<论文>(微软)避免推荐域外物品:基于LLM的受限生成式推荐
一、摘要
本文介绍微软和深圳大学合作发表于2025年5月的论文《Avoid Recommending Out-of-Domain Items: Constrained Generative Recommendation with LLMs》。论文主要研究如何解决大语言模型(LLMs)在推荐系统中推荐域外物品的问题,提出了 RecLM-ret 和 RecLM-cgen 两种方法。

译文:
大语言模型(LLMs)因其在用户交互方面的变革性能力,在生成式推荐系统中展现出了潜力。然而,确保它们不推荐域外(OOD)物品仍然是一个挑战。我们研究了两种不同的方法来解决这个问题:RecLM-ret,一种基于检索的方法;以及RecLM-cgen,一种受限生成方法。这两种方法都能与现有的大语言模型无缝集成,以确保域内推荐。在三个推荐数据集上进行的全面实验表明,RecLM-cgen在消除域外推荐的同时,在准确性上始终优于RecLM-ret和现有的基于大语言模型的推荐模型,使其成为更优的采用方法。此外,RecLM-cgen保持了强大的通用能力,并且是一个轻量级的即插即用模块,便于集成到大型语言模型中,为社区提供了有价值的实际益处。
二、核心创新点
论文的目标是避免推荐域外item,使基于大模型的推荐系统在工业服务中更可靠。从根本上说,有两种范式可以实现这一点:域内检索范式和受限生成范式。作者设计了一个简单的框架,只需要对backbone大模型进行小幅度的修改就能够适配这两种方法。
1、特殊item指示标记符(special item indicator token)
作者在backbone模型的词汇表中添加了两个特殊的token:<SOI>和<EOI>。这些token分别表示item开始和item结束,即start-of-item和end-of-item。将使用推荐数据集进行微调的大模型称为RecLM,则每当RecLM推荐一个item时,它首先会输出<SOI>标记,随后输出<EOI>标记,例如序列:<SOI>item标题<EOI>。通过利用这两个特殊标记,大模型的生成过程可以分为两个不同的阶段:item生成阶段和通用文本生成阶段。当大模型输出一个<SOI>时,意味着item生成阶段的开始,而输出<EOI>时则意味着item生成阶段结束,模型转换回通用文本生成阶段。在这个框架的基础上,在item生成阶段可以采用域内检索范式(得到RecLM-ret)或者受限生成范式(得到RecLM-cgen),以防止生成预定义域之外的item。
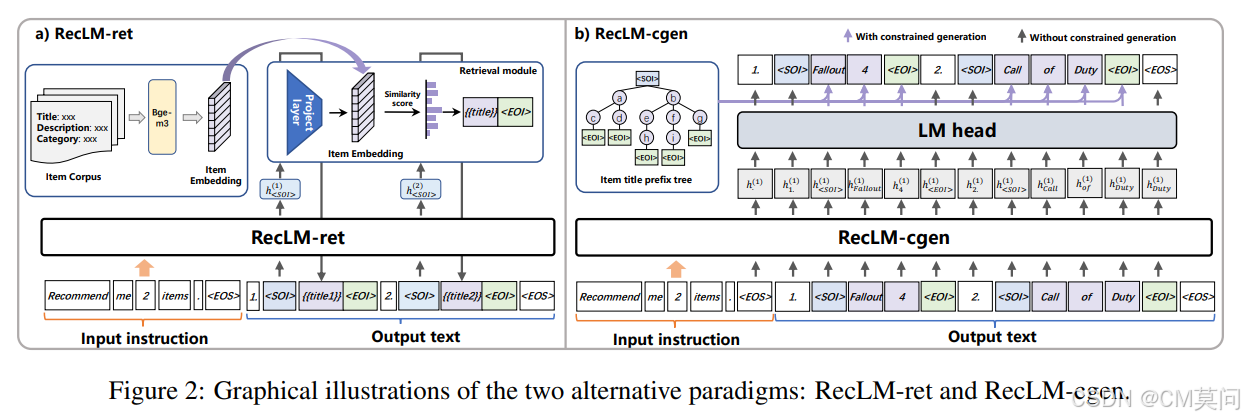
2、RecLM-ret
在这种方法中,作者首先通过将目标域中每个item的标题、描述和类别信息连接起来作为输入文本,在使用bge-m3模型为每个item(记为 i )生成embedding嵌入(记为)。由此,可以得到领域item的基础嵌入
。
接着,当RecLM输出<SOI>标记时,提取与该标记相关联的最后一层隐藏层表示。r然后应用一个投影层将
和与生成的基础嵌入集合
的向量空间对齐。最后根据相似度得分来检索推荐的item,检索到的item标题和结束标记<EOI>将与当前生成的文本连接起来。
训练阶段,作者使用一个prompt模板来将用户行为转化成监督微调数据的样例<Instruction:X, Response:Y>。
包含了用户历史交互的item列表,这将作为Instruction:X中的用户配置信息。
是被推荐给用户的包含k个item的列表,这将作为Response:Y的标签。此外,作者还进行了一定的数据增强。令
表示基线模型的可训练参数,有:
其中,为大模型训练损失,
。接着,作者构造了一个检索任务的损失来训练模型学习如何检索相关的item。首先,获取所有在Response:Y中的k个item的隐藏层向量
,然后将这些向量输入到投影层
,随后,在投影后的向量和所有item的嵌入集合
之间进行相似度匹配。由此损失函数可表示为:
其中,是softmax函数,目的在于在所有
的item中最大化真实item的相似度
。最后,总的训练损失为:
其中,表示权重超参数。
3、RecLM-cgen
在这种方法中,作者使用前缀树约束生成的策略。首先,根据目标域中的所有item标题构建前缀树。在生成阶段,一旦大模型生成<SOI>标记,就激活受限生成,从而将大模型的生成空间限制在领域内item的标题上。在生成<EOI>标记时停用受限生成,从而使得模型能够过渡到常规的通用文本生成阶段。

3.1 作用域掩码训练(Scope Mask Training)
考虑到在前缀树上进行token解码时,模型的下一个token概率并非针对整个token词汇表,而是限制在前缀树中可见的token子集,因此作者在RecLM-cgen的训练过程中引入作用域掩码损失,以保持训练和推理之间的一致性。在计算与item标题相关的token的损失时,softmax函数的分母中仅包含前缀树中的token:
其中,是一个函数,给定一个前缀token序列,它会根据指定的推荐域返回可能的下一个token集合。如果当前的token
在通用的文本部分,例如在<EOI>后面出现,则该函数返回整个token词汇表。如果当前的token
在item标题部分,即出现在<SOI>和<EOI>之间,函数返回基于前缀树的候选token集合。
3.2 多轮对话数据(Multi-round Conversation Data)
作者观察到,如果只包含像<Instruction:X, Response:Y>这样的单轮监督微调样本,模型往往会倾向于给出单轮推荐,这会显著降低模型的通用能力。因此,作者将大约10%的多轮对话数据样本纳入到训练集中。这些样本是通过从ShareGPT语料库中随机选择一个数据样本,并将其与一个单轮推荐任务样本相结合而创建的。推荐任务的样本有50%的概率出现在ShareGPT对话之前,50%的概率出现在其之后。
