【暗光图像增强】【基于CNN的方法】2020-AAAI-EEMEFN
EEMEFN:Low-Light Image Enhancement via Edge-Enhanced Multi-Exposure Fusion Network
EEMEFN:基于边缘增强多重曝光融合网络的低光照图像增强
AAAI 2020

论文链接
0.论文摘要
本研究专注于极低光照条件下的图像增强技术,旨在提升图像亮度并揭示暗部隐藏信息。近年来,图像增强方法取得了显著进展,但现有技术仍存在三大问题:(1) 低照度图像通常具有高对比度特征,现有方法难以在极暗或极亮区域恢复图像细节;(2) 当前方法无法精确校正低照度图像色偏;(3) 当物体边缘模糊时,逐像素损失函数会等同处理不同物体的像素值,导致生成图像边缘模糊。本文提出双阶段边缘增强多曝光融合网络(EEMEFN),第一阶段通过多曝光融合模块解决高对比度与色偏问题:从单幅图像合成不同曝光时长的图像序列,融合各光照条件下曝光良好的区域以重构精确的正常光照图像,从而从极端噪化的低照度图像中生成色彩准确的真实初始图像;第二阶段引入边缘增强模块,借助边缘信息优化初始图像,使得在最小化逐像素损失时能重建出边缘锐利的高品质图像。在See-in-the-Dark数据集上的实验表明,EEMEFN方法实现了最先进的性能。
1.引言
优质图像对于计算机视觉任务(如视频监控与目标检测)至关重要。然而,极端低光环境下捕获的图像可能导致暗部信息丢失,并产生异常噪声与色偏。此类低质量图像会显著降低计算机视觉方法的性能(Zhu等,2017;Long、Shelhamer与Darrell,2015),这些方法高度依赖于输入图像的质量。因此,低光照图像增强在计算机视觉领域获得了日益增长的关注。本工作专注于解决低光照图像增强问题,旨在减少色彩偏差并揭示暗区的隐藏信息。
文献中已有大量尝试致力于解决低光照图像增强问题。传统技术(Lee、Lee和Kim 2013;Land 1977)通过提升低数值像素使其服从自然分布。基于深度学习的方法则通过设计深度模型来恢复高质量图像(Chen等2018;Lore、Akintayo和Sarkar 2017)。尽管这些方法取得了显著进展,但由于三个主要问题,增强极端低光照图像仍然具有挑战性:首先,当低光照图像存在高对比度的曝光不足或过度区域时,难以建立从原始传感器数据到图像的一对一映射关系,现有方法无法从极暗或过亮区域有效恢复曝光良好的细节,导致生成图像模糊且噪声明显;其次,缺乏充分曝光的图像信息时,现有模型可能因低光照图像与真实图像间的色彩偏差而产生色偏;第三,逐像素损失函数会模糊边缘——当低光图像中物体边缘不清晰时,这种损失会破坏细节。逐像素损失对所有像素平等加权,忽略了空间分布特性。例如,L1或L2损失会通过邻近像素平均值或可能颜色的中位数来实现最小化(Isola等2017)。
本文提出边缘增强多曝光融合网络(EEMEFN)以增强极暗光图像并恢复真实图像细节。该方法将图像增强过程分解为两个阶段:第一阶段设计多曝光融合(MEF)模块解决高对比度和色偏问题。为实现高对比度暗光图像的曝光均衡,需对不同区域分配差异化曝光时间——例如亮部区域所需曝光时间短于暗部区域。我们从单张暗光图像生成具有不同曝光时间的多曝光图像序列,特别设计了融合块以互补方式整合该序列中各图像的理想曝光区域,从而使MEF模块可生成高质量初始图像并推导出更接近真实场景的颜色分布。第二阶段引入边缘增强(EE)模块处理边缘问题:首先从初始图像中预测具有精细结构的边缘信息;随后EE模块通过结合图像内容的全局特征与边缘信息的局部特征来增强初始图像。我们在See-in-the-Dark数据集(Chen等人,2018)上评估EEMEFN,定量结果显示该方法优于现有技术——例如在Sony子集上峰值信噪比(PSNR)达到29.60 dB(对比Chen等人方案的28.88 dB),在Fuji子集上将结构相似性(SSIM)从0.680提升至0.723。定性分析表明本方法可生成纹理丰富、边缘锐利的更自然结果。
综上所述,我们作出如下贡献:
• 提出创新的多曝光融合模块与融合块结构,通过整合不同光照条件下的生成图像,有效解决高对比度与色偏问题;
• 设计边缘增强模块以强化图像的锐利边缘与精细结构;
• 实验结果表明,所提方法实现了最先进的性能表现。此外,通过消融实验验证了各模块的有效性。
2.相关工作
弱光图像增强
在极低光照条件下捕获的弱光图像无疑会降低计算机视觉算法的性能(Ying等,2017)。因此,学界提出了多种弱光图像增强方法以恢复高质量图像。传统方法可分为两大类:基于直方图的方法(Lee、Lee和Kim,2013)与基于视网膜理论的方法(Land,1977)。例如,直方图均衡化(Cheng和Shi,2004)通过数学映射将全局图像直方图调整为简单分布,但这些方法对像素的修复未考虑邻域信息。基于视网膜理论的方法(Guo,2016)先根据理论估算光照图,再利用构建的光照图增强像素。Ying、Li和Gao(2017)提出基于单图动态调整曝光时间,结合光照估计技术进行图像融合。但对于存在严重噪声的极暗图像,其光照图的准确估算仍具挑战性。
近年来,基于深度学习的方法在图像增强领域取得了显著进展,涵盖去模糊(Aittala和Durand 2018)、去噪(Godard、Matzen与Uyttendaele 2018)及低光照增强(Lv等2018)等方向。LLNet(Lore、Akintayo和Sarkar 2017)由对比度增强模块与去噪模块构成;LLCNN(Tao等2017)采用特殊设计的卷积模块以利用多尺度特征图增强图像;Retinex-Net(Wei等2018)包含分解网络Decom-Net与照度调整网络Enhance-Net;CAN(Chen、Xu和Koltun 2017)则逼近多种处理算子。与现有方法处理sRGB图像不同,Chen等(2018)基于原始传感器数据,采用全卷积网络(Long、Shelhamer和Darrell 2015)实现极低光图像增强。尽管这些方法可产生令人满意的结果,但因极低光图像的高对比度和严重色偏,也可能生成低质量图像。除单帧增强外,多帧方法通过采集更多信息可解决这些问题(Mildenhall等2018;Hasinoff等2016),例如Godard等(2018)提出并行循环网络融合多帧图像,其核心在于如何整合序列帧信息。本文提出的多曝光融合模块,可从单幅图像生成不同光照条件影像并智能融合曝光良好的信息,该网络能有效降低色偏,生成高质量图像。
边缘检测
边缘检测是最基础的计算视觉任务之一。现有方法可大致分为三类:第一类通常通过人工设计多种滤波器生成边缘图,如(Canny 1986)在图像梯度提取过程中引入了高斯平滑;第二类基于人工设计特征采用数据驱动模型预测边缘,如结构化边缘检测方法(Dollár and Zitnick 2015)利用随机决策森林学习边缘块结构;第三类深度学习方法从原始数据中学习复杂特征表示并取得显著进展,如HED模型(Xie and Tu 2015)通过多尺度侧输出实现端到端边缘检测,DeepEdge(Bertasius, Shi, and Torresani 2015)通过分类分支与回归分支输出融合生成最终结果,DeepContour(Shen et al. 2015)将边缘数据划分为子类并采用不同参数拟合,RCF(Liu et al. 2017)整合所有卷积层特征实现实时图像到图像预测。Liu等(2018)提出差异化深度监督机制,针对高层与低层特征学习采用不同损失函数优化。使用L1及均方误差损失的图像增强方法易导致锐利边缘模糊、线条破坏等细节损失。鉴于人眼视觉系统对边缘高度敏感,保持结构信息对图像重建任务至关重要。受前人研究启发,我们提出边缘增强模块,在低光照图像增强任务中利用边缘信息重建具有丰富纹理与局部结构的高质量图像。
3.方法
边缘增强多重曝光融合网络(EEMEFN)旨在通过恢复良好曝光的图像细节、降低噪声与色彩偏差,同时保持锐利边缘,实现极端低照度图像的增强。如图1所示,本方法EEMEFN包含两大组件:多重曝光融合模块与边缘增强模块。
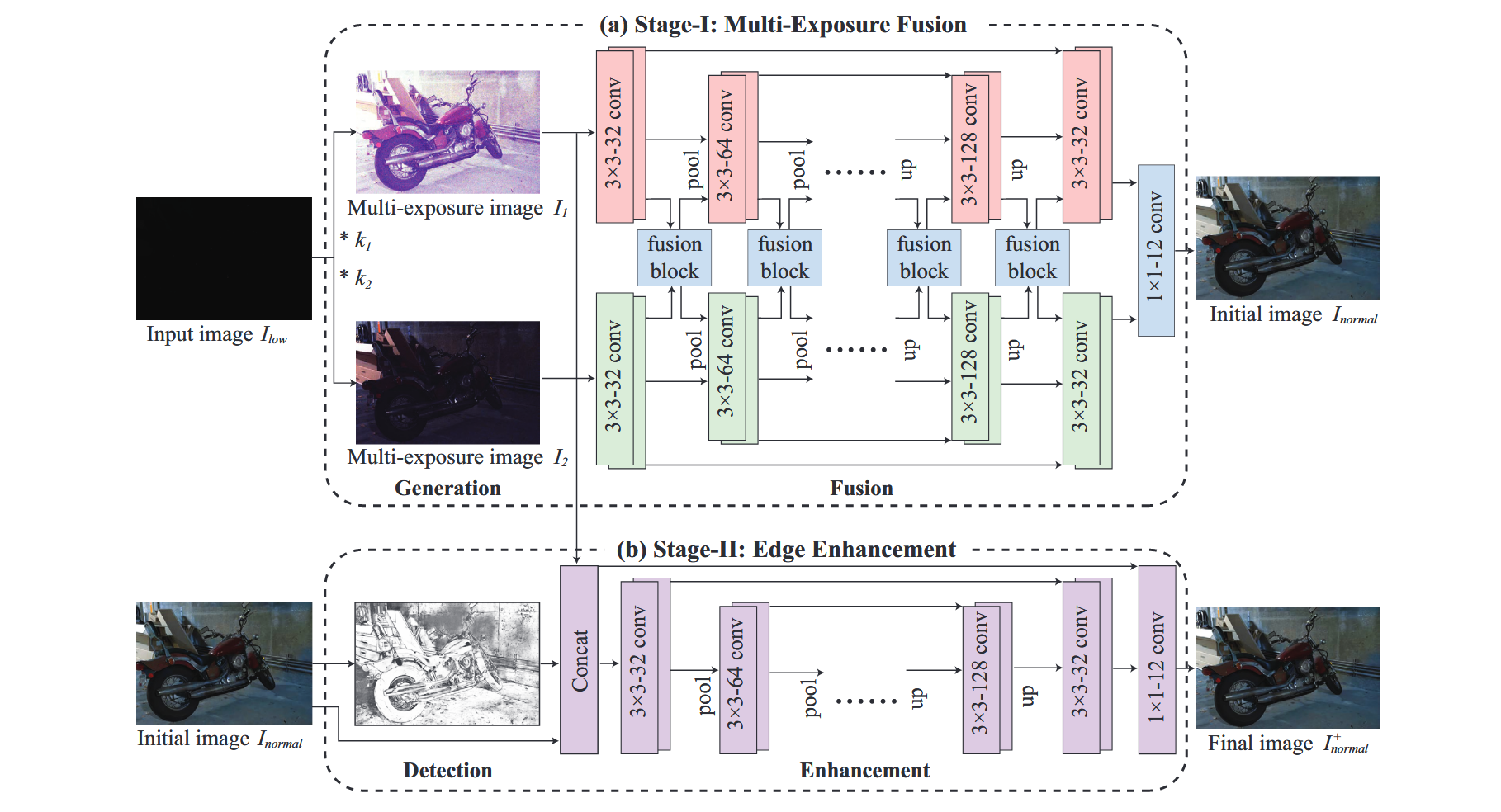
图1:低光照图像增强框架展示。提出的EEMEFN方法包含两个阶段:(a)多曝光融合与(b)边缘增强。多曝光融合模块首先生成不同光照条件下的多幅图像,随后将其融合为一张高质量初始图像;边缘增强模块从初始图像中提取边缘图,通过融合边缘信息得到最终增强结果。
阶段一:多重曝光融合
多曝光融合(MEF)模块用于将不同曝光比的图像融合为一张高质量初始图像。如图1(a)所示,MEF模块包含生成与融合两个主要步骤:在生成步骤中,我们通过不同放大比例缩放像素值,制作出一组不同光照条件下的多曝光图像,这些合成图像可在原始图像欠曝的区域实现良好曝光;在融合步骤中,我们将合成图像中的局部信息融入已包含良好曝光信息的初始图像。特别地,我们提出通过融合块共享不同卷积层获取的图像特征,以充分挖掘合成图像中的有效信息。
生成。给定一张原始低亮度图像 I l o w ∈ R H × W × 1 I_{low} ∈ \mathbb{R}^{H×W ×1} Ilow∈RH×W×1及一组曝光比例 { k 1 , k 2 , . . . , k N } \{k_1, k_2, ..., k_N\} {k1,k2,...,kN},可生成多重曝光图像集合 I = { I 1 , I 2 , . . . , I N } I = \{I_1, I_2, ..., I_N\} I={I1,I2,...,IN}。其中第 i i i幅图像定义如下:
I i = C l i p ( I l o w ∗ k i ) , I_i=Clip(I_{low}*k_i), Ii=Clip(Ilow∗ki),
其中 C l i p ( x ) = m i n ( x , 1 ) Clip(x) = min(x, 1) Clip(x)=min(x,1)函数对图像进行逐像素裁剪。我们将 k ∗ k^∗ k∗定义为低光图像与参考图像之间的曝光时间比。需要注意的是,Chen等人(2018)仅通过指定曝光比为 k ∗ k^∗ k∗生成单张图像。考虑到多曝光图像中存在信息冗余,将所有图像输入我们的模型可能不会提升性能,反而会增加计算成本。
融合。在此步骤中,多曝光融合(MEF)模块将生成的系列多曝光图像 I = { I 1 , I 2 , . . . , I N } I = \{I_1, I_2, ..., I_N\} I={I1,I2,...,IN}中曝光良好的区域进行组合,从而获得初始图像 I n o r m a l I_{normal} Inormal:
I n o r m a l = M E N ( I 0 , I 1 , . . . , I N ) . I_{normal}=MEN(I_0,I_1,...,I_N). Inormal=MEN(I0,I1,...,IN).
图1(a)展示了我们多曝光融合模块的架构,该模块可接收不同光照条件下的图像输入。我们的架构能够轻松扩展至多图像处理。本文以两幅图像为例演示该框架。
首先,每幅图像均由具有相同架构的U-net分支处理(Ronneberger, Fischer和Brox,2015年)。我们在U-net中添加跳跃连接以辅助不同尺度细节的重建。
其次,我们提出融合模块以结合不同分支获取的图像特征,通过互补方式充分利用有价值信息(见图2)。该融合模块基于一种置换不变技术(Aittala和Durand 2018),并在特征间进行更多聚合操作。因此,MEF模块能够从暗区恢复精确的图像细节,并使色彩分布更接近真实值。每个融合模块接收来自 N N N个分支的 N N N组图像特征 f 1 , f 2 , . . . , f N ∈ R c × h w f_1, f_2, ..., f_N ∈ \mathbb{R}^{c×hw} f1,f2,...,fN∈Rc×hw作为输入,通过最大值与平均值运算提取有效信息。
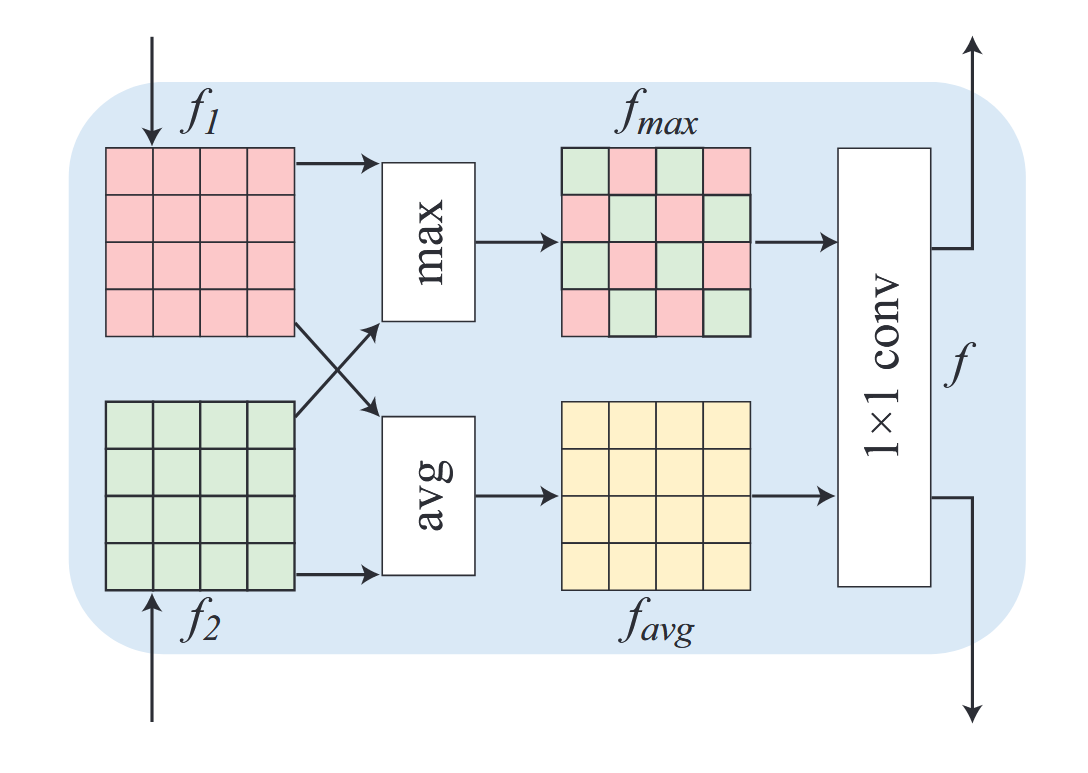
图2:所提出的融合块架构。
f m a x = max ( f 1 , f 2 , . . . , f N ) , f_{max}=\max(f_1,f_2,...,f_N), fmax=max(f1,f2,...,fN),
f a v g = ( f 1 + f 2 + . . . + f N ) / N . f_{avg}=(f_1+f_2+...+f_N)/N. favg=(f1+f2+...+fN)/N.
随后,我们将特征 f m a x f_{max} fmax和 f a v g f_{avg} favg转换至输入特征空间,并将其回馈至各分支。
f = W ∗ [ f m a x , f a v g ] , f ∈ R c × h w , W ∈ R c × 2 c , f=W*[f_{max},f_{avg}],f\in\mathbb{R}^{c\times hw},W\in\mathbb{R}^{c\times2c}, f=W∗[fmax,favg],f∈Rc×hw,W∈Rc×2c,
其中 [ ⋅ , ⋅ ] [·, ·] [⋅,⋅]表示连接操作, f f f为输出特征, W W W为学习得到的权重矩阵。
最终,所有分支的最后一层特征被拼接在一起,并通过1×1卷积层进行联合学习,以生成所需的输出。
损失函数定义为我们的MEF模块输出 I n o r m a l I_{normal} Inormal与真实值之间的L1损失:
l o s s F u s i o n = ∥ I n o r m a l − I g t ∥ 1 . loss_{Fusion}=\|I_{normal}-I_{gt}\|_1. lossFusion=∥Inormal−Igt∥1.
第二阶段:边缘增强
边缘增强(EE)模块旨在优化由多曝光融合(MEF)模块生成的初始图像。如图1(b)所示,该模块包含两个核心步骤:检测与增强。在检测阶段,我们首先从初始图像(而非输入图像)中提取边缘图。由于输入图像及多曝光序列存在严重噪声,直接边缘提取极具挑战性。MEF模块能有效降噪并生成具有精确边缘图的清晰常光图像。在增强阶段,EE模块通过利用边缘信息对初始图像进行优化:基于预测边缘图的引导,可生成色彩一致且表面平滑的物体,同时恢复丰富的纹理细节与锐利边缘。
检测。在此步骤中,我们采用边缘检测网络(Liu等人,2017)预测归一化图像 I n o r m a l I_{normal} Inormal的边缘 E ∈ R H × W × 1 E ∈ \mathbb{R}^{H×W ×1} E∈RH×W×1,即 E = D e t e c t i o n ( I n o r m a l ) E = Detection(I_{normal}) E=Detection(Inormal)。随后利用边缘信息指导高质量图像的重建。该边缘检测网络包含五个阶段,每个阶段均利用卷积层的全部激活进行像素级预测( E 1 、 E 2 、 E 3 、 E 4 、 E 5 E_1、E_2、E_3、E_4、E_5 E1、E2、E3、E4、E5),最终通过融合层精细整合各阶段的CNN特征。该网络能够获取精确的边缘图E。
鉴于边缘/非边缘像素的分布存在严重不均衡,我们采用两个类别平衡权重 α α α和 β β β来抵消这种不平衡。预测边缘图 E i E_i Ei与真实边缘图 E g t = ( e j , j = 1 , . . . , ∣ E g t ∣ ) , e j = { 0 , 1 } E_{gt} = (e_j, j = 1, ..., |E_{gt}|), e_j = \{0, 1\} Egt=(ej,j=1,...,∣Egt∣),ej={0,1}之间的边缘损失被定义为基于像素标签的加权交叉熵损失:
l e d g e ( E i , E g t ) = − α ∑ j ∈ E g t + log Pr ( e j = 1 ∣ i ) − β ∑ j ∈ E g t − log ( 1 − Pr ( e j = 1 ∣ i ) ) , \begin{aligned}l_{edge}(E_{i},E_{gt})&=-\alpha\sum_{j\in E_{gt}^+}\log\Pr(e_j=1|i)\\&-\beta\sum_{j\in E_{gt}^-}\log(1-\Pr(e_j=1|i)),\end{aligned} ledge(Ei,Egt)=−αj∈Egt+∑logPr(ej=1∣i)−βj∈Egt−∑log(1−Pr(ej=1∣i)),
α = ∣ E g t − ∣ ∣ E g t + ∣ + ∣ E g t − ∣ , β = ∣ E g t + ∣ ∣ E g t + ∣ + ∣ E g t − ∣ , \alpha=\frac{|E_{gt}^-|}{|E_{gt}^+|+|E_{gt}^-|},\beta=\frac{|E_{gt}^+|}{|E_{gt}^+|+|E_{gt}^-|}, α=∣Egt+∣+∣Egt−∣∣Egt−∣,β=∣Egt+∣+∣Egt−∣∣Egt+∣,
其中 ∣ E g t + ∣ |E^+_{gt}| ∣Egt+∣和 ∣ E g t − ∣ |E^−_{gt}| ∣Egt−∣分别表示边缘与非边缘真实标签集的大小, e j = 1 e_j = 1 ej=1代表像素j处的边缘点, P r ( e j = 1 ∣ i ) Pr(e_j = 1|i) Pr(ej=1∣i)是像素 j j j在第i阶段的预测值。损失函数通过聚合不同阶段及融合层的损失函数计算得出:
l o s s D e t e c t i o n = ∑ i = 1 5 l e d g e ( E i , E g t ) + l e d g e ( E , E g t ) . loss_{Detection}=\sum_{i=1}^5l_{edge}(E_i,E_{gt})+l_{edge}(E,E_{gt}). lossDetection=i=1∑5ledge(Ei,Egt)+ledge(E,Egt).
为训练边缘检测网络,我们生成一组输入-输出对。输入为由MEF模块生成的初始图像,输出则采用Canny边缘检测器(Canny 1986)计算得到的真实图像对应边缘图。相较于Canny算法,我们的EE模块能够从模糊初始图像中提取有效边缘,并实现更优性能。
增强。增强步骤采用UNet架构,以多曝光图像集合 I = { I 1 , I 2 , . . . , I N } I = \{I_1, I_2, ..., I_N\} I={I1,I2,...,IN}、初始图像 I n o r m a l I_{normal} Inormal及边缘图 E E E作为输入,通过整合这些图像生成最终增强图像 I n o r m a l + I^+_{normal} Inormal+。
I n o r m a l + = E n h a n c e m e n t ( I , I n o r m a l , E ) . I_{normal}^+=Enhancement(I,I_{normal},E). Inormal+=Enhancement(I,Inormal,E).
增强器利用来自图像的全局像素信息以及边缘图中的局部边缘信息。增强步骤的损失函数定义为:
l o s s E n h a n c e m e n t = ∥ I n o r m a l + − I g t ∥ 1 . loss_{Enhancement}=\|I_{normal}^+-I^{gt}\|_1. lossEnhancement=∥Inormal+−Igt∥1.
我们还评估了其他辅助损失函数,例如边缘保留损失和感知损失。然而,边缘保留损失会显著降低性能,而感知损失则无法提升性能。
4.实验
在本节中,为验证所提方法的性能,我们在极低光图像增强任务使用的See-in-the-Dark数据集(Chen等人,2018)上对EEMEFN模型进行了定量与定性评估。本方法基于Tensorflow框架和Paddlepaddle框架实现。
数据集。"暗光视觉数据集"包含两个图像子集:索尼子集和富士子集。索尼子集由索尼α7S II拍摄,包含2697张原始短曝光图像和231张长曝光图像;富士子集由富士X-T2拍摄,包含2397张原始短曝光图像和193张长曝光图像。索尼子集分辨率为4240×2832,富士子集为6000×4000。原始图像的曝光时间设定为1/30至1/10秒,对应的长曝光参考图像(真值)则采用100至300倍于原始图像的曝光时长拍摄。
实现细节。我们使用ADAM优化器(Kinga和Adam,2015)对EEMEFN进行5000轮训练,初始学习率为 1 0 − 4 10^{−4} 10−4,并在2500轮后降至 5 ∗ 1 0 − 5 5∗10^{−5} 5∗10−5,3500轮后降至 1 0 − 5 10^{−5} 10−5。参照Chen等人(2018)的方法,所有原始图像均通过减去黑电平进行预处理。MEF模块生成曝光比为 { 1 , k ∗ / 2 } \{1, k^∗/2\} {1,k∗/2}的两幅图像。我们的模型以这两幅图像及其对应的长曝光图像作为输入-输出对进行训练。实验中,我们首先以长曝光图像作为输入预训练边缘检测网络,再使用MEF模块生成的图像对网络进行微调。该训练策略使模型收敛速度显著快于从头开始训练,并取得更优性能。
定量评估
我们将本方法与现有先进技术进行比较,包括CAN(Chen、Xu和Koltun 2017)以及Chen等人(2018)采用的U-net网络。同时我们引入了一个基准模型,该模型采用相同结构的U-net网络,并以多曝光拼接图像作为输入。本文报告的结果基于TensorFlow框架实现,因多数对比方法(Chen、Xu和Koltun 2017;Chen等人 2018)均采用此框架。
表1报告了低光照图像增强的量化结果。可以看出,基线模型性能优于CAN和Chen等人的方法,这证明了采用多曝光低光照图像的有效性。此外,得益于融合模块,MEF方法相较基线模型取得了更优的性能。我们的EEMEFN方法在索尼和富士数据集上的PSNR指标分别比基线模型高出0.54 dB和0.43 dB,这表明通过交换局部信息并结合边缘信息,我们的EEMEFN模型能够充分利用原始图像的全局特征和边缘信息的局部特征。如该表所示,我们的方法在索尼和富士数据集上均取得了超越其他方法的最优性能。与(Chen等人,2018)相比,EEMEFN将索尼数据集的PSNR从28.88 dB提升至29.60 dB,富士数据集从26.61 dB提升至27.38 dB;索尼数据集的SSIM从0.787提升至0.795,富士数据集从0.680提升至0.723。我们采用LPIPS指标(Zhang等人,2018)衡量感知距离,相较(Chen等人,2018),索尼数据集的LPIPS距离从0.476降至0.458,富士数据集从0.586降至0.547。实验结果表明,我们提出的EEMEFN方法在低光照图像增强任务中实现了PSNR和SSIM指标的最佳性能。
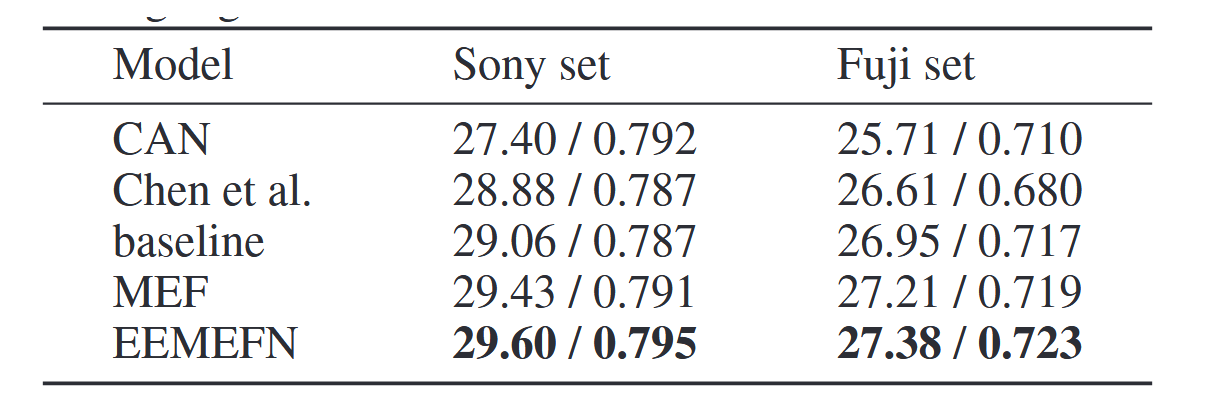
表1:低光照图像增强算法的PSNR/SSIM量化评估结果,最优数据以加粗形式标注。
定性评估
图3展示了一些具有代表性的视觉对比结果。我们呈现了经处理的输入图像、真实参考图像、Chen等人(2018)与EEMEFN方法的结果,以及增强图像与真实参考图像之间的误差图。需注意输入图像经传统流程处理并进行了线性缩放以匹配参考图像,从而获得更好的视觉效果。误差图用于可视化RGB空间中像素级的 l 1 l_1 l1距离。红色与绿色矩形框标明了对应放大子图的提取区域。
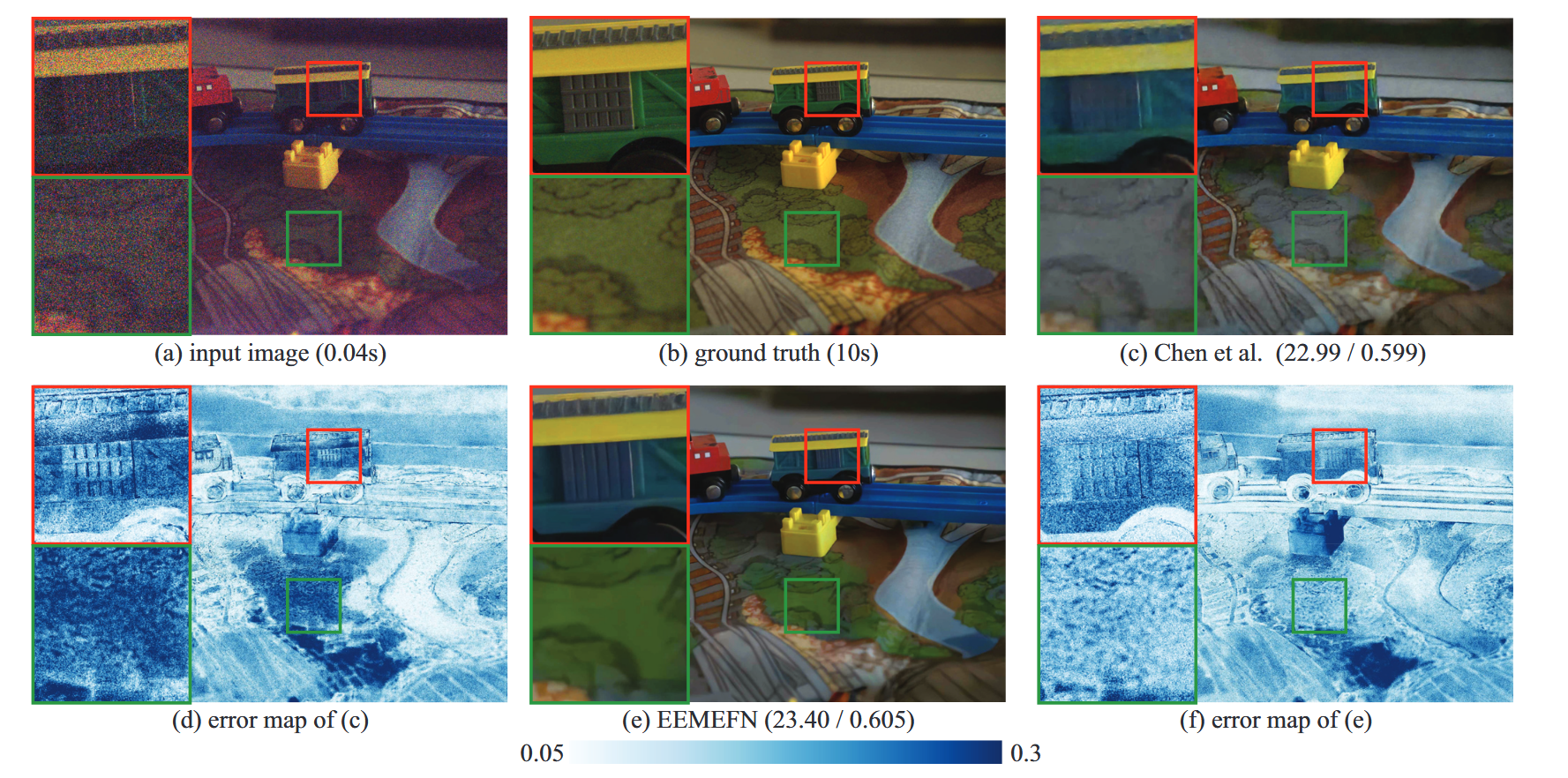
图3:U-net与我们的EEMEFN在极低光图像增强中的定性效果对比。括号内数值代表PSNR与SSIM指标。
如我们所见,在极低光照条件下拍摄的输入图像存在信息丢失、高对比度和色彩偏差问题。尽管Chen等人(2018)的模型能有效处理噪声,但输出图像仍存在模糊现象。严重失真的内容(如色彩与边缘)无法得到充分恢复——例如图3©中列车轮廓不够清晰,且代表植被的绿色完全缺失。当不同物体的边缘模糊时,此类失真难以有效消除。相比之下,我们提出的EEMEFN方法通过利用边缘信息,既能重建高质量图像又可保持局部结构。图3(f)显示本方法生成的误差图数值较小,表明EEMEFN模型生成的图像质量更高且色彩失真更小。通过对比图3(d)(f)绿色矩形框的细节可明确看出,本方法能还原更准确的色彩,并使色彩分布更接近真实情况。
综上所述,我们提出的模型能够充分利用多曝光图像中的有效信息实现色彩复原,同时保留物体结构及物体间边界等更为锐利的边缘特征。
消融实验
为全面理解我们的模型,我们进行了消融实验以验证各组件所获得的改进效果。
曝光比例。曝光比例的选择对我们的MEF模块至关重要。首先,我们评估了不同曝光比例的影响。如表2所示,当生成更多多重曝光图像时,我们能获得更高的性能表现。虽然曝光比例 k = 1 k=1 k=1生成的图像效果最差,但该图像能提供更多欠曝信息。包含k=1的曝光比例组合能产生更优结果。我们发现,采用 { 1 , k ∗ / 2 } \{1, k^∗/2\} {1,k∗/2}或 { 1 , k ∗ / 2 , k ∗ } \{1, k^∗/2, k^∗\} {1,k∗/2,k∗}曝光比例组合的MEF和EEMEFN模型均可实现最佳性能。但考虑到三幅图像会浪费计算资源且无法显著提升性能,因此在后续实验中我们选择 { 1 , k ∗ / 2 } \{1, k^∗/2\} {1,k∗/2}作为曝光比例组合。
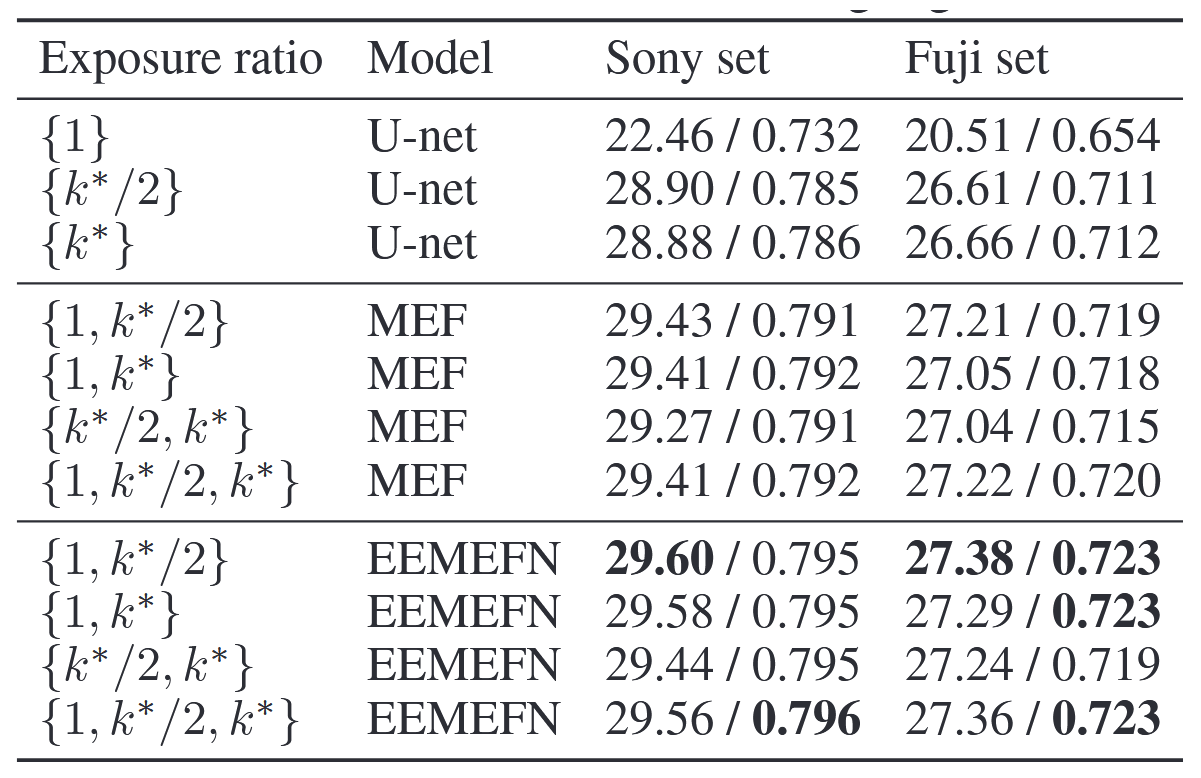
表2:曝光比例选择的消融研究。PSNR/SSIM指标下的最佳结果以加粗形式标出。
融合块。其次,我们研究了融合块及其变体的有效性。为此,我们进行了以下实验:(1)基线方法,采用U-net架构,在输入网络前将多曝光图像进行拼接;(2)基础MEF模块,即不含融合块的多曝光基础融合模块,两个U-net分支的信息仅在最后一层融合;(3)MEF(最大值),采用带最大值操作的融合块;(4)MEF(平均值),采用带平均值操作的融合块;(5)MEF(最大值+平均值),在融合块中同时采用最大值和平均值操作。
表3展示了融合模块及其变体的评估结果。需注意所有模型均以曝光比为 { 1 , k ∗ / 2 } \{1, k^∗/2\} {1,k∗/2}的两幅多重曝光图像作为输入。可见基础MEF取得了略优的性能优于基线水平,因为基础MEF对每张图像单独处理,这会增加图像特征的宽度(通道数)。此外,MEF(最大值)和MEF(平均值)表现优于基础MEF,因为它们在两条分支间传递信息以充分利用局部信息。通过结合两种聚合操作,MEF(最大值+平均值)可进一步提升性能。
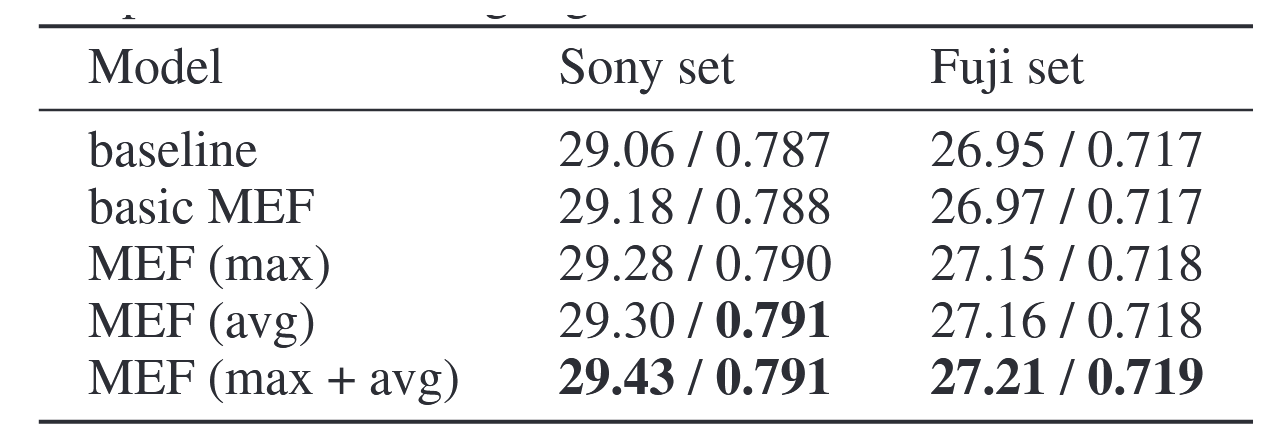
表3:融合模块设计的消融研究。最佳性能以粗体标出。
边缘增强。第三,我们研究了边缘增强模块的网络设计,例如边缘图和初始图像的重要性。我们进行了以下实验:(1)MEF,这是我们EEMEFN模型的第一阶段。(2)MEF + 边缘损失,即在MEF模块后加入边缘保留损失和L1损失:
l o s s = ∥ I n o r m a l − I g t ∥ 1 + λ ∗ l e d g e ( D e t e c t i o n ( I n o r m a l ) , E g t ) . loss=\|I_{normal}-I^{gt}\|_1+\lambda*l_{edge}(Detection(I_{normal}),E_{gt}). loss=∥Inormal−Igt∥1+λ∗ledge(Detection(Inormal),Egt).
(3) EEMEFN( E + I n o r m a l E + I_{normal} E+Inormal),仅以边缘信息和初始图像作为输入。
(4) EEMEFN( E + I E + I E+I),仅以边缘信息和多曝光图像作为输入。
(5) EEMEFN( E + I + I n o r m a l E + I + I_{normal} E+I+Inormal),以边缘信息、多曝光图像及初始图像作为输入。
表4展示了EE模块在PSNR/SSIM指标上的评估结果。可以看出,引入边缘信息能进一步提升性能。通过边缘信息增强初始图像的效果优于边缘感知平滑损失函数,这表明边缘增强模块能利用边缘图提取更多信息。EEMEFN模型间的对比表明,初始图像是对性能具有显著影响极为关键的因素。通过向网络输入多曝光图像,该网络能够借助边缘图和初始图像提取更多信息。我们提出的EEMEFN所实现的改进证明了边缘增强模块的有效性,该模块根据边缘信息对初始图像进行增强。

表4:边缘增强网络设计的消融研究。最佳性能以粗体标出。
视觉对比。最后,我们在图4中对基线方法、MEF、EEMEFN以及真实值进行了可视化对比。可以看出基线方法存在色彩偏差问题(例如书籍颜色),且书籍标题与整体边缘清晰度不足(图4(a))。MEF通过融合多曝光图像中的高质量特征来减轻色彩偏差(图4(b)),但由于在物体边缘不明确时可能对不同对象的相邻像素进行平均处理,其结果仍存在视觉模糊。EEMEFN模型在边缘图的引导下能够重建出边缘锐利、表面平滑的高质量图像(图4©)。实验结果表明,MEF与EE方法能有效提升细节恢复、减少色彩偏差并增强边缘,实现了性能的持续改进。

图4:基线方法、MEF与EEMEFN的定性对比。
5.结论
在本研究中,我们提出了一种新颖的边缘增强多曝光融合网络用于低光照图像增强。多曝光融合模块通过生成并融合不同光照条件下的多曝光图像,有效恢复曝光良好的图像细节,同时降低噪声方差与色彩偏差。此外,我们引入的边缘增强模块通过融合低光照图像与边缘信息,生成高质量图像。实验结果表明,本模型在PSNR和SSIM指标上均优于现有最优方法。所提方法生成的图像纹理丰富、边缘锐利。未来我们将开发更强大的架构以实现实时处理,并将该模型应用于其他增强任务(如低光照视频增强)。
6.引用文献
- Aittala, M., and Durand, F. 2018. Burst image deblurring using permutation invariant convolutional neural networks. In Proceedings of the European Conference on Computer Vision, 731–747.
- Bertasius, G.; Shi, J.; and Torresani, L. 2015. Deepedge: A multi-scale bifurcated deep network for top-down contour detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 4380–4389.
- Canny, J. 1986. A computational approach to edge detection. IEEE Transactions on Pattern Analysis and Machine Intelligence 8(6):679–698.
- Chen, C.; Chen, Q.; Xu, J.; and Koltun, V. 2018. Learning to see in the dark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 3291–3300.
- Chen, Q.; Xu, J.; and Koltun, V. 2017. Fast image processing with fully-convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, volume 9, 2516–2525.
- Cheng, H., and Shi, X. 2004. A simple and effective histogram equalization approach to image enhancement. Digital signal processing 14(2):158–170.
- Doll ́ar, P., and Zitnick, C. L. 2015. Fast edge detection using structured forests. IEEE transactions on pattern analysis and machine intelligence 37(8):1558–1570.
- Godard, C.; Matzen, K.; and Uyttendaele, M. 2018. Deep burst denoising. In Proceedings of the European Conference on Computer Vision, 538–554.
- Guo, X. 2016. Lime: a method for low-light image enhancement. In Proceedings of the ACM on Multimedia Conference, 87–91. ACM.
- Hasinoff, S. W.; Sharlet, D.; Geiss, R.; Adams, A.; Barron, J. T.; Kainz, F.; Chen, J.; and Levoy, M. 2016. Burst photography for high dynamic range and low-light imaging on mobile cameras. ACM Transactions on Graphics 35(6):192.
- Isola, P.; Zhu, J.-Y.; Zhou, T.; and Efros, A. A. 2017. Imageto-image translation with conditional adversarial networks. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
- Kinga, D., and Adam, J. B. 2015. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations, volume 5. Land, E. H. 1977. The retinex theory of color vision. Scientific American 237(6):108–129.
- Lee, C.; Lee, C.; and Kim, C.-S. 2013. Contrast enhancement based on layered difference representation of 2d histograms. IEEE Transactions on Image Processing 22(12):5372–5384.
- Liu, Y.; Cheng, M.-M.; Hu, X.; Wang, K.; and Bai, X. 2017. Richer convolutional features for edge detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 5872–5881. IEEE.
- Liu, Y.; Cheng, M.-M.; Bian, J.; Zhang, L.; Jiang, P.-T.; and Cao, Y. 2018. Semantic edge detection with diverse deep supervision. arXiv preprint arXiv:1804.02864.
- Long, J.; Shelhamer, E.; and Darrell, T. 2015. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 3431–3440.
- Lore, K. G.; Akintayo, A.; and Sarkar, S. 2017. Llnet: A deep autoencoder approach to natural low-light image enhancement. Pattern Recognition 61:650–662.
- Lv, F.; Lu, F.; Wu, J.; and Lim, C. 2018. Mbllen: Low-light image/video enhancement using cnns. In British Machine Vision Conference, 220.
- Mildenhall, B.; Barron, J. T.; Chen, J.; Sharlet, D.; Ng, R.; and Carroll, R. 2018. Burst denoising with kernel prediction networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2502–2510.
- Ronneberger, O.; Fischer, P.; and Brox, T. 2015. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical image computing and computer-assisted intervention, 234–241. Springer.
- Shen, W.; Wang, X.; Wang, Y.; Bai, X.; and Zhang, Z. 2015. Deepcontour: A deep convolutional feature learned by positive-sharing loss for contour detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 3982–3991.
- Tao, L.; Zhu, C.; Xiang, G.; Li, Y.; Jia, H.; and Xie, X. 2017. Llcnn: A convolutional neural network for low-light image enhancement. In Visual Communications and Image Processing, 1–4. IEEE.
- Wei, C.; Wang, W.; Yang, W.; and Liu, J. 2018. Deep retinex decomposition for low-light enhancement. arXiv preprint arXiv:1808.04560.
- Xie, S., and Tu, Z. 2015. Holistically-nested edge detection. In Proceedings of the IEEE International Conference on Computer Vision, 1395–1403.
- Ying, Z.; Li, G.; Ren, Y.; Wang, R.; and Wang, W. 2017. A new low-light image enhancement algorithm using camera response model. In Proceedings of the IEEE International Conference on Computer Vision, 3015–3022.
- Ying, Z.; Li, G.; and Gao, W. 2017. A Bio-Inspired Multi-Exposure Fusion Framework for Low-light Image Enhancement. arXiv preprint.
- Zhang, R.; Isola, P.; Efros, A. A.; Shechtman, E.; and Wang, O. 2018. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 586–595.
- Zhu, X.; Wang, Y.; Dai, J.; Yuan, L.; and Wei, Y. 2017. Flow-guided feature aggregation for video object detection. In Proceedings of the IEEE International Conference on Computer Vision.