(3)python爬虫--Xpath
文章目录
- 前言
- 一、Xpath的安装
- 1.1 第一步:安装 chrome_Xpath.zip 包
- 1.2 第二步:将Xpath插件引入到chrome插件库
- 1.3 第三步:测试
- 在这里插入图片描述
- 二、Xpath的基本使用
- 2.1 Python项目中安装对应的Xpath库
- 2.2 Xpath解析本地文件
- 2.3 Xpath解析HTML标签
- 1. 路径查询
- 2. 谓词查询
- 3. 属性查询
- 4. 模糊查询
- 5. 逻辑运算(不常用)
- 练习一: 获取百度页面中的百度一下
- 第一步: 定位百度一下在百度页面中的标签
- 第二步: 通过xpath插件输入xpath语法获取到result="百度一下"
- 第三步:抓取百度源码(requests库)并使用xpath解析到对应的内容(百度一下)
- 练习二:获取多页中的所有图片
- 总结
前言
在当今数据驱动的时代,高效地从网页中提取结构化数据已成为开发者的一项重要技能。XPath(XML Path Language)作为一种功能强大的查询语言,凭借其简洁的语法和精准的定位能力,在网页解析和数据抓取领域占据着重要地位。Python 凭借其丰富的第三方库(如 lxml、requests-html 等)为 XPath 提供了完美的运行环境,使得开发者能够轻松应对各种复杂的 HTML/XML 文档解析需求。本文将系统介绍 XPath 的核心语法、高级定位技巧以及 Python 中的实战应用场景,并通过典型示例演示如何高效利用 XPath 进行数据提取,帮助读者快速掌握这一关键技术,提升数据采集和处理的效率。
一、Xpath的安装
1.1 第一步:安装 chrome_Xpath.zip 包
因为chrome下载插件需要国外的ip,因而这里直接为大家提供了对应的zip包

1.2 第二步:将Xpath插件引入到chrome插件库
打开谷歌浏览器右上方的三个小竖点,找到扩展程序,将右上角的开发者模式打开,将安装的zip插件包直接拖住到该页面即可。如下图所示,成功之后重启谷歌浏览器。

1.3 第三步:测试
随机打开一个网址,同时按下ctrl + shift + x 页面上方出现黑色提示框,说明安装成功!!!

二、Xpath的基本使用
2.1 Python项目中安装对应的Xpath库
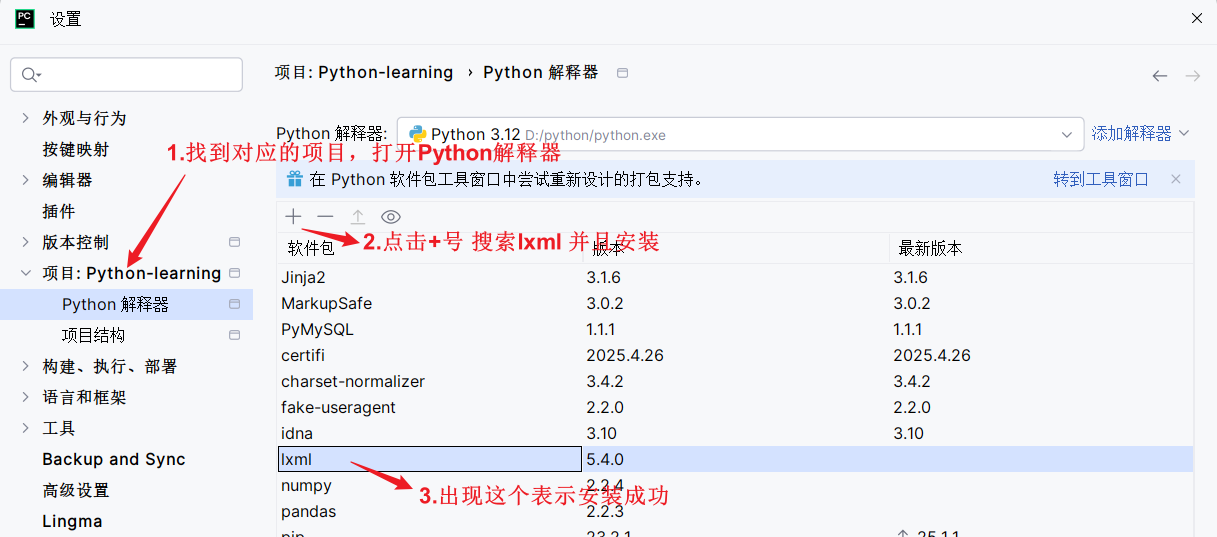
提示: 如果在后续使用时,出现没有正确安装的错误,重启pycharm并且检查是否成功安装lxml,再次测试。
2.2 Xpath解析本地文件
# Xpath解析本地文件# 1. 导入etree文件
from lxml import etree# 2. 基础语法
# 获取tree对象--检测是否正确读取到了本地文件
# parse方法的参数是文件的相对路径
tree = etree.parse("test.html")
# 出现报错的原因是Xpath严格按照html规范,所有的标签必须存在结束标签
# 而<meta charset="UTF-8">并没有出现结束标签,所以报错
# 修改为 <meta charset="UTF-8"/> 即可
print(tree)
2.3 Xpath解析HTML标签
# Xpath解析本地文件
from lxml import etreetree = etree.parse("test.html")
# print(tree)# 通过调用tree对象里面的path方法,就可以来解析HTML标签了
tree.xpath('xpath解析语法')
xpath基本语法:
- 路径查询
//:查找所有子孙节点,不考虑层级关系/:查找直接子节点
- 谓词查询
//div[@id]//div[@id="maincontent"]
- 属性查询
//@class
- 模糊查询
//div[contains(@id, "he")]//div[starts-with(@id, "he")]
- 内容查询
//div/h1/text()
- 逻辑运算
//div[@id="head" and @class="s_down"]//title | //price
1. 路径查询
# Xpath解析本地文件
from lxml import etreetree = etree.parse("test.html")# //:查找所有子孙节点,不考虑层级关系
# /:查找直接子节点# 需求获取到ul里面的li
# 前两个//表示匹配body标签
# body/ul/li 表示从body找到子节点ul 再从ul找到子节点li
li_list = tree.xpath("//body/ul/li")
# 获取元素的个数
print(len(li_list))
对应的html文件
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"/><title>Title</title>
</head>
<body><ul><li>河南</li><li>河北</li><li>山东</li><li>山西</li></ul>
</body>
</html>
2. 谓词查询
# Xpath解析本地文件
from lxml import etreetree = etree.parse("test.html")# //div[@id]
# //div[@id="maincontent"]# 查找所有有id属性的li标签
li_list = tree.xpath("//ul/li[@id]")
# 获取元素个数
print(len(li_list))
# 获取元素内容--- /text()
li_list = tree.xpath("//ul/li[@id]/text()")
print(li_list)# 查找特定id的li标签,并且输出内容
# @id="c1" 这个双引号不可以省略,否则会出现错误
li_list = tree.xpath('//ul/li[@id="c1"]/text()')
print(li_list)
对应的html文件
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"/><title>Title</title>
</head>
<body><ul><li id="c1">河南</li><li id="c2">河北</li><li>山东</li><li>山西</li></ul>
</body>
</html>
3. 属性查询
# Xpath解析本地文件
from lxml import etreetree = etree.parse("test.html")# //@class# 查找id为c1的li标签并且获取class的属性值
li = tree.xpath('//li[@id="c1"]/@class')
print(li)
对应的html文件
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"/><title>Title</title>
</head>
<body><ul><li id="c1" class="henan">河南</li><li id="c2">河北</li><li>山东</li><li>山西</li></ul>
</body>
</html>
4. 模糊查询
# Xpath解析本地文件
from lxml import etreetree = etree.parse("test.html")# //div[contains(@id, "he")]
# //div[starts-with(@id, "he")]# 找到id属性中 包含 c的li标签
li_list = tree.xpath('//ul/li[contains(@id,"c")]/text()')
print(li_list)# 找到id属性中c 开头 的li标签的
li_list = tree.xpath('//ul/li[starts-with(@id,"c")]/text()')
print(li_list)对应的html文件
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"/><title>Title</title>
</head>
<body><ul><li id="c1" class="henan">河南</li><li id="c2">河北</li><li id="3c">山东</li><li>山西</li></ul>
</body>
</html>
5. 逻辑运算(不常用)
# Xpath解析本地文件
from lxml import etreetree = etree.parse("test.html")# 极少部分会用到
# //div[@id="head" and @class="s_down"]
# //title | //price# 查询id为c1和class为c1的
# 必须是在一个li标签内才可以正常获取
li_list = tree.xpath('//ul/li[@id="c1" and @class="henan"]/text()')
print(li_list)# 或语法
li_list = tree.xpath('//ul/li[@id="c1" or @class="c2"]/text()')
print(li_list)
# 也可以这么写
li_list = tree.xpath('//ul/li[@id="c1"]/text() | //ul/li[@class="c2"]/text()')
print(li_list)
对应的html文件
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"/><title>Title</title>
</head>
<body><ul><li id="c1" class="henan">河南</li><li id="c2" class="c2">河北</li><li id="3c">山东</li><li>山西</li></ul>
</body>
</html>
练习一: 获取百度页面中的百度一下
提示: 这里会使用到下载的xpath插件
第一步: 定位百度一下在百度页面中的标签
通过F12定位到百度一下标签元素的位置

第二步: 通过xpath插件输入xpath语法获取到result=“百度一下”
通过唯一的id属性,来写xpath语法,获取到百度一下
query = //input[@id="su"]/@value - - - result="百度一下"

第三步:抓取百度源码(requests库)并使用xpath解析到对应的内容(百度一下)
提示:解析响应数据:使用etree.HTML()即可
示例代码:
# Xpath解析响应数据
# 确保是上网环境
from lxml import etree
import requestsurl = 'https://www.baidu.com'headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36'
}response = requests.get(url=url, headers=headers)content = response.content.decode()
# print(content)# 通过xpath解析响应数据
tree = etree.HTML(content)
# xpath的返回值是列表 想要获取实际值用[0]
baidu_list = tree.xpath('//input[@id="su"]/@value')
print(baidu_list) #['百度一下']
print(baidu_list[0]) # 百度一下
练习二:获取多页中的所有图片
→ 获取图片网址
# Xpath解析响应数据
# 确保是上网环境
from lxml import etree
import requests
import urllib.request# 获取多页图片
# https://sc.chinaz.com/tag_tupian/qinglvtouxiang.html
# https://sc.chinaz.com/tag_tupian/qinglvtouxiang_2.html
# https://sc.chinaz.com/tag_tupian/qinglvtouxiang_3.htmlstart_page = int(input('请输入起始页码:'))
end_page = int(input('请输入结束页码:'))
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36'
}
for page in range(start_page, end_page+1):# 获取需要解析页面的urlif page == 1:url = 'https://sc.chinaz.com/tag_tupian/qinglvtouxiang.html'else:url = 'https://sc.chinaz.com/tag_tupian/qinglvtouxiang_' + str(page) + '.html'# 获取页面源码(requests)response = requests.get(url,headers=headers)content = response.content.decode()# print(content)# 解析图片路径 以及对应的alt值 HTML解析获取来的响应数据# //div[@id="container"]//a/img/@src# //div[@id="container"]//a/img/@arttree = etree.HTML(content)# 出现错误是因为图片访问的时候设置了懒加载,图片的src属性值是空的src_list = tree.xpath('//div[@id="container"]//a/img/@src2')art_list = tree.xpath('//div[@id="container"]//a/img/@alt')# print(len(src_list)) # 20# print(len(art_list)) # 20for src in range(len(src_list)):# 拼接图片的完整路径src_url = 'https:' + src_list[src]# 获取图片名称img_name = art_list[src] + '.jpg'# 下载图片urllib.request.urlretrieve(src_url, "./imgs/" + img_name)
观察到这样的代码方式非常的杂乱,对该代码进行封装
面向对象封装(Parse)
from lxml import etree
import requests
import urllib.request
class Parse:def __init__(self):self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36'}def get_url(self,page):if page == 1:url = 'https://sc.chinaz.com/tag_tupian/qinglvtouxiang.html'else:url = 'https://sc.chinaz.com/tag_tupian/qinglvtouxiang_' + str(page) + '.html'return urldef get_content(self,url):response = requests.get(url,headers=self.headers)content = response.content.decode()return contentdef parse_content(self,content):tree = etree.HTML(content)src_list = tree.xpath('//div[@id="container"]//a/img/@src2')alt_list = tree.xpath('//div[@id="container"]//a/img/@alt')return src_list, alt_listdef save_img(self,src_list,alt_list):for src in range(len(src_list)):src_url = 'https:' + src_list[src]img_name = alt_list[src] + '.jpg'urllib.request.urlretrieve(src_url, img_name)def main(self):start_page = int(input('请输入起始页码:'))end_page = int(input('请输入结束页码:'))for page in range(start_page, end_page + 1):url = self.get_url(page)content = self.get_content(url)src_list, art_list = self.parse_content(content)self.save_img(src_list, art_list)parse = Parse()
parse.main()
总结
通过本文的探讨,我们深入了解了 XPath 在 Python 环境下的强大解析能力。从基础语法到高级轴定位,从简单文本提取到复杂结构解析,XPath 展现了其在数据抓取领域不可替代的价值。掌握 XPath 不仅能显著提升爬虫开发效率,还能应对各种反爬机制和动态页面挑战。希望读者能将本文介绍的技术应用到实际项目中,无论是构建专业的网络爬虫,还是进行日常的数据清洗工作,XPath 都将成为你得力的助手。随着对 XPath 理解的不断深入,相信你会在数据处理的道路上走得更远、更稳。