Apache Pulsar 消息、流、存储的融合
Apache Pulsar 消息、流、存储的融合
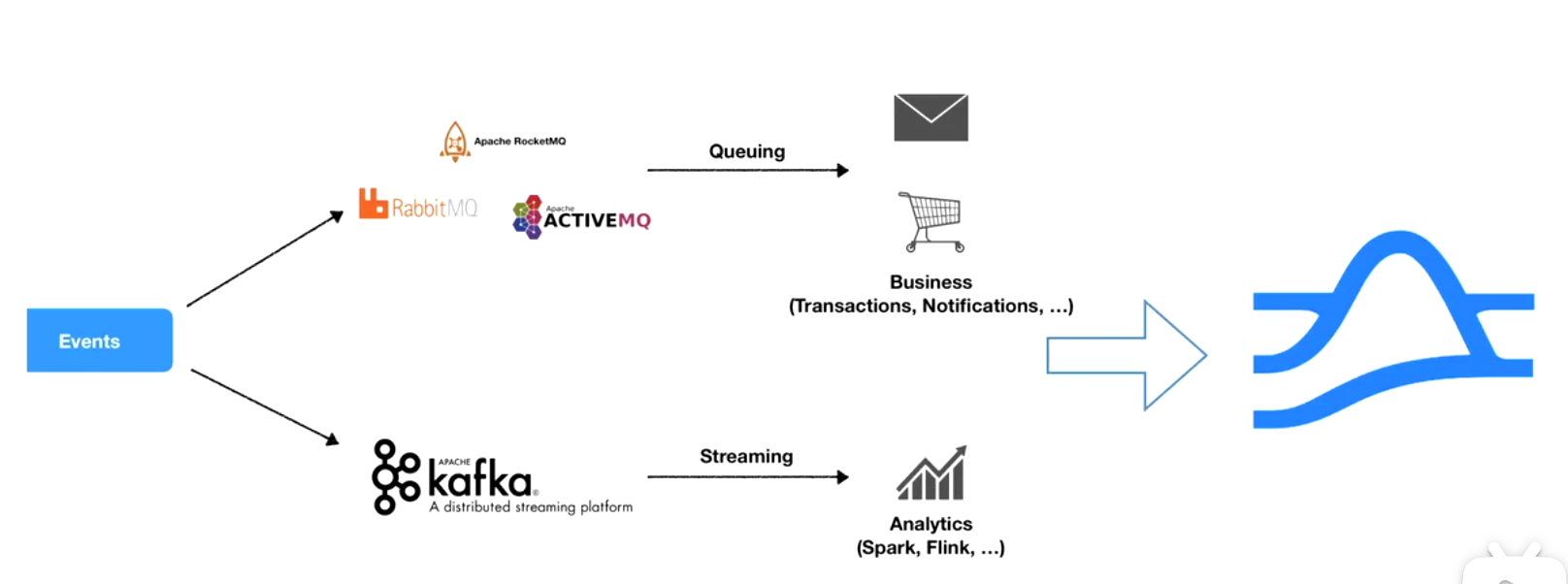
消息队列在大层面有两种不同类型的应用,一种是在线系统的message queue,一种是流计算,data pipeline的streaming高throughout,一致性较低,延迟较差的过程。
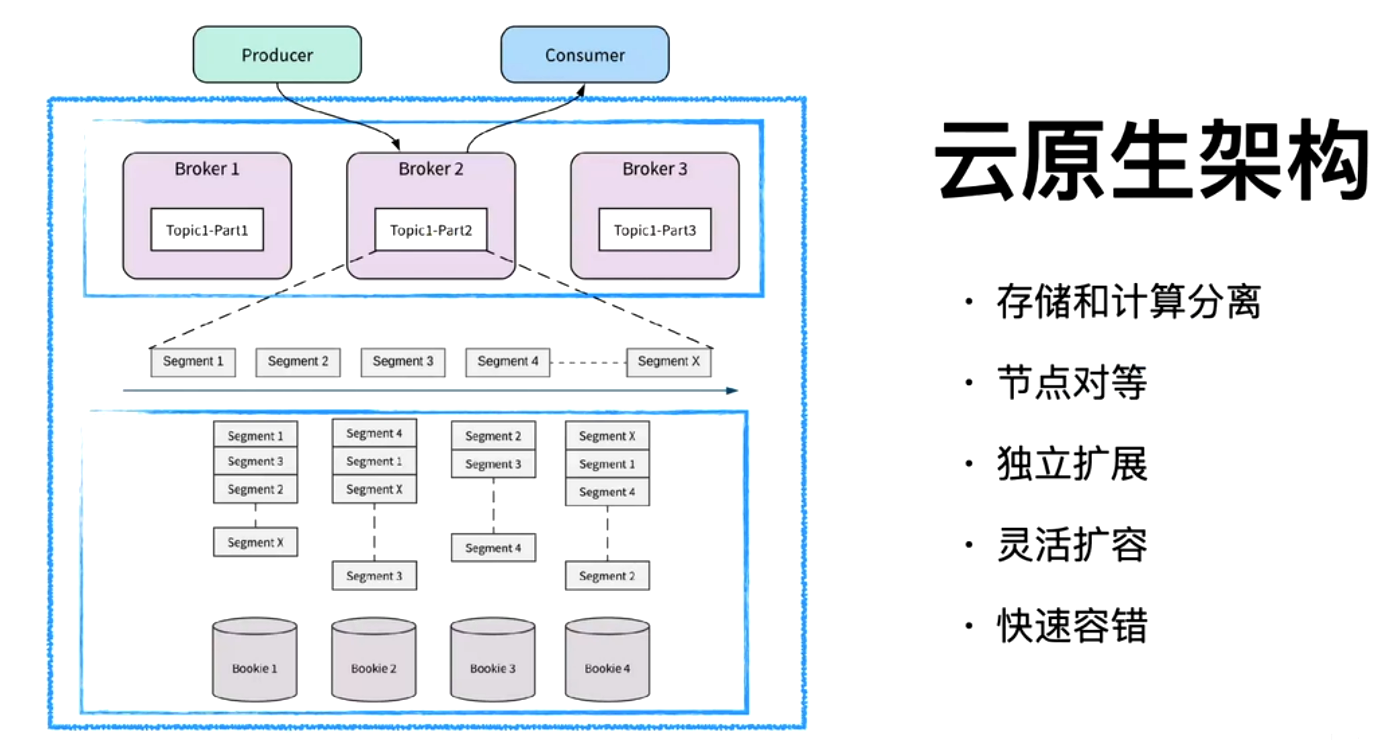
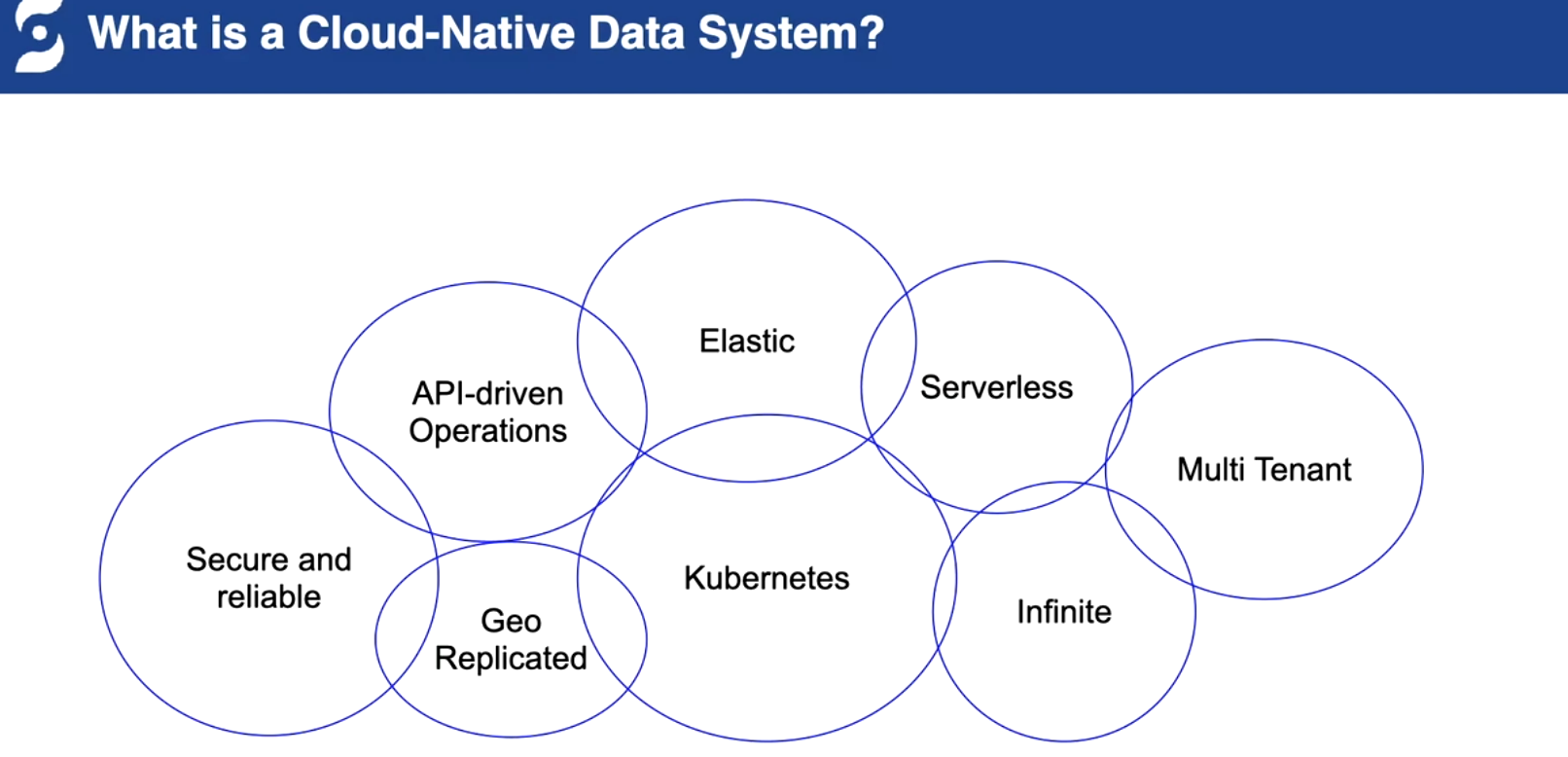
存算分离 扩容和缩容快速
segment 打散(时间和容量切分)多机器能力
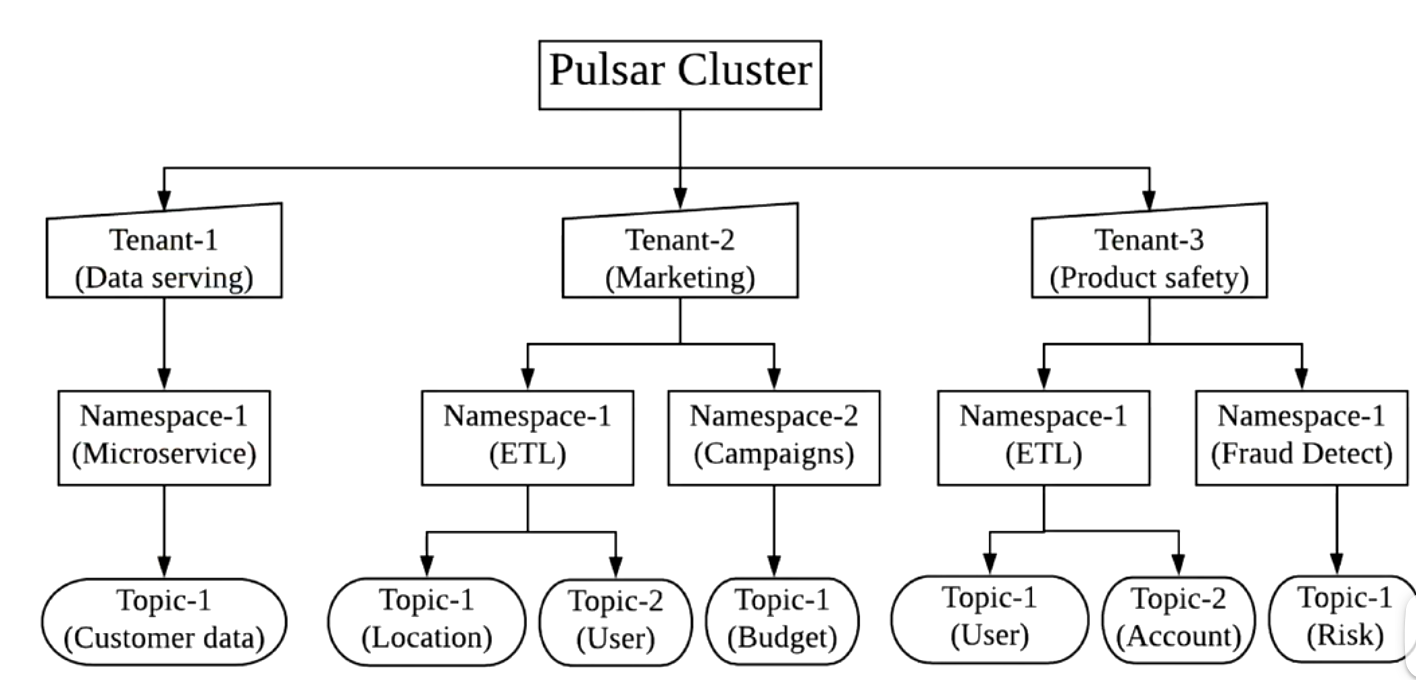
多租户的能力,配额

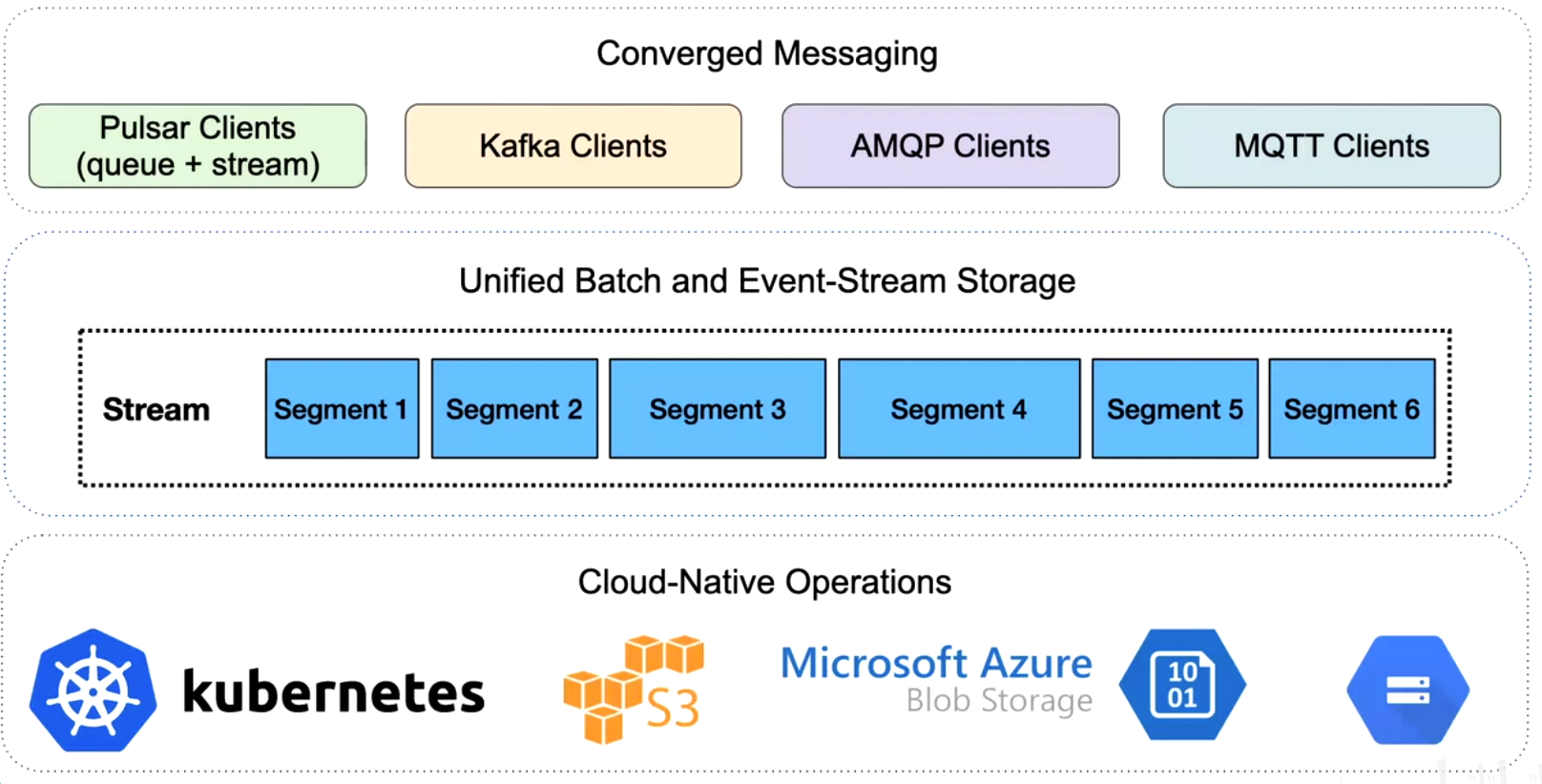
原来的架构,多种消息中间件不同场景不同选型
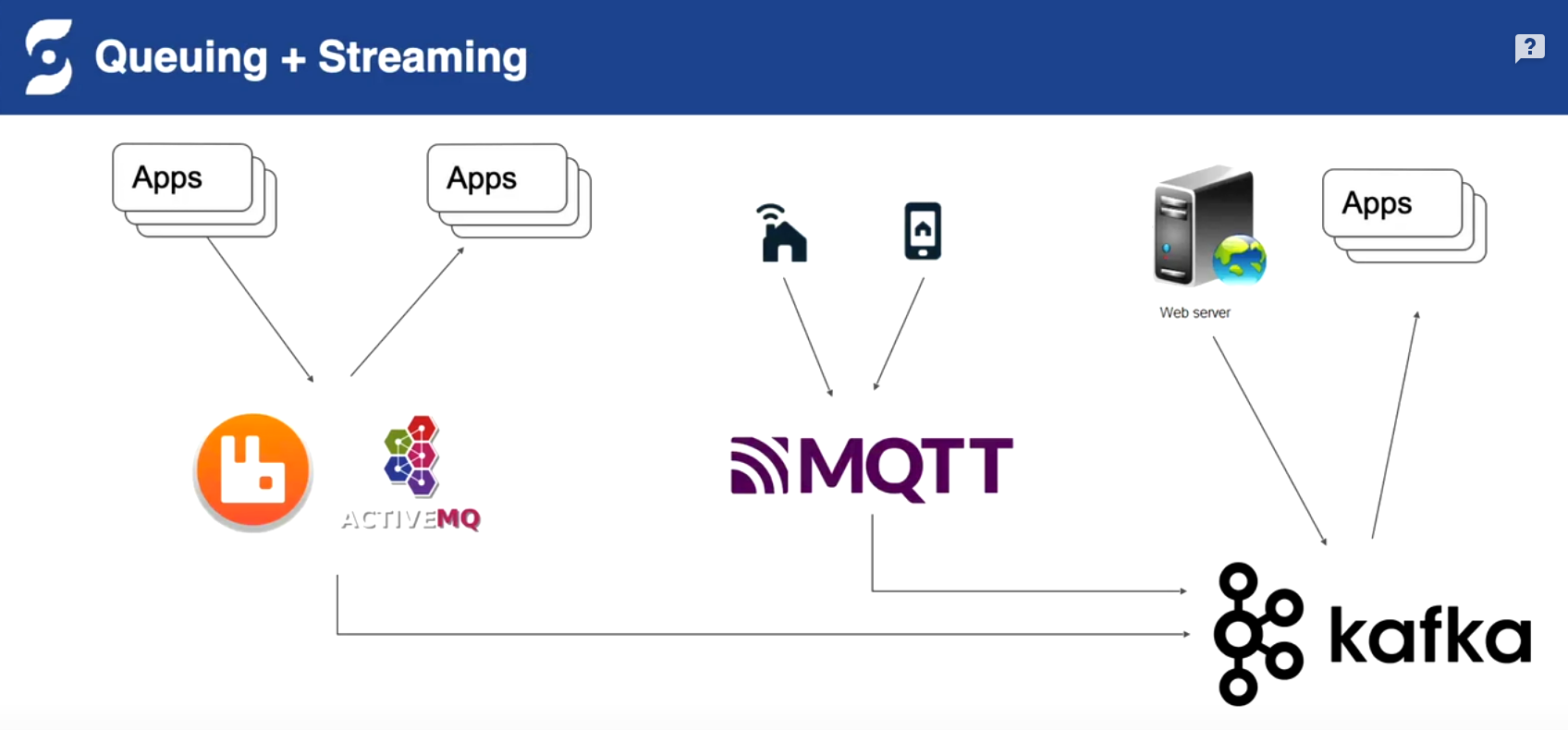
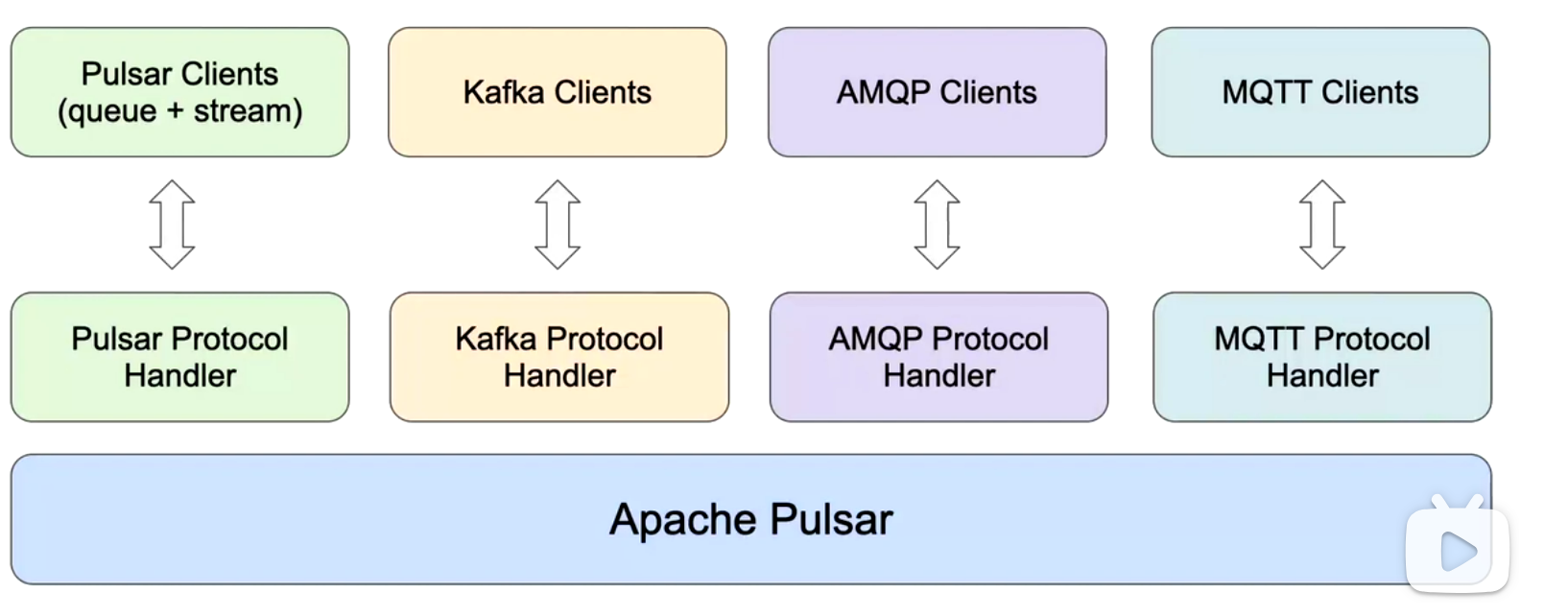
统一兼容旧系统协议,统一存储bookkeeper
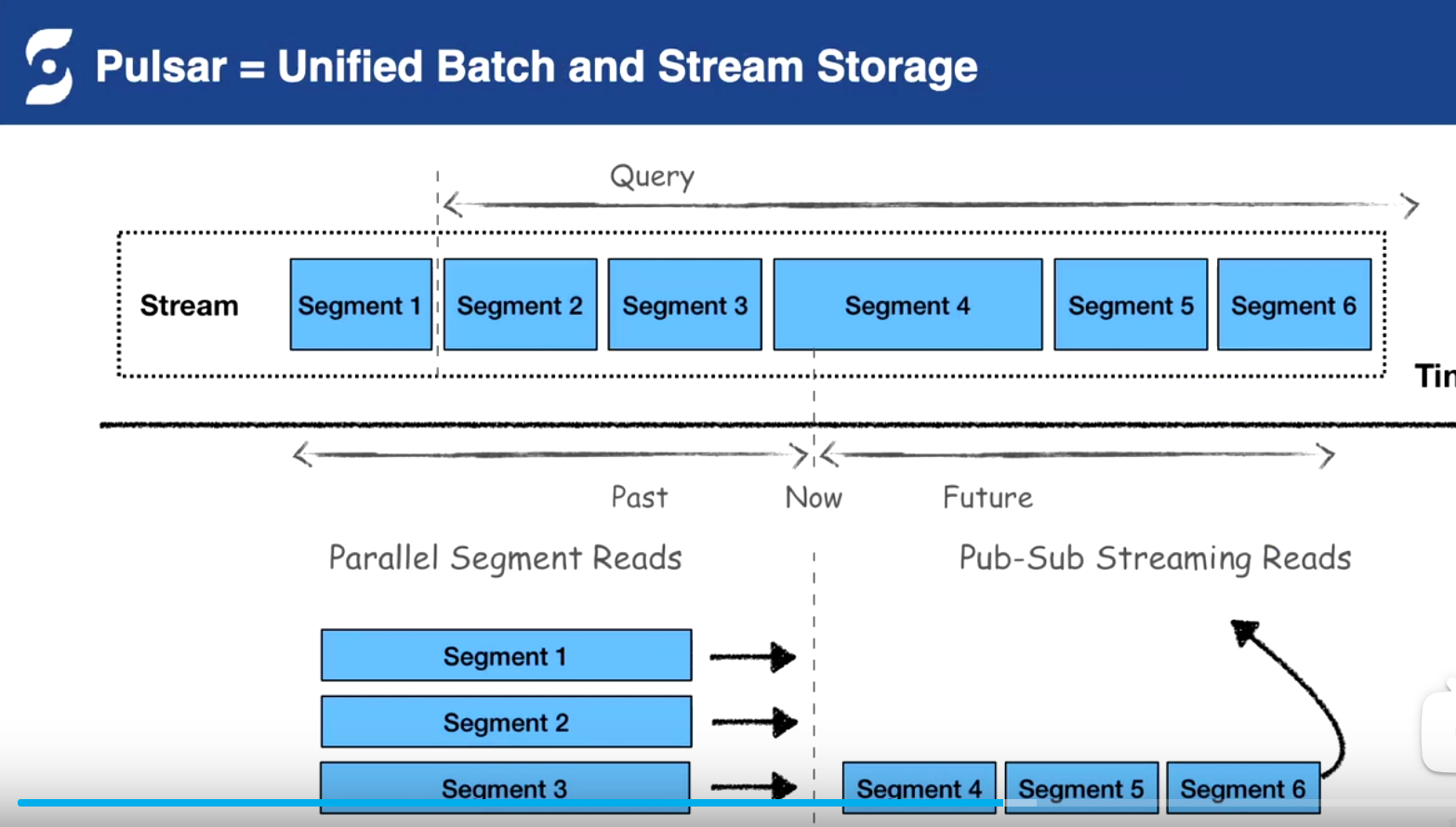
内部二级分层存储,统一批存储和流存储(之前外部系统计算存储到HDFS)
统一抽象管理,统一视图topic抽象,但是优化存储位置历史数据列存等
云原生的能力
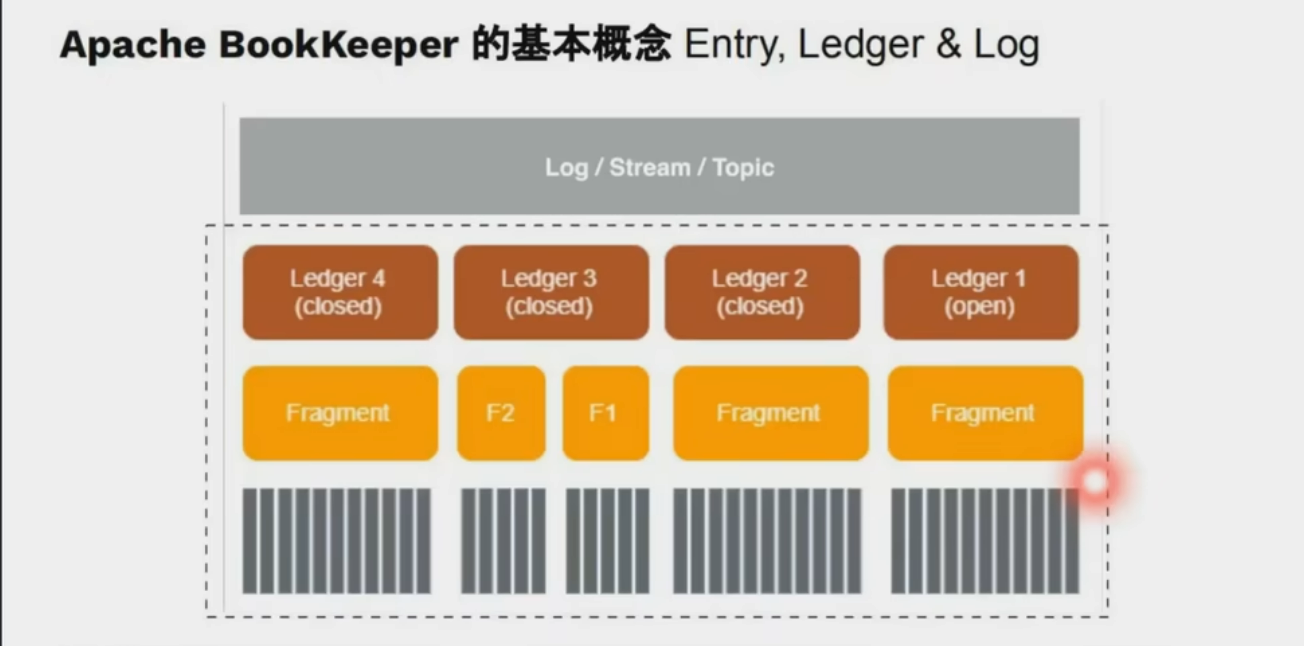
Apache BookKeeper:Apache Pulsar的高可用强一致低延迟的存储实现
可调整(带宽,灾备等级,一致性等级)
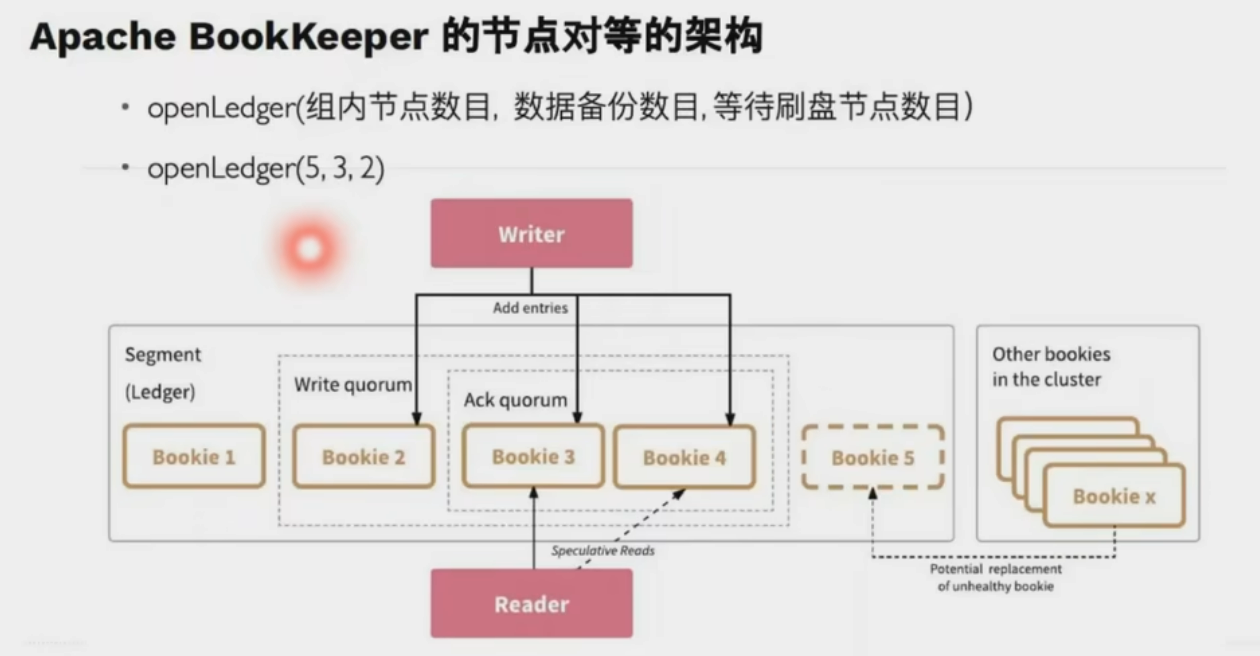
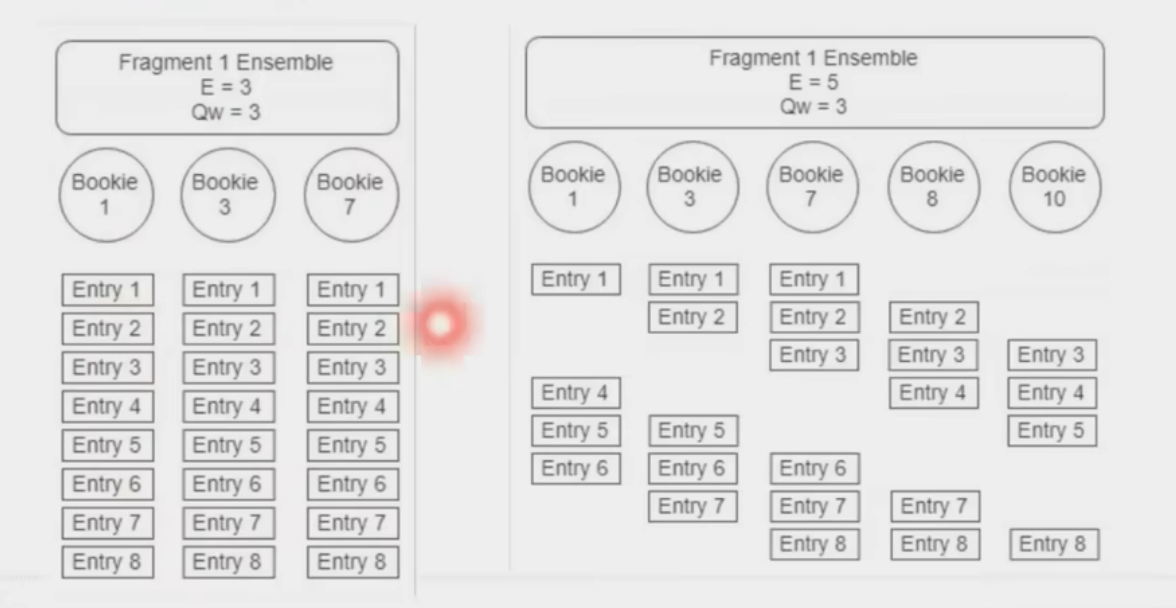

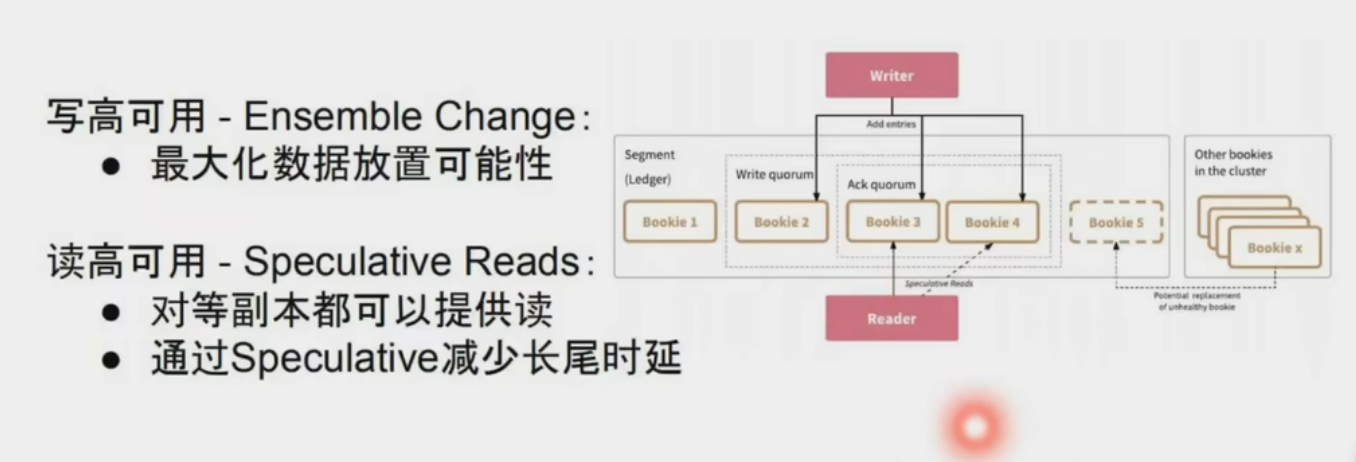
新起一份fragment承载写
writer变成master,底层存储是对等节点(区别raft一致性)
两个writer有点像paxos
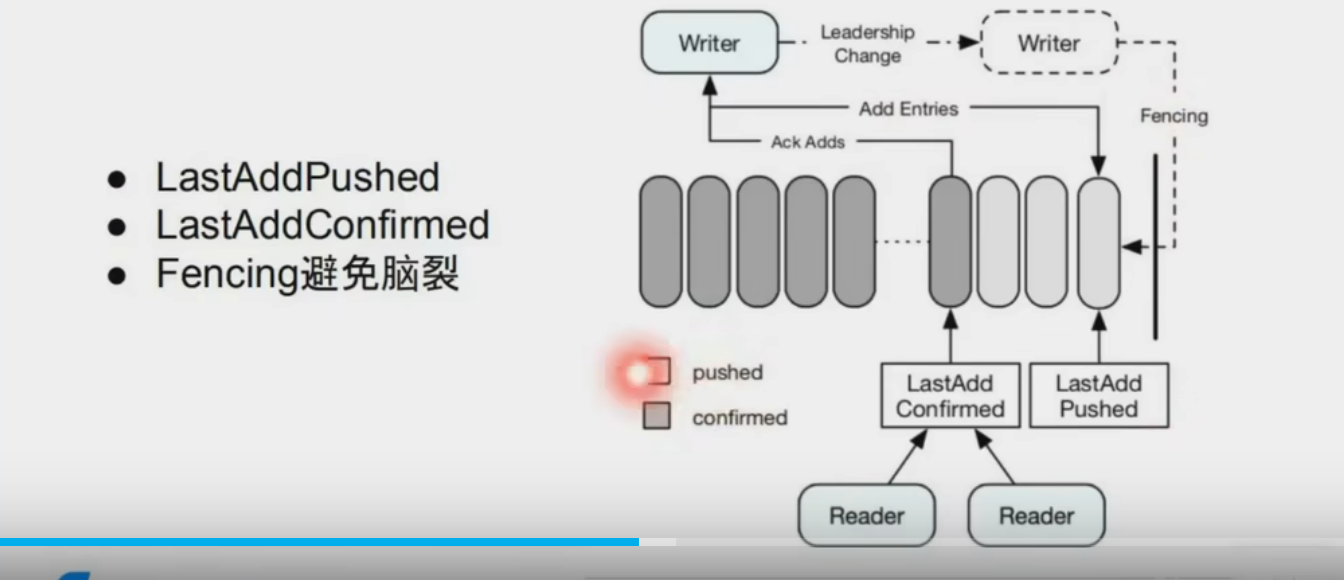
磁盘隔离WAL,数据盘隔离(可变换)
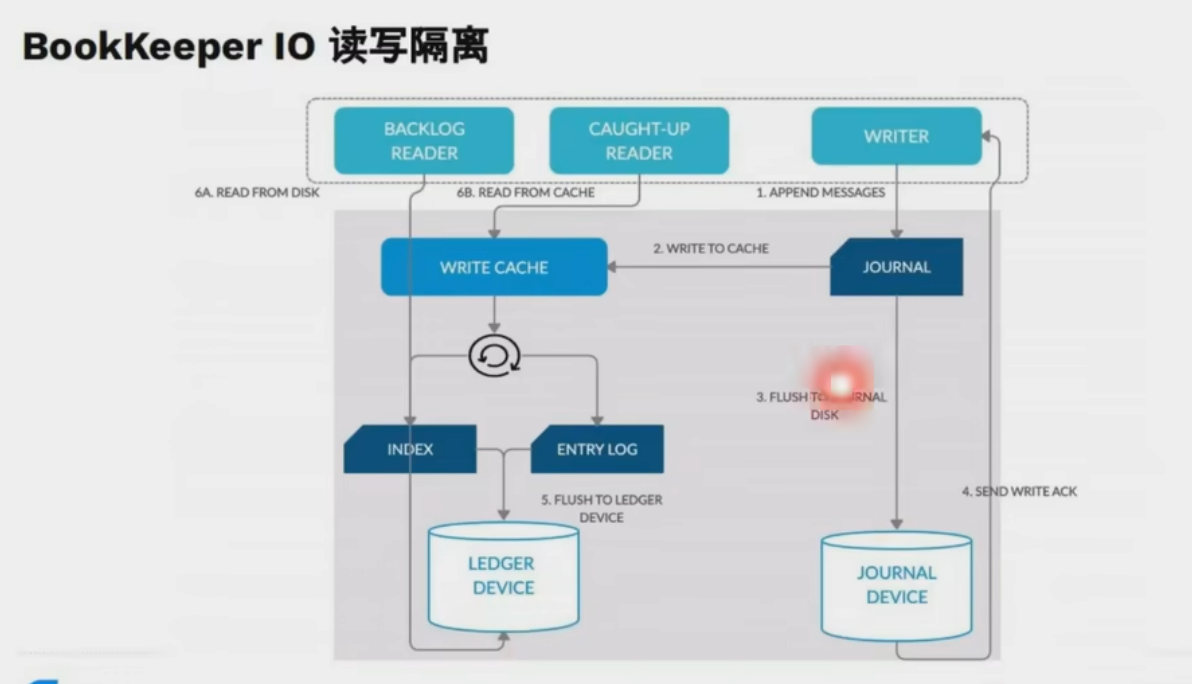
PMEM,快,容量小,寿命高,比SSD更适合做journal
Apache Pulsar 依赖的 Apache BookKeeper 作为其底层存储引擎,其架构设计与优化机制具有鲜明的分布式系统特征。以下从架构概念、适用场景、高可用优化及一致性保障等维度进行结构化解析:
一、核心架构概念
-
存储单元与数据结构
- Entry:最小存储单元,每个 Entry 包含唯一递增的序列号,支持随机访问和批量读取2。
- Ledger:由多个 Entry 组成的有序日志段,具有不可变性(一旦关闭无法追加)和原子性(写入成功或全失败)26。
- Stream:逻辑上的无限数据流,由多个 Ledger 组成;当单个 Ledger 达到空间或时间阈值时,自动创建新 Ledger2。
- Bookie 节点:存储节点,每个节点包含 Journal(预写日志)、Entry Log(Entry 持久化文件)和 Index Files(索引文件)6。
-
分片存储架构
Pulsar 将 Topic 分区的数据切分为多个 Segment(即 BookKeeper Ledger),每个 Segment 独立存储于不同 Bookie 节点,实现细粒度负载均衡和扩展性37。
二、适用场景
- 消息系统:为 Pulsar 提供持久化存储,支持低延迟(<5ms)的流式追尾写入25。
- 分布式日志:适用于需要强一致性与容错的日志存储(如 HDFS NameNode 的 Edit Log)6。
- WAL(预写日志):为数据库或分布式系统提供事务日志的高可靠存储6。
- 跨数据中心复制:支持多集群间的数据同步与一致性保障2。
三、读写高可用优化
- Quorum 机制
写入时客户端并行发送 Entry 至多个 Bookie 节点,需多数节点(例如 3/5)确认成功,确保数据冗余且容忍节点故障1。 - 动态 Ensemble 调整
根据负载动态调整写入的 Bookie 节点组合,避免热点问题并提升吞吐量1。 - 并行读取优化
读操作可并发从多个副本获取数据,优先返回最快响应,降低延迟16。 - 分片存储负载均衡
通过 Segment 切分策略,将数据均匀分布至集群,避免单节点瓶颈37。
四、一致性保障机制
- 写入一致性
基于 Quorum 的多数确认策略,保证至少多数副本持久化成功后才返回客户端确认16。 - LastAddConfirmed (LAC)
客户端通过 LAC 标记追踪已持久化的最新 Entry,确保读操作仅访问已确认数据18。 - Fencing 机制
当检测到旧 Writer 可能异常时,新 Writer 通过 fencing 操作标记旧 Ledger 为不可写,避免多 Writer 冲突(脑裂)18。 - Ledger 不可变性
已关闭的 Ledger 不可修改,防止数据篡改并简化一致性管理2。
五、Writer 脑裂避免
- Fencing 流程:新 Writer 启动时会对旧 Ledger 发起 fencing 请求,通过元数据服务(如 ZooKeeper)验证所有权,确保同一时刻仅一个有效 Writer18。(实际上也就是用外部选主,简化存储层设计,达到对等节点)
- 原子性元数据更新:Ledger 元数据(如状态、Owner)需通过原子操作更新,避免并发冲突6。
六、其他重要概念
- 跨机房复制:通过异步复制机制实现多集群间数据同步,支持地理容灾2。
- 分层存储:支持将冷数据迁移至廉价存储(如 HDFS),降低存储成本6。
- 计算存储分离:Pulsar Broker 处理计算逻辑,BookKeeper 专注存储,提升系统弹性与扩展性37。
通过上述设计,BookKeeper 在高吞吐、低延迟与强一致性之间取得平衡,成为云原生场景下可靠的分布式存储基石。
深入对比 Apache Pulsar 与 Kafka

kafka横向扩展困难,以及kafka的弹性伸缩困难

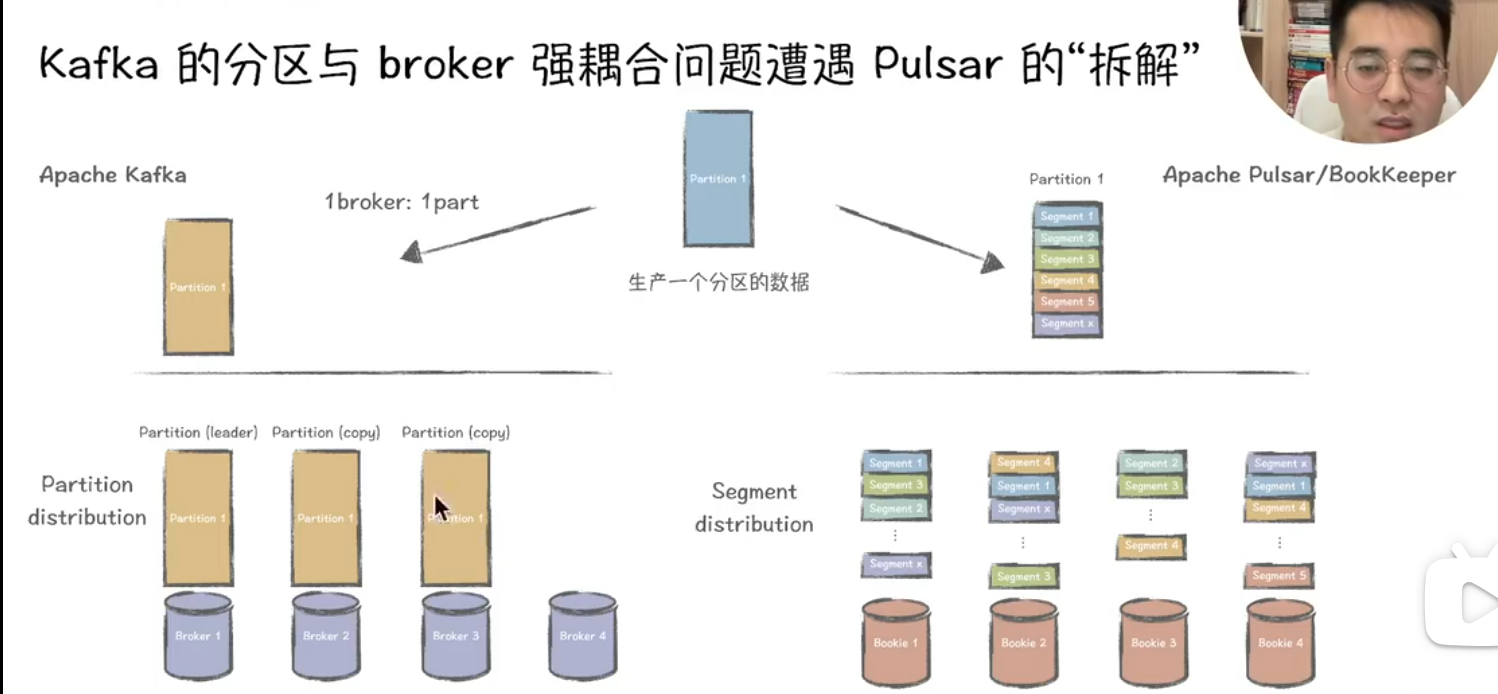
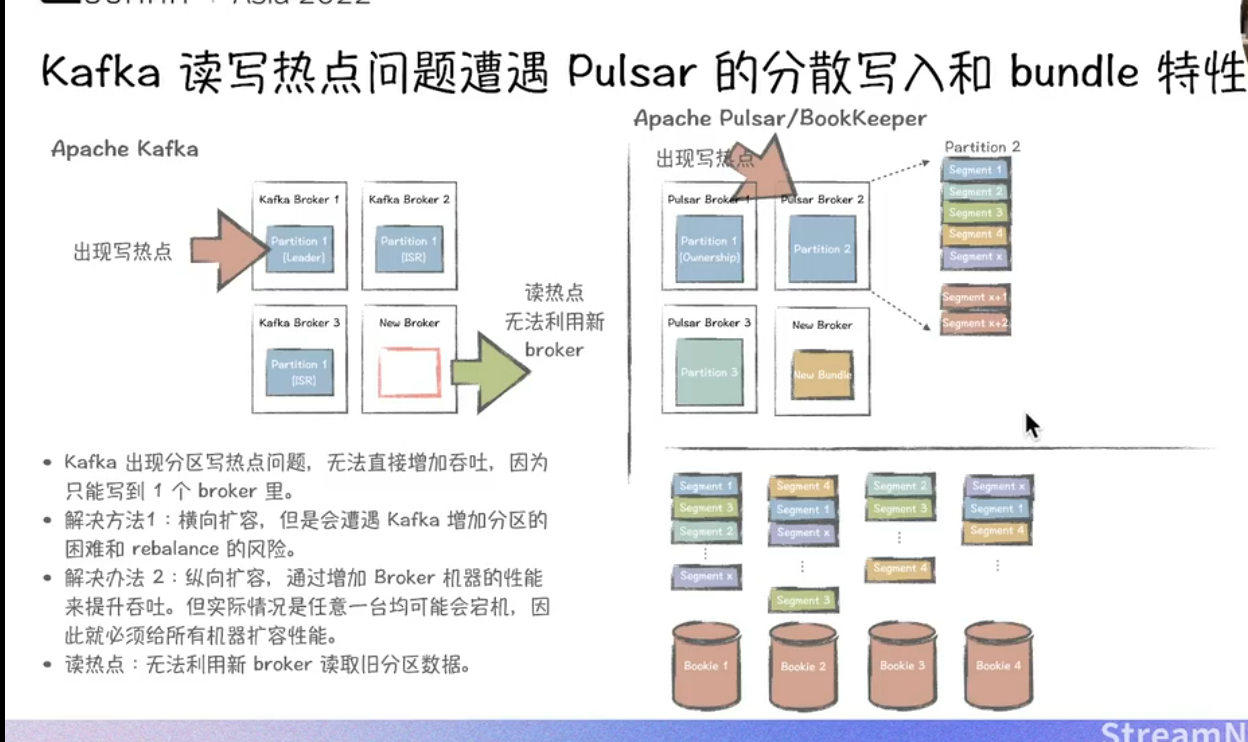
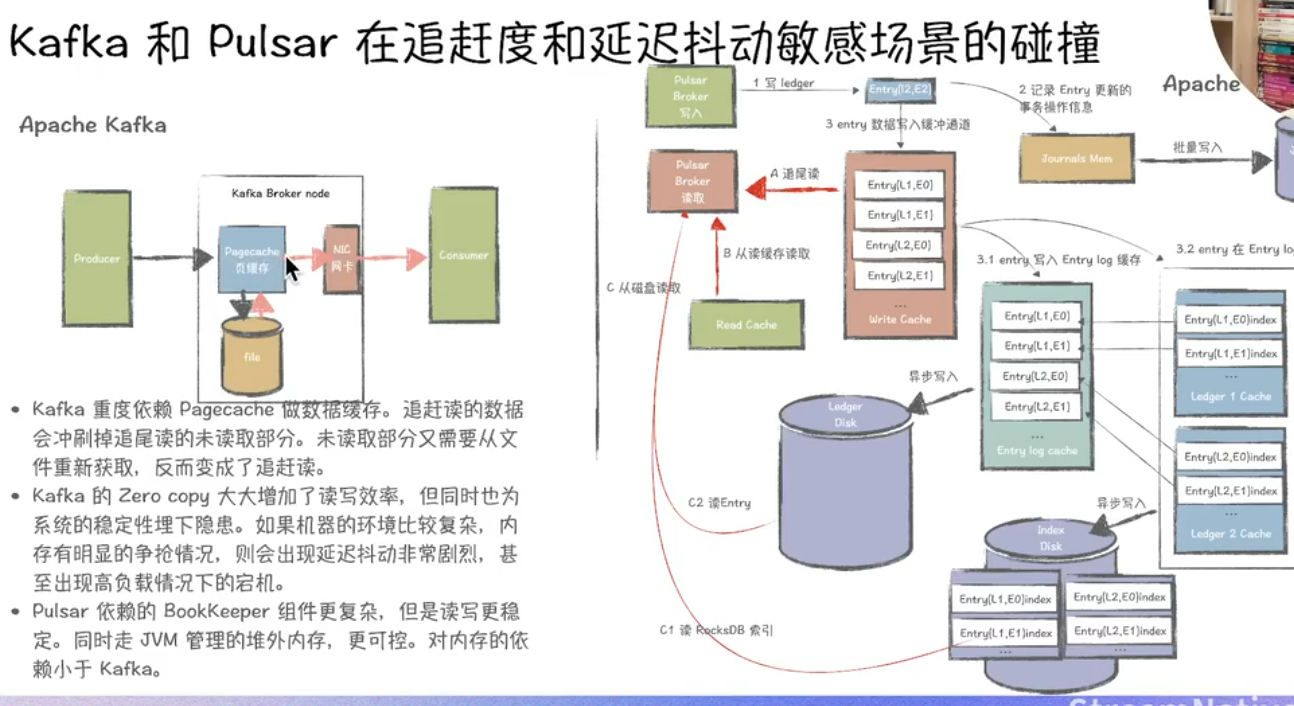

以下从追尾读、切Segment、容错恢复迁移速度、存算分离等角度对Kafka与Pulsar进行深度对比分析:
一、追尾读(Tailing Reads)
-
Kafka
- 采用消费者主动拉取机制,尾部读取延迟受消费者轮询频率影响。在高吞吐场景下,若Topic分区数过多或消费者组协调复杂,可能出现尾部延迟波动现象25。
- Broker同时承担计算与存储职责,尾部读取可能因磁盘IO压力导致性能下降8。
-
Pulsar
- 通过无状态Broker和预读缓存机制优化尾部读取性能,在同等负载下延迟可稳定低于5ms5。
- 存储与计算分离架构减少了Broker的磁盘IO竞争,结合BookKeeper的条带化写入策略,尾部读取吞吐量更高38。
二、切Segment机制
-
Kafka
- 每个分区由多个Segment文件组成,按时间或大小拆分。切Segment时需同步更新索引文件,若写入速率极高可能导致短暂写入阻塞3。
- Segment文件本地存储,扩容时需跨节点迁移数据,影响集群整体性能6。
-
Pulsar
- 基于BookKeeper存储层,Segment(Ledger)以分布式副本形式存储在多个Bookie节点上,切Segment仅需关闭当前Ledger并创建新Ledger,过程无阻塞38。
- 新Segment写入直接分配到可用Bookie节点,天然支持水平扩展,无需数据迁移3。
三、容错恢复与迁移速度
-
Kafka
- 副本恢复依赖ISR(In-Sync Replicas)机制,副本同步过程需全量复制数据,迁移速度受网络带宽和磁盘I/O限制6。
- 分区再平衡时需重新选举Leader并同步数据,大规模集群下耗时显著增长3。
-
Pulsar
- 存储层BookKeeper采用多副本Quorum写入(Write Quorum + Ack Quorum),单Bookie故障时自动切换至健康节点,恢复无需数据拷贝,仅需重放未确认的Entry8。
- Broker无状态设计,故障节点可快速替换,Topic分区自动迁移至新Broker,延迟仅取决于ZooKeeper元数据同步时间36。
四、存算分离架构
-
Kafka
- 存算一体架构,Broker同时负责消息处理和存储,扩容需同时调整计算与存储资源,难以独立扩展6。
- 云原生适配性较弱,需依赖外部工具(如Kubernetes StatefulSets)实现动态扩缩容3。
-
Pulsar
- 计算层(Broker)与存储层(Bookie)完全解耦,支持独立扩缩容。Broker无状态,可快速水平扩展;Bookie节点动态增减不影响数据一致性38。
- 原生适配云原生环境,结合Kubernetes可实现秒级弹性伸缩,资源利用率提升30%以上36。
- 数据存储采用分层设计,冷热数据可分离至不同存储介质(如SSD/HDD),进一步降低成本8。
五、其他关键差异
| 维度 | Kafka | Pulsar |
|---|---|---|
| 多租户支持 | 需手动隔离,依赖外部管控工具7 | 原生支持租户级资源配额及Namespace隔离3 |
| Topic扩展性 | 单集群支持约数万Topic6 | 单集群支持超50万Topic且性能稳定3 |
| 数据一致性 | 依赖ISR机制,极端场景可能丢数8 | Quorum写入+强一致性模型,金融级可靠性8 |
总结
- Kafka更适合对吞吐量要求极高且集群规模相对固定的场景,但运维复杂度较高。
- Pulsar在动态扩缩容、低延迟追尾读、快速容错恢复等方面优势显著,尤其适合云原生环境及需要强一致性的金融级应用35。