import async_playwrightasync def get_title(page, url):await page.goto(url)title = await page.title()print(f"{url} -> {title}")async def main():async with async_playwright() as p:browser = await p.chromium.launch(headless=True)context = await browser.new_context()urls = ["https://www.baidu.com", "https://www.bing.com", "https://www.sougou.com"]pages = [await context.new_page() for _ in urls]# 同时并发访问所有页面tasks = [get_title(page, url) for page, url in zip(pages, urls)]await asyncio.gather(*tasks)await browser.close()asyncio.run(main())
特点:
- 所有网页同时打开并加载标题;
- 利用异步 + 并发,速度飞快;
- 对于大型爬虫任务,效率提升非常明显。
对比结果
同步版本大概是:
百度 -> 用时 2 秒
Bing -> 用时 2 秒
sougou -> 用时 2 秒
总计约 6 秒
而异步版本是:
百度/Bing/sougou 几乎同时完成
总计约 2 秒
适用场景对比
| 特性 | 同步 Playwright | 异步 Playwright |
|---|---|---|
| 上手难度 | ✅ 简单 | ❗ 稍复杂 |
| 并发能力 | ❌ 差 | ✅ 优秀 |
| 写法风格 | 传统脚本风格 | 现代异步协程风格 |
| 推荐使用场景 | 小型任务、调试、单页面操作 | 大规模抓取、多个任务并发执行 |
2)browser、context、page的联系
在上面的演示示例中出现了browser,context,page。本小节将先讲解三者的联系。
| 对象 | 简介 |
|---|---|
browser | 启动的浏览器实例(比如打开了一个 Chrome) |
context | 类似于一个独立的「浏览器用户配置环境」,有独立的 cookie、session 等 |
page | 一个具体的标签页/网页 |
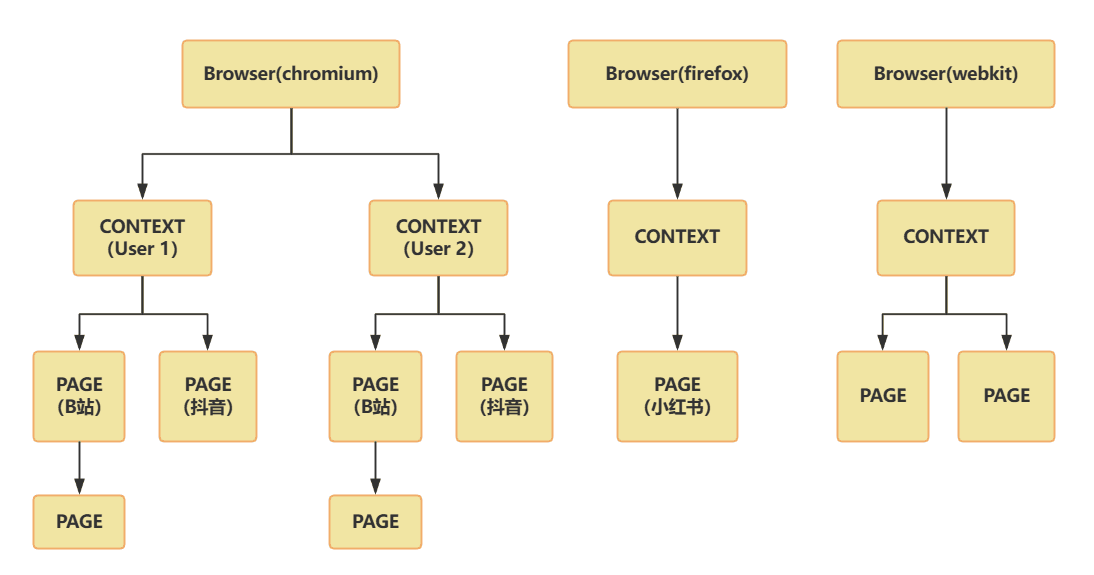
三者的层级关系(图解式)
Browser(浏览器)
└── Context(浏览器上下文 / 用户环境)├── Page(标签页 / 页面)└── Page
你可以有:
- 一个
browser启动多个context - 每个
context打开多个page
类比一下:浏览器、用户、标签页
| Playwright 对象 | 类比 | 说明 |
|---|---|---|
browser | 整个浏览器程序 | 比如你打开了 Chrome 浏览器 |
context | 一个浏览器用户 | 你在 Chrome 里登录了不同账户(环境独立) |
page | 一个标签页 | 每个页面就是你开的一个 tab(百度首页,B站首页…) |
实战中举个例子
import asyncio
from playwright.async_api import async_playwright
async def main():async with async_playwright() as p:browser = await p.chromium.launch(headless=True)context = await browser.new_context()page = await context.new_page()await page.goto("https://baidu.com")title = await page.title()print(title)
asyncio.run(main())
解释:
browser:你打开了一个新的浏览器(比如 Chromium);context:你创建了一个「用户环境」,相当于一个新的匿名窗口;page:你在这个窗口中打开了一个标签页,加载了页面。
为什么要用 context?
因为它带来更好的隔离性和模拟多个用户的能力!
比如:
- 模拟多个用户登录不同账户 → 每个用户一个
context - 多线程爬虫时不想 cookie/session 冲突 → 每个线程独立开
context - 防止共享本地存储/缓存 →
context是清洁的小环境
进阶场景
比如爬虫时这样用:
for user in users:context = await browser.new_context(storage_state=user["cookies"])page = await context.new_page()await page.goto("https://target.com/profile")
这样就能并行模拟多个用户(B站的用户1,B站的用户2…不会因为用户2的登陆导致用户1的相关信息被覆盖或丢失),互不干扰、效率超高!
3)基础使用
1.创建浏览器对象
-
同步模式
# Can be "msedge", "chrome-beta", "msedge-beta", "msedge-dev", etc. browser = playwright.chromium.launch(channel="chrome",headless=True)from playwright.sync_api import sync_playwrightwith sync_playwright() as p:for browser in [p.chromium, p.firefox, p.webkit]:browser = browser.launch(headless=False)page = browser.new_page()page.goto('https://www.baidu.com')page.screenshot(path=f'screenshot-{browser.name}.png')print(page.title())browser.close() -
异步模式
# 异步 # Can be "msedge", "chrome-beta", "msedge-beta", "msedge-dev", etc. browser = await playwright.chromium.launch(channel="chrome",headless=True)import asyncio from playwright.async_api import async_playwrightasync def get_title(page, url):try:await page.goto(url)title = await page.title()print(f"url: {url} -> {title}")except Exception as e:print(f"Error fetching {url}: {e}")async def main():async with async_playwright() as p:# 启动三种浏览器内核browsers = [await p.chromium.launch(headless=True),await p.firefox.launch(headless=True),await p.webkit.launch(headless=True)]# 为每个浏览器创建独立上下文和页面contexts = [await browser.new_context() for browser in browsers]pages = [await context.new_page() for context in contexts]# 设置 URLurl = "http://www.baidu.com"# 为每个页面分配任务(同一个 URL)tasks = [get_title(page, url) for page in pages]await asyncio.gather(*tasks)# 关闭所有浏览器for browser in browsers:await browser.close()# 运行主函数 asyncio.run(main())
参数
- channel: 可以选择不同的浏览器版本,msedge就是Microsoft Edge浏览器,同时还支持beta版本。在大部分情况下,使用默认的chrome浏览器足够了。
- headless: 是否开启无头模式(True开启无头模式不显示浏览器,False显示浏览器)
2.代码生成(本小节来自崔庆才老师的内容)
Playwright 还有一个强大的功能,那就是可以录制我们在浏览器中的操作并将代码自动生成出来,有了这个功能,我们甚至都不用写任何一行代码,这个功能可以通过 playwright 命令行调用 codegen 来实现,我们先来看看 codegen 命令都有什么参数,输入如下命令:
playwright codegen --help
结果类似如下:
Usage: npx playwright codegen [options] [url]open page and generate code for user actionsOptions:-o, --output <file name> saves the generated script to a file--target <language> language to use, one of javascript, python, python-async, csharp (default: "python")-b, --browser <browserType> browser to use, one of cr, chromium, ff, firefox, wk, webkit (default: "chromium")--channel <channel> Chromium distribution channel, "chrome", "chrome-beta", "msedge-dev", etc--color-scheme <scheme> emulate preferred color scheme, "light" or "dark"--device <deviceName> emulate device, for example "iPhone 11"--geolocation <coordinates> specify geolocation coordinates, for example "37.819722,-122.478611"--load-storage <filename> load context storage state from the file, previously saved with --save-storage--lang <language> specify language / locale, for example "en-GB"--proxy-server <proxy> specify proxy server, for example "http://myproxy:3128" or "socks5://myproxy:8080"--save-storage <filename> save context storage state at the end, for later use with --load-storage--timezone <time zone> time zone to emulate, for example "Europe/Rome"--timeout <timeout> timeout for Playwright actions in milliseconds (default: "10000")--user-agent <ua string> specify user agent string--viewport-size <size> specify browser viewport size in pixels, for example "1280, 720"-h, --help display help for commandExamples:$ codegen$ codegen --target=python$ codegen -b webkit https://example.com
可以看到这里有几个选项,比如
- -o 代表输出的代码文件的名称;
- —target 代表使用的语言,默认是 python,即会生成同步模式的操作代码,如果传入 python-async 就会生成异步模式的代码;
- -b 代表的是使用的浏览器,默认是 Chromium
- —device 可以模拟使用手机浏览器,比如 iPhone 11
- —lang 代表设置浏览器的语言
- —timeout 可以设置页面加载超时时间。
好,了解了这些用法,那我们就来尝试启动一个 Firefox 浏览器,然后将操作结果输出到 script.py 文件,命令如下:
playwright codegen -o 3_2.py -b chromium
这时候就弹出了一个 Firefox 浏览器,同时右侧会输出一个脚本窗口,实时显示当前操作对应的代码。
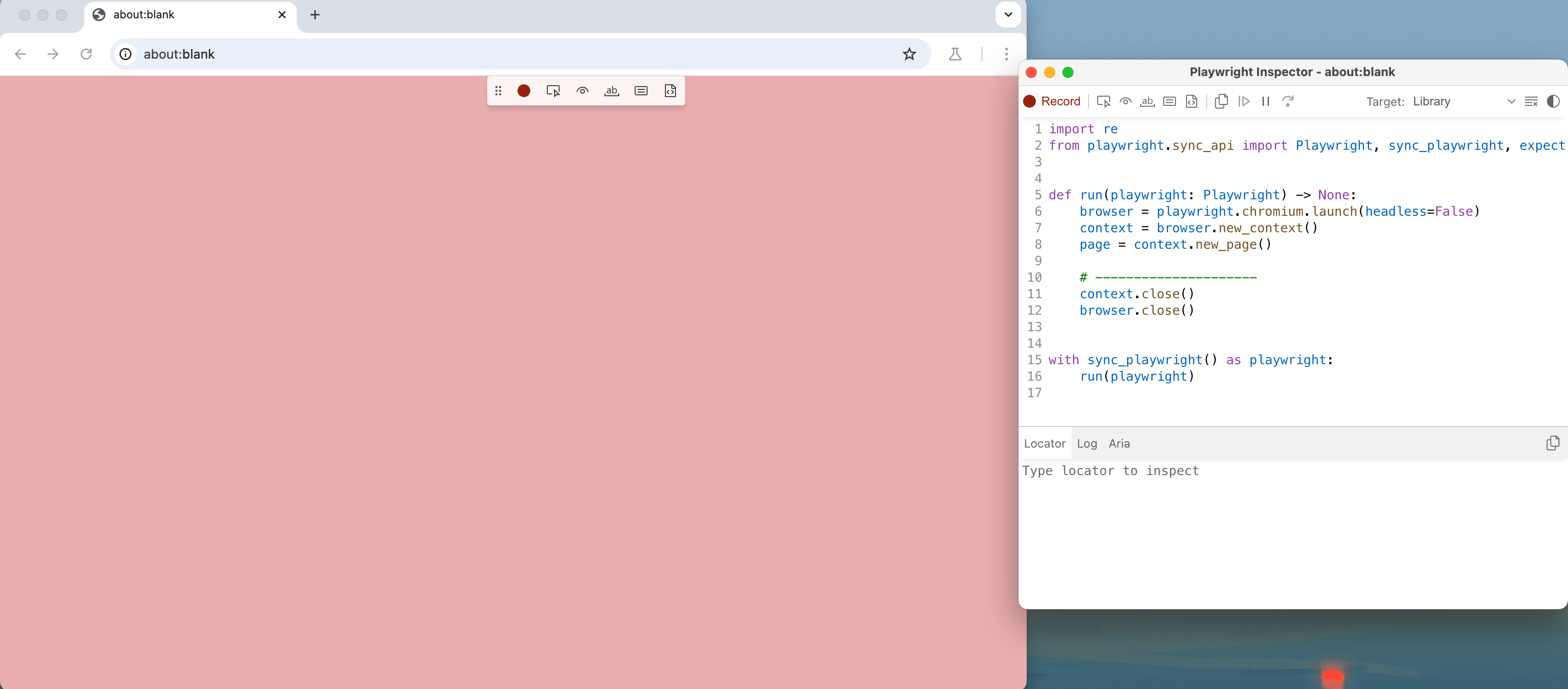
我们可以在浏览器中做任何操作,比如打开http://www.baidu.com,通过图中的检索元素可以找到对应元素的标记,点击后还可以通过右侧locator进行识别

我们现在在输入框输入NBA排名可以看见浏览器中还会高亮显示我们正在操作的页面节点,右侧的窗口如图所示:

操作完毕之后,关闭浏览器,Playwright 会生成一个 3_2.py 文件,内容如下:
import re
from playwright.sync_api import Playwright, sync_playwright, expectdef run(playwright: Playwright) -> None:browser = playwright.chromium.launch(headless=False)context = browser.new_context()page = context.new_page()page.goto("http://www.baidu.com/")page.locator("#kw").click()page.locator("#kw").fill("NBA")page.locator("#kw").press("CapsLock")page.locator("#kw").fill("NBA排名")page.goto("http://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=nba%E6%8E%92%E5%90%8D&fenlei=256&rsv_pq=0x8cc30d85063c7a80&rsv_t=e6c02Rfwvst%2F6FN9HVCbwx4kcnD9jZsz4W28bEWoUHac4rIlfbJS1AhduX1a&rqlang=en&rsv_dl=ib&rsv_sug3=11&rsv_sug1=2&rsv_sug7=100")page.close()# ---------------------context.close()browser.close()with sync_playwright() as playwright:run(playwright)可以看到这里生成的代码和我们之前写的示例代码几乎差不多,而且也是完全可以运行的,运行之后就可以看到它又可以复现我们刚才所做的操作了。
所以,有了这个功能,我们甚至都不用编写任何代码,只通过简单的可视化点击就能把代码生成出来,可谓是非常方便了!
3.常见元素操作
本小节内容将以异步模式书写,且url为http://www.baidu.com
1.页面截图
await page.screenshot(path="./baidu.png", # 保存路径full_page=False, # 是否截图整个页面(默认只截当前视口)clip={ # 指定截图区域(x, y, width, height)"x": 100,"y": 200,"width": 500,"height": 400},type="png", # 图片类型:"png"(默认)或 "jpeg"quality=80, # 图片质量(仅 jpeg 有效,0-100)omit_background=True # 透明背景(适用于 PNG 截图)
)
如果你想只截图某个具体元素(比如某个按钮、标题、div),可以这样:
await page.goto("https://baidu.com")
logo = await page.query_selector('//*[@id="s_lg_img"]')
await logo.screenshot(path="baidu_logo.png")
2.常见的元素操作(填充文字,点击等)
填充文字(fill())
await page.fill('input[name="username"]', 'my_username')
await page.fill('//input[@type="password"]', 'my_password') # XPath 用法
点击元素(click())
await page.click('button[type="submit"]')
await page.click('//a[contains(text(), "登录")]') # XPath 定位
⚠️ Playwright 会自动等待元素可见、可点击,不需要写
time.sleep()!
选中下拉框选项(select_option())
await page.select_option('select#city', 'shanghai') # value值
await page.select_option('//select[@id="lang"]', label="中文") # 根据文本
勾选/取消勾选复选框(check() / uncheck())
await page.check('input[type="checkbox"]')
await page.uncheck('input[type="checkbox"]')
上传文件(set_input_files())
await page.set_input_files('input[type="file"]', 'myfile.pdf')
提交表单
Playwright 没有专门的 submit() 方法,一般点击提交按钮即可:
await page.click('button[type="submit"]')
或者用 JS 触发提交:
await page.eval_on_selector('form', 'form => form.submit()')
获取文本内容(text_content())
text = await page.text_content('h1')
print("页面标题:", text)
获取标签属性值(get_attribute())
href = await page.get_attribute('a', 'href')
print("链接地址:", href)
判断元素是否存在
el = await page.query_selector('div.alert')
if el:print("警告提示框存在!")
判断元素是否可见(需要 is_visible())
is_visible = await page.is_visible('div#popup')
print("是否可见:", is_visible)
清除输入框内容
await page.fill('input[name="email"]', '') # 直接填空字符串
小结
| 操作 | 方法名 |
|---|---|
| 填文字 | fill() |
| 点击 | click() |
| 下拉选择 | select_option() |
| 勾选 | check() / uncheck() |
| 上传文件 | set_input_files() |
| 获取文本 | text_content() |
| 获取属性 | get_attribute() |
| 判断存在 | query_selector() |
| 判断可见 | is_visible() |
3.css选择器(内容来自崔庆才老师)
ps常用知识:id -- # class -- .
前面我们注意到 click 和 fill 等方法都传入了一个字符串,这些字符串有的符合 CSS 选择器的语法,有的又是 text= 开头的,感觉似乎没太有规律的样子,它到底支持怎样的匹配规则呢?下面我们来了解下。
传入的这个字符串,我们可以称之为 Element Selector,它不仅仅支持 CSS 选择器、XPath,Playwright 还扩展了一些方便好用的规则,比如直接根据文本内容筛选,根据节点层级结构筛选等等。
文本选择
文本选择支持直接使用 text= 这样的语法进行筛选,示例如下:
page.click("text=Log in")
这就代表选择文本是 Log in 的节点,并点击。
CSS 选择器
CSS 选择器之前也介绍过了,比如根据 id 或者 class 筛选:
page.click("button")
page.click("#nav-bar .contact-us-item")
根据特定的节点属性筛选:
page.click("[data-test=login-button]")
page.click("[aria-label='Sign in']")
CSS 选择器 + 文本
我们还可以使用 CSS 选择器结合文本值进行海选,比较常用的就是 has-text 和 text,前者代表包含指定的字符串,后者代表字符串完全匹配,示例如下:
page.click("article:has-text('Playwright')")
page.click("#nav-bar :text('Contact us')")
第一个就是选择文本中包含 Playwright 的 article 节点,第二个就是选择 id 为 nav-bar 节点中文本值等于 Contact us 的节点。
CSS 选择器 + 节点关系
还可以结合节点关系来筛选节点,比如使用 has 来指定另外一个选择器,示例如下:
page.click(".item-description:has(.item-promo-banner)")
比如这里选择的就是选择 class 为 item-description 的节点,且该节点还要包含 class 为 item-promo-banner 的子节点。
另外还有一些相对位置关系,比如 right-of 可以指定位于某个节点右侧的节点,示例如下:
page.click("input:right-of(:text('Username'))")
这里选择的就是一个 input 节点,并且该 input 节点要位于文本值为 Username 的节点的右侧。
4.与xpath结合(本人更熟悉xpath)
点击按钮
await page.click('xpath=//button[text()="提交"]')
await page.click('xpath=//a[contains(text(), "登录")]')
填写表单
await page.fill('xpath=//input[@name="username"]', 'my_user')
await page.fill('xpath=//input[@type="password"]', '123456')
获取元素文本
text = await page.text_content('xpath=//h1')
print("标题:", text)
获取属性值
href = await page.get_attribute('xpath=//a[text()="更多"]', 'href')
判断元素是否存在
el = await page.query_selector('xpath=//div[@class="alert"]')
if el:print("警告框存在")
遍历多个元素
elements = await page.query_selector_all('xpath=//ul/li')
for el in elements:text = await el.text_content()print(text)
选择下拉框
await page.select_option('xpath=//select[@id="lang"]', label="中文")
上传文件
await page.set_input_files('xpath=//input[@type="file"]', 'resume.pdf')
截图指定元素
element = await page.query_selector('xpath=//div[@id="banner"]')
await element.screenshot(path="./banner.png")
等待某元素出现(自动超时)
await page.wait_for_selector('xpath=//div[@class="loading-done"]')
XPath 表达式小抄
| 作用 | XPath 示例 |
|---|---|
| 精确匹配标签属性 | //input[@name="email"] |
| 模糊匹配文本 | //a[contains(text(), "登录")] |
| 文本等于 | //button[text()="提交"] |
| 多层级路径 | //div[@class="user"]/span |
| 获取第一个元素 | //ul/li[1] |
| 获取最后一个元素 | //ul/li[last()] |
| 多属性组合选择 | //input[@type="text" and @placeholder] |
| 自定义属性 | //div[@data-role="header"] |
5.持久化保留登陆状态(cookie内容)
案例来自于开源项目MediaCrawler(欢迎大家star):
#关键函数browser_context = await chromium.launch_persistent_context(user_data_dir=user_data_dir,accept_downloads=True,headless=headless,proxy=playwright_proxy, # type: ignoreviewport={"width": 1920, "height": 1080},user_agent=user_agent)
Cookie常用处理函数
def convert_cookies(cookies: Optional[List[Cookie]]) -> Tuple[str, Dict]:if not cookies:return "", {}cookies_str = ";".join([f"{cookie.get('name')}={cookie.get('value')}" for cookie in cookies])cookie_dict = dict()for cookie in cookies:cookie_dict[cookie.get('name')] = cookie.get('value')return cookies_str, cookie_dictdef convert_str_cookie_to_dict(cookie_str: str) -> Dict:cookie_dict: Dict[str, str] = dict()if not cookie_str:return cookie_dictfor cookie in cookie_str.split(";"):cookie = cookie.strip()if not cookie:continuecookie_list = cookie.split("=")if len(cookie_list) != 2:continuecookie_value = cookie_list[1]if isinstance(cookie_value, list):cookie_value = "".join(cookie_value)cookie_dict[cookie_list[0]] = cookie_valuereturn cookie_dict
#使用方法--登陆过后
cookie_str, cookie_dict = convert_cookies(await browser_context.cookies())
headers["Cookie"] = cookie_str
完整实例
# 是否开启无头模式
HEADLESS = False# 平台
PLATFORM = "bilibili"# 是否保存登录状态
SAVE_LOGIN_STATE = True# 用户浏览器缓存的浏览器文件配置
USER_DATA_DIR = "%s_user_data_dir" # %s will be replaced by platform nameimport os
import sys
import asyncio
from typing import Optional,Dict,List,Tuple
from playwright.async_api import async_playwright
from playwright.async_api import (BrowserContext, BrowserType, Page, async_playwright,Cookie)async def main():async with async_playwright() as p:chromium = p.chromiumbrowser_context = await launch_browser(chromium,None, None, headless=False)async def launch_browser(chromium: BrowserType,playwright_proxy: Optional[Dict], # [{"http":"http://ip:port","https":"https://ip:port"},... ...]user_agent: Optional[str], # ua列表headless: bool = True # 无头模式
) -> BrowserContext:"""launch browser and create browser context:param chromium: chromium browser:param playwright_proxy: playwright proxy:param user_agent: user agent:param headless: headless mode:return: browser context"""if SAVE_LOGIN_STATE:# feat issue #14# we will save login state to avoid login every timeuser_data_dir = os.path.join(os.getcwd(), "browser_data",config.USER_DATA_DIR % PLATFORM) # type: ignorebrowser_context = await chromium.launch_persistent_context(user_data_dir=user_data_dir,accept_downloads=True,headless=headless,proxy=playwright_proxy, # type: ignoreviewport={"width": 1920, "height": 1080},user_agent=user_agent)return browser_contextelse:# type: ignorebrowser = await chromium.launch(headless=headless, proxy=playwright_proxy)browser_context = await browser.new_context(viewport={"width": 1920, "height": 1080},user_agent=user_agent)return browser_contextdef convert_cookies(cookies: Optional[List[Cookie]]) -> Tuple[str, Dict]:if not cookies:return "", {}cookies_str = ";".join([f"{cookie.get('name')}={cookie.get('value')}" for cookie in cookies])cookie_dict = dict()for cookie in cookies:cookie_dict[cookie.get('name')] = cookie.get('value')return cookies_str, cookie_dictdef convert_str_cookie_to_dict(cookie_str: str) -> Dict:cookie_dict: Dict[str, str] = dict()if not cookie_str:return cookie_dictfor cookie in cookie_str.split(";"):cookie = cookie.strip()if not cookie:continuecookie_list = cookie.split("=")if len(cookie_list) != 2:continuecookie_value = cookie_list[1]if isinstance(cookie_value, list):cookie_value = "".join(cookie_value)cookie_dict[cookie_list[0]] = cookie_valuereturn cookie_dictif __name__ == '__main__':try:# asyncio.run(main())asyncio.get_event_loop().run_until_complete(main())except KeyboardInterrupt:sys.exit()6.js文件注入(防自动化检测),js代码运行
js文件注入
# stealth.min.js is a js script to prevent the website from detecting the crawler.
await self.browser_context.add_init_script(path="libs/stealth.min.js")
完整示例
import asyncio
import sys
from playwright.async_api import async_playwrightasync def main():async with async_playwright() as p:browser = await p.chromium.launch(headless=False)context = await browser.new_context()await context.add_init_script("./3_5_6_stealth.min.js")page = await context.new_page()await page.goto("https://baidu.com")print(f"title:{await page.title()}")if __name__ == '__main__':try:# asyncio.run(main())asyncio.get_event_loop().run_until_complete(main())except KeyboardInterrupt:sys.exit()
运行js代码
async def run_js_code():async with async_playwright() as p:browser = await p.chromium.launch(headless=False)context = await browser.new_context(storage_state="storage.json")page = await context.new_page()await page.goto("https://www.bilibili.com")title = await page.evaluate("() => document.title")print(f"页面标题是:{title}")# 模拟修改 DOMawait page.evaluate("""() => {let h = document.createElement('h1');h.innerText = "✨ Hello from injected JS!";h.style.color = "red";document.body.prepend(h);}""")await browser.close()
总结
| 功能 | 方法或函数 |
|---|---|
| 保存登录状态 | BrowserType.launch_persistent_context(path=...) |
| 注入js文件(初始) | context.add_init_script("./3_5_6_stealth.min.js") |
| 注入 JS 文件 | page.add_script_tag(content=...) |
| 执行 JS 代码片段 | page.evaluate("() => { ... }") |
7.事件监听(内容来自崔庆才老师)
Page 对象提供了一个 on 方法,它可以用来监听页面中发生的各个事件,比如 close、console、load、request、response 等等。
比如这里我们可以监听 response 事件,response 事件可以在每次网络请求得到响应的时候触发,我们可以设置对应的回调方法获取到对应 Response 的全部信息,示例如下:
from playwright.sync_api import sync_playwrightdef on_response(response):print(f'Statue {response.status}: {response.url}')with sync_playwright() as p:browser = p.chromium.launch(headless=False)page = browser.new_page()page.on('response', on_response)page.goto('https://spa6.scrape.center/')page.wait_for_load_state('networkidle')browser.close()
这里我们在创建 Page 对象之后,就开始监听 response 事件,同时将回调方法设置为 on_response,on_response 对象接收一个参数,然后把 Response 的状态码和链接都输出出来了。
运行之后,可以看到控制台输出结果如下:
Statue 200: https://spa6.scrape.center/
Statue 200: https://spa6.scrape.center/css/app.ea9d802a.css
Statue 200: https://spa6.scrape.center/js/app.5ef0d454.js
Statue 200: https://spa6.scrape.center/js/chunk-vendors.77daf991.js
Statue 200: https://spa6.scrape.center/css/chunk-19c920f8.2a6496e0.css
...
Statue 200: https://spa6.scrape.center/css/chunk-19c920f8.2a6496e0.css
Statue 200: https://spa6.scrape.center/js/chunk-19c920f8.c3a1129d.js
Statue 200: https://spa6.scrape.center/img/logo.a508a8f0.png
Statue 200: https://spa6.scrape.center/fonts/element-icons.535877f5.woff
Statue 301: https://spa6.scrape.center/api/movie?limit=10&offset=0&token=NGMwMzFhNGEzMTFiMzJkOGE0ZTQ1YjUzMTc2OWNiYTI1Yzk0ZDM3MSwxNjIyOTE4NTE5
Statue 200: https://spa6.scrape.center/api/movie/?limit=10&offset=0&token=NGMwMzFhNGEzMTFiMzJkOGE0ZTQ1YjUzMTc2OWNiYTI1Yzk0ZDM3MSwxNjIyOTE4NTE5
Statue 200: https://p0.meituan.net/movie/da64660f82b98cdc1b8a3804e69609e041108.jpg@464w_644h_1e_1c
Statue 200: https://p0.meituan.net/movie/283292171619cdfd5b240c8fd093f1eb255670.jpg@464w_644h_1e_1c
....
Statue 200: https://p1.meituan.net/movie/b607fba7513e7f15eab170aac1e1400d878112.jpg@464w_644h_1e_1c
注意:这里省略了部分重复的内容。
可以看到,这里的输出结果其实正好对应浏览器 Network 面板中所有的请求和响应内容,和下图是一一对应的:
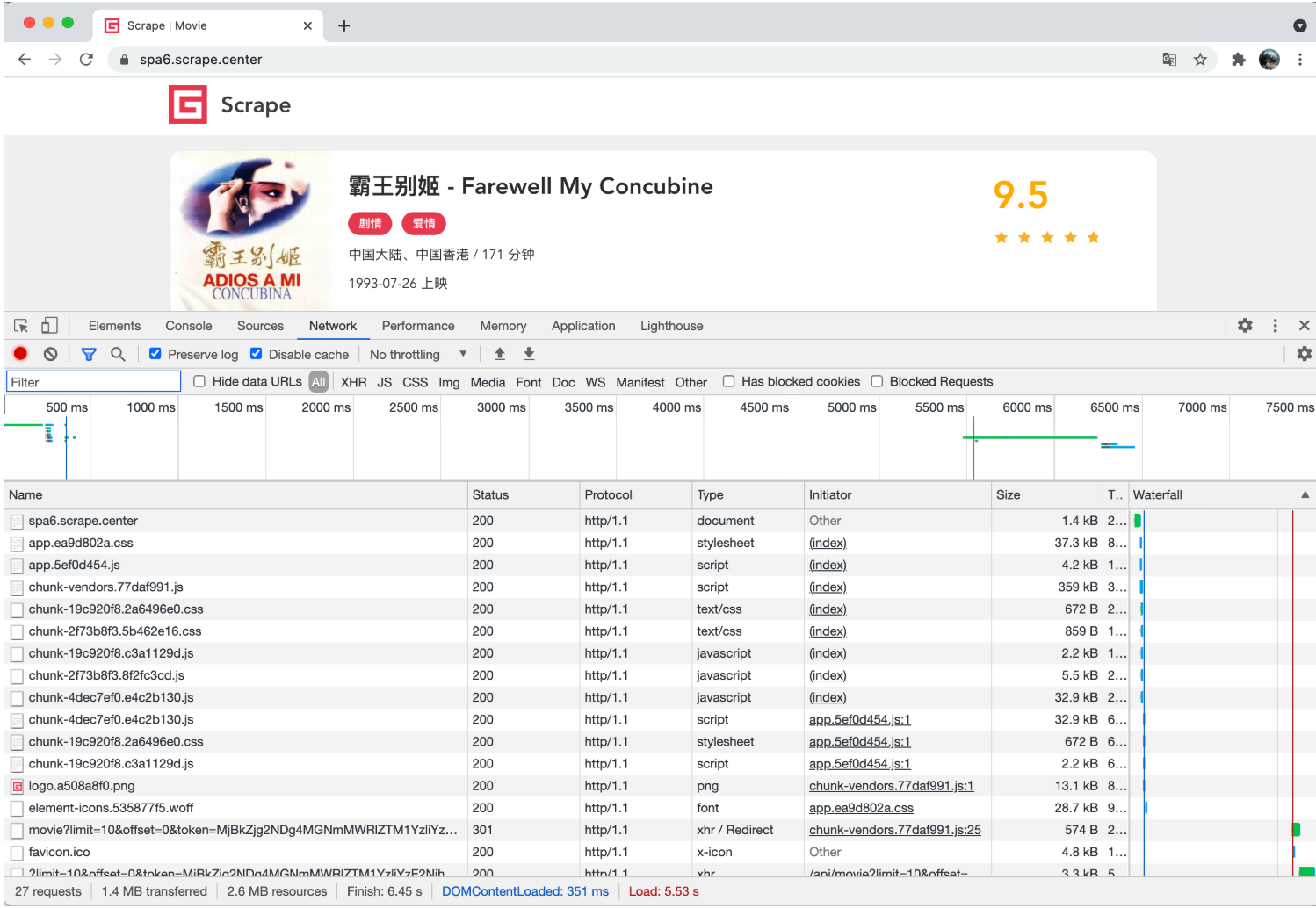
这个网站我们之前分析过,其真实的数据都是 Ajax 加载的,同时 Ajax 请求中还带有加密参数,不好轻易获取。
但有了这个方法,这里如果我们想要截获 Ajax 请求,岂不是就非常容易了?
改写一下判定条件,输出对应的 JSON 结果,改写如下:
from playwright.sync_api import sync_playwrightdef on_response(response):if '/api/movie/' in response.url and response.status == 200:print(response.json())with sync_playwright() as p:browser = p.chromium.launch(headless=False)page = browser.new_page()page.on('response', on_response)page.goto('https://spa6.scrape.center/')page.wait_for_load_state('networkidle')browser.close()
控制台输入如下:
{'count': 100, 'results': [{'id': 1, 'name': '霸王别姬', 'alias': 'Farewell My Concubine', 'cover': 'https://p0.meituan.net/movie/ce4da3e03e655b5b88ed31b5cd7896cf62472.jpg@464w_644h_1e_1c', 'categories': ['剧情', '爱情'], 'published_at': '1993-07-26', 'minute': 171, 'score': 9.5, 'regions': ['中国大陆', '中国香港']},
...
'published_at': None, 'minute': 103, 'score': 9.0, 'regions': ['美国']}, {'id': 10, 'name': '狮子王', 'alias': 'The Lion King', 'cover': 'https://p0.meituan.net/movie/27b76fe6cf3903f3d74963f70786001e1438406.jpg@464w_644h_1e_1c', 'categories': ['动画', '歌舞', '冒险'], 'published_at': '1995-07-15', 'minute': 89, 'score': 9.0, 'regions': ['美国']}]}
简直是得来全不费工夫,我们直接通过这个方法拦截了 Ajax 请求,直接把响应结果拿到了,即使这个 Ajax 请求有加密参数,我们也不用关心,因为我们直接截获了 Ajax 最后响应的结果,这对数据爬取来说实在是太方便了。
另外还有很多其他的事件监听,这里不再一一介绍了,可以查阅官方文档,参考类似的写法实现。
8.网络劫持(内容来自崔庆才老师)
最后再介绍一个实用的方法 route,利用 route 方法,我们可以实现一些网络劫持和修改操作,比如修改 request 的属性,修改 response 响应结果等。
看一个实例:
from playwright.sync_api import sync_playwright
import rewith sync_playwright() as p:browser = p.chromium.launch(headless=False)page = browser.new_page()def cancel_request(route, request):route.abort()page.route(re.compile(r"(\.png)|(\.jpg)"), cancel_request)page.goto("https://spa6.scrape.center/")page.wait_for_load_state('networkidle')page.screenshot(path='no_picture.png')browser.close()
这里我们调用了 route 方法,第一个参数通过正则表达式传入了匹配的 URL 路径,这里代表的是任何包含 .png 或 .jpg 的链接,遇到这样的请求,会回调 cancel_request 方法处理,cancel_request 方法可以接收两个参数,一个是 route,代表一个 CallableRoute 对象,另外一个是 request,代表 Request 对象。这里我们直接调用了 route 的 abort 方法,取消了这次请求,所以最终导致的结果就是图片的加载全部取消了。
观察下运行结果,如图所示:
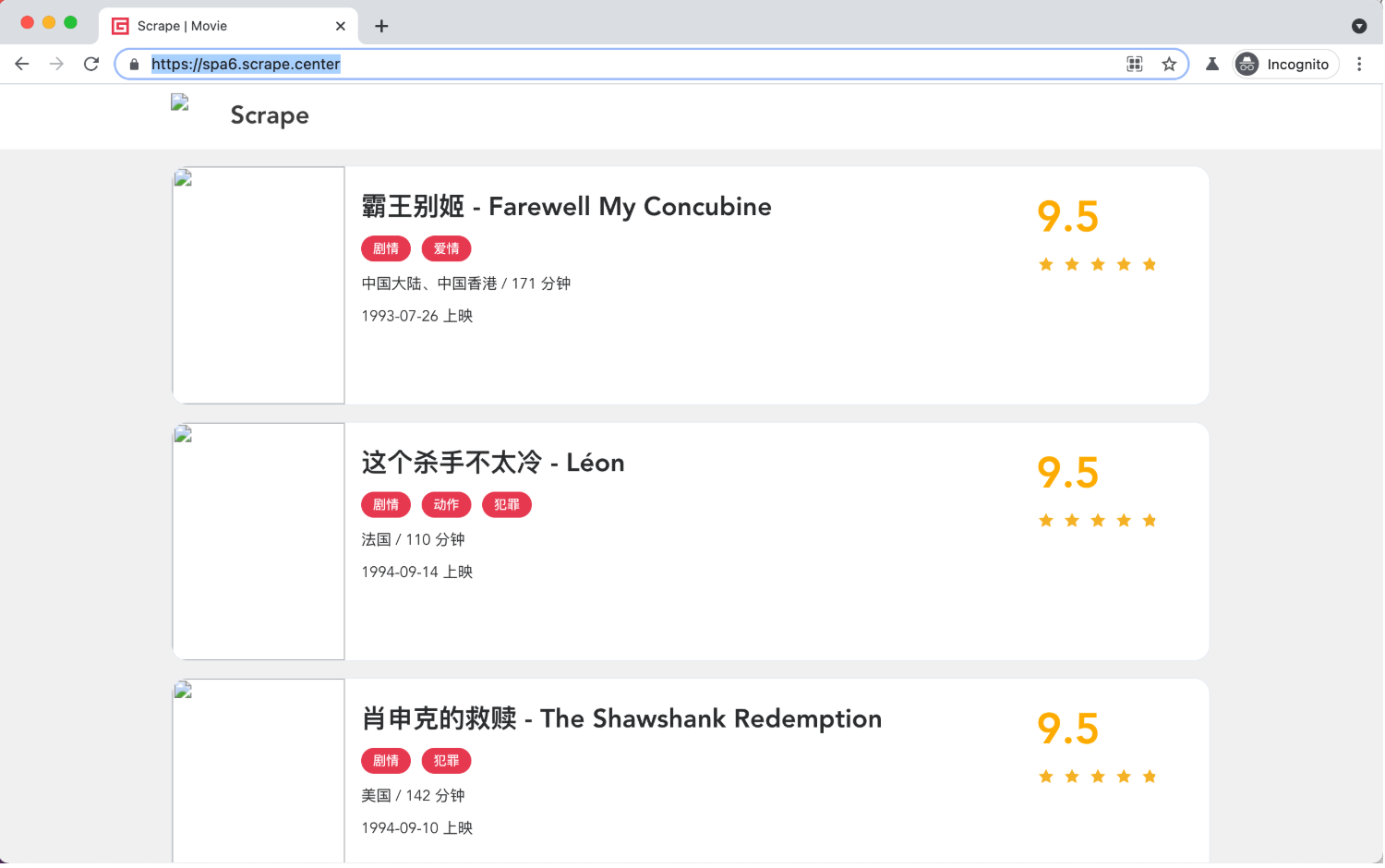
可以看到图片全都加载失败了。
这个设置有什么用呢?其实是有用的,因为图片资源都是二进制文件,而我们在做爬取过程中可能并不想关心其具体的二进制文件的内容,可能只关心图片的 URL 是什么,所以在浏览器中是否把图片加载出来就不重要了。所以如此设置之后,我们可以提高整个页面的加载速度,提高爬取效率。
另外,利用这个功能,我们还可以将一些响应内容进行修改,比如直接修改 Response 的结果为自定义的文本文件内容。
首先这里定义一个 HTML 文本文件,命名为 custom_response.html,内容如下:
<!DOCTYPE html>
<html><head><title>Hack Response</title></head><body><h1>Hack Response</h1></body>
</html>
代码编写如下:
from playwright.sync_api import sync_playwrightwith sync_playwright() as p:browser = p.chromium.launch(headless=False)page = browser.new_page()def modify_response(route, request):route.fulfill(path="./custom_response.html")page.route('/', modify_response)page.goto("https://spa6.scrape.center/")browser.close()
这里我们使用 route 的 fulfill 方法指定了一个本地文件,就是刚才我们定义的 HTML 文件,运行结果如下:
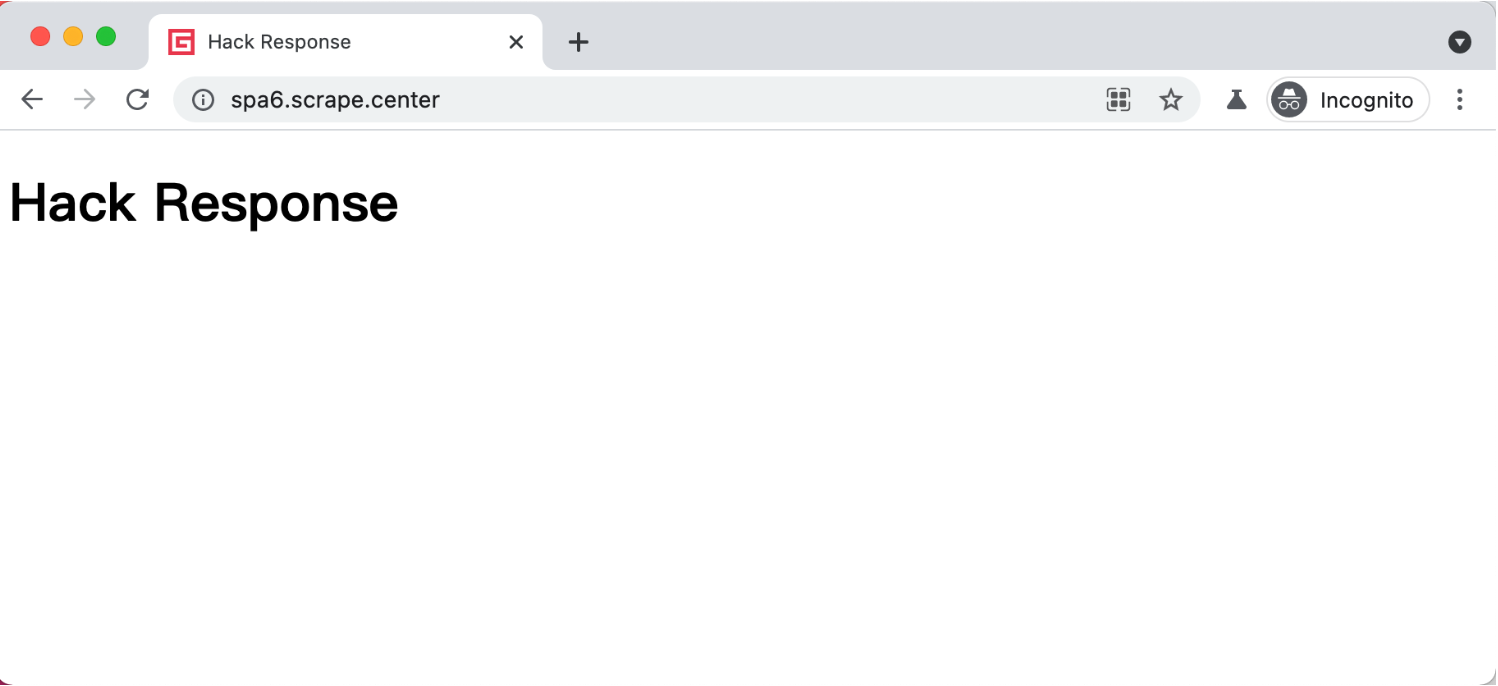
可以看到,Response 的运行结果就被我们修改了,URL 还是不变的,但是结果已经成了我们修改的 HTML 代码。
所以通过 route 方法,我们可以灵活地控制请求和响应的内容,从而在某些场景下达成某些目的。
8.页面下滑
滚动到底(页面底部)
执行 JavaScript
await page.evaluate("window.scrollTo(0, document.body.scrollHeight)")
这个语句会立刻把页面滚动到最底部。
滚动到某个元素
await page.locator('#footer').scroll_into_view_if_needed()
scroll_into_view_if_needed()是 Playwright 的高级封装,会自动判断元素是否在视口内。
模拟鼠标滚轮滚动
如果你想模拟“人手动下滑”的过程,可以用鼠标滚轮(playwright 的 mouse.wheel()):
await page.mouse.wheel(0, 1000) # 横向滚动为 0,纵向滚动 1000 像素
你可以循环调用,实现「逐步加载」。
自动滑动加载全内容(适用于瀑布流网站)
比如抓取 B 站、微博这类瀑布流页面,可以模拟“滑到底,加载,再滑…”的逻辑:
async def auto_scroll(page):await page.evaluate("""async () => {await new Promise((resolve) => {let totalHeight = 0;const distance = 200;const timer = setInterval(() => {const scrollHeight = document.body.scrollHeight;window.scrollBy(0, distance);totalHeight += distance;if (totalHeight >= scrollHeight){clearInterval(timer);resolve();}}, 100);});}""")
然后这样调用它:
await auto_scroll(page)
滚动一个特定的容器(非整个页面)
如果滚动的不是整个页面,而是某个滚动区域(比如带滚条的 <div>):
await page.evaluate('''() => {const scrollable = document.querySelector('.scroll-box');scrollable.scrollTop = scrollable.scrollHeight;
}''')
总结
| 场景 | 推荐方法 |
|---|---|
| 直接滚动到底部 | evaluate("scrollTo(...)") |
| 滚动到特定元素 | locator(...).scroll_into_view_if_needed() |
| 模拟用户滚轮操作 | page.mouse.wheel() |
| 自动滚动加载内容(瀑布流) | 自定义 JS 脚本 + evaluate() |
| 滚动容器而非页面 | 通过 JS 精准选择容器滚动 |
补充
在3)-6,3)-7中讲解了事件监听和网络劫持两种方法,在使用过程中需要注意一个地方,要在await browser.close()前添加await asyncio.sleep(2000),这样才能保证事件监听和网络劫持的持久抓取,不然容易出现页面内容更新,但是无法捕获新信息。比如将await asyncio.sleep(2000)替换为input('输入回车结束任务')来避免直接关闭浏览器,这样的写法就无法保证任务监听和网络劫持的持久抓取。
page = await context.new_page()page.on("response", on_response)await page.route(re.compile(r"(\.png)|(\.jpg)"), cancel_request)“”“其他逻辑的具体实现”“”await asyncio.sleep(2000)await browser.close()
结语
在深入学习了Playwright之后,你会发现它几乎能够应对各种复杂的爬虫任务。尽管它在速度上可能不如直接通过API接口获取数据那样快速,但在当今网络环境下,大多数网站都设置了各种反爬机制和加密参数,想要通过代码直接处理这些难题往往会变得异常繁琐。而Playwright凭借其强大的自动化功能以及对部分人工操作的支持,能够让你以一种简单高效的方式完成爬虫任务,轻松绕过那些复杂的反爬限制。
本文源码: Python爬虫之路 https://github.com/rosyrain/spider-course lesson14中。欢迎各位Follow/Star/Fork ( •̀ ω •́ )✧
有任何问题欢迎大家的评论和指正。再次声明,本专栏只做技术探讨,严谨商用,恶意攻击等。
这是我的 GitHub 主页:Rosyrain (github.com) https://github.com/rosyrain,里面有一些我学习时候的笔记或者代码。本专栏的文档和源码存到spider-course的仓库下。
欢迎大家Follow/Star/Fork三连。
参考文献
- 崔庆才老师playwright爬虫
- playwright最详细使用教程
- MediaCrawler(欢迎大家star)