腾讯开源实时语音大模型VITA-audio,92mstoken极速响应,支持多语言~
简介

VITA-Audio 是一个由腾讯优图实验室(Tencent Youtu Lab)、南京大学和厦门大学的研究人员共同开发的项目,旨在解决现有语音模型在流式生成(streaming)场景下生成第一个音频令牌(token)时的高延迟问题。这种延迟在实时应用中(如语音助手、实时语音翻译)是一个显著的瓶颈,限制了模型的部署和实际应用。
开发动机与目标
-
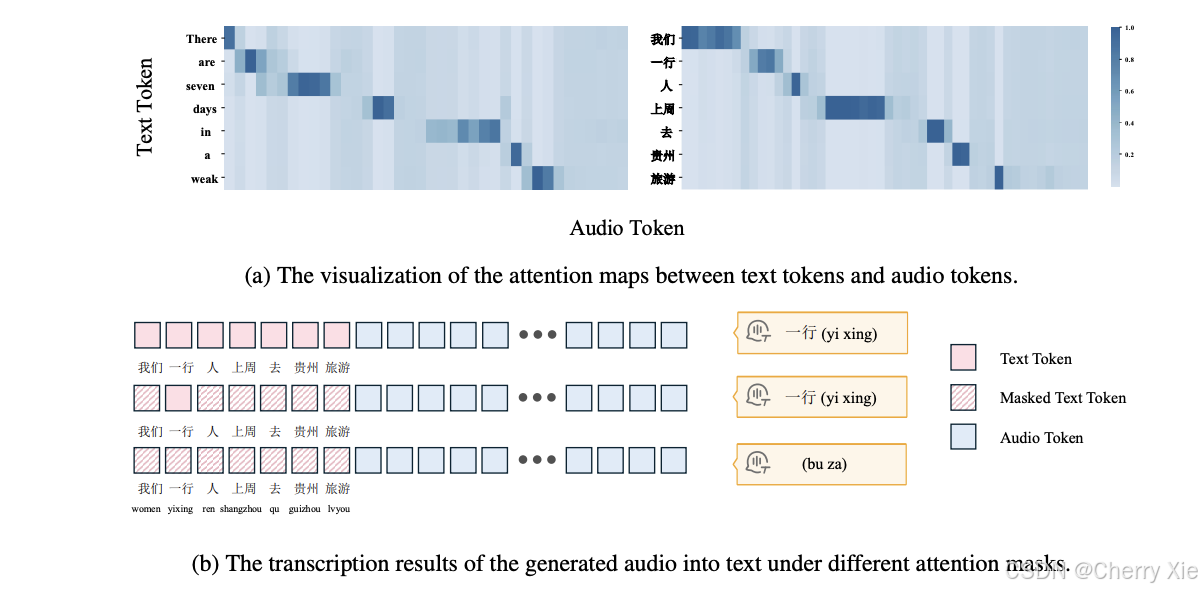
问题驱动:随着自然人机交互需求的增长,语音作为日常交流的主要形式,其实时性变得越来越重要。然而,现有模型在流式生成时存在高延迟问题,特别是在生成第一个音频令牌时,延迟可能达到数秒,影响用户体验 。
-
目标:VITA-Audio 旨在通过创新性地引入交叉模态令牌生成机制(Cross-Modal Token Generation),显著降低生成延迟,同时保持语音质量的优异表现。其核心目标是实现高效的音频-文本令牌生成,适合实时交互场景。
-
创新点:项目提出了一种轻量级的多模态令牌预测模块(Multiple Cross-modal Token Prediction, MCTP),能够在单次模型前向传播中生成多个音频令牌,从而加速推理并减少首个音频令牌的生成延迟 。
-
训练策略:采用四阶段渐进式训练策略(Four-Stage Progressive Training),确保模型在加速的同时保持高质量输出,训练基于大规模开源语音数据集,确保多语言和多风格的泛化能力 。
-
应用场景:VITA-Audio 适用于需要低延迟的语音生成任务,如实时语音助手、语音翻译、语音合成等,特别适合资源受限的设备部署 。
-
开源与社区:项目已开源,采用开放许可,GitHub 仓库提供推理代码、训练代码和模型权重,鼓励社区贡献和使用,截至 2025 年 5 月 14 日,已吸引开发者关注 。
模型结构
VITA-Audio 的模型结构设计紧凑且高效,专为实时语音生成优化。
整体架构
-
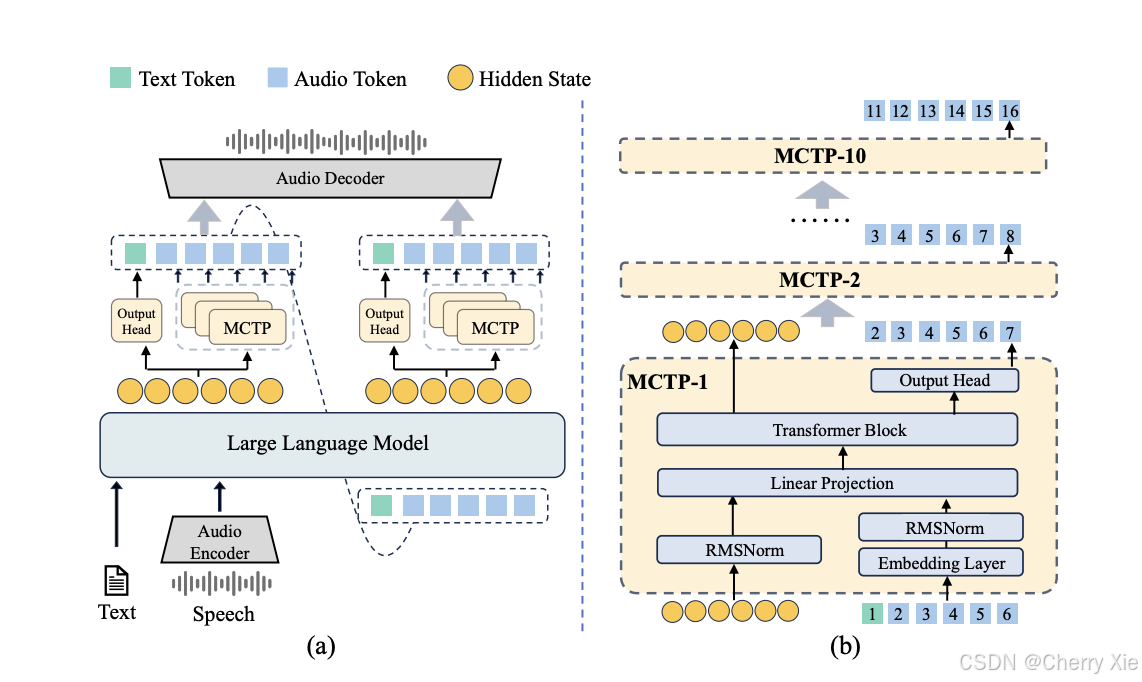
VITA-Audio 是一个端到端的大型语音模型(Large Speech-Language Model),支持音频和文本的交叉模态生成,核心目标是实现快速的音频-文本令牌生成 。
-
模型基于变分推理和对抗学习(Variational Inference with Adversarial Learning),结合了语音合成和语言模型的优点,适合端到端的语音任务。
关键模块
-
Multiple Cross-modal Token Prediction (MCTP) 模块
- 这是 VITA-Audio 的核心创新,允许模型在单次前向传播中生成多个音频令牌,从而显著减少生成第一个音频令牌的延迟 。
- MCTP 模块通过交叉模态学习(Cross-Modal Learning)实现音频和文本之间的协同生成,确保生成的音频与文本提示保持一致,适合实时交互 。
- 其轻量级设计降低了计算开销,适合资源受限的设备部署。
-
语音编码器(Voice Encoder)
-
从参考音频中提取语音特征(如音色、节奏、语调等),用于克隆目标语音 。
-
可能使用基于卷积或变换器的编码器,捕获音频的时频特征,确保音质的高保真度。
-
-
文本编码器(Text Encoder)
-
处理输入文本,生成语音合成的条件,可能是基于 Transformer 架构,支持多语言输入 。
-
确保文本和音频的语义一致性,适合跨语言生成任务。
-
-
生成器(Generator)
-
结合文本编码器和语音编码器的输出,生成目标语音,使用对抗学习确保生成语音的真实性,减少伪影 。
-
生成器可能采用 U-Net 架构,结合条件生成网络(Conditional GAN)实现高保真语音输出。
-
-
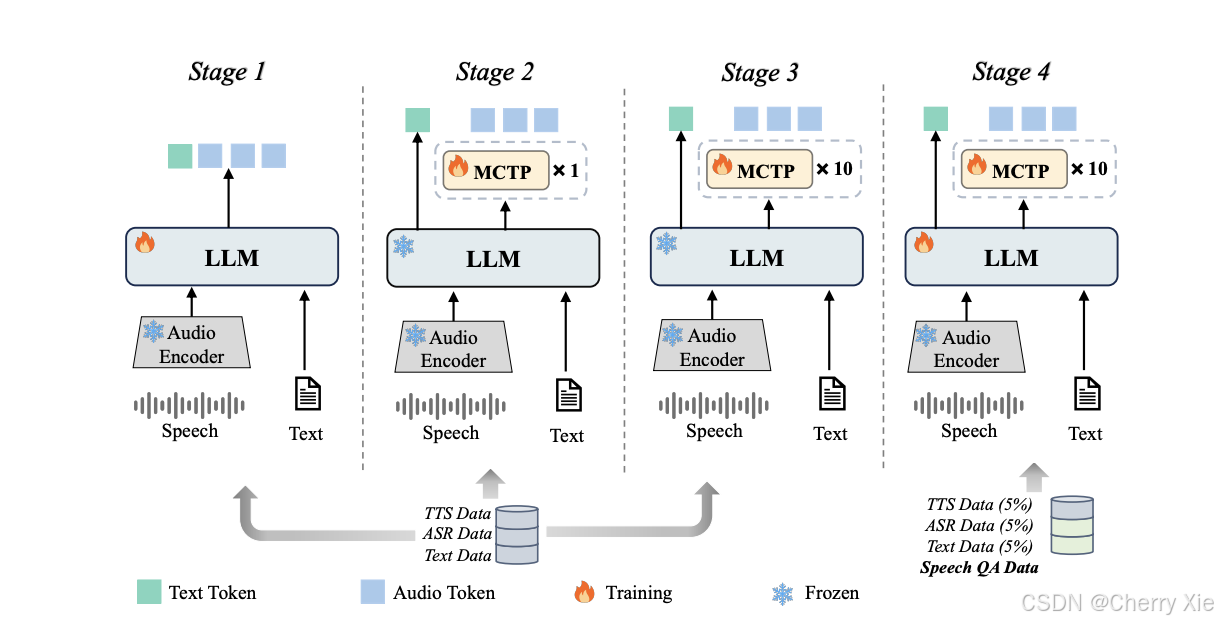
四阶段渐进式训练策略
-
模型采用四阶段训练策略,逐步增加训练难度和数据复杂度,确保模型在加速的同时保持高质量输出 。
-
可能包括预训练(Pre-training)、微调(Fine-tuning)、多模态对齐(Multimodal Alignment)和优化(Optimization)阶段。
-
性能优化
-
低延迟:通过 MCTP 模块,VITA-Audio 在流式生成场景下显著降低了生成第一个音频令牌的延迟,提升了实时性,适合语音助手等应用 。
-
高效性:模型设计轻量级,适合在资源受限的设备上部署,同时保持高质量的语音输出,社区反馈显示在 RTX 4090 上生成速度比 RTX 3090 快 50%-70% 。
交互性
-
非唤醒式交互(Non-awakening Interaction):用户无需通过唤醒词或按钮即可与模型进行语音交互,适合自然交互场景 。
-
音频中断交互(Audio Interrupt Interaction):用户可以在模型生成过程中随时提出新问题,模型会根据新问题及时响应,适合实时对话 。
性能对比

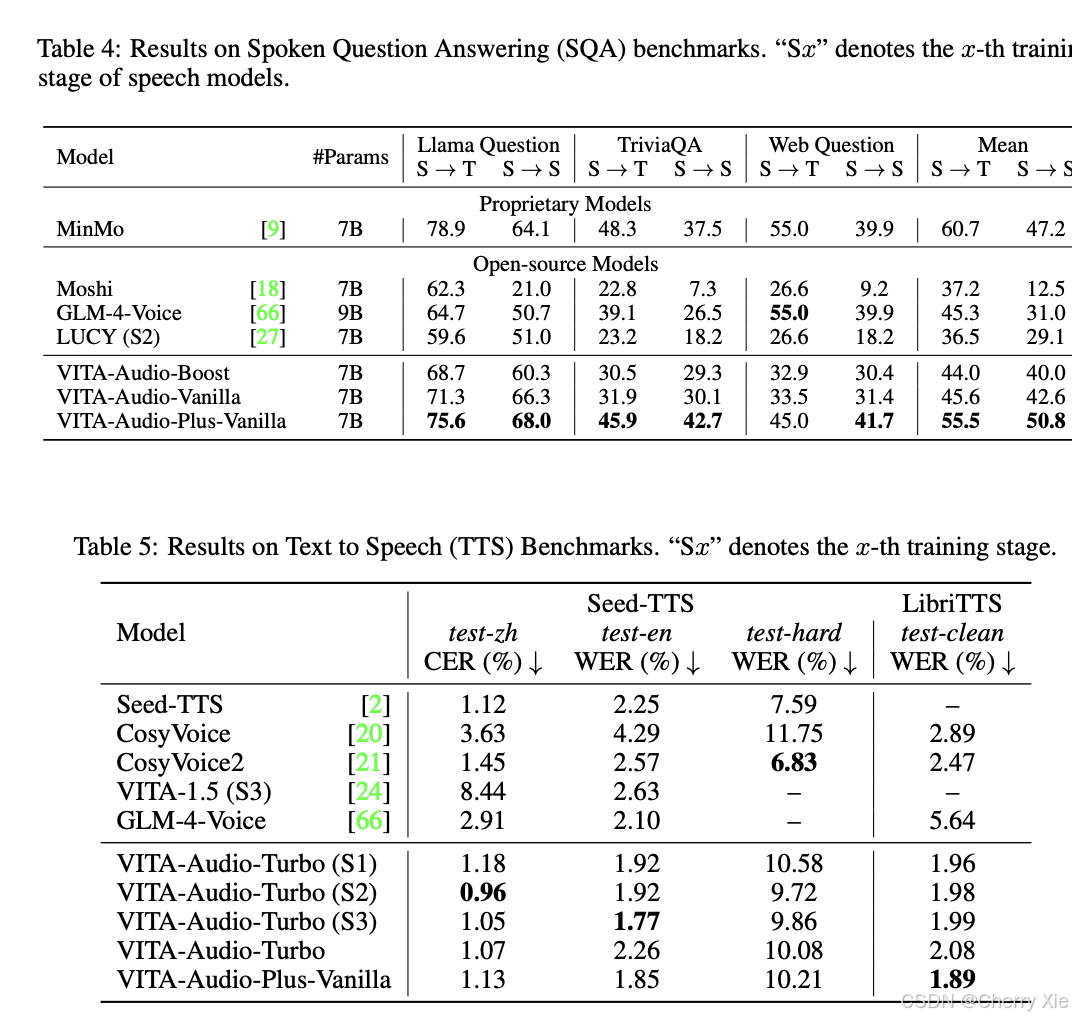
看看效果
相关文献
github地址:https://github.com/VITA-MLLM/VITA-Audio#
技术报告:https://arxiv.org/pdf/2505.03739
模型下载:https://huggingface.co/collections/VITA-MLLM/vita-audio-680f036c174441e7cdf02575