【AI论文】用于评估和改进大型语言模型中指令跟踪的多维约束框架
摘要:接下来的指令评估了大型语言模型(LLMs)生成符合用户定义约束的输出的能力。 然而,现有的基准测试通常依赖于模板化的约束提示,缺乏现实使用的多样性,并限制了细粒度的性能评估。 为了填补这一空白,我们提出了一个多维约束框架,包括三种约束模式、四种约束类别和四种难度级别。 基于这个框架,我们开发了一个自动指令生成管道,用于执行约束扩展、冲突检测和指令重写,生成1200个可验证代码的指令跟踪测试样本。 我们评估了七个模型家族中的19个LLM,并发现了约束形式在性能上的显著差异。 例如,平均性能从一级的77.67%下降到四级32.96%。此外,我们通过使用我们的方法生成强化学习数据来证明其效用,在不降低总体性能的情况下,在指导后续学习方面取得了实质性进展。 深入分析表明,这些收益主要来自模型注意力模块参数的修改,这些参数增强了约束识别和遵守。 代码和数据可以在github。Huggingface链接:Paper page,论文链接:2505.07591
研究背景和目的
研究背景
随着人工智能技术的飞速发展,大型语言模型(LLMs)在自然语言处理领域取得了显著进展,被广泛应用于对话系统、文本生成、机器翻译等多个任务中。然而,尽管这些模型在许多基准测试中表现出色,但在遵循用户定义的复杂指令方面仍存在显著不足。指令跟随能力是衡量LLMs实用性的关键指标之一,它要求模型能够准确理解并执行用户给出的具体指令,尤其是在涉及多个约束条件、复杂逻辑或特定格式要求时。
现有的指令跟随评估基准主要依赖于模板化的约束提示,这些提示往往缺乏现实世界中指令的多样性和复杂性。这种局限性导致评估结果难以准确反映模型在实际应用中的表现,也限制了细粒度性能评估的可能性。此外,尽管已有一些研究致力于改进LLMs的指令跟随能力,但这些方法往往缺乏系统性的框架来全面评估和提升模型的这一能力。
研究目的
本研究旨在填补现有研究的空白,通过提出一个多维约束框架来系统评估和提升大型语言模型的指令跟随能力。具体目标包括:
- 构建多维约束框架:设计一个包含多种约束模式、类别和难度级别的框架,以全面覆盖现实世界中用户指令的多样性。
- 开发自动化指令生成管道:基于多维约束框架,开发一个能够自动生成多样化指令样本的管道,包括约束扩展、冲突检测和指令重写等步骤。
- 评估和提升LLMs的指令跟随能力:使用生成的指令样本评估多个LLMs的性能,并通过强化学习等方法提升模型的指令跟随能力。
- 深入分析性能提升的原因:通过参数级分析,探究模型性能提升的具体原因,特别是注意力模块参数的变化对指令跟随能力的影响。
研究方法
多维约束框架设计
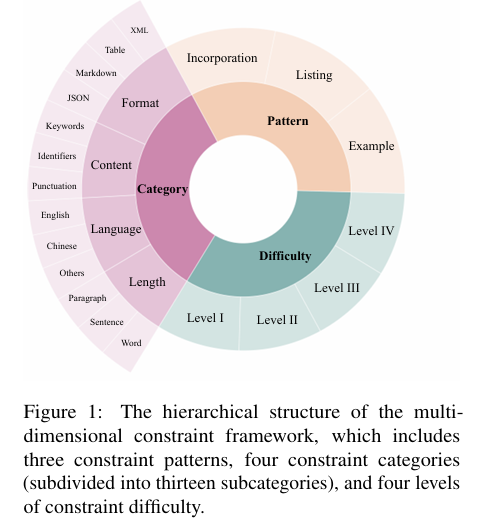
本研究提出的多维约束框架包括三个主要组成部分:
- 约束模式:识别并定义了三种常见的约束引入模式,即示例模式、列表模式和融合模式。示例模式通过提供几个具有相同约束类型的问题-答案对来增强模型的约束遵循能力;列表模式以清晰的结构化格式呈现约束;融合模式则将约束直接融入指令中。
- 约束类别:将约束分为内容、格式、语言和长度四个主要类别,并进一步细分为13个子类别。内容约束限制输出中必须包含的元素;格式约束要求输出遵循特定结构;语言约束指定输出中使用的语言;长度约束则对输出的大小进行限制。
- 约束难度级别:根据指令中包含的约束数量和种类定义了四个难度级别。级别I包含单一类型的约束;级别II包含两种类型的约束;级别III包含三种类型的约束;级别IV则包含四种类型的约束。
自动化指令生成管道
基于多维约束框架,本研究开发了一个自动化指令生成管道,包括以下步骤:
- 约束扩展:随机选择一个尚未覆盖的约束类别,并添加一个或两个来自该类别的具体约束。
- 冲突检测:检查新生成的指令是否包含冗余约束或冲突,并丢弃冲突的指令。
- 指令重写:根据不同的约束模式重写指令,以确保指令的多样性和复杂性。
通过这一管道,本研究生成了1200个可验证代码的指令跟随测试样本。
模型评估与提升
本研究评估了七个模型家族中的19个LLMs,包括LLaMA3.1、Qwen2.5、DeepSeek-R1-Distill-LLaMA、DeepSeek-R1-Distill-Qwen以及Gemini1.5、Claude3.5和GPT家族的部分模型。评估过程中,使用了生成的指令样本以及现有的基准测试集(如IFEval、Multi-IF等)。
为了提升模型的指令跟随能力,本研究采用了强化学习算法(GRPO)对模型进行训练。训练过程中,使用生成的约束指令样本作为训练数据,并通过奖励函数来优化模型输出以满足约束要求。
参数级分析
为了深入理解模型性能提升的原因,本研究进行了参数级分析。具体来说,计算了强化学习前后模型参数的变化率,并重点关注了注意力模块参数的变化。通过可视化输入令牌的重要性,分析了模型在处理约束相关信息时的注意力分布变化。
研究结果
模型性能评估
评估结果显示,不同LLMs在遵循不同形式约束的能力上存在显著差异。大多数模型在示例模式下表现最佳,而在融合模式下表现最差。此外,随着约束难度级别的增加,模型的平均性能显著下降。例如,从级别I的77.67%下降到级别IV的32.96%。
强化学习效果
通过强化学习训练,模型的指令跟随能力得到了显著提升。在自定义测试集上,经过GRPO训练的模型在多个维度上的性能均有所提高。特别是在多轮对话场景中,尽管训练仅在单轮数据上进行,但模型仍展现出了强大的泛化能力。此外,强化学习并未降低模型的一般性能,在某些基准测试集上甚至表现出改进。
参数级分析结果
参数级分析表明,模型性能的提升主要来源于注意力模块参数的变化。这些变化使得模型在处理输入时更加关注与约束相关的信息,从而提高了约束识别和遵循的能力。具体来说,经过GRPO训练的模型在处理约束相关令牌时的注意力权重显著增加,而对无关令牌的注意力则相应减少。
研究局限
尽管本研究在评估和提升大型语言模型的指令跟随能力方面取得了显著进展,但仍存在一些局限性:
- 训练方式限制:由于答案构造的复杂性,本研究未从预训练版本开始训练模型,而是直接对指令调优模型应用了GRPO算法。尽管结果显示GRPO训练的模型未丧失一般能力,甚至在某些情况下表现出改进,但这一限制仍可能影响结果的普遍性。
- 领域特定数据探索不足:本研究主要关注于提升模型的指令跟随能力,而未探索将该方法应用于领域特定数据集的效果。尽管案例研究证实了模型在核心问题组件上的注意力保持不变,但领域特定数据的应用仍需进一步验证。
- 约束冲突解决机制有限:尽管本研究在指令生成过程中包含了冲突检测步骤,但对于更复杂的约束冲突解决机制(如使用大型语言模型进行冲突调解)的探索仍显不足。
未来研究方向
针对本研究的局限性和当前研究的不足,未来研究可以从以下几个方面展开:
- 探索更高效的训练方式:研究如何从预训练版本开始训练模型,以进一步提升模型的指令跟随能力和一般性能。同时,探索结合无监督学习和强化学习的方法,以减少对标注数据的依赖。
- 拓展领域特定应用:将本研究提出的多维约束框架和自动化指令生成管道应用于领域特定数据集,评估模型在医疗、法律、金融等领域的指令跟随能力。通过领域适应技术,提升模型在特定领域内的实用性和准确性。
- 完善约束冲突解决机制:研究更复杂的约束冲突解决机制,如使用大型语言模型作为冲突调解器,自动识别和解决指令中的约束冲突。同时,开发用户友好的界面,允许用户直观地指定和调整约束条件。
- 增强模型的可解释性和可信度:通过可视化技术和可解释AI方法,增强模型在处理复杂指令时的可解释性。同时,建立模型性能评估的标准化流程和指标体系,提升模型的可信度和可靠性。
- 探索多模态指令跟随:随着多模态大语言模型的发展,未来研究可以探索如何使模型在遵循文本指令的同时,也能理解和遵循图像、音频等多模态输入中的约束条件。这将为智能助手、自动驾驶等领域带来更广泛的应用前景。