SLAM定位与地图构建
SLAM介绍
SLAM全称Simultaneous Localization And Mapping,中文名称同时定位与地图构建。旨在让移动设备在未知环境中同时完成以下两个任务(定位需要地图,而建图又依赖定位信息,两者互为依赖):
-
定位(Localization):确定自身在环境中的位置和姿态(如坐标、朝向)。
-
建图(Mapping):构建环境的地图(如2D栅格地图、3D点云地图)。
SLAM基本流程:
-
传感器数据获取
-
使用激光雷达(LiDAR)、摄像头(视觉SLAM)、IMU(惯性测量单元)、超声波等传感器采集环境数据。
-
例如:激光雷达获取点云,摄像头提取特征点。
-
-
前端处理(Frontend)
-
特征提取与匹配:从传感器数据中提取关键特征(如角点、线段、ORB特征点)。
-
运动估计:通过相邻帧数据(如两帧图像或激光扫描)估计机器人的运动(如ICP、视觉里程计VO)。
-
初步定位:计算当前位姿(位置+姿态)的变化。
-
-
后端优化(Backend)
-
位姿图优化(Pose Graph Optimization):利用图优化(如g2o、GTSAM)或滤波(如EKF、粒子滤波)消除累积误差。
-
全局一致性:确保地图和轨迹的长期准确性。
-
-
建图(Mapping)
-
根据优化后的位姿和传感器数据,构建环境的地图:
-
2D地图(如栅格地图,用于扫地机器人)。
-
3D地图(如点云地图或TSDF地图,用于自动驾驶)。
-
-
-
回环检测(Loop Closure)
-
识别机器人是否回到之前访问过的地点,以修正累积误差。
-
例如:通过视觉词袋(BoW)或激光特征匹配判断是否闭环。
-
SLAM的按传感器类型分类
-
激光SLAM(如HectorSLAM、Cartographer):使用LiDAR数据,适合结构化环境(如室内)。
-
视觉SLAM(VSLAM)(如ORB-SLAM、LSD-SLAM):使用摄像头,适合纹理丰富的场景。
-
多传感器融合SLAM(如VINS-Fusion):结合视觉+IMU+LiDAR,提升鲁棒性。
这里着重介绍激光雷达SLAM 2D地图:
机器人搭载的激光雷达通过它的驱动节点发布一个雷达数据话题/scan,激光雷达的测距数值以数据包的形式发布到/scan话题,SLAM节点只需要订阅/scan话题就能获得激光雷达的测距数值了。SLAM节点需要发布一个地图数据话题/map,将SLAM生成的地图消息发送到/map话题中,就可以使用rviz来显示地图的形状了
ROS的2D建图使用栅格地图。SLAM建图的初始状态就是就是一堆未知的栅格,颜色为灰色,栅格值为-1代表格子的障碍物状况未知。接下来使用激光雷达作为传感器获取数据,被激光雷达穿透的栅格将会被标记为白色,数值为0表示这个栅格内无障碍物,而激光被阻挡的栅格将会被标记为黑色,数值为100表示这个栅格里存在障碍物,其他没有被扫描的栅格依然为灰色。
如下图1表示机器人在初始状态激光雷达扫描一周所建图,下图2表示机器人行走一段时间后激光雷达扫描一周所建图,根据转角特征,可以将两张图进行拼合。在激光雷达SLAM中,可以合并的参照物特征是障碍物栅格的排布形状。实际上机器人移动一小段距离雷达可以扫描上百次,所以根据栅格特征合并地图比较精准。机器人不断移动,地图不断拼接,最终就会得到一个比较完整的全局地图


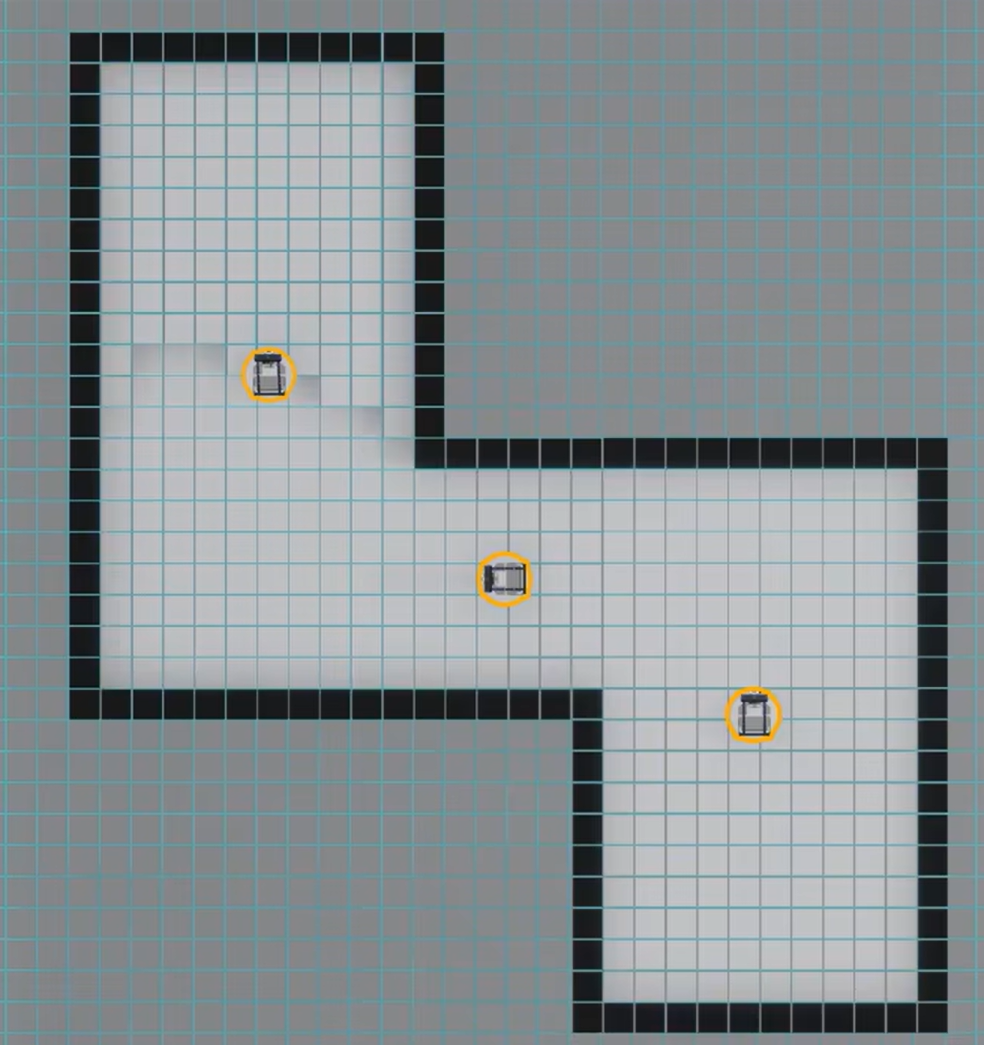
注意,激光雷达SLAM的建图过程并非简单地“每扫描一圈生成一个独立地图再拼接”,而是通过增量式融合和全局优化逐步构建全局地图。 基本过程如下
(1)单次扫描的数据处理
激光雷达每扫描一圈(如10Hz频率)会获取一帧点云数据(Point Cloud),但这一帧数据本身只是环境的“一片切片”,不能直接称为“地图”。
-
预处理:去除噪声、运动畸变校正(因机器人运动导致的点云扭曲)。
-
特征提取(可选):提取直线、角点等特征(如LOAM算法)。
(2)帧间匹配(Scan Matching)
将当前帧点云与上一帧(或局部地图)对齐,估计机器人的位姿变化(位移+旋转)。常用方法:
-
ICP(Iterative Closest Point):通过迭代最小化点云距离匹配两帧数据。
-
NDT(Normal Distributions Transform):将点云转换为概率分布进行匹配。
-
特征匹配(如基于线/面特征的匹配)。
(3)局部地图(Submap)构建
-
连续多帧点云会融合成一个局部地图(Submap),而非独立保存每一帧。
-
例如:Cartographer将几十次扫描的点云叠加为一个Submap,降低计算量。
(4)全局地图(Global Map)拼接
局部地图通过位姿图优化(Pose Graph Optimization)拼接为全局地图,而非简单叠加。关键步骤:
-
回环检测(Loop Closure)
-
当机器人回到之前访问的区域时,系统检测当前扫描与历史Submap的相似性(如匹配点云或特征)。
-
方法:Scan-to-Submap匹配、分支定界法(Branch-and-Bound)等。
-
-
位姿图优化
-
将回环约束、里程计约束、IMU数据等构建成图(节点=位姿,边=约束)。
-
使用优化库(如g2o、Ceres Solver)最小化全局误差,修正所有Submap的位姿。
-
-
地图融合
-
优化后的Submap位姿用于将局部地图对齐到全局坐标系中,最终拼接成一致的全局地图。
-
SLAM建图算法
1.Hector_Mapping
安装:sudo apt install ros-noetic-hector-mapping
要求激光雷达扫描频率高(如 40Hz 以上)且数据质量好
输入和输出数据
Hector_Mapping输入为/scan话题和/syscommand话题,syscommand主要用来接收reset这类重新建图的指令

Hector_Mapping输出如下

第一个map_metadata是地图数据,其消息数据类型如下,主要包括地图加载时间、地图分辨率 、地图宽和高和地图的原点坐标。显然这些都是地图的描述信息
 发布的第二个话题/map就是栅格地图数据。后面两个话题slam_out_pose和poseupdate分别是原始和校正后的的机器人定位数据
发布的第二个话题/map就是栅格地图数据。后面两个话题slam_out_pose和poseupdate分别是原始和校正后的的机器人定位数据
关于Hector_Mapping的具体参数,可以进入ROS wiki找hector_mapping的参数
2.Gmapping
Hector_Mapping不依赖轮式里程计,仅依靠激光雷达(LIDAR)数据和高频率的扫描匹配(scan matching)实现位姿估计和建图。通过匹配当前激光扫描与已有地图的几何特征,直接优化机器人位姿。所以建图的重点就是找地图的几何特征。
但是gmapping融合激光雷达数据和轮式里程计信息,通过粒子滤波估计机器人轨迹和地图,需要里程计作为运动模型的初始估计,粒子滤波在此基础上优化位姿。也就是说建图的重点不仅在于找地图的几何特征,还有里程计信息来记录机器人走了多远。这样的好处是,如果机器人运行在一个长直走廊,由于两侧都是墙壁并且激光雷达检测到墙壁的距离是不变的,对于没有里程计信息的Hector_Mapping,ROS就会认为小车没有移动而停在原地,但是Gmapping通过里程计就可以得知机器人仍在运动,并继续建图过程。Gmapping可兼容低频率激光雷达(如 10Hz)且对里程计噪声有一定容错能力。
里程计
里程计是机器人通过自身运动传感器(如编码器、IMU、视觉等)估计相对位姿变化的技术,通常输出机器人的位移和转角(即 Δx, Δy, Δθ)。它不依赖外部环境信息,属于递推定位(Dead Reckoning),会随着时间累积误差。
常见里程计类型
-
轮式里程计(Wheel Odometry):通过电机编码器测量轮子转动圈数,结合轮径和底盘模型计算机器人位移。
-
视觉里程计(VO, Visual Odometry):通过摄像头连续帧间的特征匹配或光流估计运动。
-
惯性里程计(IMU Odometry):使用加速度计和陀螺仪积分得到运动轨迹。
里程计(Odometry)既依赖硬件传感器获取原始数据,又需要软件算法计算位姿变化,这个算法会运行在机器人的驱动节点中,根据电机的转动数据计算机器人位移信息,这个位移信息会以tf消息包的形式发布到/tf话题中。激光雷达SLAM要输出的是map到base_footprint(小车底盘)的tf坐标变换信息,里程计要输出的是map到odom的tf坐标变换信息,实际上是在tf树中是map->odom->base_footprint的父子关系,也就说要发布map到base_footprint的tf坐标变换信息,需要获取map到odom的坐标变换信息和odom到base_footprint的坐标信息,拼接后即为map到base_footprint的tf坐标变换信息。odom更新频率很高(100+Hz)可进行短期运动预测,提供机器人短期运动平滑估计,而map(数据来源于SLAM算法(激光匹配)更新频率较低)可进行全局较准,无累积误差,提供全局一致的地图和定位,SLAM算法(如gmapping)通过激光匹配计算出一个更准确的位姿,并计算odom→map的变换(tf),这个变换会逐步修正 odom 的漂移,保证长期定位准确。
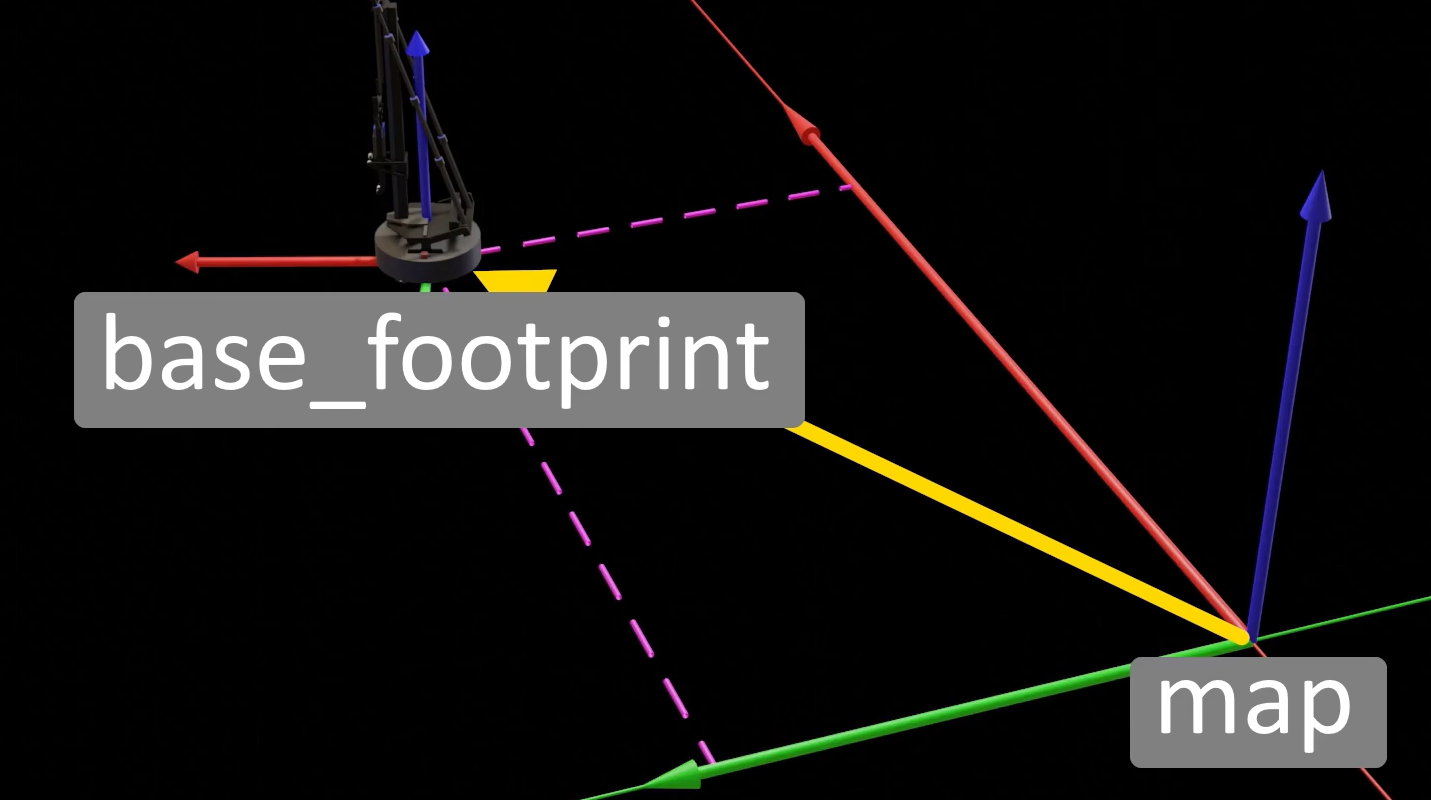
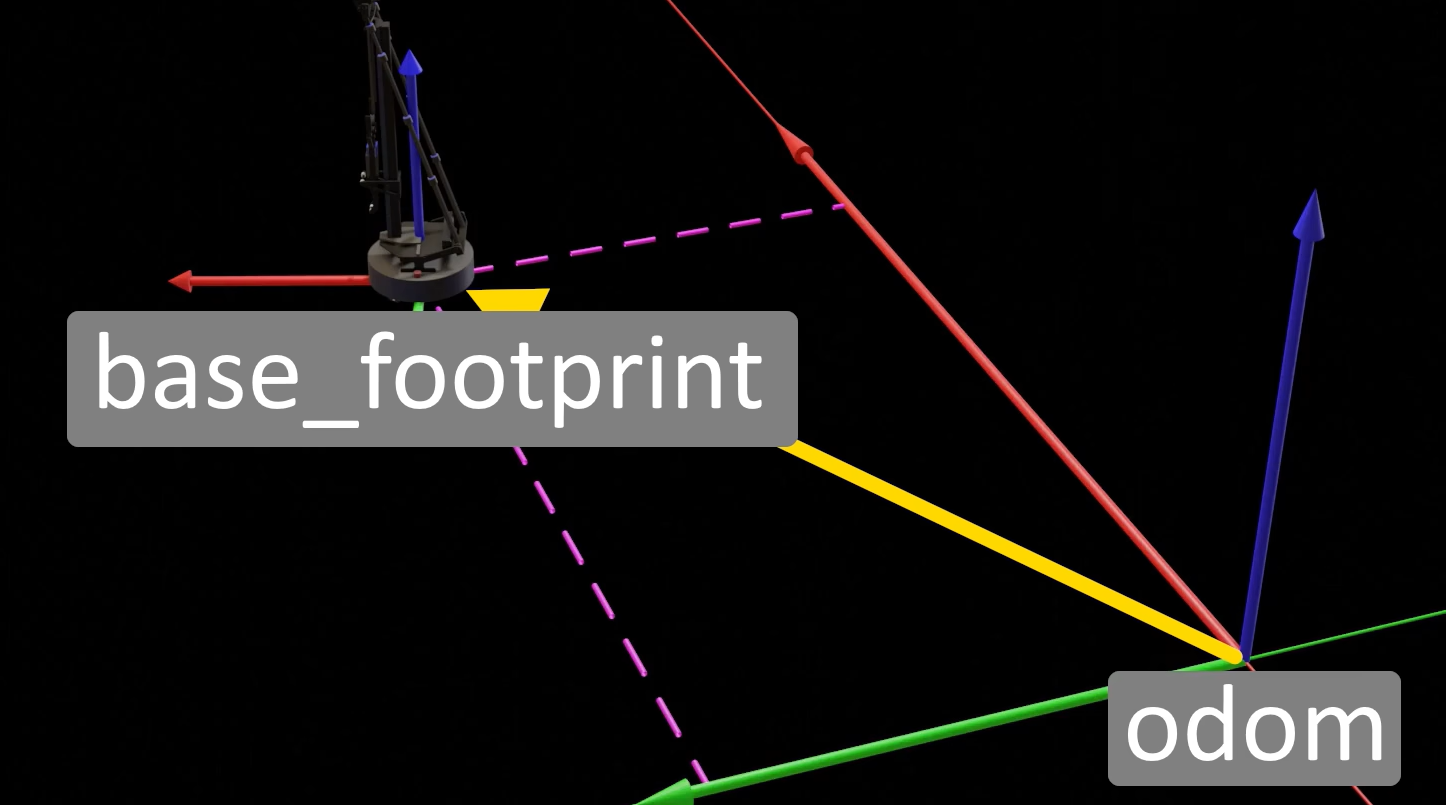
里程计计算的只是一个机器人位移的理论值,必然会和实际情况存在一些偏差,而且机器人走的越远,这个误差还会累积,这时就需要用到激光雷达检测障碍物特征用的障碍物点云配准的定位算法(也就是Hector_Mapping用的建图方法)进行误差纠正。
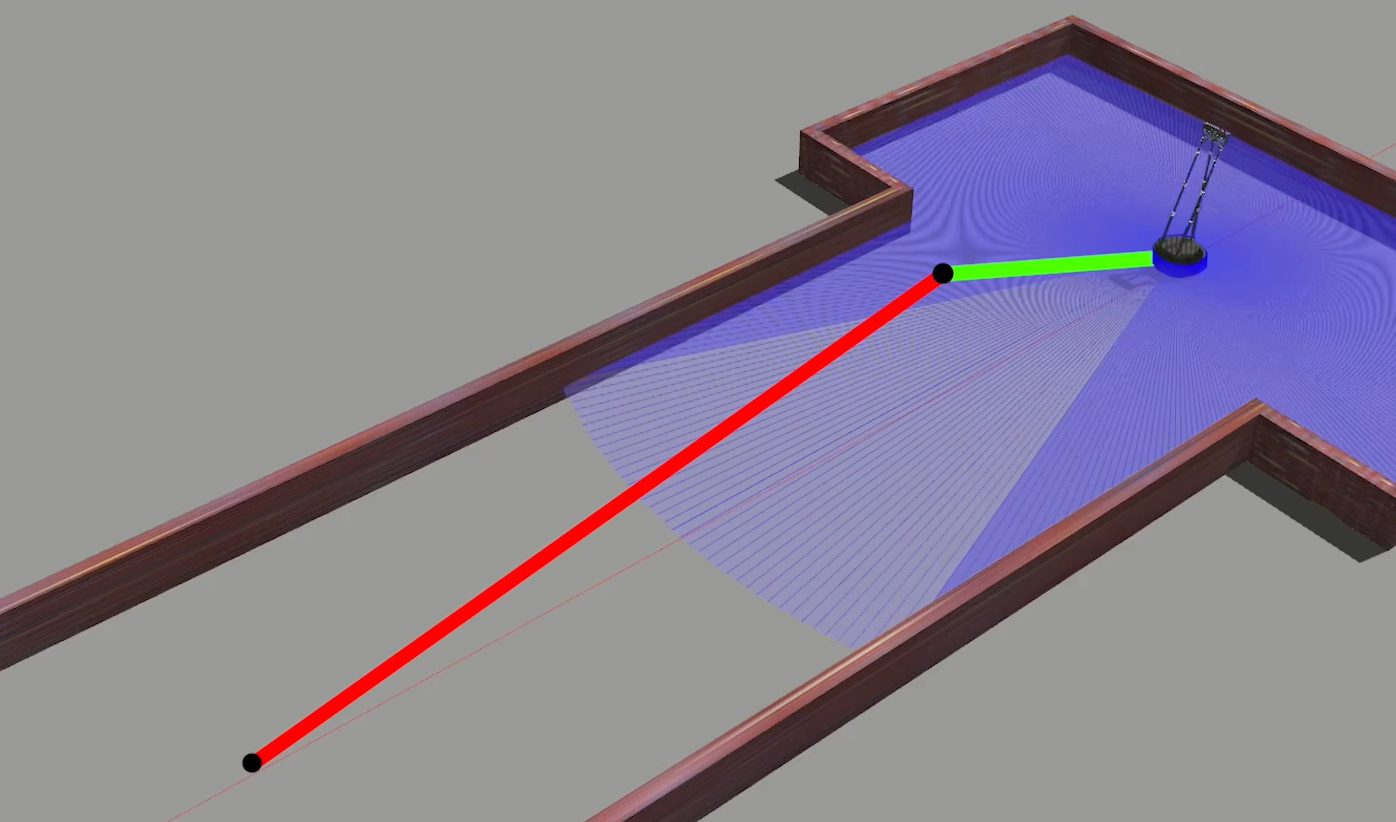
如下图,根据里程计信息机器人走的路线如红线所示,但是机器人的实际位置根据激光雷达点云信息(蓝线)是在如图所示的位置。这就是里程计累计产生的误差
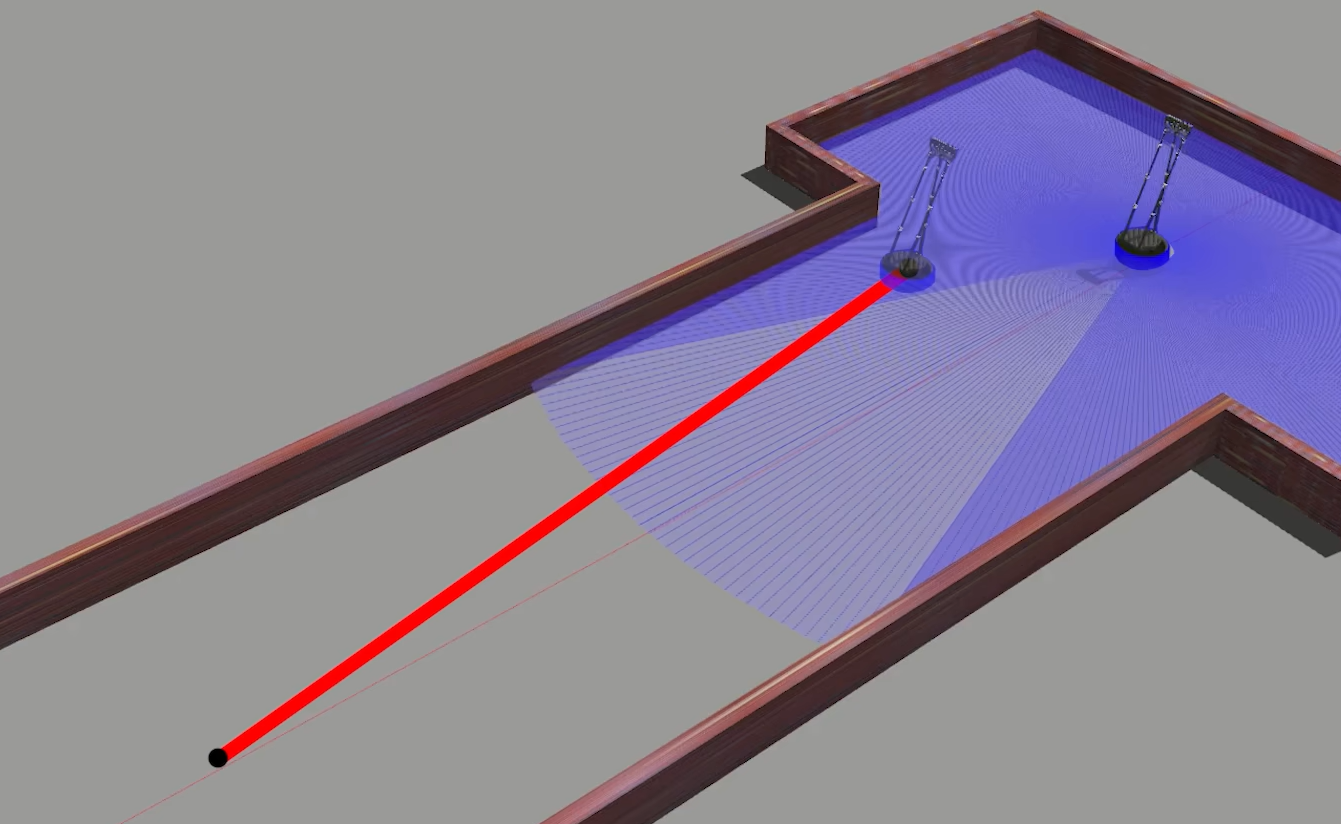
这时将机器人位置拉到正确的位置,只需要在里程计估算的位置上加上一段位移(绿线)即可。
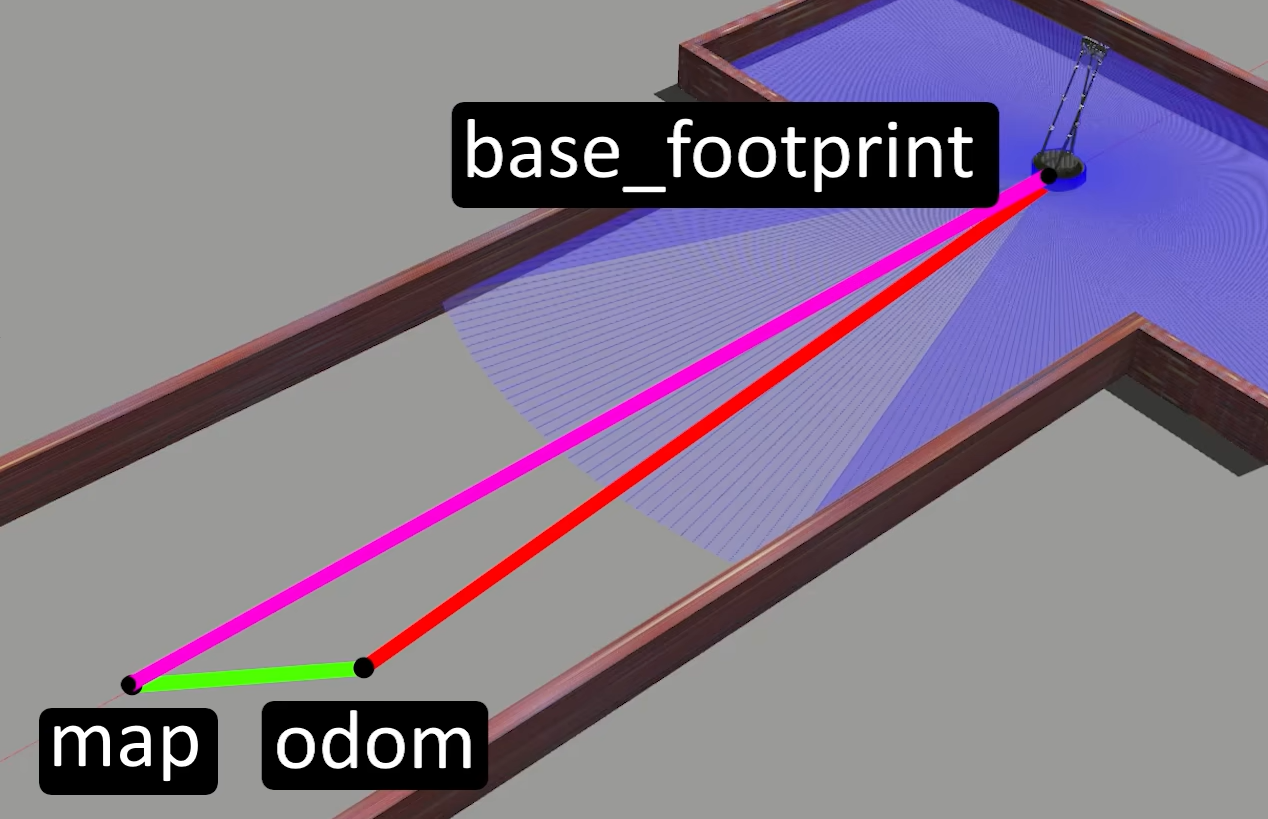
但这里有个问题,里程计输出的是odom到base_footprint的TF,而SLAM节点要输出的是map到base_footprint的TF,但这时base_footprint已经被里程计占用了,SLAM就会把绿线这段TF挪到跟端的odom之前和odom到base_footprint这段TF连接起来,就实现了map到base_footprint的TF(开始时map和odom重合,odom 坐标系相对于 map 的偏离(即 map → odom 的变换)直接反映了SLAM算法对里程计误差的修正)。如果直接让base_footprint跳到“真实位置”,控制器会认为机器人“瞬间移动了”,导致电机速度突变(可能急停或加速)导航规划失效(如路径跟踪出现震荡)等等。SLAM 的修正作用在 map → odom 上,相当于“悄悄调整里程计的坐标系”,让base_footprint在全局(map 系)下逐渐对齐到正确位置,而不会引起跳变。
可以参考以下过程理解:
假设:机器人实际向前移动了 4.8 米(真实值)。但里程计因轮子打滑,认为移动了 5.0 米(误差 +0.2m)。SLAM 通过激光匹配发现误差,需要修正。
-
当前
odom → base_link=(5.0, 0, 0)(仍然由里程计提供,保持平滑)。 -
SLAM 计算
map → odom=(-0.2, 0, 0)(表示里程计多算了0.2米)。 -
全局位姿
map → base_link=map → odom+odom → base_link=4.8m(正确值)。 -
结果:
base_link在odom系下仍然是连续运动的,但全局位置已修正。
像这样,先使用里程计推算机器人的位移,然后通过雷达点云贴合障碍物轮廓修正里程计误差的方法就是Gmapping的核心算法
Gmapping核心原理
Gmapping 基于粒子滤波(Rao-Blackwellized Particle Filter, RBPF) 实现,其核心思想是通过融合激光数据和里程计信息,估计机器人的轨迹并构建环境地图。
Gmapping 的核心是 Rao-Blackwellized 粒子滤波,它将 SLAM 问题分解为:机器人位姿估计(用粒子滤波实现)和地图构建(基于已知位姿的激光数据拼接)。
RBPF 的核心思想:
-
每个粒子(Particle)代表一个可能的机器人轨迹假设。
-
每个粒子独立维护一张地图(即“如果机器人按这个轨迹走,地图应该长这样”)。
-
通过激光匹配和重采样(Resampling)筛选出最可信的粒子,最终用最优粒子的地图作为输出。
Gmapping 的流程可分为以下步骤:
(1) 初始化
-
生成
N个粒子(默认N=30),每个粒子的初始位姿相同(通常设为(0,0,0))。 -
每个粒子初始化一张空白地图(栅格地图,分辨率通常
0.05m)。
(2) 运动更新(Prediction)
-
当收到里程计数据时,根据 运动模型 预测每个粒子的新位姿:
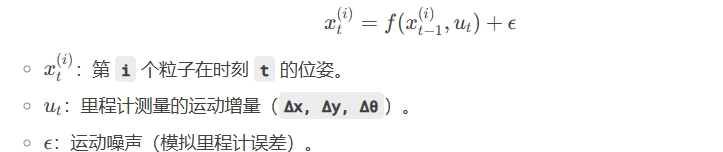
- 比如说里程计测量移动
0.1m,并不是所有粒子都移动了0.1m,而是每个粒子的实际移动量会加入随机噪声(用来模拟里程计误差),例如,某些粒子可能移动0.09m,另一些0.11m(取决于噪声参数alpha1~alpha4)
![]()
(3) 观测更新(Correction)
当收到激光扫描数据 z_t 时,对每个粒子执行:
-
扫描匹配(Scan Matching):用当前激光数据和粒子维护的地图匹配,计算最优位姿修正 Δx。不是简单比较激光数据与地图的“相似度”,而是计算似然概率:即“当前激光数据在粒子位姿和地图下的概率”。
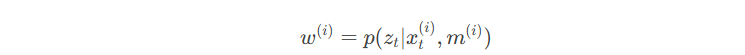
- 权重计算:根据匹配结果更新粒子权重:即“当前激光数据与粒子地图的吻合程度”。所有粒子权重会归一化
(4) 重采样(Resampling)
重采样目的:随着时间推移,少数高权重粒子会占据主导,其他粒子权重趋近于0,导致粒子多样性丧失,这可能会导致所有粒子收敛到同一错误位姿,SLAM彻底失效。
重采样作用:通过复制高权重粒子、淘汰低权重粒子,重新分配资源给更可能的位姿假设。重采样本质是按权重概率随机选择粒子并进行复制,高权重粒子被选中的概率更高,可能被多次复制;低权重粒子可能被淘汰。
Gmapping采用自适应重采样,这是因为使用固定频率重采样可能导致过早收敛(如粒子全部集中在错误位姿)。自适应重采样在仅当有效粒子数(Effective Sample Size, Neff)低于阈值时触发。注意在Gmapping的重采样过程中,粒子数量(N)始终不变,所谓的“粒子减少”是指有效粒子数(NeffNeff)的下降,而非物理上的粒子数量减少。
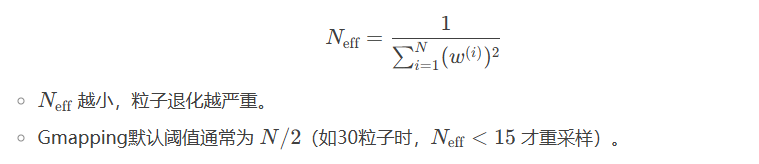
假设有4个粒子,权重分别为 [0.7, 0.2, 0.05, 0.05],有四个粒子,但是计算Neff,即计算有效粒子数如下,这意味着只有约2个粒子对结果有实质贡献(其他粒子权重可忽略)
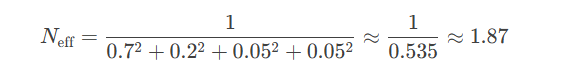
当少数粒子权重远高于其他粒子时(例如某个粒子权重接近1),Neff会趋近于1。这种现象称为粒子退化(Particle Deprivation),表明系统过度依赖少数粒子,可能丢失真实位姿。
重采样不是对高权重粒子的简单复制,而是会注入噪声 。Gmapping在复制高权重粒子后,会对其位姿添加微小高斯噪声(如位置噪声 ~N(0, 0.01m),角度噪声 ~N(0, 0.02rad)),形成新粒子。

假设粒子A权重高,位姿为 (5.0, 3.0, 0.1rad),复制时可能生成:
-
新粒子1:
(5.01, 2.99, 0.09rad) -
新粒子2:
(4.99, 3.02, 0.11rad)
(5) 地图更新
-
最终地图是由最高权重粒子(或最后一次重采样后的存活粒子)维护的地图直接输出。
-
地图更新是增量式的:每次激光数据插入到当前最优粒子的地图中(栅格占用概率更新)。
输入和输出数据
订阅的话题有/tf,即需要一些tf坐标变换关系,具体需要的是雷达坐标系到地盘坐标系base_link的TF和base_link到odom的TF。还需要订阅/scan话题

发布的话题一共有三个。第一个map_metadata是地图信息,第二个map是栅格地图数据,第三个~entropy是机器人定位的置信度,这个值越大表示机器人定位错误的可能性就越大。除此之外,Gmapping还会输出地图map到里程计odom的TF关系

参数
Gmapping的参数可大体分为三类,第一类是接口参数,主要就是三个TF坐标系的名称

第二类参数是性能参数,在计算资源有限的平台上使用一组适当的性能参数,可以让Gmapping在略微损失一些精度的情况下流畅运行。如下图,其主要分为四组类型:第一组是地图尺寸相关的参数,包含地图边界尺寸和栅格地图分辨率,地图尺寸越大占用内存也就越大,栅格地图分辨率也就是每个栅格的边长;第二组是激光雷达相关的参数,其中maxUrange指的是长度超过这个范围的射线的有效范围会被限制到以maxUrange为半径的圆形区域里,超出部分会被裁剪。maxRange指的是所有超过这个数值的射线会被直接抛弃,不参与建图运算。lskip跳线,如果一个激光雷达扫描一周为360条射线,lskip=1则每隔一个射线选取一次,即选择第1 3 5 7 9序号的射线。throttle_scans的用法和lskip相似,如果thorottle_scans=3,则对于连续的三帧数据只处理最后一帧,即每隔两帧处理一帧,如果thorottle_scans=1则会处理每一帧数据;第三组是地图更新相关的数据,但是需要注意map_update_interval的地图更新优先级最高,也就是说小车在5s内移动了2米也只会更新一次,linerUpdate和angularUpdate优先级相同;第四组是定位相关的参数

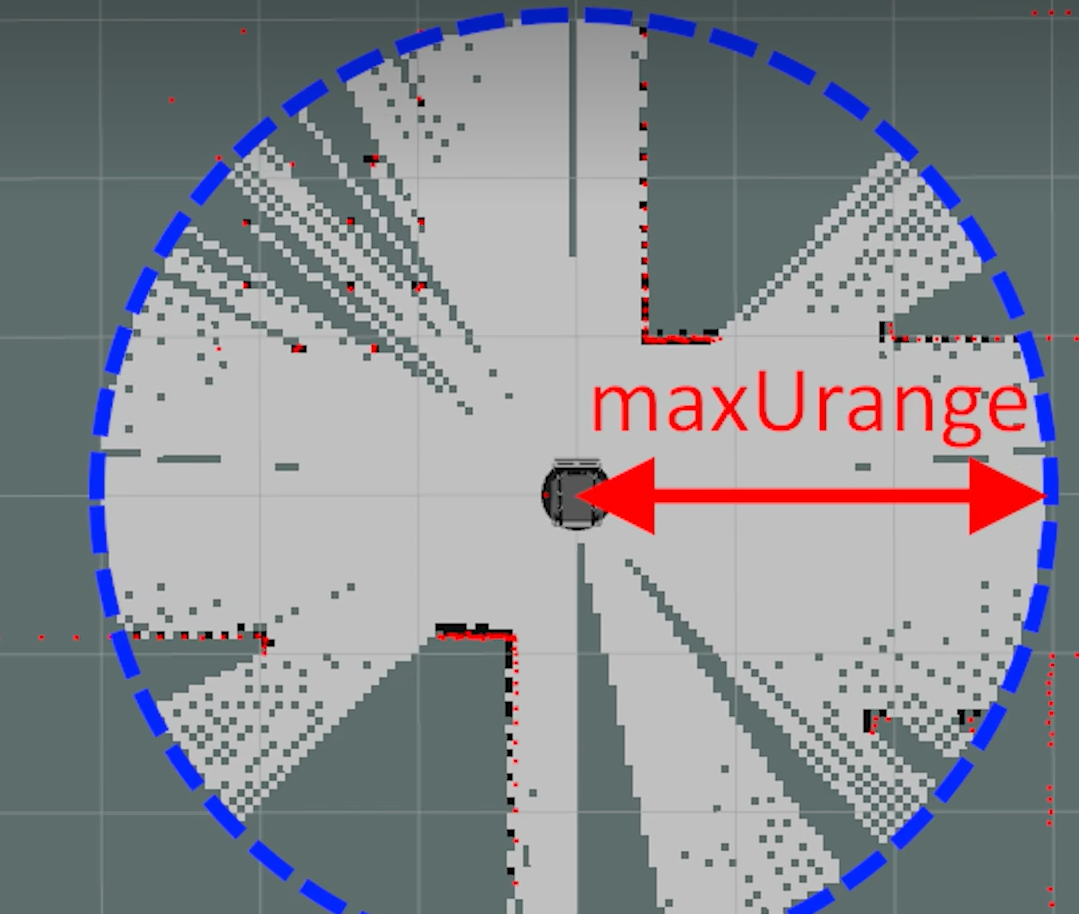
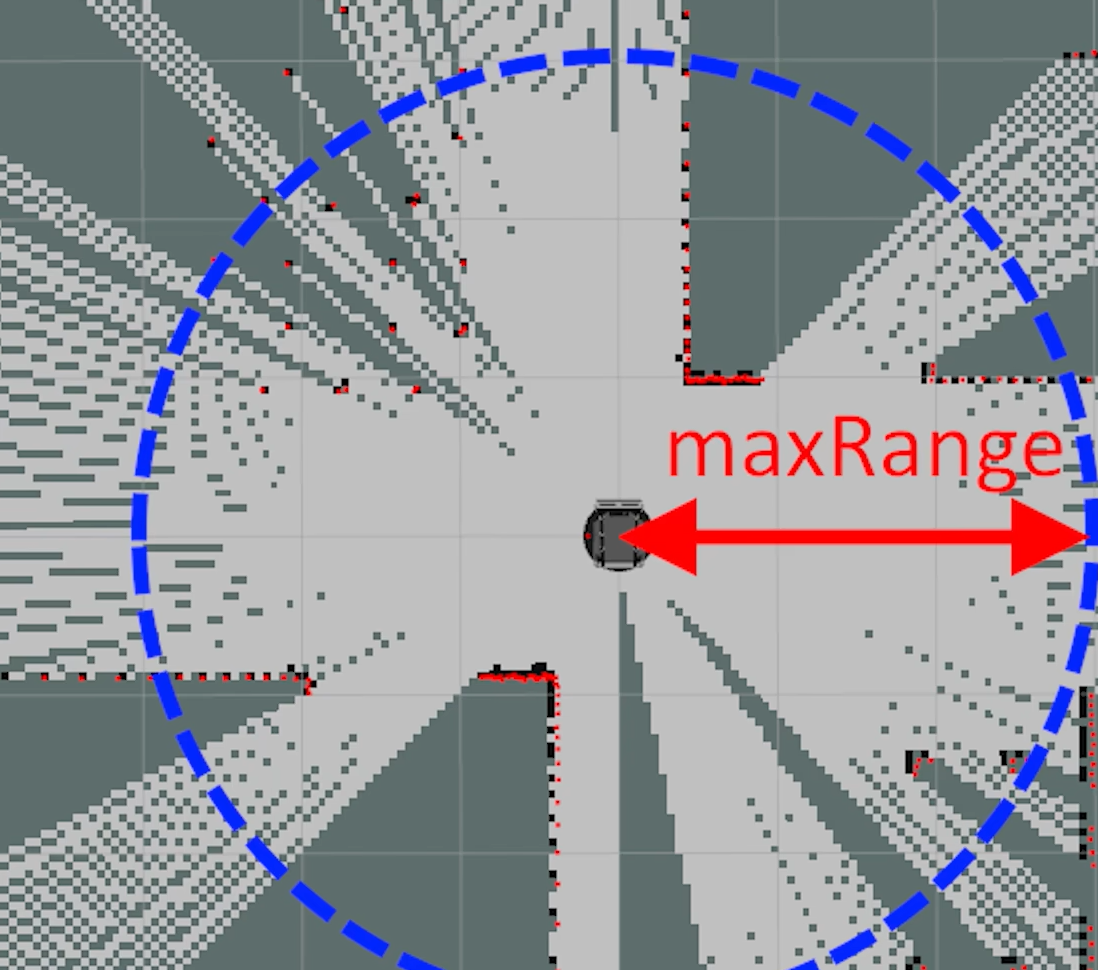

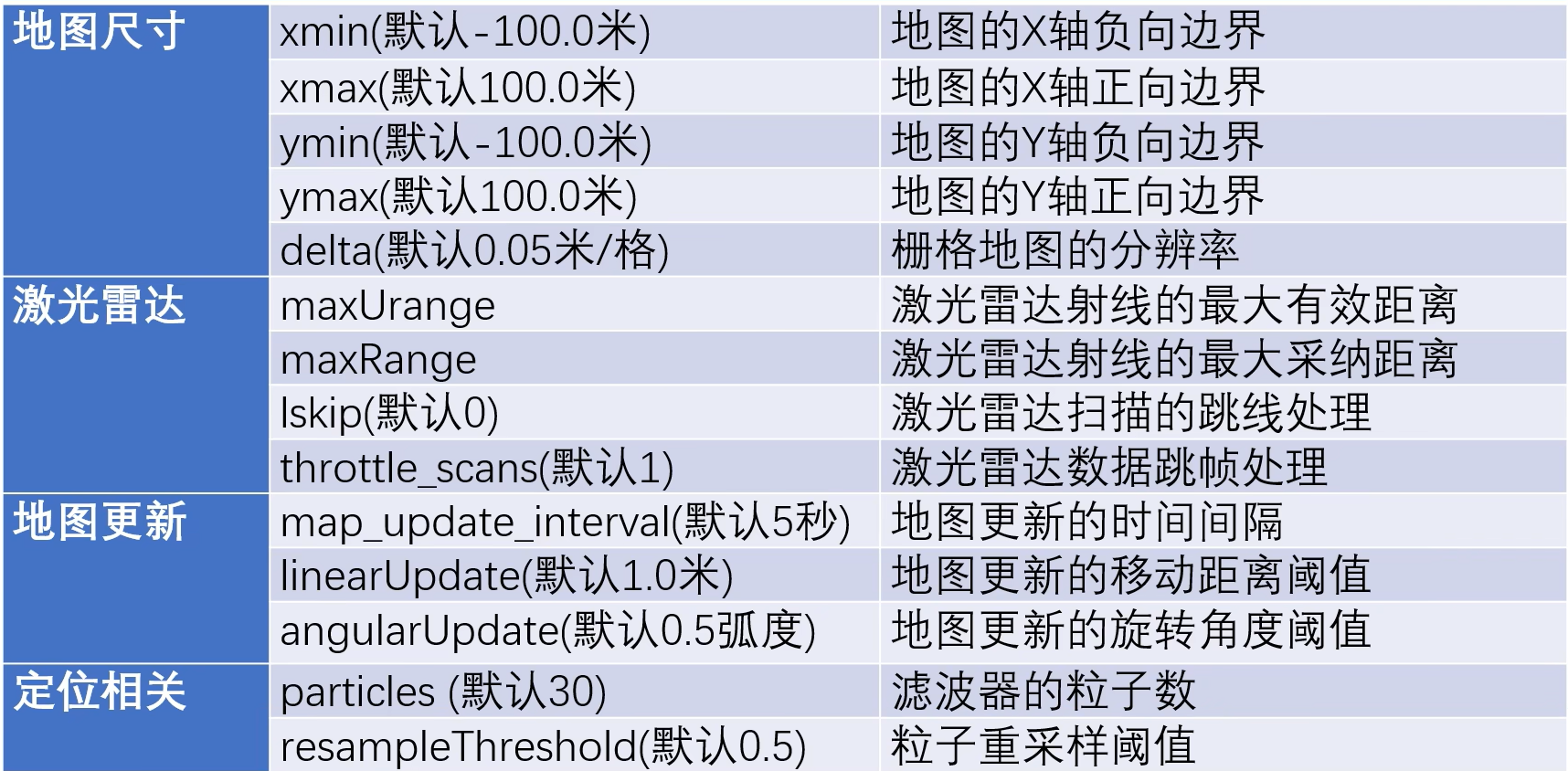
具体参数如下:
<launch><arg name="scan_topic" default="scan" /><!--建图参数调节--><!--最重要的几个参数介绍如下:包括srr,srt,str,stt,--><!--srr/srt/str/stt:描述 机器人运动模型噪声 的关键参数,用于建模里程计(Odometry)的误差分布--><!--srr:平移运动引起的平移噪声。当机器人直线移动一定距离dx时,实际位置与里程计报告的位移之间的误差标准差。设 srr=0.05,机器人命令移动 dx=1m,实际位移可能是 1 ± 0.05m(高斯分布)。--><!--srt:旋转运动引起的平移噪声。当机器人 旋转一定角度 dθ 时,对平移造成的额外误差标准差。设 srt=0.02,机器人旋转 dθ=1rad,可能导致平移误差 ±0.02m。--><!--str:平移运动引起的旋转噪声。当机器人 直线移动 dx 时,对朝向角度的附加误差标准差。设 str=0.01,移动 dx=1m 可能导致角度误差 ±0.01rad。--><!--stt:旋转运动引起的旋转噪声。当机器人 旋转 dθ 时,实际角度与里程计报告角度的误差标准差。设 stt=0.03,旋转 dθ=1rad,实际角度可能是 1 ± 0.03rad。--><!--gmapping 使用 粒子滤波(Particle Filter) 融合激光数据和里程计数据。每个粒子代表一个可能的机器人位姿假设,其运动根据里程计预测,并通过激光匹配修正。当 srr/srt/str/stt 较小时,gmapping 过度信任里程计,若里程计本身有偏差(如持续向左漂移),粒子会继承这一偏差,导致地图偏移。当噪声参数较大时,gmapping 会 放宽对里程计的信任,更多依赖激光匹配纠正位姿,从而抑制漂移。--><!--如果机器人平移时地图偏转增大 str。如果机器人旋转时地图偏转,增大 stt。平常遇到的主要是旋转噪声导致的地图偏转所以一般调这两个参数--><!--linearUpdate:linearUpdate 是 gmapping 中控制 地图更新条件 的关键参数,它决定了机器人 在直线运动过程中,每隔多少距离才触发一次地图更新(即激光数据与地图的匹配和优化)当机器人从上次地图更新位置开始,直线移动的距离超过 linearUpdate 值时,gmapping 会执行一次新的扫描匹配(Scan Matching)和地图更新。如果机器人移动距离未达到该值,则 暂不更新地图,仅依赖里程计预测位姿。linearUpdate较小则地图更新频率高,激光匹配修正更频繁,能 更快纠正里程计漂移。linearUpdate 较大则激光匹配机会减少,过度依赖里程计--><!--angularUpdate:控制机器人旋转角度达到多少弧度时触发地图更新当机器人从上次地图更新后的 累计旋转角度 超过 angularUpdate 时,执行扫描匹配和地图更新。angularUpdate较小则更频繁的旋转修正,适合快速转向或里程计旋转误差大的场景angularUpdate较大则旋转漂移可能累积。--><!--temporalUpdate:强制按 固定时间间隔(秒)更新地图,优先级高于 linearUpdate 和 angularUpdate。默认值:-1.0(表示禁用,完全依赖运动阈值更新)。无论机器人是否移动,每隔 temporalUpdate 秒必更新一次地图。--><!--sigma:激光扫描匹配的似然场方差,表示激光测距的置信度。控制激光点与地图匹配时的容忍度,即允许激光点与地图障碍物的最大偏差。越小 → 匹配越严格;越大 → 匹配越宽松。通俗易懂的来说,当你蒙着眼睛用手摸墙找门,sigma=0.02表示你的手指必须几乎贴到墙才能确认位置(稍有偏差就认为“不匹配”)。sigma=0.1即使手指离墙有10厘米,你也认为“差不多是这里”。对于建图来说,更小的sigma让地图细节更清晰(适合高精度激光雷达),但是抗干扰弱,如果机器人轻微晃动或有人走过,地图容易错乱。而较大的sigma,抗干扰强,人在旁边走动也不影响地图,但是地图上的墙会变“厚”,精度下降。--><!--ogain:地图的 增益因子,控制激光数据融入地图的强度。决定激光雷达观测到障碍物时,地图栅格概率的更新速度.越大 → 地图更新越快,障碍物越清晰;越小 → 地图更新越保守。通俗易懂的来说,当你用粉笔画地图,ogain=5.0看到障碍物就画一笔浓墨重彩,立刻标到地图上。地图快速成型,但如果有人路过,会留下“鬼影”。ogain=1.0看到障碍物先轻轻画一笔,反复确认后再加深。地图更新慢,但动态物体(如人)不会留痕迹。--><!--lstep:平移搜索步长(单位:米),表示在 优化机器人位置(x, y) 时,每次尝试调整的最小距离。扫描匹配过程中,算法会尝试不同的平移位置(x, y),寻找最优匹配。lstep 决定了 每次调整位置的步长,步长越小,搜索越精细,但计算量越大。扫描匹配流程:机器人获取一帧激光数据,并尝试与现有地图匹配。算法在当前位置附近 微调机器人的 x 和 y 坐标,计算匹配得分(激光点与地图的吻合程度)。例如,lstep=0.05 表示每次尝试移动 ±0.05m,看看匹配是否更好。lstep较小则位姿优化更精细,能更准确找到最佳匹配位置。lstep较大可能错过最优匹配点,导致位姿误差累积。--><!--astep:旋转搜索步长(单位:弧度),表示在 优化机器人朝向(θ) 时,每次尝试调整的最小角度astep较小则角度优化更精细,能更准确找到最佳朝向。astep较大则 可能错过最优角度,导致旋转漂移。--><node pkg="gmapping" type="slam_gmapping" name="slam_gmapping" output="screen" clear_params="true"><param name="odom_frame" value="odom"/><param name="mapp_update_interval" value="3.0"/><!-- Set maxUrange < actual maximum range of the Laser --><param name="maxRange" value="4.2"/><param name="maxUrange" value="4.0"/><param name="sigma" value="0.05"/><param name="kernelSize" value="1"/><param name="minimumScore" value="400"/><param name="lstep" value="0.05"/><param name="astep" value="0.05"/><param name="iterations" value="5"/><param name="lsigma" value="0.075"/><param name="ogain" value="3.0"/><param name="lskip" value="0"/><param name="srr" value="0.01"/><param name="srt" value="0.02"/><param name="str" value="0.01"/><param name="stt" value="0.02"/><param name="linearUpdate" value="0.1"/><param name="angularUpdate" value="0.1"/><param name="temporalUpdate" value="-1.0"/><param name="resampleThreshold" value="0.5"/><param name="particles" value="30"/><param name="xmin" value="-1.0"/><param name="ymin" value="-1.0"/><param name="xmax" value="1.0"/><param name="ymax" value="1.0"/><param name="delta" value="0.01"/><param name="llsamplerange" value="0.01"/><param name="llsamplestep" value="0.01"/><param name="lasamplerange" value="0.005"/><param name="lasamplestep" value="0.005"/><remap from="scan" to="$(arg scan_topic)"/></node>
</launch>