【AI论文】MiMo:解锁语言模型的推理潜力——从预训练到后训练
摘要:我们提出了MiMo-7B,这是一个为推理任务而生的语言模型,在预训练和后训练阶段都进行了优化。 在预训练过程中,我们增强了数据预处理管道,并采用了一种三阶段数据混合策略来增强基础模型的推理潜力。 MiMo-7B-Base在25万亿个令牌上进行预训练,并具有额外的多令牌预测目标,以提高性能和加速推理速度。 在训练后,我们为强化学习整理了一个包含13万个可验证数学和编程问题的数据集,整合了一个测试难度驱动的代码奖励方案,以缓解稀疏奖励问题,并采用策略性数据重采样来稳定训练。 广泛的评估表明,MiMo-7B-Base具有卓越的推理潜力,甚至超过了更大的32B模型。 最终的RL调优模型MiMo-7B-RL在数学、代码和一般推理任务上取得了优异的性能,超过了OpenAI o1-mini的性能。 模型检查点可以在 Github 上找到。Huggingface链接:Paper page,论文链接:2505.07608
研究背景和目的
研究背景
近年来,大型语言模型(LLMs)在复杂任务中展现出了卓越的推理能力,如OpenAI的o系列、DeepSeek R1和Claude3.7等模型,在数学推理和代码生成等任务中取得了显著成就。这些模型通过大规模的强化学习(RL)训练,发展出了复杂的推理模式,包括逐步分析、自我反思和回溯等,从而在各种领域中实现了更强大和准确的问题解决能力。然而,目前大多数成功的RL工作,包括开源研究,都依赖于相对较大的基础模型,如32B模型,特别是在增强代码推理能力方面。此外,人们普遍认为,在小模型中同时实现数学和代码能力的均匀和同时提升是具有挑战性的。
尽管如此,研究人员认为,RL训练的推理模型的有效性依赖于基础模型固有的推理潜力。为了充分解锁语言模型的推理潜力,不仅需要在后训练阶段努力,还需要在预训练阶段制定针对推理的策略。然而,现有研究在预训练阶段对推理能力的关注相对较少,主要集中在增加模型规模和复杂度上,而忽视了通过优化预训练策略来提升基础模型的推理潜力。
研究目的
本研究旨在提出MiMo-7B系列模型,这是一个从头开始训练并专为推理任务设计的大型语言模型系列。MiMo-7B通过优化预训练和后训练阶段,旨在充分解锁语言模型的推理潜力。具体而言,本研究的目标包括:
- 优化预训练策略:通过改进数据预处理管道和采用三阶段数据混合策略,增强基础模型MiMo-7B-Base的推理潜力。
- 开发高效的后训练方法:通过整理可验证的数学和编程问题数据集,并引入测试难度驱动的代码奖励方案,解决稀疏奖励问题,并通过策略性数据重采样稳定训练过程。
- 验证模型性能:通过广泛的评估,验证MiMo-7B系列模型在数学、代码和一般推理任务上的卓越性能,特别是与OpenAI o1-mini等先进模型进行比较。
- 开源模型:将MiMo-7B系列模型的检查点开源,供研究社区使用,以促进更强大的推理LLMs的开发。
研究方法
预训练阶段
- 数据预处理:优化自然文本预处理管道,提高质量和推理数据密度。特别开发了针对数学内容和代码块的HTML提取工具,并增强了PDF解析工具包以更好地处理STEM和代码内容。
- 数据混合策略:采用三阶段数据混合策略,第一阶段包含所有数据源(除合成响应外),下采样过度代表的内容,上采样高质量数据;第二阶段增加数学和代码相关数据至约70%;第三阶段进一步加入约10%的数学、代码和创意写作查询的合成响应,并将上下文长度从8,192扩展到32,768。
- 模型架构:采用类似于Llama和Qwen的解码器-仅Transformer架构,并引入多令牌预测(MTP)模块作为额外的训练目标,以提高模型性能和加速推理。
- 超参数设置:设置Transformer层数为36,隐藏维度为4,096,FFN中间隐藏维度为11,008,注意力头数为32,键值组数为8。使用AdamW优化器,并设置梯度裁剪最大范数为1.0。
后训练阶段
- 监督微调(SFT):使用开源和专有蒸馏数据的组合,通过三阶段预处理管道确保数据质量和多样性。SFT数据集包含约500K个样本。
- RL数据整理:整理包含130K个可验证数学和编程问题的数据集,用于强化学习。通过模型评估问题难度,并过滤掉容易的问题。
- RL训练配方:采用改进的组相对策略优化(GRPO)算法,并引入测试难度驱动的代码奖励方案和策略性数据重采样。奖励函数仅基于规则准确性,不包含格式奖励或长度惩罚奖励。
- RL基础设施:开发无缝滚动引擎(Seamless Rollout Engine)以加速RL训练和验证,通过连续滚动、异步奖励计算和早期终止优化GPU利用率。同时,增强vLLM的鲁棒性,以支持MTP模块。
研究结果
预训练结果
MiMo-7B-Base在预训练阶段表现出了卓越的推理潜力。在多个推理基准测试中,MiMo-7B-Base的得分显著高于其他可比规模的基础模型,包括Llama-3.1-8B、Gemma-2-9B和Qwen2.5-7B。特别是在LiveCodeBench和AIME等基准测试中,MiMo-7B-Base展现出了强大的代码和数学推理能力。
后训练结果
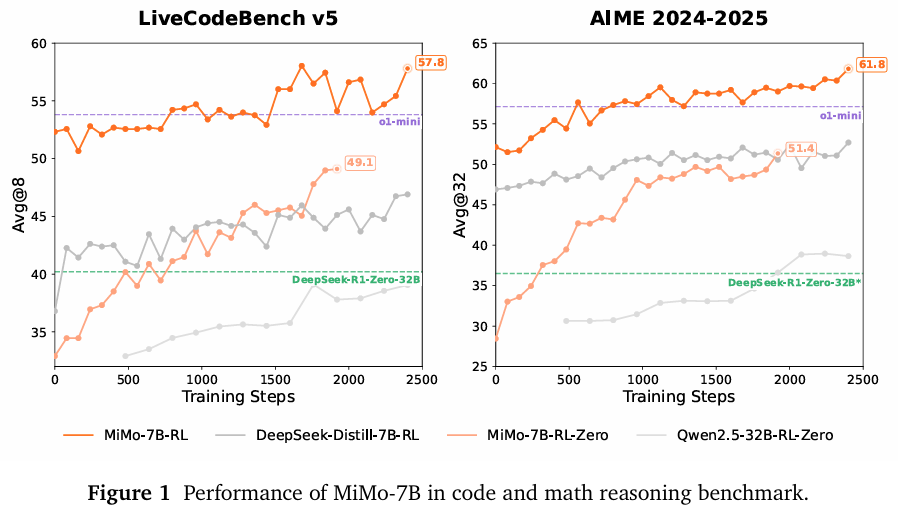
- MiMo-7B-RL-Zero:通过直接从MiMo-7B-Base进行RL训练得到的模型,在数学和代码任务上展现出了优异的性能,超过了32B基础模型的RL训练性能。
- MiMo-7B-RL:从MiMo-7B-SFT进行RL训练得到的模型,在数学、代码和一般推理任务上取得了顶级性能。在AIME 2025基准测试中,MiMo-7B-RL的得分为55.4,超过了OpenAI o1-mini的50.7。在LiveCodeBench v5和v6基准测试中,MiMo-7B-RL也显著优于OpenAI o1-mini。
综合性能
MiMo-7B-RL不仅在数学和代码任务上表现出色,还在一般推理任务中保持了竞争力。这表明MiMo-7B系列模型在多个领域中都具有强大的推理能力。
研究局限
- 数据依赖:尽管本研究在数据预处理和混合策略上进行了大量优化,但模型性能仍然高度依赖于训练数据的质量和多样性。未来研究需要探索更多数据来源和增强方法,以进一步提高模型的泛化能力。
- 计算资源:RL训练过程需要大量的计算资源,特别是在处理大规模数据集和复杂模型时。这限制了研究的可扩展性和可重复性。未来研究可以探索更高效的训练算法和硬件加速技术。
- 模型解释性:尽管MiMo-7B系列模型在推理任务上取得了显著成就,但其决策过程仍然缺乏解释性。未来研究可以探索模型解释性技术,以更好地理解模型的推理机制。
- 领域特定性能:尽管MiMo-7B在多个领域中表现出了强大的推理能力,但在某些特定领域(如生物医学、法律等)的性能可能仍然有限。未来研究可以针对这些领域进行定制化优化。
未来研究方向
- 持续优化预训练策略:探索更多数据增强技术和预训练目标,以进一步提高基础模型的推理潜力。例如,可以研究如何利用自监督学习或对比学习来增强模型的表示能力。
- 开发更高效的RL算法:针对RL训练过程中的稀疏奖励和采样效率问题,开发更高效的RL算法。例如,可以研究如何结合元学习或迁移学习来加速RL训练过程。
- 增强模型解释性:研究模型解释性技术,以更好地理解MiMo-7B系列模型的推理机制。这有助于发现模型的潜在问题,并指导未来的模型改进。
- 探索多模态推理:将MiMo-7B系列模型扩展到多模态领域,如图像、音频等,以探索更复杂的推理任务。这需要研究如何有效地融合不同模态的信息,并设计相应的模型架构和训练策略。
- 定制化领域优化:针对特定领域(如生物医学、法律等)进行定制化优化,以提高模型在这些领域中的性能。这可能需要收集特定领域的数据集,并设计相应的预处理和后训练策略。
- 开源社区合作:继续与开源社区合作,共同推动MiMo-7B系列模型的发展和应用。通过共享模型检查点、数据集和训练代码,促进研究社区的交流和合作。
结论
本研究提出了MiMo-7B系列模型,通过优化预训练和后训练阶段,充分解锁了语言模型的推理潜力。MiMo-7B-Base在预训练阶段展现出了卓越的推理潜力,而MiMo-7B-RL在后训练阶段取得了顶级性能。这些结果表明,通过针对推理的预训练和后训练策略,可以在小模型中实现与大模型相媲美的推理能力。未来研究将继续探索更高效的训练算法、增强模型解释性、探索多模态推理以及定制化领域优化等方向,以推动MiMo-7B系列模型的发展和应用。