深度理解用于多智能体强化学习的单调价值函数分解QMIX算法:基于python从零实现
引言:合作式多智能体强化学习与功劳分配
在合作式多智能体强化学习(MARL)中,多个智能体携手合作,共同达成一个目标,通常会收到一个团队共享的奖励。在这种场景下,一个关键的挑战就是功劳分配:一个单独的智能体如何仅凭全局奖励信号来判断自己对团队成功或失败的贡献呢?简单的独立学习方法(比如每个智能体都运行 DQN)往往行不通,因为它把其他智能体当作了非静态环境的一部分,而且在功劳分配上也搞不定。
价值分解方法,像 QMIX,为应对合作式 MARL 中的这一挑战提供了一种结构化的解决方案。
QMIX 是啥玩意儿?
QMIX(Q 值混合)是一种用于合作任务的离线策略、基于价值的 MARL 算法。它遵循集中式训练、分散式执行的范式。它的核心创新之处在于学习各个智能体的效用函数(表示为 Q i Q_i Qi),并通过一个单调混合网络将它们组合起来,以估计联合行动价值函数( Q t o t Q_{tot} Qtot)。
核心思想:价值函数分解
QMIX 假定团队的联合行动价值函数 Q t o t Q_{tot} Qtot 可以分解或者表示为各个智能体效用函数 Q i Q_i Qi 的单调组合。每个 Q i ( o i , a i ) Q_i(o_i, a_i) Qi(oi,ai) 只依赖于智能体 i i i 的局部观测 o i o_i oi 和行动 a i a_i ai。
混合网络
一个单独的混合网络以每个智能体的个体网络产生的值( Q 1 , . . . , Q N Q_1, ..., Q_N Q1,...,QN)作为输入,并输出估计的联合行动价值 Q t o t Q_{tot} Qtot。关键的是,这个混合网络还以全局状态 x x x 作为输入,使得个体效用与团队价值之间的关系能够依赖于整体情况。通常会使用超网络根据全局状态来生成混合网络层的权重和偏置。
单调性约束(IQL 原则)
为了确保分散式执行(每个智能体根据 Q i Q_i Qi 选择最佳行动)与集中式训练(优化 Q t o t Q_{tot} Qtot)之间的一致性,QMIX 强制执行单调性约束:
∂ Q t o t ∂ Q i ≥ 0 ∀ i \frac{\partial Q_{tot}}{\partial Q_i} \ge 0 \quad \forall i ∂Qi∂Qtot≥0∀i
这意味着,增加一个单独智能体的效用 Q i Q_i Qi 绝对不能降低团队的总价值 Q t o t Q_{tot} Qtot。这保证了智能体在执行阶段最大化其局部 Q i Q_i Qi 时,会对最大化全局 Q t o t Q_{tot} Qtot 做出积极贡献。QMIX 通过确保混合网络的权重为非负值来实现这一约束。
这个约束体现了个体 - 全局最大(IQL)原则:最大化 Q t o t Q_{tot} Qtot 的联合行动与最大化每个智能体 Q i Q_i Qi 的个体行动是一样的。
QMIX 为啥这么牛?优势所在
- 搞定功劳分配:通过学习单调地贡献于 Q t o t Q_{tot} Qtot 的个体 Q i Q_i Qi 函数,它比只用全局奖励的方法更好地隐式处理功劳分配问题。
- 可扩展性(行动空间):与直接学习联合 Q 函数的方法(随着智能体和行动数量呈指数级增长)不同,QMIX 学习个体 Q i Q_i Qi 函数和一个混合网络,使其在联合行动空间方面更具可扩展性。
- 分散式执行:智能体在训练后可以仅使用其局部 Q i Q_i Qi 函数来行动。
- 依赖状态的混合:使用全局状态可以让混合函数捕捉到依赖于整体上下文的智能体效用之间的复杂非线性关系。
QMIX 在哪儿用?怎么用?
QMIX 是一种流行的用于合作式 MARL 任务的算法,特别是在具有离散行动空间的任务中:
- 星际争霸多智能体挑战(SMAC):QMIX 及其变体在这些基准微观管理任务上表现出色。
- 协调游戏:需要智能体同步或协调行动的网格世界或其他任务。
- 多机器人协作:协作导航、编队控制。
QMIX 的数学基础
个体智能体 Q 函数( Q i Q_i Qi)
每个智能体 i i i 有一个网络(如果需要历史信息,通常是 DRQN - 深度循环 Q 网络,或者是一个 MLP),它以智能体的局部观测历史 τ i \tau_i τi 作为输入,并输出其可能行动 a i a_i ai 的 Q 值: Q i ( τ i , a i ; θ i ) Q_i(\tau_i, a_i; \theta_i) Qi(τi,ai;θi)。为了简化 Markovian 状态,我们使用 Q i ( o i , a i ; θ i ) Q_i(o_i, a_i; \theta_i) Qi(oi,ai;θi)。
联合行动价值函数( Q t o t Q_{tot} Qtot)
混合网络 f m i x f_{mix} fmix 将个体 Q 值和全局状态 x x x 结合起来,产生联合行动价值:
Q t o t ( x , a ) = f m i x ( Q 1 ( o 1 , a 1 ) , . . . , Q N ( o N , a N ) ; x ; ϕ m i x ) Q_{tot}(x, \mathbf{a}) = f_{mix}(Q_1(o_1, a_1), ..., Q_N(o_N, a_N); x; \phi_{mix}) Qtot(x,a)=fmix(Q1(o1,a1),...,QN(oN,aN);x;ϕmix)
其中 a = ( a 1 , . . . , a N ) \mathbf{a} = (a_1, ..., a_N) a=(a1,...,aN)。
混合网络架构与单调性
混合网络强制执行 ∂ Q t o t ∂ Q i ≥ 0 \frac{\partial Q_{tot}}{\partial Q_i} \ge 0 ∂Qi∂Qtot≥0。这通常是通过以下方式实现的:
- 在混合层中使用非负权重。
- 使用单调激活函数(比如 ReLU 或线性层,其中权重受到限制)。
原始 QMIX 论文通过使用超网络生成混合层的权重和偏置,这些超网络以全局状态为条件。
超网络用于依赖状态
为了使混合依赖于状态,使用超网络。例如,对于一个混合层 Q t o t = W 1 Q + b 1 Q_{tot} = W_1 \mathbf{Q} + b_1 Qtot=W1Q+b1(其中 Q = [ Q 1 , . . . , Q N ] T \mathbf{Q} = [Q_1, ..., Q_N]^T Q=[Q1,...,QN]T):
- 一个超网络以全局状态 x x x 作为输入,并输出权重矩阵 W 1 W_1 W1。通过取
abs()或使用 ELU 激活函数 + 1 来限制 W 1 W_1 W1 的元素为非负值。 - 另一个超网络以 x x x 作为输入并输出偏置 b 1 b_1 b1。(偏置不需要正性约束。)
如果混合网络有多个层,就会重复这个过程。
损失函数( Q t o t Q_{tot} Qtot 的 TD 误差)
QMIX 使用来自回放缓冲区 D \mathcal{D} D 的离线策略数据。损失函数旨在最小化联合行动价值函数的 TD 误差,类似于 DQN:
L ( θ 1 , . . . , θ N , ϕ m i x ) = E ( x , a , r , x ′ ) ∼ D [ ( y − Q t o t ( x , a ) ) 2 ] L(\theta_1, ..., \theta_N, \phi_{mix}) = \mathbb{E}_{(x, \mathbf{a}, r, x') \sim \mathcal{D}} [ (y - Q_{tot}(x, \mathbf{a}))^2 ] L(θ1,...,θN,ϕmix)=E(x,a,r,x′)∼D[(y−Qtot(x,a))2]
目标 y y y 是使用目标智能体网络( Q i ′ Q'_i Qi′)和目标混合网络( f m i x ′ f'_{mix} fmix′)计算的:
y = r + γ Q t o t ′ ( x ′ , a ′ ) y = r + \gamma Q'_{tot}(x', \mathbf{a}') y=r+γQtot′(x′,a′)
其中 a ′ = ( a 1 ′ , . . . , a N ′ ) 且 a i ′ = arg max a i Q i ′ ( o i ′ , a i ) \text{其中 } \mathbf{a}' = (a'_1, ..., a'_N) \text{ 且 } a'_i = \arg\max_{a_i} Q'_i(o'_i, a_i) 其中 a′=(a1′,...,aN′) 且 ai′=argaimaxQi′(oi′,ai)
梯度 ∇ L \nabla L ∇L 会反向传播到主混合网络以及所有主智能体网络 Q i Q_i Qi。
目标网络
目标网络(每个智能体的 Q i ′ Q'_i Qi′,以及目标混合网络 f m i x ′ f'_{mix} fmix′)用于稳定 TD 目标计算。它们会定期或通过软更新从主网络更新。
QMIX 的逐步解释
- 初始化:对于每个智能体 i i i:智能体网络 Q i ( θ i ) Q_i(\theta_i) Qi(θi),目标智能体网络 Q i ′ ( θ i ′ ) Q'_i(\theta'_i) Qi′(θi′) 并且 θ i ′ ← θ i \theta'_i \leftarrow \theta_i θi′←θi。
- 初始化:混合网络 f m i x ( ϕ m i x ) f_{mix}(\phi_{mix}) fmix(ϕmix),目标混合网络 f m i x ′ ( ϕ m i x ′ ) f'_{mix}(\phi'_{mix}) fmix′(ϕmix′) 并且 ϕ m i x ′ ← ϕ m i x \phi'_{mix} \leftarrow \phi_{mix} ϕmix′←ϕmix。
- 初始化:回放缓冲区 D \mathcal{D} D。超参数(缓冲区大小、批量大小、 γ \gamma γ、 τ \tau τ、学习率、 ϵ \epsilon ϵ)。
- 对于每个剧集:
a. 获取初始联合观测 o = ( o 1 , . . . , o N ) o=(o_1, ..., o_N) o=(o1,...,oN) 和全局状态 x x x。
b. 对于每个步骤 t t t:
i. 对于每个智能体 i i i,使用 ϵ \epsilon ϵ-贪婪在 Q i ( o i , ⋅ ) Q_i(o_i, \cdot) Qi(oi,⋅) 上选择行动 a i a_i ai。
ii. 执行联合行动 a = ( a 1 , . . . , a N ) \mathbf{a}=(a_1, ..., a_N) a=(a1,...,aN),观察共享奖励 r r r,下一个联合观测 o ′ o' o′,下一个全局状态 x ′ x' x′,以及完成标志 d d d。
iii. 将转换 ( o , a , r , o ′ , x , x ′ , d ) (o, \mathbf{a}, r, o', x, x', d) (o,a,r,o′,x,x′,d) 存储到 D \mathcal{D} D 中。
iv. o ← o ′ , x ← x ′ o \leftarrow o', x \leftarrow x' o←o′,x←x′。
v. 更新步骤(如果缓冲区有足够的样本):
1. 从 D \mathcal{D} D 中采样一个大小为 B B B 的小批量转换。
2. 对于批次中的每个转换 j j j:
- 计算目标 Q t o t , j ′ Q'_{tot,j} Qtot,j′:
- 对于每个智能体 i i i,找到 a i , j ′ = arg max a Q i ′ ( o i , j ′ , a ) a'_{i,j} = \arg\max_{a} Q'_{i}(o'_{i,j}, a) ai,j′=argmaxaQi′(oi,j′,a)。
- 获取 Q i , j ′ = Q i ′ ( o i , j ′ , a i , j ′ ) Q'_{i,j} = Q'_{i}(o'_{i,j}, a'_{i,j}) Qi,j′=Qi′(oi,j′,ai,j′)。
- 计算 Q t o t , j ′ = f m i x ′ ( Q 1 , j ′ , . . . , Q N , j ′ ; x j ′ ) Q'_{tot,j} = f'_{mix}(Q'_{1,j}, ..., Q'_{N,j}; x'_{j}) Qtot,j′=fmix′(Q1,j′,...,QN,j′;xj′)。
- 计算 TD 目标 y j = r j + γ ( 1 − d j ) Q t o t , j ′ y_j = r_j + \gamma (1-d_j) Q'_{tot,j} yj=rj+γ(1−dj)Qtot,j′。
- 计算当前 Q t o t , j Q_{tot,j} Qtot,j:
- 对于每个智能体 i i i,获取 Q i , j = Q i ( o i , j , a i , j ) Q_{i,j} = Q_{i}(o_{i,j}, a_{i,j}) Qi,j=Qi(oi,j,ai,j)(使用缓冲区中的行动 a i , j a_{i,j} ai,j)。
- 计算 Q t o t , j = f m i x ( Q 1 , j , . . . , Q N , j ; x j ) Q_{tot,j} = f_{mix}(Q_{1,j}, ..., Q_{N,j}; x_{j}) Qtot,j=fmix(Q1,j,...,QN,j;xj)。
3. 计算损失 L = 1 B ∑ j ( y j − Q t o t , j ) 2 L = \frac{1}{B} \sum_j (y_j - Q_{tot,j})^2 L=B1∑j(yj−Qtot,j)2。
4. 对 L L L 关于 θ 1 , . . . , θ N , ϕ m i x \theta_1, ..., \theta_N, \phi_{mix} θ1,...,θN,ϕmix 执行梯度下降步骤。
5. 通过软更新(或定期硬更新)更新目标网络( Q i ′ Q'_i Qi′ 和 f m i x ′ f'_{mix} fmix′)。
vi. 如果完成,则中断步骤循环。 - 重复:直到收敛。
QMIX 的关键组成部分
智能体网络( Q i Q_i Qi)
- 基于局部观测学习个体效用 / Q 函数。
- 可以是 MLP 或 DRQN(如果历史重要)。
混合网络
- 将个体 Q i Q_i Qi 值和全局状态 x x x 结合起来产生 Q t o t Q_{tot} Qtot。
- 强制执行单调性约束( ∂ Q t o t / ∂ Q i ≥ 0 \partial Q_{tot} / \partial Q_i \ge 0 ∂Qtot/∂Qi≥0)。
超网络
- 生成混合网络的权重 / 偏置,以全局状态 x x x 为条件。
- 确保混合依赖于状态,且权重为非负值。
回放缓冲区(共享)
- 存储联合转换以供离线策略学习。
目标网络(智能体和混合器)
- 稳定 TD 目标计算。
行动选择(分散式, ϵ \epsilon ϵ-贪婪)
- 每个智能体仅根据自己的 Q i Q_i Qi 贪婪地(或 ϵ \epsilon ϵ-贪婪地)行动。
集中式训练
- 更新使用联合信息(全局状态 x x x,所有 Q i Q_i Qi 值)通过混合网络。
超参数
- 标准 RL 参数( γ \gamma γ, ϵ \epsilon ϵ,学习率, τ \tau τ,缓冲区 / 批量大小)。
- 混合网络架构,超网络架构。
实践示例:自定义多智能体网格世界
环境设计理由
这个合作式 2 智能体网格世界非常适合在离散设置中展示 QMIX 的价值分解。
环境细节:
- 全局状态( x x x):两个智能体和两个目标的归一化位置的连接( r 1 , c 1 , r 2 , c 2 , g 1 r , g 1 c , g 2 r , g 2 c r1, c1, r2, c2, g1r, g1c, g2r, g2c r1,c1,r2,c2,g1r,g1c,g2r,g2c)。
- 局部观测( o i o_i oi):智能体 i i i 的归一化位置,另一个智能体的归一化位置,智能体 i i i 的目标归一化位置( s e l f _ r , s e l f _ c , o t h e r _ r , o t h e r _ c , g o a l _ i _ r , g o a l _ i _ c self\_r, self\_c, other\_r, other\_c, goal\_i\_r, goal\_i\_c self_r,self_c,other_r,other_c,goal_i_r,goal_i_c)。
- 行动 / 奖励:如之前所定义。
设置环境
导入库。
# 导入必要的库
import numpy as np
import matplotlib.pyplot as plt
import random
import math
from collections import namedtuple, deque, defaultdict
from itertools import count
from typing import List, Tuple, Dict, Optional, Callable, Any
import copy# 导入 PyTorch
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F# 设置设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备:{device}")# 设置随机种子
seed = 42
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
if torch.cuda.is_available():torch.cuda.manual_seed_all(seed)%matplotlib inline
使用设备:cpu
创建自定义多智能体环境
使用来自 MADDPG 笔记本的 MultiAgentGridEnv,添加一个获取全局状态的方法。
class MultiAgentGridEnv:"""简单的 2 智能体合作网格世界。智能体必须同时到达各自的终点。观测包括智能体位置和终点位置。奖励是共享的。"""def __init__(self, size: int = 5, num_agents: int = 2):self.size: int = sizeself.num_agents: int = num_agentsself.action_dim: int = 4 # 上,下,左,右self.action_map: Dict[int, Tuple[int, int]] = {0: (-1, 0), 1: (1, 0), 2: (0, -1), 3: (0, 1)}self.actions: List[int] = list(self.action_map.keys())# 为简单起见,定义固定的起始位置和终点位置self.start_positions: List[Tuple[int, int]] = [(0, 0), (size - 1, size - 1)]self.goal_positions: List[Tuple[int, int]] = [(size - 1, 0), (0, size - 1)]if num_agents != 2:raise NotImplementedError("目前仅支持 2 个智能体。")self.agent_positions: List[Tuple[int, int]] = list(self.start_positions)# 智能体 i 的观测空间:(self_r, self_c, other_r, other_c, goal_i_r, goal_i_c)# 在 0 和 1 之间进行归一化self.observation_dim_per_agent: int = 6 self.max_coord = float(self.size - 1)def _normalize_pos(self, pos: Tuple[int, int]) -> Tuple[float, float]:""" 对网格位置进行归一化。 """r, c = posreturn (r / self.max_coord, c / self.max_coord) if self.max_coord > 0 else (0.0, 0.0)def _get_observation(self, agent_id: int) -> np.ndarray:""" 获取特定智能体的归一化局部观测。 """obs = []# 自身位置self_pos_norm = self._normalize_pos(self.agent_positions[agent_id])obs.extend(self_pos_norm)# 另一个智能体的位置other_id = 1 - agent_idother_pos_norm = self._normalize_pos(self.agent_positions[other_id])obs.extend(other_pos_norm)# 自身终点位置goal_pos_norm = self._normalize_pos(self.goal_positions[agent_id])obs.extend(goal_pos_norm)return np.array(obs, dtype=np.float32)def get_joint_observation(self) -> List[np.ndarray]:""" 获取所有智能体的观测列表。 """return [self._get_observation(i) for i in range(self.num_agents)]def reset(self) -> List[np.ndarray]:""" 重置环境,返回初始观测列表。 """self.agent_positions = list(self.start_positions)return self.get_joint_observation()def step(self, actions: List[int]) -> Tuple[List[np.ndarray], List[float], bool]:"""执行所有智能体的一个步骤。参数:- actions (List[int]): 每个智能体的行动列表。返回:- Tuple[List[np.ndarray], List[float], bool]: - 每个智能体的下一个观测列表。- 每个智能体的奖励列表(共享奖励)。- 全局完成标志。"""if len(actions) != self.num_agents:raise ValueError(f"期望有 {self.num_agents} 个行动,但得到了 {len(actions)} 个")next_positions: List[Tuple[int, int]] = list(self.agent_positions) # 从当前开始total_dist_reduction = 0.0hit_wall_penalty = 0.0for i in range(self.num_agents):current_pos = self.agent_positions[i]if current_pos == self.goal_positions[i]: # 如果智能体已经在终点,则不移动continue action = actions[i]dr, dc = self.action_map[action]next_r, next_c = current_pos[0] + dr, current_pos[1] + dc# 检查边界并更新位置if 0 <= next_r < self.size and 0 <= next_c < self.size:next_positions[i] = (next_r, next_c)else:hit_wall_penalty -= 0.5 # 碰墙惩罚next_positions[i] = current_pos # 保持原位# 简单的碰撞处理:如果智能体移动到同一个位置,则反弹if self.num_agents == 2 and next_positions[0] == next_positions[1]:next_positions = list(self.agent_positions) # 恢复到之前的位置hit_wall_penalty -= 0.5 # 视为惩罚(就像碰墙一样)self.agent_positions = next_positions# 计算奖励和完成标志done = all(self.agent_positions[i] == self.goal_positions[i] for i in range(self.num_agents))if done:reward = 10.0 # 合作成功获得大奖励else:# 基于距离的奖励(终点距离的负和)dist_reward = 0.0for i in range(self.num_agents):dist = abs(self.agent_positions[i][0] - self.goal_positions[i][0]) + \abs(self.agent_positions[i][1] - self.goal_positions[i][1])dist_reward -= dist * 0.1 # 缩放后的负距离reward = -0.05 + dist_reward + hit_wall_penalty # 小步惩罚 + 距离 + 碰墙惩罚next_observations = self.get_joint_observation()# 共享奖励rewards = [reward] * self.num_agents return next_observations, rewards, done
class MultiAgentGridEnv_QMIX(MultiAgentGridEnv):""" 为 MA 网格环境添加全局状态方法。 """def __init__(self, size: int = 5, num_agents: int = 2):super().__init__(size=size, num_agents=num_agents)# 全局状态:(r1,c1, r2,c2, g1r,g1c, g2r,g2c) 归一化self.global_state_dim = self.num_agents * 4 def get_global_state(self) -> np.ndarray:""" 返回归一化的全局状态。 """state = []# 智能体位置for i in range(self.num_agents):state.extend(self._normalize_pos(self.agent_positions[i]))# 目标位置for i in range(self.num_agents):state.extend(self._normalize_pos(self.goal_positions[i]))return np.array(state, dtype=np.float32)def reset_qmix(self) -> Tuple[List[np.ndarray], np.ndarray]:""" 重置并返回观测列表和全局状态。 """obs_list = super().reset()global_state = self.get_global_state()return obs_list, global_statedef step_qmix(self, actions: List[int]) -> Tuple[List[np.ndarray], np.ndarray, float, bool]:""" 执行环境步骤,返回观测列表、全局状态、共享奖励和完成标志。 """next_obs_list, rewards, done = super().step(actions)next_global_state = self.get_global_state()shared_reward = rewards[0] # 使用共享奖励return next_obs_list, next_global_state, shared_reward, done
实例化并测试环境。
qmix_env = MultiAgentGridEnv_QMIX(size=5, num_agents=2)
obs_list_qmix, global_state_qmix = qmix_env.reset_qmix()
n_agents_qmix = qmix_env.num_agents
obs_dim_qmix = qmix_env.observation_dim_per_agent
global_state_dim_qmix = qmix_env.global_state_dim
action_dim_qmix = qmix_env.action_dimprint(f"QMIX 环境大小:{qmix_env.size}x{qmix_env.size}")
print(f"智能体数量:{n_agents_qmix}")
print(f"每个智能体的观测维度:{obs_dim_qmix}")
print(f"全局状态维度:{global_state_dim_qmix}")
print(f"每个智能体的行动维度:{action_dim_qmix}")
print(f"初始观测列表:{obs_list_qmix}")
print(f"初始全局状态:{global_state_qmix}")
QMIX 环境大小:5x5
智能体数量:2
每个智能体的观测维度:6
全局状态维度:8
每个智能体的行动维度:4
初始观测列表:[array([0., 0., 1., 1., 1., 0.], dtype=float32), array([1., 1., 0., 0., 0., 1.], dtype=float32)]
初始全局状态:[0. 0. 1. 1. 1. 0. 0. 1.]
实现 QMIX 算法
定义智能体网络(DRQN 或 MLP)
输出所有行动的 Q i ( o i , a ) Q_i(o_i, a) Qi(oi,a)。我们这里使用一个简单的 MLP。对于具有部分可观测性的环境,使用 LSTM 或 GRU 的 DRQN(深度循环 Q 网络)会更常见。
class AgentQNetwork(nn.Module):""" QMIX 中的个体智能体 Q 网络。输出所有行动的 Q 值。 """def __init__(self, obs_dim: int, action_dim: int):super(AgentQNetwork, self).__init__()self.fc1 = nn.Linear(obs_dim, 64) # 个体智能体的较小网络self.fc2 = nn.Linear(64, 64)self.fc3 = nn.Linear(64, action_dim) # 为每个行动输出 Q 值def forward(self, obs: torch.Tensor) -> torch.Tensor:""" 将观测映射到所有行动的 Q 值。 """x = F.relu(self.fc1(obs))x = F.relu(self.fc2(x))q_values = self.fc3(x)return q_values
定义混合网络(带超网络)
将个体 Q i Q_i Qi 值以单调的方式组合起来,以全局状态为条件。
class QMixer(nn.Module):""" QMIX 的混合网络,带超网络。 """def __init__(self, num_agents: int, global_state_dim: int, mixing_embed_dim: int = 32):super(QMixer, self).__init__()self.num_agents = num_agentsself.state_dim = global_state_dimself.embed_dim = mixing_embed_dim# 为第一层混合网络生成权重的超网络# 输入:全局状态,输出:权重形状(num_agents * embed_dim)self.hyper_w1 = nn.Sequential(nn.Linear(self.state_dim, 64),nn.ReLU(),nn.Linear(64, self.num_agents * self.embed_dim))# 为第一层混合网络生成偏置的超网络# 输入:全局状态,输出:偏置形状(embed_dim)self.hyper_b1 = nn.Linear(self.state_dim, self.embed_dim)# 为第二层混合网络(可选,可以是单层)生成权重的超网络# 输入:全局状态,输出:权重形状(embed_dim * 1)self.hyper_w2 = nn.Sequential(nn.Linear(self.state_dim, 64),nn.ReLU(),nn.Linear(64, self.embed_dim) # 输出大小为 embed_dim)# 为最终偏置(标量)生成的超网络# 输入:全局状态,输出:偏置(标量)self.hyper_b2 = nn.Sequential(nn.Linear(self.state_dim, 32),nn.ReLU(),nn.Linear(32, 1))def forward(self, agent_qs: torch.Tensor, global_state: torch.Tensor) -> torch.Tensor:"""将个体智能体 Q 值混合以产生 $Q_{tot}$。参数:- agent_qs (torch.Tensor): 个体 Q 值张量,形状为 (batch_size, num_agents)。- global_state (torch.Tensor): 全局状态张量,形状为 (batch_size, global_state_dim)。返回:- torch.Tensor: 估计的 $Q_{tot}$ 值,形状为 (batch_size, 1)。"""batch_size = agent_qs.size(0)# 将 agent_qs 重塑为 (batch_size, 1, num_agents),以便进行批量矩阵乘法agent_qs_reshaped = agent_qs.view(batch_size, 1, self.num_agents)# --- 第一层混合网络 --- # 生成权重并确保非负性w1 = torch.abs(self.hyper_w1(global_state)) # abs() 确保权重非负# 将权重重塑为 (batch_size, num_agents, embed_dim)w1 = w1.view(batch_size, self.num_agents, self.embed_dim)# 生成偏置b1 = self.hyper_b1(global_state)# 将偏置重塑为 (batch_size, 1, embed_dim)b1 = b1.view(batch_size, 1, self.embed_dim)# 应用第一层:$Q_{hidden} = Q_{agents} \times W1 + b1$hidden = F.elu(torch.bmm(agent_qs_reshaped, w1) + b1)# 形状:(batch_size, 1, embed_dim)# --- 第二层混合网络 --- # 生成权重并确保非负性w2 = torch.abs(self.hyper_w2(global_state))# 将权重重塑为 (batch_size, embed_dim, 1)w2 = w2.view(batch_size, self.embed_dim, 1)# 生成偏置b2 = self.hyper_b2(global_state)# 将偏置重塑为 (batch_size, 1, 1)b2 = b2.view(batch_size, 1, 1)# 应用第二层:$Q_{tot} = Q_{hidden} \times W2 + b2$q_tot = torch.bmm(hidden, w2) + b2# 形状:(batch_size, 1, 1)return q_tot.view(batch_size, 1) # 返回形状 (batch_size, 1)
定义回放记忆
存储联合转换,包括全局状态。
# 定义 QMIX 缓冲区的转换结构
QMIXTransition = namedtuple('QMIXTransition', ('obs_list', 'actions_list', 'reward', 'next_obs_list', 'global_state', 'next_global_state', 'done'))class QMIXReplayBuffer:def __init__(self, capacity: int):self.memory = deque([], maxlen=capacity)def push(self, obs_list: List[np.ndarray], actions_list: List[int], reward: float, next_obs_list: List[np.ndarray], global_state: np.ndarray,next_global_state: np.ndarray, done: bool) -> None:""" 保存一个联合转换。 """# 以 numpy 数组或原始类型存储self.memory.append(QMIXTransition(obs_list, actions_list, reward, next_obs_list, global_state,next_global_state, done))def sample(self, batch_size: int) -> Optional[QMIXTransition]:""" 采样一批经验并转换为张量。 """if len(self.memory) < batch_size:return Nonetransitions = random.sample(self.memory, batch_size)# 解包并先转换为 numpy 数组以便于堆叠obs_l, act_l, rew_l, next_obs_l, gs_l, next_gs_l, done_l = zip(*transitions)num_agents = len(obs_l[0])obs_dim = obs_l[0][0].shape[0]global_dim = gs_l[0].shape[0]# 堆叠观测:列表的列表 -> (batch, agent, dim)obs_arr = np.array(obs_l, dtype=np.float32).reshape(batch_size, num_agents, obs_dim)next_obs_arr = np.array(next_obs_l, dtype=np.float32).reshape(batch_size, num_agents, obs_dim)# 堆叠行动、奖励、完成标志、全局状态act_arr = np.array(act_l, dtype=np.int64) # 行动索引rew_arr = np.array(rew_l, dtype=np.float32)gs_arr = np.array(gs_l, dtype=np.float32).reshape(batch_size, global_dim)next_gs_arr = np.array(next_gs_l, dtype=np.float32).reshape(batch_size, global_dim)done_arr = np.array(done_l, dtype=np.float32)# 转换为张量return QMIXTransition(torch.from_numpy(obs_arr).to(device),torch.from_numpy(act_arr).to(device),torch.from_numpy(rew_arr).unsqueeze(1).to(device),torch.from_numpy(next_obs_arr).to(device),torch.from_numpy(gs_arr).to(device),torch.from_numpy(next_gs_arr).to(device),torch.from_numpy(done_arr).unsqueeze(1).to(device))def __len__(self) -> int:return len(self.memory)
软更新函数
标准的软更新。
def soft_update(target_net: nn.Module, main_net: nn.Module, tau: float) -> None:for target_param, main_param in zip(target_net.parameters(), main_net.parameters()):target_param.data.copy_(tau * main_param.data + (1.0 - tau) * target_param.data)
QMIX 更新步骤
执行集中式的 QMIX 更新的函数。
def update_qmix(memory: QMIXReplayBuffer,batch_size: int,agent_networks: List[AgentQNetwork],target_agent_networks: List[AgentQNetwork],mixer: QMixer,target_mixer: QMixer,optimizer: optim.Optimizer, # 单个优化器用于所有智能体 + 混合器参数gamma: float,tau: float,num_agents: int,action_dim: int) -> float:"""为所有智能体和混合器执行一次 QMIX 更新步骤。返回:- float: TD 损失值。"""if len(memory) < batch_size:return 0.0batch = memory.sample(batch_size)if batch is None: return 0.0obs_b, act_b, rew_b, next_obs_b, gs_b, next_gs_b, done_b = batch# obs_b 形状:(batch_size, num_agents, obs_dim)# act_b 形状:(batch_size, num_agents) -> 行动索引# rew_b 形状:(batch_size, 1)# gs_b 形状:(batch_size, global_state_dim)# done_b 形状:(batch_size, 1)# --- 计算目标 $Q_{tot}'$ --- target_agent_qs_list = []with torch.no_grad():for i in range(num_agents):# 从目标智能体网络获取下一个观测的 Q 值target_q_values_next = target_agent_networks[i](next_obs_b[:, i, :])# 选择使目标 $Q_i$ 最大化的行动max_actions_next = target_q_values_next.argmax(dim=1, keepdim=True) # 形状:(batch_size, 1)# 获取对应于该最大行动的 Q 值max_target_q_next = torch.gather(target_q_values_next, 1, max_actions_next)target_agent_qs_list.append(max_target_q_next)# 堆叠目标智能体 Q 值:(batch_size, num_agents)target_agent_qs = torch.cat(target_agent_qs_list, dim=1)# 使用目标混合器计算目标 $Q_{tot}'$q_tot_target = target_mixer(target_agent_qs, next_gs_b)# 计算 TD 目标 $y = r + \gamma \times Q_{tot}' \times (1 - done)$y = rew_b + gamma * (1.0 - done_b) * q_tot_target# --- 计算当前 $Q_{tot}$ --- current_agent_qs_list = []for i in range(num_agents):# 从主智能体网络获取当前观测的 Q 值q_values_current = agent_networks[i](obs_b[:, i, :])# 选择缓冲区中采取的行动对应的 Q 值action_i = act_b[:, i].unsqueeze(1) # 形状:(batch_size, 1)q_current_i = torch.gather(q_values_current, 1, action_i)current_agent_qs_list.append(q_current_i)# 堆叠当前智能体 Q 值:(batch_size, num_agents)current_agent_qs = torch.cat(current_agent_qs_list, dim=1)# 使用主混合器计算当前 $Q_{tot}$q_tot_current = mixer(current_agent_qs, gs_b)# --- 计算损失并优化 --- loss = F.mse_loss(q_tot_current, y)optimizer.zero_grad()loss.backward()# 可选的梯度裁剪# total_norm = torch.nn.utils.clip_grad_norm_([param for net in agent_networks for param in net.parameters()] + # list(mixer.parameters()), max_norm=1.0)optimizer.step()# --- 更新目标网络 --- for i in range(num_agents):soft_update(target_agent_networks[i], agent_networks[i], tau)soft_update(target_mixer, mixer, tau)return loss.item()
运行 QMIX 算法
超参数设置
# QMIX 在自定义多智能体网格世界中的超参数
BUFFER_SIZE_QMIX = int(5e4) # 对于简单环境,较小的缓冲区可能就足够了
BATCH_SIZE_QMIX = 64
GAMMA_QMIX = 0.99
TAU_QMIX = 1e-3 # 软更新因子
LR_QMIX = 5e-4 # 智能体网络和混合器的学习率
EPSILON_QMIX_START = 1.0
EPSILON_QMIX_END = 0.05
EPSILON_QMIX_DECAY = 100000 # 在 N 步内衰减
MIXING_EMBED_DIM = 32 # 混合网络中的嵌入维度
HYPERNET_HIDDEN = 64 # 超网络的隐藏大小NUM_EPISODES_QMIX = 600
MAX_STEPS_PER_EPISODE_QMIX = 100
UPDATE_EVERY_QMIX = 4 # 每 N 个环境步骤执行一次更新
TARGET_UPDATE_FREQ_QMIX = 100 # 目标网络软更新的步数(替代方案)
USE_SOFT_UPDATE = True # 使用软更新(True)或定期硬更新(False)
初始化
# 初始化环境
env_qmix = MultiAgentGridEnv_QMIX(size=5, num_agents=2)
num_agents_qmix = env_qmix.num_agents
obs_dim_qmix = env_qmix.observation_dim_per_agent
global_state_dim_qmix = env_qmix.global_state_dim
action_dim_qmix = env_qmix.action_dim# 初始化智能体网络和目标网络
agent_networks = [AgentQNetwork(obs_dim_qmix, action_dim_qmix).to(device) for _ in range(num_agents_qmix)]
target_agent_networks = [AgentQNetwork(obs_dim_qmix, action_dim_qmix).to(device) for _ in range(num_agents_qmix)]
for i in range(num_agents_qmix):target_agent_networks[i].load_state_dict(agent_networks[i].state_dict())for p in target_agent_networks[i].parameters(): p.requires_grad = False# 初始化混合网络和目标混合网络
mixer = QMixer(num_agents_qmix, global_state_dim_qmix, MIXING_EMBED_DIM).to(device)
target_mixer = QMixer(num_agents_qmix, global_state_dim_qmix, MIXING_EMBED_DIM).to(device)
target_mixer.load_state_dict(mixer.state_dict())
for p in target_mixer.parameters(): p.requires_grad = False# 收集所有参数用于单个优化器
all_params = list(mixer.parameters())
for net in agent_networks:all_params.extend(list(net.parameters()))# 初始化优化器
optimizer_qmix = optim.Adam(all_params, lr=LR_QMIX)# 初始化回放缓冲区
memory_qmix = QMIXReplayBuffer(BUFFER_SIZE_QMIX)# 用于绘图的列表
qmix_episode_rewards = []
qmix_episode_losses = []
qmix_episode_epsilons = []
训练循环
print("开始 QMIX 训练...")total_steps_qmix = 0
epsilon = EPSILON_QMIX_STARTfor i_episode in range(1, NUM_EPISODES_QMIX + 1):obs_list_np, global_state_np = env_qmix.reset_qmix()episode_reward = 0episode_loss = 0num_updates_ep = 0for t in range(MAX_STEPS_PER_EPISODE_QMIX):# --- 行动选择(分散式 $\epsilon$-贪婪) --- actions_list = []for i in range(num_agents_qmix):obs_tensor = torch.from_numpy(obs_list_np[i]).float().to(device)agent_networks[i].eval() # 评估模式用于选择with torch.no_grad():q_values = agent_networks[i](obs_tensor)agent_networks[i].train() # 恢复训练模式if random.random() < epsilon:action = random.randrange(action_dim_qmix)else:action = q_values.argmax().item()actions_list.append(action)# --- 环境交互 --- next_obs_list_np, next_global_state_np, reward, done = env_qmix.step_qmix(actions_list)# --- 存储经验 --- memory_qmix.push(obs_list_np, actions_list, reward, next_obs_list_np, global_state_np, next_global_state_np, done)# 更新当前状态 / 观测obs_list_np = next_obs_list_npglobal_state_np = next_global_state_npepisode_reward += rewardtotal_steps_qmix += 1# --- 更新网络 --- if len(memory_qmix) > BATCH_SIZE_QMIX and total_steps_qmix % UPDATE_EVERY_QMIX == 0:loss = update_qmix(memory_qmix, BATCH_SIZE_QMIX,agent_networks, target_agent_networks,mixer, target_mixer,optimizer_qmix,GAMMA_QMIX, TAU_QMIX if USE_SOFT_UPDATE else 1.0, # 如果是硬更新,则 Tau=1.0num_agents_qmix, action_dim_qmix)episode_loss += lossnum_updates_ep += 1# --- 目标网络更新逻辑 --- if not USE_SOFT_UPDATE and total_steps_qmix % TARGET_UPDATE_FREQ_QMIX == 0:# 定期硬更新for i in range(num_agents_qmix):target_agent_networks[i].load_state_dict(agent_networks[i].state_dict())target_mixer.load_state_dict(mixer.state_dict())# 如果 USE_SOFT_UPDATE 为 True,则在 update_qmix 中进行软更新# 衰减 epsilon(基于步数的衰减)epsilon = max(EPSILON_QMIX_END, EPSILON_QMIX_START - total_steps_qmix / EPSILON_QMIX_DECAY * (EPSILON_QMIX_START - EPSILON_QMIX_END))if done:break# --- 剧集结束 --- qmix_episode_rewards.append(episode_reward)qmix_episode_losses.append(episode_loss / num_updates_ep if num_updates_ep > 0 else 0)qmix_episode_epsilons.append(epsilon)# 打印进度if i_episode % 50 == 0:avg_reward = np.mean(qmix_episode_rewards[-50:])avg_loss = np.mean(qmix_episode_losses[-50:])print(f"剧集 {i_episode}/{NUM_EPISODES_QMIX} | 步骤数:{total_steps_qmix} | 平均奖励:{avg_reward:.2f} | 平均损失:{avg_loss:.4f} | Epsilon:{epsilon:.3f}")print("QMIX 训练完成。")
开始 QMIX 训练...
剧集 50/600 | 步骤数:3981 | 平均奖励:-70.69 | 平均损失:0.3158 | Epsilon:0.962
剧集 100/600 | 步骤数:7651 | 平均奖励:-50.70 | 平均损失:0.0936 | Epsilon:0.927
剧集 150/600 | 步骤数:10213 | 平均奖励:-32.85 | 平均损失:0.0371 | Epsilon:0.903
剧集 200/600 | 步骤数:12701 | 平均奖励:-27.53 | 平均损失:0.0442 | Epsilon:0.879
剧集 250/600 | 步骤数:15222 | 平均奖励:-24.79 | 平均损失:0.0468 | Epsilon:0.855
剧集 300/600 | 步骤数:17356 | 平均奖励:-19.04 | 平均损失:0.0500 | Epsilon:0.835
剧集 350/600 | 步骤数:19198 | 平均奖励:-14.75 | 平均损失:0.0539 | Epsilon:0.818
剧集 400/600 | 步骤数:20969 | 平均奖励:-13.01 | 平均损失:0.0618 | Epsilon:0.801
剧集 450/600 | 步骤数:22741 | 平均奖励:-13.86 | 平均损失:0.0642 | Epsilon:0.784
剧集 500/600 | 步骤数:24157 | 平均奖励:-7.86 | 平均损失:0.0676 | Epsilon:0.771
剧集 550/600 | 步骤数:25939 | 平均奖励:-13.20 | 平均损失:0.0675 | Epsilon:0.754
剧集 600/600 | 步骤数:27128 | 平均奖励:-5.17 | 平均损失:0.0629 | Epsilon:0.742
QMIX 训练完成。
可视化学习过程
绘制剧集奖励、TD 损失和 epsilon 衰减的图表。
# 绘制 QMIX 的结果
plt.figure(figsize=(18, 4))# 剧集奖励(共享)
plt.subplot(1, 3, 1)
plt.plot(qmix_episode_rewards)
plt.title('QMIX 网格世界:剧集奖励(共享)')
plt.xlabel('剧集')
plt.ylabel('总奖励')
plt.grid(True)
if len(qmix_episode_rewards) >= 50:rewards_ma_qmix = np.convolve(qmix_episode_rewards, np.ones(50)/50, mode='valid')plt.plot(np.arange(len(rewards_ma_qmix)) + 49, rewards_ma_qmix, label='50 剧集移动平均', color='orange')plt.legend()# TD 损失 / 剧集
plt.subplot(1, 3, 2)
plt.plot(qmix_episode_losses)
plt.title('QMIX 网格世界:每剧集平均 TD 损失')
plt.xlabel('剧集')
plt.ylabel('平均 MSE 损失')
plt.yscale('log') # 如果损失变化很大,则使用对数刻度
plt.grid(True, which='both')
if len(qmix_episode_losses) >= 50:loss_ma_qmix = np.convolve(qmix_episode_losses, np.ones(50)/50, mode='valid')# 避免对数刻度下绘制 0 或负值(如果损失非常低)valid_indices = np.where(loss_ma_qmix > 1e-8)[0] if len(valid_indices) > 0:plt.plot(np.arange(len(loss_ma_qmix))[valid_indices] + 49, loss_ma_qmix[valid_indices], label='50 剧集移动平均', color='orange')plt.legend()# Epsilon
plt.subplot(1, 3, 3)
plt.plot(qmix_episode_epsilons)
plt.title('QMIX:Epsilon 衰减')
plt.xlabel('剧集')
plt.ylabel('Epsilon')
plt.grid(True)plt.tight_layout()
plt.show()
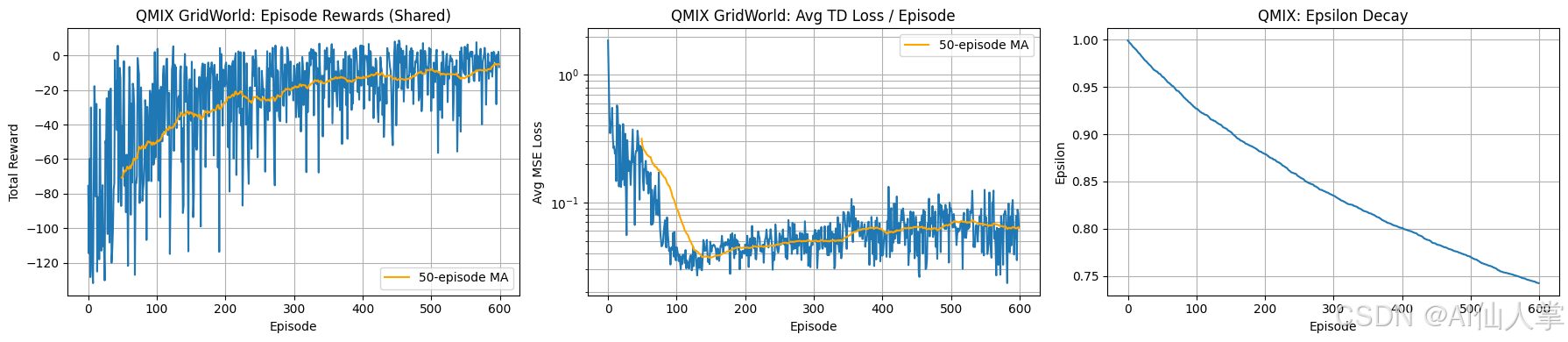
QMIX 学习曲线分析(网格世界 - 共享奖励):
-
剧集奖励(共享):
- 观察结果: 学习过程显示出明显的、尽管缓慢且嘈杂的改进趋势。每剧集的总共享奖励起初非常低(大约 -120),并且极其不稳定。50 剧集移动平均值(橙色线)显示从第 100 剧集开始有一个明显的向上爬升趋势,最终在第 500-600 剧集时稳定在 -10 到 -20 之间。尽管平均值有所改善,但原始剧集奖励(蓝色线)在整个 600 剧集期间保持很高的方差,经常在接近零的值和显著的负值之间大幅波动。
- 解释: 这表明 QMIX 智能体团队正在学习协调以实现更高的共享奖励,明显地远离了最初的糟糕表现。移动平均值的逐渐爬升证实了在更长时间尺度上的成功学习。然而,持续的高方差是多智能体协调挑战的特征。QMIX 依赖于个体智能体根据其局部 Q 值贪婪行动,这些值通过一个单调的混合网络组合。尽管这种结构有助于学习,但找到一致的最优联合行动仍然很困难,导致了奖励的波动。
-
每剧集平均 TD 损失:
- 观察结果: 在对数刻度上绘制,混合网络的平均 TD(时间差分)损失在最初的 100 剧集内急剧下降,大约减少了两个数量级。在这一快速的初始下降之后,损失稳定在一个较低的平均水平(大约 0.01),在剩余的训练期间表现出适度的波动。移动平均值确认了这种收敛模式。
- 解释: 这个图表至关重要,因为它反映了集中式混合网络在基于个体智能体的当前估计学习团队价值函数( Q t o t Q_{tot} Qtot)方面的表现。急剧的初始下降表明混合网络很快就能熟练地根据智能体的 Q 值表示团队价值函数。随后在低水平的稳定表明价值函数学习部分的 QMIX 运行良好,为选择联合行动提供了一个一致的基础,即使智能体的策略(因此它们的 Q i Q_i Qi 值)可能仍在演变。
-
Epsilon 衰减:
- 观察结果: 探索参数 epsilon 遵循预定义的衰减计划,从 1.0 开始,到第 600 剧集时大约减少到 0.74。衰减看起来相对缓慢,可能是线性或轻微指数型的。
- 解释: 这显示了基于 Q 学习的方法中使用的标准 epsilon-greedy 探索策略。从 epsilon=1.0 开始,智能体逐渐减少采取随机行动的倾向,越来越多地利用学习到的 Q 值。在第 600 剧集时仍然相对较高的 epsilon 值表明在整个展示的训练期间保持了相当程度的探索。这种持续的探索可能有助于发现更好的策略,但它也可能阻碍更快地收敛到一个完全稳定的、利用性的策略。
总体结论:
QMIX 在多智能体网格世界任务中成功地进行了学习,在 600 剧集内显著提高了共享团队奖励。其核心机制,学习个体 Q 函数并通过一个收敛良好的混合网络进行组合(由低 TD 损失所表明),被证明是估计价值的有效方法。然而,与 MADDPG 类似,团队的整体表现仍然高度不稳定,这表明基于分解的价值函数实现一致的最优协调是具有挑战性的。缓慢的 epsilon 衰减可能有助于这种持续的方差,因为它在整个训练期间维持了相当程度的探索。
分析学习到的策略(测试)
使用从它们学习到的 Q i Q_i Qi 网络派生出的贪婪策略,测试智能体以分散式的方式行动。
def test_qmix_agents(agent_nets: List[AgentQNetwork], env_instance: MultiAgentGridEnv_QMIX, num_episodes: int = 5, seed_offset: int = 6000) -> None:""" 测试训练好的 QMIX 智能体以分散式方式(贪婪策略)行动。 """print(f"\n--- 测试 QMIX 智能体({num_episodes} 剧集) ---")all_episode_rewards = []for i in range(num_episodes):obs_list_np, _ = env_instance.reset_qmix()episode_reward = 0done = Falset = 0while not done and t < MAX_STEPS_PER_EPISODE_QMIX:actions_list = []for agent_id in range(env_instance.num_agents):obs_tensor = torch.from_numpy(obs_list_np[agent_id]).float().to(device)agent_nets[agent_id].eval() # 设置为评估模式with torch.no_grad():q_values = agent_nets[agent_id](obs_tensor)action = q_values.argmax().item() # 贪婪行动actions_list.append(action)# 执行环境步骤next_obs_list_np, _, reward, done = env_instance.step_qmix(actions_list)# 更新观测obs_list_np = next_obs_list_npepisode_reward += rewardt += 1print(f"测试剧集 {i+1}: 奖励 = {episode_reward:.2f}, 长度 = {t}")all_episode_rewards.append(episode_reward)print(f"--- 测试完成。平均奖励:{np.mean(all_episode_rewards):.2f} ---")# 运行测试剧集
test_qmix_agents(agent_networks, env_qmix, num_episodes=5)
--- 测试 QMIX 智能体(5 剧集) ---
测试剧集 1: 奖励 = 8.65, 长度 = 4
测试剧集 2: 奖励 = 8.65, 长度 = 4
测试剧集 3: 奖励 = 8.65, 长度 = 4
测试剧集 4: 奖励 = 8.65, 长度 = 4
测试剧集 5: 奖励 = 8.65, 长度 = 4
--- 测试完成。平均奖励:8.65 ---
QMIX 的常见挑战和扩展
挑战:有限的表示能力
- 问题: 单调性约束( ∂ Q t o t ∂ Q i ≥ 0 \frac{\partial Q_{tot}}{\partial Q_i} \ge 0 ∂Qi∂Qtot≥0)限制了 QMIX 可以表示的联合行动价值函数的类别。它无法表示某些状态下需要牺牲一个智能体的高效用以实现团队更大利益的情况(需要非单调混合)。
- 解决方案:
- QTRAN: 扩展 QMIX 以处理更广泛的分解类别。
- 加权 QMIX: 引入依赖于状态的权重,可以为负值,从而放宽严格的单调性约束。
- QPLEX: 使用 dueling 架构实现更通用的价值分解。
挑战:全局状态需求
- 问题: 混合网络在集中式训练期间需要访问全局状态 x x x。这可能并不总是可用的,或者可能非常高维。
- 解决方案:
- 近似全局状态: 使用聚合信息或智能体之间的通信来近似全局状态。
- 替代方法: 使用依赖于紧凑全局状态表示的方法。
挑战:多智能体环境中的探索
- 问题: 协调探索可能很困难。在个体智能体上简单地使用 ϵ \epsilon ϵ-greedy 可能不足以发现复杂的联合策略。
解决方案:- 更复杂的探索: 技术如 MAVEN 通过引入潜在变量来鼓励多样化的联合探索策略。
- 参数噪声: 给智能体网络参数添加噪声。
挑战:超参数敏感性
- 问题: 与许多 DRL 算法一样,QMIX 的性能取决于对学习率、目标更新频率 / 率、缓冲区 / 批量大小和探索参数等的精心调整。
解决方案:系统地调整,并使用常见的成功设置作为起始点。
扩展:
- VDN(价值分解网络): 一个更简单的前身,其中 Q t o t = ∑ i Q i Q_{tot} = \sum_i Q_i Qtot=∑iQi$。缺乏依赖于状态的混合。
- QTRAN、QPLEX、加权 QMIX: 放宽单调性约束以获得更大的表示能力。
- MAVEN: 通过学习潜在探索空间来改进探索。
结论
QMIX 是一种用于合作式多智能体强化学习的极具影响力的基于价值的算法。其核心贡献是单调价值函数分解,使得集中式训练稳定,分散式执行高效。通过学习个体智能体 Q 函数,并通过一个依赖于状态的混合网络以单调的方式将它们组合起来,QMIX 有效地解决了许多合作任务中的功劳分配问题。
尽管其表示能力受到单调性约束的限制,QMIX 在可扩展性方面具有显著优势(与学习完整的联合 Q 函数相比),并且为许多后续的 MARL 价值分解方法提供了坚实的基础。它在诸如 SMAC 等基准测试中的成功,突显了结构化价值函数分解在合作式多智能体问题中的强大能力。