2025年,多模态特征融合只会更火
推荐一个高潜力、高回报的研究方向:多模态特征融合。从近期各大顶会的论文占比上就可以看出,这方向仍然是今年的发文热点,尤其在医学、自动驾驶等垂直领域。
现在顶会对解决实际问题的创新方法接受度较高,而多模态特征融合能够提升模型的性能、鲁棒性和应用范围,又得益于其通用性,在教育、娱乐、人机交互等多样化场景中都十分适用。
因此这方向无论是创新性,还是发展前景都非常可观,论文er可冲。同时也建议各位结合Mamba等新兴模型与具体应用场景做创新。我这边整理了10篇多模态特征融合2025新论文(有代码),可用作参考,需要的同学自取。
全部论文+开源代码需要的同学看文末
ECHOVIDEO: IDENTITY-PRESERVING HUMAN VIDEO GENERATION BY MULTIMODAL FEATURE FUSION
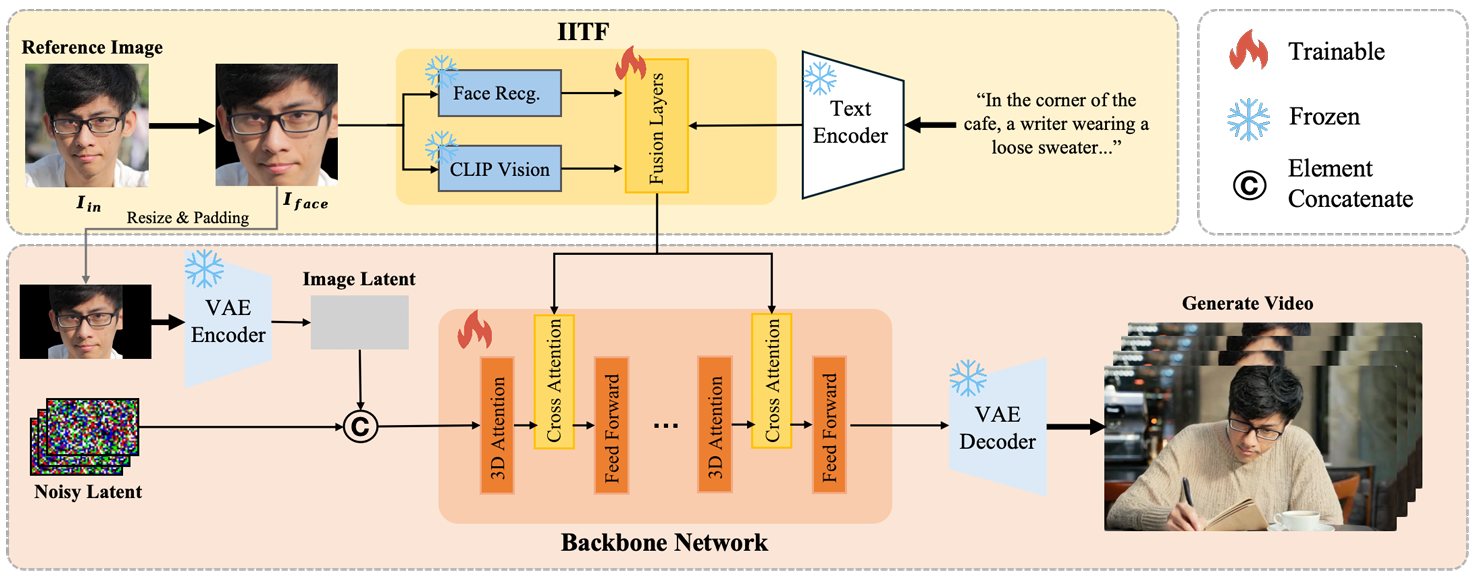
方法:EchoVideo是一种身份保持型视频生成模型,通过多模态特征融合解决了现有方法中的“复制粘贴”和低相似性问题。它利用身份图像-文本融合模块整合文本和图像的高级语义特征,提取干净的身份信息,并通过两阶段训练策略平衡浅层和高层特征的使用,从而生成高质量且身份一致的视频。
创新点:
-
提出身份图像-文本融合模块,整合文本和图像的高级语义特征,提取干净的身份信息,避免无关细节干扰。
-
采用两阶段训练策略,第二阶段随机利用浅层面部信息,平衡浅层和高层特征的使用,提升模型鲁棒性。
-
实现面部身份与全身特征的一致性保持,生成高质量、可控且逼真的视频。

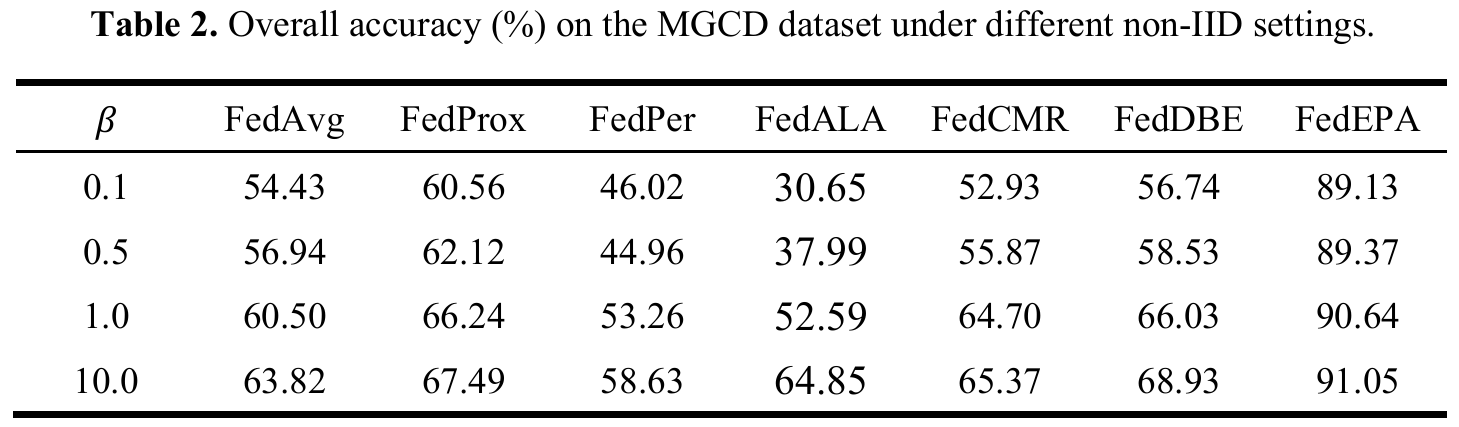
FedEPA: Enhancing Personalization and Modality Alignment in Multimodal Federated Learning
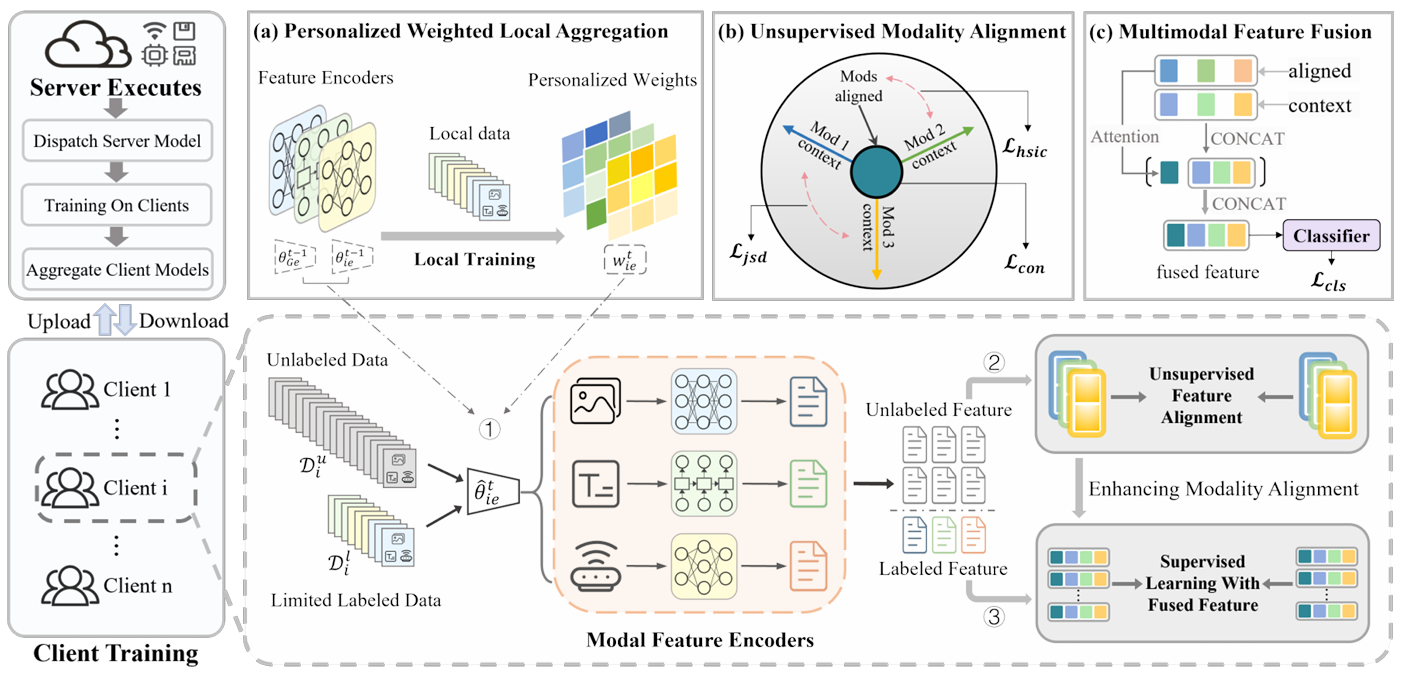
方法:论文提出FedEPA,一种多模态联邦学习框架。其核心是:通过个性化加权策略减轻数据异质性;用无监督方法对齐多模态特征,确保独立性和多样性;最后融合多模态特征,提升分类性能。
创新点:
-
提个性化加权聚合策略,用客户端标记数据算权重,优化全局模型参数聚合,适配数据异质性。
-
设无监督模态对齐策略,分解多模态特征为对齐与上下文特征,对比学习对齐特征、分离上下文特征,提升特征表示。
-
引多模态特征融合策略,借自注意力机制动态整合两类特征,增强多模态分类任务性能。
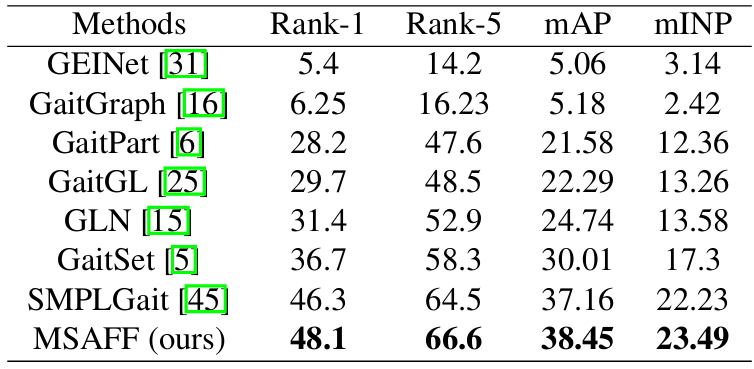
A Multi-Stage Adaptive Feature Fusion Neural Network for Multimodal Gait Recognition
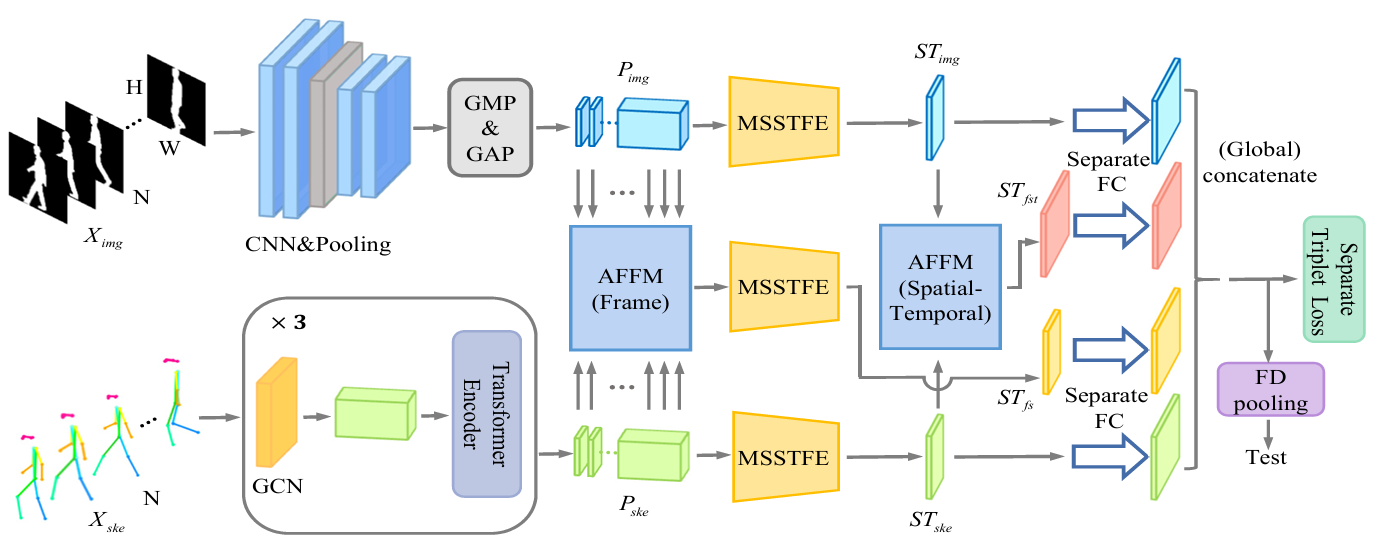
方法:论文提出了一种多模态步态识别方法,通过多阶段特征融合策略和自适应特征融合模块,在不同阶段对轮廓和骨架数据进行多次融合,并利用多尺度时空特征提取器提取时空关联特征,从而充分利用多模态数据的互补优势,提升步态识别性能。
创新点:
-
提出多阶段特征融合策略,在特征提取的不同阶段多次融合多模态数据。
-
设计自适应特征融合模块,捕捉轮廓与骨架的语义关联,增强特征融合效果。
-
提出多尺度时空特征提取器,同时提取不同空间尺度上的时空关联特征。
Efficient Multimodal Semantic Segmentation via Dual-Prompt Learning
方法:论文提出了一种名为DPLNet的多模态语义分割方法,通过多模态提示生成器和多模态特征适配器两个模块,将预训练的RGB模型高效地适应到多模态任务中,实现了高效的特征融合和语义分割性能。
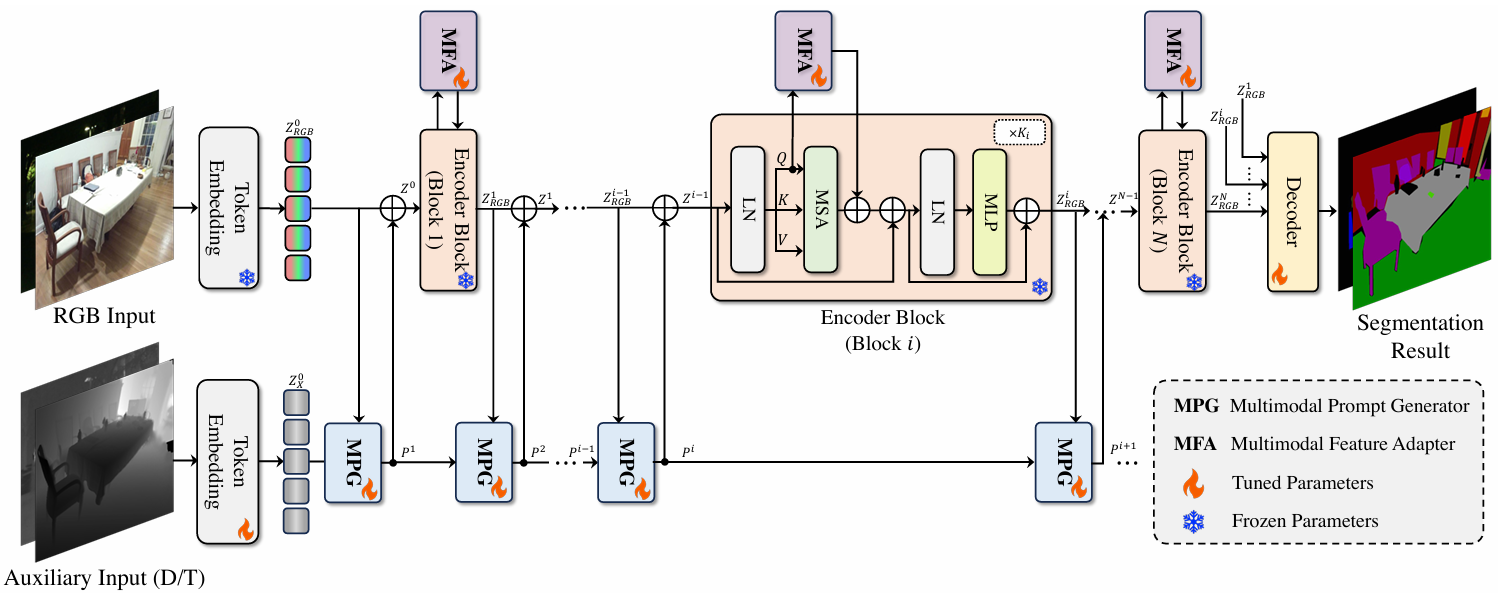
创新点:
-
提出了一种双提示学习网络DPLNet,通过少量可训练参数实现高效的多模态语义分割。
-
设计了多模态提示生成器,以紧凑的方式融合不同模态的特征,生成多级提示注入冻结的主干网络。
-
引入多模态特征适配器,通过少量可学习的提示令牌适应特定任务,提升多模态特征提取性能。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“222”获取全部方案+开源代码
码字不易,欢迎大家点赞评论收藏