【Python】【OCR识别】 提取图片文字并根据内容智能分类存储
Python 使用PaddleOCR引擎识别图片内容,提取图片文字并根据内容智能分类存储

上一篇文章提到了OCR提取文字,并格式化处理提取内容,这篇我们把图片分类并储存功能实现一下
目录
- Python 使用PaddleOCR引擎识别图片内容,提取图片文字并根据内容智能分类存储
- 1、项目概述
- 2、核心功能
- 3、核心配置
- 4、目录结构
- 5、执行流程
- 6、代码编写
- 7、结果核查
1、项目概述
基于PaddleOCR引擎实现纺织品标签图像的自动化处理,通过文字识别与语义分析实现智能分类归档。系统可自动将含有特定成分信息的图像按预设规则分类存储。
2、核心功能
-
多格式支持
支持.jpg/.png/.jpeg格式图像文件批处理 -
语义识别分类
内置4大类语义特征识别:- 公制单位(克重/密度/尺寸)
- 合成纤维(聚酯/尼龙/涤纶)
- 环保材料(再生/有机/ECO)
- 混合材料(混纺/百分比组合)
CATEGORIES = [("公制单位", [r"G/SQM", r"g/m2", r"厘米", r"cm", r"克", r"gram"]),("合成纤维", [r"聚酯", r"polyester", r"尼龙", r"nylon", r"涤纶", r"polyamide"]),("环保材料", [r"再生", r"recycled", r"有机", r"organic", r"eco", r"green"]),("混合材料", [r"/", r"%", r"混纺", r"blend", r"mixed"])
]
- 自动化归档
根据识别结果自动创建分类目录并移动文件
3、核心配置
安装核心依赖
pip install paddleocr pillow
4、目录结构
📂 images/ # 原始图片存放目录
📂 images_results/ # 处理结果输出目录
├── 公制单位 # 含重量/尺寸参数的标签
├── 合成纤维 # 含单一化纤成分的标签
├── 环保材料 # 含环保声明的标签
└── 混合材料 # 含多种成分混合的标签
5、执行流程
python fabric_classifier.py
6、代码编写
from pathlib import Path
from paddleocr import PaddleOCR
import re
import os# 初始化 OCR(第一次运行会自动下载模型)
ocr = PaddleOCR(use_angle_cls=True, lang='ch', use_gpu=False) # 中文识别更准确# 分类关键词定义(正则表达式不区分大小写)
CATEGORIES = [("公制单位", [r"G/SQM", r"g/m2", r"厘米", r"cm", r"克", r"gram"]),("合成纤维", [r"聚酯", r"polyester", r"尼龙", r"nylon", r"涤纶", r"polyamide"]),("环保材料", [r"再生", r"recycled", r"有机", r"organic", r"eco", r"green"]),("混合材料", [r"/", r"%", r"混纺", r"blend", r"mixed"])
]def classify_text(text):text_lower = text.lower() # 统一转为小写便于匹配for category, keywords in CATEGORIES:for pattern in keywords:if re.search(pattern, text_lower, re.IGNORECASE):return categoryreturn "待分类"def ocr_and_classify(image_path):# 关键修复1:确保传入字符串路径result = ocr.ocr(str(image_path), cls=True)all_text = ""# 安全处理OCR结果if result and result[0]:for line in result[0]:if len(line) >= 2 and isinstance(line[1], (list, tuple)):word = line[1][0]all_text += word + " "print(f"识别出的文字:{all_text.strip()}")category = classify_text(all_text)print(f"分类结果:{category}")return categoryif __name__ == '__main__':# 输入输出路径设置ROOT_PATH = Path('./images').resolve()OUTPUT_DIR = ROOT_PATH.parent / f"{ROOT_PATH.name}_results"# 确保输入路径存在if not ROOT_PATH.exists():print(f"错误:输入目录不存在 {ROOT_PATH}")exit(1)# 遍历所有图片for image_path in ROOT_PATH.rglob('*.*'):if image_path.suffix.lower() in ('.jpg', '.png', '.jpeg'):# 进行分类category = ocr_and_classify(image_path)# 构建目标路径target_dir = OUTPUT_DIR / categorytarget_dir.mkdir(parents=True, exist_ok=True)# 移动文件(关键修复2:正确路径操作)new_path = target_dir / image_path.nametry:os.rename(str(image_path), str(new_path))print(f"文件移动成功:{image_path} → {new_path}")except Exception as e:print(f"文件移动失败:{str(e)}")
7、结果核查
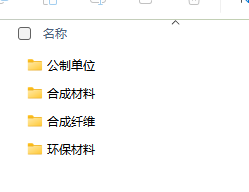
分类成功

感谢大佬指正 小Monkey
如果你觉得有用的话,就留个赞吧!蟹蟹