最大熵逆强化学习
目录
## 解决问题
## 具体算法
## 推导过程
### 高效统计每个状态下的频次
## 优点
1.提升确定性与探索性
2.能够解决Label Bias问题:Conditional Random Field literature
1. 动作基分布的核心特点
2. 标签偏差(Label Bias)问题
3. 对IRL的负面影响
4. 最大熵路径分布的优势
## 局限性
## 总结
参考:
## 解决问题
逆强化学习:目标是从专家的行为数据中推断出隐含的奖励函数。一旦得到了奖励函数,就可以用强化学习的方法来训练新的智能体执行任务。
最大熵:在满足已知约束的条件下,概率分布应该尽可能均匀,即保留最大的不确定性。这样可以避免模型做出过于武断的假设,尤其是在数据有限或者存在噪声的情况下,模型更鲁棒。
解决次优演示下的路径分布歧义:
-
核心矛盾:当专家演示行为不是完全最优时,可能存在无数种不同的路径分布都能匹配专家特征期望(即满足约束 E[f]=
)。
-
歧义性:这些分布可能对路径存在“额外偏好”(例如偏好某些无关特征或路径),但这些偏好并未体现在数据中。
-
示例:假设两种路径A和B的特征期望相同,但某个分布赋予A更高概率,而另一个分布赋予B更高概率。这种偏好缺乏数据支持,需消除。
MaxEnt IRL:
应用到逆强化学习中,它假设专家轨迹的分布服从一个指数族分布,其概率与轨迹的累计奖励呈指数关系。也就是说,轨迹的累计奖励越高,其出现的概率越大。同时,整个分布的熵要尽可能大。这样,模型在拟合专家数据的同时,不会对未观察到的数据做过多假设。
-
核心思想:在所有满足特征期望的分布中,选择熵最大(即最不确定、最无偏)的分布。
-
数学意义:最大熵分布是唯一满足约束且不引入额外假设的分布(符合奥卡姆剃刀原则)。
-
直观解释:
-
若两条路径的特征贡献相同,则它们的概率相等。
-
仅通过特征期望的差异来区分路径概率,避免主观偏好。
-
## 具体算法
- 定义特征向量:状态或状态-动作对映射到特征空间。奖励函数通常表示为这些特征的线性组合,即权重向量与特征向量的点积:
- 定义概率模型:
路径ζ的概率由指数奖励加权,参数化为奖励权重θ
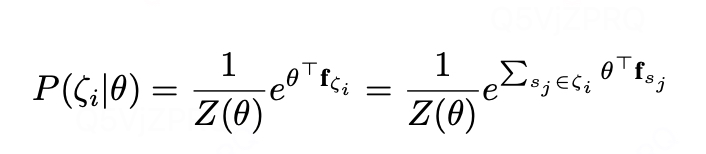
- 最大熵学习:
-
目标:从专家演示数据中学习策略,使策略的熵最大,同时匹配专家的特征期望。
-
优化问题:
-
最大化对数似然:
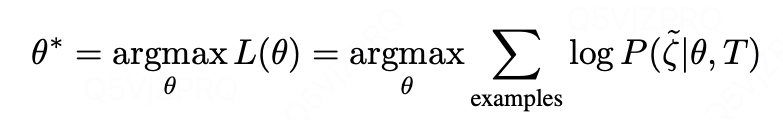
-
约束条件:学习策略的特征期望 E[f]必须等于专家特征期望
-
4. 梯度更新:
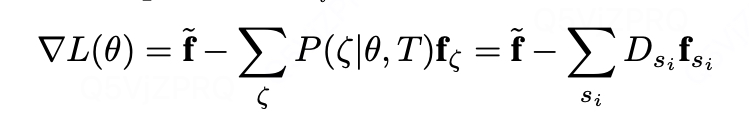
梯度是专家特征期望与学习策略特征期望的差。
-
计算状态访问频率
(即每个状态被访问的概率)。
-
用
,得到学习策略的特征期望。
当梯度为零时,学习策略的特征期望与专家完全匹配。
得到参数,进而得到奖励函数,再通过强化学习训练策略
## 推导过程
最大熵模型的学习等价于以下约束最优化问题:
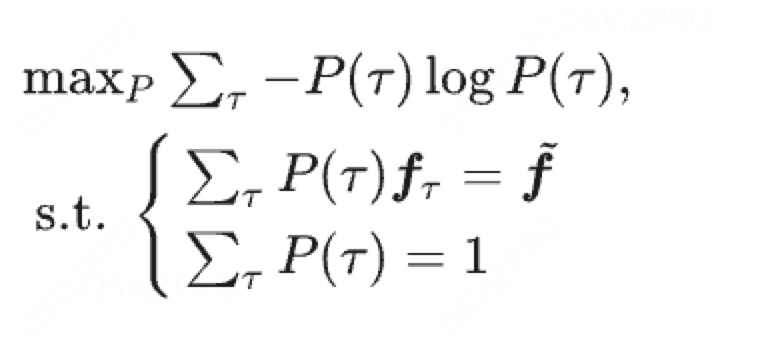
其中为某条轨迹
的概率;
为特征,
为特征期望;
求解方式为将约束最优化的原始问题转换为无约束最优化的对偶问题(具体推导过程可以参考统计学习方法)

先求解:
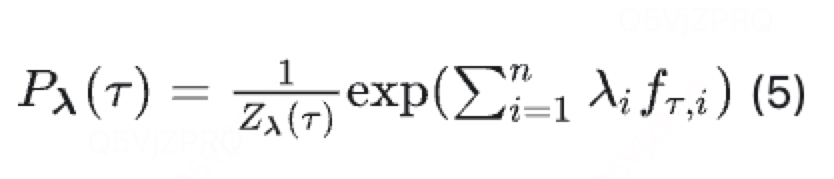 (最大熵模型)
(最大熵模型)
再求解参数(最大熵模型中的参数向量);
对偶函数的极大化等价于最大熵模型的极大似然估计。
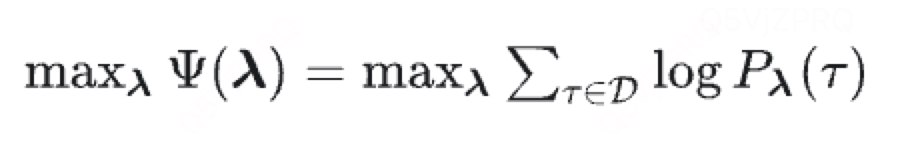
使用专家示例轨迹集,进行上述最大似然估计即可求得 λ ,从而得到奖励函数:
### 高效统计每个状态下的频次
优化过程中需要计算配分函数,离散空间太大的情况下计算复杂度过高。文中解决问题的技巧类似前馈条件随机场或者RL里的value iteration。

## 优点
1.提升确定性与探索性
最大熵模型能够处理专家数据中的不确定性和多模态行为,不会假设专家只遵循单一的最优路径,而是允许存在多种可能的轨迹,只要它们的特征期望与专家的一致。这对于现实世界中专家可能存在多种策略的情况尤为重要。该方法在存在多种可能的解释(路径分布),但选择最“保守”的一种(最大熵)。保证满足约束的情况下,在不确定状态下保证最大熵,避免算法陷入局部偏好或过拟合。
2.能够解决Label Bias问题:Conditional Random Field literature
1. 动作基分布的核心特点
-
定义:路径的概率分布基于局部动作选择(每个状态下动作的概率独立计算),而非全局路径结构。
-
概率分配规则:
P(ζ)=P(a1∣s0)⋅P(a2∣s1)
每条路径的概率 = 其所有动作选择概率的连乘。
例如:路径 ζ=(s0→a1s1→a2s2)的概率为: -
局部归一化:每个状态下动作概率之和为1(即 ∑aP(a∣s)=1)。
2. 标签偏差(Label Bias)问题
-
现象:由于局部归一化,路径概率受分支因子(Branching Factor)影响:
-
分支因子:一个状态下可选的动作数量。
-
分支因子小的状态 → 动作概率集中,路径概率易被放大。
-
分支因子大的状态 → 动作概率分散,路径概率易被稀释。
-
-
示例:
-
路径A:经过状态 s1s1(分支因子=2,动作概率各0.5)。
-
路径B:经过状态 s2s2(分支因子=3,动作概率各≈0.33)。
若两条路径奖励相同,路径A的概率 0.5×...0.5×... 会高于路径B的 0.33×...0.33×...。
-
3. 对IRL的负面影响
-
问题1:最优策略可能非最概然
假设存在一条高奖励路径,但经过高分支因子状态,其全局概率可能被稀释,导致模型更倾向于低分支因子的次优路径。 -
问题2:相同奖励的策略概率不同
两条期望奖励相同的路径,因分支因子差异,在动作基分布中概率不同(违背最大熵的无偏原则)。 -
问题3:偏好与奖励无关的结构
模型隐式偏好分支因子小的路径(结构偏差),而非真正高奖励路径(目标偏差)。
4. 最大熵路径分布的优势
-
全局归一化:路径概率直接由指数奖励加权(全局路径奖励),归一化因子 Z(θ)考虑所有路径。
-
消除结构偏好:
-
仅依赖路径总奖励,与分支因子无关。
-
相同奖励的路径概率相等,高奖励路径指数级更优。
-
问题本质:动作基分布像“近视决策”——每一步只关注当前状态的动作概率,忽略全局路径结构,导致概率分配不公平。
最大熵方案:像“全局裁判”——直接根据路径总奖励打分,避免结构干扰,更公平且符合目标。
应用启示:在复杂环境中(如机器人导航、游戏AI),最大熵方法能更准确地从数据中反推奖励函数,尤其在存在多条等效路径时。
## 局限性
1. 计算复杂度高,特别是处理大规模状态空间或长时程轨迹时,配分函数的计算(需要枚举所有轨迹)可能不可行。
配分函数:
2. 此外,特征工程的选择对结果影响很大,如果特征不能很好地捕捉奖励函数的关键因素,学到的奖励函数可能不准确。还有,
3. MaxEnt IRL假设专家数据是独立同分布的,但在实际应用中,轨迹之间可能存在时间相关性,这需要进一步考虑。
## 总结
-
问题:如何从专家演示中学习一个既随机(鲁棒)又能匹配专家行为的策略?
-
方法:
-
假设专家行为服从指数族分布(奖励函数线性加权特征)。
-
最大化路径分布的熵,同时让学习策略的特征期望与专家一致。
-
-
实现:用梯度下降优化奖励权重 θ,直到学习策略的行为与专家无法区分。
这种方法广泛应用于逆向强化学习(IRL)和机器人模仿学习,能够处理噪声数据并避免过拟合。
参考:
- https://zhuanlan.zhihu.com/p/512638348
- https://www.andrew.cmu.edu/course/10-703/slides/Lecture_IRL_GAIL.pdf
- Maximum Entropy Inverse Reinforcement Learning (AAAI-2008)