Python爬虫第21节- 基础图形验证码识别实战
目录
前言
一、学习目标
二、环境准备
2.1 安装依赖
2.2 验证安装
三、获取验证码图片
3.1 常见获取方式
3.2 图片格式要求
四、基础识别流程
4.1 基础流程
4.2 常见问题及解决方案
五、 图像预处理提升识别率
5.1 灰度化
5.2 二值化
5.3 自定义阈值二值化
5.4 其他预处理技巧
六、综合识别流程示例
6.1 识别流程示例
6.2 进一步优化代码示例
七、小结与建议
八、常见问题解答
8.1 如何提高识别率?
8.2 遇到复杂验证码怎么办?
8.3 如何集成到爬虫项目?
九、结语

🎬 攻城狮7号:个人主页
🔥 个人专栏: 《python爬虫教程》
⛺️ 君子慎独!
🌈 大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 图形验证码 的识别
📚 本期文章收录在《python爬虫教程》,大家有兴趣可以自行查看!
⛺️ 欢迎各位 ✔️ 点赞 👍 收藏 ⭐留言 📝!
前言
在互联网安全防护中,验证码是一道常见的"门槛",它们被广泛用于防止恶意爬虫和自动化攻击。随着技术进步,验证码的形式也日益多样化,从最初的简单数字字母组合,到如今的滑动拼图、点选图片、复杂干扰线等多种类型。对于数据采集和自动化测试来说,如何高效识别验证码成为了一个重要课题。
本节将聚焦于最基础、最常见的"图形验证码",即由数字或字母组成的图片验证码。我们将介绍其识别原理、常用工具、图像预处理技巧,并通过代码实例带你一步步实现自动识别。
一、学习目标
- 理解图形验证码的基本原理和常见类型
- 掌握 OCR(光学字符识别)工具 Tesseract 的基本用法
- 学会通过opencv等图像预处理手段提升验证码识别准确率
- 了解常见问题及解决方案
二、环境准备
识别验证码通常需要用到 OCR 技术。这里我们推荐使用 `pytesseract`,它是 Tesseract OCR 引擎的 Python 封装,配合 `Pillow` 进行图片处理。
2.1 安装依赖
在Python环境下,若想运用Tesseract实现光学字符识别功能,具体的安装方法涵盖了安装Tesseract OCR软件、引入Python库pytesseract以及配置环境变量等方面。
首先,Tesseract OCR软件是整个流程的基础,作为一款由Google维护的强大开源光学字符识别引擎,需要从其官方渠道获取与操作系统适配的版本并完成安装。具体而言:
(1)下载并安装Tesseract:
- 对于Windows用户,访问Tesseract OCR的GitHub页面( https://github.com/tesseract-ocr/tesseract )或windows安装包地址( https://github.com/UB-Mannheim/tesseract/wiki ),下载对应的可执行安装文件,按照安装提示逐步操作。
- macOS系统用户,借助Homebrew工具,在命令行中输入“brew install tesseract”即可完成安装。
- Linux用户则依据自身的发行版本,使用相应的包管理器,如通过“sudo apt-get install tesseract-ocr”命令来安装Tesseract OCR软件。
(2)确认安装:安装结束后,在命令行输入“tesseract -v”,若能显示版本相关信息,就表明Tesseract OCR软件安装成功。
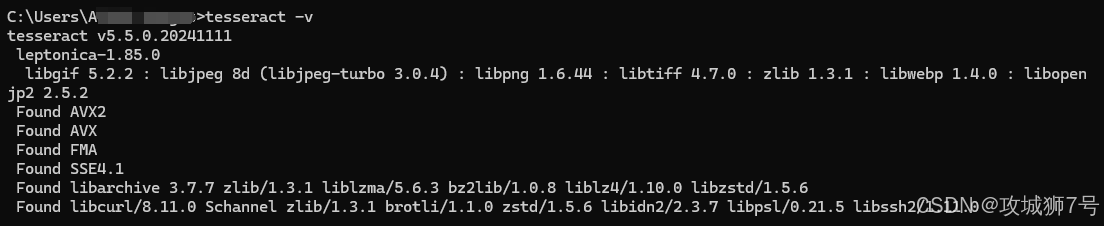
其次,pytesseract作为Python的一个库,提供了与Tesseract OCR引擎交互的便捷接口,能让Python调用Tesseract的功能更为顺畅。其安装与验证步骤如下:
(1)安装pytesseract:打开命令行,执行“pip install pytesseract”命令,即可完成该库的安装。
(2)验证安装:在Python环境里,尝试执行“import pytesseract”语句,若未弹出错误提示,则意味着pytesseract库安装无误。
最后,为确保pytesseract能够准确找到Tesseract可执行文件,环境变量的设置至关重要:
(1)Windows:先确定Tesseract的安装路径,如“C:\Program Files\Tesseract-OCR”,接着右键点击“此电脑”,选择“属性”,进入“高级系统设置”,点击“环境变量”,在“系统变量”中找到“Path”变量进行编辑,将Tesseract的安装路径添加到其中。
(2)macOS和Linux:一般情况下,包管理器会自动配置路径,无需手动设置。但特殊情况下,可通过修改“~/.bash_profile”或“~/.bashrc”文件来手动添加Tesseract的路径。
2.2 验证安装
安装完成后,可通过以下代码验证环境是否正常:
import pytesseract
print(pytesseract.get_tesseract_version())输出:
5.5.0.20241111
如果输出版本号,说明安装成功。
三、获取验证码图片
在实际项目中,验证码图片通常可以通过接口或页面下载。为了便于演示,我们假设已经将验证码图片保存为 `code.jpg`。
3.1 常见获取方式
- 接口下载:通过 API 获取验证码图片
- 页面抓取:使用 Selenium 或 Requests 从网页中提取验证码图片
- 手动保存:在测试阶段,可手动保存验证码图片
3.2 图片格式要求
- 支持常见格式:JPG、PNG、BMP 等
- 建议使用 PNG 格式,避免压缩损失
四、基础识别流程
4.1 基础流程
![]()
直接用 pytesseract 识别图片验证码非常简单:
import pytesseract
from PIL import Imageimage = Image.open('code.jpg')
result = pytesseract.image_to_string(image)
print(result.strip())旧版python的 `tesserocr` 库可以支持直接读取图片文件,如:
import tesserocr
print(tesserocr.file_to_text('code.jpg'))但是我们使用的是 pytesseract 库。运行后即可输出识别结果:
JIR42.
准确率不高,或许tesserocr的正确率会高一点,我们继续往下探讨。
4.2 常见问题及解决方案
识别结果为空:检查图片是否清晰,尝试调整图片大小或对比度
识别错误:可能是图片干扰过多,需进行图像预处理
五、 图像预处理提升识别率
实际验证码往往会加入干扰线、噪点、颜色变化等,直接识别效果有限。此时可以通过图像预处理(如灰度化、二值化)来提升准确率。
5.1 灰度化
将彩色图片转为灰度,有助于去除颜色干扰:
image = image.convert('L') # 转为灰度图
image.show()5.2 二值化
将灰度图进一步转为黑白图像,突出字符主体:
image = image.convert('1') # 默认阈值127
image.show()5.3 自定义阈值二值化
有时需要手动调整阈值以获得更好效果:
image = image.convert('L')
threshold = 80 # 可根据实际图片调整
binary_table = [0 if i < threshold else 1 for i in range(256)]
image = image.point(binary_table, '1')
image.show()5.4 其他预处理技巧
降噪:使用中值滤波或高斯滤波去除噪点
锐化:增强字符边缘,提高识别率
旋转校正:处理倾斜的验证码
六、综合识别流程示例
6.1 识别流程示例
完整识别流程如下:
import pytesseract
from PIL import Imageimage = Image.open('code.jpg')
image = image.convert('L')
threshold = 127
binary_table = [0 if i < threshold else 1 for i in range(256)]
image = image.point(binary_table, '1')
result = pytesseract.image_to_string(image)
print(result)输出:
JSR42
经过预处理后,正确率还是差一点。
6.2 进一步优化代码示例
优化方案:
(1)使用 OpenCV 进行灰度、二值化和去噪预处理
(2)用 pytesseract 限定只识别字母和数字,并设置 --psm 8 提高验证码识别率
import cv2
import pytesseractdef preprocess_opencv(image_path, threshold=130):img = cv2.imread(image_path)gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)_, thresh = cv2.threshold(gray, threshold, 255, cv2.THRESH_BINARY)denoised = cv2.medianBlur(thresh, 3)return denoised# 使用示例
img = preprocess_opencv('code.jpg', threshold=130)
result = pytesseract.image_to_string(img,config='--psm 8 -c tessedit_char_whitelist=ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789'
)
print(result.strip())得到正确值:
JR42
继续以一张带有干扰线的验证码 `code2.jpg` 验证:
![]()
将代码中的 code.jpg 改成 code2.jpg,运行代码输出:
PFRT
到此准确率达到预期。
七、小结与建议
- 图形验证码识别的核心在于图像预处理,灰度化和二值化是最常用的手段。
- 阈值的选择对识别效果影响很大,可多尝试不同值。
- 对于更复杂的验证码(如扭曲、旋转、强干扰),可考虑进一步图像处理使用 opencv 或训练专用模型。
- tesserocr 或 pytesseract 适合简单验证码,遇到复杂场景可结合深度学习方法。
通过本节内容,你已经掌握了用 Python 自动识别基础图形验证码的完整流程。后续可以尝试识别更复杂的验证码类型,或将识别流程集成到自动化测试、爬虫等项目中。
八、常见问题解答
8.1 如何提高识别率?
- 确保图片清晰,避免模糊或压缩
- 调整阈值,找到最佳二值化效果
- 尝试多种预处理方法,如降噪、锐化等
8.2 遇到复杂验证码怎么办?
- 使用深度学习模型,如 CNN 或 RNN
- 结合传统图像处理与机器学习方法
- 考虑使用商业 OCR 服务
8.3 如何集成到爬虫项目?
- 将识别流程封装为函数,方便调用
- 结合 Selenium 或 Requests 自动获取验证码
- 处理识别失败的情况,如重试或人工干预
九、结语
图形验证码识别是自动化测试和爬虫开发中的基础技能。通过本节内容,你已经掌握了从环境搭建到图像预处理、再到完整识别流程的全面知识。希望这些内容能帮助你更好地应对实际项目中的图形验证码挑战。
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!