【Deepseek 学cuda】CUTLASS: Fast Linear Algebra in CUDA C++
CUTLASS: Fast Linear Algebra in CUDA C++




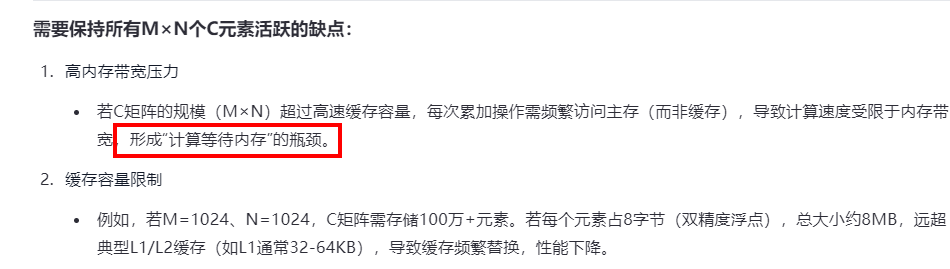
上面一次内存访问,数据计算重复N次,达到理论值,是要将A B C矩阵一次性全部放到缓冲里。所以实际做不到
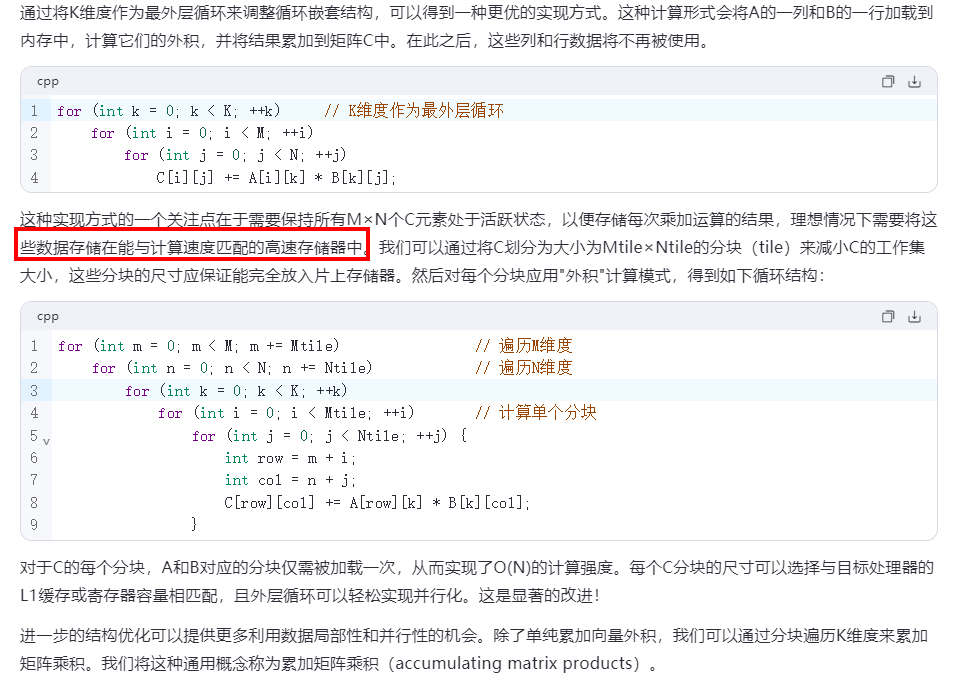
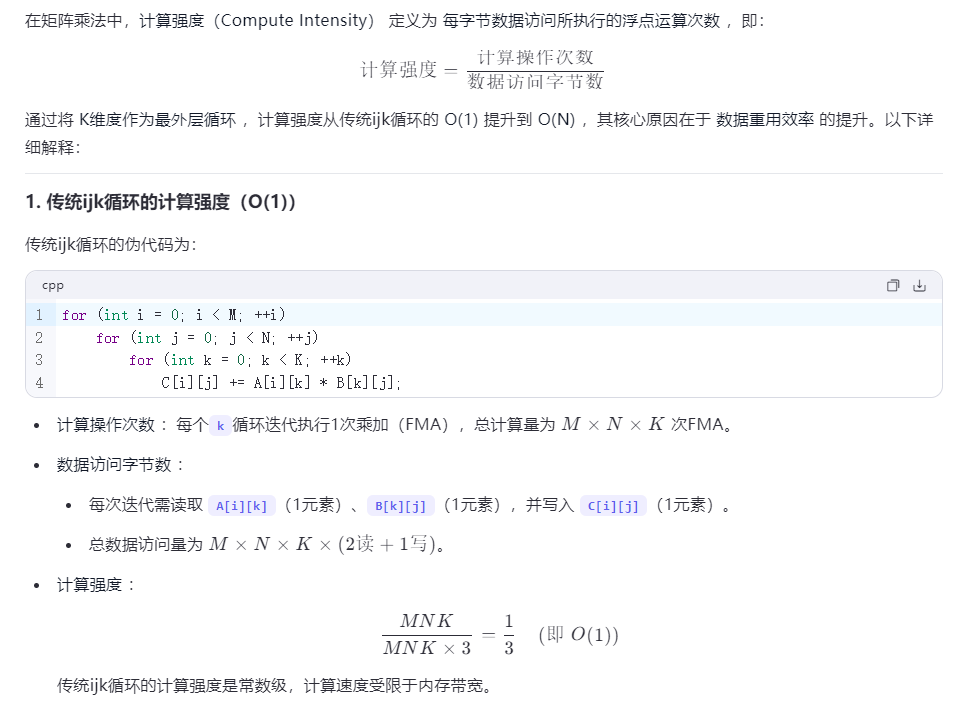
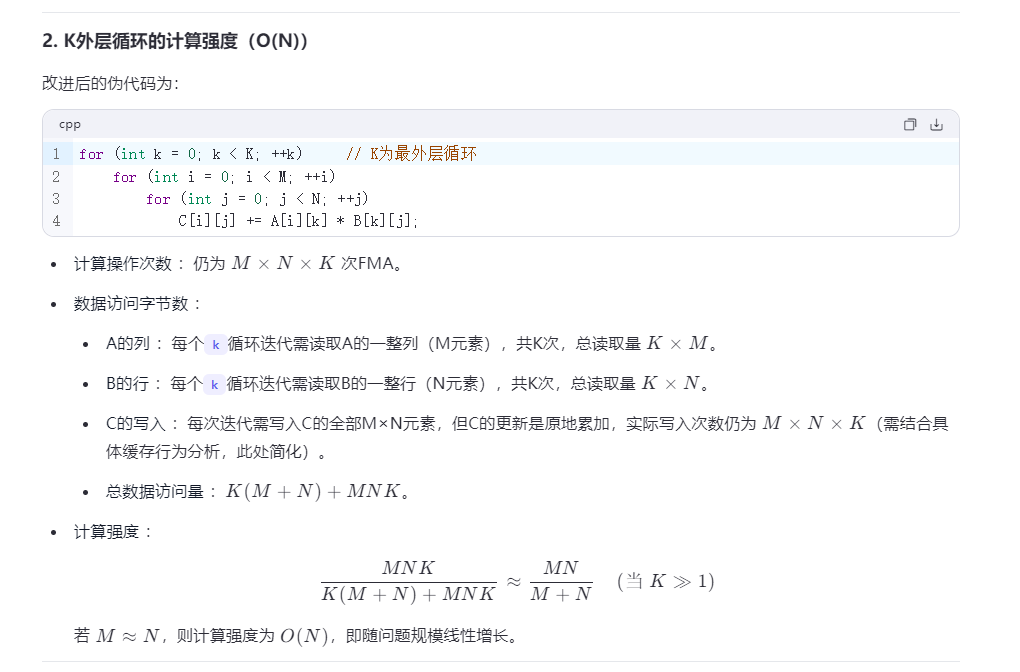
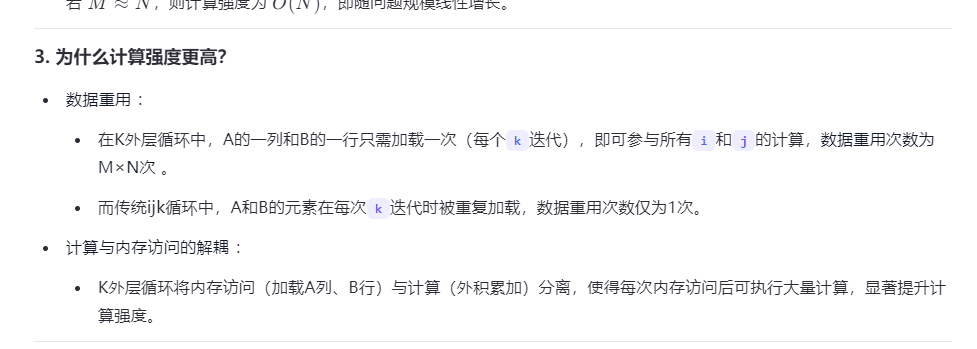




在这里插入图片描述
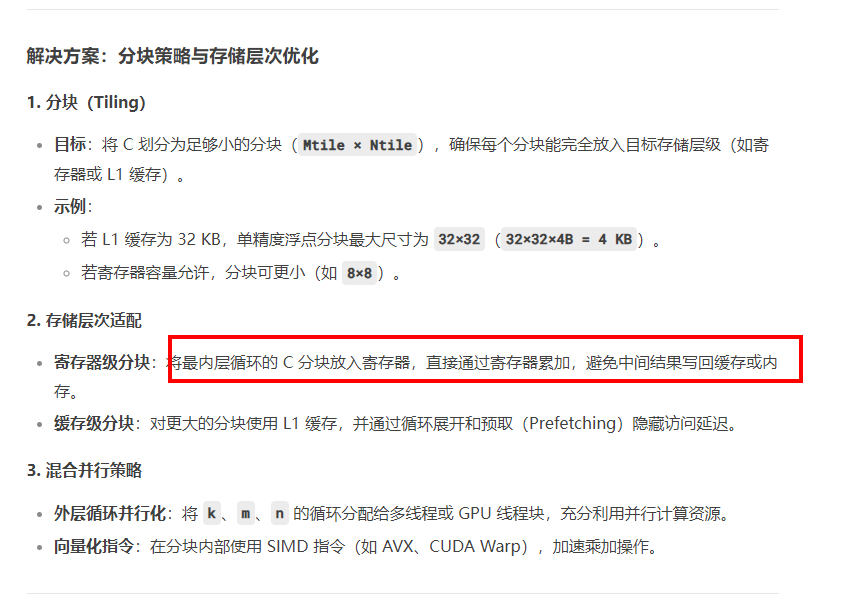
k 在外层,可以将C放入寄存器, 遍历完所有的K之后,计算后,最终一次性将结果写回内存,而不需要中间结果写回内存



**
这里需要注意共享内存与寄存器的区别:
寄存器是线程私有的,每个线程的寄存器在物理上位于不同的位置,无法被其他线程访问。而共享内存是线程块内共享的,属于片上内存,访问速度快,适合协作。
当多个线程需要协作处理数据时,如果数据在寄存器中,每个线程必须独立处理自己的数据,无法直接共享,导致数据冗余或重复计算。而共享内存允许线程块内的线程共享数据,减少重复加载,提高效率。
由于共享内存是block 内所有线程共享的, 所以 可以让block 所有线程 写作将A B tile 一次性从HBM搬到SMEM。
但是由SMEM搬到寄存器, 每个线程会重复搬运。(每个线程有自己的寄存器)