分布式2(限流算法、分布式一致性算法、Zookeeper )
目录
限流算法
固定窗口计数器(Fixed Window Counter)
滑动窗口计数器(Sliding Window Counter)
漏桶算法(Leaky Bucket)
令牌桶算法(Token Bucket)
令牌桶与漏桶的对比
分布式限流实现
限流框架推荐
根据业务场景选择合适的限流算法:
评估算法特性
1. 性能指标
2. 关键特性对比
Ngixn 控制速率/控制并发连接数
网关令牌桶限流
分布式一致性算法
常见算法
1. Paxos 算法
2. Raft 算法
3. ZAB 协议(ZooKeeper Atomic Broadcast)
4. Paxos 变体(Multi-Paxos、Fast Paxos)
5. 拜占庭容错算法(PBFT、PoW)
应用场景与实践
1. 分布式协调服务
2. 分布式数据库
3. 区块链
选择建议
常见误区与挑战
总结
算法对比
Zookeeper
数据结构
特点
核心功能
统一配置管理
命名服务
分布式锁
核心特点
典型场景
底层技术支撑
集群管理
架构设计
典型应用场景
关键技术细节
优缺点
最佳实践
替代方案
总结
Dubbo
限流算法
限流是分布式系统中控制流量的重要手段,用于防止系统因过载而崩溃。以下是几种常见的限流算法及其原理、优缺点和实现方式:
固定窗口计数器(Fixed Window Counter)
- 原理:将时间划分为固定大小的窗口,每个窗口内维护一个计数器。当请求到达时,若计数器超过阈值则拒绝请求。
- 优点:实现简单,空间复杂度低(O (1))。
- 缺点:存在临界问题(如窗口切换时可能出现突发流量)。
- 示例代码:
import java.util.concurrent.atomic.AtomicInteger;public class FixedWindowRateLimiter {private final int capacity; // 窗口容量private final long windowSizeMillis; // 窗口大小(毫秒)private AtomicInteger count = new AtomicInteger(0);private long windowStartMillis;public FixedWindowRateLimiter(int capacity, long windowSizeMillis) {this.capacity = capacity;this.windowSizeMillis = windowSizeMillis;this.windowStartMillis = System.currentTimeMillis();}public synchronized boolean allow() {long currentTimeMillis = System.currentTimeMillis();// 窗口已过期,重置计数器if (currentTimeMillis - windowStartMillis > windowSizeMillis) {windowStartMillis = currentTimeMillis;count.set(0);}// 未超过容量,允许请求if (count.get() < capacity) {count.incrementAndGet();return true;}return false;} }
滑动窗口计数器(Sliding Window Counter)
- 原理:将固定窗口划分为更小的时间片段,每个片段维护独立计数器。统计时,将所有片段的计数器累加作为当前窗口的计数。
- 优点:解决了固定窗口的临界问题,更平滑地控制流量。
- 缺点:实现复杂度高,空间复杂度增加(O (n),n 为片段数量)。
- 示例代码:
import java.util.concurrent.ConcurrentLinkedQueue;public class SlidingWindowRateLimiter {private final int capacity; // 窗口容量private final long windowSizeMillis; // 窗口大小(毫秒)private final ConcurrentLinkedQueue<Long> queue = new ConcurrentLinkedQueue<>();public SlidingWindowRateLimiter(int capacity, long windowSizeMillis) {this.capacity = capacity;this.windowSizeMillis = windowSizeMillis;}public boolean allow() {long currentTimeMillis = System.currentTimeMillis();// 移除过期的请求记录while (!queue.isEmpty() && currentTimeMillis - queue.peek() > windowSizeMillis) {queue.poll();}// 未超过容量,允许请求并记录时间if (queue.size() < capacity) {queue.offer(currentTimeMillis);return true;}return false;} }
漏桶算法(Leaky Bucket)
- 原理:请求如同水流进入桶中,桶以固定速率处理请求。若桶满则溢出(拒绝请求)。
- 优点:平滑流量,保证输出速率稳定。
- 缺点:无法应对突发流量,即使系统此时有处理能力。
- 示例代码:
public class LeakyBucketRateLimiter {private final int capacity; // 桶容量private final double rate; // 漏水速率(每秒处理请求数)private int water; // 当前水量(请求数)private long lastLeakTimeMillis; // 上次漏水时间public LeakyBucketRateLimiter(int capacity, double rate) {this.capacity = capacity;this.rate = rate;this.water = 0;this.lastLeakTimeMillis = System.currentTimeMillis();}public synchronized boolean allow() {long currentTimeMillis = System.currentTimeMillis();// 计算这段时间漏出的水量long elapsedMillis = currentTimeMillis - lastLeakTimeMillis;double leakedWater = elapsedMillis * rate / 1000.0;water = Math.max(0, (int) (water - leakedWater));lastLeakTimeMillis = currentTimeMillis;// 桶未满,允许请求if (water < capacity) {water++;return true;}return false;} }
令牌桶算法(Token Bucket)
- 原理:系统以固定速率生成令牌放入桶中,每个请求需获取一个令牌才能被处理。桶满时令牌溢出。
- 优点:既能限制平均速率,又能应对突发流量(桶内有令牌时)。
- 缺点:实现较复杂,需维护令牌生成逻辑。
- 示例代码:
import java.util.concurrent.atomic.AtomicLong;public class TokenBucketRateLimiter {private final long capacity; // 桶容量(最大令牌数)private final long rate; // 令牌生成速率(每秒生成令牌数)private AtomicLong tokens; // 当前令牌数private AtomicLong lastRefillTime; // 上次生成令牌时间public TokenBucketRateLimiter(long capacity, long rate) {this.capacity = capacity;this.rate = rate;this.tokens = new AtomicLong(capacity);this.lastRefillTime = new AtomicLong(System.currentTimeMillis());}public boolean allow() {refill(); // 先补充令牌return tokens.getAndUpdate(t -> t - 1) >= 1;}private void refill() {long now = System.currentTimeMillis();long lastTime = lastRefillTime.get();// 计算这段时间应生成的令牌数long generatedTokens = (now - lastTime) * rate / 1000;if (generatedTokens > 0) {// 使用CAS确保线程安全long newTokens = Math.min(capacity, tokens.get() + generatedTokens);if (tokens.compareAndSet(tokens.get(), newTokens)) {lastRefillTime.set(now);}}} }
使用示例
public class RateLimiterExample {public static void main(String[] args) throws InterruptedException {// 固定窗口:每秒允许10个请求FixedWindowRateLimiter fixedWindow = new FixedWindowRateLimiter(10, 1000);// 令牌桶:每秒生成5个令牌,桶容量10TokenBucketRateLimiter tokenBucket = new TokenBucketRateLimiter(10, 5);// 测试固定窗口System.out.println("=== 固定窗口测试 ===");for (int i = 0; i < 20; i++) {System.out.println("Request " + i + ": " + fixedWindow.allow());Thread.sleep(100); // 每100ms发送一个请求}// 测试令牌桶System.out.println("\n=== 令牌桶测试 ===");for (int i = 0; i < 20; i++) {System.out.println("Request " + i + ": " + tokenBucket.allow());Thread.sleep(100);}}
}令牌桶与漏桶的对比
| 特性 | 令牌桶算法 | 漏桶算法 |
|---|---|---|
| 突发流量 | 允许(桶内有令牌时) | 不允许(严格固定速率) |
| 输出速率 | 可变(取决于令牌生成和消耗) | 固定(漏出速率恒定) |
| 实现复杂度 | 较高(需维护令牌生成) | 较低(只需记录水量) |
| 适用场景 | 允许突发但平均速率受控的场景 | 需要严格平滑流量的场景 |
分布式限流实现
在分布式系统中,限流通常需要基于中心化存储(如 Redis)实现:
- 基于 Redis 的令牌桶:
import redis.clients.jedis.Jedis;public class DistributedTokenBucket {private final Jedis jedis;private final String key;private final long capacity;private final long rate;public DistributedTokenBucket(Jedis jedis, String key, long capacity, long rate) {this.jedis = jedis;this.key = key;this.capacity = capacity;this.rate = rate;}public boolean allow() {// Lua脚本实现原子操作String luaScript = "local tokens_key = KEYS[1] " +"local timestamp_key = KEYS[2] " +"local capacity = tonumber(ARGV[1]) " +"local rate = tonumber(ARGV[2]) " +"local now = tonumber(ARGV[3]) " +"local last_tokens = tonumber(redis.call('get', tokens_key) or capacity) " +"local last_refreshed = tonumber(redis.call('get', timestamp_key) or 0) " +"local delta = math.max(0, now - last_refreshed) " +"local filled_tokens = math.min(capacity, last_tokens + (delta * rate / 1000)) " +"local allowed = filled_tokens >= 1 " +"local new_tokens = filled_tokens " +"if allowed then " +" new_tokens = filled_tokens - 1 " +"end " +"redis.call('set', tokens_key, new_tokens) " +"redis.call('set', timestamp_key, now) " +"return allowed";return (Long) jedis.eval(luaScript, 2, key + ":tokens", key + ":timestamp", String.valueOf(capacity), String.valueOf(rate), String.valueOf(System.currentTimeMillis())) == 1;} }
限流框架推荐
- Sentinel:阿里巴巴开源,支持流量控制、熔断降级,集成 Spring Cloud。(生产环境推荐)
- 使用 Sentinel:
// 引入依赖 <dependency><groupId>com.alibaba.csp</groupId><artifactId>sentinel-core</artifactId><version>1.8.6</version> </dependency>// 示例代码 public class SentinelExample {public static void main(String[] args) {// 定义资源Entry entry = null;try {// 限流规则:每秒最多20个请求initFlowRules();// 获取资源入口entry = SphU.entry("resourceName");// 执行业务逻辑System.out.println("Processing request...");} catch (BlockException e) {// 被限流时的处理System.out.println("Request blocked by Sentinel");} finally {if (entry != null) {entry.exit();}}}private static void initFlowRules() {List<FlowRule> rules = new ArrayList<>();FlowRule rule = new FlowRule();rule.setResource("resourceName");rule.setCount(20); // 限流阈值rule.setGrade(RuleConstant.FLOW_GRADE_QPS); // QPS模式rules.add(rule);FlowRuleManager.loadRules(rules);} } - Resilience4j:轻量级 Java 库,支持限流、熔断、重试等。
- Guava RateLimiter:Google Guava 提供的本地...
- Redis + Lua:自定义分布式限流,通过 Lua 脚本保证原子...
根据业务场景选择合适的限流算法:
- 固定窗口:简单但临界问题明显。
- 滑动窗口:解决临界问题,适合平滑限流。
- 漏桶:严格控制速率,适合需要稳定输出的场景。
- 令牌桶:允许突发流量,适合大多数场景。
| 算法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 固定窗口 | 实现简单 | 临界问题明显 | 对精度要求不高的场景 |
| 滑动窗口 | 解决临界问题 | 实现复杂 | 需要更精确限流的场景 |
| 漏桶 | 严格平滑流量 | 无法应对突发流量 | 需要稳定输出速率的场景 |
| 令牌桶 | 允许突发流量 | 实现复杂 | 大多数场景,尤其是有突发流量 |
| 分布式限流 | 跨节点统一限流 | 依赖外部存储 | 微服务架构下的全局限流 |
评估算法特性
1. 性能指标
| 算法 | 时间复杂度 | 空间复杂度 | 突发流量支持 | 实现难度 |
|---|---|---|---|---|
| 固定窗口 | O(1) | O(1) | 差(临界问题) | 低 |
| 滑动窗口 | O(n) | O(n) | 中 | 中 |
| 漏桶 | O(1) | O(1) | 不支持 | 低 |
| 令牌桶 | O(1) | O(1) | 支持 | 中 |
2. 关键特性对比
| 需求 | 推荐算法 |
|---|---|
| 简单实现 | 固定窗口、本地令牌桶 |
| 严格速率控制 | 漏桶 |
| 突发流量处理 | 令牌桶、滑动窗口 |
| 分布式场景 | Redis + 令牌桶 / Lua 脚本 |
| 熔断降级一体化 | Sentinel、Resilience4j |
限流实现方式:
①Tomcat:可以设置最大连接数(maxThreads) 单机
②Nginx 漏桶算法
控制速率(突发容量),让请求以固定速率处理请求,可以应对突发容量。
控制并发数,限制单个 IP和链接数并发链接总数。
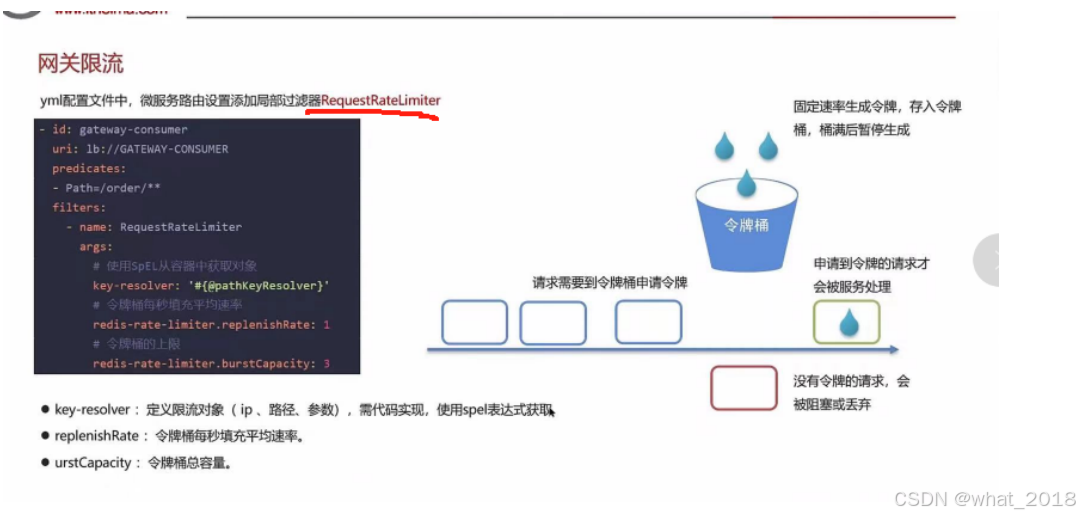
③网关令牌桶算法
在springCloud gateway中支持局部过滤器RequestRateLimiter来做限流,可以根据ip或者路径进行限流,可以设置每秒填充的平均速率和令牌的总容量。
④自定义拦截器
计数器 (固定窗口、滑动窗口)
漏桶:固定速率漏出请求,多余请求等待或者抛出。
令牌桶:固定速率生成令牌,存入令牌桶,桶满后暂停生成。请求需要到令牌桶申请到令牌,才能被服务处理。
Ngixn 控制速率/控制并发连接数


网关令牌桶限流
分布式一致性算法
常见算法
1. Paxos 算法
- 核心思想:通过多轮投票达成共识,分为提案(Prepare)和接受(Accept)两个阶段。
- 角色:提议者(Proposer)、接受者(Acceptor)、学习者(Learner)。
- 流程:
- Prepare 阶段:Proposer 发送提案编号给 Acceptors。
- Accept 阶段:若多数 Acceptors 响应,Proposer 发送值给 Acceptors。
- Learn 阶段:多数 Acceptors 接受后,值被确认。
- 优点:理论完备,被广泛研究。
- 缺点:实现复杂,难以理解。
2. Raft 算法
- 核心思想:通过选举 leader 简化共识过程,leader 负责日志复制。
- 角色:Leader、Follower、Candidate( 英/ˈkændɪdət/候选人)。
- 流程:
- Leader 选举:超时未收到心跳的 Follower 变为 Candidate,发起选举。
- 日志复制:Leader 接收客户端请求,复制日志到 Follower。
- 安全机制:通过任期(Term)和日志匹配原则保证安全性。
- 优点:易于理解,实现简单。
- 缺点:不适合拜占庭故障场景。
3. ZAB 协议(ZooKeeper Atomic Broadcast)
- 核心思想:ZooKeeper 使用的原子广播协议,类似 Raft 但更注重事务顺序。
- 角色:Leader、Follower、Observer。
- 流程:
- 崩溃恢复:选举新 Leader,同步最新事务。
- 消息广播:Leader 接收事务,生成 ZXID,广播给 Follower。
- 应用:ZooKeeper 分布式协调服务。
4. Paxos 变体(Multi-Paxos、Fast Paxos)
- Multi-Paxos:优化 Paxos,减少通信开销,常用于分布式数据库(如 Spanner)。
- Fast Paxos:允许在某些情况下跳过 Prepare 阶段,提高性能。
5. 拜占庭容错算法(PBFT、PoW)
- PBFT(Practical Byzantine Fault Tolerance):
- 在存在恶意节点(最多 1/3 故障)的情况下达成共识。
- 流程:预准备(Pre-Prepare)、准备(Prepare)、提交(Commit)。
- PoW(Proof of Work):
- 比特币使用的共识机制,通过算力竞争达成共识。
- 优点:抗攻击能力强;缺点:能耗高、效率低。
应用场景与实践
1. 分布式协调服务
- ZooKeeper:基于 ZAB 协议,用于服务注册发现、配置管理。
- etcd:基于 Raft 协议,用于 Kubernetes 的核心数据存储。
2. 分布式数据库
- Spanner:Google 的全球分布式数据库,使用 Multi-Paxos。
- CockroachDB:开源分布式 SQL 数据库,使用 Raft。
3. 区块链
- 比特币:基于 PoW 共识,处理拜占庭故障。
- 联盟链:如 Hyperledger Fabric,使用 PBFT 或 Raft。
选择建议
-
非拜占庭故障场景:
- 优先选择 Raft(实现简单)或 ZAB(适合顺序事务)。
- 案例:etcd、Consul、ZooKeeper。
-
拜占庭故障场景:
- 低性能需求:PoW(比特币)。
- 高性能需求:PBFT 及其变体(如 Hyperledger Fabric)。
-
性能敏感场景:
- 使用 Fast Paxos 或优化的 Raft 实现。
常见误区与挑战
-
过度设计:
- 简单场景无需复杂算法,如单机系统使用本地锁即可。
-
忽略网络分区:
- 在分区时需权衡可用性和一致性(如 MongoDB 的 write concern 设置)。
-
性能与一致性的权衡:
- 强一致性(如 Paxos)可能导致延迟增加,需根据业务调整。
总结
分布式一致性算法是构建可靠分布式系统的基石,选择时需考虑:
- 故障类型:非拜占庭(如服务器崩溃)或拜占庭(如恶意攻击)。
- 性能需求:吞吐量和延迟要求。
- 实现复杂度:团队技术栈和维护成本。
优先使用成熟框架(如 etcd、ZooKeeper),避免自行实现底层算法。在实践中,需通过压测和故障注入测试验证算法的可靠性。
算法对比
| 算法 | 容错类型 | 复杂度 | 性能 | 应用场景 |
|---|---|---|---|---|
| Paxos | 非拜占庭故障 | 高 | 中 | 理论研究、分布式数据库 |
| Raft | 非拜占庭故障 | 低 | 中 | 分布式协调(etcd、Consul) |
| ZAB | 非拜占庭故障 | 中 | 高 | ZooKeeper |
| PBFT | 拜占庭故障 | 高 | 中 | 联盟链(Hyperledger) |
| PoW | 拜占庭故障 | 低 | 低 | 公有链(比特币、以太坊) |
非拜占庭故障(也称良性故障)指节点故障后表现出可预测、非恶意的行为。这类故障通常是由于硬件故障、软件崩溃、网络中断等原因导致,节点不会故意发送错误信息或破坏系统一致性。
非拜占庭故障(也称良性故障)指节点故障后表现出可预测、非恶意的行为。这类故障通常是由于硬件故障、软件崩溃、网络中断等原因导致,节点不会故意发送错误信息或破坏系统一致性。
Zookeeper
ZooKeeper 是 Apache 开源的分布式协调服务,为分布式系统提供统一命名服务、配置管理、集群协调、分布式锁等核心功能。以下是关于 ZooKeeper 的详细介绍:
数据结构
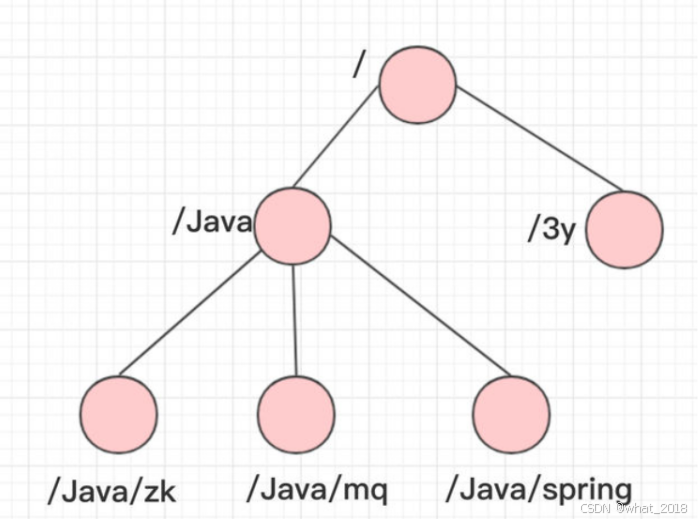
跟Unix文件系统非常类似,可以看做是一颗树,每个节点叫做ZNode(节点的存放数据上限为1M)。每一个节点可以通过路径来标识,结构图如下:
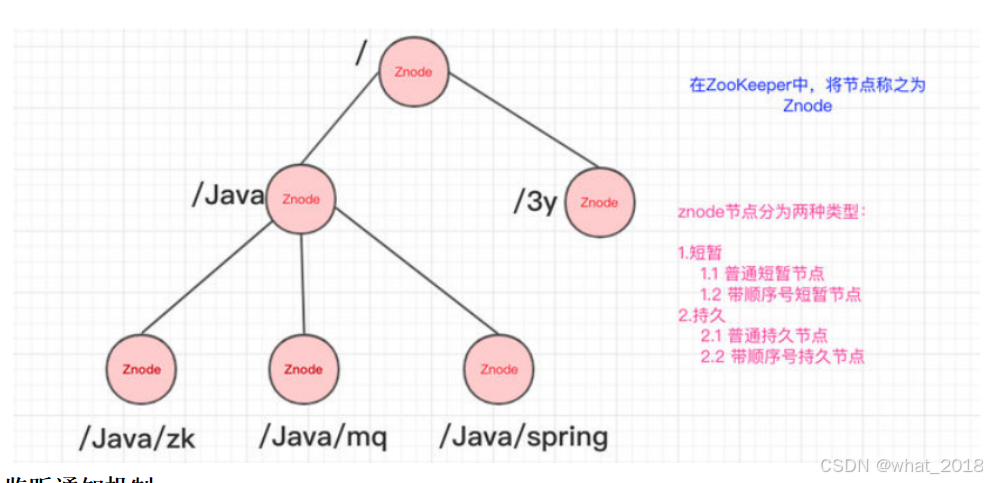
临时(Ephemeral):当客户端和服务端断开连接后,所创建的Znode(节点)会自动删除
持久(Persistent):当客户端和服务端断开连接后,所创建的Znode(节点)不会删除
ZooKeeper和Redis一样,也是C/S结构(分成客户端和服务端)
临时有序、持久有序
监听通知机制
Zookeeper 上创建的节点,可以对这些节点绑定监听事件,比如可以监听节点数据变更、节点删除、子节点状态变更等事件,通过这个事件机制,可以基于 Zookeeper 实现分布式锁、集群管理等功能。
特点
- 集中存储
将所有服务的配置信息(如数据库连接串、参数阈值)存储在 ZooKeeper 的 Znode 中,形成统一的配置中心。 - 实时更新
通过 Watcher 机制,当配置变更时,所有订阅该配置的客户端会立即收到通知,并获取最新值。 - 版本控制
每个 Znode 的元数据包含version字段,配置更新时版本号自动递增,支持回滚和审计。 - 高可用性
集群模式下,Leader 节点处理写请求,Follower 节点提供读服务,确保配置始终可访问。
从设计模式角度来看,zk是一个基于观察者设计模式的框架,它负责管理跟存储大家都关心的数据,然后接受观察者的注册,数据发现生变化zk会通知在zk上注册的观察者做出反应。
典型场景
- 微服务配置:如 Spring Cloud 应用通过 ZooKeeper 获取数据库连接池参数。
- 分布式系统参数调优:如 Kafka 集群的
replication.factor参数动态调整。 - 灰度发布:通过配置中心控制新功能的开关,实现流量灰度。
ZooKeeper 树的核心价值
这棵 “树” 通过 层级结构 组织数据,通过 节点类型 适配不同业务场景,通过 Watcher 实现事件驱动,通过 ZAB 协议 保障一致性,最终成为分布式系统中 协调与元数据管理 的基础设施。理解其节点特性和设计逻辑,是掌握 ZooKeeper 分布式锁、配置中心、Leader 选举等核心功能的关键。
Znode 按 生命周期 和 顺序性 分为 4 种类型,每种类型对应不同的业务场景:
| 节点类型 | 特点 | 典型用途 |
|---|---|---|
| 持久节点(Persistent) | 节点创建后一直存在,直到主动删除(与客户端会话无关)。 | 存储固定配置(如 /config/server1)。 |
| 持久顺序节点(Persistent_Sequential) | 在持久节点基础上,名称自动附加递增序号(如 worker- → worker-0000000001)。 | 分布式锁序号生成、任务队列分配。 |
| 临时节点(Ephemeral) | 节点与会话绑定,会话结束后自动删除(不能有子节点)。 | 服务健康检查(如 /services/server1 存活状态)。 |
| 临时顺序节点(Ephemeral_Sequential) | 在临时节点基础上,名称自动附加递增序号。 | 公平锁竞争(如多个客户端竞争锁时按序号排序)。 |
数据与元数据的强关联性
每个 Znode 包含 数据内容(Data) 和 元数据(Metadata),元数据记录节点的关键信息:
- 数据内容
存储少量业务数据(如配置参数、锁状态),通过getData接口读取,通过setData接口更新。 - 元数据字段
czxid:创建节点的事务 ID(ZXID,全局唯一)。mzxid:最后一次修改节点的事务 ID。ctime:节点创建时间(毫秒级时间戳)。mtime:节点最后一次修改时间。version:数据版本号(每次修改自增,用于乐观锁控制)。cversion:子节点版本号(子节点增删时自增)。aclVersion:权限版本号(ACL 变更时自增)。ephemeralOwner:若为临时节点,记录创建该节点的会话 ID;否则为0。
Watcher 机制:事件驱动的响应式模型
- 监听节点变化
客户端可通过exists/getData/getChildren接口为节点注册 Watcher(监听器),监听以下事件:- 节点创建(
NodeCreated) - 节点删除(
NodeDeleted) - 节点数据更新(
NodeDataChanged) - 子节点变更(
NodeChildrenChanged)
- 节点创建(
- 一次性触发特性
Watcher 事件触发后自动失效,需重新注册才能继续监听(避免持续占用资源)。 - 典型应用
动态感知配置变更(如配置中心)、服务上下线通知(如服务注册发现)。
一致性与顺序性保证
- 线性一致性(Linearizability)
写操作由 Leader 节点通过 ZAB 协议 广播到多数派节点,确保所有节点数据一致。 - 全局有序性
所有事务(写操作)通过 ZXID 全局唯一编号,保证按顺序执行,读操作可选择从 Leader 节点获取最新数据(默认从 Follower 节点读取,可能存在毫秒级延迟)。
核心功能
-
配置管理
- 集中存储分布式系统的配置信息,支持动态更新(如 Kafka 的 broker 配置)。
-
命名服务
- 提供分布式命名空间,类似文件系统目录结构(如服务注册发现中的服务路径)。
-
集群协调
- Leader 选举(如 Hadoop YARN ResourceManager 的主备切换)。
- 状态同步(如分布式任务的全局状态)。
-
分布式锁
- 实现公平锁、读写锁(如 HBase 的分布式锁机制)。
-
健康检查
- 通过临时节点(Ephemeral Node)监控服务存活状态(如 Dubbo 的服务注册发现)。
统一配置管理
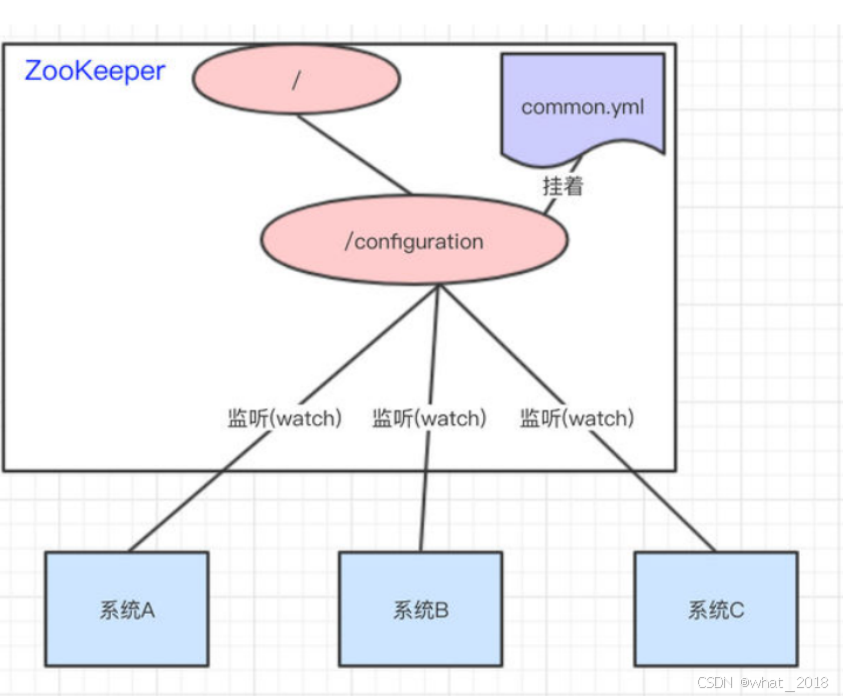
比如我们现在有三个系统A、B、C,他们有三份配置,分别是ASystem.yml、BSystem.yml、CSystem.yml,然后,这三份配置又非常类似,很多的配置项几乎都一样。
此时,如果我们要改变其中一份配置项的信息,很可能其他两份都要改。并且,改变了配置项的信息很可能就要重启系统
于是,我们希望把ASystem.yml、BSystem.yml、CSystem.yml相同的配置项抽取出来成一份公用的配置common.yml,并且即便common.yml改了,也不需要系统A、B、C重启。
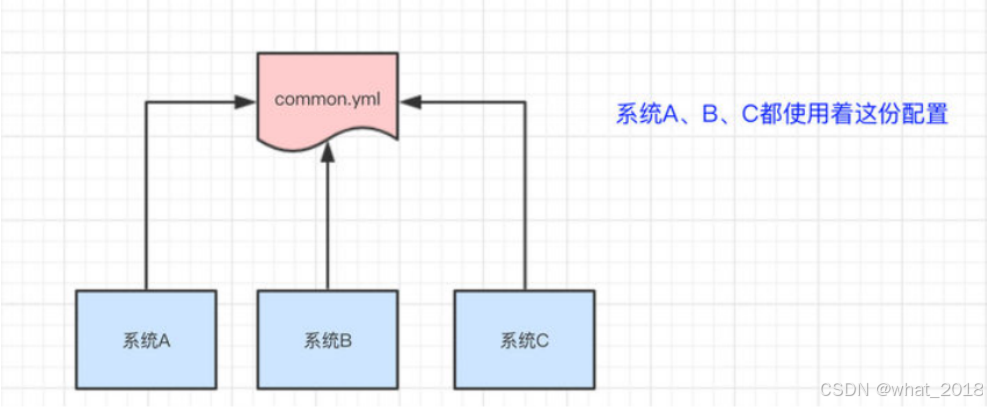
做法:我们可以将common.yml这份配置放在ZooKeeper的Znode节点中,系统A、B、C监听着这个Znode节点有无变更,如果变更了,及时响应。
命名服务
命名服务是指通过指定的名字来获取资源或者服务的地址,利用 zk 创建一个全局唯一的路径,这个路径就可以作为一个名字,指向集群中的集群,提供的服务的地址,或者一个远程的对象等等。
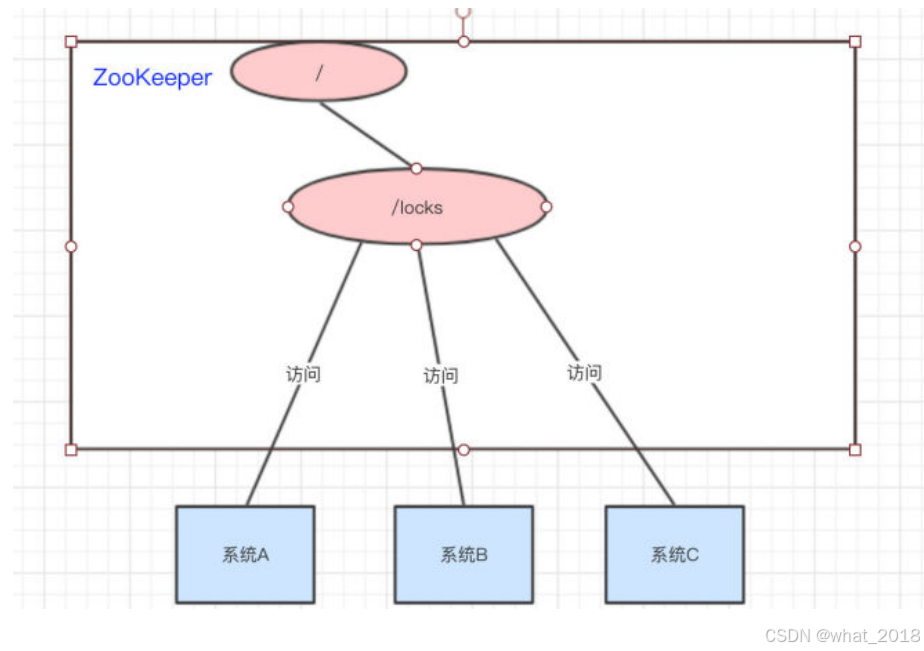
分布式锁
锁的概念在这我就不说了,如果对锁概念还不太了解的同学,可参考下面的文章
我们可以使用ZooKeeper来实现分布式锁,那是怎么做的呢??下面来看看:
访问的时候会创建带顺序号的临时(EPHEMERAL_SEQUENTIAL)节点,比如,系统A创建了id_000000节点,系统B创建了id_000002节点,系统C创建了id_000001节点。
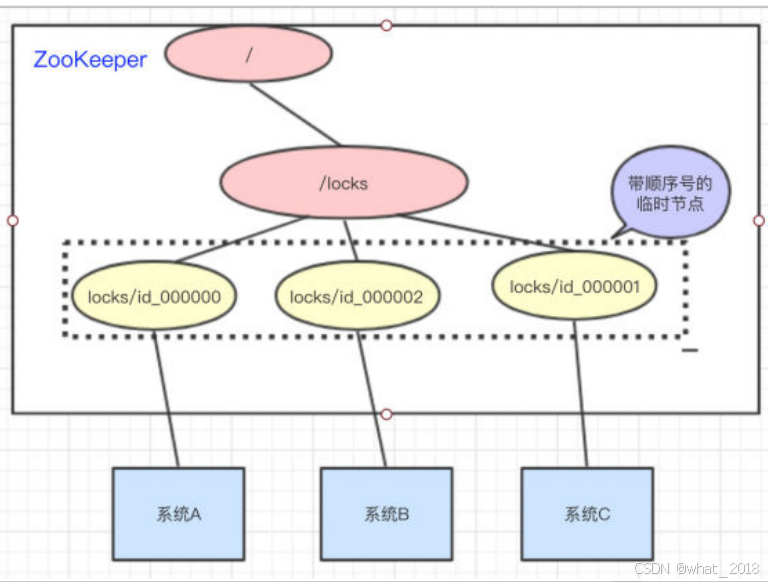
接着,拿到/locks节点下的所有子节点(id_000000,id_000001,id_000002),判断自己创建的是不是最小的那个节点
如果是,则拿到锁。
释放锁:执行完操作后,把创建的节点给删掉
如果不是,则监听比自己要小1的节点变化
举个例子:
- A拿到/locks节点下的所有子节点,经过比较,发现自己(id_000000),是所有子节点最小的。所以得到锁
- B拿到/locks节点下的所有子节点,经过比较,发现自己(id_000002),不是所有子节点最小的。所以监听比自己小1的节点id_000001的状态
- C拿到/locks节点下的所有子节点,经过比较,发现自己(id_000001),不是所有子节点最小的。所以监听比自己小1的节点id_000000的状态
- A执行完操作以后,将自己创建的节点删除(id_000000)。通过监听,系统C发现id_000000节点已经删除了,发现自己已经是最小的节点了,于是顺利拿到锁
- 系统B如上
公平竞争与有序执行
核心特点
- 基于临时顺序节点
- 客户端在锁路径(如
/locks/distributed-lock)下创建 临时顺序节点。 - 通过比较节点序号,最小序号的节点获得锁,其余节点监听前一个节点的删除事件。
- 客户端在锁路径(如
- 公平性保证
节点序号严格递增,先创建的节点优先获得锁,避免 “惊群效应”。 - 异常自动释放
若持有锁的客户端崩溃,其临时节点自动删除,下一个节点自动获得锁。 - 可重入锁支持
通过记录客户端 ID 和加锁次数,支持同一客户端在锁未释放时重复加锁。
典型场景
- 分布式资源竞争:如多个任务同时操作 HBase 表,需通过锁保证互斥。
- 全局唯一性约束:如生成全局唯一订单号,确保同一时刻只有一个节点生成 ID。
- 批量任务调度:如定时任务在集群中仅需一个节点执行。
底层技术支撑
| 应用场景 | 依赖的 ZooKeeper 特性 |
|---|---|
| 配置管理 | 1. 持久节点存储配置数据 2. Watcher 监听数据变更 3. 版本控制保证变更可追溯 |
| 命名服务 | 1. 临时节点自动删除机制(健康检查) 2. 顺序节点保证服务列表有序 3. 集群高可用确保服务地址始终可访问 |
| 分布式锁 | 1. 临时顺序节点实现公平竞争 2. Watcher 监听锁释放事件 3. ZAB 协议保证操作原子性 |
集群管理
所谓集群管理无在乎两点:是否有机器退出和加入、选举master。
我们三个系统A、B、C为例,在ZooKeeper中创建临时节点即可:
只要系统A挂了,那/groupMember/A这个节点就会删除,通过监听groupMember下的子节点,系统B和C就能够感知到系统A已经挂了。(新增也是同理)
除了能够感知节点的上下线变化,ZooKeeper还可以实现动态选举Master的功能。(如果集群是主从架构模式下)
原理也很简单,如果想要实现动态选举Master的功能,Znode节点的类型是带顺序号的临时节点(EPHEMERAL_SEQUENTIAL)就好了。
Zookeeper会每次选举最小编号的作为Master,如果Master挂了,自然对应的Znode节点就会删除。然后让新的最小编号作为Master,这样就可以实现动态选举的功能了。
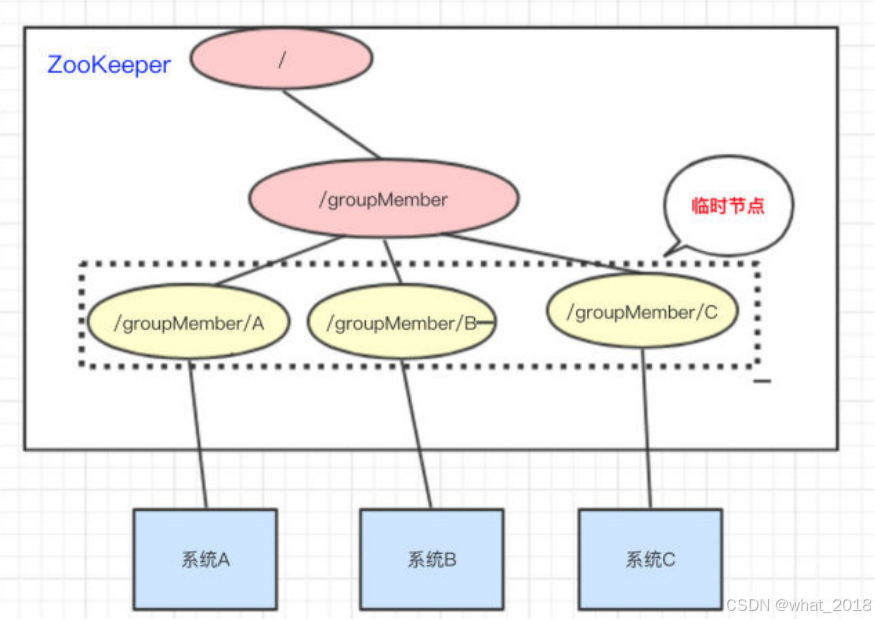
1、leader(主节点) ,不是固定的,启动后根据选举算法选出
https://zhuanlan.zhihu.com/p/62526102
架构设计
-
集群模式
- Quorum:由奇数个节点组成(如 3、5、7),确保多数派(Quorum)可用。
- 角色:
- Leader:处理写请求,执行原子广播(ZAB 协议)。
- Follower:接收客户端读请求,参与选举和提案投票。
- Observer:扩展读性能,不参与选举(可选角色)。
-
数据模型
- ZNode:类似文件系统的节点,存储少量数据(默认≤1MB)。
- 类型:
- 持久节点(Persistent):手动删除才会消失。
- 临时节点(Ephemeral):会话结束自动删除(用于健康检查)。
- 顺序节点(Sequential):创建时自动附加递增序号(用于分布式锁)。
-
ZAB 协议(ZooKeeper Atomic Broadcast)
- 原子广播:确保事务按顺序在集群中执行。
- 崩溃恢复:Leader 故障时,快速选举新 Leader 并同步数据。
典型应用场景
-
服务注册与发现
- 服务提供者将地址注册到 ZooKeeper(如 Dubbo、Spring Cloud Zookeeper)。
- 服务消费者订阅节点变化,动态感知提供者上线 / 下线。
-
分布式锁
- 实现方式:
// 创建临时顺序节点 String lockPath = zk.create("/locks/lock-", CreateMode.EPHEMERAL_SEQUENTIAL); // 获取最小序号节点,判断是否获得锁 List<String> children = zk.getChildren("/locks", false); if (lockPath.equals("/locks/" + Collections.min(children))) {// 获得锁 } else {// 监听前一个节点zk.exists(previousNode, true); }
- 实现方式:
-
配置中心
- 应用启动时从 ZooKeeper 加载配置,监听配置变更事件。
- 如 Kafka 的 broker 配置、HBase 的集群参数。
-
主备切换
- 通过临时节点实现主节点选举(如 Hadoop YARN 的 ResourceManager 高可用)。
关键技术细节
-
会话(Session)
- 客户端与 ZooKeeper 建立的 TCP 连接,超时自动失效。
- 临时节点与会话绑定,会话结束时自动删除。
-
Watcher 机制
- 客户端可监听 ZNode 变化(创建、删除、数据更新)。
- 事件触发后,Watcher 自动失效,需重新注册(一次性触发)。
-
ZXID(ZooKeeper Transaction ID)
- 全局唯一事务 ID,确保事务顺序(如
0x100000001)。 - Leader 生成 ZXID,保证递增性和原子性。
- 全局唯一事务 ID,确保事务顺序(如
-
一致性保证
- 线性一致性(Linearizability):写操作通过 Leader 广播,读操作可配置是否从 Leader 获取(确保最新数据)。
优缺点
| 优点 | 缺点 |
|---|---|
| 高可用性(集群模式) | 不适合存储大量数据(ZNode≤1MB) |
| 强一致性(ZAB 协议) | 写性能随节点数增加而下降 |
| 丰富的 Watcher 机制 | 客户端 API 较底层,使用复杂 |
| 社区活跃,广泛集成(Hadoop、Kafka 等) | 配置不当易导致脑裂(Split-Brain) |
最佳实践
-
集群规模
- 推荐奇数节点(3、5、7),容忍
(N-1)/2节点故障(如 5 节点容忍 2 节点故障)。
- 推荐奇数节点(3、5、7),容忍
-
配置优化
tickTime:基本时间单位(默认 2000ms),影响会话超时和选举周期。initLimit:Follower 与 Leader 同步的最大时间(initLimit * tickTime)。syncLimit:Follower 与 Leader 通信的最大延迟。
-
避免脑裂
- 配置
electionAlg=3(默认),使用 TCP 选举协议。 - 确保多数派(Quorum)可用。
- 配置
-
监控与告警
- 监控
zkServer.sh status输出,检查集群健康状态。 - 告警指标:连接数、请求延迟、Leader 变更频率。
- 监控
替代方案
-
etcd
- 基于 Raft 协议,API 更友好,性能更高(尤其写操作)。
- 适用于 Kubernetes(默认存储组件)、服务发现(如 Consul)。
-
Consul
- 提供服务发现、健康检查、KV 存储一体化解决方案。
- 支持多数据中心,分布式锁实现更简单。
-
Nacos
- 阿里巴巴开源,支持动态配置管理、服务注册发现。
- 更适合微服务架构,中文文档完善。
总结
ZooKeeper 是分布式系统的 “协调基石”,尤其适合需要强一致性、高可用的场景(如分布式锁、配置中心)。但由于其 API 较底层,维护成本较高,在轻量级场景中可考虑 etcd 或 Consul。在使用时需注意集群规模、配置参数调优,避免单点故障和脑裂问题。
定义:简单的说zookepper=文件系统+监听通知机制
是一个分布式协调服务,CP为了分布式应用提供了一致性服务的软件,
可以基于它实现统一配置管理、命名服务、分布式锁、集群管理、负载均衡、分布式队列、Master 选举等。
场景:
配置管理 【数据发布与订阅配置中心】
数据发布到zk节点上,供订阅者动态获取数据,
实时更新watch机制。比如全局配置信息、地址列表。K-V结构。
命名服务: 通过名字获取服务资源或者服务地址。
集群管理 :是否有机器退出和加入、选举mater。
分布式锁: 临时有序节点 ,监听器
【临时zk 死掉会释放锁,有序 就是先获取最小的,然后依次执行】
持久化/临时目录 -->有序
客户端注册监听它关心的目录节点,当目录节点发生变化(数据改变、被删除、子目录节点增加删除)时,zookeeper会通知客户端。
使用分布式系统就无法避免对节点管理的问题(需要实时感知节点的状态、对节点 进行统一管理等等),而由于这些问题处理起来可能相对麻烦和提高了系统的复杂性,ZooKeeper作为一个能够通用解决这些问题的中间件就应运而生了
ZK 通常指 ZooKeeper,是一个分布式协调服务,在分布式系统中起着关键作用。
从架构上看,ZooKeeper 由服务器集群组成,集群中的节点分为领导者(Leader)、跟随者(Follower)和观察者(Observer)。Leader 负责处理事务请求,比如写操作,同时管理整个集群的状态变化。Follower 用于处理客户端的读请求,并与 Leader 保持数据同步,还参与领导者选举。Observer 可以接收客户端的读请求,能提高集群的读性能,其数据也从 Leader 同步,但不参与选举过程。
在数据存储方面,ZooKeeper 使用类似文件系统的树形数据结构,其中的每个节点称为 znode。znode 可以存储数据,数据格式一般是字节数组,并且每个 znode 都有一个唯一的路径来标识。znode 有多种类型,包括持久节点、临时节点和顺序节点。持久节点在创建后会一直存在,除非被显式删除;临时节点在创建它的客户端会话结束时自动删除,可用于实现分布式锁等功能;顺序节点在创建时会在节点名后加上一个递增的数字,常被用于实现分布式队列等功能。
ZooKeeper 有重要的应用场景。在分布式锁的应用中,通过在 ZooKeeper 上创建临时顺序节点,多个客户端竞争锁时,只有序号最小的节点对应的客户端获得锁,使用完后删除节点释放锁。
在配置管理上,系统的配置信息可以集中存储在 ZooKeeper 的 znode 中,客户端可以对配置节点进行监听,当配置发生改变时,ZooKeeper 会通知客户端,实现配置的动态更新。
对于服务发现,服务提供者将自己的服务信息注册到 ZooKeeper 的某个 znode 下,服务消费者通过查询该节点获取服务提供者列表,并且能通过监听机制及时知晓服务提供者的变化。
此外,ZooKeeper 在一些大型分布式系统中有广泛应用。比如在 Hadoop 生态系统中,它被用于协调多个组件之间的资源分配、任务调度和状态管理等。在 Kubernetes 中,也可以用于集群的管理和协调,保障集群的稳定运行。
Dubbo
Dubbo,它是一款高性能、轻量级的开源微服务框架,以下是详细介绍:
待续