window 显示驱动开发-命令和 DMA 缓冲区简介
命令和 DMA 缓冲区非常相似。 但是,命令缓冲区由用户模式显示驱动程序使用,DMA 缓冲区由显示微型端口驱动程序使用。
命令缓冲区具有以下特征:
-
它永远不会由 GPU 直接访问。
-
硬件供应商控制格式。
-
它从呈现应用程序的专用地址空间中的常规可分页内存中为用户模式显示驱动程序分配。
DMA 缓冲区具有以下特征:
-
它基于命令缓冲区的已验证内容。
-
它由显示微型端口驱动程序从内核可分页内存中分配。
-
在 GPU 可以从 DMA 缓冲区读取数据之前,显示微型端口驱动程序必须对 DMA 缓冲区进行分页锁定,并通过光圈映射 DMA 缓冲区。
命令缓冲区 vs DMA 缓冲区的对比
| 特性 | 命令缓冲区 (Command Buffer) | DMA缓冲区 (DMA Buffer) |
|---|---|---|
| 使用者 | 用户模式显示驱动程序(UMD) | 显示微型端口驱动程序(KMD) |
| 内存位置 | 用户空间的可分页内存 | 内核空间的可分页内存 |
| GPU访问方式 | 不直接访问,需转换为DMA缓冲区 | 通过光圈映射后GPU直接读取 |
| 内存管理 | 由UMD分配和管理 | 由视频内存管理器(VidMm)分配,KMD转换 |
| 验证要求 | 无硬件验证 | 必须通过KMD验证 |
| 生命周期 | 短暂存在,提交后即可释放 | 需保持到GPU执行完成 |
详细工作流程
命令生成阶段
// 用户模式驱动(UMD)生成命令
void UmdGenerateCommands() {BYTE* cmdBuffer = AllocUserPagedMemory(); // 分配用户空间可分页内存// 填充硬件特定命令格式WriteDrawCommand(cmdBuffer, ...);WriteTextureBind(cmdBuffer, ...);pfnSubmitCommand(cmdBuffer); // 提交到运行时
}验证与转换阶段
// 内核模式驱动(KMD)处理
NTSTATUS KmdProcessCommands(BYTE* userCmdBuffer) {// 1. 验证命令安全性if (!ValidateCommands(userCmdBuffer)) return STATUS_ACCESS_VIOLATION;// 2. 分配DMA缓冲区DMA_BUFFER* dmaBuffer = VidMmAllocateDmaBuffer(); // 3. 转换并复制命令TranslateToHardwareFormat(userCmdBuffer, dmaBuffer);// 4. 锁定内存并映射光圈MmPageLockBuffer(dmaBuffer);MapToAperture(dmaBuffer);// 5. 提交到GPU队列DxgkDdiSubmitCommand(dmaBuffer);
}GPU执行阶段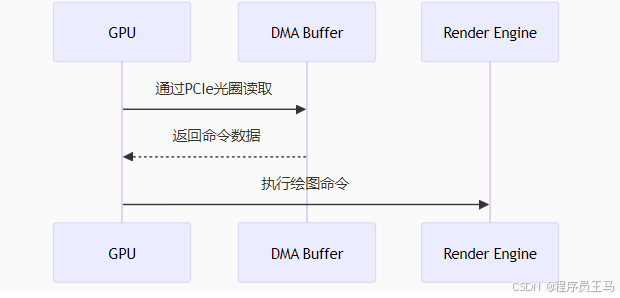
关键设计考量
- 安全隔离机制
- 用户模式命令缓冲区无法直接访问硬件,必须通过内核验证
- DMA缓冲区地址对用户模式不可见,防止恶意修改
- 性能优化
- 命令批处理:UMD可累积多个命令后一次性提交
- 内存复用:DMA缓冲区常采用环形缓冲区(Ring Buffer)设计
- 异步提交:KMD使用DMA引擎并行处理多个缓冲区
- 错误处理
// 典型错误检测点 void ValidateCommands(BYTE* cmdBuffer) {if (cmdBuffer->textureHandle == INVALID_HANDLE)ThrowException("无效纹理句柄");if (cmdBuffer->shaderCodeSize > MAX_SHADER_SIZE)ThrowException("着色器代码过大"); }多引擎支持;现代GPU可能有多个DMA队列:
- 3D渲染队列
- 计算队列
- 拷贝引擎队列
每个队列需要独立的DMA缓冲区管理
实际开发注意事项
用户模式驱动开发
// 良好实践示例
struct CommandHeader {DWORD engineType; // 指定GPU引擎类型DWORD size; // 命令总大小DWORD fenceId; // 用于同步的标识
};void SubmitRenderCommands() {CommandHeader* header = (CommandHeader*)AllocCommandBuffer();header->engineType = ENGINE_3D;header->fenceId = GenerateFenceId();// 填充具体命令...EmitDrawPrimitive(header+1, ...);// 提交时包含元数据pfnSubmitCommandEx(header, sizeof(CommandHeader)+payloadSize);
}内核模式驱动开发
// DMA缓冲区处理示例
void HandleDmaBuffer(DMA_BUFFER* buffer) {// 确保内存有效if (!MmIsBufferValid(buffer)) {DbgPrint("无效DMA缓冲区地址");return STATUS_INVALID_PARAMETER;}// 硬件特定处理if (IsAmdGpu()) {ApplyAmdWorkaround(buffer);}// 添加至执行队列InsertToRingBuffer(g_CommandRing, buffer);
}调试技巧
捕获命令缓冲区
# 使用PIX工具捕获
pixcap -start -cmd -out trace.wpix检查DMA状态
# WinDbg扩展命令
!dxgkd_ext.dmabuffer 0xFFFFFA8001234560性能分析标记
// 在命令中插入调试标记
#define DBG_MARKER 0xDEADBEEF
*(DWORD*)(cmdPtr+offset) = DBG_MARKER;演进趋势
- GPU虚拟内存:现代GPU支持虚拟地址空间,DMA缓冲区可直接引用GPU虚拟地址而非物理地址
- 直接提交优化:Windows 11引入DirectSubmission模式,允许特定条件下绕过部分验证
- 跨进程共享:DX12支持跨进程命令缓冲区共享,但需额外安全审查
理解这些底层机制对于开发高性能图形应用、调试复杂渲染问题以及优化驱动程序性能都至关重要。实际开发中应结合WDK文档和硬件厂商的特定指南进行实现。