测序的原理
Sanger
测序原理 https://v.qq.com/x/page/d0124c0k44t.html
illumina
测序原理: https://v.qq.com/x/page/i0770fd7r9i.html
PacBio
第三代 SMRT 单分子测序 https://v.qq.com/x/page/r03534cry7u.html
Ion torrent
测序原理 https://v.qq.com/x/page/v01754s6r82.html
Oxford Nanopore
https://v.qq.com/x/page/v0746ixokzz.html
好的,以下是根据这份讲义内容,对第一、二、三代测序技术相关知识的详细讲解:
一、第一代测序技术(Sanger 测序)
(一)背景与历史
- 时间:1977 年,Frederick Sanger 和 Coulson 开创了双脱氧链终止法(Sanger 测序法),并完成了第一个噬菌体全基因组的测序。
- 意义:开启了现代基因测序的时代,为后续的基因组学研究奠定了基础。
(二)测序原理
- 核心方法:基于 DNA 聚合酶的链终止反应。通过在 DNA 合成过程中随机引入标记了不同荧光染料的双脱氧核苷酸(ddNTP),使 DNA 链在不同位置终止。
- 具体步骤:
- 模板制备:将待测 DNA 片段克隆到合适的载体中,获得单链 DNA 模板。
- 引物退火:加入短的引物,使其与模板 DNA 的互补序列结合。
- 链合成与终止:在反应体系中加入 DNA 聚合酶、dNTP(正常脱氧核苷酸)和少量标记了荧光的 ddNTP。DNA 聚合酶从引物开始延伸 DNA 链,当随机遇到一个 ddNTP 时,链合成终止。
- 电泳分离与检测:将反应产物在聚丙烯酰胺凝胶中进行电泳分离,根据荧光标记的 ddNTP 不同,产生不同颜色的荧光信号,通过检测荧光信号的位置和颜色,确定 DNA 序列。
(三)特点
- 优点:
- 准确性高:单次测序的准确性可达 99.9% 以上,适合对准确性要求极高的应用,如基因组参考序列的构建。
- 读长较长:单次测序读长可达 500-1000 个碱基,能够覆盖较长的 DNA 片段,减少拼接错误。
- 缺点:
- 速度慢:每次测序只能处理一个 DNA 片段,通量低,难以满足大规模基因组测序的需求。
- 成本高:设备和试剂成本较高,不适合大规模应用。
二、第二代测序技术(Next-Generation Sequencing, NGS)
(一)背景与历史
- 时间:2005 年左右,随着 Roche 454 测序仪和 Illumina Solexa 测序仪的推出,第二代测序技术逐渐成熟并广泛应用。
- 意义:极大地提高了测序通量,降低了测序成本,推动了基因组学研究的快速发展,使大规模基因组测序成为可能。
(二)测序原理(以 Illumina 测序为例)
-
核心方法:基于可逆终止化学和边合成边测序(Sequencing by Synthesis, SBS)技术。
-
具体步骤:
-
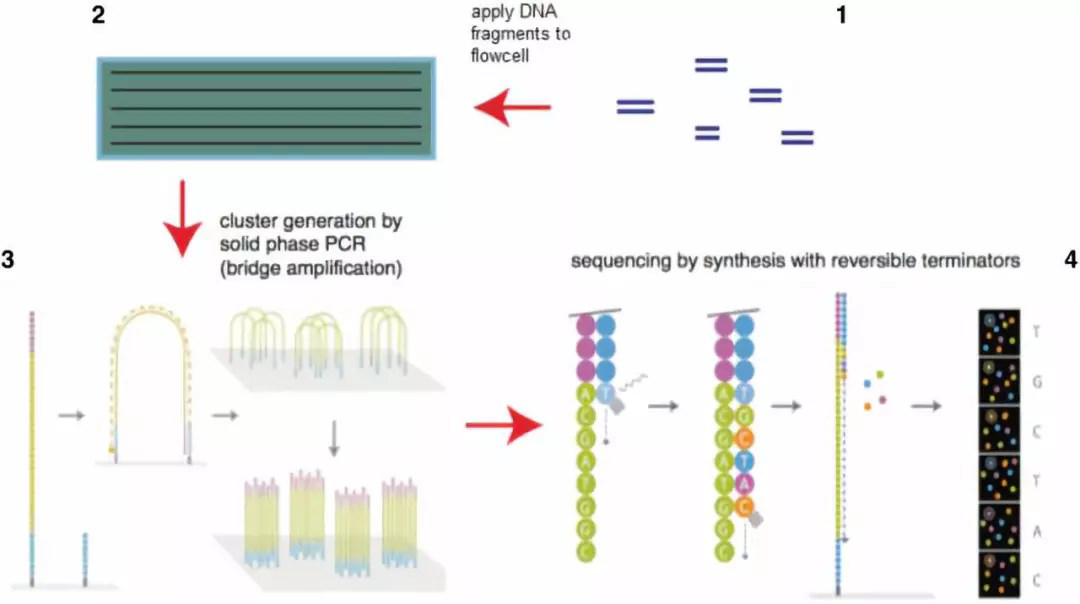
- 建库:
- DNA 片段化:将待测 DNA 随机打断成一定长度的小片段(如 300bp-800bp)。
- 末端修复与接头连接:对 DNA 片段的末端进行修复,并连接上特定的接头序列,使片段能够固定在测序芯片上。
- 加 index 标签:为不同样本的 DNA 添加独特的 index 标签,便于后续数据拆分。
- Flowcell 芯片准备:

- 建库:
Flowcell 的结构
- 通道(Lanes):Flowcell 包含多个通道,每个通道称为一个 lane。图中显示的 flowcell 有八条 lane,意味着可以同时进行八个独立的测序运行。
- 表面修饰:每个 lane 的表面都经过化学修饰,以便能够固定 DNA 片段。这些修饰包括大量的引物,如 P7 和 P5 引物,它们与 DNA 文库上的接头序列互补,从而能够固定 DNA 片段。
- Swath 和 Tile:每个 lane 有两个面,每个面上有三个 swath(区域),每个 swath 包含 16 个 tile(小方格)。因此,每个 lane 总共有 98 个 tile(两面各 48 个)。整个 flowcell 有 768 个 tile(96 lanes × 8 tiles/lane)。
Flowcell 的功能
-
DNA 固定:在测序过程中,DNA 片段需要固定在 flowcell 上,以防止在液体流动时被冲走。这是通过 DNA 片段上的接头与 flowcell 表面的引物结合来实现的。
-
大规模并行测序:由于 flowcell 上有大量的 tile,每个 tile 可以独立进行测序反应,因此可以实现大规模并行测序,大大提高测序效率和通量。
-
测序反应容器:所有的测序反应都在 flowcell 上进行,包括 DNA 的固定、扩增和测序。
- 芯片表面修饰:Flowcell 芯片表面含有大量固定化的引物,与 DNA 片段上的接头序列互补。
- DNA 固定:将建库后的 DNA 片段加入 Flowcell,使其与芯片上的引物结合。
- Cluster 扩增:
- 桥式 PCR:通过桥式 PCR 扩增,使每个 DNA 片段在芯片上形成一个簇(Cluster),每个簇包含多个相同的 DNA 拷贝,放大信号。
- 测序:
- 边合成边测序:在反应体系中加入带有荧光标记的 dNTP 和 DNA 聚合酶。每次只添加一个 dNTP 到 DNA 链上,通过激发荧光信号并记录,确定碱基类型。
- 信号处理与碱基识别:将荧光信号转换为碱基序列,生成 fastq 格式的测序数据。
(三)特点
- 优点:
- 高通量:一次运行可以产生大量的测序数据,适合大规模基因组测序。
- 成本低:单位碱基的测序成本大幅降低,使基因组学研究更加普及。
- 应用广泛:可用于基因组组装、变异检测、RNA 测序、单细胞测序等多种应用。
- 缺点:
- 读长短:单次测序读长较短(通常在 50-300bp),难以处理重复序列和复杂基因组区域。
- 测序时间长:从建库到测序完成通常需要数天时间。
- 偏向性:由于 PCR 扩增等步骤,可能导致某些区域的测序偏向性。
三、第三代测序技术
(一)PacBio 测序
1. 背景与历史
- 时间:2010 年左右,PacBio 公司推出了基于单分子实时测序(SMRT)技术的测序仪。
- 意义:提供了超长读长的测序能力,解决了第二代测序技术在处理复杂基因组区域时的局限性。
2. 测序原理
- 核心方法:单分子实时测序(SMRT)。
- 具体步骤:
- SMRT Cell 准备:将待测 DNA 样本转移到 SMRT Cell 中,该芯片含有大量零模波导孔(ZMW)。
- 文库构建:构建 SMRTbell 文库,将 DNA 片段连接成环状结构,便于多次测序。
- 测序过程:
- DNA 聚合酶固定:在 ZMW 孔底部固定 DNA 聚合酶。
- 单分子测序:DNA 模板与聚合酶结合,四种不同荧光标记的 dNTP 被逐个添加到 DNA 链上。每次添加一个 dNTP 时,荧光信号被激发并记录,通过信号分析确定碱基类型。
- 滚环测序:对于环状 DNA 模板,聚合酶可以多次绕环测序,提高测序准确性。
- 数据生成:生成长读长的测序数据,如 Polymerase Read、Subreads、CLR 和 CCS 等。
3. 特点
- 优点:
- 超长读长:平均读长可达 10-70kb,甚至更长,适合复杂基因组的组装和结构变异检测。
- 高准确性:通过多次测序和算法校正,可以获得高准确性的 HiFi Reads(>99.9%)。
- 无需 PCR 扩增:避免了 PCR 扩增带来的偏向性,适合低丰度基因的检测。
- 缺点:
- 数据量小:单次测序产生的数据量相对较小,适合小规模基因组测序。
- 成本高:测序成本较高,不适合大规模应用。
- 设备昂贵:测序仪价格较高,不适合小规模实验室购买。
(二)纳米孔测序
1. 背景与历史
- 时间:2014 年左右,Oxford Nanopore 公司推出了基于纳米孔技术的测序仪,如 MinION。
- 意义:提供了实时、长读长的测序能力,适合现场快速测序和长片段基因组分析。
2. 测序原理
- 核心方法:基于纳米孔的电信号检测。
- 具体步骤:
- 纳米孔准备:选择合适的生物纳米孔或固态纳米孔,将其嵌入到合成膜中。
- DNA 样本处理:将待测 DNA 样本连接上测序接头和马达蛋白,使其能够通过纳米孔。
- 测序过程:
- DNA 通过纳米孔:在电场作用下,DNA 链在马达蛋白的牵引下逐个碱基通过纳米孔。
- 电流变化检测:每个碱基通过纳米孔时会引起特定的电流变化,通过检测电流变化信号,识别碱基序列。
- 碱基识别:利用机器学习算法将电流信号(Squiggle)转换为碱基序列。
- 数据生成:生成长读长的测序数据,通常以 fastq 格式输出。
3. 特点
- 优点:
- 长读长:可以生成长达数十万个碱基的测序数据,适合复杂基因组的组装和结构变异检测。
- 实时测序:数据可以实时生成和分析,适合快速检测和现场应用。
- 便携性:测序设备轻便,如 MinION 适合野外和现场使用。
- 缺点:
- 高错误率:初始测序错误率较高(约 5%-15%),但可以通过算法校正和多次测序提高准确性。
- 数据处理复杂:需要复杂的碱基识别算法和软件进行数据处理。
- 成本高:虽然单次运行成本较低,但设备和试剂成本较高。
总结
- 第一代测序技术(Sanger 测序):准确性高、读长长,但速度慢、成本高,适合小规模、高精度的测序项目。
- 第二代测序技术(NGS):高通量、成本低、应用广泛,但读长短、有偏向性,适合大规模基因组测序和转录组分析。
- 第三代测序技术(PacBio 和纳米孔测序):长读长、无需 PCR 扩增、适合复杂基因组分析,但数据量小、成本高、设备昂贵,适合特定应用场景,如基因组组装、结构变异检测和现场快速测序。