表记录的检索
1.select语句的语法格式
select 字段列表 from 表名
where 条件表达式
group by 分组字段 [having 条件表达式]
order by 排序字段 [asc|desc];
说明:
from 子句用于指定检索的数据源
where子句用于指定记录的过滤条件
group by 子句用于对检索的数据进行分组
having 子句通常和group by 子句一起使用,用于过滤分组后的统计信息
order by子句用于对检索的数据进行排序处理,默认为升序asc
2.select子句指定字段列表
(1)字段列表可以包含字段名,也可以包含表达式,字段名之间使用逗号分隔,并且顺序可以任意指定
(2)可以为字段列表中的字段名或者表达式指定别名,中间使用as关键字分隔即可
(3)多表查询时,同名字段前必须添加表名前缀,中间使用"."分隔
(4)结果集中的列名为字段列表中的字段名或者表达式名
例如:select version(), now(), pi(), 1+2, null=null, null!=null, null is null;的查询如下:
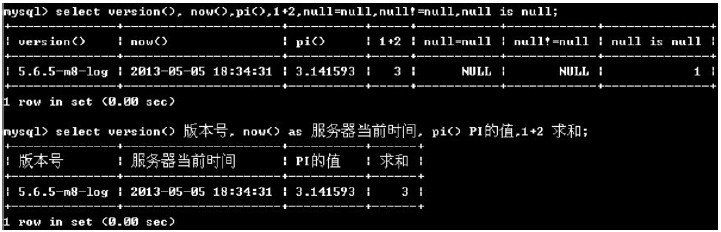
(5)检索表student全部记录
select * from student;
3.使用谓词过滤记录
MYSQL中的两个谓词distinct和limit可以过滤记录
(1)使用谓词distinct过滤结果集中的重复记录
数据库表中不允许出现重复的记录,但这不意味着select的查询结果击中不会出现记录重复的现象。如果需要过滤结果集中重复的记录,可以使用谓词关键字distinct,语法格式如下:
distinct 字段名;
例如:select distinct department_name from classes;
(2)使用谓词limit查询某几行记录
使用select语句时,经常需要返回前几条或者中间某几条记录,可以使用谓词关键字limit实现。语法格式如下:
select 字段列表
from 数据源
limit [start,] length
例如:前三条记录
select * from student limit 0,3; 等效于 select * from student limit 3;
从第二条记录开始的3条记录
select * from choose limit 1,3;
4.使用from指定数据源
在实际应用中,为了避免数据冗余,需要将一张大表划分成若干张小表。但检索数据时,为了更加直观看到所有数据,往往需要将若干张小表缝补连接成成一张大表。连接的方法有两种,一种是在from子句使用连接运算,讲多个数据源按照某种连接条件“缝补”在一起,一种是在where子句中指定连接条件。
通过from指定连接运算的格式如下:
from 表名1 连接类型 join 表名2 on 连接条件;
SQL标准中,连接类型有inner连接和outer连接,而外连接又分为left左外连接,right右外连接以及full完全外连接。
如果表1和表2存在相同意义的字段,则可以通过该字段连接这两张表。例如,在student表中,想要直接看到学生和其班级信息,可以通过班级id把班级信息连接上来。
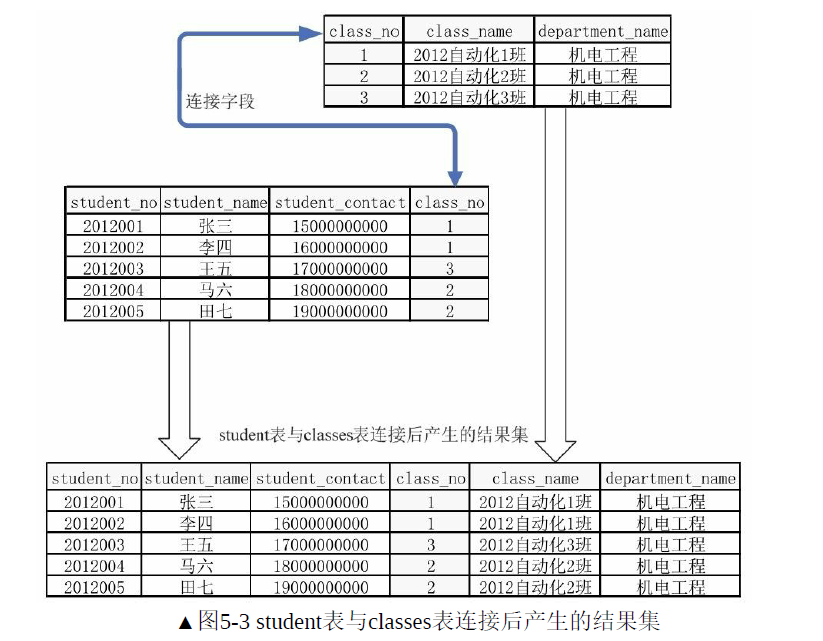
(1)内连接:
from 表1 inner join 表2 on 连接条件
重点:会过滤掉表1和表2的不符合条件的信息
(2)左外连接:
from 表1 left join 表2 on 连接条件
重点:保留表1的全部信息,而表2 不符合的信息则过滤掉,表1如果存在某些匹配不到表2的信息,则该行的表2部分信息都是NULL
(3)右外连接:
from 表1 right join 表2 on 连接条件
重点:保留表2的全部记录,而表1中不符合的信息则过滤掉,表2中如果存在某些匹配不到表1的信息,则该行的表1部分则都是NULL。
(4)全连接:
MYSQL暂不支持全连接运算,不赘述。
5.多表连接
格式如下:
from 表1 连接类型 join 表2 on 连接条件
连接类型 join 表3 on 连接条件
6.使用where子句过滤结果集
(1)单一条件过滤
where 表达式1 比较运算符 表达式2
select * from classes where class_name=‘2012自动化2班’;
(2)is NULL运算
表达式 is [not] NULL
判断表达式的值是否为NULL或者不为NULL
(3)逻辑运算符
逻辑非为符号 !, 一般用于"! 布尔表达式"
例如: select * from course where !(up_limit=60);
等效于: select * from course where up_limit != 60;
(4)and逻辑运算 和 or逻辑运算
布尔表达式1 and|or 布尔表达式2
(5)between … and …
用于判断一个表达式的值是否位于指定的取值范围内
(6)in运算符
in运算符用于判断一个表达式的值是否位于一个离散的数学集合内
格式:表达式 [not] in (数学集合)
例如:select * from student where substring(student_name, 1, 1) in ('张’, ‘田’);
(7)like进行模糊查询
like运算符用于判断一个字符串是否与给定的模式相匹配。模式是一种特殊的字符串,特殊之处在于它不仅包含普通字符,还包含通配符。
格式:字符串表达式 [not] like 模式
通配符:
%(匹配零个或多个字符组成的任意字符串)
_ (匹配任意一个字符)
例如:
检索所有姓张但是名字只有两个字的学生的信息
select * from student where student_name like ‘张_’;
检索姓名中带有’三’的所有学生的信息
select * from student where student_name like ‘%三%’;
7.使用order by排序
order by 字段名1 [asc|desc] […, 字段名n [asc|desc]]
(1)单个排序
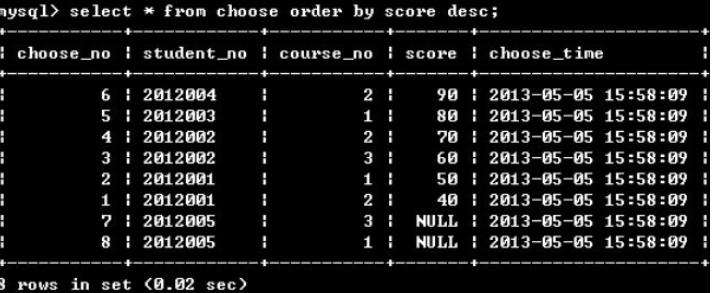
(2)多重排序
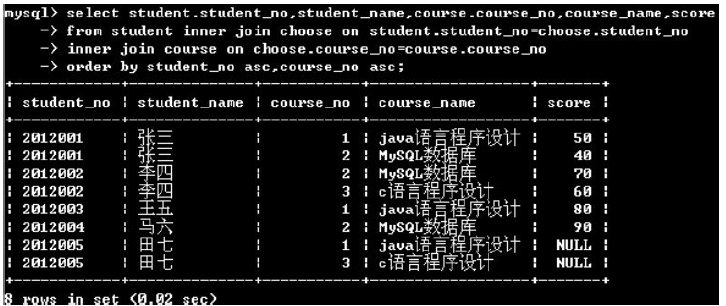
8.使用聚合函数汇总结果集
(1)聚合函数:sum(), avg(), count(), max(),min()
9.使用groupby子句对记录进行分组
格式:group by 字段列表[having 条件表达式][with rollup]
(1)单独使用group by没意义,因为只保留各分组的一条记录
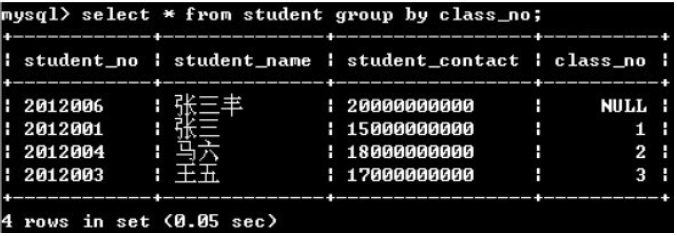
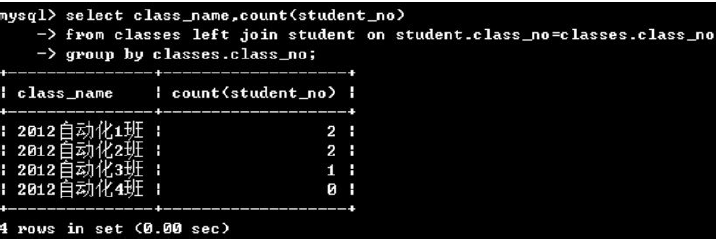
(2)group by + 聚合函数
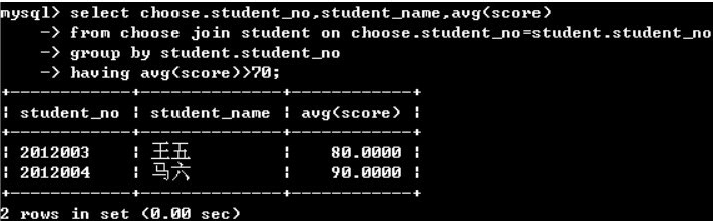
(3)group by +having子句
having子句无法用where代替,因为where和group by和having同时存在的时候,where首先运行,然后group by和having对where运算结果进行过滤筛选。
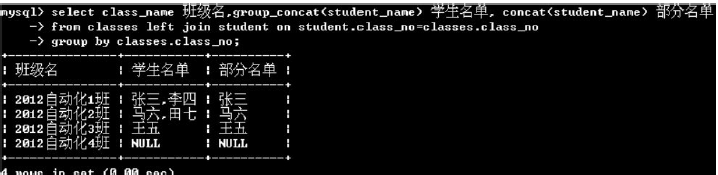
(4)group_concat()
group_concat()函数可以将各个字段的值用逗号连接起来
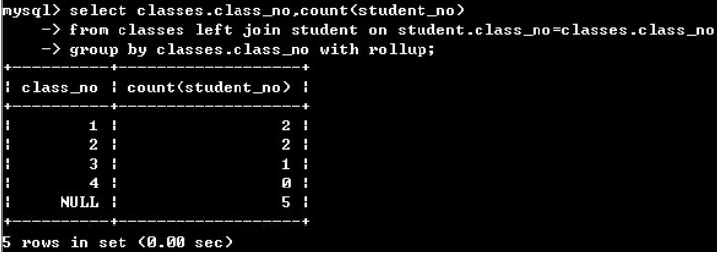
(5)group by + 聚合函数 + with rollup
在原先的group by+聚合函数中,聚合函数处理每个分组,但是没有处理整个表,with rollup在最后加上一行处理整个表的结果
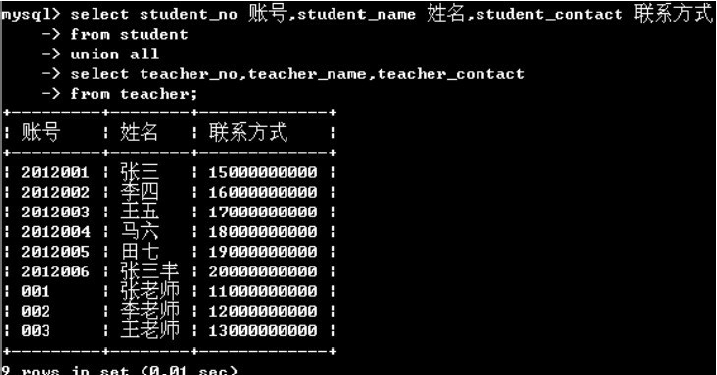
10.合并结果集
select 字段列表1 from table1
union [all]
select 字段列表2 from table2
要求:字段列表1和字段列表2的字段个数和对应的数据类型必须一致
例如:查询所有学生和老师的联系方式
11.子查询