计算机组成与体系结构:全相联映射(Fully Associative Mapping)
目录
🧩 从直接映射的弊端说起
🎯 Cache Miss 的三种类型
🔄 关联映射解决了什么问题?
🌐 全相联映射(Fully Associative Mapping)
地址结构(Address Breakdown)
🏗️ 工作原理简述:
优点:
缺点:
举例说明:
♻️ 替换策略
🔍 命中延迟(Hit Latency)
🧩 从直接映射的弊端说起
在缓存(Cache)设计中,直接映射(Direct Mapped Cache)是一种简单的实现方式。它将主存中的每一个块(Block)只能映射到缓存中的某一个固定位置。
比如:
一个主存地址 0x1234 经过地址映射公式后,只能放在缓存的第 i 行,不能放在别的位置。
这种设计虽然实现简单,访问速度快,但是也带来了明显的缺点:
弊端:冲突率高(High Conflict Rate)
即使主存中不同的块频繁被访问,但它们如果映射到缓存的同一个位置,会频繁地发生替换,导致缓存命中率(Cache Hit Rate)大大降低。
🎯 Cache Miss 的三种类型
在这个过程中,我们自然引出了三种常见的 Cache Miss(缓存未命中)类型:
| 英文术语 | 中文翻译 | 简单说明 |
|---|---|---|
| Compulsory Miss (a.k.a Cold Miss) | 冷启动未命中/强制未命中 | 第一次访问数据时,由于缓存中还没有它,无论如何都会未命中。 |
| Conflict Miss | 冲突未命中 | 不同的数据映射到同一个 Cache 行,频繁替换造成未命中。直接映射常见。 |
| Capacity Miss | 容量未命中 | 缓存空间不够大,无法容纳程序运行期间所有活跃数据,即便映射规则很好也会未命中。 |
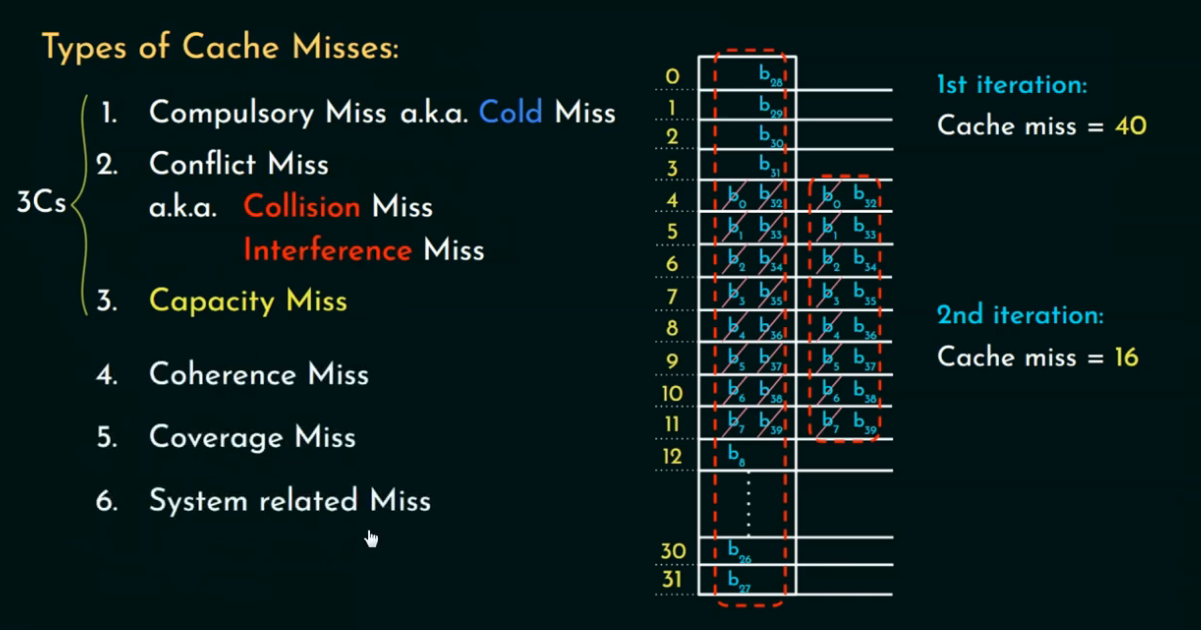
举个例子:
假设你有一个只有 4 行的缓存,每次都要访问 8 个不同的地址,如果使用直接映射,并且这些地址映射到相同的行上,那就会不断地互相替换,导致 冲突未命中。
🔄 关联映射解决了什么问题?
为了解决直接映射中的冲突未命中问题,计算机引入了关联映射策略,也就是 Associative Mapping。
我们今天重点讲解其中最灵活的一种方式——
🌐 全相联映射(Fully Associative Mapping)
定义:
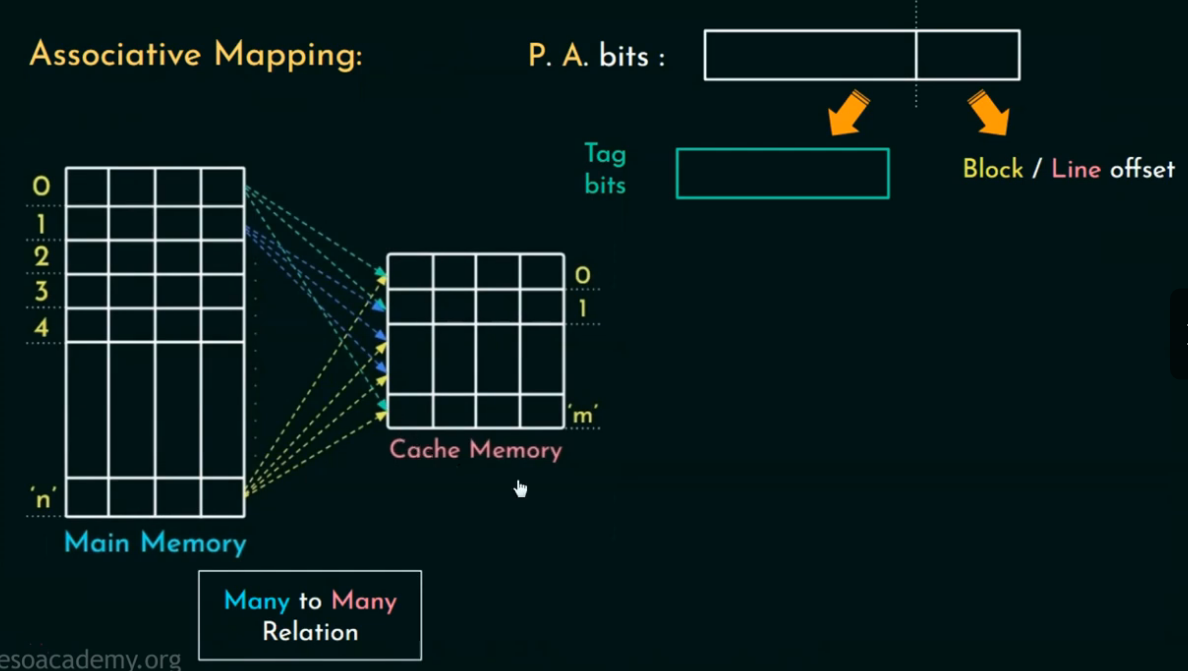
Fully Associative Mapping 全相联映射 指的是:主存中的任何一个块都可以存储在缓存的任何一行,缓存中的任何一行都可以存放任何主存块。
因此,不需要通过地址中的一部分(如 Line Number 或 Index)来选择一个特定的缓存行。
地址结构(Address Breakdown)
主存地址(memory address)被分为两个部分:
-
Tag(标记):用于与缓存中每行的 Tag 进行匹配,判断是否命中。
-
Block Offset(块内偏移):定位该块内的字节。
地址格式举例:假设主存地址为 32 bits,缓存块大小为 64 Bytes(即 2⁶),那么:
-
低6位 = Block Offset
-
高26位 = Tag
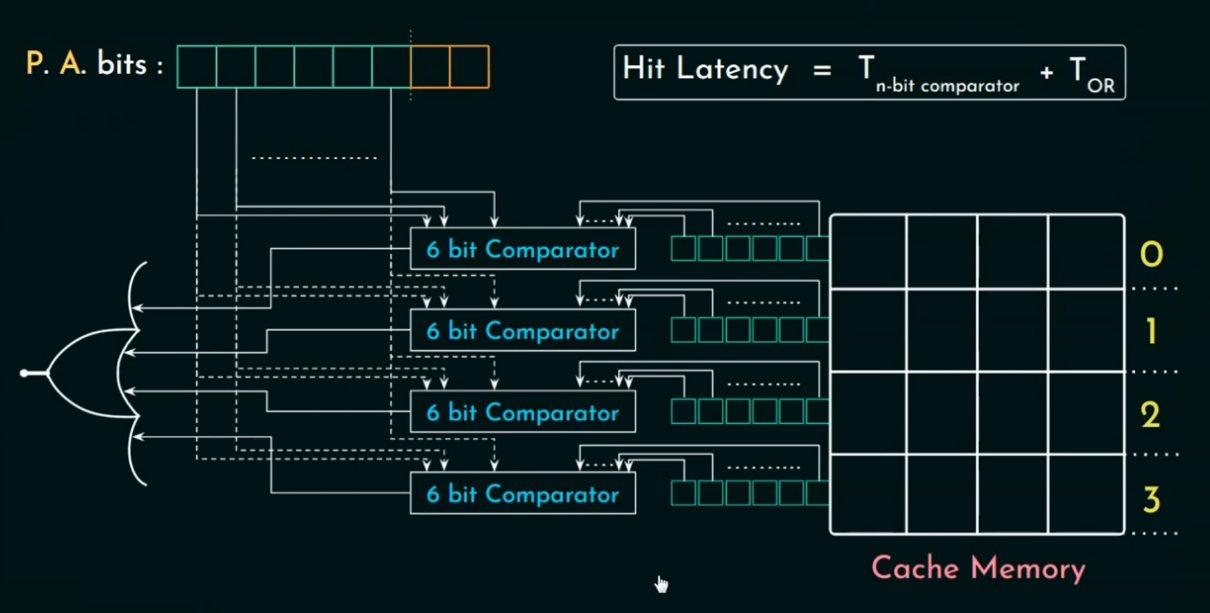
🏗️ 工作原理简述:
-
读请求发起:CPU 提供一个主存地址。
-
提取 Tag:从地址中提取出高位 Tag。
-
并行比较(Parallel Comparison):
-
将该 Tag 与 Cache 中 每一行的 Tag 字段并行比较。
-
若某一行匹配且 valid bit = 1,表示命中(Hit)。
-
否则 Miss(未命中)。
-
实现这一过程需要 N 个比较器(N-way comparators),其中 N 是 Cache 行数,因此硬件开销大。
优点:
-
极大地减少了 Conflict Miss(冲突未命中):因为没有固定位置,数据不再“争抢”同一条 Cache 行。
-
更灵活,缓存命中率高。
缺点:
-
查找成本高:需要将每一条 Cache 行的 Tag 都拿出来对比。要使用并行比较器,硬件实现复杂。
-
成本更高:硬件复杂度和功耗都比直接映射高很多。
虽然全相联映射能有效减少 冲突未命中,但并不能消除:
-
Compulsory Miss(冷启动未命中):首次访问某个数据块,Cache 中还没它。
-
Capacity Miss(容量未命中):当活跃数据总量超过缓存大小时发生。
-
Conflict Miss 几乎被消除,因为任何块可以放在任何位置。
举例说明:
假设:
-
Cache 有 4 行,每行能存储一个数据块;
-
每行存储:
-
Valid Bit(有效位)
-
Tag(标记)
-
Data Block(数据块)
-
| Line | Valid | Tag | Data |
|---|---|---|---|
| 0 | 1 | 0x12A | ... |
| 1 | 1 | 0x45C | ... |
| 2 | 1 | 0x7F0 | ... |
| 3 | 1 | 0xD02 | ... |
CPU 要访问地址 0x45C1100:
-
提取 Tag =
0x45C -
用 4 个比较器同时比较 4 行的 Tag 字段
-
找到 Line 1 匹配,命中(Hit)
♻️ 替换策略
当 Cache 满了,而且需要替换一行时,我们必须选一个块被淘汰。
常见策略包括:
-
LRU(Least Recently Used,最近最少使用)
-
替换最久未被访问的块
-
实现较复杂,需维护访问时间顺序
-
-
Random Replacement(随机替换)
-
随机选择一行替换
-
简单但效率不一定最优
-
-
FIFO(先进先出)
-
最早进入缓存的块先被替换
-
结构上比 LRU 更容易实现
-
🔍 命中延迟(Hit Latency)
Hit Latency 是指 当访问的内存块已经在缓存中时,完成数据访问所需的时间,也就是说,这是在 cache 命中的情况下,系统从 cache 中获取数据所用的时间。
在结构上,hit latency 通常包括:
-
比较 Tag 的时间(也就是比较地址中的 tag 和缓存中所有 tag 的时间)
-
识别是否命中(命中线路的逻辑判断),通常通过一个 多输入 OR 门 得出是否有某一行匹配
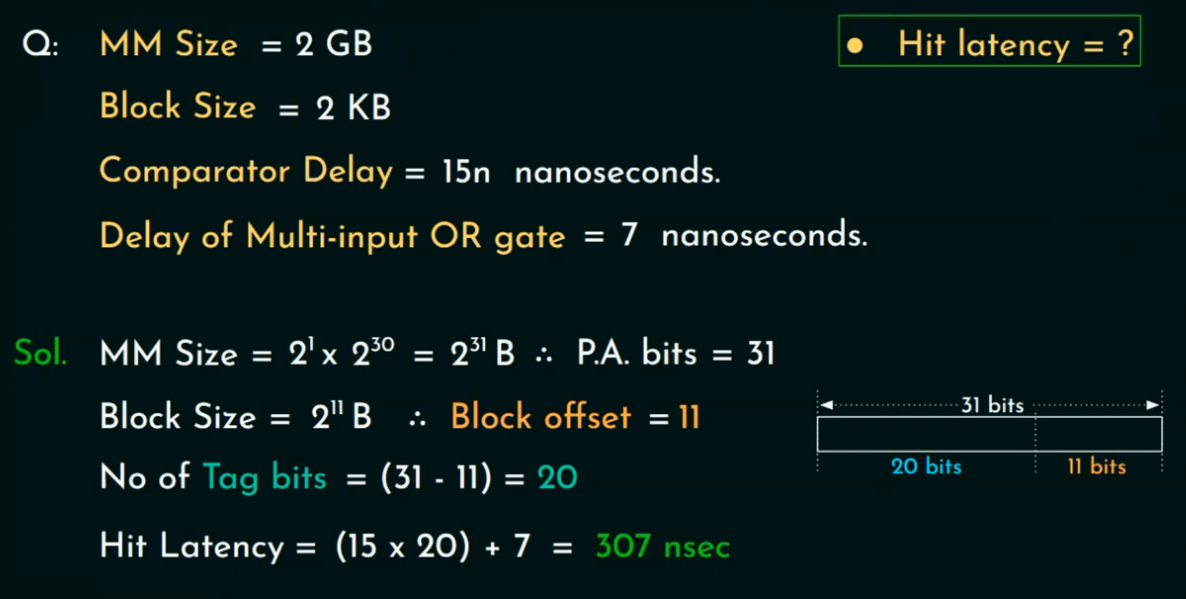
例题: